 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BiRdQA: A Bilingual Dataset for Question Answering on Tricky Riddles
Sep 23, 2021
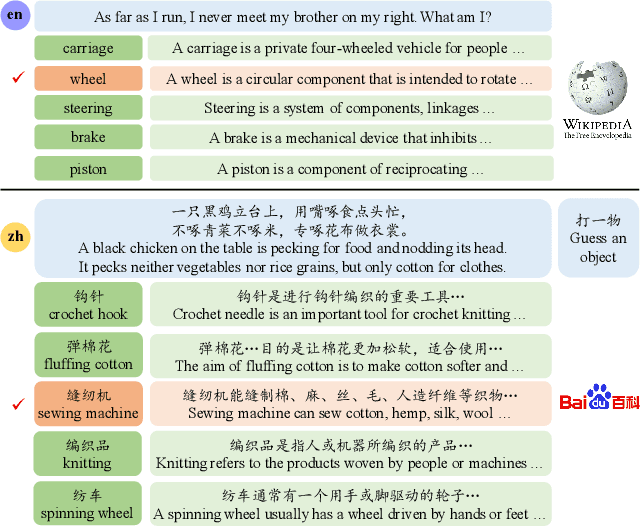
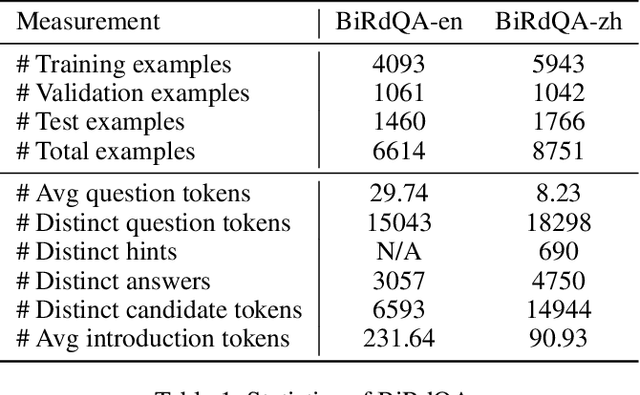
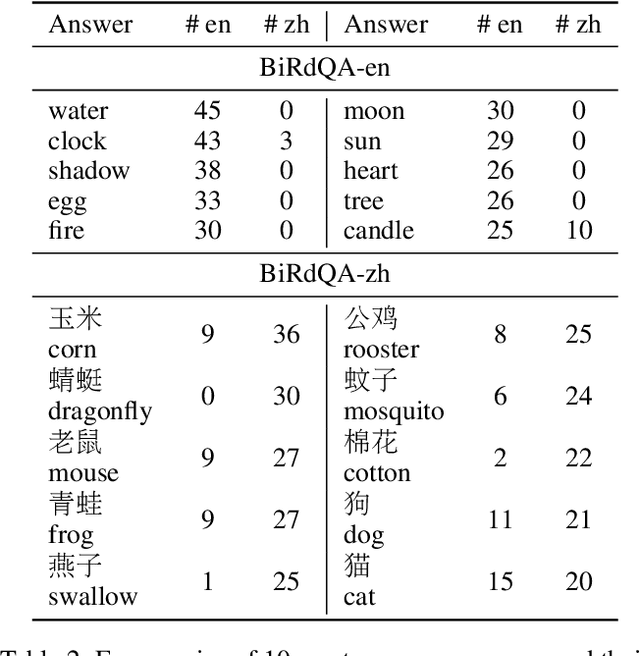
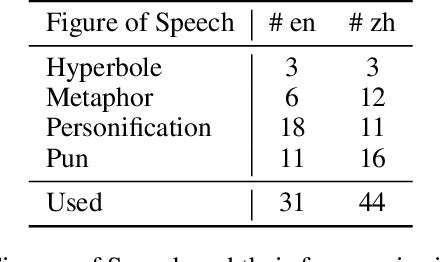
A riddle is a question or statement with double or veiled meanings, followed by an unexpected answer. Solving riddle is a challenging task for both machine and human, testing the capability of understanding figurative, creative natural language and reasoning with commonsense knowledge. We introduce BiRdQA, a bilingual multiple-choice question answering dataset with 6614 English riddles and 8751 Chinese riddles. For each riddle-answer pair, we provide four distractors with additional information from Wikipedia. The distractors are automatically generated at scale with minimal bias. Existing monolingual and multilingual QA models fail to perform well on our dataset, indicating that there is a long way to go before machine can beat human on solving tricky riddles. The dataset has been released to the community.
