 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
iCallee: Recovering Call Graphs for Binaries
Nov 03, 2021
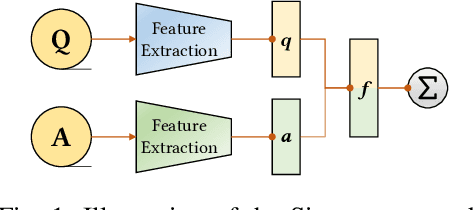
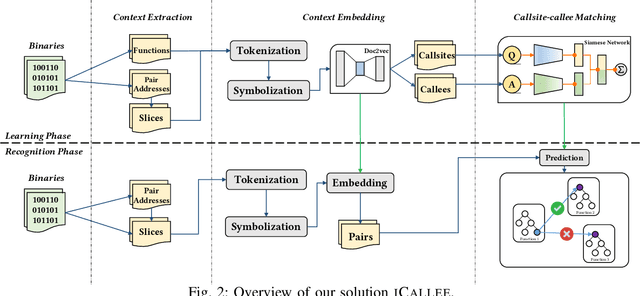
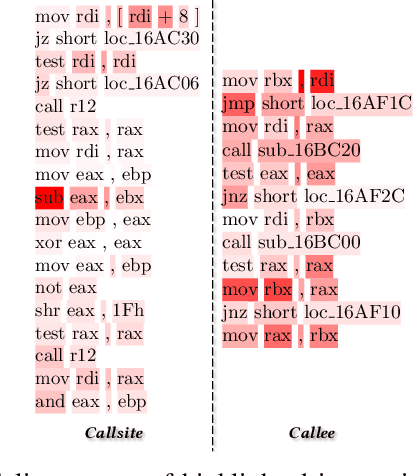
Recovering programs' call graphs is crucial for inter-procedural analysis tasks and applications based on them. The core challenge is recognizing targets of indirect calls (i.e., indirect callees). It becomes more challenging if target programs are in binary forms, due to information loss in binaries. Existing indirect callee recognition solutions for binaries all have high false positives and negatives, making call graphs inaccurate. In this paper, we propose a new solution iCallee based on the Siamese Neural Network, inspired by the advances in question-answering applications. The key insight is that, neural networks can learn to answer whether a callee function is a potential target of an indirect callsite by comprehending their contexts, i.e., instructions nearby callsites and of callees. Following this insight, we first preprocess target binaries to extract contexts of callsites and callees. Then, we build a customized Natural Language Processing (NLP) model applicable to assembly language. Further, we collect abundant pairs of callsites and callees, and embed their contexts with the NLP model, then train a Siamese network and a classifier to answer the callsite-callee question. We have implemented a prototype of iCallee and evaluated it on several groups of targets. Evaluation results showed that, our solution could match callsites to callees with an F1-Measure of 93.7%, recall of 93.8%, and precision of 93.5%, much better than state-of-the-art solutions. To show its usefulness, we apply iCallee to two specific applications - binary code similarity detection and binary program hardening, and found that it could greatly improve state-of-the-art solutions.
MOOCRep: A Unified Pre-trained Embedding of MOOC Entities
Jul 12, 2021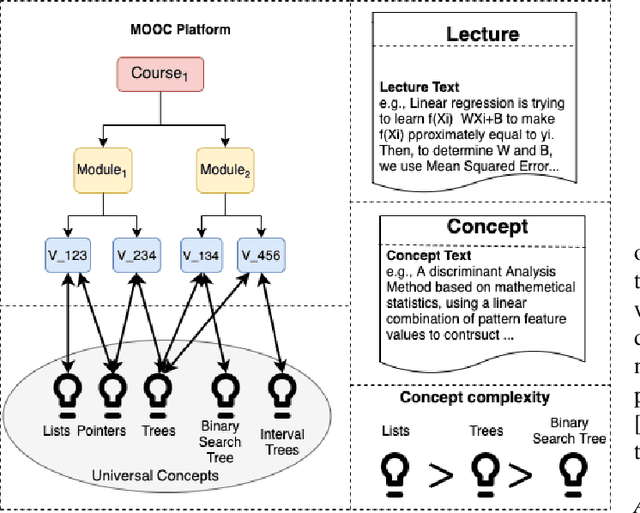
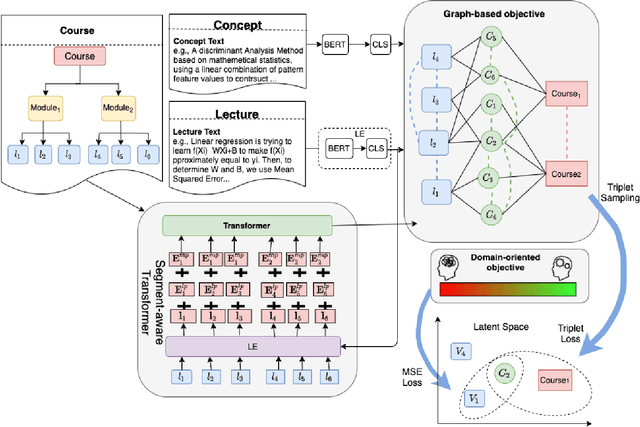
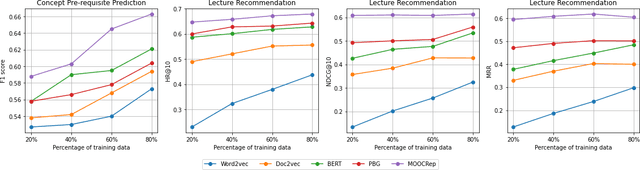

