 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Prunability of Attention Heads in Multilingual BERT
Sep 26, 2021
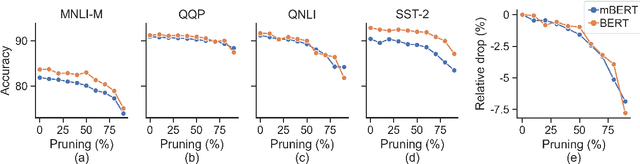
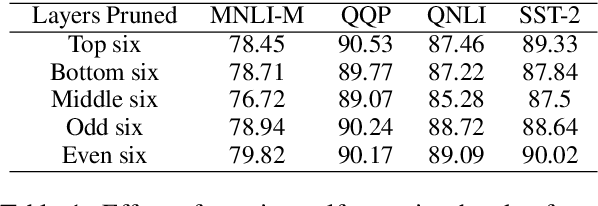
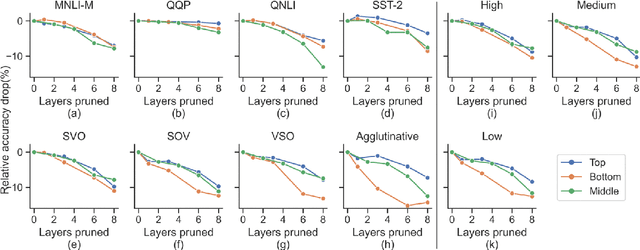
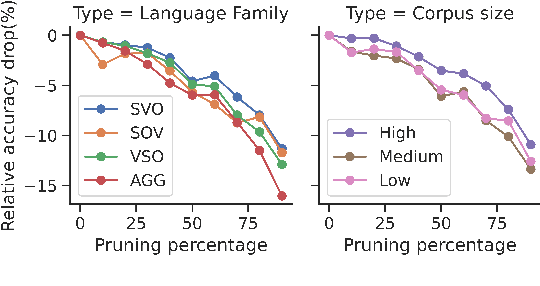
Large multilingual models, such as mBERT, have shown promise in crosslingual transfer. In this work, we employ pruning to quantify the robustness and interpret layer-wise importance of mBERT. On four GLUE tasks, the relative drops in accuracy due to pruning have almost identical results on mBERT and BERT suggesting that the reduced attention capacity of the multilingual models does not affect robustness to pruning. For the crosslingual task XNLI, we report higher drops in accuracy with pruning indicating lower robustness in crosslingual transfer. Also, the importance of the encoder layers sensitively depends on the language family and the pre-training corpus size. The top layers, which are relatively more influenced by fine-tuning, encode important information for languages similar to English (SVO) while the bottom layers, which are relatively less influenced by fine-tuning, are particularly important for agglutinative and low-resource languages.
Integrating Categorical Features in End-to-End ASR
