 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spiking Neural Networks with Improved Inherent Recurrence Dynamics for Sequential Learning
Sep 04, 2021
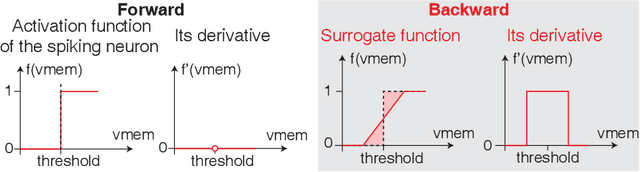
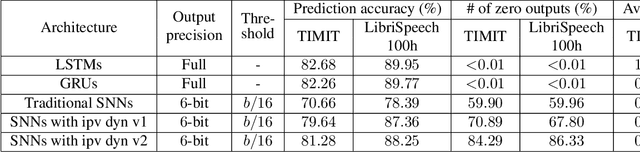
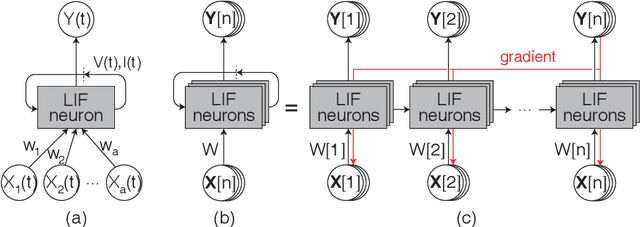
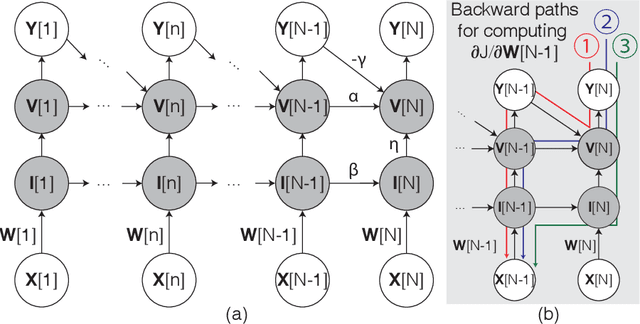
Spiking neural networks (SNNs) with leaky integrate and fire (LIF) neurons, can be operated in an event-driven manner and have internal states to retain information over time, providing opportunities for energy-efficient neuromorphic computing, especially on edge devices. Note, however, many representative works on SNNs do not fully demonstrate the usefulness of their inherent recurrence (membrane potentials retaining information about the past) for sequential learning. Most of the works train SNNs to recognize static images by artificially expanded input representation in time through rate coding. We show that SNNs can be trained for sequential tasks and propose modifications to a network of LIF neurons that enable internal states to learn long sequences and make their inherent recurrence resilient to the vanishing gradient problem. We then develop a training scheme to train the proposed SNNs with improved inherent recurrence dynamics. Our training scheme allows spiking neurons to produce multi-bit outputs (as opposed to binary spikes) which help mitigate the mismatch between a derivative of spiking neurons' activation function and a surrogate derivative used to overcome spiking neurons' non-differentiability. Our experimental results indicate that the proposed SNN architecture on TIMIT and LibriSpeech 100h dataset yields accuracy comparable to that of LSTMs (within 1.10% and 0.36%, respectively), but with 2x fewer parameters than LSTMs. The sparse SNN outputs also lead to 10.13x and 11.14x savings in multiplication operations compared to GRUs, which is generally con-sidered as a lightweight alternative to LSTMs, on TIMIT and LibriSpeech 100h datasets, respectively.
