 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dendritic Self-Organizing Maps for Continual Learning
Oct 18, 2021
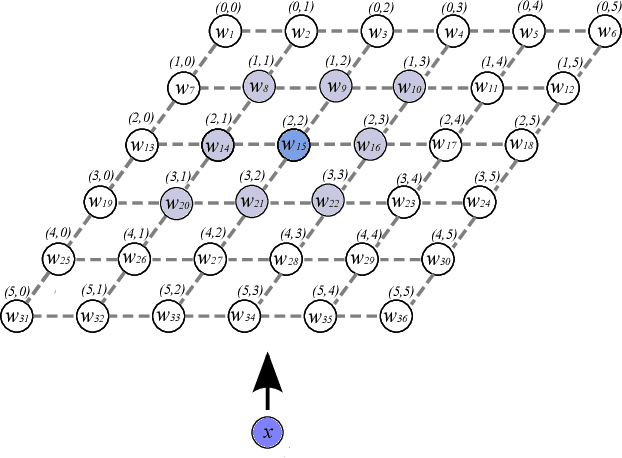

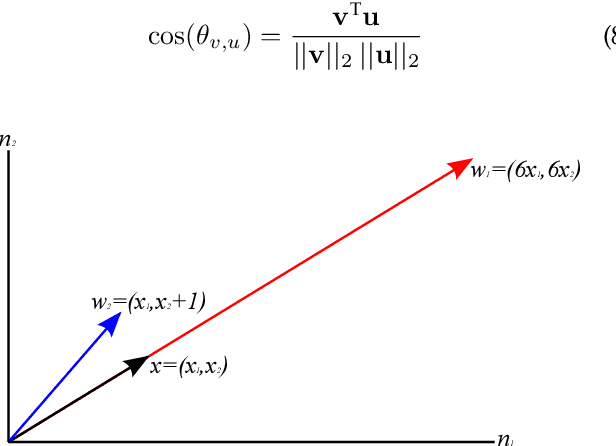
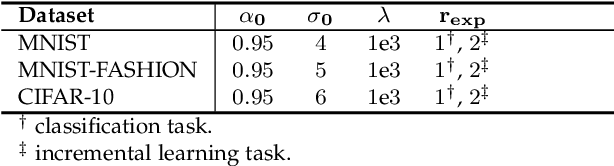
Current deep learning architectures show remarkable performance when trained in large-scale, controlled datasets. However, the predictive ability of these architectures significantly decreases when learning new classes incrementally. This is due to their inclination to forget the knowledge acquired from previously seen data, a phenomenon termed catastrophic-forgetting. On the other hand, Self-Organizing Maps (SOMs) can model the input space utilizing constrained k-means and thus maintain past knowledge. Here, we propose a novel algorithm inspired by biological neurons, termed Dendritic-Self-Organizing Map (DendSOM). DendSOM consists of a single layer of SOMs, which extract patterns from specific regions of the input space accompanied by a set of hit matrices, one per SOM, which estimate the association between units and labels. The best-matching unit of an input pattern is selected using the maximum cosine similarity rule, while the point-wise mutual information is employed for class inference. DendSOM performs unsupervised feature extraction as it does not use labels for targeted updating of the weights. It outperforms classical SOMs and several state-of-the-art continual learning algorithms on benchmark datasets, such as the Split-MNIST and Split-CIFAR-10. We propose that the incorporation of neuronal properties in SOMs may help remedy catastrophic forgetting.
