 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Elevation Angle-Dependent Trajectory Design for Aerial RIS-aided Communication
Sep 10, 2021
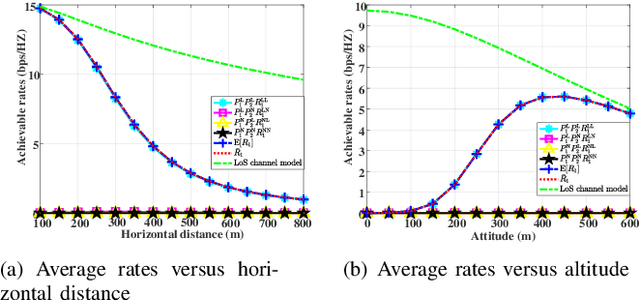
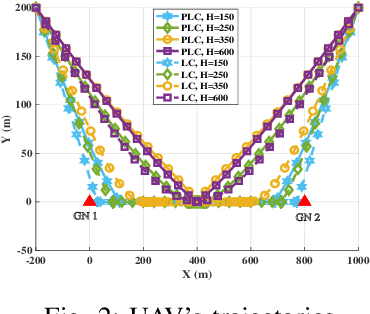
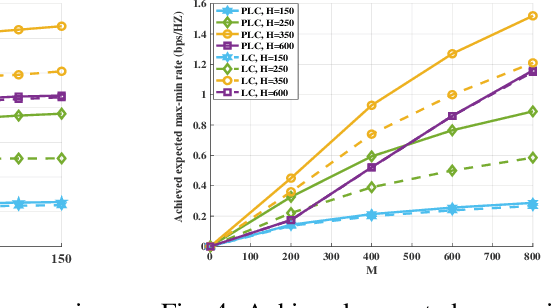
This paper investigates an aerial reconfigurable intelligent surface (RIS)-aided communication system under the probabilistic line-of-sight (LoS) channel, where an unmanned aerial vehicle (UAV) equipped with an RIS is deployed to assist two ground nodes in their information exchange. An optimization problem with the objective of maximizing the minimum average achievable rate is formulated to design the communication scheduling, the RIS's phase, and the UAV trajectory. To solve such a non-convex problem, we propose an efficient iterative algorithm to obtain its suboptimal solution. Simulation results show that our proposed design significantly outperforms the existing schemes and provides new insights into the elevation angle and distance trade-off for the UAV-borne RIS communication system.
Chaos as an interpretable benchmark for forecasting and data-driven modelling
Oct 11, 2021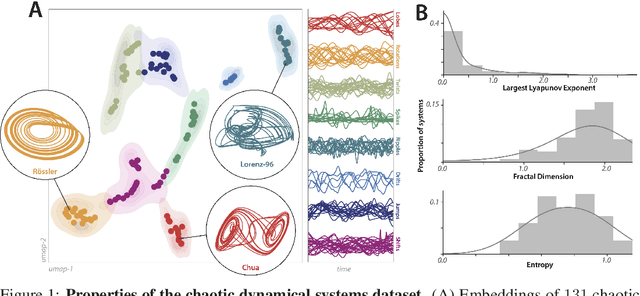

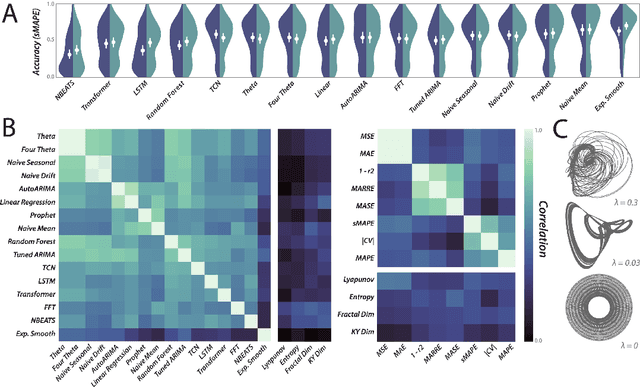
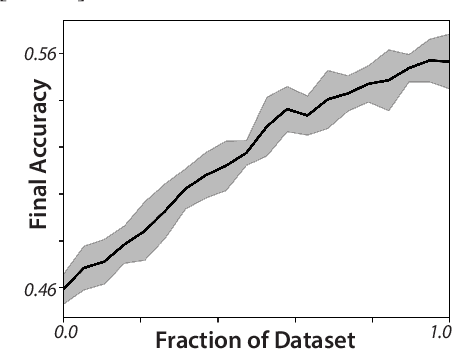
The striking fractal geometry of strange attractors underscores the generative nature of chaos: like probability distributions, chaotic systems can be repeatedly measured to produce arbitrarily-detailed information about the underlying attractor. Chaotic systems thus pose a unique challenge to modern statistical learning techniques, while retaining quantifiable mathematical properties that make them controllable and interpretable as benchmarks. Here, we present a growing database currently comprising 131 known chaotic dynamical systems spanning fields such as astrophysics, climatology, and biochemistry. Each system