A Survey on Reinforcement Learning for Recommender Systems
Sep 22, 2021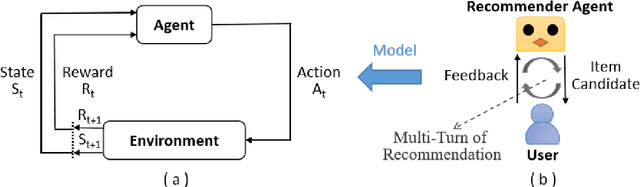

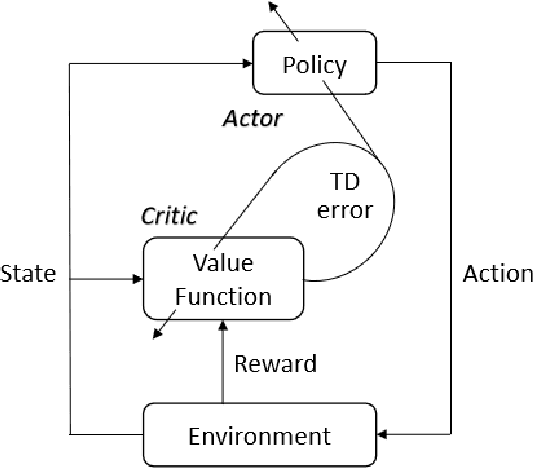
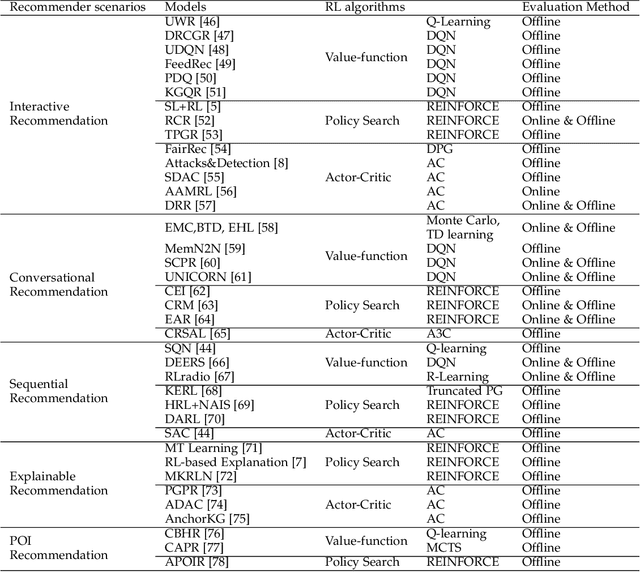
Recommender systems have been widely applied in different real-life scenarios to help us find useful information. Recently, Reinforcement Learning (RL) based recommender systems have become an emerging research topic. It often surpasses traditional recommendation models even most deep learning-based methods, owing to its interactive nature and autonomous learning ability. Nevertheless, there are various challenges of RL when applying in recommender systems. Toward this end, we firstly provide a thorough overview, comparisons, and summarization of RL approaches for five typical recommendation scenarios, following three main categories of RL: value-function, policy search, and Actor-Critic. Then, we systematically analyze the challenges and relevant solutions on the basis of existing literature. Finally, under discussion for open issues of RL and its limitations of recommendation, we highlight some potential research directions in this field.
Soft Attention: Does it Actually Help to Learn Social Interactions in Pedestrian Trajectory Prediction?
