 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Non-Gaussian Gaussian Processes for Few-Shot Regression
Oct 26, 2021
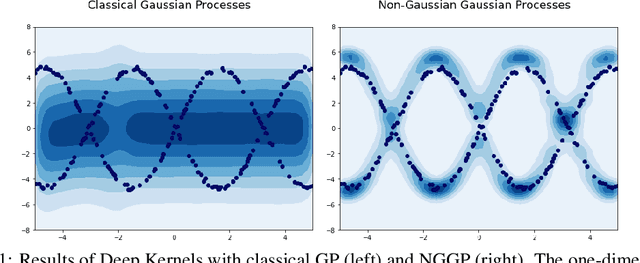
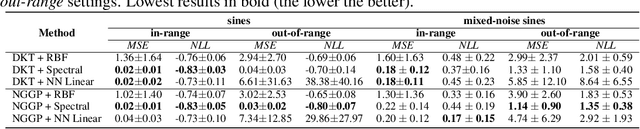
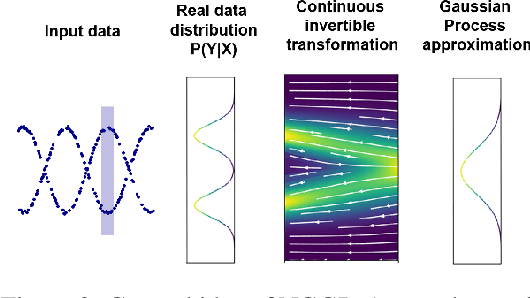
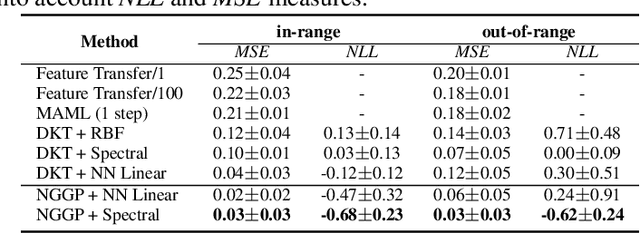
Gaussian Processes (GPs) have been widely used in machine learning to model distributions over functions, with applications including multi-modal regression, time-series prediction, and few-shot learning. GPs are particularly useful in the last application since they rely on Normal distributions and enable closed-form computation of the posterior probability function. Unfortunately, because the resulting posterior is not flexible enough to capture complex distributions, GPs assume high similarity between subsequent tasks - a requirement rarely met in real-world conditions. In this work, we address this limitation by leveraging the flexibility of Normalizing Flows to modulate the posterior predictive distribution of the GP. This makes the GP posterior locally non-Gaussian, therefore we name our method Non-Gaussian Gaussian Processes (NGGPs). More precisely, we propose an invertible ODE-based mapping that operates on each component of the random variable vectors and shares the parameters across all of them. We empirically tested the flexibility of NGGPs on various few-shot learning regression datasets, showing that the mapping can incorporate context embedding information to model different noise levels for periodic functions. As a result, our method shares the structure of the problem between subsequent tasks, but the contextualization allows for adaptation to dissimilarities. NGGPs outperform the competing state-of-the-art approaches on a diversified set of benchmarks and applications.
More than Encoder: Introducing Transformer Decoder to Upsample
Jun 20, 2021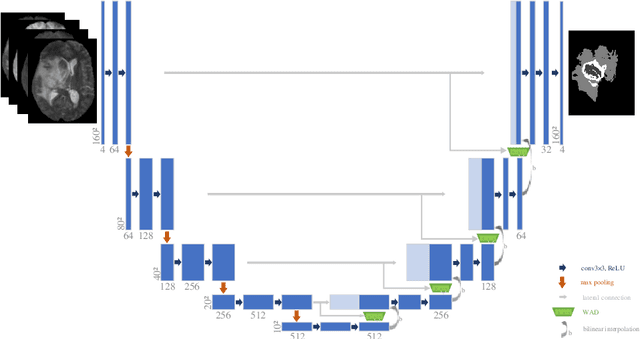
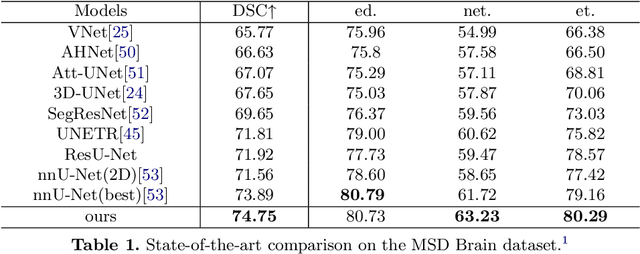
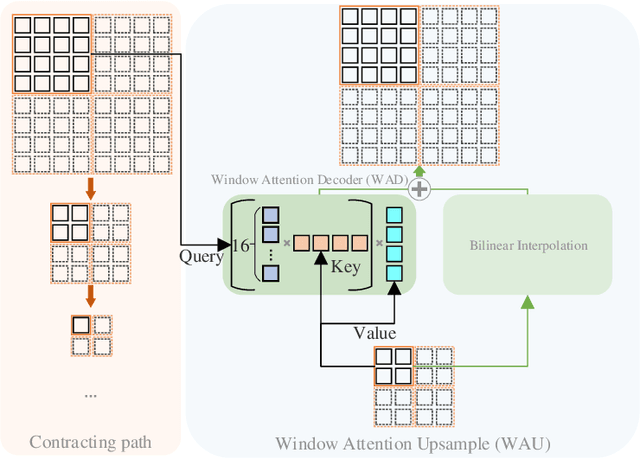
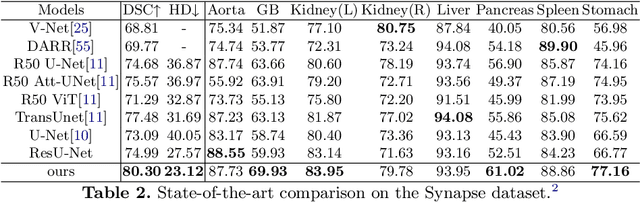