Harnessing the Conditioning Sensorium for Improved Image Translation
Oct 13, 2021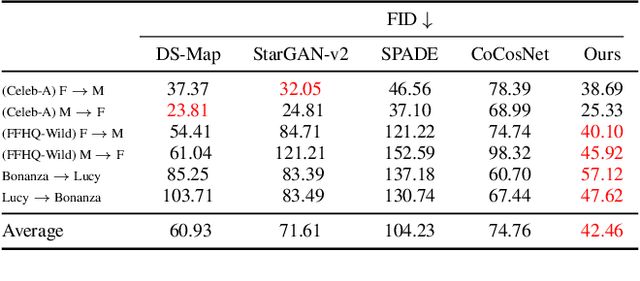
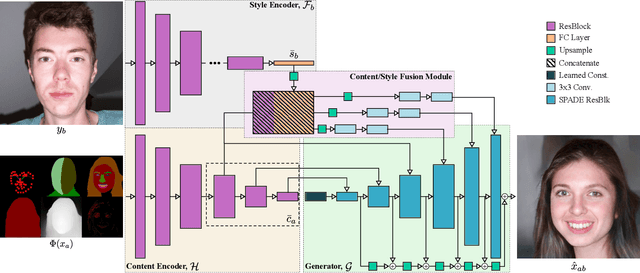


Multi-modal domain translation typically refers to synthesizing a novel image that inherits certain localized attributes from a 'content' image (e.g. layout, semantics, or geometry), and inherits everything else (e.g. texture, lighting, sometimes even semantics) from a 'style' image. The dominant approach to this task is attempting to learn disentangled 'content' and 'style' representations from scratch. However, this is not only challenging, but ill-posed, as what users wish to preserve during translation varies depending on their goals. Motivated by this inherent ambiguity, we define 'content' based on conditioning information extracted by off-the-shelf pre-trained models. We then train our style extractor and image decoder with an easy to optimize set of reconstruction objectives. The wide variety of high-quality pre-trained models available and simple training procedure makes our approach straightforward to apply across numerous domains and definitions of 'content'. Additionally it offers intuitive control over which aspects of 'content' are preserved across domains. We evaluate our method on traditional, well-aligned, datasets such as CelebA-HQ, and propose two novel datasets for evaluation on more complex scenes: ClassicTV and FFHQ-Wild. Our approach, Sensorium, enables higher quality domain translation for more complex scenes.
Leveraging MoCap Data for Human Mesh Recovery
Oct 18, 2021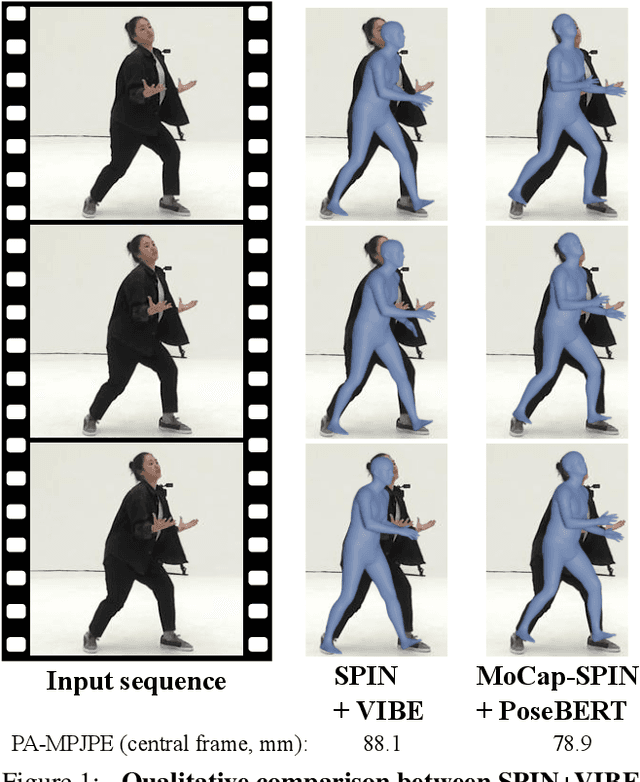
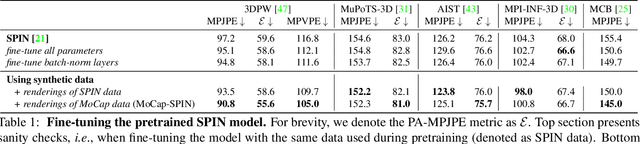


Training state-of-the-art models for human body pose and shape recovery from images or videos requires datasets with corresponding annotations that are really hard and expensive to obtain. Our goal in this paper is to study whether poses from 3D Motion Capture (MoCap) data can be used to improve image-based and video-based human mesh recovery methods. We find that fine-tune image-based models with synthetic renderings from MoCap data can increase their performance, by providing them with a wider variety of poses, textures and backgrounds. In fact, we show that simply fine-tuning the batch normalization layers of the model is enough to achieve large gains. We further study the use of MoCap data for video, and introduce PoseBERT, a transformer module that directly regresses the pose parameters and is trained via masked modeling. It is simple, generic and can be plugged on top of any state-of-the-art image-based model in order to transform it in a video-based model leveraging temporal information. Our experimental results show that the proposed approaches reach state-of-the-art performance on various datasets including 3DPW, MPI-INF-3DHP, MuPoTS-3D, MCB and AIST. Test code and models will be available soon.
