 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GLSD: The Global Large-Scale Ship Database and Baseline Evaluations
Jun 05, 2021
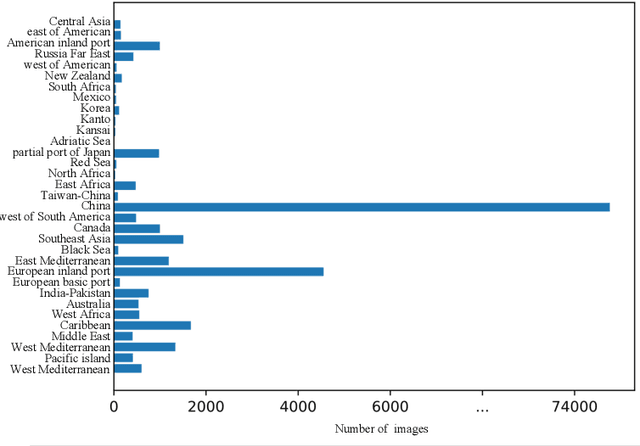


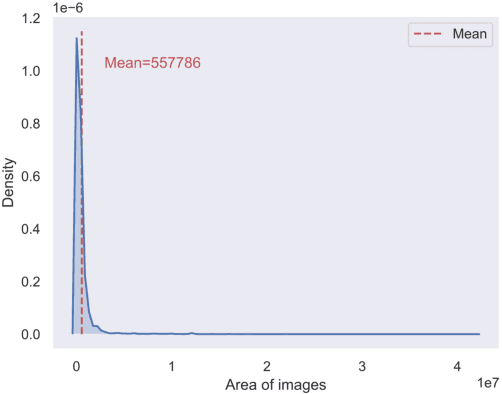
In this paper, we introduce a challenging global large-scale ship database (called GLSD), designed specifically for ship detection tasks. The designed GLSD database includes a total of 140,616 annotated instances from 100,729 images. Based on the collected images, we propose 13 categories that widely exists in international routes. These categories include sailing boat, fishing boat, passenger ship, war ship, general cargo ship, container ship, bulk cargo carrier, barge, ore carrier, speed boat, canoe, oil carrier, and tug. The motivations of developing GLSD include the following: 1) providing a refined ship detection database; 2) providing the worldwide researchers of ship detection and exhaustive label information (bounding box and ship class label) in one uniform global database; and 3) providing a large-scale ship database with geographic information (port and country information) that benefits multi-modal analysis. In addition, we discuss the evaluation protocols given image characteristics in GLSD and analyze the performance of selected state-of-the-art object detection algorithms on GSLD, providing baselines for future studies. More information regarding the designed GLSD can be found at https://github.com/jiaming-wang/GLSD.
On Homophony and Rényi Entropy
Sep 28, 2021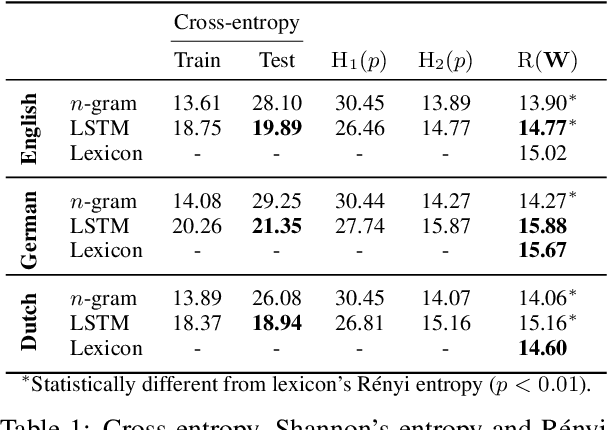
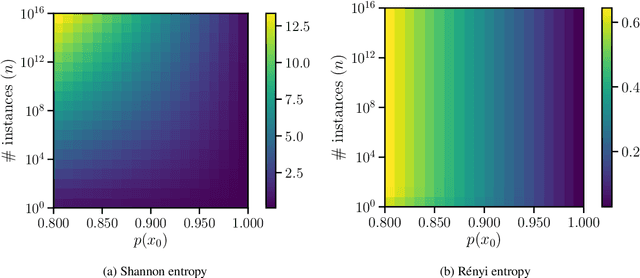
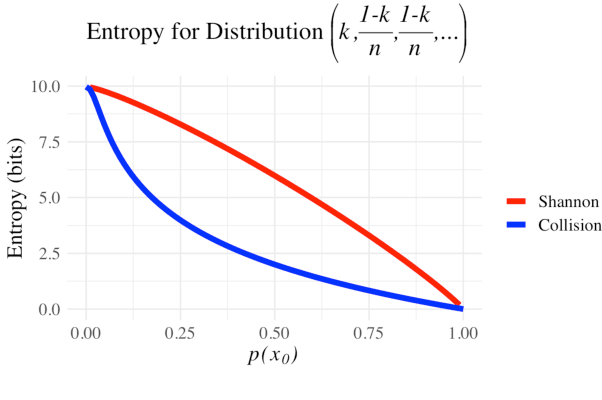
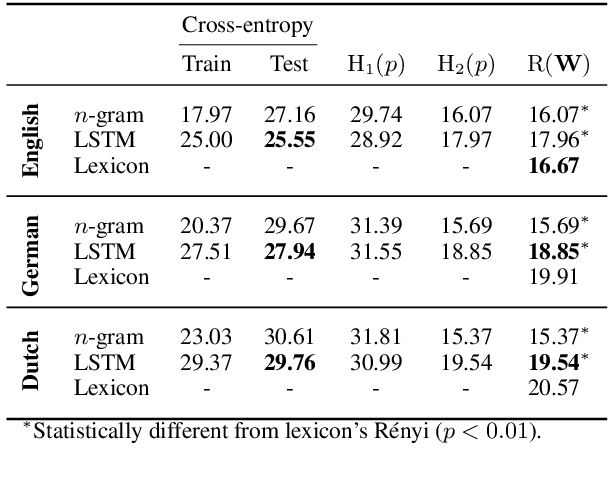