Multitask Identity-Aware Image Steganography via Minimax Optimization
Jul 13, 2021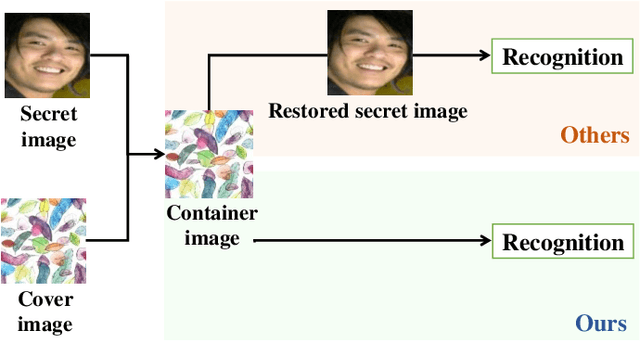

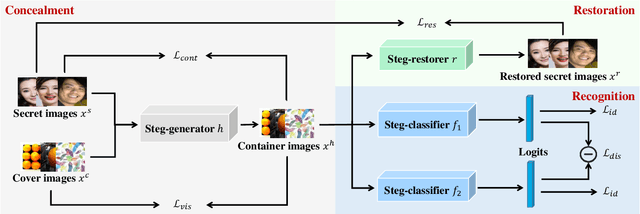
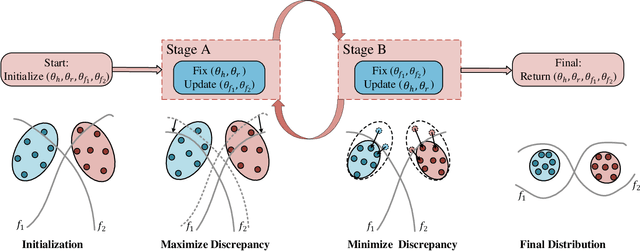
High-capacity image steganography, aimed at concealing a secret image in a cover image, is a technique to preserve sensitive data, e.g., faces and fingerprints. Previous methods focus on the security during transmission and subsequently run a risk of privacy leakage after the restoration of secret images at the receiving end. To address this issue, we propose a framework, called Multitask Identity-Aware Image Steganography (MIAIS), to achieve direct recognition on container images without restoring secret images. The key issue of the direct recognition is to preserve identity information of secret images into container images and make container images look similar to cover images at the same time. Thus, we introduce a simple content loss to preserve the identity information, and design a minimax optimization to deal with the contradictory aspects. We demonstrate that the robustness results can be transferred across different cover datasets. In order to be flexible for the secret image restoration in some cases, we incorporate an optional restoration network into our method, providing a multitask framework. The experiments under the multitask scenario show the effectiveness of our framework compared with other visual information hiding methods and state-of-the-art high-capacity image steganography methods.