is paired with precomputed multivariate and univariate time series. Our dataset has comparable scale to existing static time series databases; however, our systems can be re-integrated to produce additional datasets of arbitrary length and granularity. Our dataset is annotated with known mathematical properties of each system, and we perform feature analysis to broadly categorize the diverse dynamics present across the collection. Chaotic systems inherently challenge forecasting models, and across extensive benchmarks we correlate forecasting performance with the degree of chaos present. We also exploit the unique generative properties of our dataset in several proof-of-concept experiments: surrogate transfer learning to improve time series classification, importance sampling to accelerate model training, and benchmarking symbolic regression algorithms.
* 10 pages, 4 figures, plus appendices
QAInfomax: Learning Robust Question Answering System by Mutual Information Maximization
Aug 31, 2019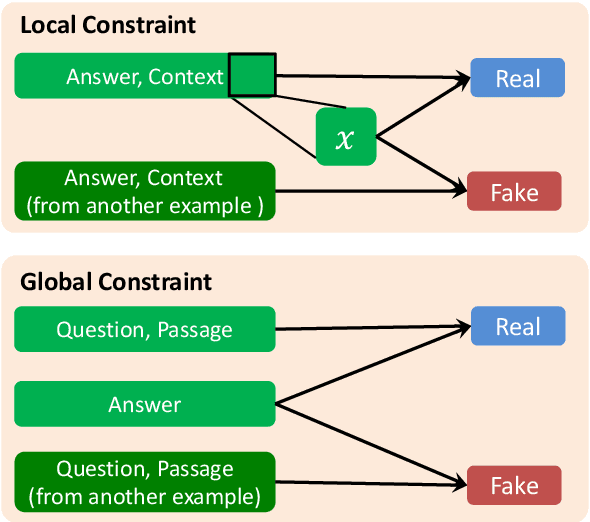
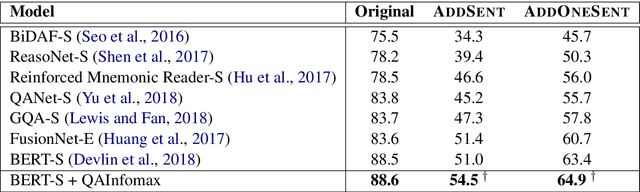

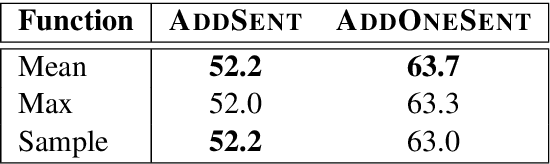
Standard accuracy metrics indicate that modern reading comprehension systems have achieved strong performance in many question answering datasets. However, the extent these systems truly understand language remains unknown, and existing systems are not good at distinguishing distractor sentences, which look related but do not actually answer the question. To address this problem, we propose QAInfomax as a regularizer in reading comprehension systems by maximizing mutual information among passages, a question, and its answer. QAInfomax helps regularize the model to not simply learn the superficial correlation for answering questions. The experiments show that our proposed QAInfomax achieves the state-of-the-art performance on the benchmark Adversarial-SQuAD dataset.
