 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contrastive Learning for Cold-Start Recommendation
Jul 12, 2021
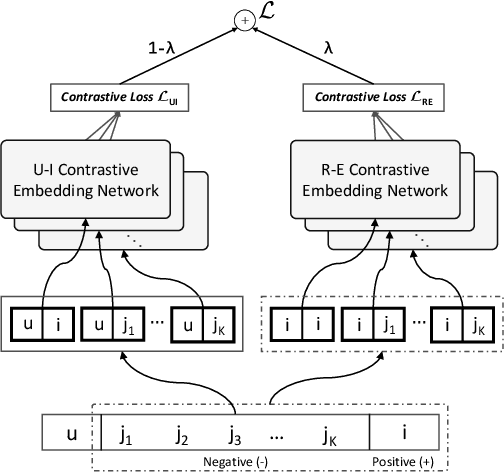
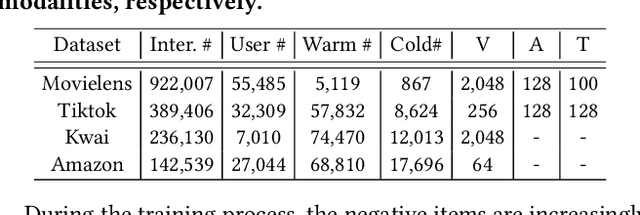
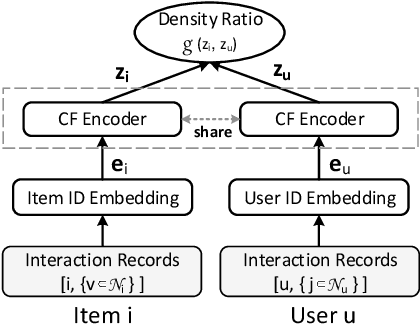
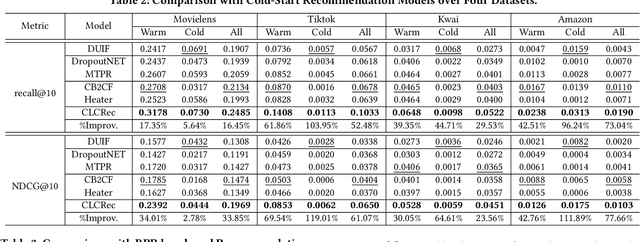
Recommending cold-start items is a long-standing and fundamental challenge in recommender systems. Without any historical interaction on cold-start items, CF scheme fails to use collaborative signals to infer user preference on these items. To solve this problem, extensive studies have been conducted to incorporate side information into the CF scheme. Specifically, they employ modern neural network techniques (e.g., dropout, consistency constraint) to discover and exploit the coalition effect of content features and collaborative representations. However, we argue that these works less explore the mutual dependencies between content features and collaborative representations and lack sufficient theoretical supports, thus resulting in unsatisfactory performance. In this work, we reformulate the cold-start item representation learning from an information-theoretic standpoint. It aims to maximize the mutual dependencies between item content and collaborative signals. Specifically, the representation learning is theoretically lower-bounded by the integration of two terms: mutual information between collaborative embeddings of users and items, and mutual information between collaborative embeddings and feature representations of items. To model such a learning process, we devise a new objective function founded upon contrastive learning and develop a simple yet effective Contrastive Learning-based Cold-start Recommendation framework(CLCRec). In particular, CLCRec consists of three components: contrastive pair organization, contrastive embedding, and contrastive optimization modules. It allows us to preserve collaborative signals in the content representations for both warm and cold-start items. Through extensive experiments on four publicly accessible datasets, we observe that CLCRec achieves significant improvements over state-of-the-art approaches in both warm- and cold-start scenarios.