Homophony's widespread presence in natural languages is a controversial topic. Recent theories of language optimality have tried to justify its prevalence, despite its negative effects on cognitive processing time; e.g., Piantadosi et al. (2012) argued homophony enables the reuse of efficient wordforms and is thus beneficial for languages. This hypothesis has recently been challenged by Trott and Bergen (2020), who posit that good wordforms are more often homophonous simply because they are more phonotactically probable. In this paper, we join in on the debate. We first propose a new information-theoretic quantification of a language's homophony: the sample R\'enyi entropy. Then, we use this quantification to revisit Trott and Bergen's claims. While their point is theoretically sound, a specific methodological issue in their experiments raises doubts about their results. After addressing this issue, we find no clear pressure either towards or against homophony -- a much more nuanced result than either Piantadosi et al.'s or Trott and Bergen's findings.
Incentivizing an Unknown Crowd
Sep 09, 2021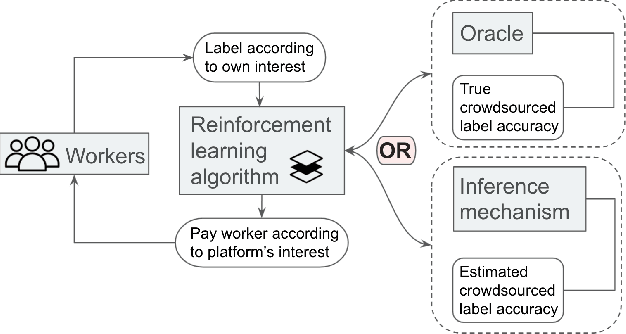
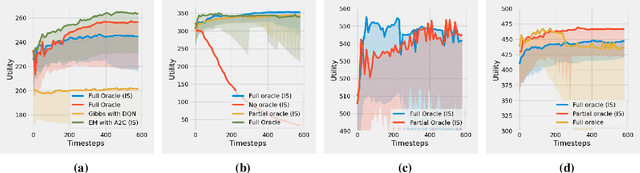
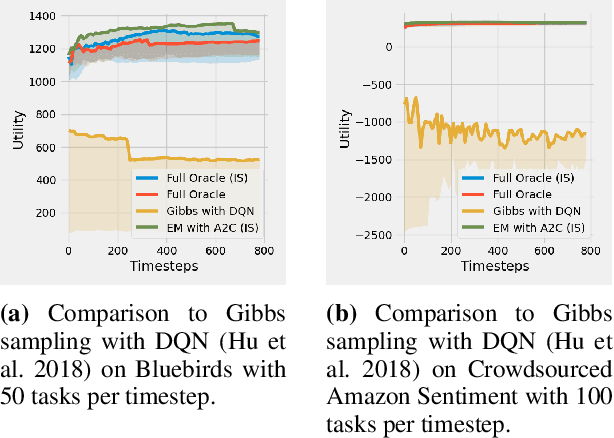
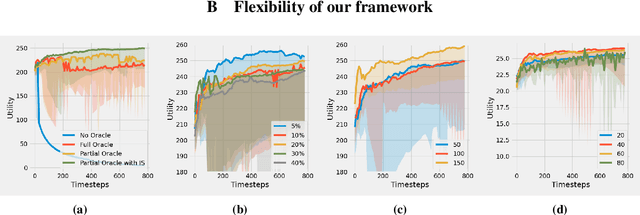
Motivated by the common strategic activities in crowdsourcing labeling, we study the problem of sequential eliciting information without verification (EIWV) for workers with a heterogeneous and unknown crowd. We propose a reinforcement learning-based approach that is effective against a wide range of settings including potential irrationality and collusion among workers. With the aid of a costly oracle and the inference method, our approach dynamically decides the oracle calls and gains robustness even under the presence of frequent collusion activities. Extensive experiments show the advantage of our approach. Our results also present the first comprehensive experiments of EIWV on large-scale real datasets and the first thorough study of the effects of environmental variables.