Jun 16, 2021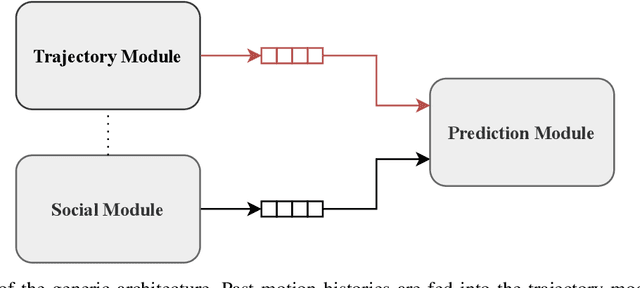
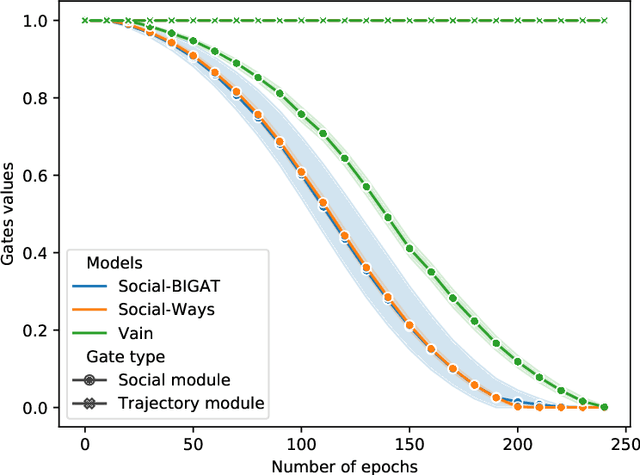
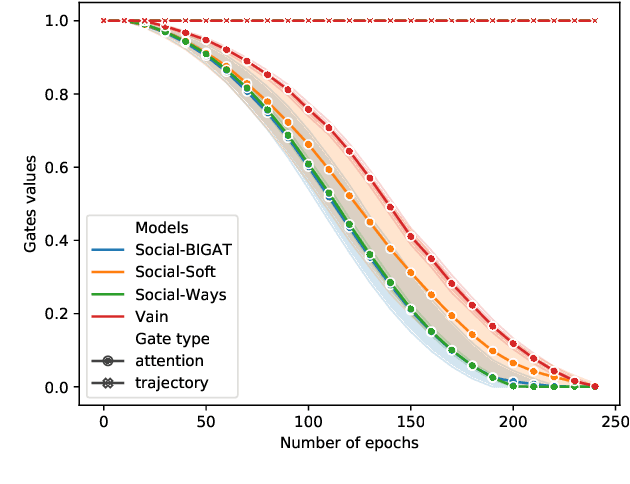
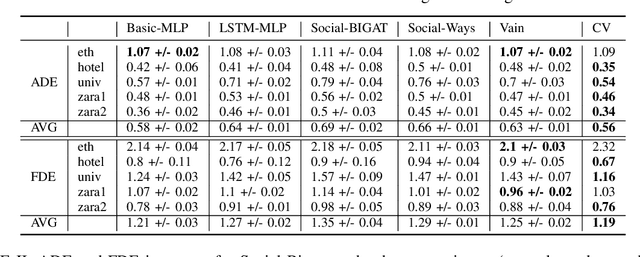
We consider the problem of predicting the future path of a pedestrian using its motion history and the motion history of the surrounding pedestrians, called social information. Since the seminal paper on Social-LSTM, deep-learning has become the main tool used to model the impact of social interactions on a pedestrian's motion. The demonstration that these models can learn social interactions relies on an ablative study of these models. The models are compared with and without their social interactions module on two standard metrics, the Average Displacement Error and Final Displacement Error. Yet, these complex models were recently outperformed by a simple constant-velocity approach. This questions if they actually allow to model social interactions as well as the validity of the proof. In this paper, we focus on the deep-learning models with a soft-attention mechanism for social interaction modeling and study whether they use social information at prediction time. We conduct two experiments across four state-of-the-art approaches on the ETH and UCY datasets, which were also used in previous work. First, the models are trained by replacing the social information with random noise and compared to model trained with actual social information. Second, we use a gating mechanism along with a $L_0$ penalty, allowing models to shut down their inner components. The models consistently learn to prune their soft-attention mechanism. For both experiments, neither the course of the convergence nor the prediction performance were altered. This demonstrates that the soft-attention mechanism and therefore the social information are ignored by the models.