A surprisal--duration trade-off across and within the world's languages
Sep 30, 2021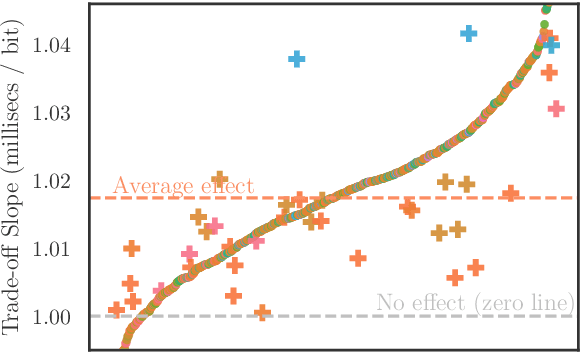
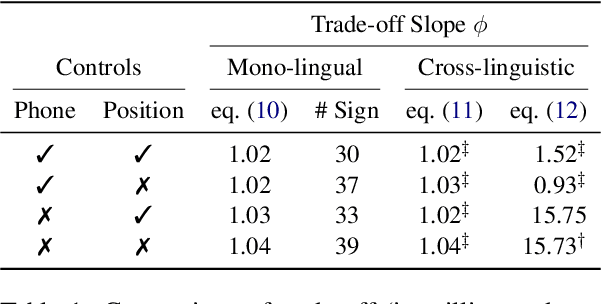
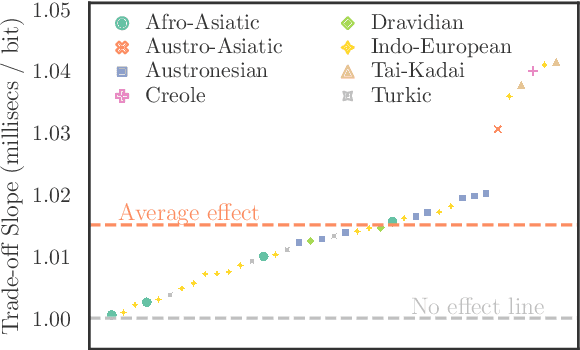
While there exist scores of natural languages, each with its unique features and idiosyncrasies, they all share a unifying theme: enabling human communication. We may thus reasonably predict that human cognition shapes how these languages evolve and are used. Assuming that the capacity to process information is roughly constant across human populations, we expect a surprisal--duration trade-off to arise both across and within languages. We analyse this trade-off using a corpus of 600 languages and, after controlling for several potential confounds, we find strong supporting evidence in both settings. Specifically, we find that, on average, phones are produced faster in languages where they are less surprising, and vice versa. Further, we confirm that more surprising phones are longer, on average, in 319 languages out of the 600. We thus conclude that there is strong evidence of a surprisal--duration trade-off in operation, both across and within the world's languages.