AutoPlace: Robust Place Recognition with Low-cost Single-chip Automotive Radar
Sep 17, 2021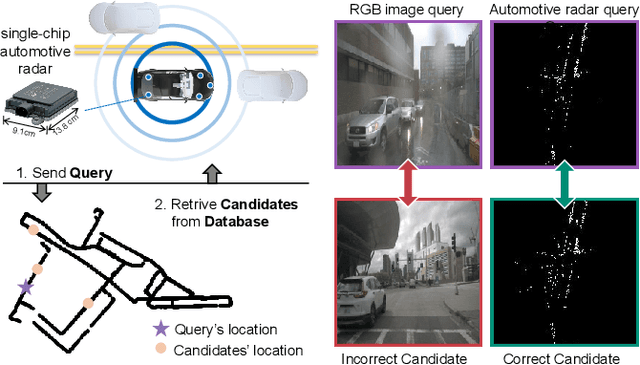
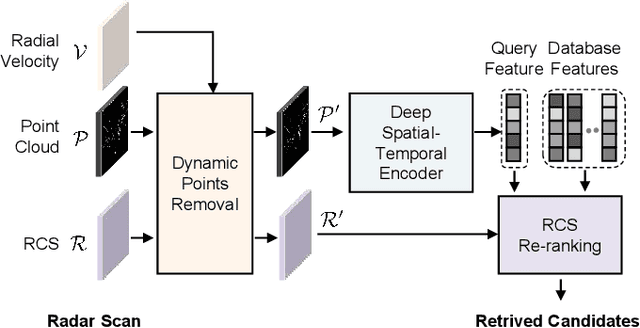
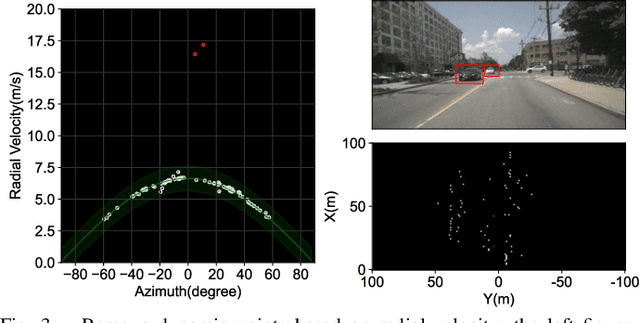
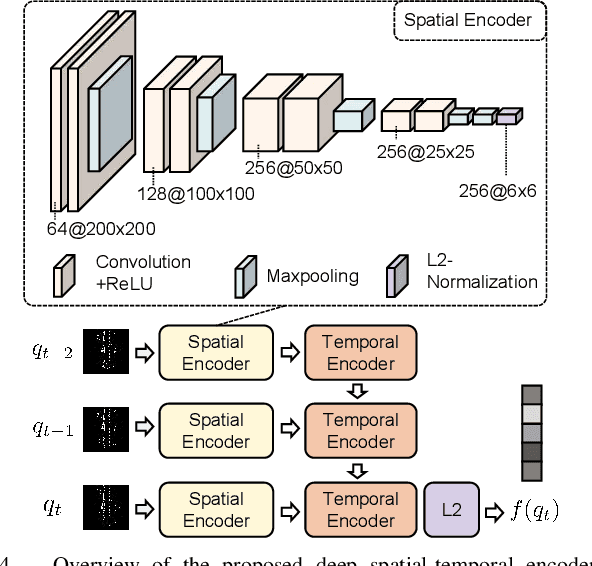
This paper presents a novel place recognition approach to autonomous vehicles by using low-cost, single-chip automotive radar. Aimed at improving recognition robustness and fully exploiting the rich information provided by this emerging automotive radar, our approach follows a principled pipeline that comprises (1) dynamic points removal from instant Doppler measurement, (2) spatial-temporal feature embedding on radar point clouds, and (3) retrieved candidates refinement from Radar Cross Section measurement. Extensive experimental results on the public nuScenes dataset demonstrate that existing visual/LiDAR/spinning radar place recognition approaches are less suitable for single-chip automotive radar. In contrast, our purpose-built approach for automotive radar consistently outperforms a variety of baseline methods via a comprehensive set of metrics, providing insights into the efficacy when used in a realistic system.
