 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Residual Overfit Method of Exploration
Oct 06, 2021
Exploration is a crucial aspect of bandit and reinforcement learning algorithms. The uncertainty quantification necessary for exploration often comes from either closed-form expressions based on simple models or resampling and posterior approximations that are computationally intensive. We propose instead an approximate exploration methodology based on fitting only two point estimates, one tuned and one overfit. The approach, which we term the residual overfit method of exploration (ROME), drives exploration towards actions where the overfit model exhibits the most overfitting compared to the tuned model. The intuition is that overfitting occurs the most at actions and contexts with insufficient data to form accurate predictions of the reward. We justify this intuition formally from both a frequentist and a Bayesian information theoretic perspective. The result is a method that generalizes to a wide variety of models and avoids the computational overhead of resampling or posterior approximations. We compare ROME against a set of established contextual bandit methods on three datasets and find it to be one of the best performing.
Extracting Feelings of People Regarding COVID-19 by Social Network Mining
Oct 12, 2021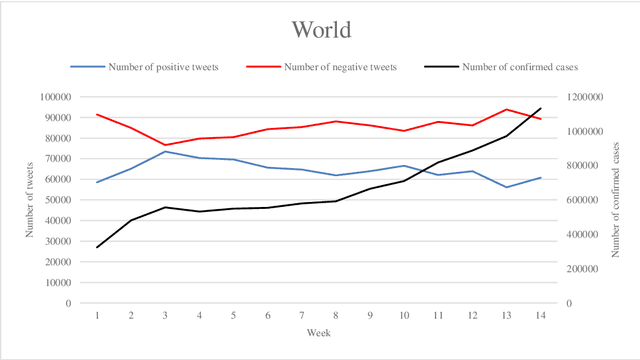
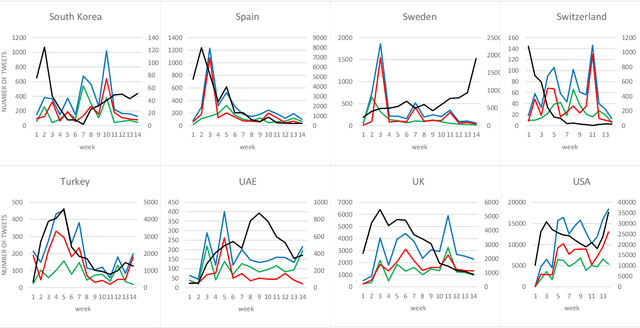
In 2020, COVID-19 became the chief concern of the world and is still reflected widely in all social networks. Each day, users post millions of tweets and comments on this subject, which contain significant implicit information about the public opinion. In this regard, a dataset of COVID-related tweets in English language is collected, which consists of more than two million tweets from March 23 to June 23 of 2020 to extract the feelings of the people in various countries in the early stages of this outbreak. To this end, first, we use a lexicon-based approach in conjunction with the GeoNames geographic database to label the tweets with their locations. Next, a method based on the recently introduced and widely cited RoBERTa model is proposed to analyze their sentimental content. After that, the trend graphs of the frequency of tweets as well as sentiments are produced for the world and the nations that were more engaged with COVID-19. Graph analysis shows that the frequency graphs of the tweets for the majority of nations are significantly correlated with the official statistics of the daily afflicted in them. Moreover, several implicit knowledge is extracted and discussed.