General segmentation models downsample images and then upsample to restore resolution for pixel level prediction. In such schema, upsample technique is vital in maintaining information for better performance. In this paper, we present a new upsample approach, Attention Upsample (AU), that could serve as general upsample method and be incorporated into any segmentation model that possesses lateral connections. AU leverages pixel-level attention to model long range dependency and global information for better reconstruction. It consists of Attention Decoder (AD) and bilinear upsample as residual connection to complement the upsampled features. AD adopts the idea of decoder from transformer which upsamples features conditioned on local and detailed information from contracting path. Moreover, considering the extensive memory and computation cost of pixel-level attention, we further propose to use window attention scheme to restrict attention computation in local windows instead of global range. Incorporating window attention, we denote our decoder as Window Attention Decoder (WAD) and our upsample method as Window Attention Upsample (WAU). We test our method on classic U-Net structure with lateral connection to deliver information from contracting path and achieve state-of-the-arts performance on Synapse (80.30 DSC and 23.12 HD) and MSD Brain (74.75 DSC) datasets.
Clustering acoustic emission data streams with sequentially appearing clusters using mixture models
Aug 25, 2021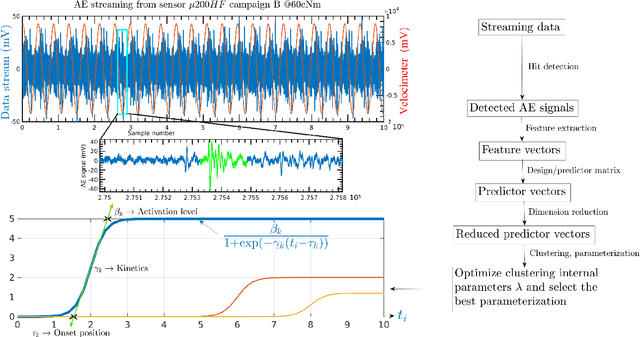
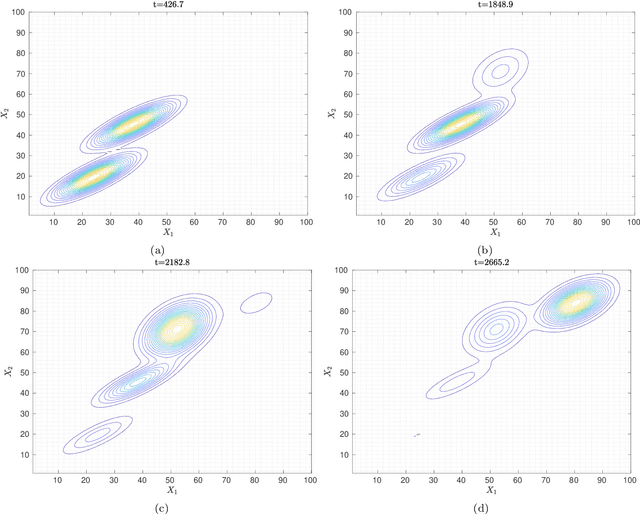
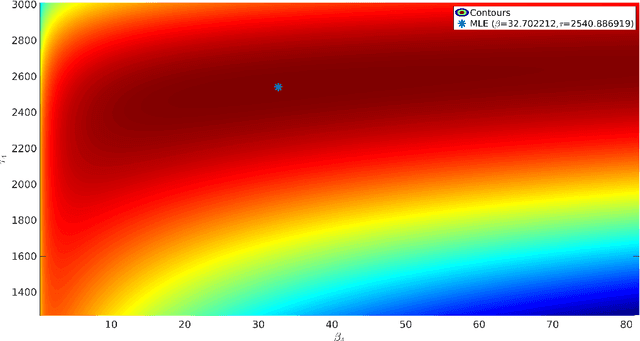
The interpretation of unlabeled acoustic emission (AE) data classically relies on general-purpose clustering methods. While several external criteria have been used in the past to select the hyperparameters of those algorithms, few studies have paid attention to the development of dedicated objective functions in clustering methods able to cope with the specificities of AE data. We investigate how to explicitly represent clusters onsets in mixture models in general, and in Gaussian Mixture Models (GMM) in