Oct 06, 2021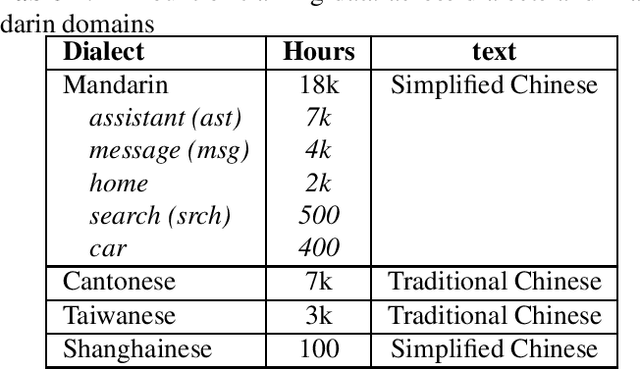
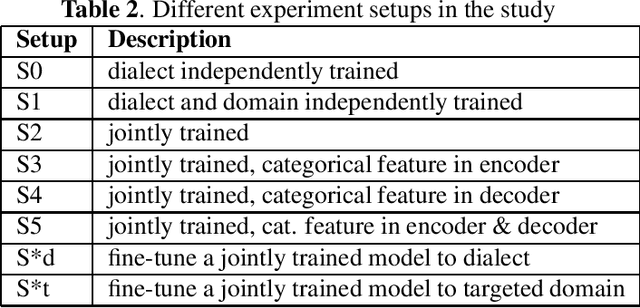
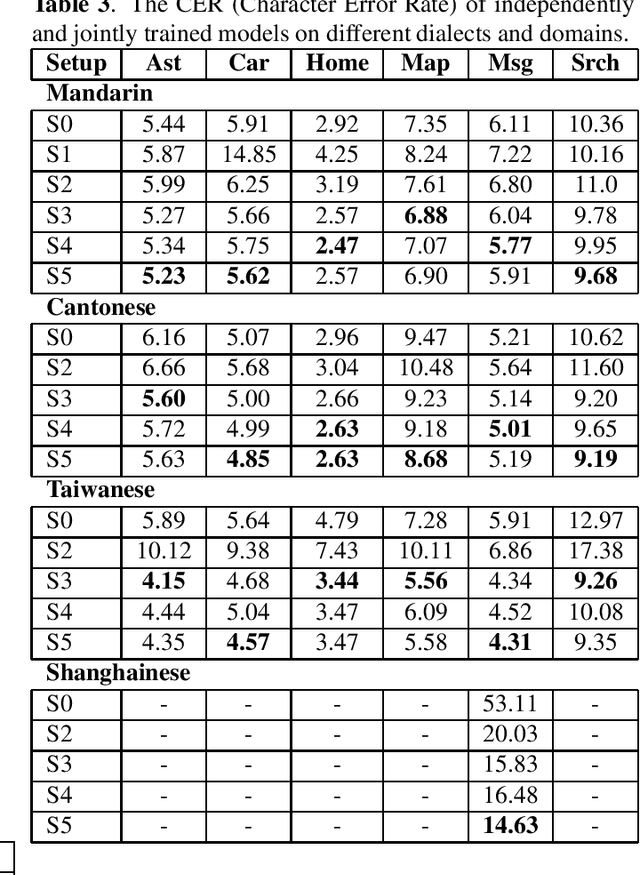
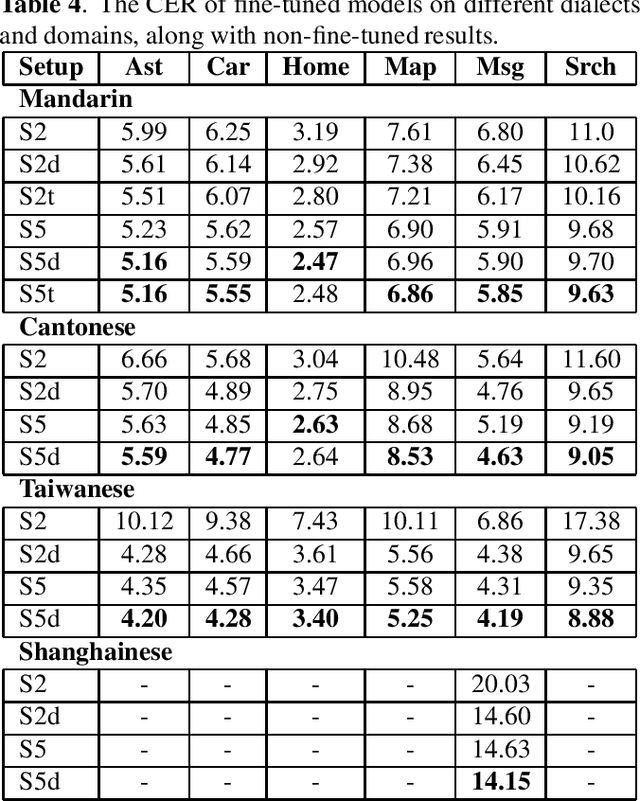
All-neural, end-to-end ASR systems gained rapid interest from the speech recognition community. Such systems convert speech input to text units using a single trainable neural network model. E2E models require large amounts of paired speech text data that is expensive to obtain. The amount of data available varies across different languages and dialects. It is critical to make use of all these data so that both low resource languages and high resource languages can be improved. When we want to deploy an ASR system for a new application domain, the amount of domain specific training data is very limited. To be able to leverage data from existing domains is important for ASR accuracy in the new domain. In this paper, we treat all these aspects as categorical information in an ASR system, and propose a simple yet effective way to integrate categorical features into E2E model. We perform detailed analysis on various training strategies, and find that building a joint model that includes categorical features can be more accurate than multiple independently trained models.