Trust your neighbors: A comprehensive survey of neighborhood-based methods for recommender systems
Sep 09, 2021
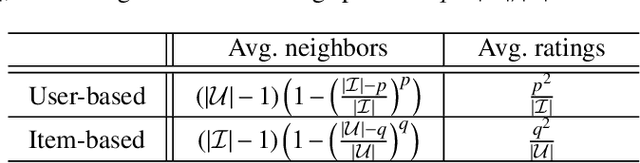

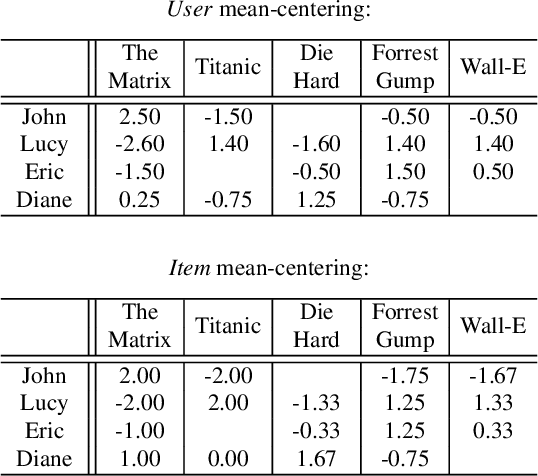
Collaborative recommendation approaches based on nearest-neighbors are still highly popular today due to their simplicity, their efficiency, and their ability to produce accurate and personalized recommendations. This chapter offers a comprehensive survey of neighborhood-based methods for the item recommendation problem. It presents the main characteristics and benefits of such methods, describes key design choices for implementing a neighborhood-based recommender system, and gives practical information on how to make these choices. A broad range of methods is covered in the chapter, including traditional algorithms like k-nearest neighbors as well as advanced approaches based on matrix factorization, sparse coding and random walks.
Time-Distributed Feature Learning in Network Traffic Classification for Internet of Things
Sep 29, 2021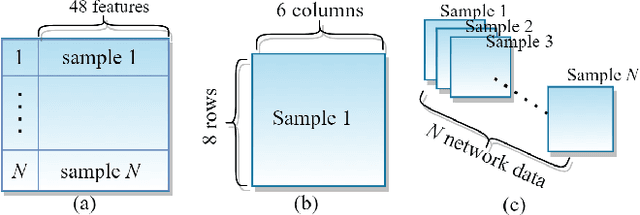
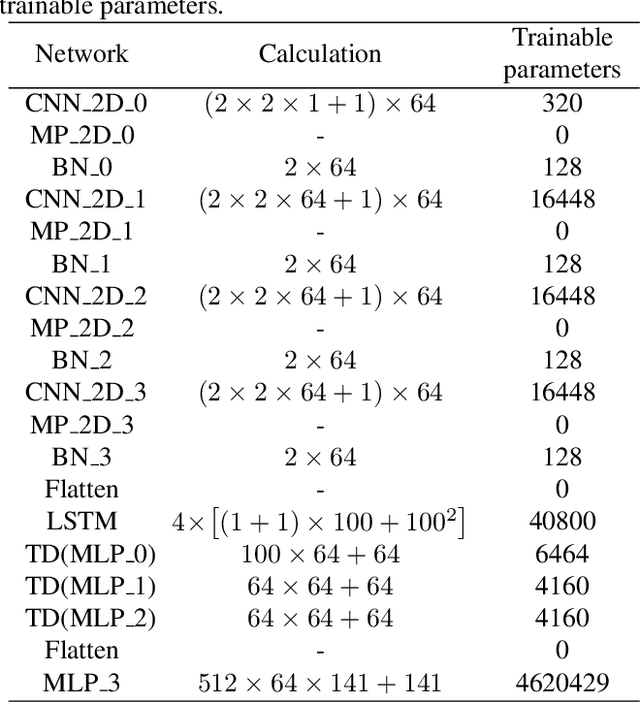
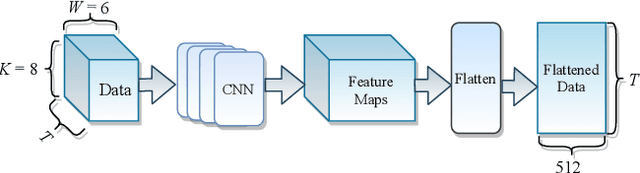

The plethora of Internet of Things (IoT) devices leads to explosive network traffic. The network traffic classification (NTC) is an essential tool to explore behaviours of network flows, and NTC is required for Internet service providers (ISPs) to manage the performance of the IoT network. We propose a novel network data representation, treating the traffic data as a series of images. Thus, the network data is realized as a video stream to employ time-distributed (TD) feature learning. The intra-temporal information within the network statistical data is learned using convolutional neural networks (CNN) and long short-term memory (LSTM), and the inter pseudo-temporal feature among the flows is learned by TD multi-layer perceptron (MLP). We conduct experiments using a large data-set with more number of classes. The experimental result shows that the TD feature learning elevates the network classification performance by 10%.
