 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient Medical Image Segmentation Based on Knowledge Distillation
Aug 23, 2021
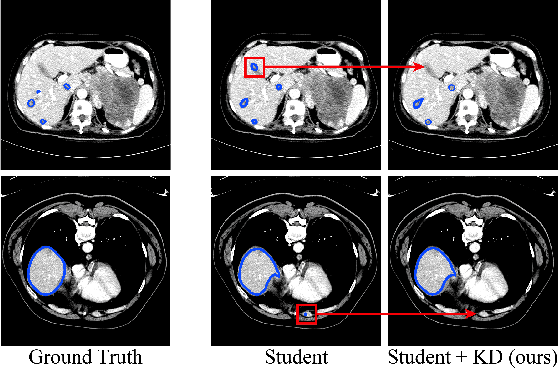
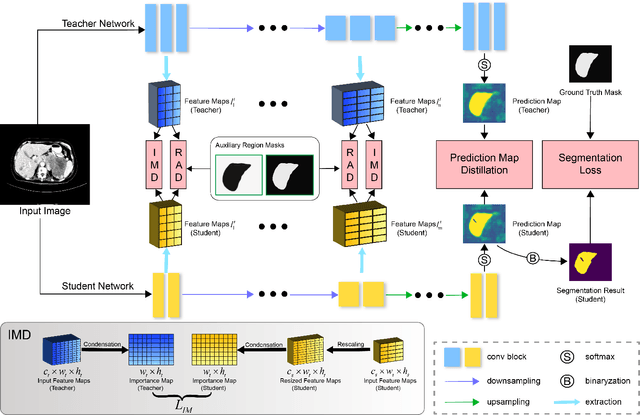
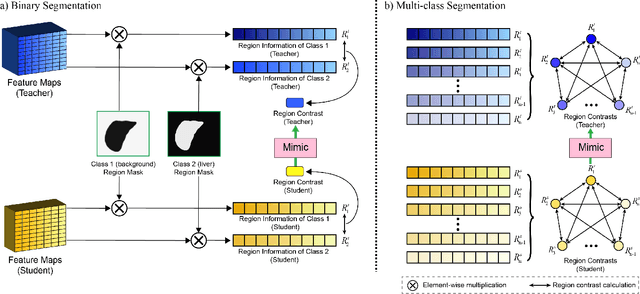
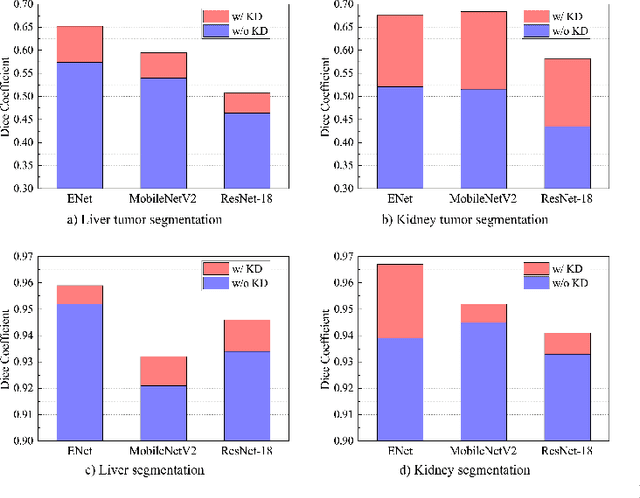
Recent advances have been made in applying convolutional neural networks to achieve more precise prediction results for medical image segmentation problems. However, the success of existing methods has highly relied on huge computational complexity and massive storage, which is impractical in the real-world scenario. To deal with this problem, we propose an efficient architecture by distilling knowledge from well-trained medical image segmentation networks to train another lightweight network. This architecture empowers the lightweight network to get a significant improvement on segmentation capability while retaining its runtime efficiency. We further devise a novel distillation module tailored for medical image segmentation to transfer semantic region information from teacher to student network. It forces the student network to mimic the extent of difference of representations calculated from different tissue regions. This module avoids the ambiguous boundary problem encountered when dealing with medical imaging but instead encodes the internal information of each semantic region for transferring. Benefited from our module, the lightweight network could receive an improvement of up to 32.6% in our experiment while maintaining its portability in the inference phase. The entire structure has been verified on two widely accepted public CT datasets LiTS17 and KiTS19. We demonstrate that a lightweight network distilled by our method has non-negligible value in the scenario which requires relatively high operating speed and low storage usage.