Unsupervised Multimodal Language Representations using Convolutional Autoencoders
Oct 06, 2021
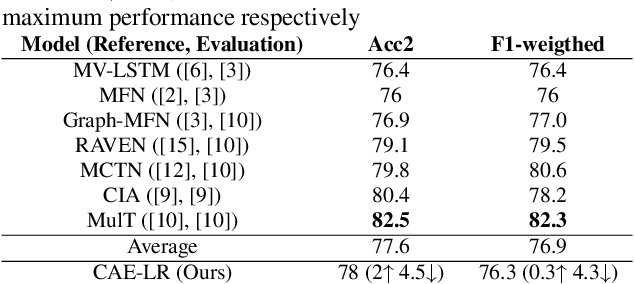
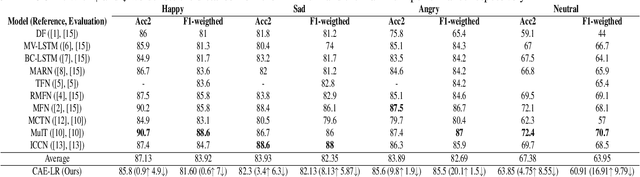
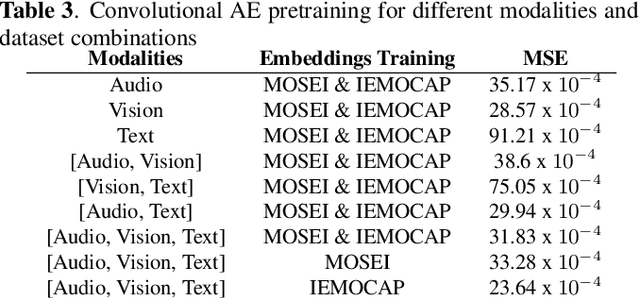
Multimodal Language Analysis is a demanding area of research, since it is associated with two requirements: combining different modalities and capturing temporal information. During the last years, several works have been proposed in the area, mostly centered around supervised learning in downstream tasks. In this paper we propose extracting unsupervised Multimodal Language representations that are universal and can be applied to different tasks. Towards this end, we map the word-level aligned multimodal sequences to 2-D matrices and then use Convolutional Autoencoders to learn embeddings by combining multiple datasets. Extensive experimentation on Sentiment Analysis (MOSEI) and Emotion Recognition (IEMOCAP) indicate that the learned representations can achieve near-state-of-the-art performance with just the use of a Logistic Regression algorithm for downstream classification. It is also shown that our method is extremely lightweight and can be easily generalized to other tasks and unseen data with small performance drop and almost the same number of parameters. The proposed multimodal representation models are open-sourced and will help grow the applicability of Multimodal Language.
Blind Modulo Analog-to-Digital Conversion of Vector Processes
Oct 12, 2021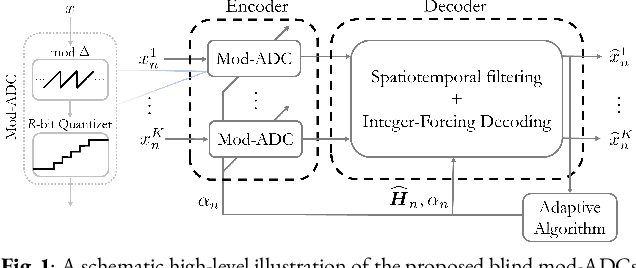
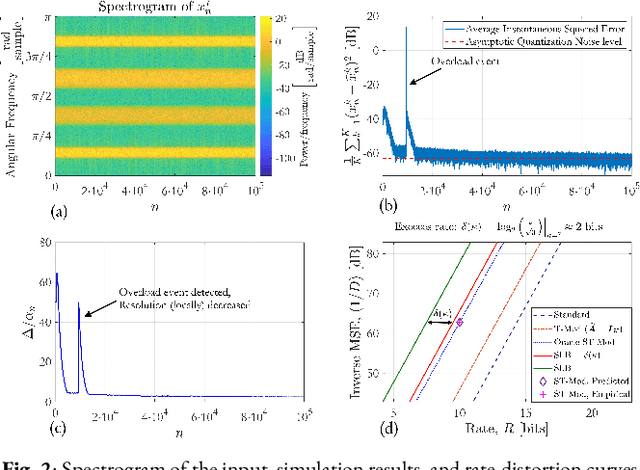
In a growing number of applications, there is a need to digitize a (possibly high) number of correlated signals whose spectral characteristics are challenging for traditional analog-to-digital converters (ADCs). Examples, among others, include multiple-input multiple-output systems where the ADCs must acquire at once several signals at a very wide but sparsely and dynamically occupied bandwidth supporting diverse services. In such scenarios, the resolution requirements can be prohibitively high. As an alternative, the recently proposed modulo-ADC architecture can in principle require dramatically fewer bits in the conversion to obtain the target fidelity, but requires that spatiotemporal information be known and explicitly taken into account by the analog and digital processing in the converter, which is frequently impractical. Building on our recent work, we address this limitation and develop a blind version of the architecture that requires no such knowledge in the converter. In particular, it features an automatic modulo-level adjustment and a fully adaptive modulo-decoding mechanism, allowing it to asymptotically match the characteristics of the unknown input signal. Simulation results demonstrate the successful operation of the proposed algorithm.