Many machine learning models have been built to tackle information overload issues on Massive Open Online Courses (MOOC) platforms. These models rely on learning powerful representations of MOOC entities. However, they suffer from the problem of scarce expert label data. To overcome this problem, we propose to learn pre-trained representations of MOOC entities using abundant unlabeled data from the structure of MOOCs which can directly be applied to the downstream tasks. While existing pre-training methods have been successful in NLP areas as they learn powerful textual representation, their models do not leverage the richer information about MOOC entities. This richer information includes the graph relationship between the lectures, concepts, and courses along with the domain knowledge about the complexity of a concept. We develop MOOCRep, a novel method based on Transformer language model trained with two pre-training objectives : 1) graph-based objective to capture the powerful signal of entities and relations that exist in the graph, and 2) domain-oriented objective to effectively incorporate the complexity level of concepts. Our experiments reveal that MOOCRep's embeddings outperform state-of-the-art representation learning methods on two tasks important for education community, concept pre-requisite prediction and lecture recommendation.
Deep Transfer Learning for Land Use Land Cover Classification: A Comparative Study
Oct 08, 2021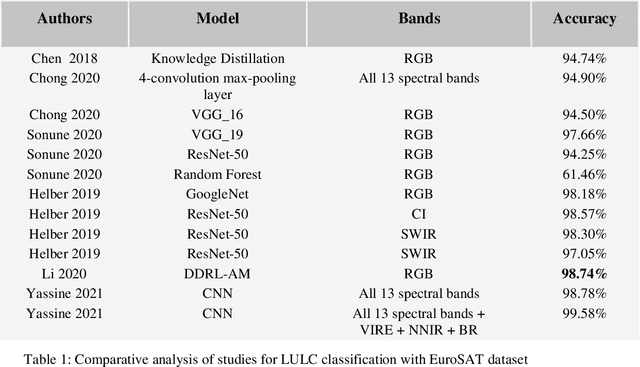
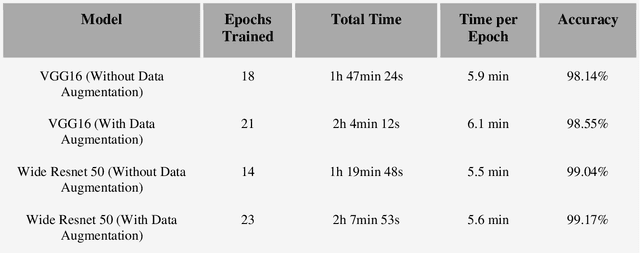
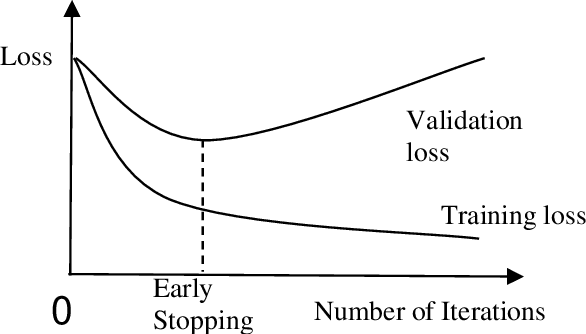
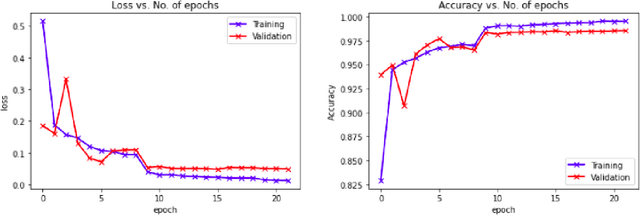
Efficiently implementing remote sensing image classification with high spatial resolution imagery can provide great significant value in land-use land-cover classification (LULC). The developments in remote sensing and deep learning technologies have facilitated the extraction of spatiotemporal information for LULC classification. Moreover, the diverse disciplines of science, including remote sensing, have utilised tremendous improvements in image classification by CNNs with Transfer Learning. In this study, instead of training