Machine Learning-Based Soft Sensors for Vacuum Distillation Unit
Nov 19, 2021
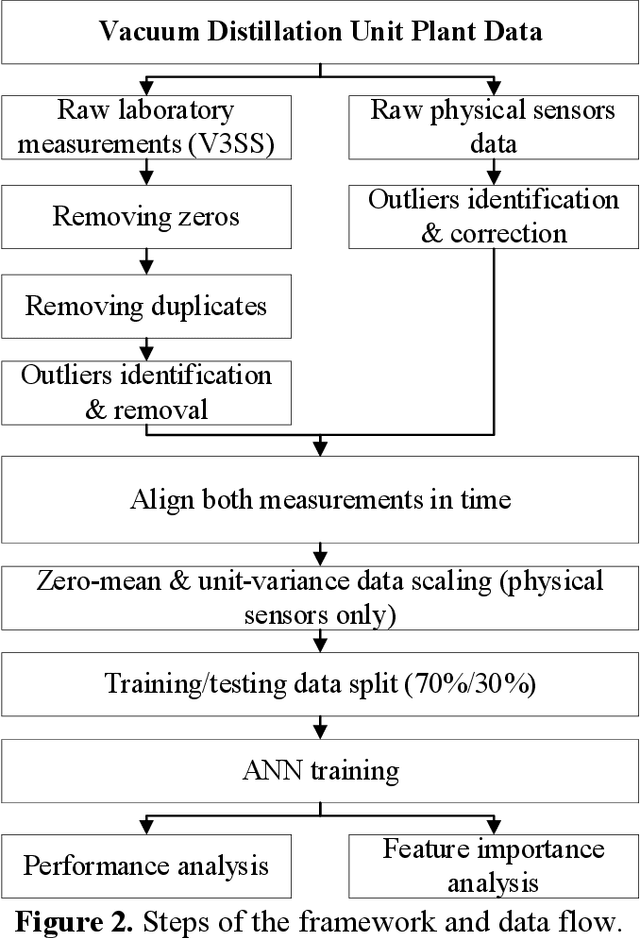
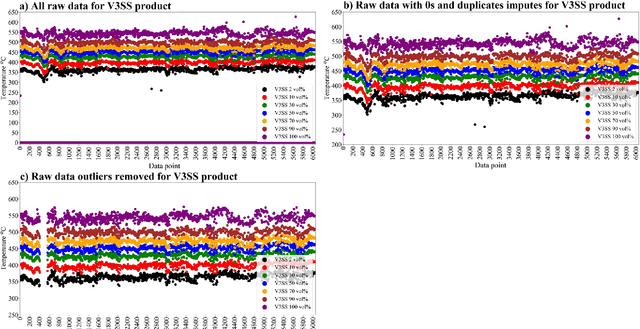
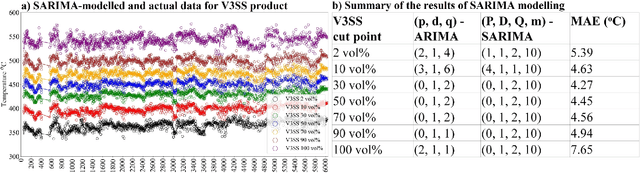
Product quality assessment in the petroleum processing industry can be difficult and time-consuming, e.g. due to a manual collection of liquid samples from the plant and subsequent chemical laboratory analysis of the samples. The product quality is an important property that informs whether the products of the process are within the specifications. In particular, the delays caused by sample processing (collection, laboratory measurements, results analysis, reporting) can lead to detrimental economic effects. One of the strategies to deal with this problem is soft sensors. Soft sensors are a collection of models that can be used to predict and forecast some infrequently measured properties (such as laboratory measurements of petroleum products) based on more frequent measurements of quantities like temperature, pressure and flow rate provided by physical sensors. Soft sensors short-cut the pathway to obtain relevant information about the product quality, often providing measurements as frequently as every minute. One of the applications of soft sensors is for the real-time optimization of a chemical process by a targeted adaptation of operating parameters. Models used for soft sensors can have various forms, however, among the most common are those based on artificial neural networks (ANNs). While soft sensors can deal with some of the issues in the refinery processes, their development and deployment can pose other challenges that are addressed in this paper. Firstly, it is important to enhance the quality of both sets of data (laboratory measurements and physical sensors) in a data pre-processing stage (as described in Methodology section). Secondly, once the data sets are pre-processed, different models need to be tested against prediction error and the model's interpretability. In this work, we present a framework for soft sensor development from raw data to ready-to-use models.
