 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Feudal Reinforcement Learning by Reading Manuals
Oct 13, 2021
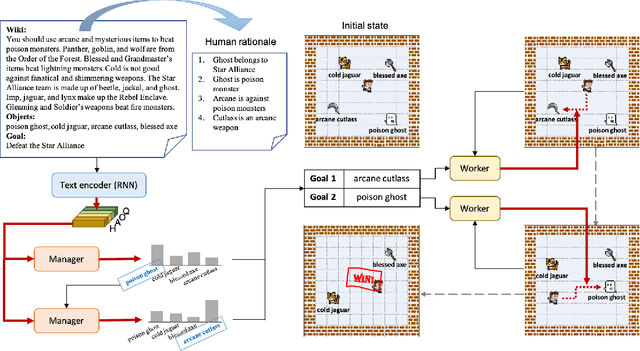

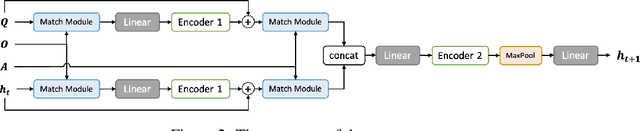
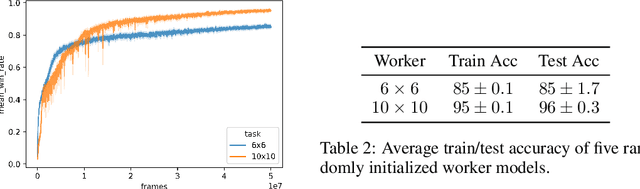
Reading to act is a prevalent but challenging task which requires the ability to reason from a concise instruction. However, previous works face the semantic mismatch between the low-level actions and the high-level language descriptions and require the human-designed curriculum to work properly. In this paper, we present a Feudal Reinforcement Learning (FRL) model consisting of a manager agent and a worker agent. The manager agent is a multi-hop plan generator dealing with high-level abstract information and generating a series of sub-goals in a backward manner. The worker agent deals with the low-level perceptions and actions to achieve the sub-goals one by one. In comparison, our FRL model effectively alleviate the mismatching between text-level inference and low-level perceptions and actions; and is general to various forms of environments, instructions and manuals; and our multi-hop plan generator can significantly boost for challenging tasks where multi-step reasoning form the texts is critical to resolve the instructed goals. We showcase our approach achieves competitive performance on two challenging tasks, Read to Fight Monsters (RTFM) and Messenger, without human-designed curriculum learning.
A Visual Technique to Analyze Flow of Information in a Machine Learning System
Aug 02, 2019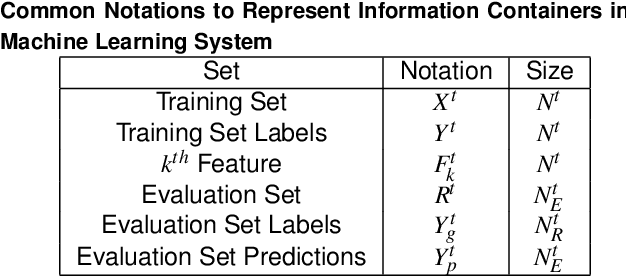

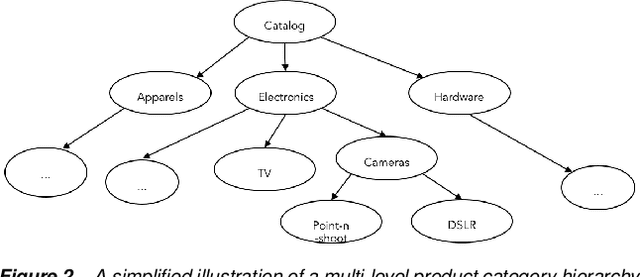
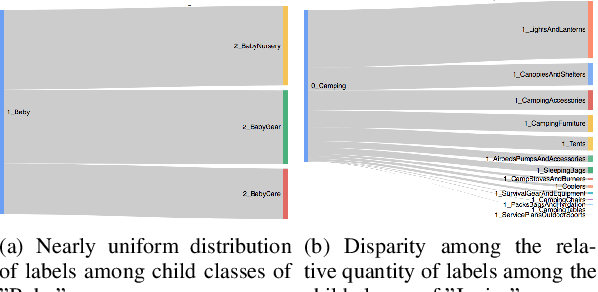
Machine learning (ML) algorithms and machine learning based software systems implicitly or explicitly involve complex flow of information between various entities such as training data, feature space, validation set and results. Understanding the statistical distribution of such information and how they flow from one entity to another influence the operation and correctness of such