CNNs from scratch, we make use of transfer learning to fine-tune pre-trained networks a) VGG16 and b) Wide Residual Networks (WRNs), by replacing the final layer with additional layers, for LULC classification with EuroSAT dataset. Further, the performance and computational time were compared and optimized with techniques like early stopping, gradient clipping, adaptive learning rates and data augmentation. With the proposed approaches we were able to address the limited-data problem and achieved very good accuracy. Comprehensive comparisons over the EuroSAT RGB version benchmark have successfully established that our method outperforms the previous best-stated results, with a significant improvement over the accuracy from 98.57% to 99.17%.
KaraSinger: Score-Free Singing Voice Synthesis with VQ-VAE using Mel-spectrograms
Oct 08, 2021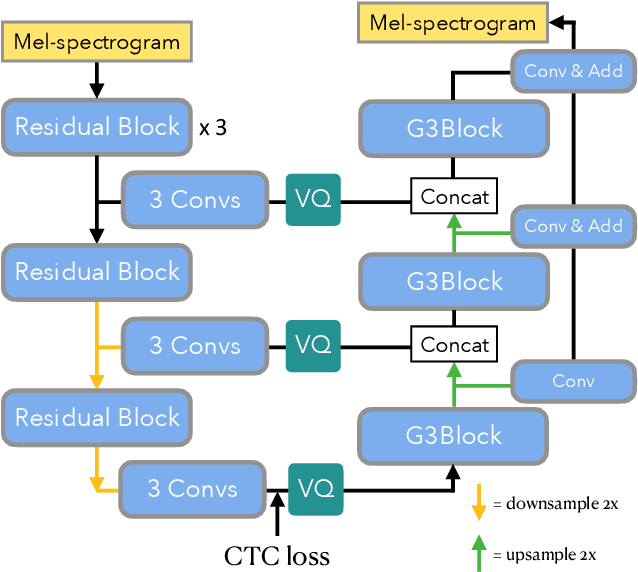
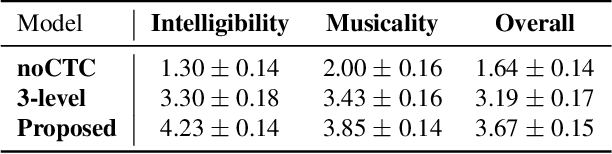
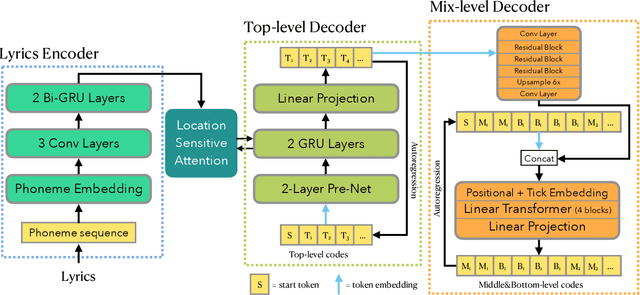

In this paper, we propose a novel neural network model called KaraSinger for a less-studied singing voice synthesis (SVS) task named score-free SVS, in which the prosody and melody are spontaneously decided by machine. KaraSinger comprises a vector-quantized variational autoencoder (VQ-VAE) that compresses the Mel-spectrograms of singing audio to sequences of discrete codes, and a language model (LM) that learns to predict the discrete codes given the corresponding lyrics. For the VQ-VAE part, we employ a Connectionist Temporal Classification (CTC) loss to encourage the discrete codes to carry phoneme-related information. For the LM part, we use location-sensitive attention for learning a robust alignment between the input phoneme sequence and the output discrete code. We keep the architecture of both the VQ-VAE and LM light-weight for fast training and inference speed. We validate the effectiveness of the proposed design choices using a proprietary collection of 550 English pop songs sung by multiple amateur singers. The result of a listening test shows that KaraSinger achieves high scores in intelligibility, musicality, and the overall quality.