Neural Distributed Source Coding
Jun 05, 2021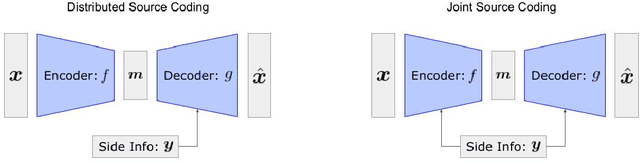
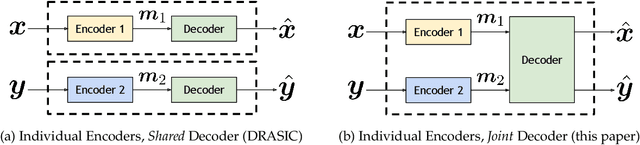


Distributed source coding is the task of encoding an input in the absence of correlated side information that is only available to the decoder. Remarkably, Slepian and Wolf showed in 1973 that an encoder that has no access to the correlated side information can asymptotically achieve the same compression rate as when the side information is available at both the encoder and the decoder. While there is significant prior work on this topic in information theory, practical distributed source coding has been limited to synthetic datasets and specific correlation structures. Here we present a general framework for lossy distributed source coding that is agnostic to the correlation structure and can scale to high dimensions. Rather than relying on hand-crafted source-modeling, our method utilizes a powerful conditional deep generative model to learn the distributed encoder and decoder. We evaluate our method on realistic high-dimensional datasets and show substantial improvements in distributed compression performance.
Clustering acoustic emission data streams with sequentially appearing clusters using mixture models
Aug 25, 2021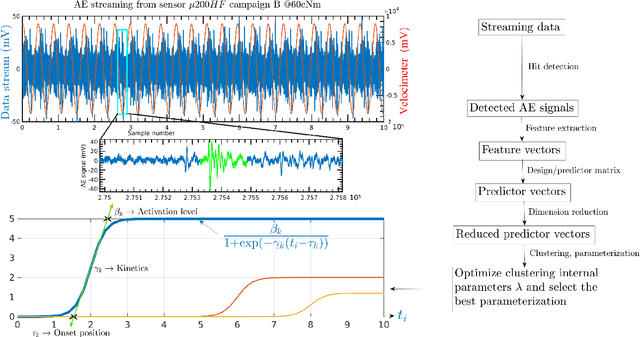
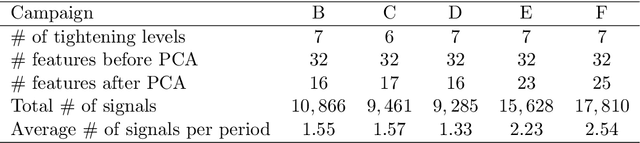
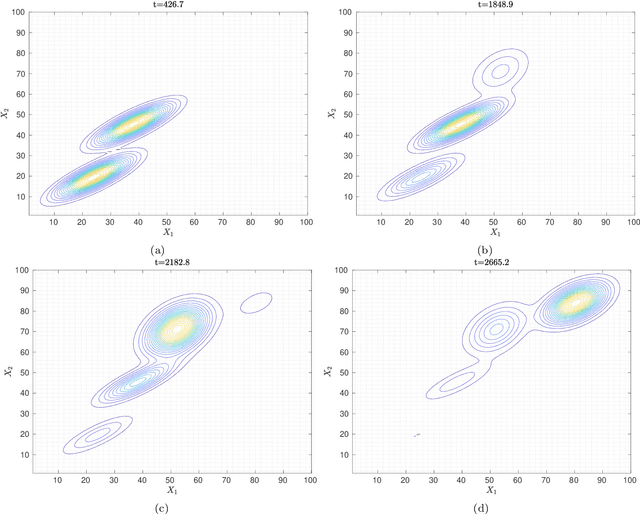
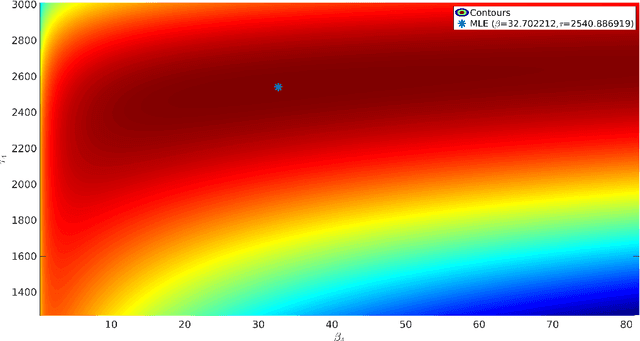
The interpretation of unlabeled acoustic emission (AE) data classically relies on general-purpose clustering methods. While several external criteria have been used in the past to select the hyperparameters of those algorithms, few studies have paid attention to the development of dedicated objective functions in clustering methods able to cope with the specificities of AE data. We investigate how to explicitly represent clusters onsets in mixture models in general, and in Gaussian Mixture Models (GMM) in particular. By modifying the internal criterion of such models, we propose the first clustering method able to provide, through parameters estimated by an expectation-maximization procedure, information about when clusters occur (onsets), how they grow (kinetics) and their