Instance-Dependent Partial Label Learning
Oct 26, 2021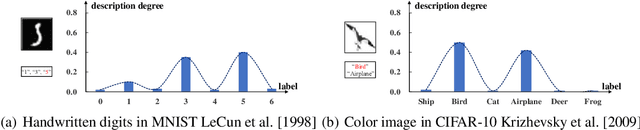
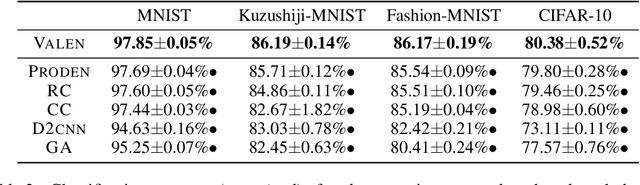
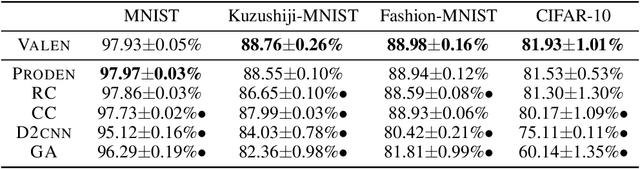
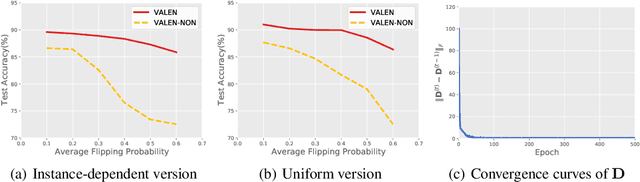
Partial label learning (PLL) is a typical weakly supervised learning problem, where each training example is associated with a set of candidate labels among which only one is true. Most existing PLL approaches assume that the incorrect labels in each training example are randomly picked as the candidate labels. However, this assumption is not realistic since the candidate labels are always instance-dependent. In this paper, we consider instance-dependent PLL and assume that each example is associated with a latent label distribution constituted by the real number of each label, representing the degree to each label describing the feature. The incorrect label with a high degree is more likely to be annotated as the candidate label. Therefore, the latent label distribution is the essential labeling information in partially labeled examples and worth being leveraged for predictive model training. Motivated by this consideration, we propose a novel PLL method that recovers the label distribution as a label enhancement (LE) process and trains the predictive model iteratively in every epoch. Specifically, we assume the true posterior density of the latent label distribution takes on the variational approximate Dirichlet density parameterized by an inference model. Then the evidence lower bound is deduced for optimizing the inference model and the label distributions generated from the variational posterior are utilized for training the predictive model. Experiments on benchmark and real-world datasets validate the effectiveness of the proposed method. Source code is available at https://github.com/palm-ml/valen.