Multi-frame Joint Enhancement for Early Interlaced Videos
Sep 29, 2021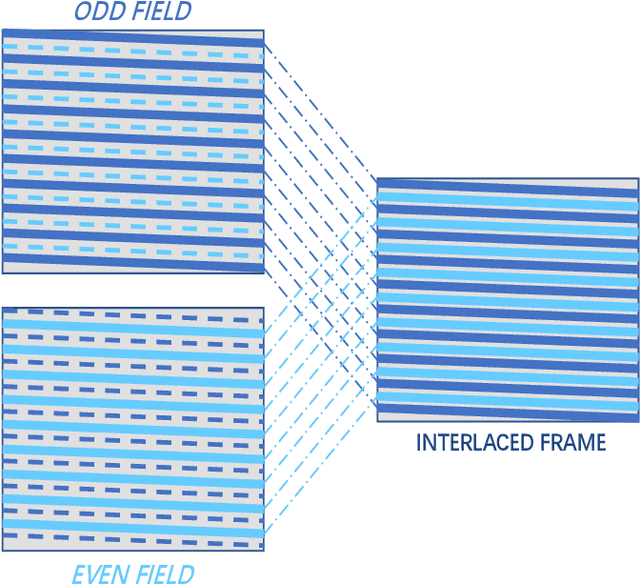


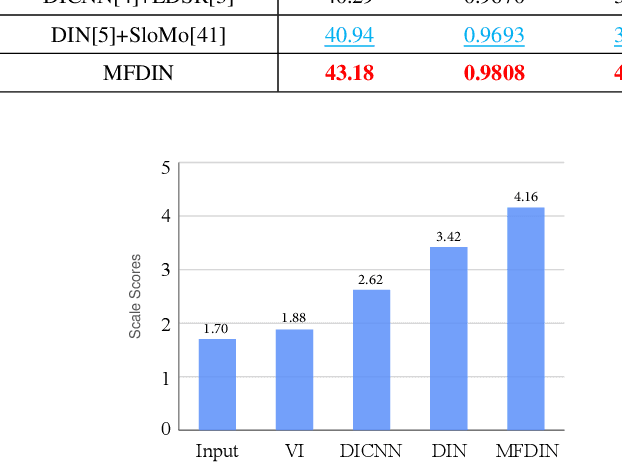
Early interlaced videos usually contain multiple and interlacing and complex compression artifacts, which significantly reduce the visual quality. Although the high-definition reconstruction technology for early videos has made great progress in recent years, related research on deinterlacing is still lacking. Traditional methods mainly focus on simple interlacing mechanism, and cannot deal with the complex artifacts in real-world early videos. Recent interlaced video reconstruction deep deinterlacing models only focus on single frame, while neglecting important temporal information. Therefore, this paper proposes a multiframe deinterlacing network joint enhancement network for early interlaced videos that consists of three modules, i.e., spatial vertical interpolation module, temporal alignment and fusion module, and final refinement module. The proposed method can effectively remove the complex artifacts in early videos by using temporal redundancy of multi-fields. Experimental results demonstrate that the proposed method can recover high quality results for both synthetic dataset and real-world early interlaced videos.