systems, especially in large-scale applications that perform classification or prediction in real time. In this paper, we propose a visual approach to understand and analyze flow of information during model training and serving phases. We build the visualizations using a technique called Sankey Diagram - conventionally used to understand data flow among sets - to address various use cases of in a machine learning system. We demonstrate how the proposed technique, tweaked and twisted to suit a classification problem, can play a critical role in better understanding of the training data, the features, and the classifier performance. We also discuss how this technique enables diagnostic analysis of model predictions and comparative analysis of predictions from multiple classifiers. The proposed concept is illustrated with the example of categorization of millions of products in the e-commerce domain - a multi-class hierarchical classification problem.
Correlated Stochastic Block Models: Exact Graph Matching with Applications to Recovering Communities
Jul 14, 2021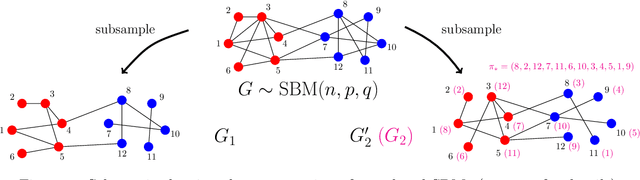
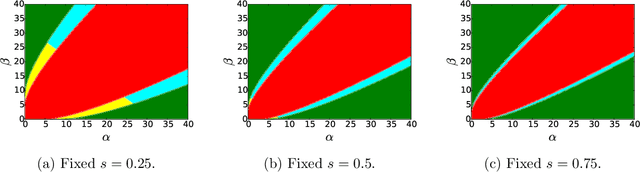
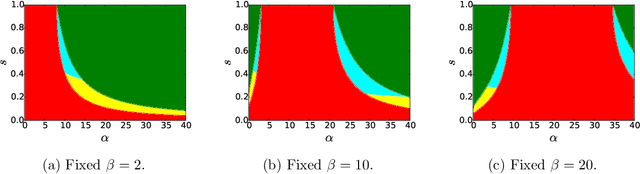
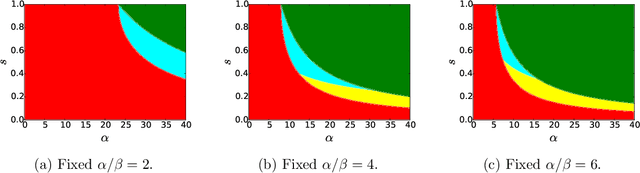
We consider the task of learning latent community structure from multiple correlated networks. First, we study the problem of learning the latent vertex correspondence between two edge-correlated stochastic block models, focusing on the regime where the average degree is logarithmic in the number of vertices. We derive the precise information-theoretic threshold for exact recovery: above the threshold there exists an estimator that outputs the true correspondence with probability close to 1, while below it no estimator can recover the true correspondence with probability bounded away from 0. As an application of our results, we show how one can exactly recover the latent communities using multiple correlated graphs in parameter regimes where it is information-theoretically impossible to do so using just a single graph.
