 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pushing Paraphrase Away from Original Sentence: A Multi-Round Paraphrase Generation Approach
Sep 04, 2021
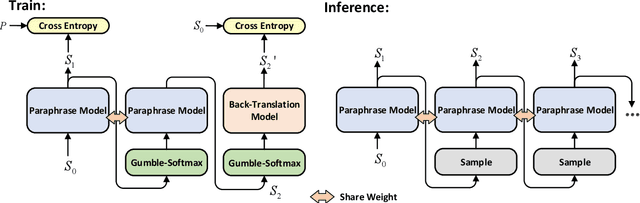
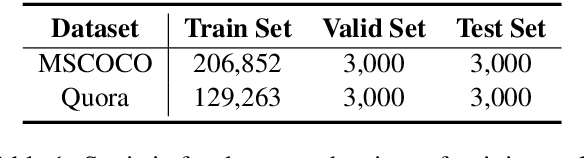
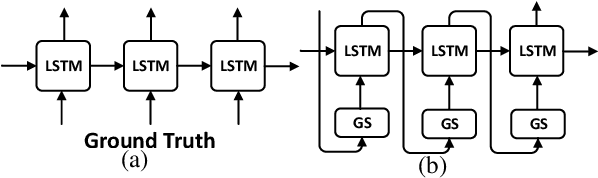
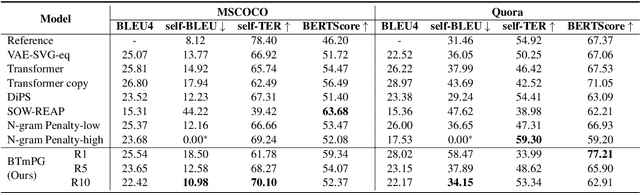
In recent years, neural paraphrase generation based on Seq2Seq has achieved superior performance, however, the generated paraphrase still has the problem of lack of diversity. In this paper, we focus on improving the diversity between the generated paraphrase and the original sentence, i.e., making generated paraphrase different from the original sentence as much as possible. We propose BTmPG (Back-Translation guided multi-round Paraphrase Generation), which leverages multi-round paraphrase generation to improve diversity and employs back-translation to preserve semantic information. We evaluate BTmPG on two benchmark datasets. Both automatic and human evaluation show BTmPG can improve the diversity of paraphrase while preserving the semantics of the original sentence.
AliMe MKG: A Multi-modal Knowledge Graph for Live-streaming E-commerce
Sep 13, 2021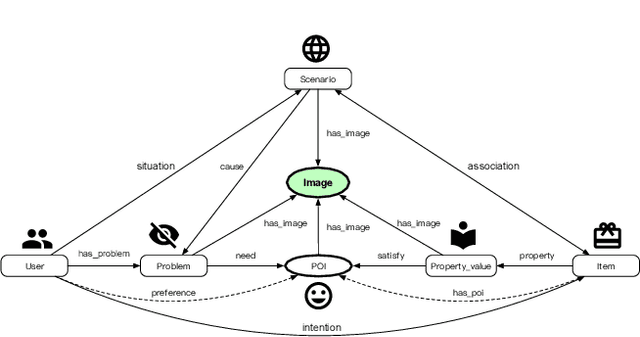
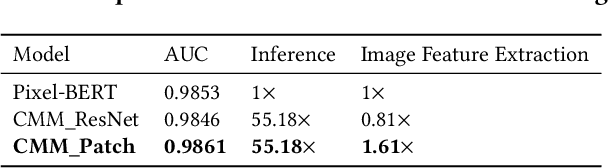
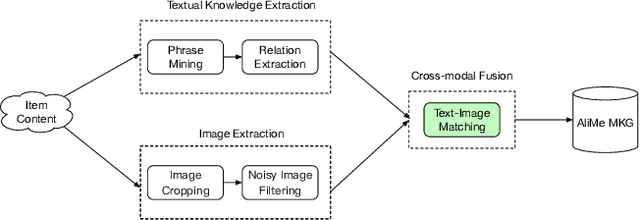
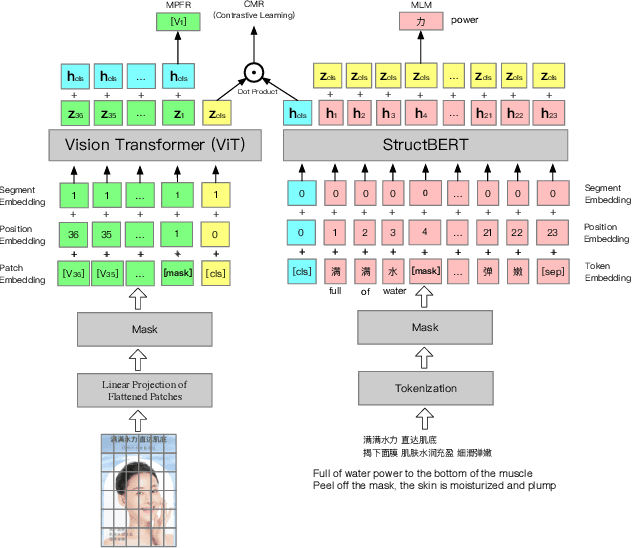
Live streaming is becoming an increasingly popular trend of sales in E-commerce. The core of live-streaming sales is to encourage customers to purchase in an online broadcasting room. To enable customers to better understand a product without jumping out, we propose AliMe MKG, a multi-modal knowledge