particular. By modifying the internal criterion of such models, we propose the first clustering method able to provide, through parameters estimated by an expectation-maximization procedure, information about when clusters occur (onsets), how they grow (kinetics) and their level of activation through time. This new objective function accommodates continuous timestamps of AE signals and, thus, their order of occurrence. The method, called GMMSEQ, is experimentally validated to characterize the loosening phenomenon in bolted structure under vibrations. A comparison with three standard clustering methods on raw streaming data from five experimental campaigns shows that GMMSEQ not only provides useful qualitative information about the timeline of clusters, but also shows better performance in terms of cluster characterization. In view of developing an open acoustic emission initiative and according to the FAIR principles, the datasets and the codes are made available to reproduce the research of this paper.
An artificial neural network approach to bifurcating phenomena in computational fluid dynamics
Sep 22, 2021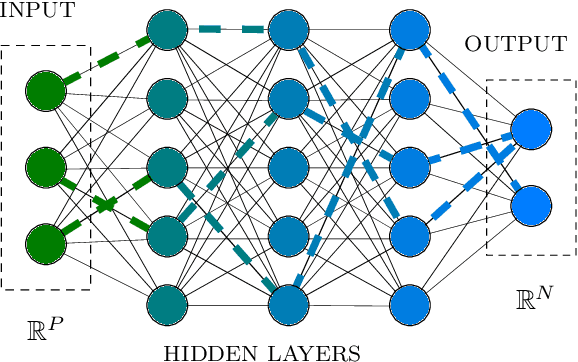


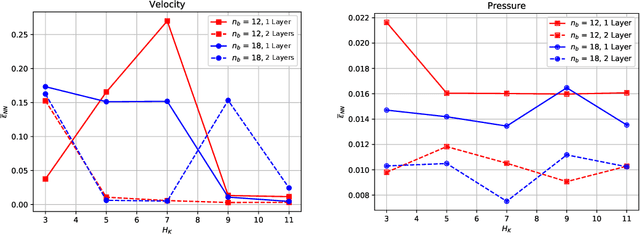
This work deals with the investigation of bifurcating fluid phenomena using a reduced order modelling setting aided by artificial neural networks. We discuss the POD-NN approach dealing with non-smooth solutions set of nonlinear parametrized PDEs. Thus, we study the Navier-Stokes equations describing: (i) the Coanda effect in a channel, and (ii) the lid driven triangular cavity flow, in a physical/geometrical multi-parametrized setting, considering the effects of the domain's configuration on the position of the bifurcation points. Finally, we propose a reduced manifold-based bifurcation diagram for a non-intrusive recovery of the critical points evolution. Exploiting such detection tool, we are able to efficiently obtain information about the pattern flow behaviour, from symmetry breaking profiles to attaching/spreading vortices, even at high Reynolds numbers.