level of activation through time. This new objective function accommodates continuous timestamps of AE signals and, thus, their order of occurrence. The method, called GMMSEQ, is experimentally validated to characterize the loosening phenomenon in bolted structure under vibrations. A comparison with three standard clustering methods on raw streaming data from five experimental campaigns shows that GMMSEQ not only provides useful qualitative information about the timeline of clusters, but also shows better performance in terms of cluster characterization. In view of developing an open acoustic emission initiative and according to the FAIR principles, the datasets and the codes are made available to reproduce the research of this paper.
Learning to Transfer with von Neumann Conditional Divergence
Aug 07, 2021
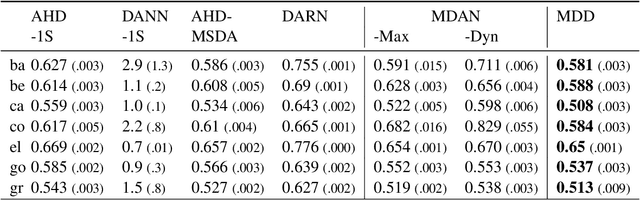
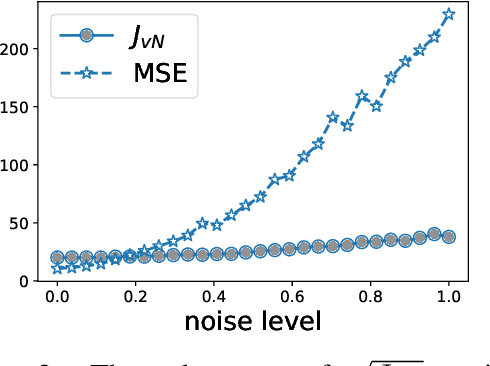
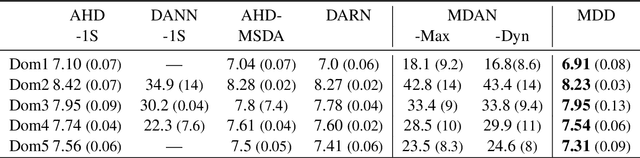
The similarity of feature representations plays a pivotal role in the success of domain adaptation and generalization. Feature similarity includes both the invariance of marginal distributions and the closeness of conditional distributions given the desired response $y$ (e.g., class labels). Unfortunately, traditional methods always learn such features without fully taking into consideration the information in $y$, which in turn may lead to a mismatch of the conditional distributions or the mix-up of discriminative structures underlying data distributions. In this work, we introduce the recently proposed von Neumann conditional divergence to improve the transferability across multiple domains. We show that this new divergence is differentiable and eligible to easily quantify the functional dependence between features and $y$. Given multiple source tasks, we integrate this divergence to capture discriminative information in $y$ and design novel learning objectives assuming those source tasks are observed either simultaneously or sequentially. In both scenarios, we obtain favorable performance against state-of-the-art methods in terms of smaller generalization error on new tasks and less catastrophic forgetting on source tasks (in the sequential setup).