Learning Stereopsis from Geometric Synthesis for 6D Object Pose Estimation
Sep 25, 2021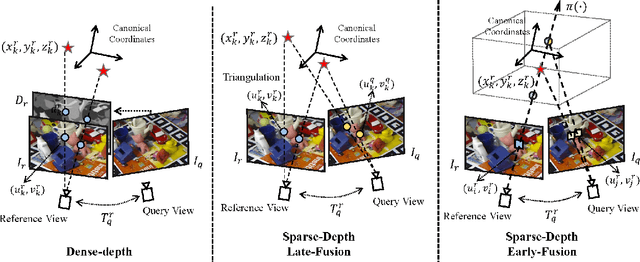
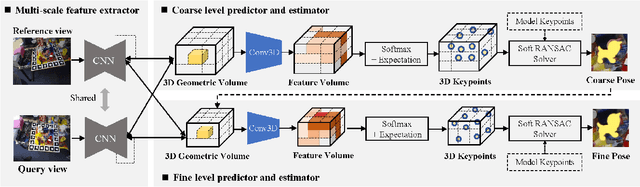
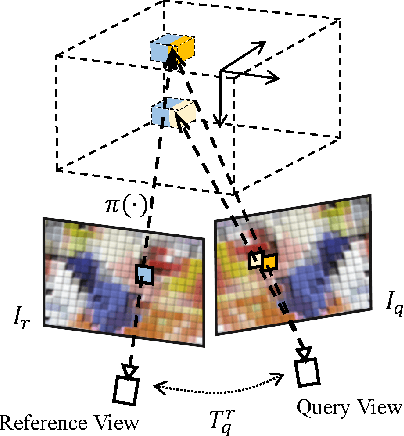
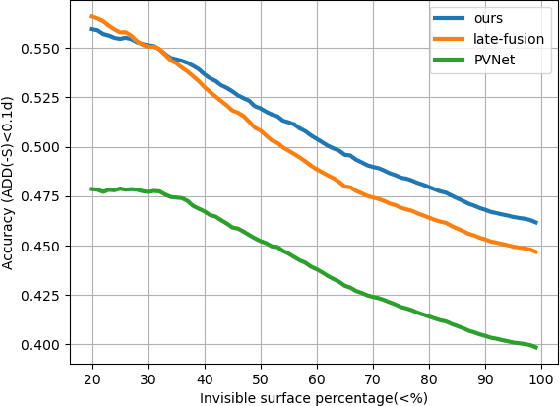
Current monocular-based 6D object pose estimation methods generally achieve less competitive results than RGBD-based methods, mostly due to the lack of 3D information. To make up this gap, this paper proposes a 3D geometric volume based pose estimation method with a short baseline two-view setting. By constructing a geometric volume in the 3D space, we combine the features from two adjacent images to the same 3D space. Then a network is trained to learn the distribution of the position of object keypoints in the volume, and a robust soft RANSAC solver is deployed to solve the pose in closed form. To balance accuracy and cost, we propose a coarse-to-fine framework to improve the performance in an iterative way. The experiments show that our method outperforms state-of-the-art monocular-based methods, and is robust in different objects and scenes, especially in serious occlusion situations.
Compound eye inspired flat lensless imaging with spatially-coded Voronoi-Fresnel phase
Sep 28, 2021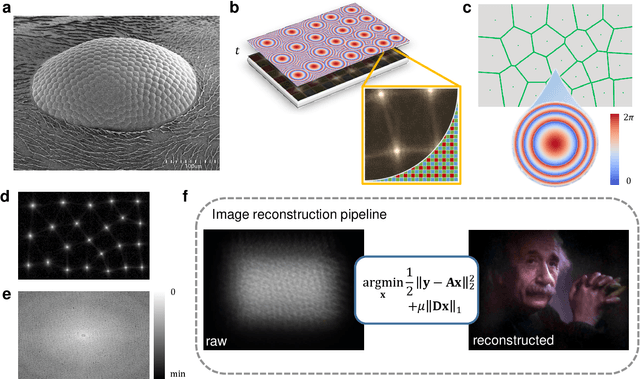
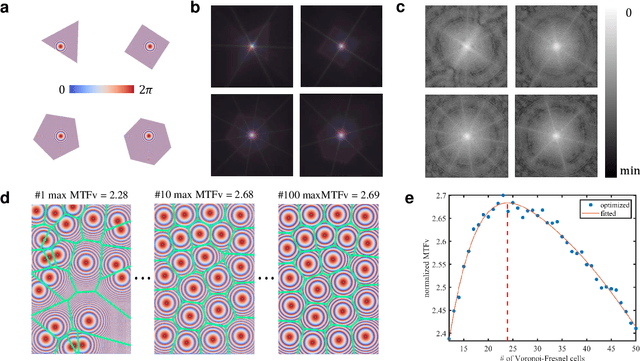

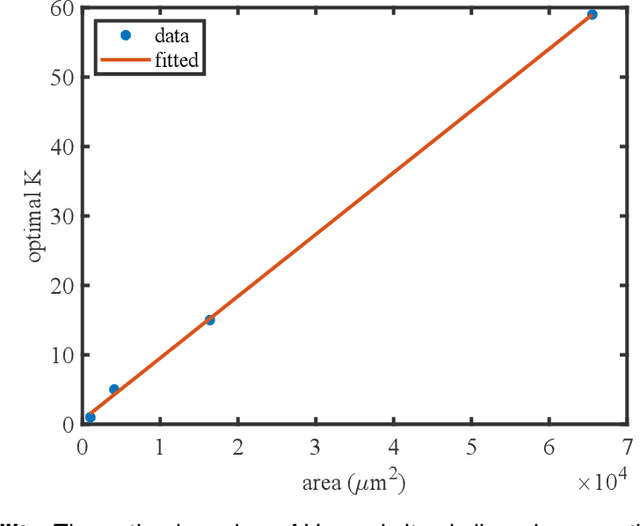
Lensless cameras are a class of imaging devices that shrink the physical dimensions to the very close vicinity of the image sensor by integrating flat optics and computational algorithms. Here we report a flat lensless camera with spatially-coded Voronoi-Fresnel phase, partly inspired by biological apposition compound eye, to achieve superior image quality. We propose a design principle of maximizing the information in optics to facilitate the computational reconstruction. By introducing a Fourier domain metric, Modulation Transfer Function volume (MTFv), we devise an optimization framework to guide the optimal design of the optical element. The resulting Voronoi-Fresnel phase features an irregular array of quasi-Centroidal Voronoi cells containing a base first-order Fresnel phase function. We demonstrate and verify the imaging performance with a prototype Voronoi-Fresnel lensless camera on a 1.6-megapixel image sensor in various illumination conditions. The proposed design could benefit the development of compact imaging systems working in extreme physical conditions.