Don't Search for a Search Method -- Simple Heuristics Suffice for Adversarial Text Attacks
Oct 04, 2021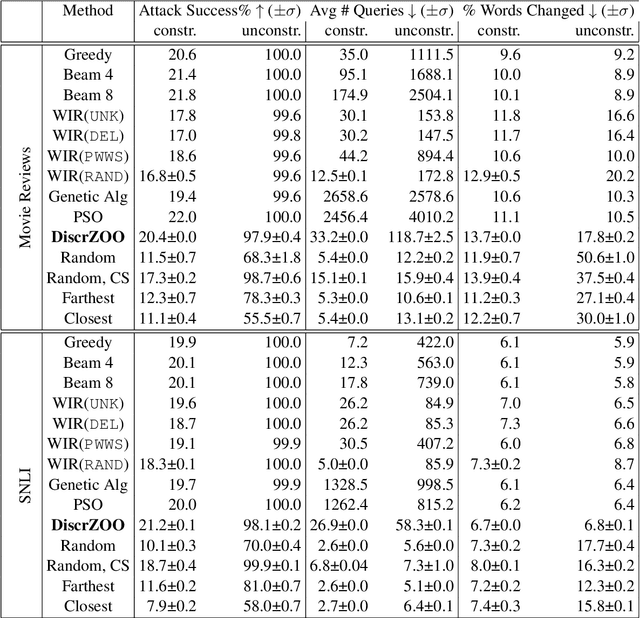
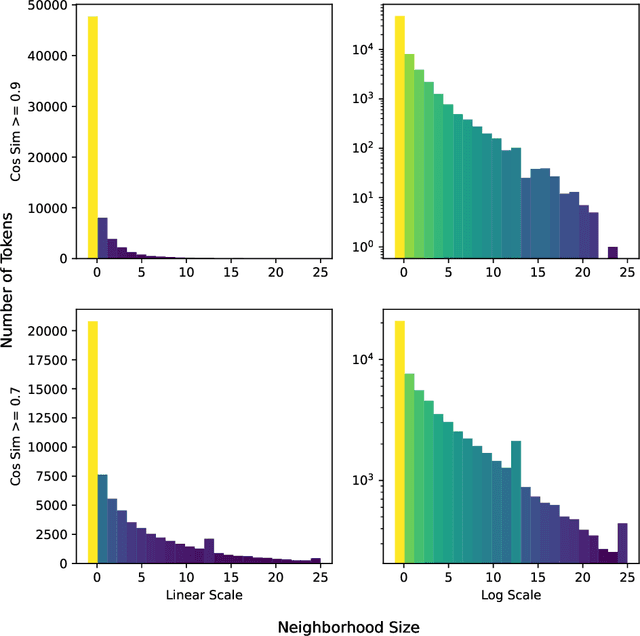
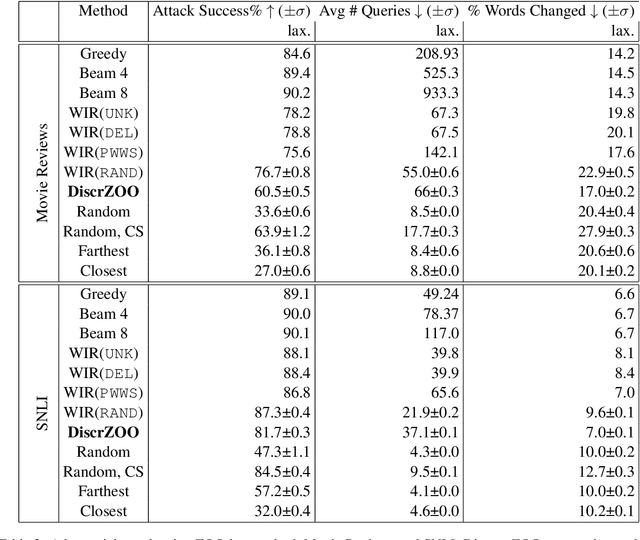
Recently more attention has been given to adversarial attacks on neural networks for natural language processing (NLP). A central research topic has been the investigation of search algorithms and search constraints, accompanied by benchmark algorithms and tasks. We implement an algorithm inspired by zeroth order optimization-based attacks and compare with the benchmark results in the TextAttack framework. Surprisingly, we find that optimization-based methods do not yield any improvement in a constrained setup and slightly benefit from approximate gradient information only in unconstrained setups where search spaces are larger. In contrast, simple heuristics exploiting nearest neighbors without querying the target function yield substantial success rates in constrained setups, and nearly full success rate in unconstrained setups, at an order of magnitude fewer queries. We conclude from these results that current TextAttack benchmark tasks are too easy and constraints are too strict, preventing meaningful research on black-box adversarial text attacks.