A Signal Detection Scheme Based on Deep Learning in OFDM Systems
Jul 24, 2021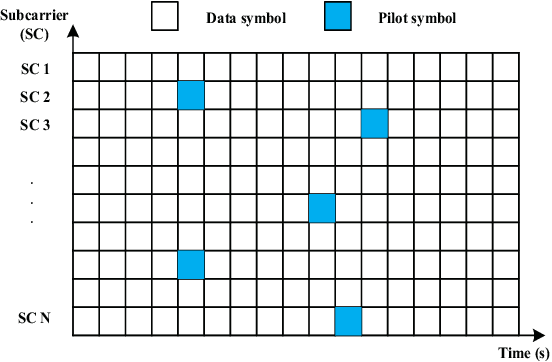
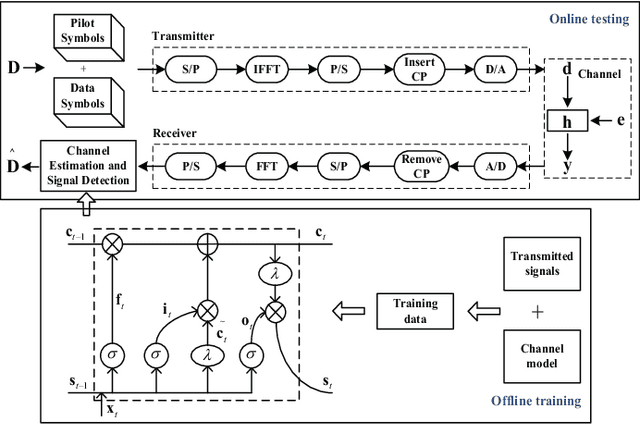
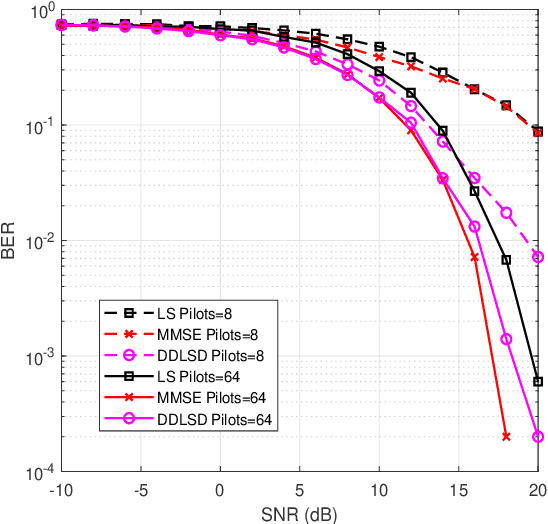
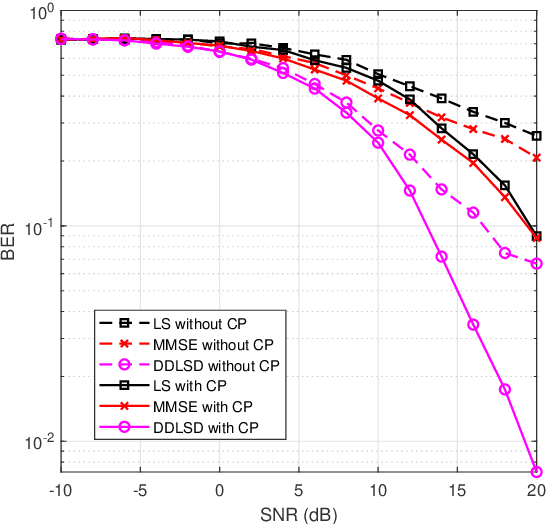
Channel estimation and signal detection are essential steps to ensure the quality of end-to-end communication in orthogonal frequency-division multiplexing (OFDM) systems. In this paper, we develop a DDLSD approach, i.e., Data-driven Deep Learning for Signal Detection in OFDM systems. First, the OFDM system model is established. Then, the long short-term memory (LSTM) is introduced into the OFDM system model. Wireless channel data is generated through simulation, the preprocessed time series feature information is input into the LSTM to complete the offline training. Finally, the trained model is used for online recovery of transmitted signal. The difference between this scheme and existing OFDM receiver is that explicit estimated channel state information (CSI) is transformed into invisible estimated CSI, and the transmit symbol is directly restored. Simulation results show that the DDLSD scheme outperforms the existing traditional methods in terms of improving channel estimation and signal detection performance.