Identifying causal associations in tweets using deep learning: Use case on diabetes-related tweets from 2017-2021
Nov 03, 2021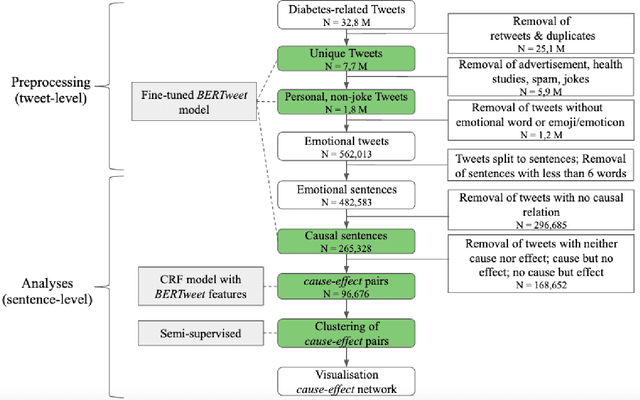
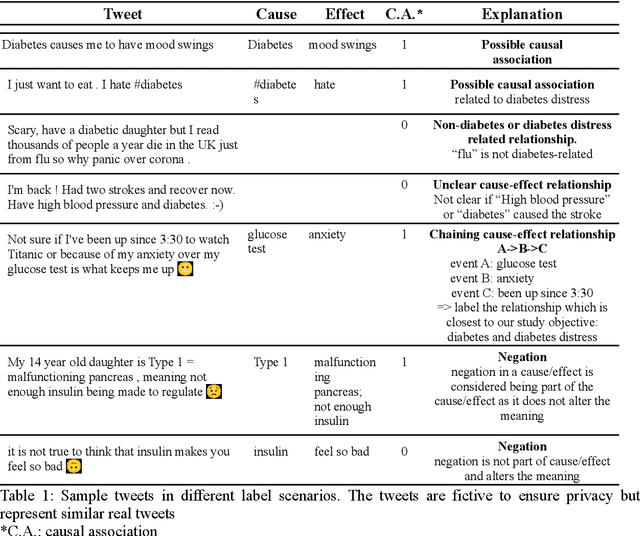
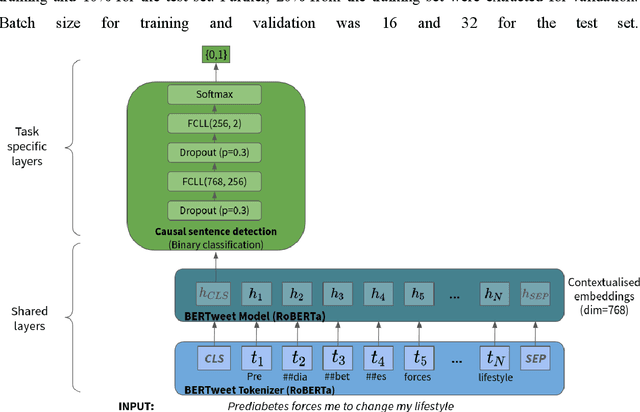
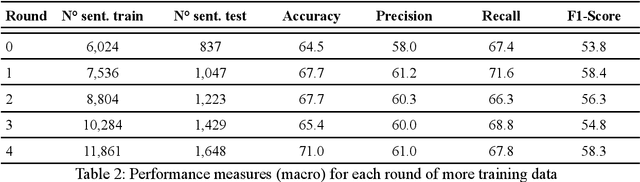
Objective: Leveraging machine learning methods, we aim to extract both explicit and implicit cause-effect associations in patient-reported, diabetes-related tweets and provide a tool to better understand opinion, feelings and observations shared within the diabetes online community from a causality perspective. Materials and Methods: More than 30 million diabetes-related tweets in English were collected between April 2017 and January 2021. Deep learning and natural language processing methods were applied to focus on tweets with personal and emotional content. A cause-effect-tweet dataset was manually labeled and used to train 1) a fine-tuned Bertweet model to detect causal sentences containing a causal association 2) a CRF model with BERT based features to extract possible cause-effect associations. Causes and effects were clustered in a semi-supervised approach and visualised in an interactive cause-effect-network. Results: Causal sentences were detected with a recall of 68% in an imbalanced dataset. A CRF model with BERT based features outperformed a fine-tuned BERT model for cause-effect detection with a macro recall of 68%. This led to 96,676 sentences with cause-effect associations. "Diabetes" was identified as the central cluster followed by "Death" and "Insulin". Insulin pricing related causes were frequently associated with "Death". Conclusions: A novel methodology was developed