Data-driven and Automatic Surface Texture Analysis Using Persistent Homology
Oct 19, 2021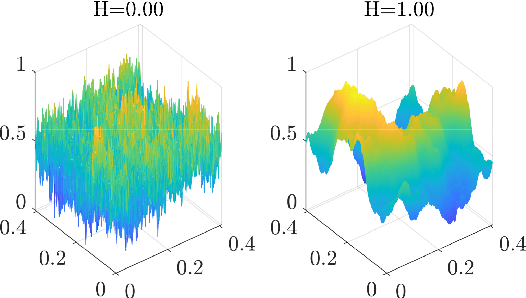
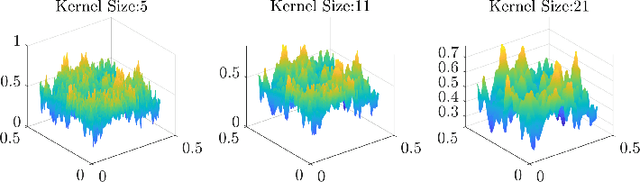
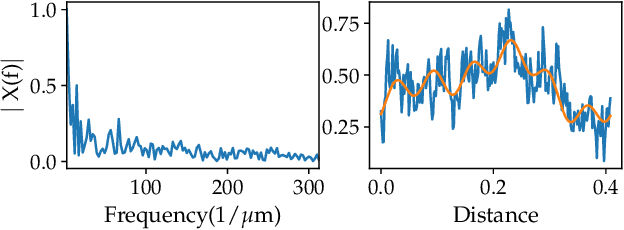
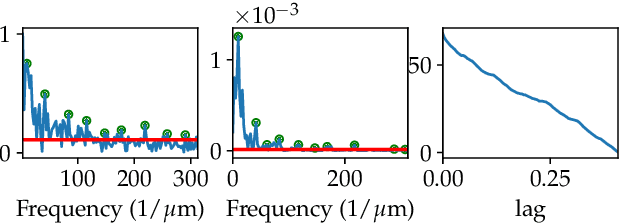
Surface roughness plays an important role in analyzing engineering surfaces. It quantifies the surface topography and can be used to determine whether the resulting surface finish is acceptable or not. Nevertheless, while several existing tools and standards are available for computing surface roughness, these methods rely heavily on user input thus slowing down the analysis and increasing manufacturing costs. Therefore, fast and automatic determination of the roughness level is essential to avoid costs resulting from surfaces with unacceptable finish, and user-intensive analysis. In this study, we propose a Topological Data Analysis (TDA) based approach to classify the roughness level of synthetic surfaces using both their areal images and profiles. We utilize persistent homology from TDA to generate persistence diagrams that encapsulate information on the shape of the surface. We then obtain feature matrices for each surface or profile using Carlsson coordinates, persistence images, and template functions. We compare our results to two widely used methods in the literature: Fast Fourier Transform (FFT) and Gaussian filtering. The results show that our approach yields mean accuracies as high as 97%. We also show that, in contrast to existing surface analysis tools, our TDA-based approach is fully automatable and provides adaptive feature extraction.