Hepatic vessel segmentation based on 3Dswin-transformer with inductive biased multi-head self-attention
Nov 05, 2021
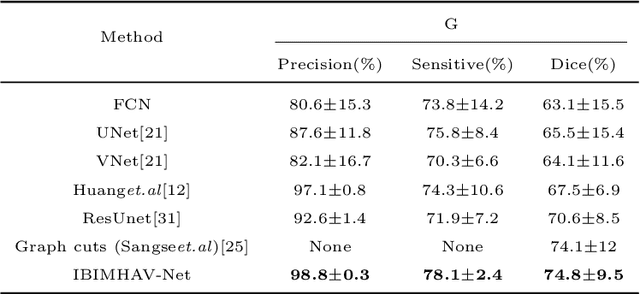
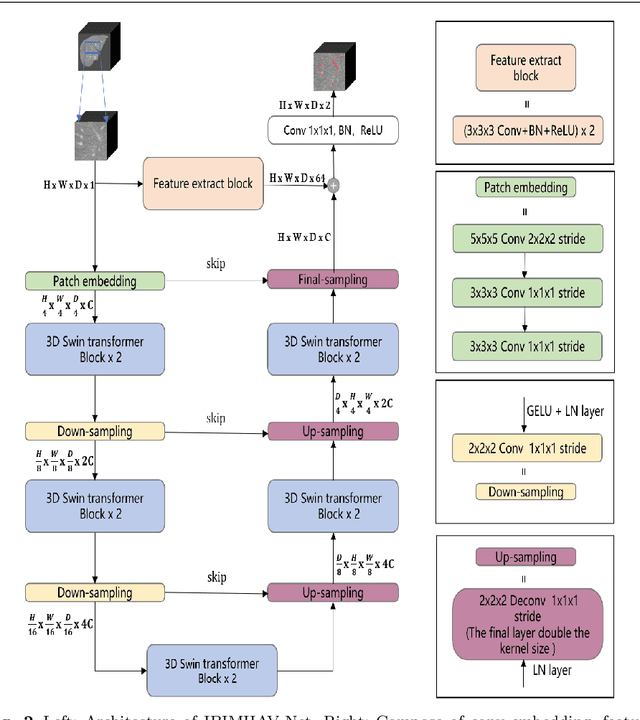
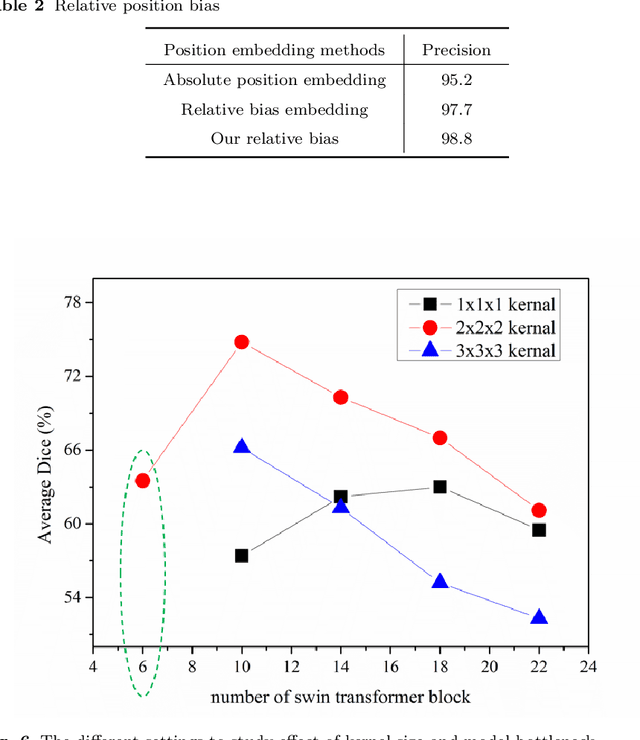
Purpose: Segmentation of liver vessels from CT images is indispensable prior to surgical planning and aroused broad range of interests in the medical image analysis community. Due to the complex structure and low contrast background, automatic liver vessel segmentation remains particularly challenging. Most of the related researches adopt FCN, U-net, and V-net variants as a backbone. However, these methods mainly focus on capturing multi-scale local features which may produce misclassified voxels due to the convolutional operator's limited locality reception field. Methods: We propose a robust end-to-end vessel segmentation network called Inductive BIased Multi-Head Attention Vessel Net(IBIMHAV-Net) by expanding swin transformer to 3D and employing an effective combination of convolution and self-attention. In practice, we introduce the voxel-wise embedding rather than patch-wise embedding to locate precise liver vessel voxels, and adopt multi-scale convolutional operators to gain local spatial information. On the other hand, we propose the inductive biased multi-head self-attention which learns inductive biased relative positional embedding from initialized absolute position embedding. Based on this, we can gain a more reliable query and key matrix. To validate the generalization of our model, we test on samples which have different