Streaming Transformer Transducer Based Speech Recognition Using Non-Causal Convolution
Oct 07, 2021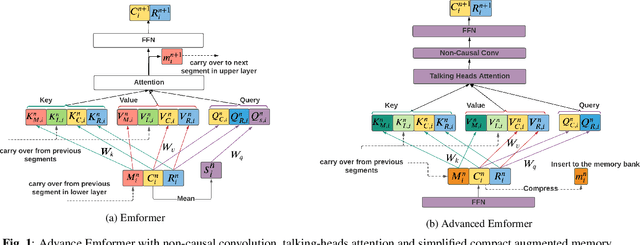
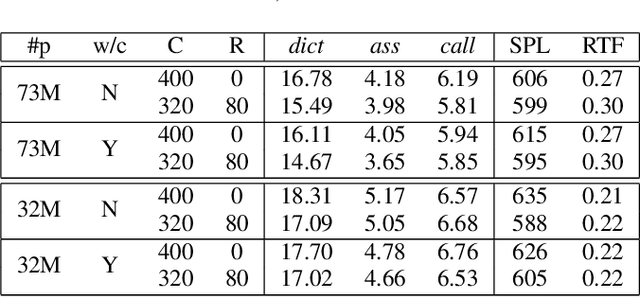
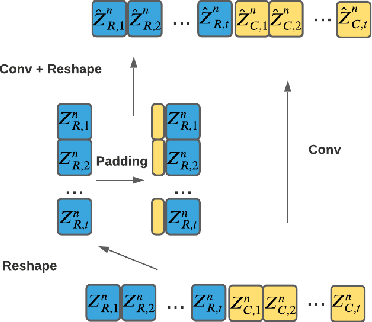
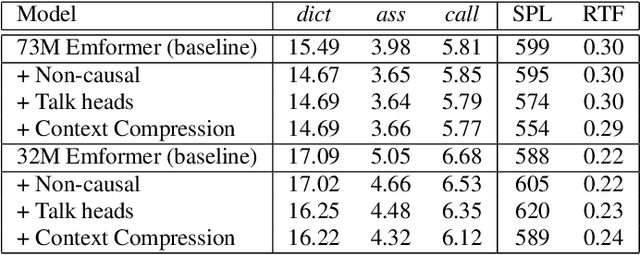
This paper improves the streaming transformer transducer for speech recognition by using non-causal convolution. Many works apply the causal convolution to improve streaming transformer ignoring the lookahead context. We propose to use non-causal convolution to process the center block and lookahead context separately. This method leverages the lookahead context in convolution and maintains similar training and decoding efficiency. Given the similar latency, using the non-causal convolution with lookahead context gives better accuracy than causal convolution, especially for open-domain dictation scenarios. Besides, this paper applies talking-head attention and a novel history context compression scheme to further improve the performance. The talking-head attention improves the multi-head self-attention by transferring information among different heads. The history context compression method introduces more extended history context compactly. On our in-house data, the proposed methods improve a small Emformer baseline with lookahead context by relative WERR 5.1\%, 14.5\%, 8.4\% on open-domain dictation, assistant general scenarios, and assistant calling scenarios, respectively.
Semantics-Guided Contrastive Network for Zero-Shot Object detection
Sep 04, 2021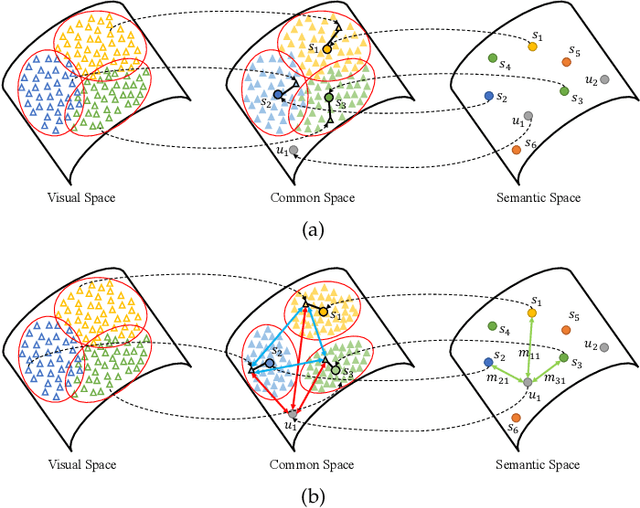
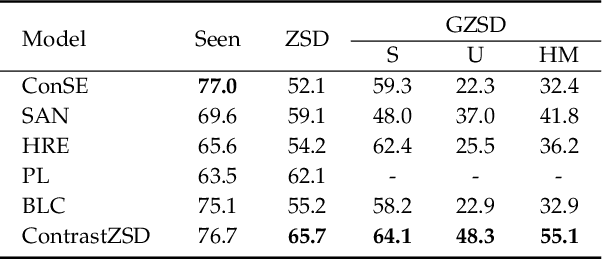
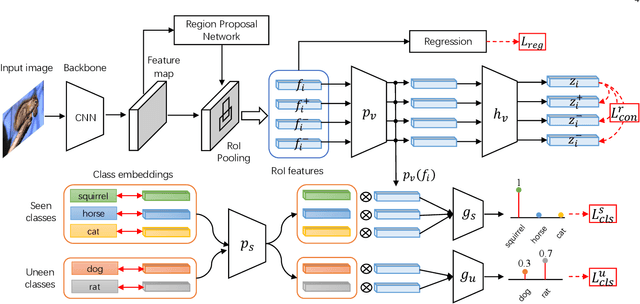
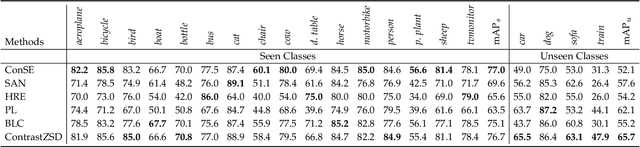
Zero-shot object detection (ZSD), the task that extends conventional detection models to detecting objects from unseen categories, has emerged as a new challenge in computer vision. Most existing approaches tackle the ZSD task with a strict mapping-transfer strategy, which may lead to suboptimal ZSD results: 1) the learning process of those models ignores the available unseen class information, and thus can be easily biased towards the seen categories; 2) the original visual feature space is not well-structured and lack of discriminative information. To address these issues, we develop a novel Semantics-Guided Contrastive Network for ZSD, named ContrastZSD, a detection