Deep Fraud Detection on Non-attributed Graph
Oct 04, 2021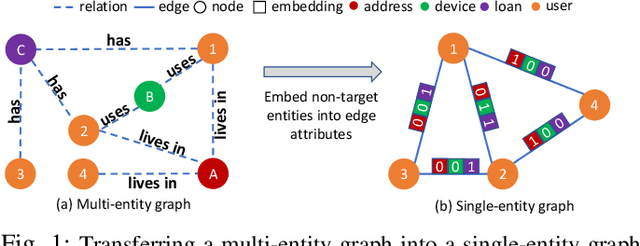
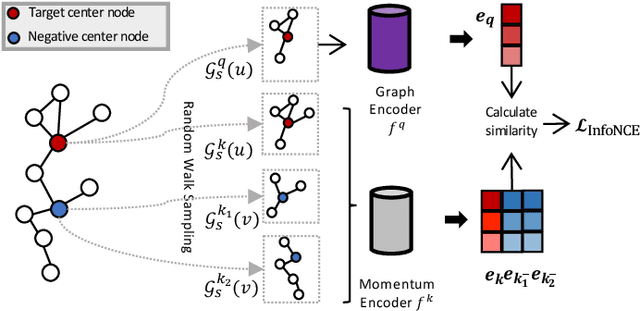
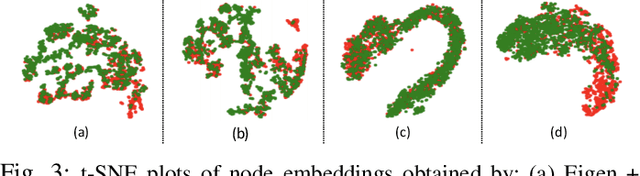

Fraud detection problems are usually formulated as a machine learning problem on a graph. Recently, Graph Neural Networks (GNNs) have shown solid performance on fraud detection. The successes of most previous methods heavily rely on rich node features and high-fidelity labels. However, labeled data is scarce in large-scale industrial problems, especially for fraud detection where new patterns emerge from time to time. Meanwhile, node features are also limited due to privacy and other constraints. In this paper, two improvements are proposed: 1) We design a graph transformation method capturing the structural information to facilitate GNNs on non-attributed fraud graphs. 2) We propose a novel graph pre-training strategy to leverage more unlabeled data via contrastive learning. Experiments on a large-scale industrial dataset demonstrate the effectiveness of the proposed framework for fraud detection.
Omnidata: A Scalable Pipeline for Making Multi-Task Mid-Level Vision Datasets from 3D Scans
Oct 11, 2021
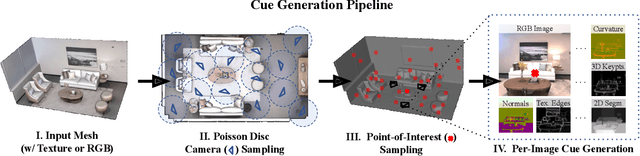
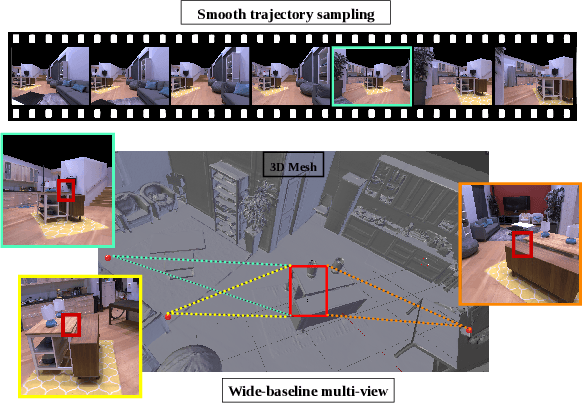
This paper introduces a pipeline to parametrically sample and render multi-task vision datasets from comprehensive 3D scans from the real world. Changing the sampling parameters allows one to "steer" the generated datasets to emphasize specific information. In addition to enabling interesting lines of research, we show the tooling and generated data suffice to train robust vision models. Common architectures trained on a generated starter dataset reached state-of-the-art performance on multiple common vision tasks and benchmarks, despite having seen no benchmark or non-pipeline data. The depth estimation network outperforms MiDaS and the surface normal estimation network is the first to achieve human-level performance for in-the-wild surface normal estimation -- at least according to one metric on the OASIS benchmark. The Dockerized pipeline with CLI, the (mostly python) code, PyTorch dataloaders for the generated data, the generated starter dataset, download scripts and other utilities are available through our project website, https://omnidata.vision.