SimulLR: Simultaneous Lip Reading Transducer with Attention-Guided Adaptive Memory
Aug 31, 2021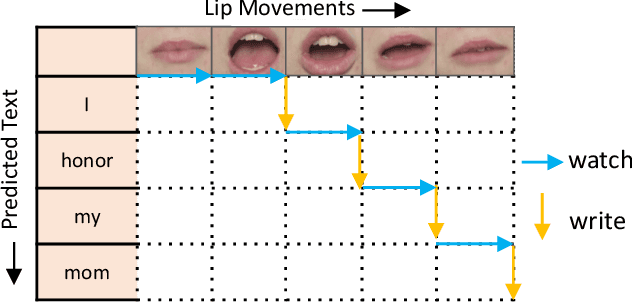
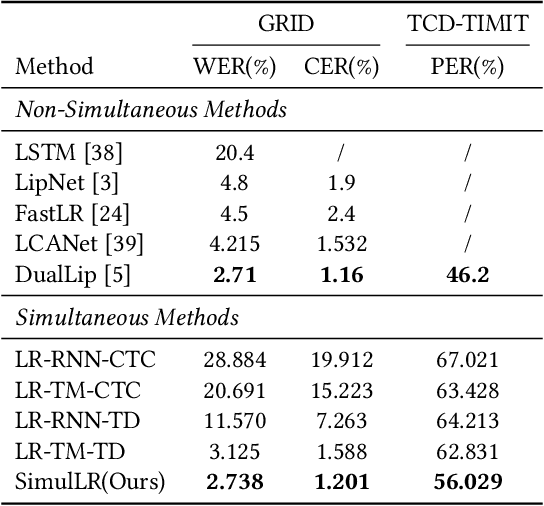
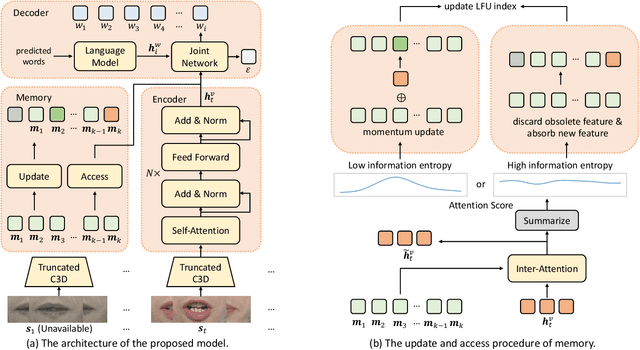
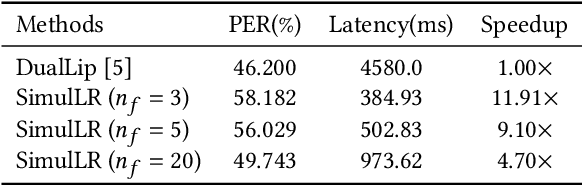
Lip reading, aiming to recognize spoken sentences according to the given video of lip movements without relying on the audio stream, has attracted great interest due to its application in many scenarios. Although prior works that explore lip reading have obtained salient achievements, they are all trained in a non-simultaneous manner where the predictions are generated requiring access to the full video. To breakthrough this constraint, we study the task of simultaneous lip reading and devise SimulLR, a simultaneous lip Reading transducer with attention-guided adaptive memory from three aspects: (1) To address the challenge of monotonic alignments while considering the syntactic structure of the generated sentences under simultaneous setting, we build a transducer-based model and design several effective training strategies including CTC pre-training, model warm-up and curriculum learning to promote the training of the lip reading transducer. (2) To learn better spatio-temporal representations for simultaneous encoder, we construct a truncated 3D convolution and time-restricted self-attention layer to perform the frame-to-frame interaction within a video segment containing fixed number of frames. (3) The history information is always limited due to the storage in real-time scenarios, especially for massive video data. Therefore, we devise a novel attention-guided adaptive memory to organize semantic information of history segments and enhance the visual representations with acceptable computation-aware latency. The experiments show that the SimulLR achieves the translation speedup 9.10$\times$ compared with the state-of-the-art non-simultaneous methods, and also obtains competitive results, which indicates the effectiveness of our proposed methods.