Uncertainty in the Variational Information Bottleneck
Jul 02, 2018
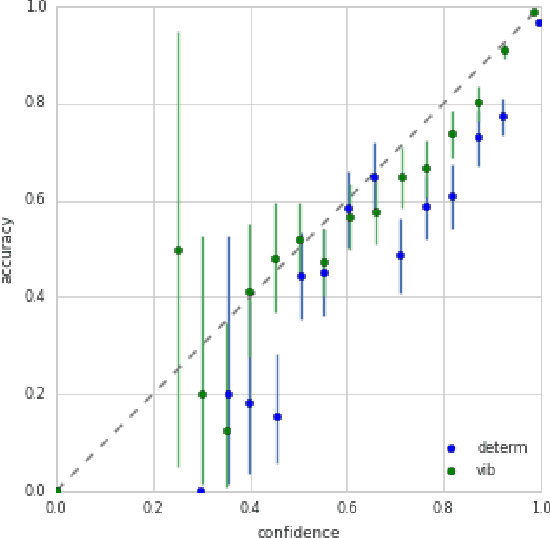
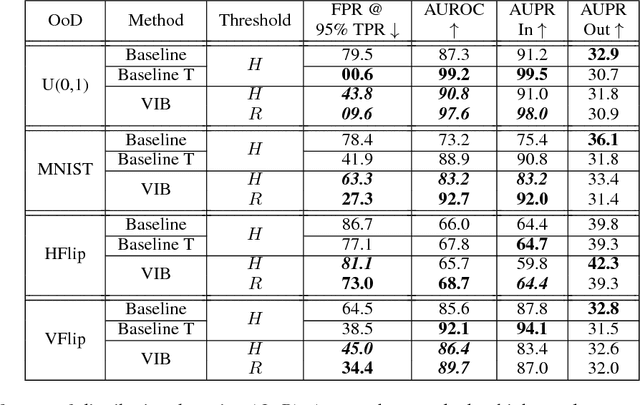
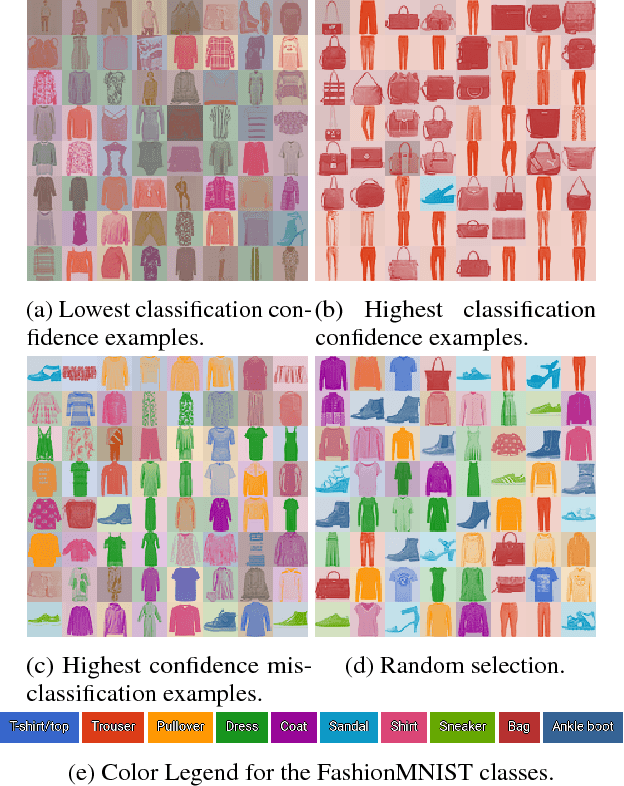
We present a simple case study, demonstrating that Variational Information Bottleneck (VIB) can improve a network's classification calibration as well as its ability to detect out-of-distribution data. Without explicitly being designed to do so, VIB gives two natural metrics for handling and quantifying uncertainty.