Topologically-Informed Atlas Learning
Oct 01, 2021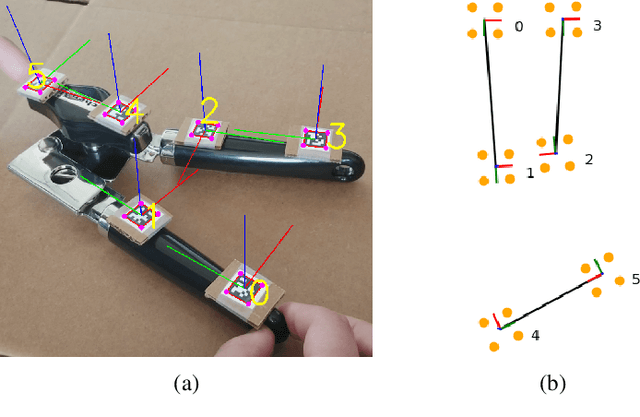


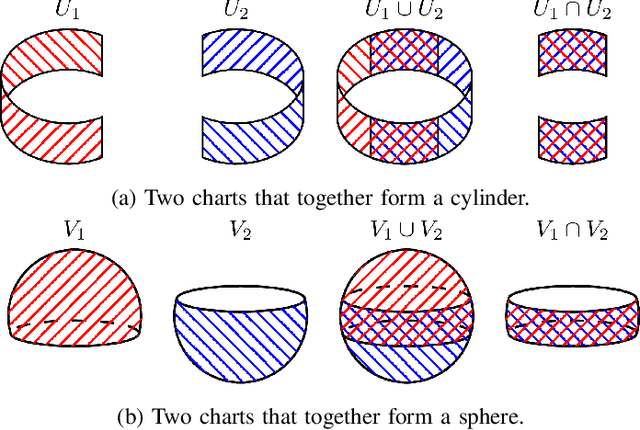
We present a new technique that enables manifold learning to accurately embed data manifolds that contain holes, without discarding any topological information. Manifold learning aims to embed high dimensional data into a lower dimensional Euclidean space by learning a coordinate chart, but it requires that the entire manifold can be embedded in a single chart. This is impossible for manifolds with holes. In such cases, it is necessary to learn an atlas: a collection of charts that collectively cover the entire manifold. We begin with many small charts, and combine them in a bottom-up approach, where charts are only combined if doing so will not introduce problematic topological features. When it is no longer possible to combine any charts, each chart is individually embedded with standard manifold learning techniques, completing the construction of the atlas. We show the efficacy of our method by constructing atlases for challenging synthetic manifolds; learning human motion embeddings from motion capture data; and learning kinematic models of articulated objects.
Do Language Models Know the Way to Rome?
Sep 16, 2021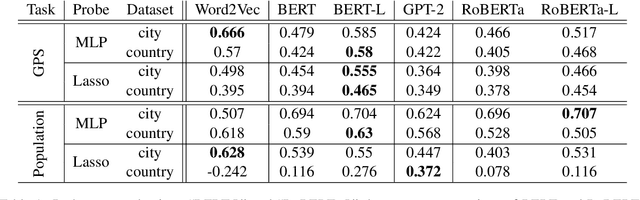
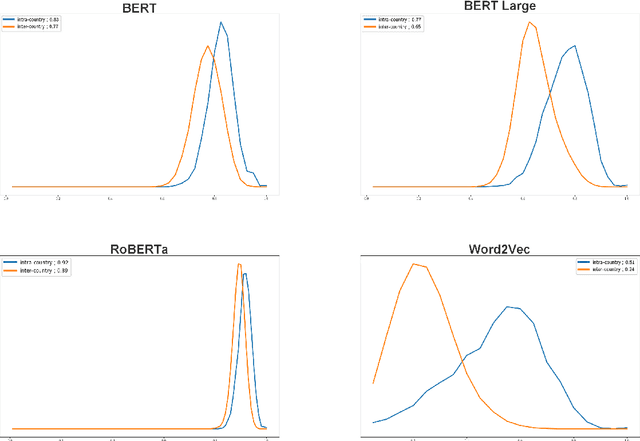
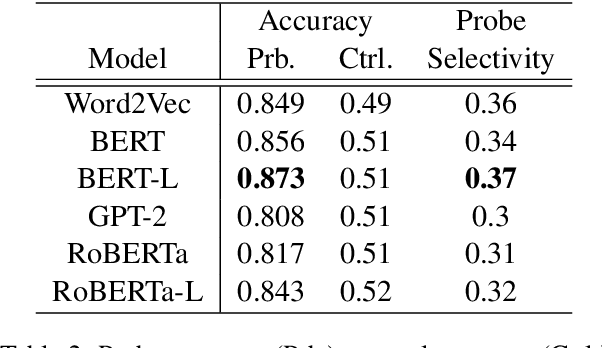
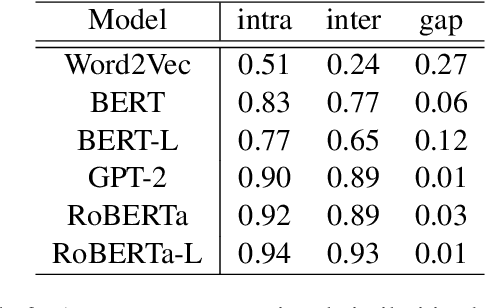
The global geometry of language models is important for a range of applications, but language model probes tend to evaluate rather local relations, for which ground truths are easily obtained. In this paper we exploit the fact that in geography, ground truths are available beyond local relations. In a series of experiments, we evaluate the extent to which language model representations of city and country names are isomorphic to real-world geography, e.g., if you tell a language model where Paris and Berlin are, does it know the way to Rome? We find that language models generally encode limited geographic information, but with larger models performing the best, suggesting that geographic knowledge can be induced from higher-order co-occurrence statistics.