framework that first brings contrastive learning mechanism into the realm of zero-shot detection. Particularly, ContrastZSD incorporates two semantics-guided contrastive learning subnets that contrast between region-category and region-region pairs respectively. The pairwise contrastive tasks take advantage of additional supervision signals derived from both ground truth label and pre-defined class similarity distribution. Under the guidance of those explicit semantic supervision, the model can learn more knowledge about unseen categories to avoid the bias problem to seen concepts, while optimizing the data structure of visual features to be more discriminative for better visual-semantic alignment. Extensive experiments are conducted on two popular benchmarks for ZSD, i.e., PASCAL VOC and MS COCO. Results show that our method outperforms the previous state-of-the-art on both ZSD and generalized ZSD tasks.
SpeechT5: Unified-Modal Encoder-Decoder Pre-training for Spoken Language Processing
Oct 14, 2021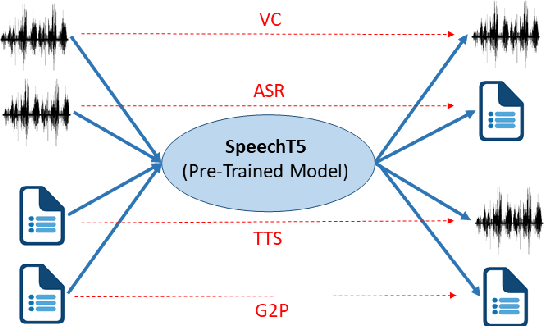
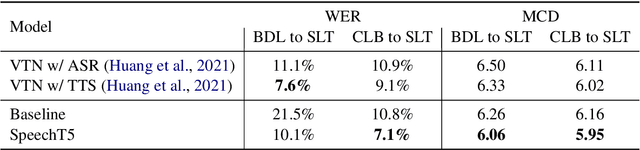
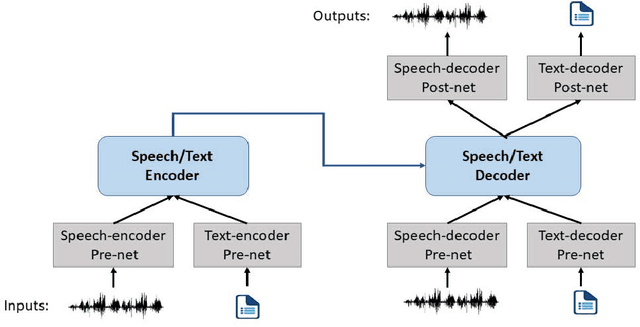
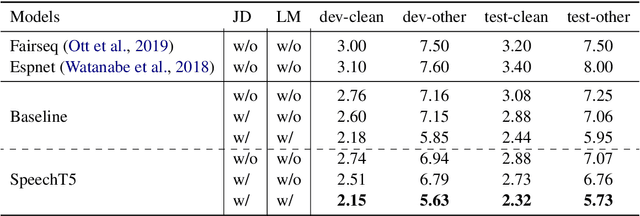
Motivated by the success of T5 (Text-To-Text Transfer Transformer) in pre-training natural language processing models, we propose a unified-modal SpeechT5 framework that explores the encoder-decoder pre-training for self-supervised speech/text representation learning. The SpeechT5 framework consists of a shared encoder-decoder network and six modal-specific (speech/text) pre/post-nets. After preprocessing the speech/text input through the pre-nets, the shared encoder-decoder network models the sequence to sequence transformation, and then the post-nets generate the output in the speech/text modality based on the decoder output. Particularly, SpeechT5 can pre-train on a large scale of unlabeled speech and text data to improve the capability of the speech and textual modeling. To align the textual and speech information into a unified semantic space, we propose a cross-modal vector quantization method with random mixing-up to bridge speech and text. Extensive evaluations on a wide variety of spoken language processing tasks, including voice conversion, automatic speech recognition, text to speech, and speaker identification, show the superiority of the proposed SpeechT5 framework.