Hepatic vessel segmentation based on 3Dswin-transformer with inductive biased multi-head self-attention
Nov 05, 2021
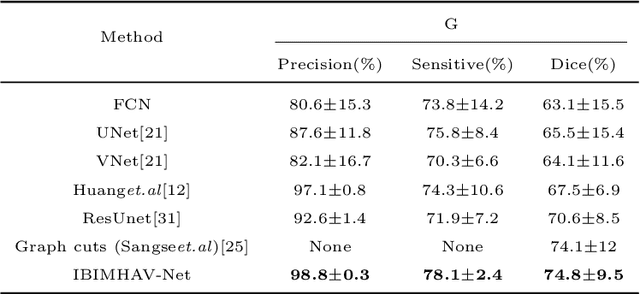
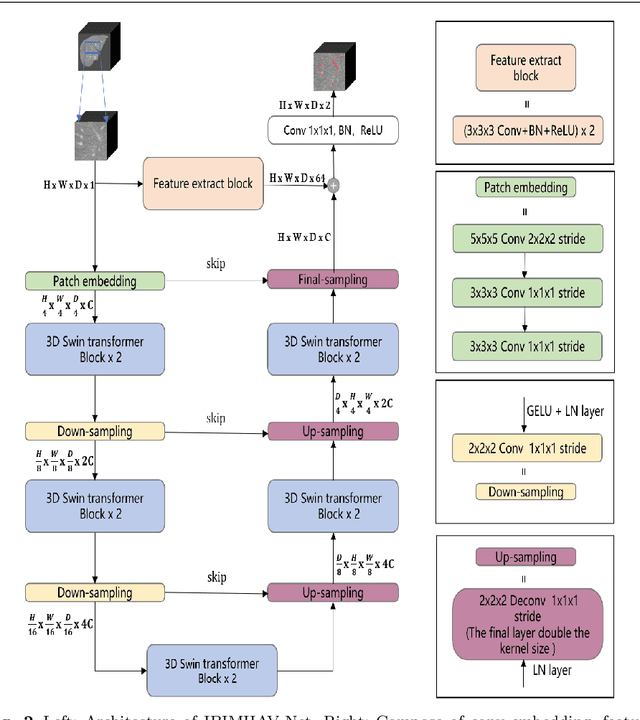
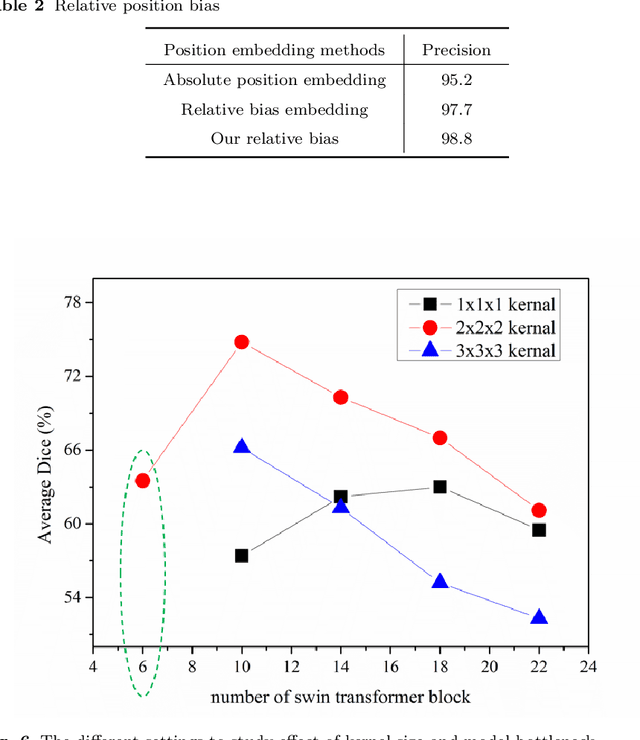
Purpose: Segmentation of liver vessels from CT images is indispensable prior to surgical planning and aroused broad range of interests in the medical image analysis community. Due to the complex structure and low contrast background, automatic liver vessel segmentation remains particularly challenging. Most of the related researches adopt FCN, U-net, and V-net variants as a backbone. However, these methods mainly focus on capturing multi-scale local features which may produce misclassified voxels due to the convolutional operator's limited locality reception field. Methods: We propose a robust end-to-end vessel segmentation network called Inductive BIased Multi-Head Attention Vessel Net(IBIMHAV-Net) by expanding swin transformer to 3D and employing an effective combination of convolution and self-attention. In practice, we introduce the voxel-wise embedding rather than patch-wise embedding to locate precise liver vessel voxels, and adopt multi-scale convolutional operators to gain local spatial information. On the other hand, we propose the inductive biased multi-head self-attention which learns inductive biased relative positional embedding from initialized absolute position embedding. Based on this, we can gain a more reliable query and key matrix. To validate the generalization of our model, we test on samples which have different structural complexity. Results: We conducted experiments on the 3DIRCADb datasets. The average dice and sensitivity of the four tested cases were 74.8% and 77.5%, which exceed results of existing deep learning methods and improved graph cuts method. Conclusion: The proposed model IBIMHAV-Net provides an automatic, accurate 3D liver vessel segmentation with an interleaved architecture that better utilizes both global and local spatial features in CT volumes. It can be further extended for other clinical data.