Feature Fusion Vision Transformer Fine-Grained Visual Categorization
Jul 06, 2021
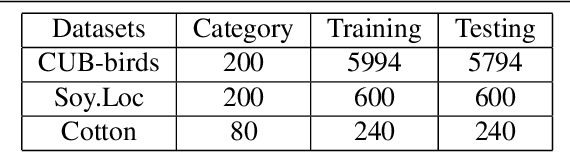
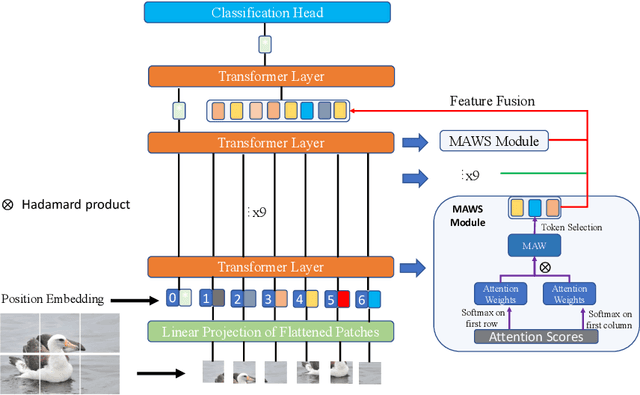
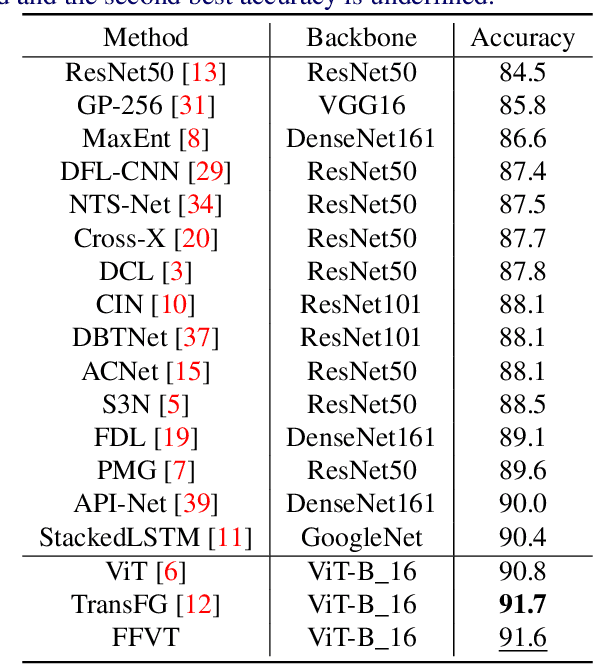
The core for tackling the fine-grained visual categorization (FGVC) is to learn subtleyet discriminative features. Most previous works achieve this by explicitly selecting thediscriminative parts or integrating the attention mechanism via CNN-based approaches.However, these methods enhance the computational complexity and make the modeldominated by the regions containing the most of the objects. Recently, vision trans-former (ViT) has achieved SOTA performance on general image recognition tasks. Theself-attention mechanism aggregates and weights the information from all patches to theclassification token, making it perfectly suitable for FGVC. Nonetheless, the classifi-cation token in the deep layer pays more attention to the global information, lackingthe local and low-level features that are essential for FGVC. In this work, we proposea novel pure transformer-based framework Feature Fusion Vision Transformer (FFVT)where we aggregate the important tokens from each transformer layer to compensate thelocal, low-level and middle-level information. We design a novel token selection mod-ule called mutual attention weight selection (MAWS) to guide the network effectivelyand efficiently towards selecting discriminative tokens without introducing extra param-eters. We verify the effectiveness of FFVT on three benchmarks where FFVT achievesthe state-of-the-art performance.