to detect causal sentences and identify both explicit and implicit, single and multi-word cause and corresponding effect as expressed in diabetes-related tweets leveraging BERT-based architectures and visualised as cause-effect-network. Extracting causal associations on real-life, patient reported outcomes in social media data provides a useful complementary source of information in diabetes research.
Polarity in the Classroom: A Case Study Leveraging Peer Sentiment Toward Scalable Assessment
Aug 02, 2021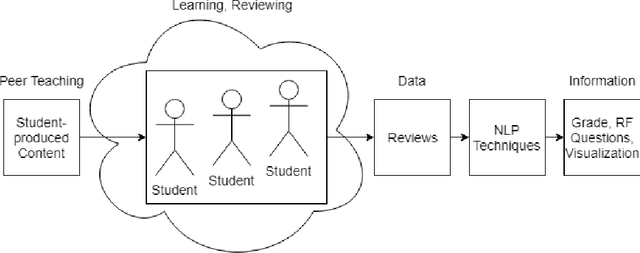

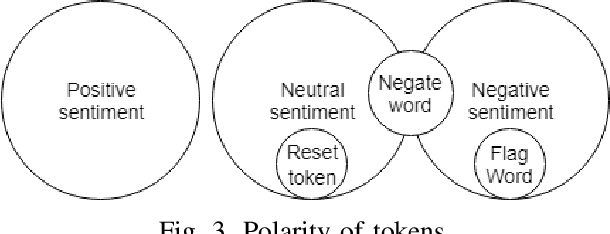
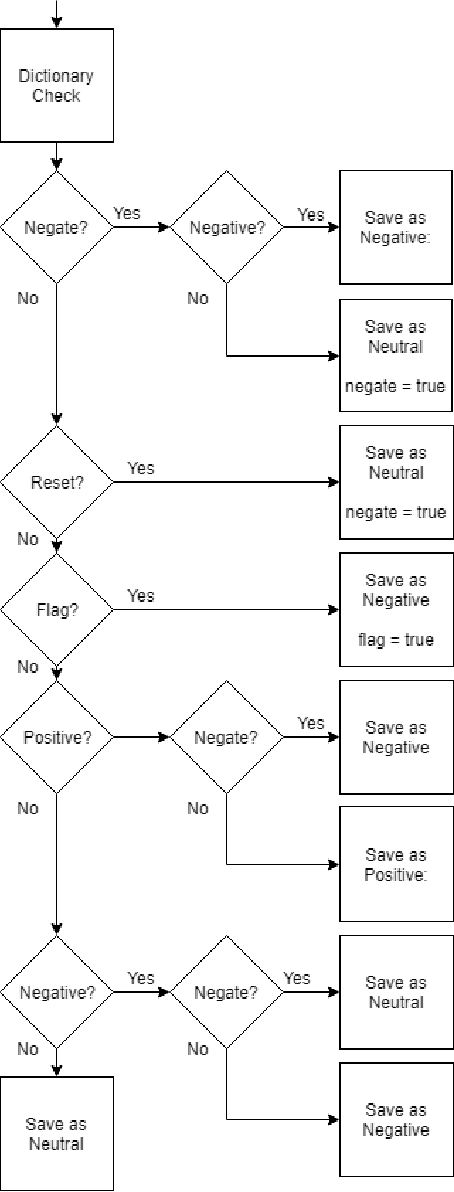
Accurately grading open-ended assignments in large or massive open online courses (MOOCs) is non-trivial. Peer review is a promising solution but can be unreliable due to few reviewers and an unevaluated review form. To date, no work has 1) leveraged sentiment analysis in the peer-review process to inform or validate grades or 2) utilized aspect extraction to craft a review form from what students actually communicated. Our work utilizes, rather than discards, student data from review form comments to deliver better information to the instructor. In this work, we detail the process by which we create our domain-dependent lexicon and aspect-informed review form as well as our entire sentiment analysis algorithm which provides a fine-grained sentiment score from text alone. We end by analyzing validity and discussing conclusions from our corpus of over 6800 peer reviews from nine courses to understand the viability of sentiment in the classroom for increasing the information from and reliability of grading open-ended assignments in large courses.