Using Keypoint Matching and Interactive Self Attention Network to verify Retail POSMs
Oct 07, 2021
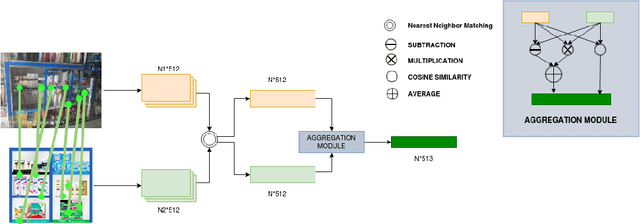
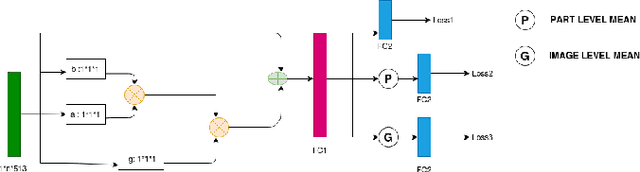
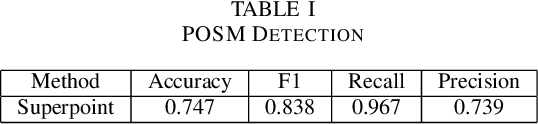
Point of Sale Materials(POSM) are the merchandising and decoration items that are used by companies to communicate product information and offers in retail stores. POSMs are part of companies' retail marketing strategy and are often applied as stylized window displays around retail shelves. In this work, we apply computer vision techniques to the task of verification of POSMs in supermarkets by telling if all desired components of window display are present in a shelf image. We use Convolutional Neural Network based unsupervised keypoint matching as a baseline to verify POSM components and propose a supervised Neural Network based method to enhance the accuracy of baseline by a large margin. We also show that the supervised pipeline is not restricted to the POSM material it is trained on and can generalize. We train and evaluate our model on a private dataset composed of retail shelf images.
Hierarchical Summarization for Longform Spoken Dialog
Aug 21, 2021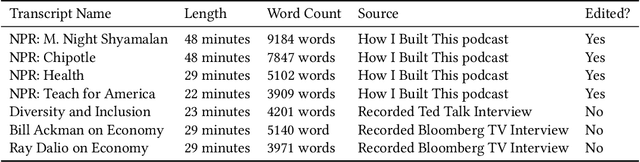
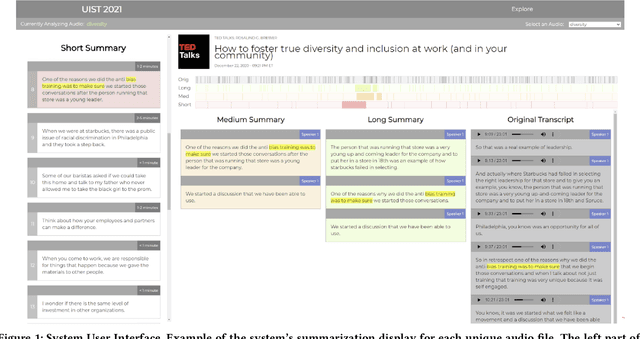

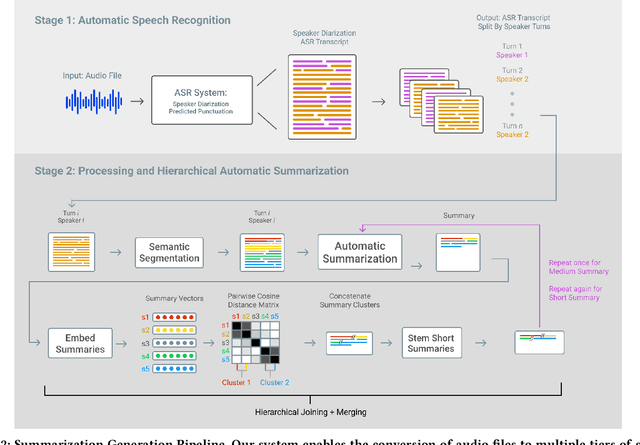
Every day we are surrounded by spoken dialog. This medium delivers rich diverse streams of information auditorily; however, systematically understanding dialog can often be non-trivial. Despite the pervasiveness of spoken dialog, automated speech understanding and quality information extraction remains markedly poor, especially when compared to written prose. Furthermore, compared to understanding text, auditory communication poses many additional challenges such as speaker disfluencies, informal prose styles, and lack of structure. These concerns all demonstrate the need for a distinctly speech tailored interactive system to help users understand and navigate the spoken language domain. While individual automatic speech recognition (ASR) and text summarization methods already exist, they are imperfect technologies; neither consider user purpose and intent nor address spoken language induced complications. Consequently, we design a two stage ASR and text summarization pipeline and propose a set of semantic segmentation and merging algorithms to resolve these speech modeling challenges. Our system enables users to easily browse and navigate content as well as recover from errors in these underlying technologies. Finally, we present an evaluation of the system which highlights user preference for hierarchical summarization as a tool to quickly skim audio and identify content of interest to the user.