Feature Mining: A Novel Training Strategy for Convolutional Neural Network
Jul 18, 2021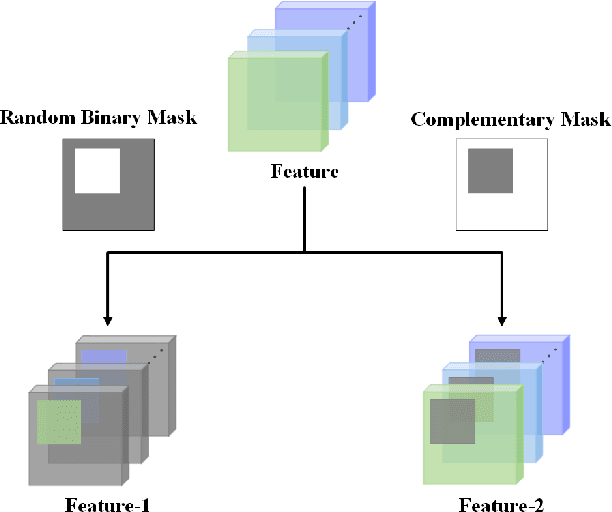
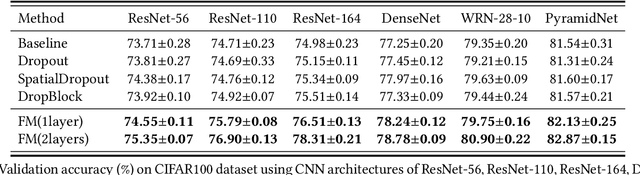


In this paper, we propose a novel training strategy for convolutional neural network(CNN) named Feature Mining, that aims to strengthen the network's learning of the local feature. Through experiments, we find that semantic contained in different parts of the feature is different, while the network will inevitably lose the local information during feedforward propagation. In order to enhance the learning of local feature, Feature Mining divides the complete feature into two complementary parts and reuse these divided feature to make the network learn more local information, we call the two steps as feature segmentation and feature reusing. Feature Mining is a parameter-free method and has plug-and-play nature, and can be applied to any CNN models. Extensive experiments demonstrate the wide applicability, versatility, and compatibility of our method.
Feature Fusion Vision Transformer Fine-Grained Visual Categorization
Jul 06, 2021
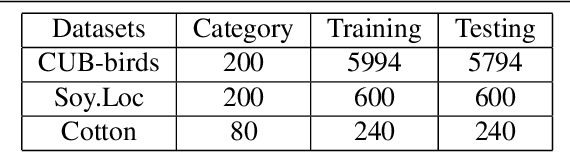
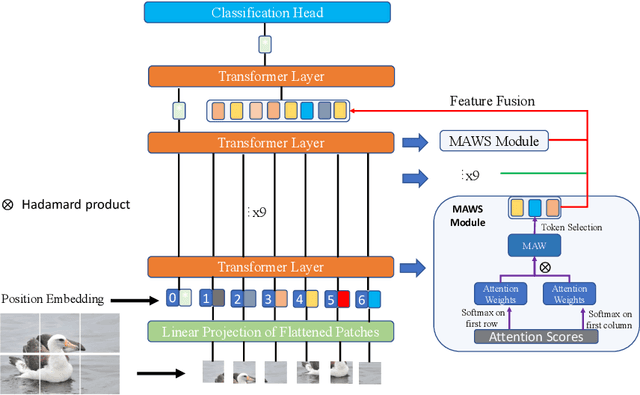
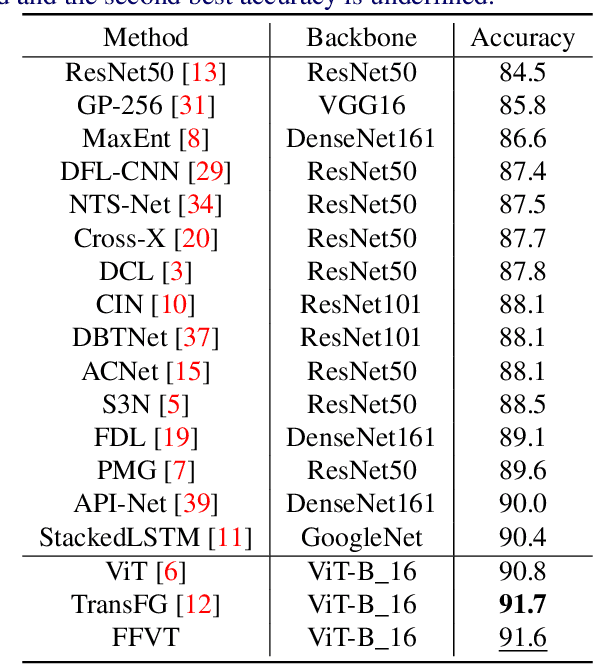
The core for tackling the fine-grained visual categorization (FGVC) is to learn subtleyet discriminative features. Most previous works achieve this by explicitly selecting thediscriminative parts or integrating the attention mechanism via CNN-based approaches.However, these methods enhance the computational complexity and make the modeldominated by the regions containing the most of the objects. Recently, vision trans-former (ViT) has achieved SOTA performance on general image recognition tasks. Theself-attention mechanism aggregates and weights the information from all patches to theclassification token, making it perfectly suitable for FGVC. Nonetheless, the classifi-cation token in the deep layer pays more attention to the global information, lackingthe local and low-level features that are essential for FGVC. In this work, we proposea novel pure transformer-based framework Feature Fusion Vision Transformer (FFVT)where we aggregate the important tokens from each transformer layer to compensate thelocal, low-level and middle-level information. We design a novel token selection mod-ule called mutual attention weight selection (MAWS) to guide the network effectivelyand efficiently towards selecting discriminative tokens without introducing extra param-eters. We verify the effectiveness of FFVT on three benchmarks where FFVT achievesthe state-of-the-art performance.