Recommending POIs for Tourists by User Behavior Modeling and Pseudo-Rating
Oct 14, 2021
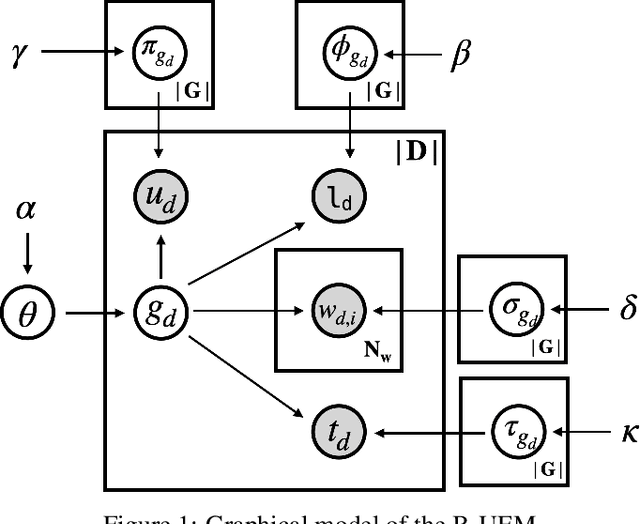
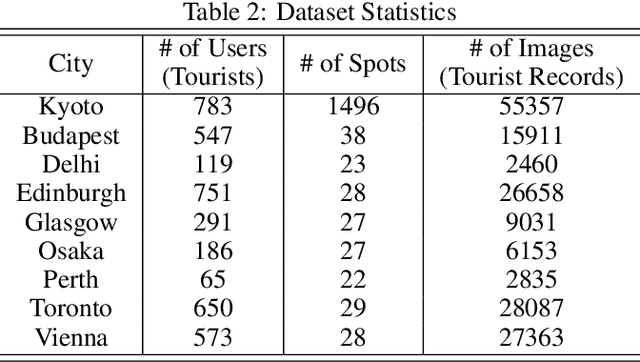
POI recommendation is a key task in tourism information systems. However, in contrast to conventional point of interest (POI) recommender systems, the available data is extremely sparse; most tourist visit a few sightseeing spots once and most of these spots have no check-in data from new tourists. Most conventional systems rank sightseeing spots based on their popularity, reputations, and category-based similarities with users' preferences. They do not clarify what users can experience in these spots, which makes it difficult to meet diverse tourism needs. To this end, in this work, we propose a mechanism to recommend POIs to tourists. Our mechanism include two components: one is a probabilistic model that reveals the user behaviors in tourism; the other is a pseudo rating mechanism to handle the cold-start issue in POIs recommendations. We carried out extensive experiments with two datasets collected from Flickr. The experimental results demonstrate that our methods are superior to the state-of-the-art methods in both the recommendation performances (precision, recall and F-measure) and fairness. The experimental results also validate the robustness of the proposed methods, i.e., our methods can handle well the issue of data sparsity.