Visually Exploring Multi-Purpose Audio Data
Oct 09, 2021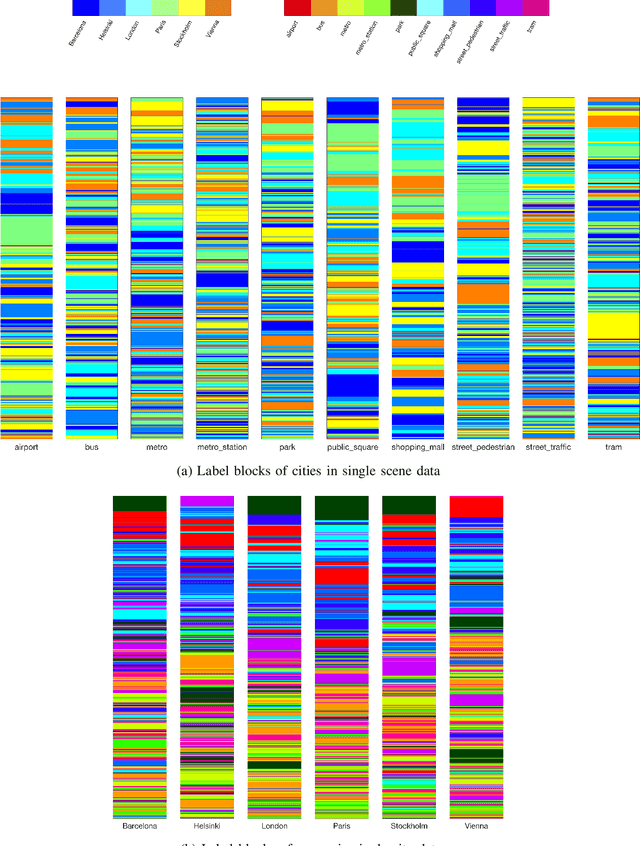
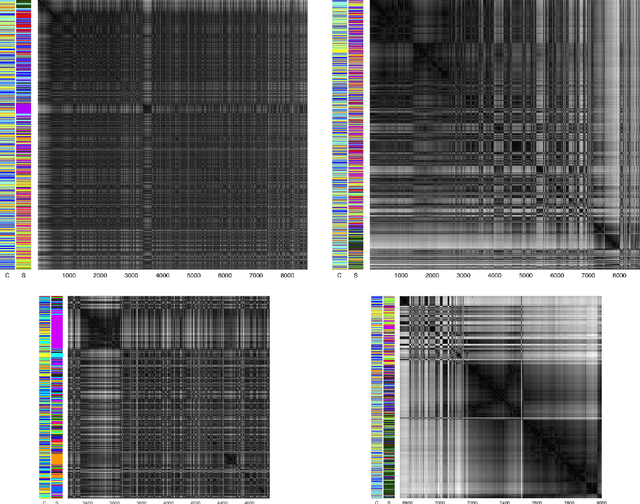


We analyse multi-purpose audio using tools to visualise similarities within the data that may be observed via unsupervised methods. The success of machine learning classifiers is affected by the information contained within system inputs, so we investigate whether latent patterns within the data may explain performance limitations of such classifiers. We use the visual assessment of cluster tendency (VAT) technique on a well known data set to observe how the samples naturally cluster, and we make comparisons to the labels used for audio geotagging and acoustic scene classification. We demonstrate that VAT helps to explain and corroborate confusions observed in prior work to classify this audio, yielding greater insight into the performance - and limitations - of supervised classification systems. While this exploratory analysis is conducted on data for which we know the "ground truth" labels, this method of visualising the natural groupings as dictated by the data leads to important questions about unlabelled data that can help the evaluation and realistic expectations of future (including self-supervised) classification systems.