Robust Dynamic Bus Control: A Distributional Multi-agent Reinforcement Learning Approach
Nov 02, 2021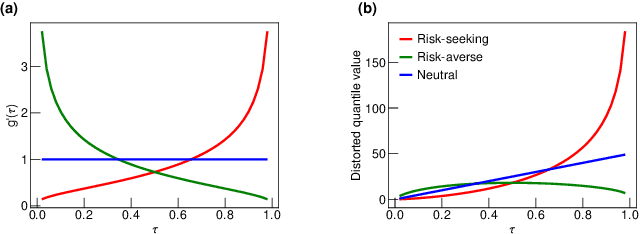
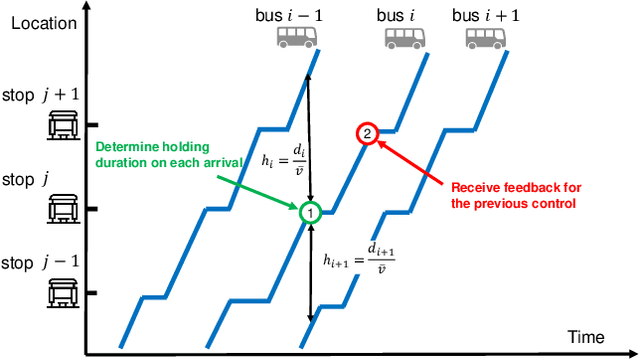
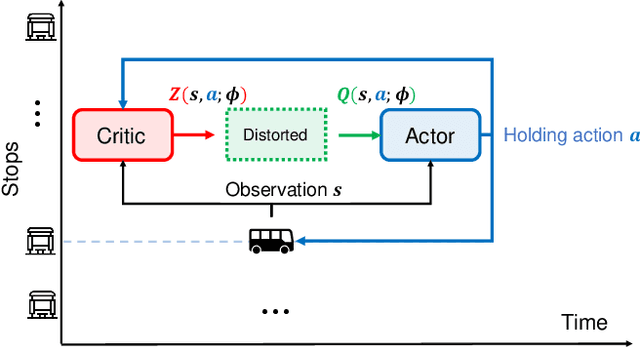
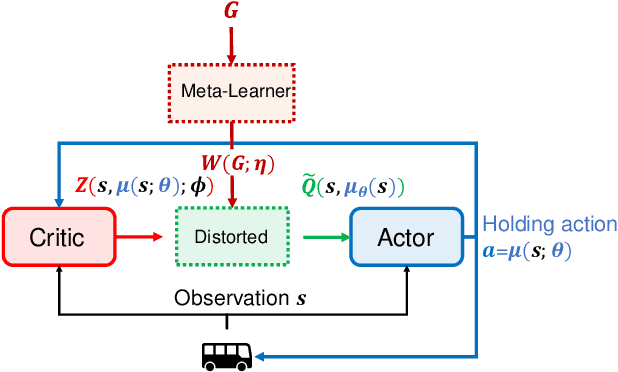
Bus system is a critical component of sustainable urban transportation. However, the operation of a bus fleet is unstable in nature, and bus bunching has become a common phenomenon that undermines the efficiency and reliability of bus systems. Recently research has demonstrated the promising application of multi-agent reinforcement learning (MARL) to achieve efficient vehicle holding control to avoid bus bunching. However, existing studies essentially overlook the robustness issue resulting from various events, perturbations and anomalies in a transit system, which is of utmost importance when transferring the models for real-world deployment/application. In this study, we integrate implicit quantile network and meta-learning to develop a distributional MARL framework -- IQNC-M -- to learn continuous control. The proposed IQNC-M framework achieves efficient and reliable control decisions through better handling various uncertainties/events in real-time transit operations. Specifically, we introduce an interpretable meta-learning module to incorporate global information into the distributional MARL framework, which is an effective solution to circumvent the credit assignment issue in the transit system. In addition, we design a specific learning procedure to train each agent within the framework to pursue a robust control policy. We develop simulation environments based on real-world bus services and passenger demand data and evaluate the proposed framework against both traditional holding control models and state-of-the-art MARL models. Our results show that the proposed IQNC-M framework can effectively handle the various extreme events, such as traffic state perturbations, service interruptions, and demand surges, thus improving both efficiency and reliability of the system.