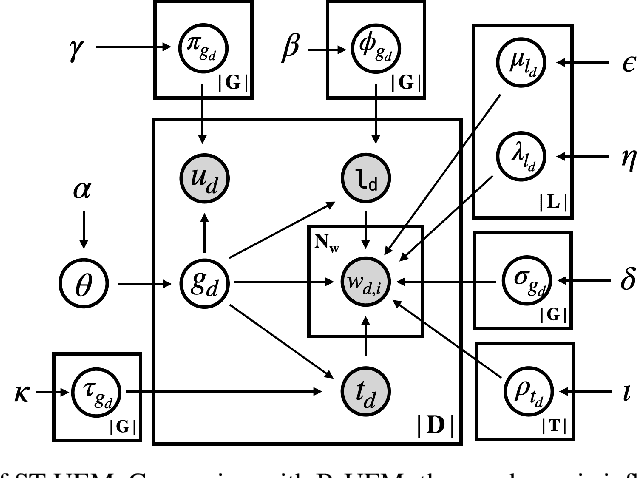
MOON: Multi-Hash Codes Joint Learning for Cross-Media Retrieval
Aug 17, 2021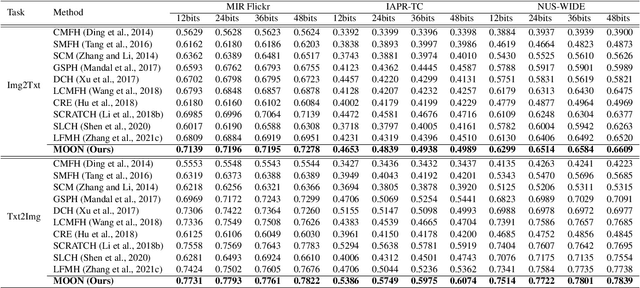
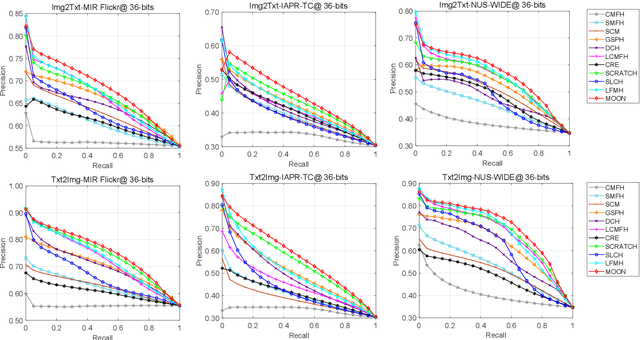
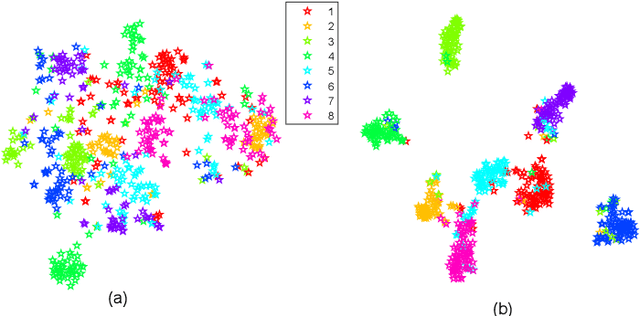
In recent years, cross-media hashing technique has attracted increasing attention for its high computation efficiency and low storage cost. However, the existing approaches still have some limitations, which need to be explored. 1) A fixed hash length (e.g., 16bits or 32bits) is predefined before learning the binary codes. Therefore, these models need to be retrained when the hash length changes, that consumes additional computation power, reducing the scalability in practical applications. 2) Existing cross-modal approaches only explore the information in the original multimedia data to perform the hash learning, without exploiting the semantic information contained in the learned hash codes. To this end, we develop a novel Multiple hash cOdes jOint learNing method (MOON) for cross-media retrieval. Specifically, the developed MOON synchronously learns the hash codes with multiple lengths in a unified framework. Besides, to enhance the underlying discrimination, we combine the clues from the multimodal data, semantic labels and learned hash codes for hash learning. As far as we know, the proposed MOON is the first work to simultaneously learn different length hash codes without retraining in cross-media retrieval. Experiments on several databases show that our MOON can achieve promising performance, outperforming some recent competitive shallow and deep methods.