Bayesian Over-The-Air Computation
Sep 08, 2021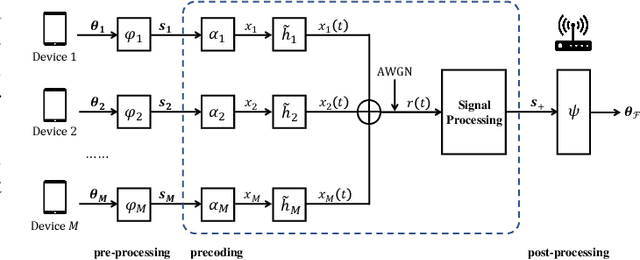
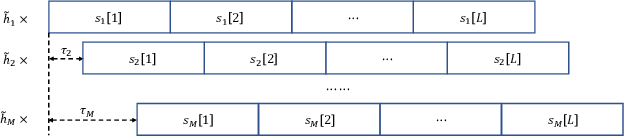
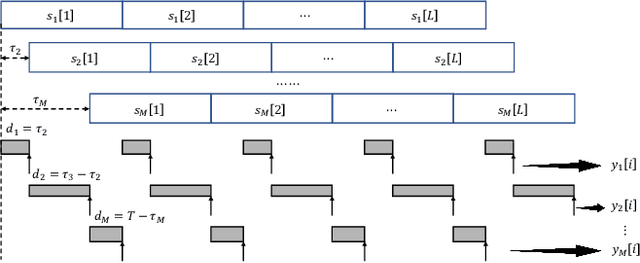
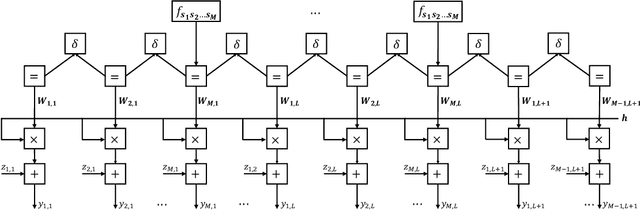
Analog over-the-air computation (OAC) is an efficient solution to a class of uplink data aggregation tasks over a multiple-access channel (MAC), wherein the receiver, dubbed the fusion center, aims to reconstruct a function of the data distributed at edge devices rather than the individual data themselves. Existing OAC relies exclusively on the maximum likelihood (ML) estimation at the fusion center to recover the arithmetic sum of the transmitted signals from different devices. ML estimation, however, is much susceptible to noise. In particular, in the misaligned OAC where there are channel misalignments among transmitted signals, ML estimation suffers from severe error propagation and noise enhancement. To address these challenges, this paper puts forth a Bayesian approach for OAC by letting each edge device transmit two pieces of prior information to the fusion center. Three OAC systems are studied: the aligned OAC with perfectly-aligned signals; the synchronous OAC with misaligned channel gains among the received signals; and the asynchronous OAC with both channel-gain and time misalignments. Using the prior information, we devise linear minimum mean squared error (LMMSE) estimators and a sum-product maximum a posteriori (SP-MAP) estimator for the three OAC systems. Numerical results verify that, 1) For the aligned and synchronous OAC, our LMMSE estimator significantly outperforms the ML estimator. In the low signal-to-noise ratio (SNR) regime, the LMMSE estimator reduces the mean squared error (MSE) by at least 6 dB; in the high SNR regime, the LMMSE estimator lowers the error floor on the MSE by 86.4%; 2) For the asynchronous OAC, our LMMSE and SP-MAP estimators are on an equal footing in terms of the MSE performance, and are significantly better than the ML estimator.