structural complexity. Results: We conducted experiments on the 3DIRCADb datasets. The average dice and sensitivity of the four tested cases were 74.8% and 77.5%, which exceed results of existing deep learning methods and improved graph cuts method. Conclusion: The proposed model IBIMHAV-Net provides an automatic, accurate 3D liver vessel segmentation with an interleaved architecture that better utilizes both global and local spatial features in CT volumes. It can be further extended for other clinical data.
Learning Meta-class Memory for Few-Shot Semantic Segmentation
Aug 16, 2021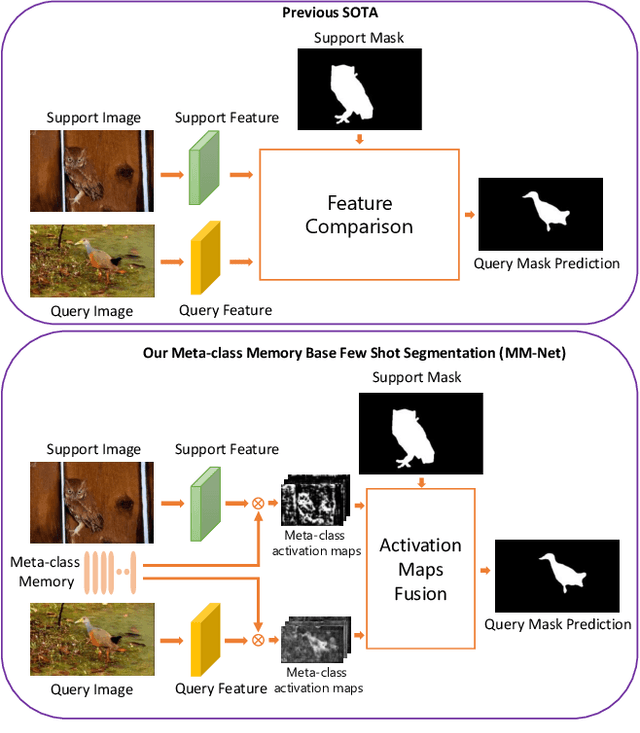
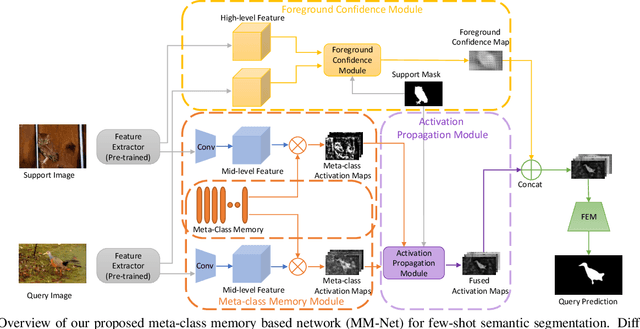
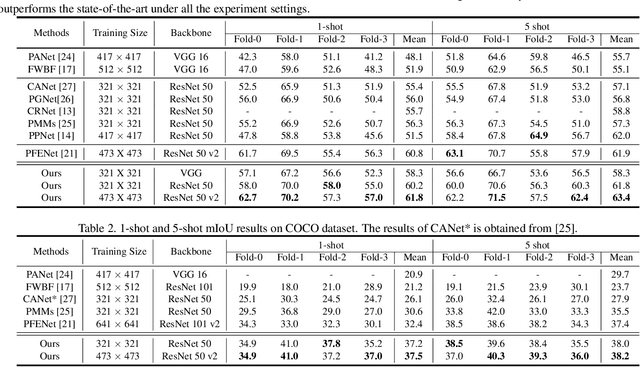
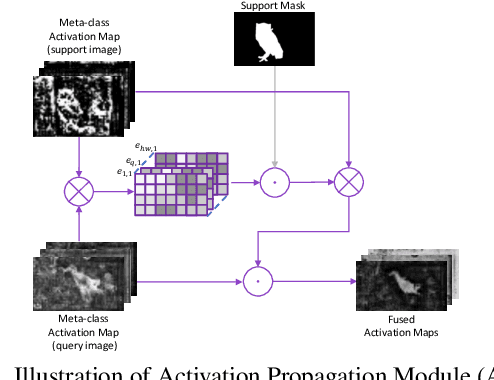
Currently, the state-of-the-art methods treat few-shot semantic segmentation task as a conditional foreground-background segmentation problem, assuming each class is independent. In this paper, we introduce the concept of meta-class, which is the meta information (e.g. certain middle-level features) shareable among all classes. To explicitly learn meta-class representations in few-shot segmentation task, we propose a novel Meta-class Memory based few-shot segmentation method (MM-Net), where we introduce a set of learnable memory embeddings to memorize the meta-class information during the base class training and transfer to novel classes during the inference stage. Moreover, for the $k$-shot scenario, we propose a novel image quality measurement module to select images from the set of support images. A high-quality class prototype could be obtained with the weighted sum of support image features based on the quality measure. Experiments on both PASCAL-$5^i$ and COCO dataset shows that our proposed method is able to achieve state-of-the-art results in both 1-shot and 5-shot settings. Particularly, our proposed MM-Net achieves 37.5\% mIoU on the COCO dataset in 1-shot setting, which is 5.1\% higher than the previous state-of-the-art.
Residual Overfit Method of Exploration
Oct 06, 2021Exploration is a crucial aspect of bandit and reinforcement learning algorithms. The uncertainty quantification necessary for exploration often comes from either closed-form expressions based on simple models or resampling and posterior approximations that are computationally intensive. We propose instead an approximate exploration methodology based on fitting only two point estimates, one tuned and one overfit. The approach, which we term the residual overfit method of exploration (ROME), drives exploration towards actions where the overfit model exhibits the most overfitting compared to the tuned model. The intuition is that overfitting occurs the most at actions and contexts with insufficient data to form accurate predictions of the reward. We justify this intuition formally from both a frequentist and a Bayesian information theoretic perspective. The result is a method that generalizes to a wide variety of models and avoids the computational overhead of resampling or posterior approximations. We compare ROME against a set of established contextual bandit methods on three datasets and find it to be one of the best performing.