ACN: Adversarial Co-training Network for Brain Tumor Segmentation with Missing Modalities
Jun 29, 2021
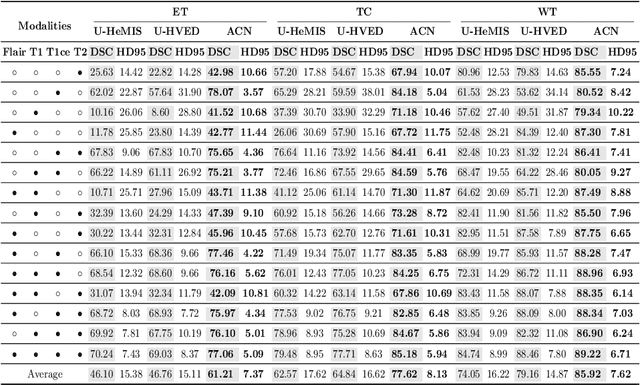
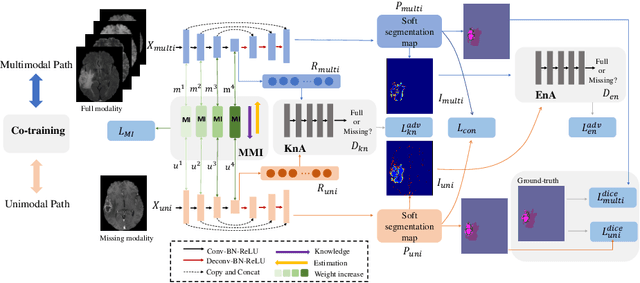
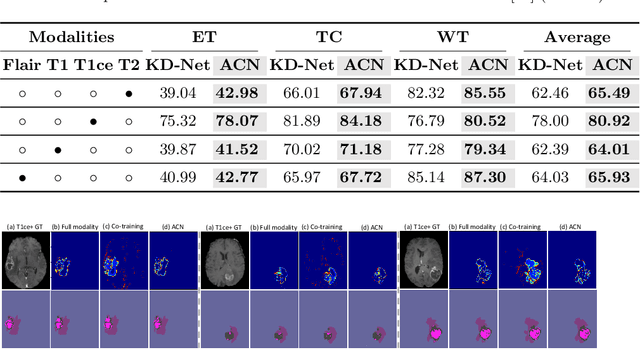
Accurate segmentation of brain tumors from magnetic resonance imaging (MRI) is clinically relevant in diagnoses, prognoses and surgery treatment, which requires multiple modalities to provide complementary morphological and physiopathologic information. However, missing modality commonly occurs due to image corruption, artifacts, different acquisition protocols or allergies to certain contrast agents in clinical practice. Though existing efforts demonstrate the possibility of a unified model for all missing situations, most of them perform poorly when more than one modality is missing. In this paper, we propose a novel Adversarial Co-training Network (ACN) to solve this issue, in which a series of independent yet related models are trained dedicated to each missing situation with significantly better results. Specifically, ACN adopts a novel co-training network, which enables a coupled learning process for both full modality and missing modality to supplement each other's domain and feature representations, and more importantly, to recover the `missing' information of absent modalities. Then, two unsupervised modules, i.e., entropy and knowledge adversarial learning modules are proposed to minimize the domain gap while enhancing prediction reliability and encouraging the alignment of latent representations, respectively. We also adapt modality-mutual information knowledge transfer learning to ACN to retain the rich mutual information among modalities. Extensive experiments on BraTS2018 dataset show that our proposed method significantly outperforms all state-of-the-art methods under any missing situation.