3D Human Texture Estimation from a Single Image with Transformers
Sep 06, 2021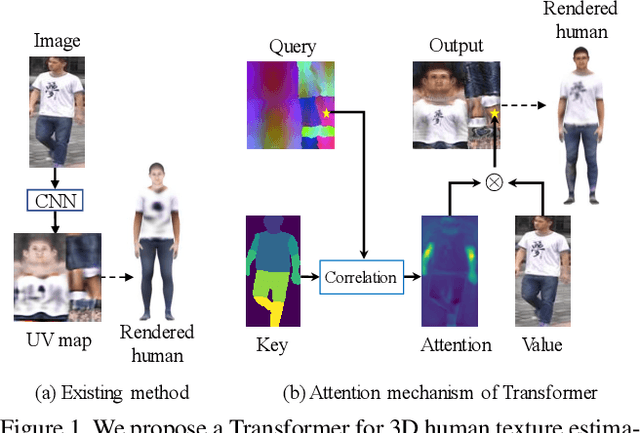
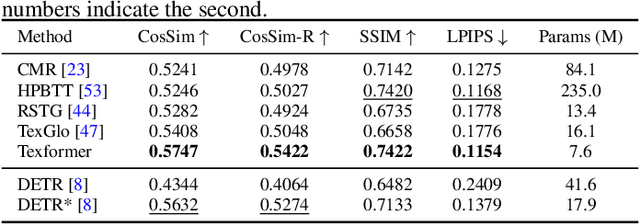
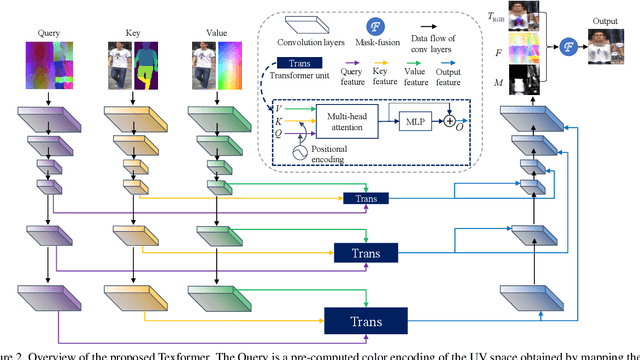
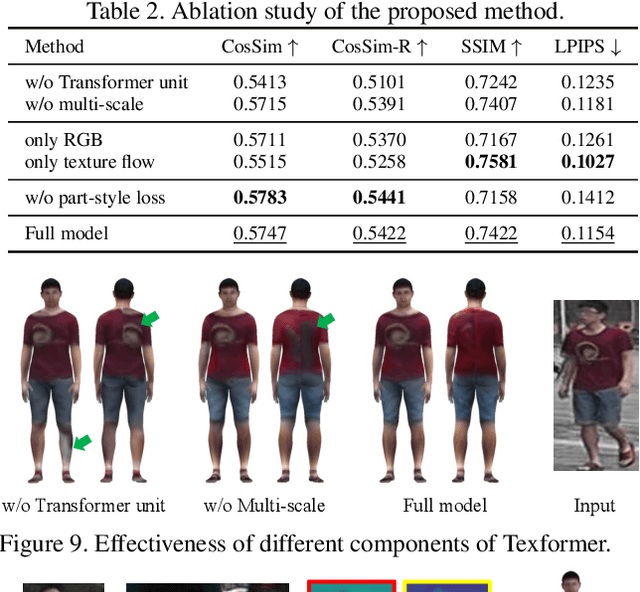
We propose a Transformer-based framework for 3D human texture estimation from a single image. The proposed Transformer is able to effectively exploit the global information of the input image, overcoming the limitations of existing methods that are solely based on convolutional neural networks. In addition, we also propose a mask-fusion strategy to combine the advantages of the RGB-based and texture-flow-based models. We further introduce a part-style loss to help reconstruct high-fidelity colors without introducing unpleasant artifacts. Extensive experiments demonstrate the effectiveness of the proposed method against state-of-the-art 3D human texture estimation approaches both quantitatively and qualitatively.