Audio-Visual Grounding Referring Expression for Robotic Manipulation
Sep 22, 2021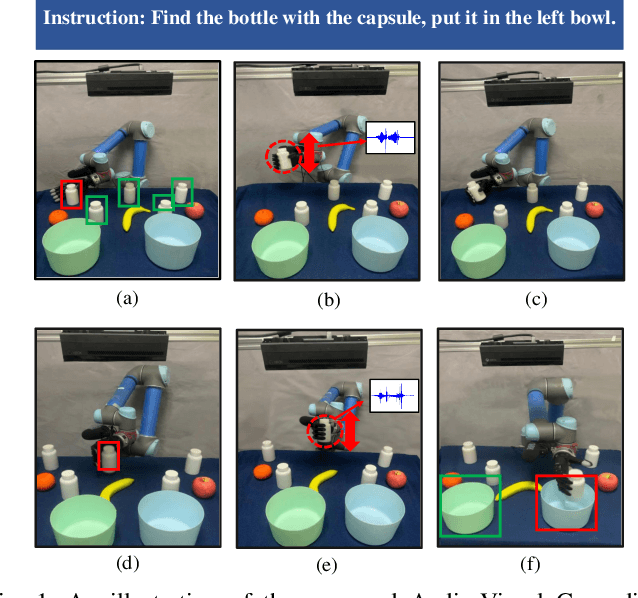
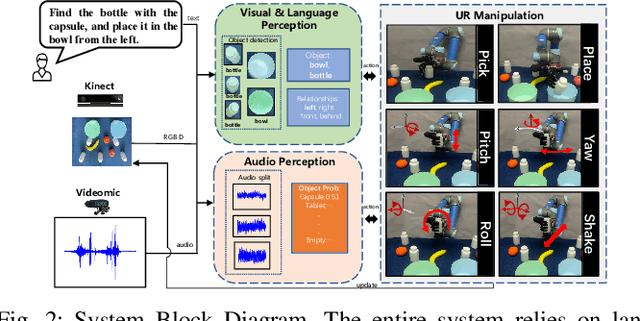
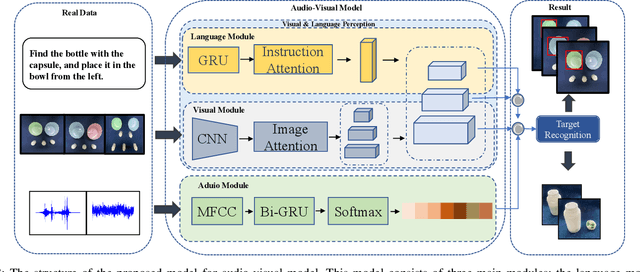

Referring expressions are commonly used when referring to a specific target in people's daily dialogue. In this paper, we develop a novel task of audio-visual grounding referring expression for robotic manipulation. The robot leverages both the audio and visual information to understand the referring expression in the given manipulation instruction and the corresponding manipulations are implemented. To solve the proposed task, an audio-visual framework is proposed for visual localization and sound recognition. We have also established a dataset which contains visual data, auditory data and manipulation instructions for evaluation. Finally, extensive experiments are conducted both offline and online to verify the effectiveness of the proposed audio-visual framework. And it is demonstrated that the robot performs better with the audio-visual data than with only the visual data.