Fractal Pyramid Networks
Jun 28, 2021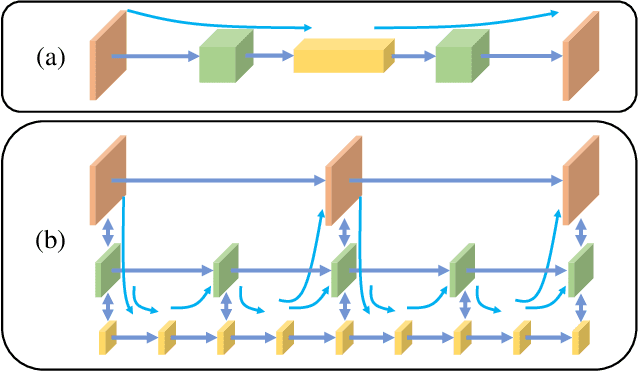
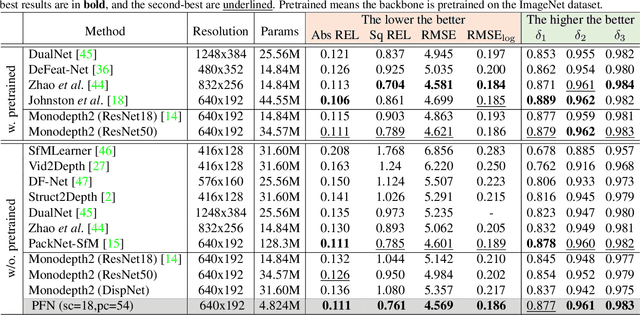
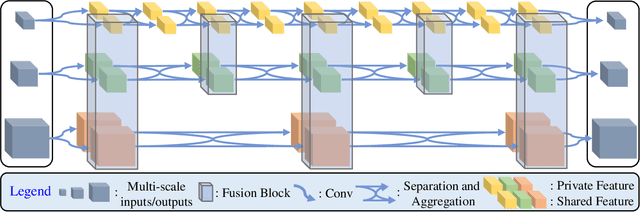
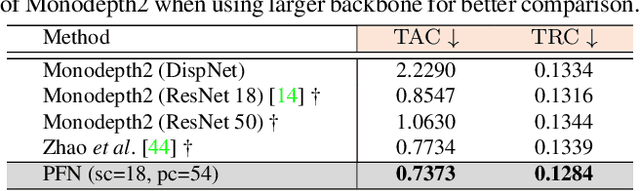
We propose a new network architecture, the Fractal Pyramid Networks (PFNs) for pixel-wise prediction tasks as an alternative to the widely used encoder-decoder structure. In the encoder-decoder structure, the input is processed by an encoding-decoding pipeline that tries to get a semantic large-channel feature. Different from that, our proposed PFNs hold multiple information processing pathways and encode the information to multiple separate small-channel features. On the task of self-supervised monocular depth estimation, even without ImageNet pretrained, our models can compete or outperform the state-of-the-art methods on the KITTI dataset with much fewer parameters. Moreover, the visual quality of the prediction is significantly improved. The experiment of semantic segmentation provides evidence that the PFNs can be applied to other pixel-wise prediction tasks, and demonstrates that our models can catch more global structure information.