W-Net: A Two-Stage Convolutional Network for Nucleus Detection in Histopathology Image
Oct 26, 2021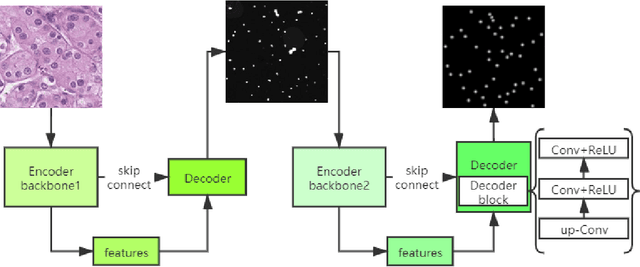

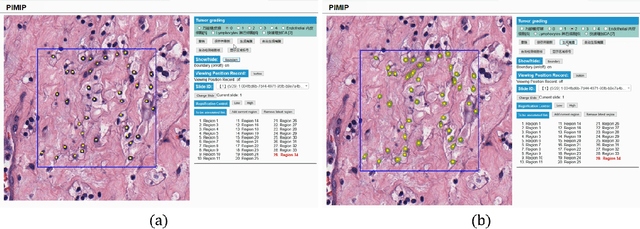
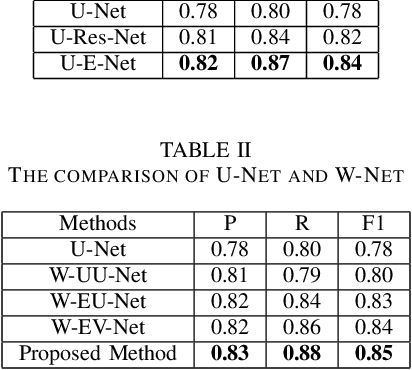
Pathological diagnosis is the gold standard for cancer diagnosis, but it is labor-intensive, in which tasks such as cell detection, classification, and counting are particularly prominent. A common solution for automating these tasks is using nucleus segmentation technology. However, it is hard to train a robust nucleus segmentation model, due to several challenging problems, the nucleus adhesion, stacking, and excessive fusion with the background. Recently, some researchers proposed a series of automatic nucleus segmentation methods based on point annotation, which can significant improve the model performance. Nevertheless, the point annotation needs to be marked by experienced pathologists. In order to take advantage of segmentation methods based on point annotation, further alleviate the manual workload, and make cancer diagnosis more efficient and accurate, it is necessary to develop an automatic nucleus detection algorithm, which can automatically and efficiently locate the position of the nucleus in the pathological image and extract valuable information for pathologists. In this paper, we propose a W-shaped network for automatic nucleus detection. Different from the traditional U-Net based method, mapping the original pathology image to the target mask directly, our proposed method split the detection task into two sub-tasks. The first sub-task maps the original pathology image to the binary mask, then the binary mask is mapped to the density mask in the second sub-task. After the task is split, the task's difficulty is significantly reduced, and the network's overall performance is improved.