* ICCV 2021 Oral, Project: https://www.mmlab-ntu.com/project/texformer, Code: https://github.com/xuxy09/Texformer
Syntactic Persistence in Language Models: Priming as a Window into Abstract Language Representations
Sep 30, 2021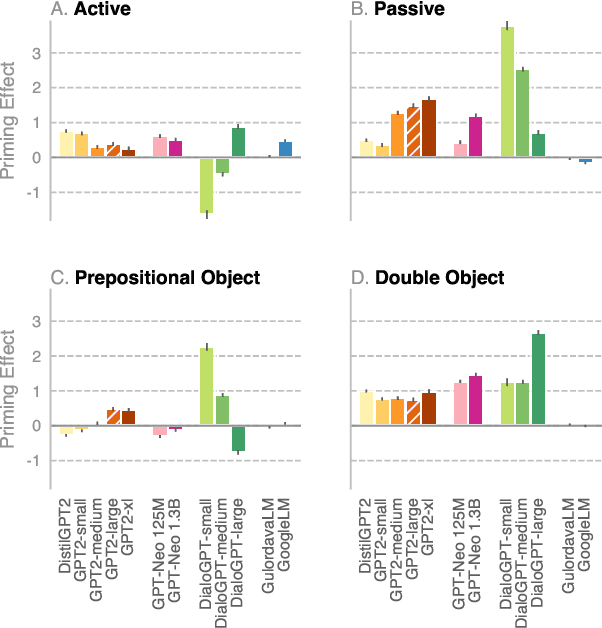
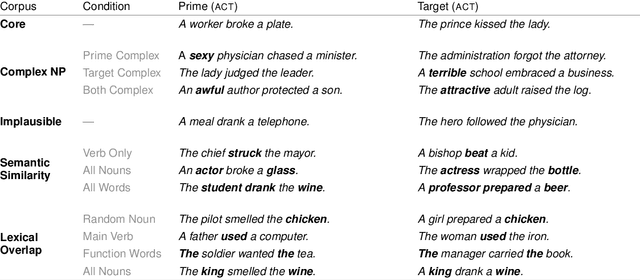
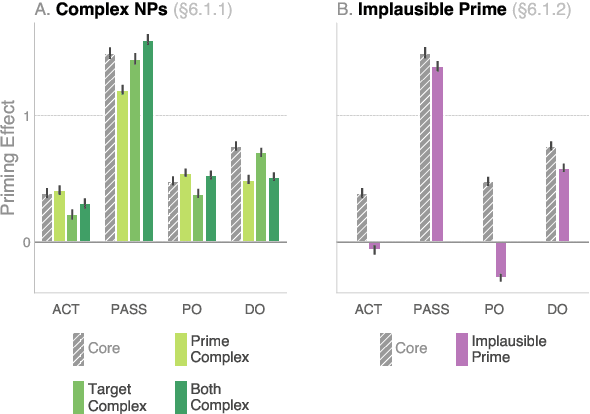

We investigate the extent to which modern, neural language models are susceptible to syntactic priming, the phenomenon where the syntactic structure of a sentence makes the same structure more probable in a follow-up sentence. We explore how priming can be used to study the nature of the syntactic knowledge acquired by these models. We introduce a novel metric and release Prime-LM, a large corpus where we control for various linguistic factors which interact with priming strength. We find that recent large Transformer models indeed show evidence of syntactic priming, but also that the syntactic generalisations learned by these models are to some extent modulated by semantic information. We report surprisingly strong priming effects when priming with multiple sentences, each with different words and meaning but with identical syntactic structure. We conclude that the syntactic priming paradigm is a highly useful, additional tool for gaining insights into the capacities of language models.