Looking for Confirmations: An Effective and Human-Like Visual Dialogue Strategy
Sep 11, 2021



Generating goal-oriented questions in Visual Dialogue tasks is a challenging and long-standing problem. State-Of-The-Art systems are shown to generate questions that, although grammatically correct, often lack an effective strategy and sound unnatural to humans. Inspired by the cognitive literature on information search and cross-situational word learning, we design Confirm-it, a model based on a beam search re-ranking algorithm that guides an effective goal-oriented strategy by asking questions that confirm the model's conjecture about the referent. We take the GuessWhat?! game as a case-study. We show that dialogues generated by Confirm-it are more natural and effective than beam search decoding without re-ranking.
Updating Street Maps using Changes Detected in Satellite Imagery
Oct 13, 2021
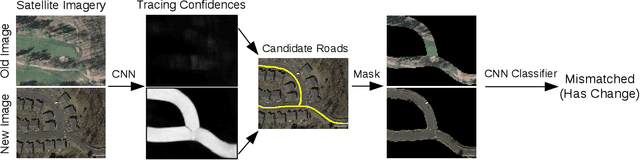


Accurately maintaining digital street maps is labor-intensive. To address this challenge, much work has studied automatically processing geospatial data sources such as GPS trajectories and satellite images to reduce the cost of maintaining digital maps. An end-to-end map update system would first process geospatial data sources to extract insights, and second leverage those insights to update and improve the map. However, prior work largely focuses on the first step of this pipeline: these map extraction methods infer road networks from scratch given geospatial data sources (in effect creating entirely new maps), but do not address the second step of leveraging this extracted information to update the existing digital map data. In this paper, we first explain why current map extraction techniques yield low accuracy when extended to update existing maps. We then propose a novel method that leverages the progression of satellite imagery over time to substantially improve accuracy. Our approach first compares satellite images captured at different times to identify portions of the physical road network that have visibly changed, and then updates the existing map accordingly. We show that our change-based approach reduces map update error rates four-fold.