FINN.no Slates Dataset: A new Sequential Dataset Logging Interactions, allViewed Items and Click Responses/No-Click for Recommender Systems Research
Nov 05, 2021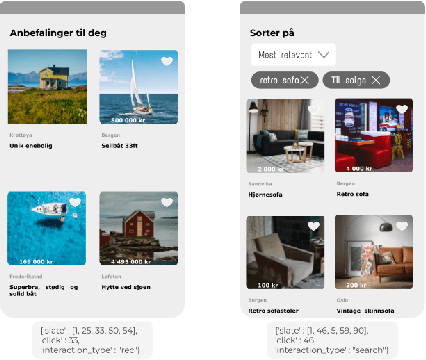

We present a novel recommender systems dataset that records the sequential interactions between users and an online marketplace. The users are sequentially presented with both recommendations and search results in the form of ranked lists of items, called slates, from the marketplace. The dataset includes the presented slates at each round, whether the user clicked on any of these items and which item the user clicked on. Although the usage of exposure data in recommender systems is growing, to our knowledge there is no open large-scale recommender systems dataset that includes the slates of items presented to the users at each interaction. As a result, most articles on recommender systems do not utilize this exposure information. Instead, the proposed models only depend on the user's click responses, and assume that the user is exposed to all the items in the item universe at each step, often called uniform candidate sampling. This is an incomplete assumption, as it takes into account items the user might not have been exposed to. This way items might be incorrectly considered as not of interest to the user. Taking into account the actually shown slates allows the models to use a more natural likelihood, based on the click probability given the exposure set of items, as is prevalent in the bandit and reinforcement learning literature. \cite{Eide2021DynamicSampling} shows that likelihoods based on uniform candidate sampling (and similar assumptions) are implicitly assuming that the platform only shows the most relevant items to the user. This causes the recommender system to implicitly reinforce feedback loops and to be biased towards previously exposed items to the user.
A Signal Detection Scheme Based on Deep Learning in OFDM Systems
Jul 24, 2021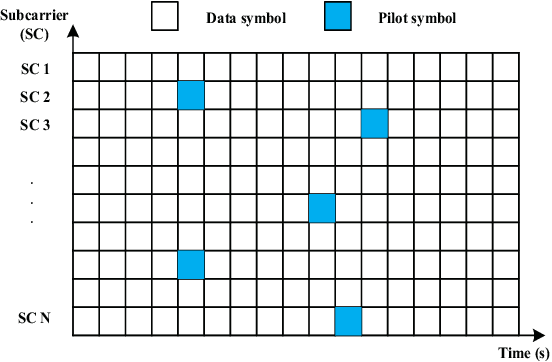
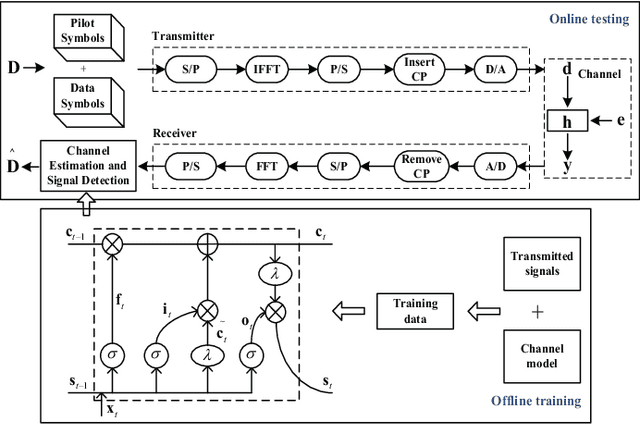
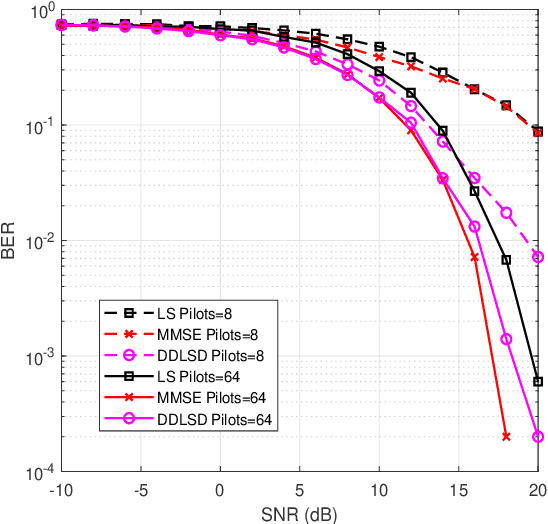
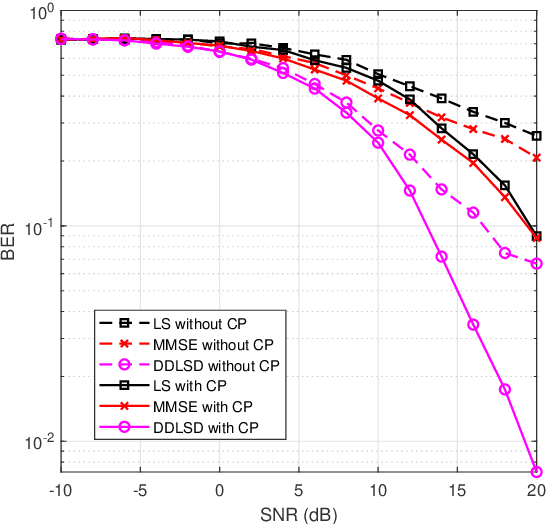