graph that aims at providing a cognitive profile for products, through which customers are able to seek information about and understand a product. Based on the MKG, we build an online live assistant that highlights product search, product exhibition and question answering, allowing customers to skim over item list, view item details, and ask item-related questions. Our system has been launched online in the Taobao app, and currently serves hundreds of thousands of customers per day.
A Deep, Information-theoretic Framework for Robust Biometric Recognition
Feb 23, 2019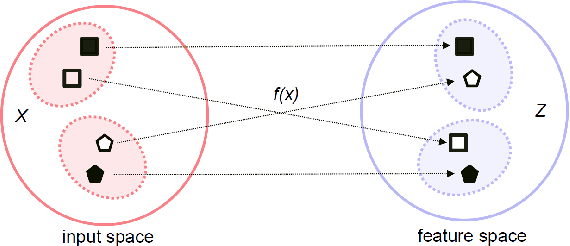

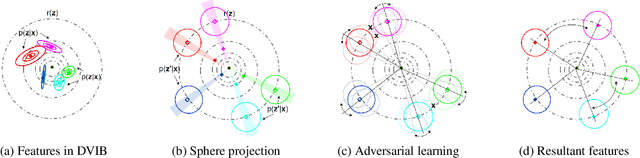

Deep neural networks (DNN) have been a de facto standard for nowadays biometric recognition solutions. A serious, but still overlooked problem in these DNN-based recognition systems is their vulnerability against adversarial attacks. Adversarial attacks can easily cause the output of a DNN system to greatly distort with only tiny changes in its input. Such distortions can potentially lead to an unexpected match between a valid biometric and a synthetic one constructed by a strategic attacker, raising security issue. In this work, we show how this issue can be resolved by learning robust biometric features through a deep, information-theoretic framework, which builds upon the recent deep variational information bottleneck method but is carefully adapted to biometric recognition tasks. Empirical evaluation demonstrates that our method not only offers stronger robustness against adversarial attacks but also provides better recognition performance over state-of-the-art approaches.