QAInfomax: Learning Robust Question Answering System by Mutual Information Maximization
Aug 31, 2019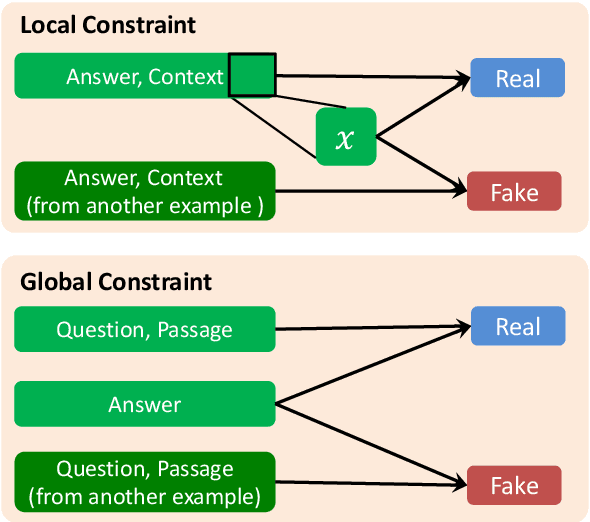
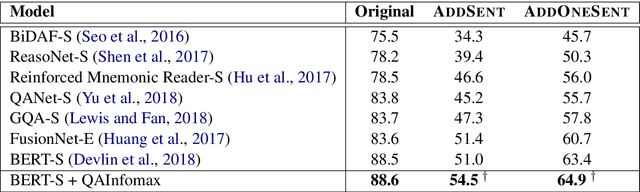

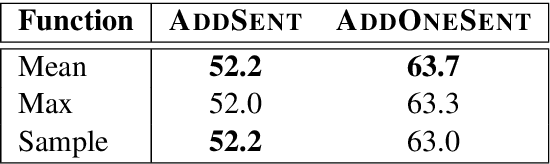
Standard accuracy metrics indicate that modern reading comprehension systems have achieved strong performance in many question answering datasets. However, the extent these systems truly understand language remains unknown, and existing systems are not good at distinguishing distractor sentences, which look related but do not actually answer the question. To address this problem, we propose QAInfomax as a regularizer in reading comprehension systems by maximizing mutual information among passages, a question, and its answer. QAInfomax helps regularize the model to not simply learn the superficial correlation for answering questions. The experiments show that our proposed QAInfomax achieves the state-of-the-art performance on the benchmark Adversarial-SQuAD dataset.
ES-ImageNet: A Million Event-Stream Classification Dataset for Spiking Neural Networks
Oct 23, 2021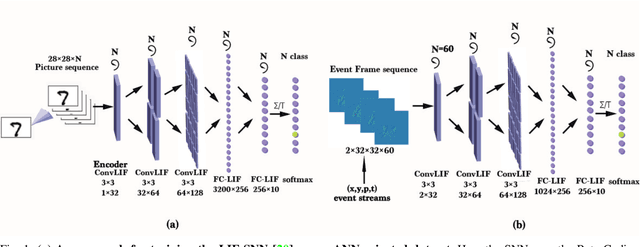
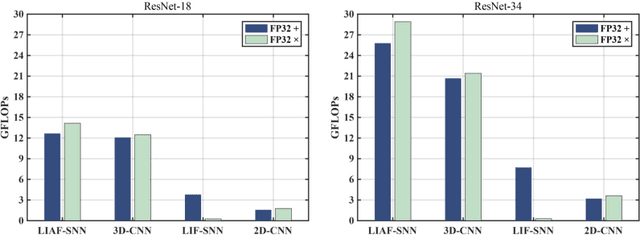
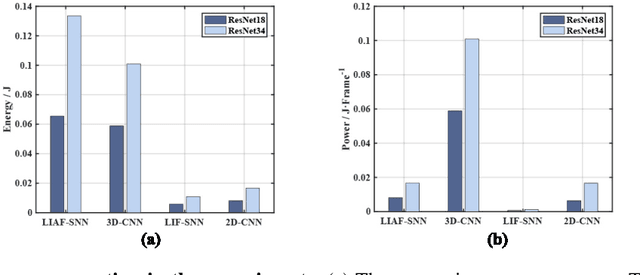
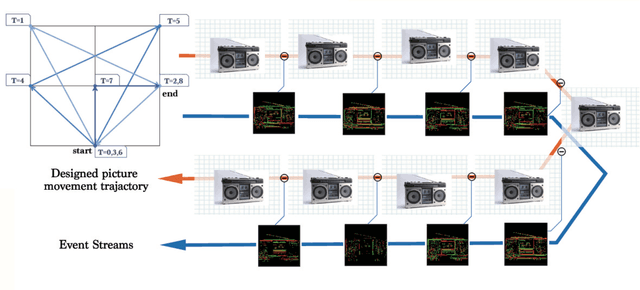
With event-driven algorithms, especially the spiking neural networks (SNNs), achieving continuous improvement in neuromorphic vision processing, a more challenging event-stream-dataset is urgently needed. However, it is well known that creating an ES-dataset is a time-consuming and costly task with neuromorphic cameras like dynamic vision sensors (DVS). In this work, we propose a fast and effective algorithm termed Omnidirectional Discrete Gradient (ODG) to convert the popular computer vision dataset ILSVRC2012 into its event-stream (ES) version, generating about 1,300,000 frame-based images into ES-samples in 1000 categories. In this way, we propose an ES-dataset called ES-ImageNet, which is dozens of times larger than other neuromorphic classification datasets at present and completely generated by the software. The ODG algorithm implements an image motion to generate local value changes with discrete gradient information in different directions, providing a low-cost and high-speed way for converting frame-based images into event streams, along with Edge-Integral to reconstruct the high-quality images from event streams. Furthermore, we analyze the statistics of the ES-ImageNet in multiple ways, and a performance benchmark of the dataset is also provided using both famous deep neural network algorithms and spiking neural network algorithms. We believe that this work shall provide a new large-scale benchmark dataset for SNNs and neuromorphic vision.