Channel estimation and signal detection are essential steps to ensure the quality of end-to-end communication in orthogonal frequency-division multiplexing (OFDM) systems. In this paper, we develop a DDLSD approach, i.e., Data-driven Deep Learning for Signal Detection in OFDM systems. First, the OFDM system model is established. Then, the long short-term memory (LSTM) is introduced into the OFDM system model. Wireless channel data is generated through simulation, the preprocessed time series feature information is input into the LSTM to complete the offline training. Finally, the trained model is used for online recovery of transmitted signal. The difference between this scheme and existing OFDM receiver is that explicit estimated channel state information (CSI) is transformed into invisible estimated CSI, and the transmit symbol is directly restored. Simulation results show that the DDLSD scheme outperforms the existing traditional methods in terms of improving channel estimation and signal detection performance.
Comparative Study of Long Document Classification
Nov 01, 2021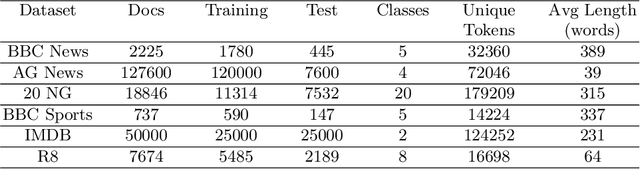
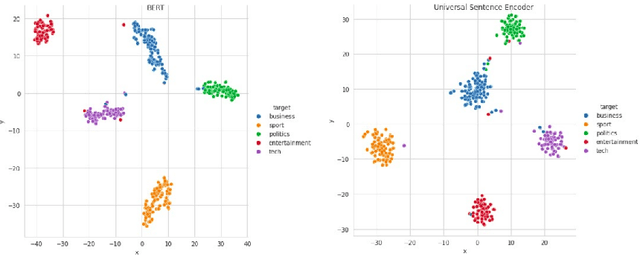
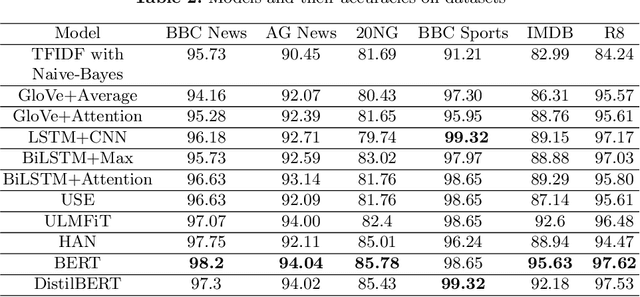
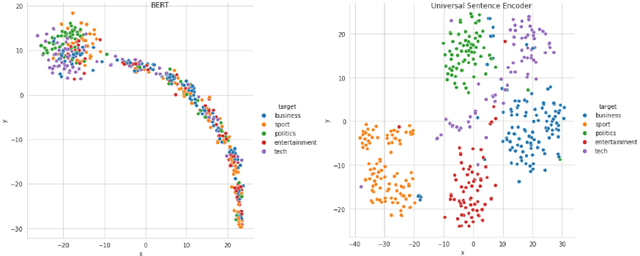
The amount of information stored in the form of documents on the internet has been increasing rapidly. Thus it has become a necessity to organize and maintain these documents in an optimum manner. Text classification algorithms study the complex relationships between words in a text and try to interpret the semantics of the document. These algorithms have evolved significantly in the past few years. There has been a lot of progress from simple machine learning algorithms to transformer-based architectures. However, existing literature has analyzed different approaches on different data sets thus making it difficult to compare the performance of machine learning algorithms. In this work, we revisit long document classification using standard machine learning approaches. We benchmark approaches ranging from simple Naive Bayes to complex BERT on six standard text classification