EventNarrative: A large-scale Event-centric Dataset for Knowledge Graph-to-Text Generation
Oct 30, 2021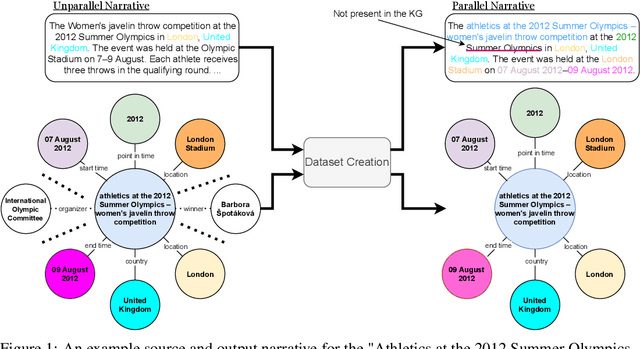



We introduce EventNarrative, a knowledge graph-to-text dataset from publicly available open-world knowledge graphs. Given the recent advances in event-driven Information Extraction (IE), and that prior research on graph-to-text only focused on entity-driven KGs, this paper focuses on event-centric data. However, our data generation system can still be adapted to other other types of KG data. Existing large-scale datasets in the graph-to-text area are non-parallel, meaning there is a large disconnect between the KGs and text. The datasets that have a paired KG and text, are small scale and manually generated or generated without a rich ontology, making the corresponding graphs sparse. Furthermore, these datasets contain many unlinked entities between their KG and text pairs. EventNarrative consists of approximately 230,000 graphs and their corresponding natural language text, 6 times larger than the current largest parallel dataset. It makes use of a rich ontology, all of the KGs entities are linked to the text, and our manual annotations confirm a high data quality. Our aim is two-fold: help break new ground in event-centric research where data is lacking, and to give researchers a well-defined, large-scale dataset in order to better evaluate existing and future knowledge graph-to-text models. We also evaluate two types of baseline on EventNarrative: a graph-to-text specific model and two state-of-the-art language models, which previous work has shown to be adaptable to the knowledge graph-to-text domain.
Autonomous Urban Localization and Navigation with Limited Information
Oct 09, 2018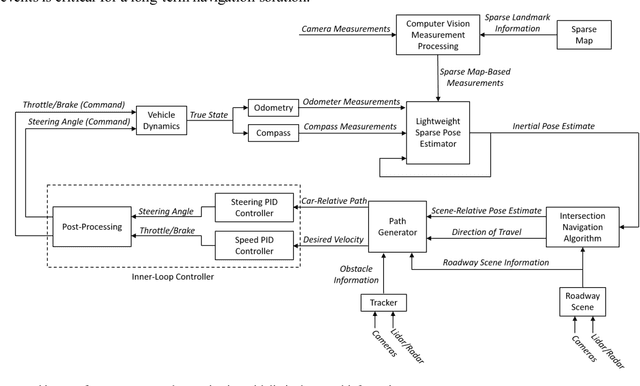
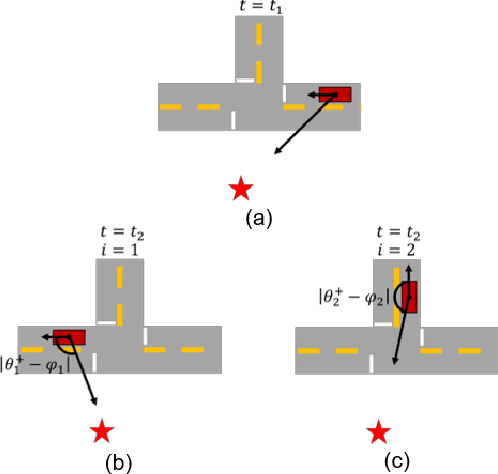
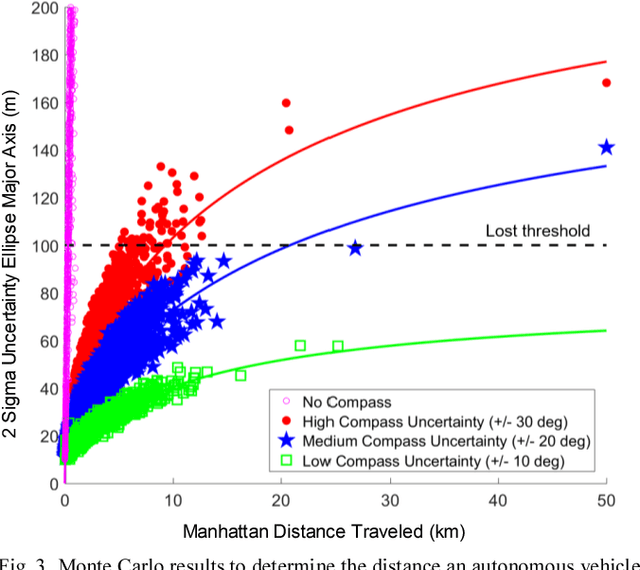