Correlated Stochastic Block Models: Exact Graph Matching with Applications to Recovering Communities
Jul 14, 2021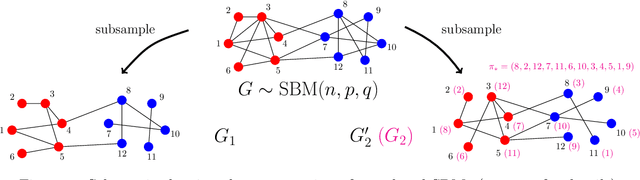
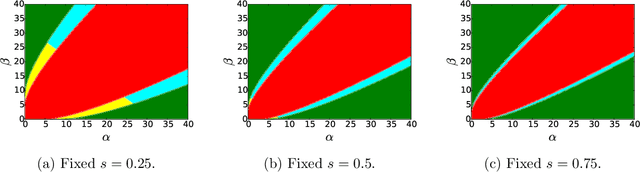
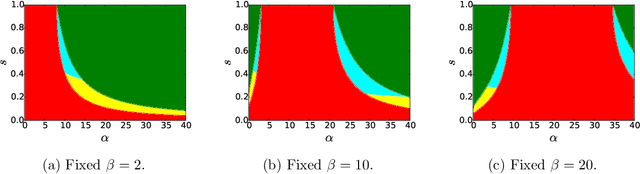
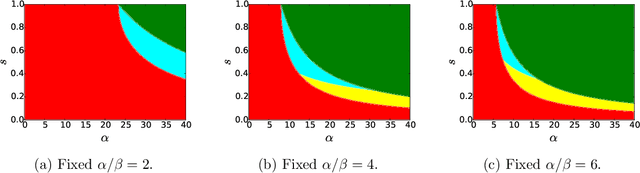
We consider the task of learning latent community structure from multiple correlated networks. First, we study the problem of learning the latent vertex correspondence between two edge-correlated stochastic block models, focusing on the regime where the average degree is logarithmic in the number of vertices. We derive the precise information-theoretic threshold for exact recovery: above the threshold there exists an estimator that outputs the true correspondence with probability close to 1, while below it no estimator can recover the true correspondence with probability bounded away from 0. As an application of our results, we show how one can exactly recover the latent communities using multiple correlated graphs in parameter regimes where it is information-theoretically impossible to do so using just a single graph.
A/B/n Testing with Control in the Presence of Subpopulations
Oct 29, 2021
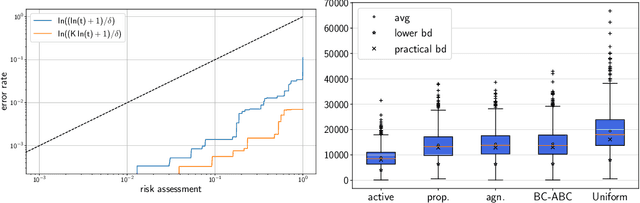
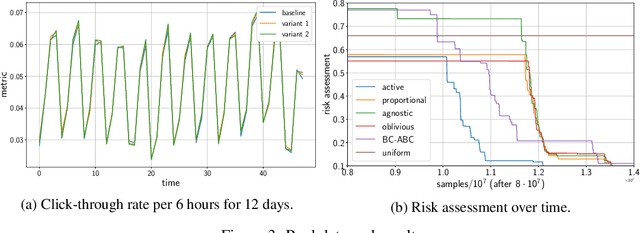

Motivated by A/B/n testing applications, we consider a finite set of distributions (called \emph{arms}), one of which is treated as a \emph{control}. We assume that the population is stratified into homogeneous subpopulations. At every time step, a subpopulation is sampled and an arm is chosen: the resulting observation is an independent draw from the arm conditioned on the subpopulation. The quality of each arm is assessed through a weighted combination of its subpopulation means. We propose a strategy for sequentially choosing one arm per time step so as to discover as fast as possible which arms, if any, have higher weighted expectation than the control. This strategy is shown to be asymptotically optimal in the following sense: if $\tau_\delta$ is the first time when the strategy ensures that it is able to output the correct answer with probability at least $1-\delta$, then $\mathbb{E}[\tau_\delta]$ grows linearly with $\log(1/\delta)$ at the exact optimal rate. This rate is identified in the paper in three different settings: (1) when the experimenter does not observe the subpopulation information, (2) when the subpopulation of each sample is observed but not chosen, and (3) when the experimenter can select the subpopulation from which each response is sampled. We illustrate the efficiency of the proposed strategy with numerical simulations on synthetic and real data collected from an A/B/n experiment.