datasets. We present an exhaustive comparison of different algorithms on a range of long document datasets. We re-iterate that long document classification is a simpler task and even basic algorithms perform competitively with BERT-based approaches on most of the datasets. The BERT-based models perform consistently well on all the datasets and can be blindly used for the document classification task when the computations cost is not a concern. In the shallow model's category, we suggest the usage of raw BiLSTM + Max architecture which performs decently across all the datasets. Even simpler Glove + Attention bag of words model can be utilized for simpler use cases. The importance of using sophisticated models is clearly visible in the IMDB sentiment dataset which is a comparatively harder task.
Uncertainty-Aware Semi-Supervised Few Shot Segmentation
Oct 18, 2021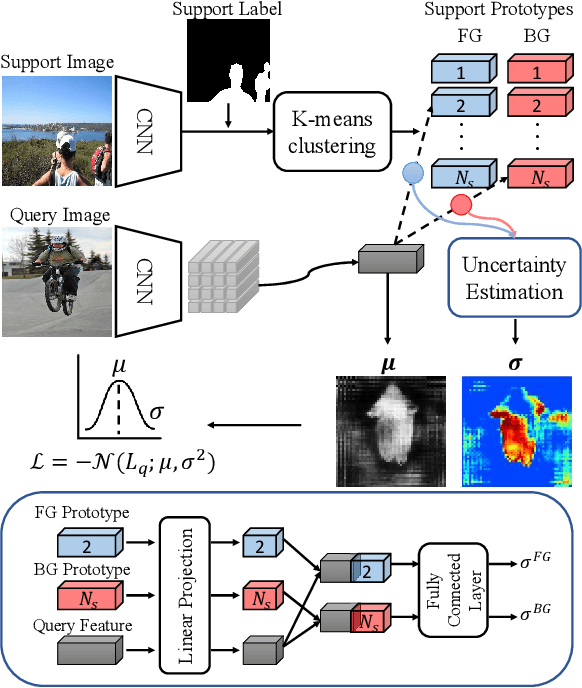
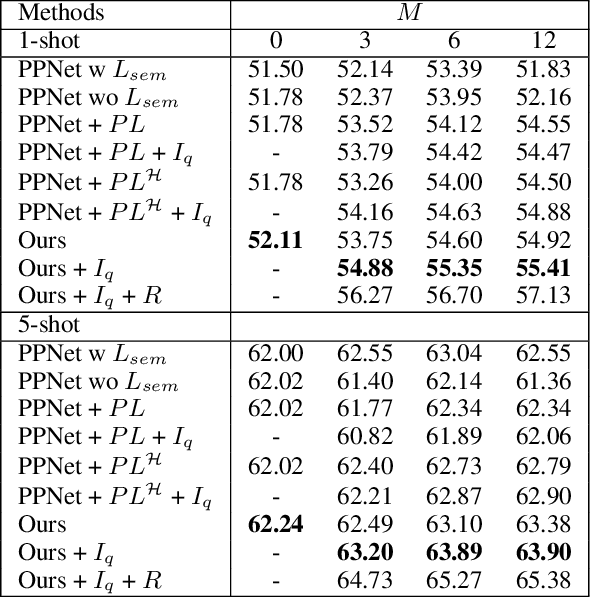
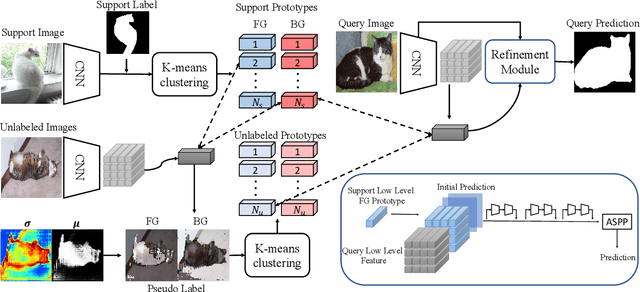
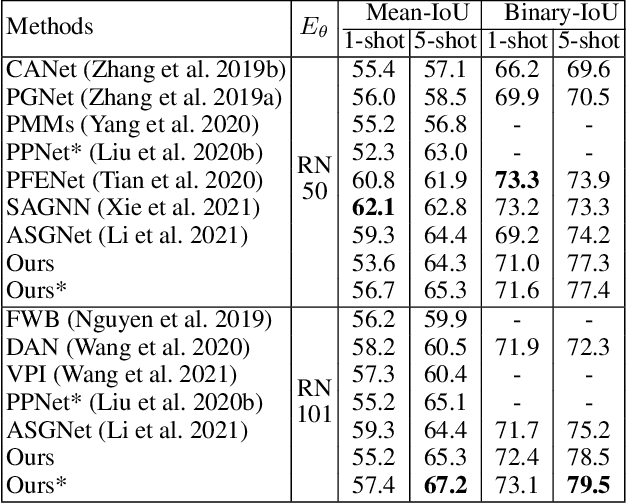
Few shot segmentation (FSS) aims to learn pixel-level classification of a target object in a query image using only a few annotated support samples. This is challenging as it requires modeling appearance variations of target objects and the diverse visual cues between query and support images with limited information. To address this problem, we propose a semi-supervised FSS strategy that leverages additional prototypes from unlabeled images with uncertainty guided pseudo label refinement. To obtain reliable prototypes from unlabeled images, we meta-train a neural network to jointly predict segmentation and estimate the uncertainty of predictions. We employ the uncertainty estimates to exclude predictions with high degrees of uncertainty for pseudo label construction to obtain additional prototypes based on the refined pseudo labels. During inference, query segmentation is predicted using prototypes from both support and unlabeled images including low-level features of the query images. Our approach is end-to-end and can easily supplement existing approaches without the requirement of additional training to employ unlabeled samples. Extensive experiments on PASCAL-$5^i$ and COCO-$20^i$ demonstrate that our model can effectively remove unreliable predictions to refine pseudo labels and significantly improve upon state-of-the-art performances.