Informational Design of Dynamic Multi-Agent System
May 07, 2021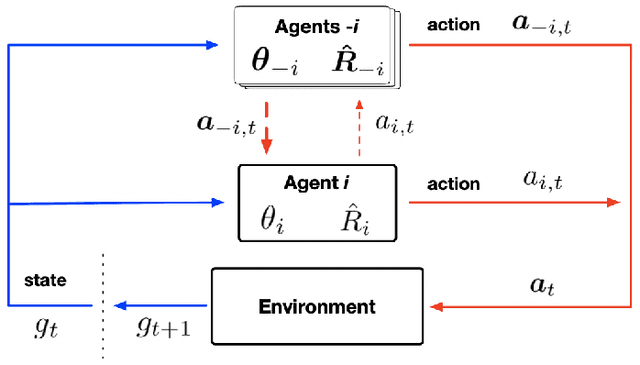
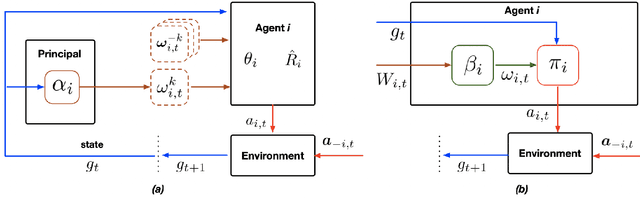
This work considers a novel information design problem and studies how the craft of payoff-relevant environmental signals solely can influence the behaviors of intelligent agents. The agents' strategic interactions are captured by an incomplete-information Markov game, in which each agent first selects one environmental signal from multiple signal sources as additional payoff-relevant information and then takes an action. There is a rational information designer (principal) who possesses one signal source and aims to control the equilibrium behaviors of the agents by designing the information structure of her signals sent to the agents. An obedient principle is established which states that it is without loss of generality to focus on the direct information design when the information design incentivizes each agent to select the signal sent by the principal, such that the design process avoids the predictions of the agents' strategic selection behaviors. Based on the obedient principle, we introduce the design protocol given a goal of the principal referred to as obedient implementability (OIL) and study a Myersonian information design that characterizes the OIL in a class of obedient sequential Markov perfect Bayesian equilibria (O-SMPBE). A framework is proposed based on an approach which we refer to as the fixed-point alignment that incentivizes the agents to choose the signal sent by the principal, makes sure that the agents' policy profile of taking actions is the policy component of an O-SMPBE, and the principal's goal is achieved. The proposed approach can be applied to elicit desired behaviors of multi-agent systems in competing as well as cooperating settings and be extended to heterogeneous stochastic games in the complete- and the incomplete-information environments.
Harnessing the Conditioning Sensorium for Improved Image Translation
Oct 13, 2021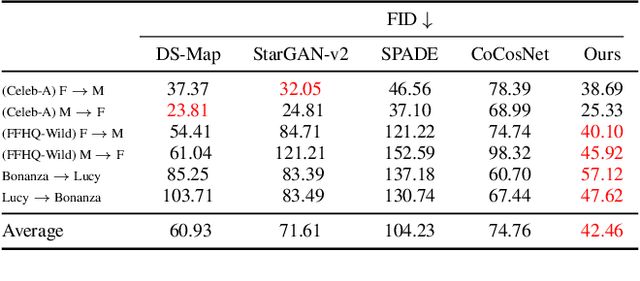
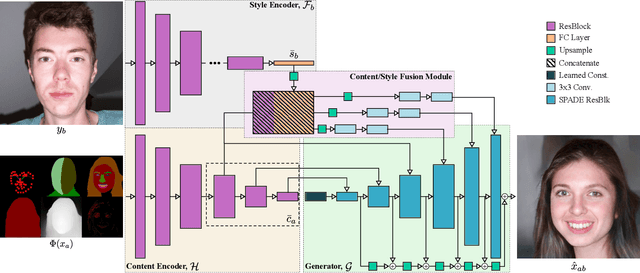


Multi-modal domain translation typically refers to synthesizing a novel image that inherits certain localized attributes from a 'content' image (e.g. layout, semantics, or geometry), and inherits everything else (e.g. texture, lighting, sometimes even semantics) from a 'style' image. The dominant approach to this task is attempting to learn disentangled 'content' and 'style' representations from scratch. However, this is not only challenging, but ill-posed, as what users wish to preserve during translation varies depending on their goals. Motivated by this inherent ambiguity, we define 'content' based on conditioning information extracted by off-the-shelf pre-trained models. We then train our style extractor and image decoder with an easy to optimize set of reconstruction objectives. The wide variety of high-quality pre-trained models available and simple training procedure makes our approach straightforward to apply across numerous domains and definitions of 'content'. Additionally it offers intuitive control over which aspects of 'content' are preserved across domains. We evaluate our method on traditional, well-aligned, datasets such as CelebA-HQ, and propose two novel datasets for evaluation on more complex scenes: ClassicTV and FFHQ-Wild. Our approach, Sensorium, enables higher quality domain translation for more complex scenes.