Projection-wise Disentangling for Fair and Interpretable Representation Learning: Application to 3D Facial Shape Analysis
Jun 28, 2021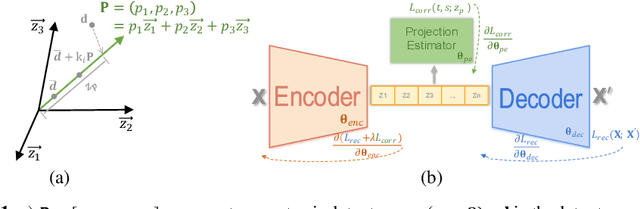
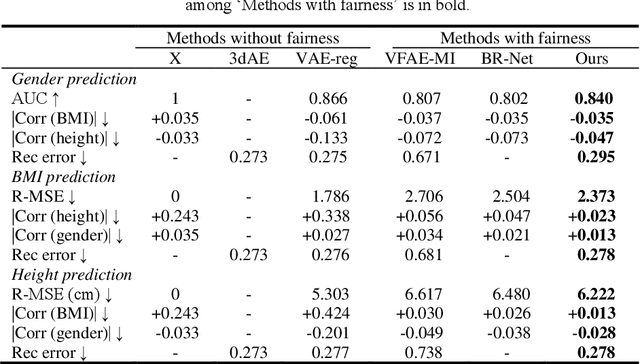
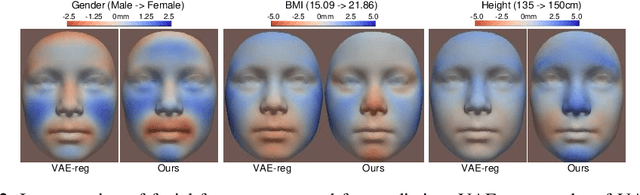
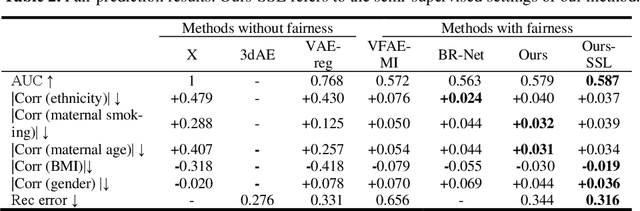
Confounding bias is a crucial problem when applying machine learning to practice, especially in clinical practice. We consider the problem of learning representations independent to multiple biases. In literature, this is mostly solved by purging the bias information from learned representations. We however expect this strategy to harm the diversity of information in the representation, and thus limiting its prospective usage (e.g., interpretation). Therefore, we propose to mitigate the bias while keeping almost all information in the latent representations, which enables us to observe and interpret them as well. To achieve this, we project latent features onto a learned vector direction, and enforce the independence between biases and projected features rather than all learned features. To interpret the mapping between projected features and input data, we propose projection-wise disentangling: a sampling and reconstruction along the learned vector direction. The proposed method was evaluated on the analysis of 3D facial shape and patient characteristics (N=5011). Experiments showed that this conceptually simple method achieved state-of-the-art fair prediction performance and interpretability, showing its great potential for clinical applications.