Understanding the Logit Distributions of Adversarially-Trained Deep Neural Networks
Aug 26, 2021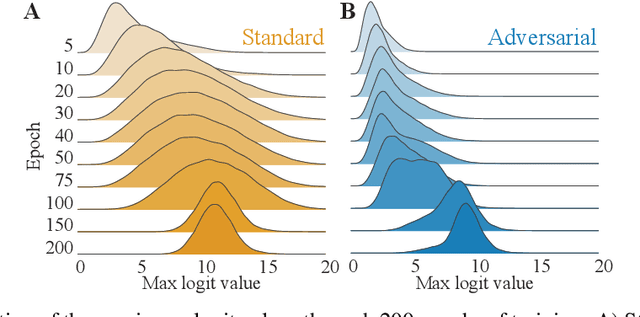

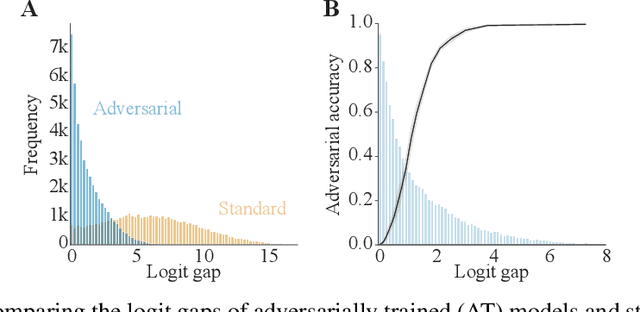

Adversarial defenses train deep neural networks to be invariant to the input perturbations from adversarial attacks. Almost all defense strategies achieve this invariance through adversarial training i.e. training on inputs with adversarial perturbations. Although adversarial training is successful at mitigating adversarial attacks, the behavioral differences between adversarially-trained (AT) models and standard models are still poorly understood. Motivated by a recent study on learning robustness without input perturbations by distilling an AT model, we explore what is learned during adversarial training by analyzing the distribution of logits in AT models. We identify three logit characteristics essential to learning adversarial robustness. First, we provide a theoretical justification for the finding that adversarial training shrinks two important characteristics of the logit distribution: the max logit values and the "logit gaps" (difference between the logit max and next largest values) are on average lower for AT models. Second, we show that AT and standard models differ significantly on which samples are high or low confidence, then illustrate clear qualitative differences by visualizing samples with the largest confidence difference. Finally, we find learning information about incorrect classes to be essential to learning robustness by manipulating the non-max logit information during distillation and measuring the impact on the student's robustness. Our results indicate that learning some adversarial robustness without input perturbations requires a model to learn specific sample-wise confidences and incorrect class orderings that follow complex distributions.