Optimal Sequential Stochastic Deployment of Multiple Passenger Robots
Oct 19, 2021
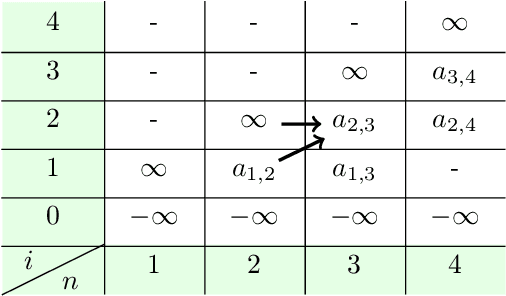
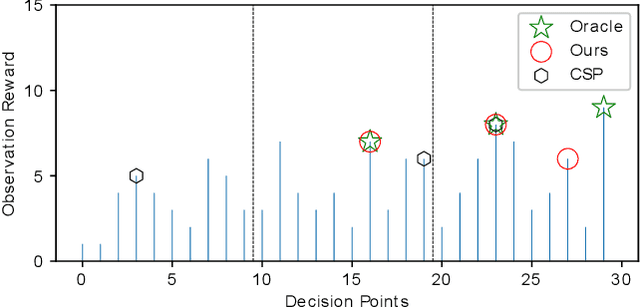
We present a new algorithm for deploying passenger robots in marsupial robot systems. A marsupial robot system consists of a carrier robot (e.g., a ground vehicle), which is highly capable and has a long mission duration, and at least one passenger robot (e.g., a short-duration aerial vehicle) transported by the carrier. We optimize the performance of passenger robot deployment by proposing an algorithm that reasons over uncertainty by exploiting information about the prior probability distribution of features of interest in the environment. Our algorithm is formulated as a solution to a sequential stochastic assignment problem (SSAP). The key feature of the algorithm is a recurrence relationship that defines a set of observation thresholds that are used to decide when to deploy passenger robots. Our algorithm computes the optimal policy in $O(NR)$ time, where $N$ is the number of deployment decision points and $R$ is the number of passenger robots to be deployed. We conducted drone deployment exploration experiments on real-world data from the DARPA Subterranean challenge to test the SSAP algorithm. Our results show that our deployment algorithm outperforms other competing algorithms, such as the classic secretary approach and baseline partitioning methods, and is comparable to an offline oracle algorithm.
Come Again? Re-Query in Referring Expression Comprehension
Oct 19, 2021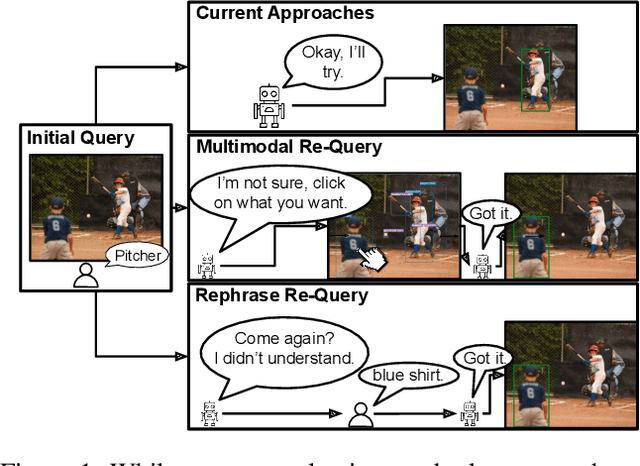
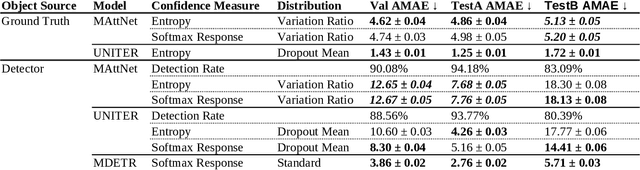


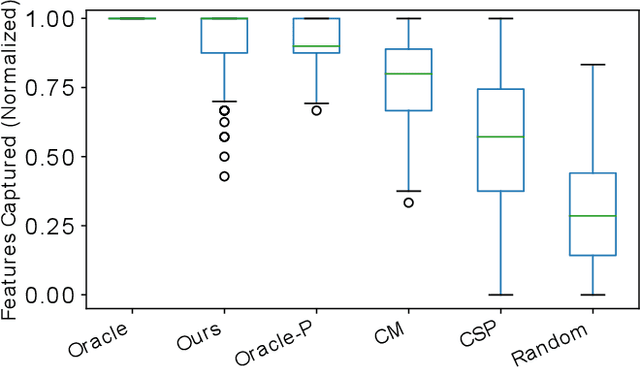
To build a shared perception of the world, humans rely on the ability to resolve misunderstandings by requesting and accepting clarifications. However, when evaluating visiolinguistic models, metrics such as accuracy enforce the assumption that a decision must be made based on a single piece of evidence. In this work, we relax this assumption for the task of referring expression comprehension by allowing the model to request help when its confidence is low. We consider two ways in which this help can be provided: multimodal re-query, where the user is allowed to point or click to provide additional information to the model, and rephrase re-query, where the user is only allowed to provide another referring expression. We demonstrate the importance of re-query by showing that providing the best referring expression for all objects can increase accuracy by up to 21.9% and that this accuracy can be matched by re-querying only 12% of initial referring expressions. We further evaluate re-query functions for both multimodal and rephrase re-query across three modern approaches and demonstrate combined replacement for rephrase re-query, which improves average single-query performance by up to 6.5% and converges to as close as 1.6% of the upper bound of single-query performance.
SGoLAM: Simultaneous Goal Localization and Mapping for Multi-Object Goal Navigation
Oct 14, 2021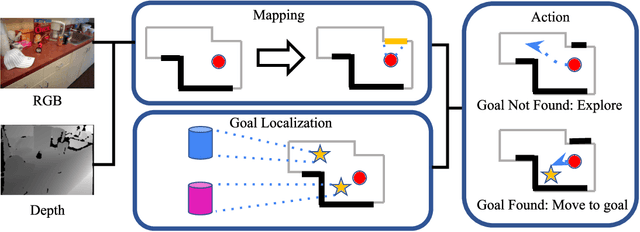
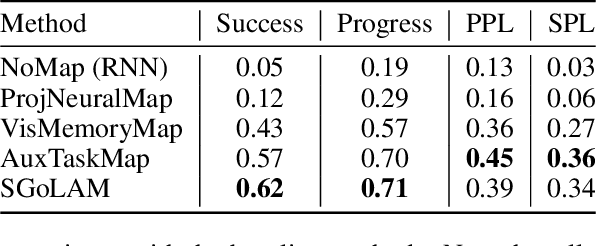
We present SGoLAM, short for simultaneous goal localization and mapping, which is a simple and efficient algorithm for Multi-Object Goal navigation. Given an agent equipped with an RGB-D camera and a GPS/Compass sensor, our objective is to have the agent navigate to a sequence of target objects in realistic 3D environments. Our pipeline fully leverages the strength of classical approaches for visual navigation, by decomposing the problem into two key components: mapping and goal localization. The mapping module converts the depth observations into an occupancy map, and the goal localization module marks the locations of goal objects. The agent's policy is determined using the information provided by the two modules: if a current goal is found, plan towards the goal and otherwise, perform exploration. As our approach does not require any training of neural networks, it could be used in an off-the-shelf manner, and amenable for fast generalization in new, unseen environments. Nonetheless, our approach performs on par with the state-of-the-art learning-based approaches. SGoLAM is ranked 2nd in the CVPR 2021 MultiON (Multi-Object Goal Navigation) challenge. We have made our code publicly available at \emph{https://github.com/eunsunlee/SGoLAM}.