Aware Adoption of AI: from Potential to Reusable Value
Oct 21, 2021
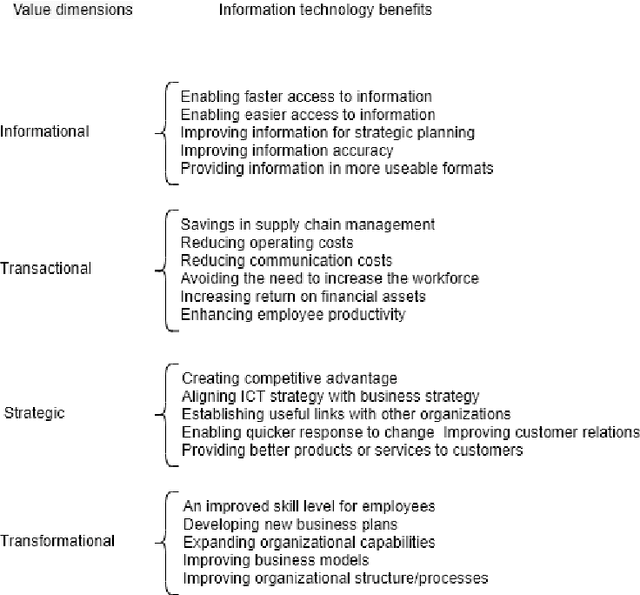
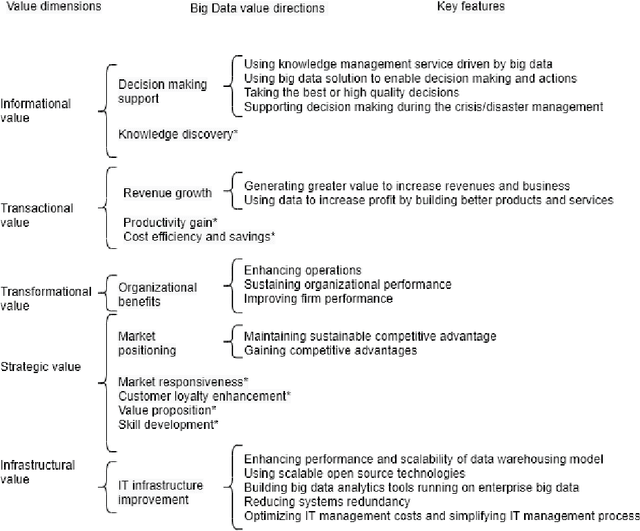
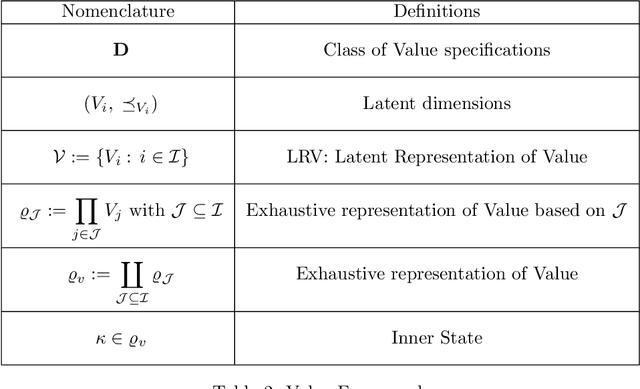
Artificial Intelligence (AI) provides practical advantages in different applied domains. This is changing the way decision-makers reason about complex systems. Indeed, broader visibility on greater information (re)sources, e.g. Big Data, is now available to intelligent agents. On the other hand, decisions are not always based on reusable, multi-purpose, and explainable knowledge. Therefore, it is necessary to define new models to describe and manage this new (re)source of uncertainty. This contribution aims to introduce a multidimensional framework to deal with the notion of Value in the AI context. In this model, Big Data represent a distinguished dimension (characteristic) of Value rather than an intrinsic property of Big Data. Great attention is paid to hidden dimensions of value, which may be linked to emerging innovation processes. The requirements to describe the framework are provided, and an associated mathematical structure is presented to deal with comparison, combination, and update of states of knowledge regarding Value. We introduce a notion of consistency of a state of knowledge to investigate the relation between Human and Artificial intelligences; this form of uncertainty is specified in analogy with two scenarios concerning decision-making and non-classical measurements. Finally, we propose future investigations aiming at the inclusion of this form of uncertainty in the assessment of impact, risks, and structural modelling.