RPT++: Customized Feature Representation for Siamese Visual Tracking
Oct 23, 2021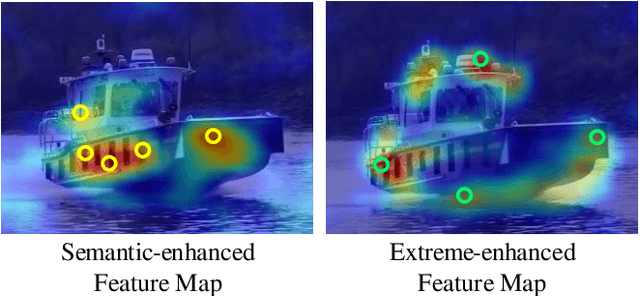

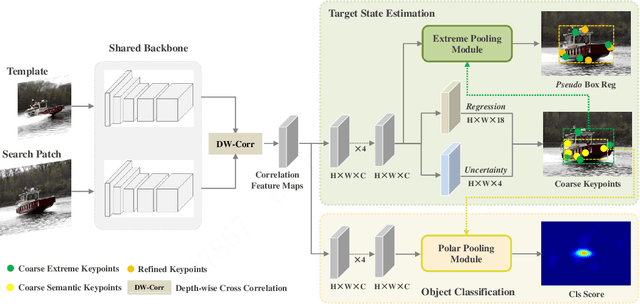

While recent years have witnessed remarkable progress in the feature representation of visual tracking, the problem of feature misalignment between the classification and regression tasks is largely overlooked. The approaches of feature extraction make no difference for these two tasks in most of advanced trackers. We argue that the performance gain of visual tracking is limited since features extracted from the salient area provide more recognizable visual patterns for classification, while these around the boundaries contribute to accurately estimating the target state. We address this problem by proposing two customized feature extractors, named polar pooling and extreme pooling to capture task-specific visual patterns. Polar pooling plays the role of enriching information collected from the semantic keypoints for stronger classification, while extreme pooling facilitates explicit visual patterns of the object boundary for accurate target state estimation. We demonstrate the effectiveness of the task-specific feature representation by integrating it into the recent and advanced tracker RPT. Extensive experiments on several benchmarks show that our Customized Features based RPT (RPT++) achieves new state-of-the-art performances on OTB-100, VOT2018, VOT2019, GOT-10k, TrackingNet and LaSOT.
CESI: Canonicalizing Open Knowledge Bases using Embeddings and Side Information
Feb 01, 2019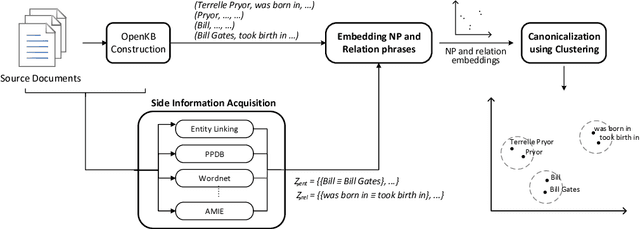
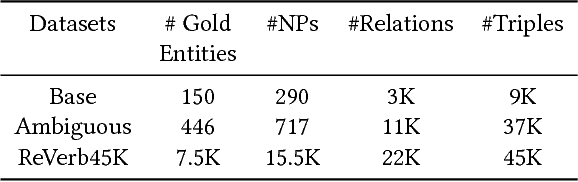
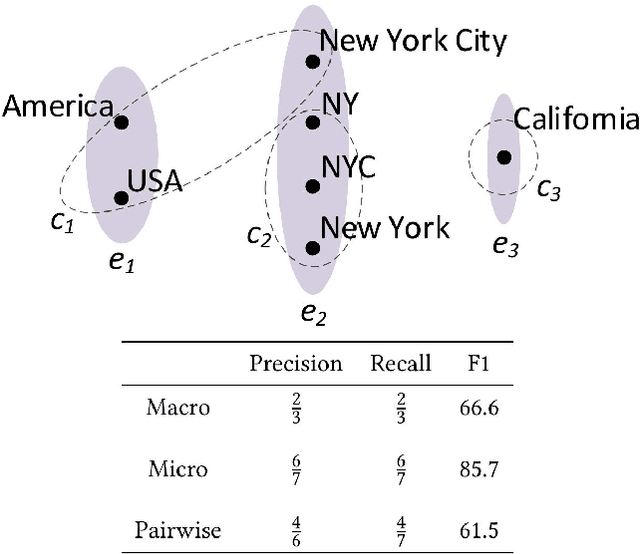
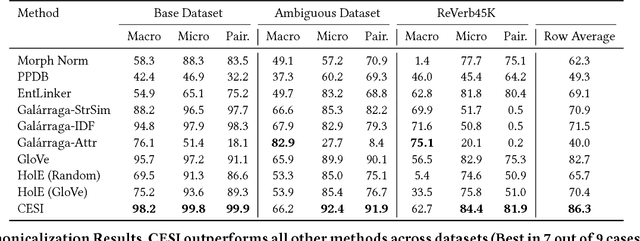
Open Information Extraction (OpenIE) methods extract (noun phrase, relation phrase, noun phrase) triples from text, resulting in the construction of large Open Knowledge Bases (Open KBs). The noun phrases (NPs) and relation phrases in such Open KBs are not canonicalized, leading to the storage of redundant and ambiguous facts. Recent research has posed canonicalization of Open KBs as clustering over manuallydefined feature spaces. Manual feature engineering is expensive and often sub-optimal. In order to overcome this challenge, we propose Canonicalization using Embeddings and Side Information (CESI) - a novel approach which performs canonicalization over learned embeddings of Open KBs. CESI extends recent advances in KB embedding by incorporating relevant NP and relation phrase side information in a principled manner. Through extensive experiments on multiple real-world datasets, we demonstrate CESI's effectiveness.