Grounding-aware RRT* for Path Planning and Safe Navigation of Marine Crafts in Confined Waters
Sep 14, 2021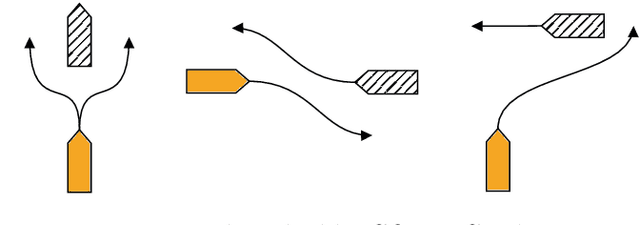

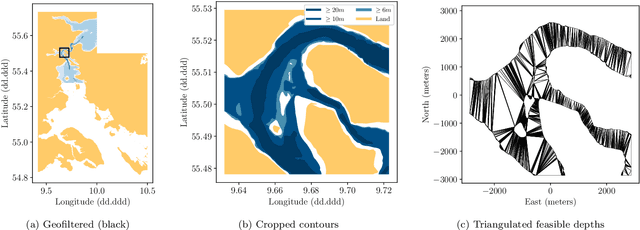
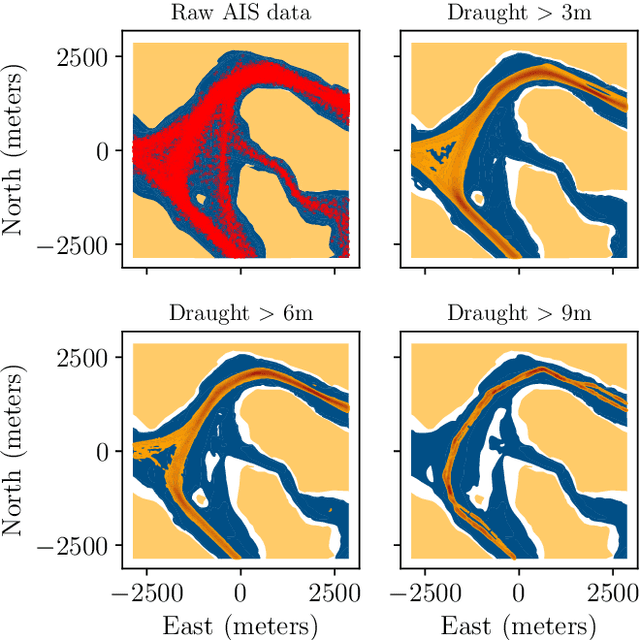
The paper presents a path planning algorithm based on RRT* that addresses the risk of grounding during evasive manoeuvres to avoid collision. The planner achieves this objective by integrating a collective navigation experience with the systematic use of water depth information from the electronic navigational chart. Multivariate kernel density estimation is applied to historical AIS data to generate a probabilistic model describing seafarer's best practices while sailing in confined waters. This knowledge is then encoded into the RRT* cost function to penalize path deviations that would lead own ship to sail in shallow waters. Depth contours satisfying the own ship draught define the actual navigable area, and triangulation of this non-convex region is adopted to enable uniform sampling. This ensures the optimal path deviation.