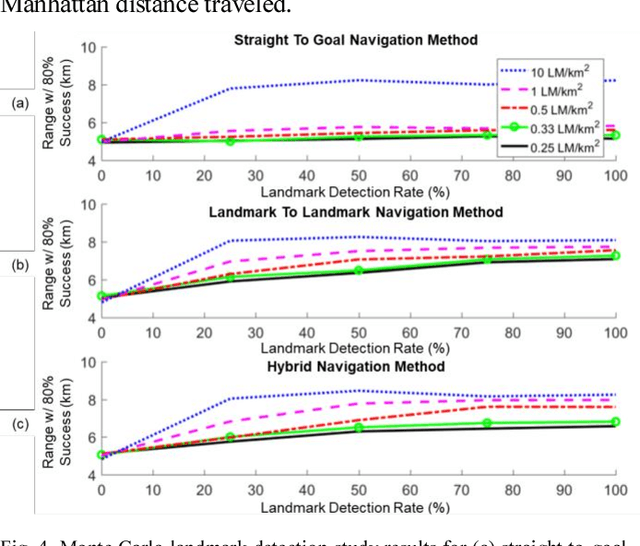
Urban environments offer a challenging scenario for autonomous driving. Globally localizing information, such as a GPS signal, can be unreliable due to signal shadowing and multipath errors. Detailed a priori maps of the environment with sufficient information for autonomous navigation typically require driving the area multiple times to collect large amounts of data, substantial post-processing on that data to obtain the map, and then maintaining updates on the map as the environment changes. This paper addresses the issue of autonomous driving in an urban environment by investigating algorithms and an architecture to enable fully functional autonomous driving with limited information. An algorithm to autonomously navigate urban roadways with little to no reliance on an a priori map or GPS is developed. Localization is performed with an extended Kalman filter with odometry, compass, and sparse landmark measurement updates. Navigation is accomplished by a compass-based navigation control law. Key results from Monte Carlo studies show success rates of urban navigation under different environmental conditions. Experiments validate the simulated results and demonstrate that, for given test conditions, an expected range can be found for a given success rate.
On the Optimality of Ergodic Trajectories for Information Gathering Tasks
Aug 20, 2018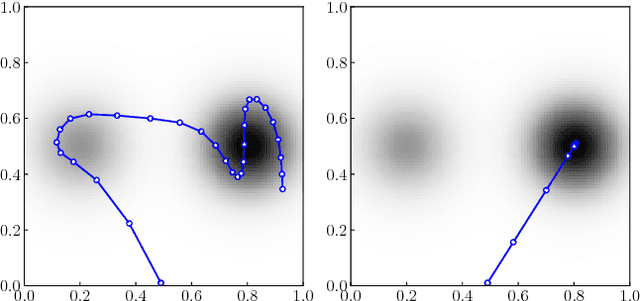
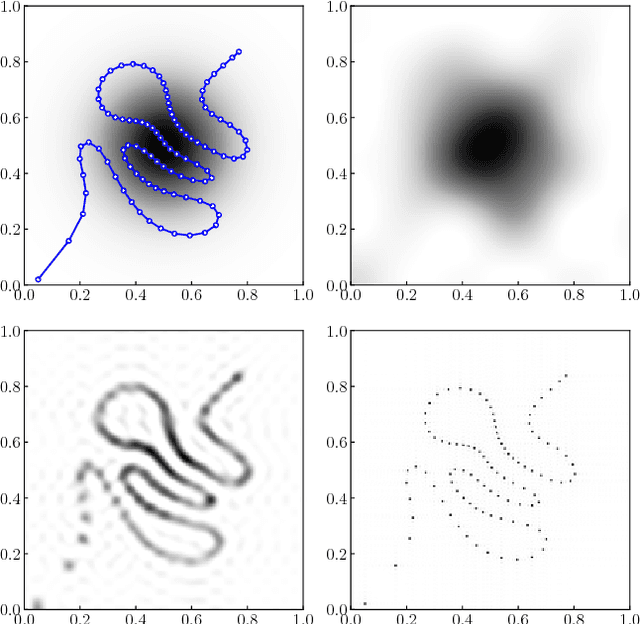
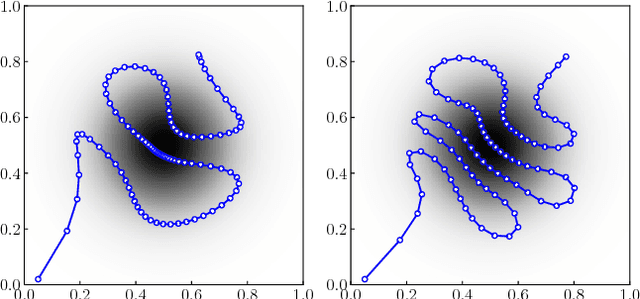
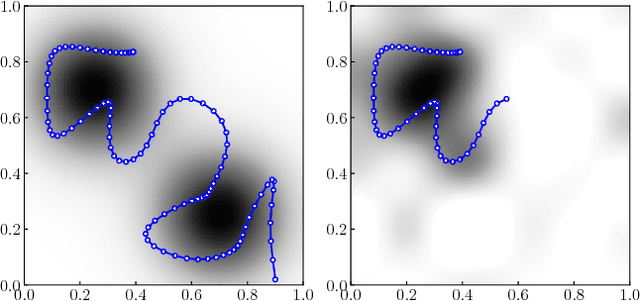
Recently, ergodic control has been suggested as a means to guide mobile sensors for information gathering tasks. In ergodic control, a mobile sensor follows a trajectory that is ergodic with respect to some information density distribution. A trajectory is ergodic if time spent in a state space region is proportional to the information