Leveraging MoCap Data for Human Mesh Recovery
Oct 18, 2021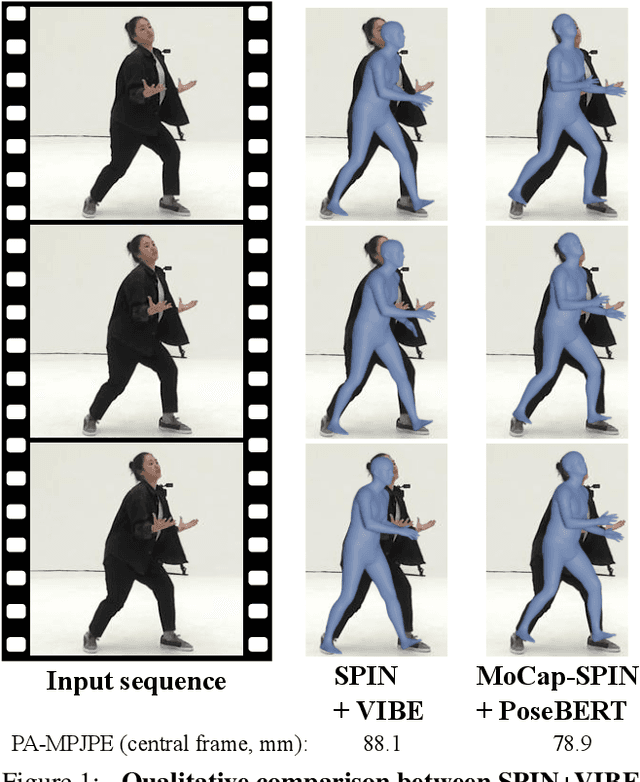
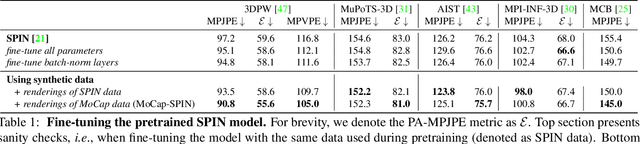


Training state-of-the-art models for human body pose and shape recovery from images or videos requires datasets with corresponding annotations that are really hard and expensive to obtain. Our goal in this paper is to study whether poses from 3D Motion Capture (MoCap) data can be used to improve image-based and video-based human mesh recovery methods. We find that fine-tune image-based models with synthetic renderings from MoCap data can increase their performance, by providing them with a wider variety of poses, textures and backgrounds. In fact, we show that simply fine-tuning the batch normalization layers of the model is enough to achieve large gains. We further study the use of MoCap data for video, and introduce PoseBERT, a transformer module that directly regresses the pose parameters and is trained via masked modeling. It is simple, generic and can be plugged on top of any state-of-the-art image-based model in order to transform it in a video-based model leveraging temporal information. Our experimental results show that the proposed approaches reach state-of-the-art performance on various datasets including 3DPW, MPI-INF-3DHP, MuPoTS-3D, MCB and AIST. Test code and models will be available soon.