Sarcasm Detection in Twitter -- Performance Impact when using Data Augmentation: Word Embeddings
Aug 23, 2021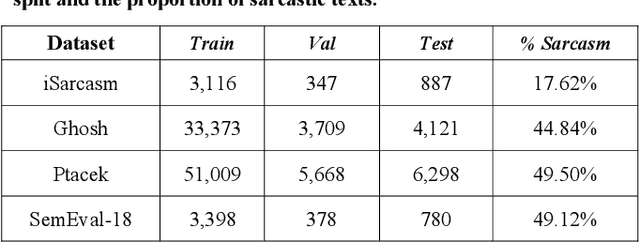
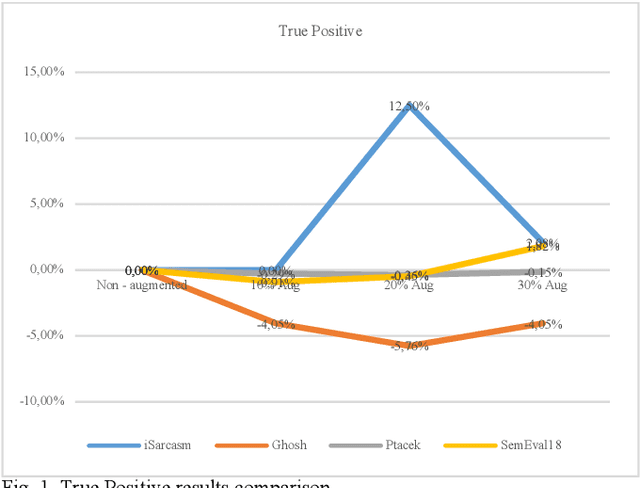
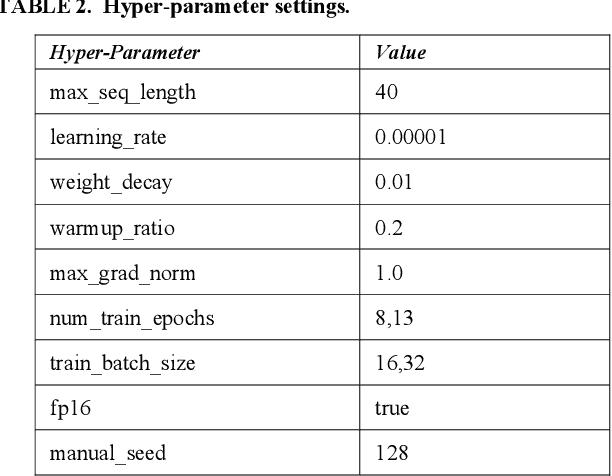
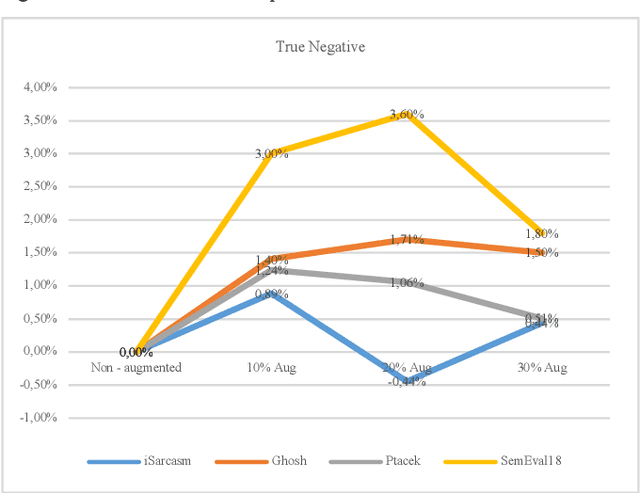
Sarcasm is the use of words usually used to either mock or annoy someone, or for humorous purposes. Sarcasm is largely used in social networks and microblogging websites, where people mock or censure in a way that makes it difficult even for humans to tell if what is said is what is meant. Failure to identify sarcastic utterances in Natural Language Processing applications such as sentiment analysis and opinion mining will confuse classification algorithms and generate false results. Several studies on sarcasm detection have utilized different learning algorithms. However, most of these learning models have always focused on the contents of expression only, leaving the contextual information in isolation. As a result, they failed to capture the contextual information in the sarcastic expression. Moreover, some datasets used in several studies have an unbalanced dataset which impacting the model result. In this paper, we propose a contextual model for sarcasm identification in twitter using RoBERTa, and augmenting the dataset by applying Global Vector representation (GloVe) for the construction of word embedding and context learning to generate more data and balancing the dataset. The effectiveness of this technique is tested with various datasets and data augmentation settings. In particular, we achieve performance gain by 3.2% in the iSarcasm dataset when using data augmentation to increase 20% of data labeled as sarcastic, resulting F-score of 40.4% compared to 37.2% without data augmentation.