RPBA -- Robust Parallel Bundle Adjustment Based on Covariance Information
Oct 17, 2019
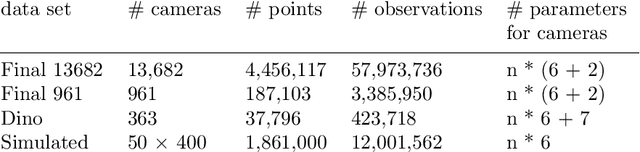


A core component of all Structure from Motion (SfM) approaches is bundle adjustment. As the latter is a computational bottleneck for larger blocks, parallel bundle adjustment has become an active area of research. Particularly, consensus-based optimization methods have been shown to be suitable for this task. We have extended them using covariance information derived by the adjustment of individual three-dimensional (3D) points, i.e., "triangulation" or "intersection". This does not only lead to a much better convergence behavior, but also avoids fiddling with the penalty parameter of standard consensus-based approaches. The corresponding novel approach can also be seen as a variant of resection / intersection schemes, where we adjust during intersection a number of sub-blocks directly related to the number of threads available on a computer each containing a fraction of the cameras of the block. We show that our novel approach is suitable for robust parallel bundle adjustment and demonstrate its capabilities in comparison to the basic consensus-based approach as well as a state-of-the-art parallel implementation of bundle adjustment. Code for our novel approach is available on GitHub: https://github.com/helmayer/RPBA
DoSSIER@COLIEE 2021: Leveraging dense retrieval and summarization-based re-ranking for case law retrieval
Aug 09, 2021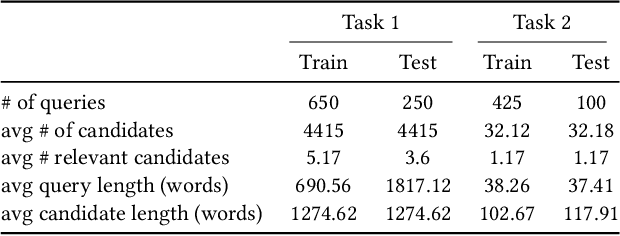
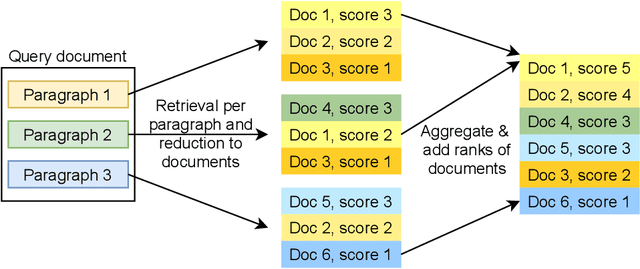
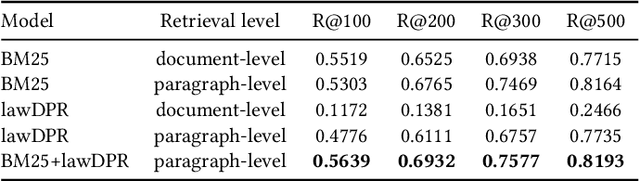
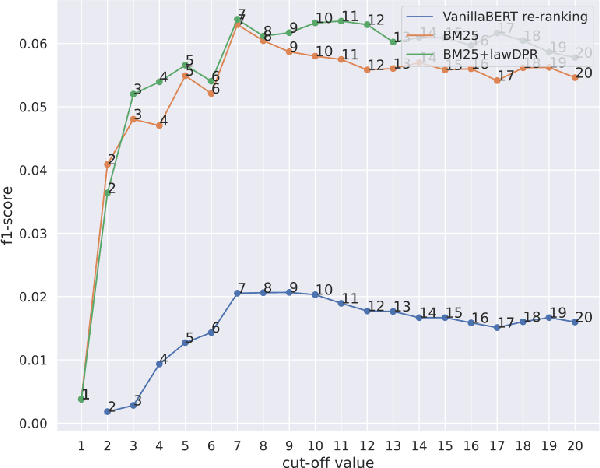
In this paper, we present our approaches for the case law retrieval and the legal case entailment task in the Competition on Legal Information Extraction/Entailment (COLIEE) 2021. As first stage retrieval methods combined with neural re-ranking methods using contextualized language models like BERT achieved great performance improvements for information retrieval in the web and news domain, we evaluate these methods for the legal domain. A distinct characteristic of legal case retrieval is that the query case and case description in the corpus tend to be long documents and therefore exceed the input length of BERT. We address this challenge by combining lexical and dense retrieval methods on the paragraph-level of the cases for the first stage retrieval. Here we demonstrate that the retrieval on the paragraph-level outperforms the retrieval on the document-level. Furthermore the experiments suggest that dense retrieval methods outperform lexical retrieval. For re-ranking we address the problem of long documents by summarizing the cases and fine-tuning a BERT-based re-ranker with the summaries. Overall, our best results were obtained with a combination of BM25 and dense passage retrieval using domain-specific embeddings.