DeepCVA: Automated Commit-level Vulnerability Assessment with Deep Multi-task Learning
Aug 18, 2021
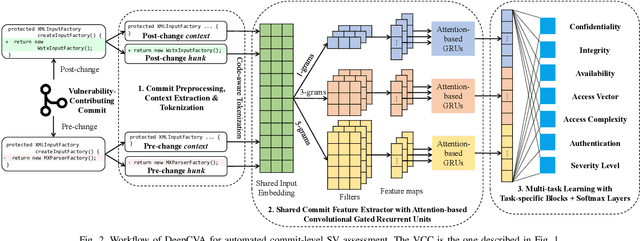

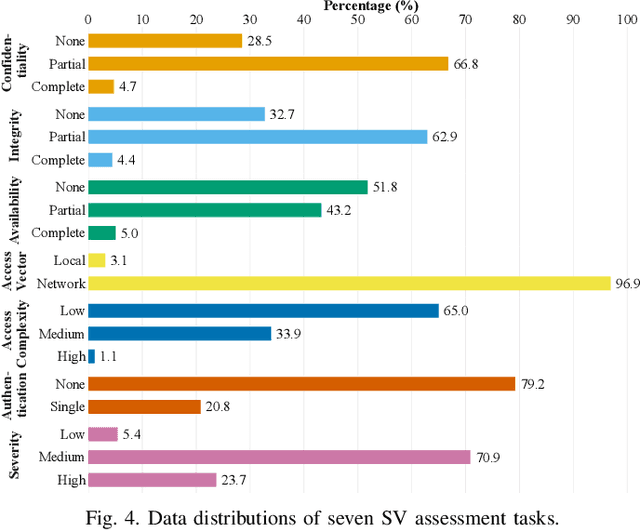
It is increasingly suggested to identify Software Vulnerabilities (SVs) in code commits to give early warnings about potential security risks. However, there is a lack of effort to assess vulnerability-contributing commits right after they are detected to provide timely information about the exploitability, impact and severity of SVs. Such information is important to plan and prioritize the mitigation for the identified SVs. We propose a novel Deep multi-task learning model, DeepCVA, to automate seven Commit-level Vulnerability Assessment tasks simultaneously based on Common Vulnerability Scoring System (CVSS) metrics. We conduct large-scale experiments on 1,229 vulnerability-contributing commits containing 542 different SVs in 246 real-world software projects to evaluate the effectiveness and efficiency of our model. We show that DeepCVA is the best-performing model with 38% to 59.8% higher Matthews Correlation Coefficient than many supervised and unsupervised baseline models. DeepCVA also requires 6.3 times less training and validation time than seven cumulative assessment models, leading to significantly less model maintenance cost as well. Overall, DeepCVA presents the first effective and efficient solution to automatically assess SVs early in software systems.
Deep Hybrid Self-Prior for Full 3D Mesh Generation
Aug 18, 2021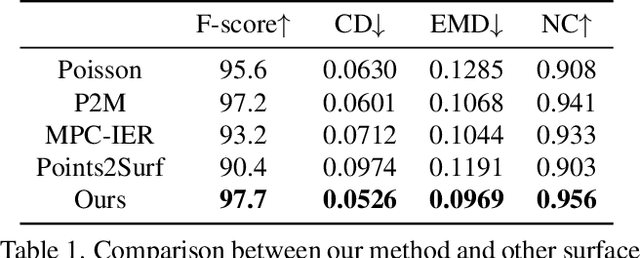
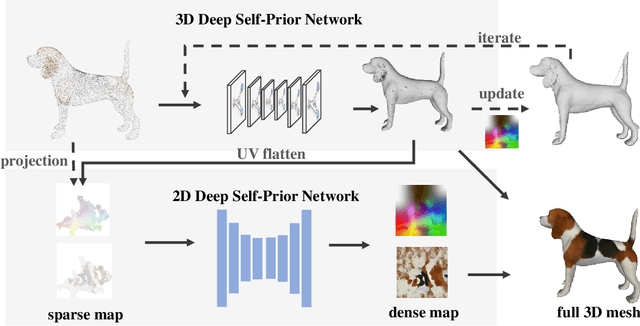
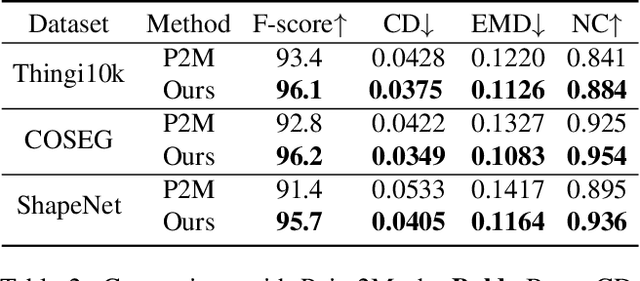
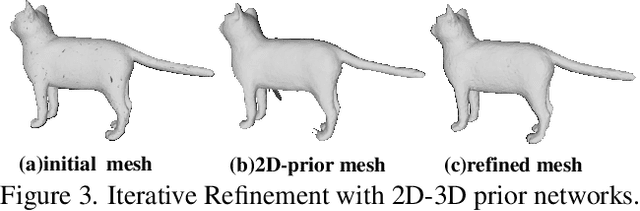
We present a deep learning pipeline that leverages network self-prior to recover a full 3D model consisting of both a triangular mesh and a texture map from the colored 3D point cloud. Different from previous methods either exploiting 2D self-prior for image editing or 3D self-prior for pure surface reconstruction, we propose to exploit a novel hybrid 2D-3D self-prior in deep neural networks to significantly improve the geometry quality