density of the region. Although ergodic control has shown promising experimental results, there is little understanding of why it works or when it is optimal. In this paper, we study a problem class under which optimal information gathering trajectories are ergodic. This class relies on a submodularity assumption for repeated measurements from the same state. It is assumed that information available in a region decays linearly with time spent there. This assumption informs selection of the horizon used in ergodic trajectory generation. We support our claims with a set of experiments that demonstrate the link between ergodicity, optimal information gathering, and submodularity.
To Beta or Not To Beta: Information Bottleneck for DigitaL Image Forensics
Aug 11, 2019
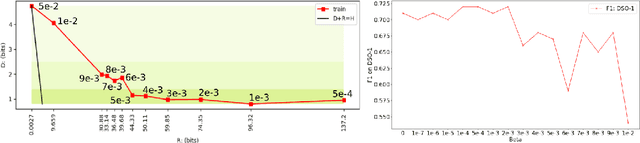

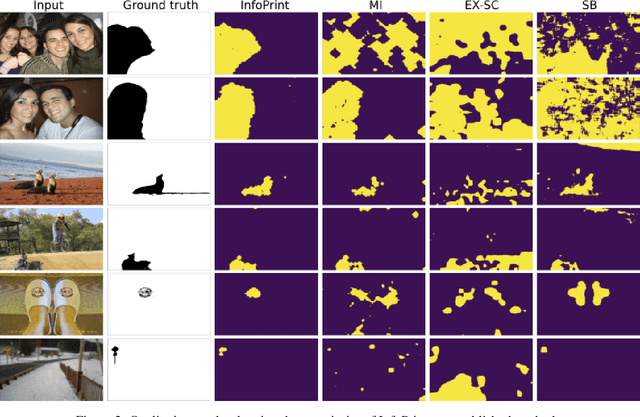
We consider an information theoretic approach to address the problem of identifying fake digital images. We propose an innovative method to formulate the issue of localizing manipulated regions in an image as a deep representation learning problem using the Information Bottleneck (IB), which has recently gained popularity as a framework for interpreting deep neural networks. Tampered images pose a serious predicament since digitized media is a ubiquitous part of our lives. These are facilitated by the easy availability of image editing software and aggravated by recent advances in deep generative models such as GANs. We propose InfoPrint, a computationally efficient solution to the IB formulation using approximate variational inference and compare it to a numerical solution that is computationally expensive. Testing on a number of standard datasets, we demonstrate that InfoPrint outperforms the state-of-the-art and the numerical solution. Additionally, it also has the ability to detect alterations made by inpainting GANs.