A Promising Technology for 6G Wireless Networks: Intelligent Reflecting Surface
Oct 18, 2021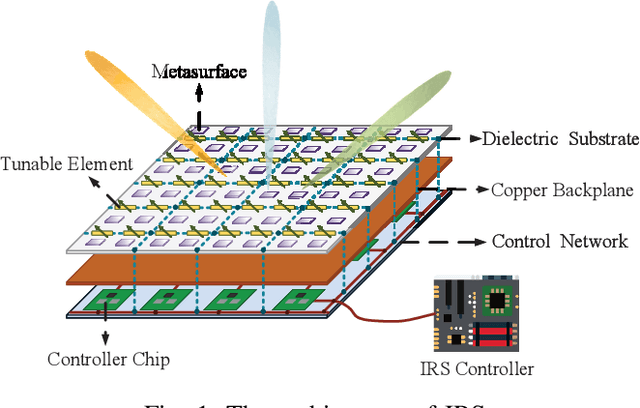
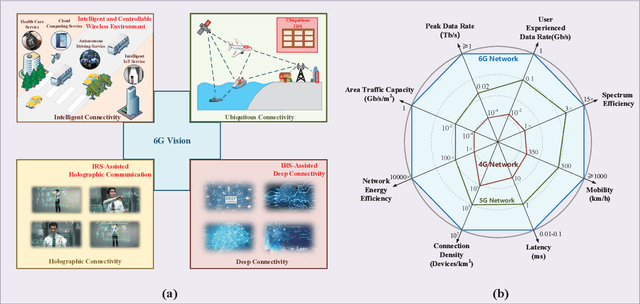
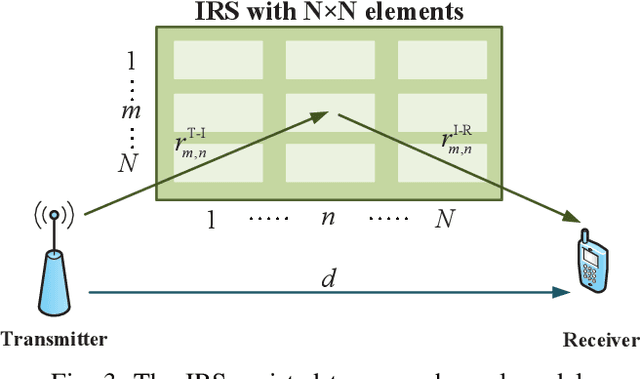
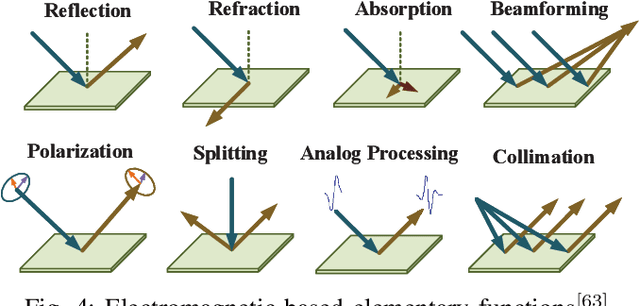
The intelligent information society, which is highly digitized, intelligence inspired and globally data driven, will be deployed in the next decade. The next 6G wireless communication networks are the key to achieve this grand blueprint, which is expected to connect everything, provide full dimensional wireless coverage and integrate all functions to support full-vertical applications. Recent research reveals that intelligent reflecting surface (IRS) with wireless environment control capability is a promising technology for 6G networks. Specifically, IRS can intelligently control the wavefront, e.g., the phase, amplitude, frequency, and even polarization by massive tunable elements, thus achieving fine-grained 3-D passive beamforming. In this paper, we first give a blueprint of the next 6G networks including the vision, typical scenarios and key performance indicators (KPIs). Then, we provide an overview of IRS including the new signal model, hardware architecture and competitive advantages in 6G networks. Besides, we discuss the potential application of IRS in the connectivity of 6G networks in detail, including intelligent and controllable wireless environment, ubiquitous connectivity, deep connectivity and holographic connectivity. At last, we summarize the challenges of IRS application and deployment in 6G networks. As a timely review of IRS, our summary will be of interest to both researchers and practitioners engaging in IRS for 6G networks.