and produce a high-resolution texture map, which is typically missing from the output of commodity-level 3D scanners. In particular, we first generate an initial mesh using a 3D convolutional neural network with 3D self-prior, and then encode both 3D information and color information in the 2D UV atlas, which is further refined by 2D convolutional neural networks with the self-prior. In this way, both 2D and 3D self-priors are utilized for the mesh and texture recovery. Experiments show that, without the need of any additional training data, our method recovers the 3D textured mesh model of high quality from sparse input, and outperforms the state-of-the-art methods in terms of both the geometry and texture quality.
Hindsight Value Function for Variance Reduction in Stochastic Dynamic Environment
Aug 05, 2021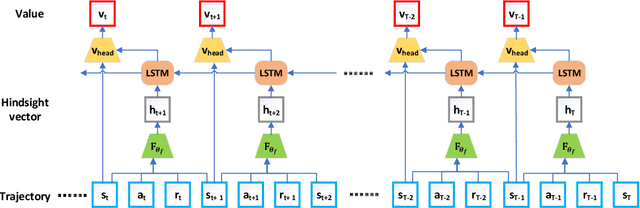
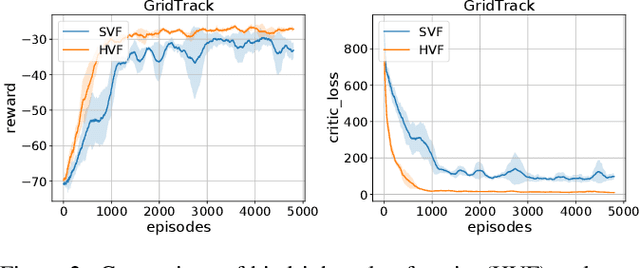
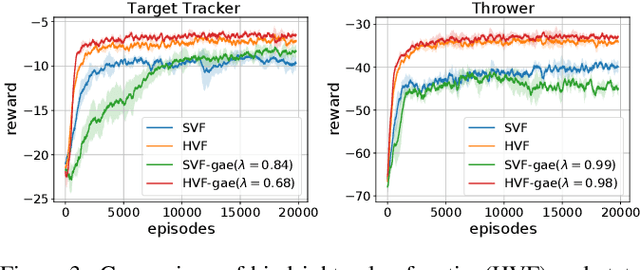
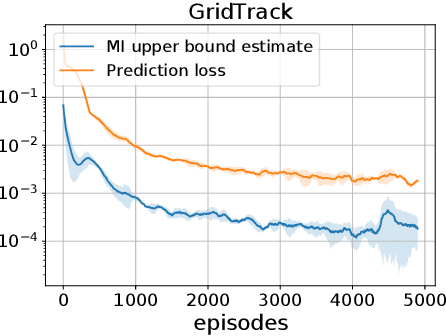
Policy gradient methods are appealing in deep reinforcement learning but suffer from high variance of gradient estimate. To reduce the variance, the state value function is applied commonly. However, the effect of the state value function becomes limited in stochastic dynamic environments, where the unexpected state dynamics and rewards will increase the variance. In this paper, we propose to replace the state value function with a novel hindsight value function, which leverages the information from the future to reduce the variance of the gradient estimate for stochastic dynamic environments. Particularly, to obtain an ideally unbiased gradient estimate, we propose an information-theoretic approach, which optimizes the embeddings of the future to be independent of previous actions. In our experiments, we apply the proposed hindsight value function in stochastic dynamic environments, including discrete-action environments and continuous-action environments. Compared with the standard state value function, the proposed hindsight value function consistently reduces the variance, stabilizes the training, and improves the eventual policy.