CertainNet: Sampling-free Uncertainty Estimation for Object Detection
Oct 04, 2021
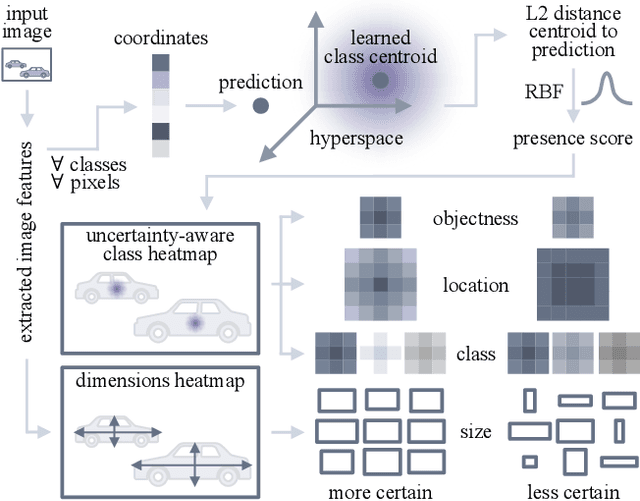
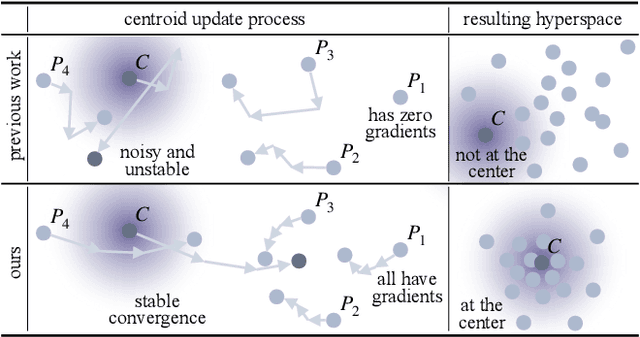
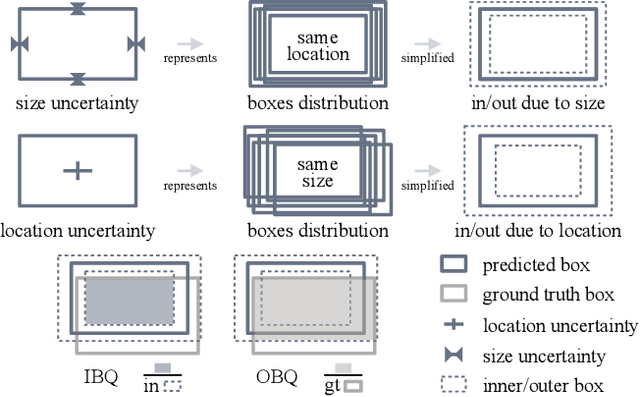
Estimating the uncertainty of a neural network plays a fundamental role in safety-critical settings. In perception for autonomous driving, measuring the uncertainty means providing additional calibrated information to downstream tasks, such as path planning, that can use it towards safe navigation. In this work, we propose a novel sampling-free uncertainty estimation method for object detection. We call it CertainNet, and it is the first to provide separate uncertainties for each output signal: objectness, class, location and size. To achieve this, we propose an uncertainty-aware heatmap, and exploit the neighboring bounding boxes provided by the detector at inference time. We evaluate the detection performance and the quality of the different uncertainty estimates separately, also with challenging out-of-domain samples: BDD100K and nuImages with models trained on KITTI. Additionally, we propose a new metric to evaluate location and size uncertainties. When transferring to unseen datasets, CertainNet generalizes substantially better than previous methods and an ensemble, while being real-time and providing high quality and comprehensive uncertainty estimates.