A Visual Technique to Analyze Flow of Information in a Machine Learning System
Aug 02, 2019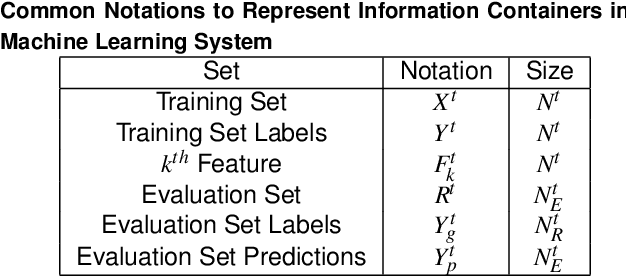

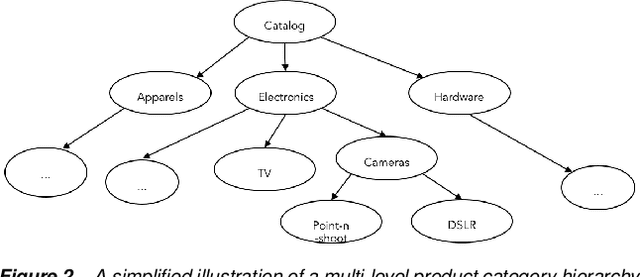
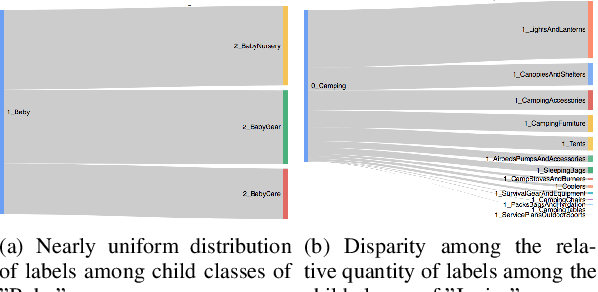
Machine learning (ML) algorithms and machine learning based software systems implicitly or explicitly involve complex flow of information between various entities such as training data, feature space, validation set and results. Understanding the statistical distribution of such information and how they flow from one entity to another influence the operation and correctness of such systems, especially in large-scale applications that perform classification or prediction in real time. In this paper, we propose a visual approach to understand and analyze flow of information during model training and serving phases. We build the visualizations using a technique called Sankey Diagram - conventionally used to understand data flow among sets - to address various use cases of in a machine learning system. We demonstrate how the proposed technique, tweaked and twisted to suit a classification problem, can play a critical role in better understanding of the training data, the features, and the classifier performance. We also discuss how this technique enables diagnostic analysis of model predictions and comparative analysis of predictions from multiple classifiers. The proposed concept is illustrated with the example of categorization of millions of products in the e-commerce domain - a multi-class hierarchical classification problem.
VisBuddy -- A Smart Wearable Assistant for the Visually Challenged
Aug 17, 2021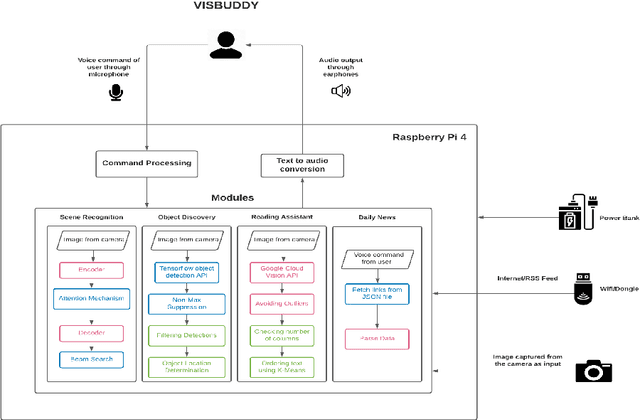


Vision plays a crucial role to comprehend the world around us as more than 85% of the external information is obtained through the vision system. It largely influences our mobility, cognition, information access, and interaction with the environment as well as with other people. Blindness prevents a person from gaining knowledge of the surrounding environment and makes unassisted navigation, object recognition, obstacle avoidance, and reading tasks major challenges. Many existing systems are often limited by cost and complexity. To help the visually challenged overcome these difficulties faced in everyday life, we propose the idea of VisBuddy, a smart assistant which will help the visually challenged with their day-to-day activities. VisBuddy is a voice-based assistant, where the user can give voice commands to perform specific tasks. VisBuddy uses the techniques of image captioning for describing the user's surroundings, optical character recognition (OCR) for reading the text in the user's view, object detection to search and find the objects in a room and web scraping to give the user the latest news. VisBuddy has been built by combining the concepts from Deep Learning and the Internet of Things. Thus, VisBuddy serves as a cost-efficient, powerful and all-in-one assistant for the visually challenged by helping them with their day-to-day activities.