Extracting Feelings of People Regarding COVID-19 by Social Network Mining
Oct 12, 2021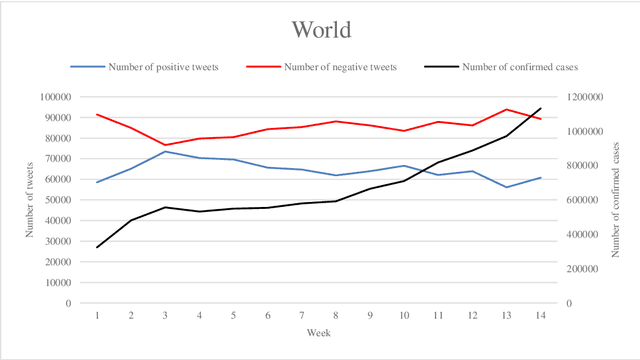
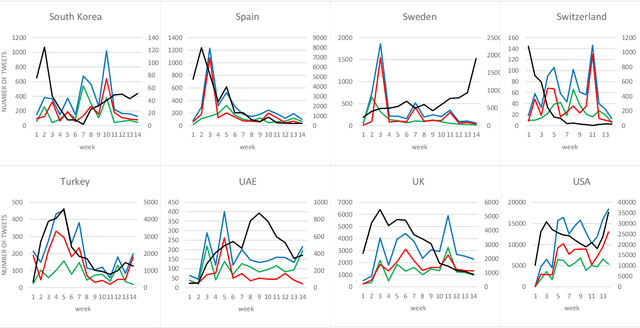
In 2020, COVID-19 became the chief concern of the world and is still reflected widely in all social networks. Each day, users post millions of tweets and comments on this subject, which contain significant implicit information about the public opinion. In this regard, a dataset of COVID-related tweets in English language is collected, which consists of more than two million tweets from March 23 to June 23 of 2020 to extract the feelings of the people in various countries in the early stages of this outbreak. To this end, first, we use a lexicon-based approach in conjunction with the GeoNames geographic database to label the tweets with their locations. Next, a method based on the recently introduced and widely cited RoBERTa model is proposed to analyze their sentimental content. After that, the trend graphs of the frequency of tweets as well as sentiments are produced for the world and the nations that were more engaged with COVID-19. Graph analysis shows that the frequency graphs of the tweets for the majority of nations are significantly correlated with the official statistics of the daily afflicted in them. Moreover, several implicit knowledge is extracted and discussed.
Two Headed Dragons: Multimodal Fusion and Cross Modal Transactions
Jul 24, 2021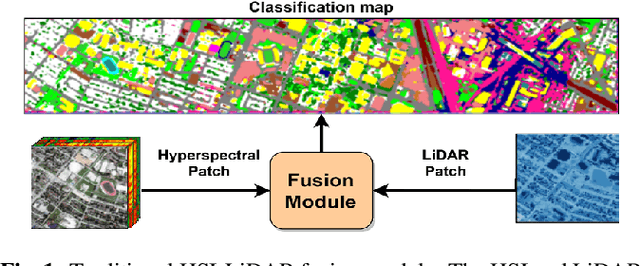
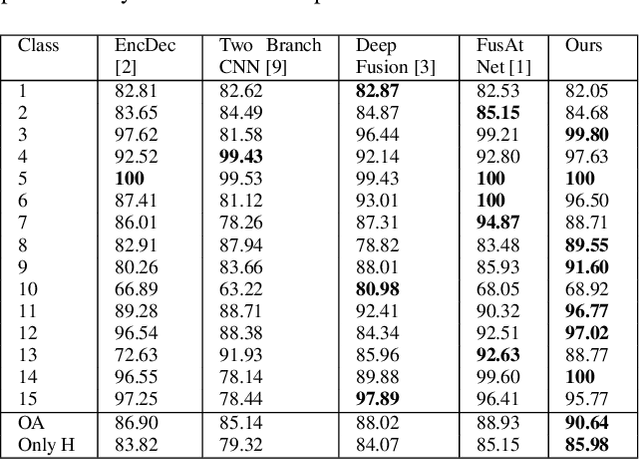
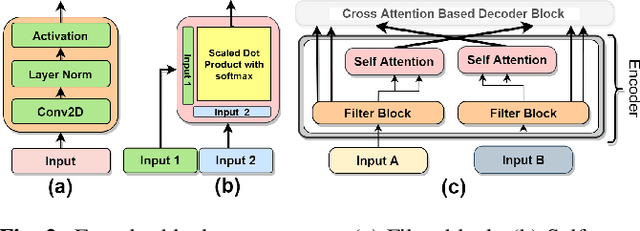
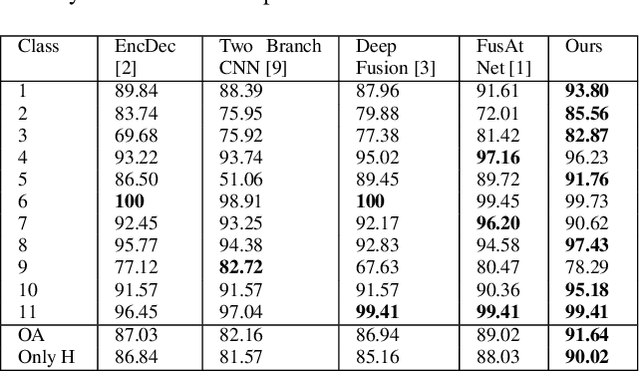