Instance-Dependent Partial Label Learning
Oct 26, 2021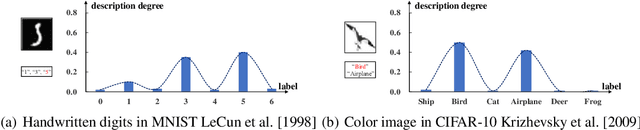
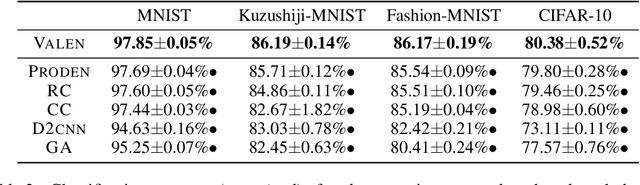
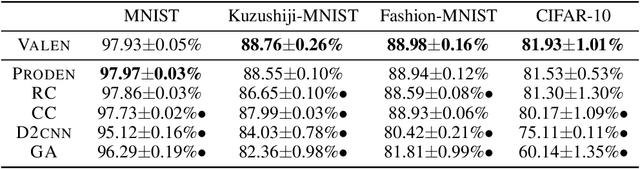
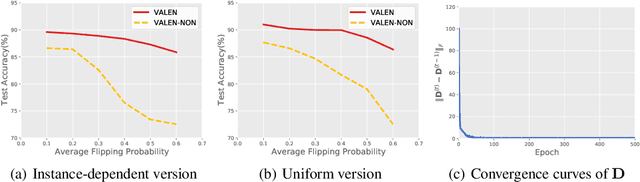
Partial label learning (PLL) is a typical weakly supervised learning problem, where each training example is associated with a set of candidate labels among which only one is true. Most existing PLL approaches assume that the incorrect labels in each training example are randomly picked as the candidate labels. However, this assumption is not realistic since the candidate labels are always instance-dependent. In this paper, we consider instance-dependent PLL and assume that each example is associated with a latent label distribution constituted by the real number of each label, representing the degree to each label describing the feature. The incorrect label with a high degree is more likely to be annotated as the candidate label. Therefore, the latent label distribution is the essential labeling information in partially labeled examples and worth being leveraged for predictive model training. Motivated by this consideration, we propose a novel PLL method that recovers the label distribution as a label enhancement (LE) process and trains the predictive model iteratively in every epoch. Specifically, we assume the true posterior density of the latent label distribution takes on the variational approximate Dirichlet density parameterized by an inference model. Then the evidence lower bound is deduced for optimizing the inference model and the label distributions generated from the variational posterior are utilized for training the predictive model. Experiments on benchmark and real-world datasets validate the effectiveness of the proposed method. Source code is available at https://github.com/palm-ml/valen.
Deep convolutional forest: a dynamic deep ensemble approach for spam detection in text
Oct 10, 2021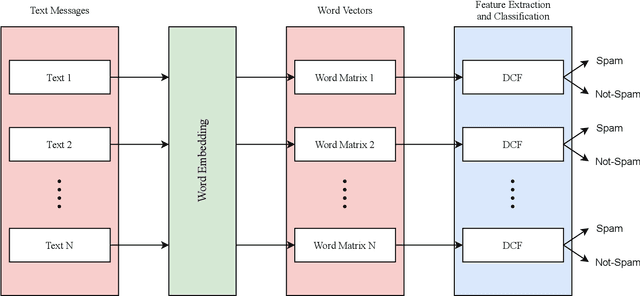



The increase in people's use of mobile messaging services has led to the spread of social engineering attacks like phishing, considering that spam text is one of the main factors in the dissemination of phishing attacks to steal sensitive data such as credit cards and passwords. In addition, rumors and incorrect medical information regarding the COVID-19 pandemic are widely shared on social media leading to people's fear and confusion. Thus, filtering spam content is vital to reduce risks and threats. Previous studies relied on machine learning and deep learning approaches for spam classification, but these approaches have two limitations. Machine learning models require manual feature engineering, whereas deep neural networks require a high computational cost. This paper introduces a dynamic deep ensemble model for spam detection that adjusts its complexity and extracts features automatically. The proposed model utilizes convolutional and pooling layers for feature extraction along with base classifiers such as random forests and extremely randomized trees for classifying texts into spam or legitimate ones. Moreover, the model employs ensemble learning procedures like boosting and bagging. As a result, the model achieved high precision, recall, f1-score and accuracy of 98.38%.