* Accepted at WWW 2018
QRFA: A Data-Driven Model of Information-Seeking Dialogues
Dec 27, 2018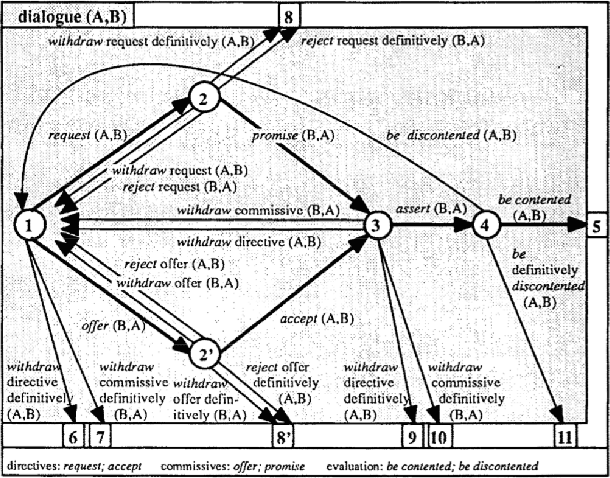

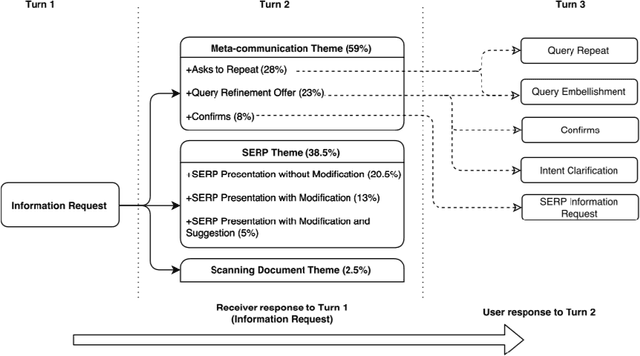
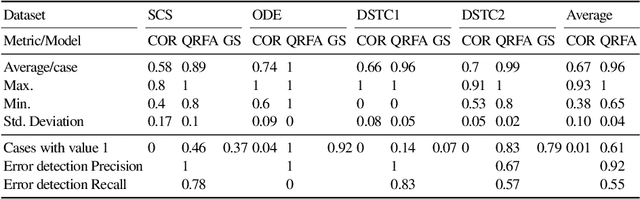
Understanding the structure of interaction processes helps us to improve information-seeking dialogue systems. Analyzing an interaction process boils down to discovering patterns in sequences of alternating utterances exchanged between a user and an agent. Process mining techniques have been successfully applied to analyze structured event logs, discovering the underlying process models or evaluating whether the observed behavior is in conformance with the known process. In this paper, we apply process mining techniques to discover patterns in conversational transcripts and extract a new model of information-seeking dialogues, QRFA, for Query, Request, Feedback, Answer. Our results are grounded in an empirical evaluation across multiple conversational datasets from different domains, which was never attempted before. We show that the QRFA model better reflects conversation flows observed in real information-seeking conversations than models proposed previously. Moreover, QRFA allows us to identify malfunctioning in dialogue system transcripts as deviations from the expected conversation flow described by the model via conformance analysis.