As the field of remote sensing is evolving, we witness the accumulation of information from several modalities, such as multispectral (MS), hyperspectral (HSI), LiDAR etc. Each of these modalities possess its own distinct characteristics and when combined synergistically, perform very well in the recognition and classification tasks. However, fusing multiple modalities in remote sensing is cumbersome due to highly disparate domains. Furthermore, the existing methods do not facilitate cross-modal interactions. To this end, we propose a novel transformer based fusion method for HSI and LiDAR modalities. The model is composed of stacked auto encoders that harness the cross key-value pairs for HSI and LiDAR, thus establishing a communication between the two modalities, while simultaneously using the CNNs to extract the spectral and spatial information from HSI and LiDAR. We test our model on Houston (Data Fusion Contest - 2013) and MUUFL Gulfport datasets and achieve competitive results.
Position Masking for Improved Layout-Aware Document Understanding
Sep 01, 2021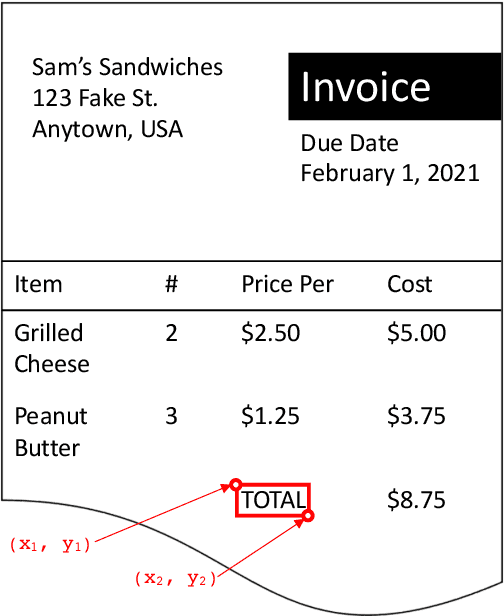
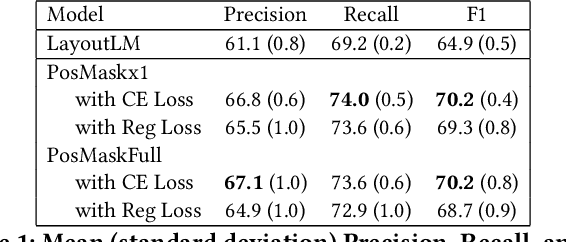
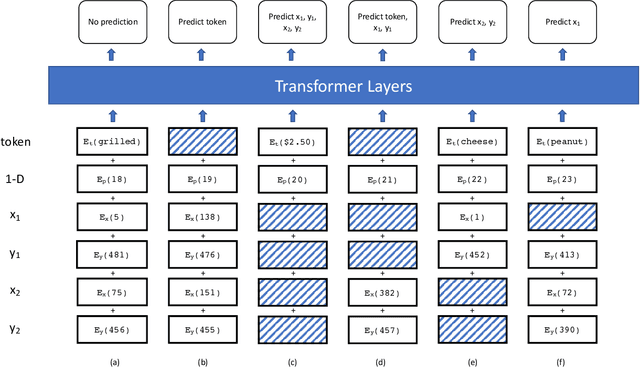
Natural language processing for document scans and PDFs has the potential to enormously improve the efficiency of business processes. Layout-aware word embeddings such as LayoutLM have shown promise for classification of and information extraction from such documents. This paper proposes a new pre-training task called that can improve performance of layout-aware word embeddings that incorporate 2-D position embeddings. We compare models pre-trained with only language masking against models pre-trained with both language masking and position masking, and we find that position masking improves performance by over 5% on a form understanding task.