Max-MIG: an Information Theoretic Approach for Joint Learning from Crowds
May 31, 2019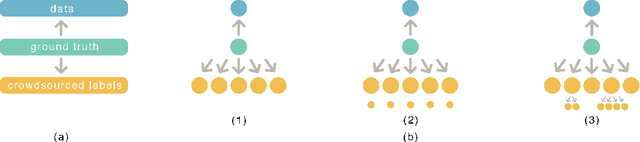
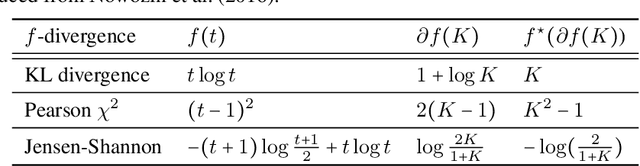

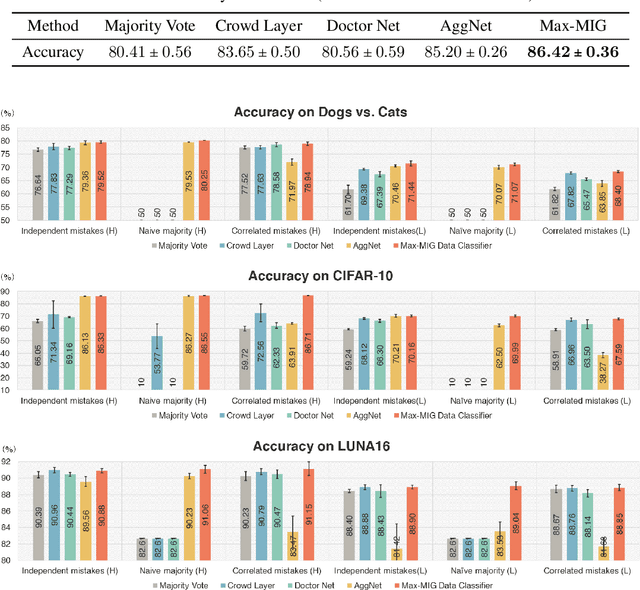
Eliciting labels from crowds is a potential way to obtain large labeled data. Despite a variety of methods developed for learning from crowds, a key challenge remains unsolved: \emph{learning from crowds without knowing the information structure among the crowds a priori, when some people of the crowds make highly correlated mistakes and some of them label effortlessly (e.g. randomly)}. We propose an information theoretic approach, Max-MIG, for joint learning from crowds, with a common assumption: the crowdsourced labels and the data are independent conditioning on the ground truth. Max-MIG simultaneously aggregates the crowdsourced labels and learns an accurate data classifier. Furthermore, we devise an accurate data-crowds forecaster that employs both the data and the crowdsourced labels to forecast the ground truth. To the best of our knowledge, this is the first algorithm that solves the aforementioned challenge of learning from crowds. In addition to the theoretical validation, we also empirically show that our algorithm achieves the new state-of-the-art results in most settings, including the real-world data, and is the first algorithm that is robust to various information structures. Codes are available at \hyperlink{https://github.com/Newbeeer/Max-MIG}{https://github.com/Newbeeer/Max-MIG}
Trust your neighbors: A comprehensive survey of neighborhood-based methods for recommender systems
Sep 09, 2021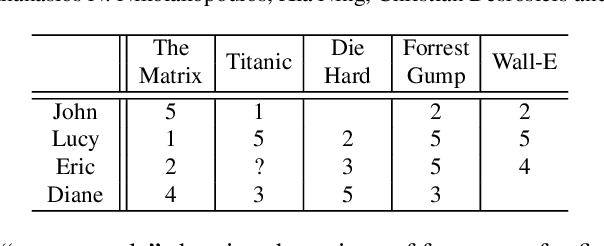
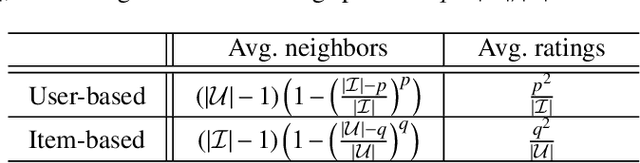

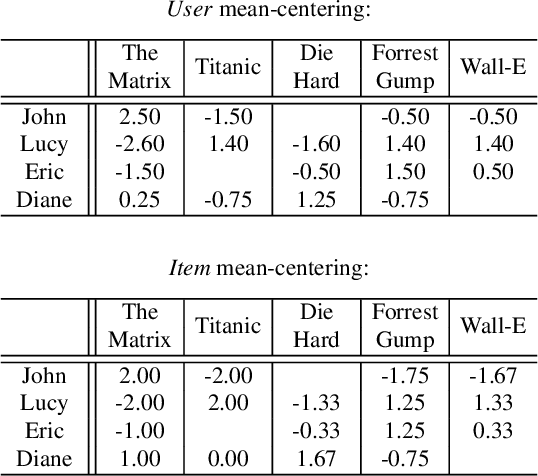
Collaborative recommendation approaches based on nearest-neighbors are still highly popular today due to their simplicity, their efficiency, and their ability to produce accurate and personalized recommendations. This chapter offers a comprehensive survey of neighborhood-based methods for the item recommendation problem. It presents the main characteristics and benefits of such methods, describes key design choices for implementing a neighborhood-based recommender system, and gives practical information on how to make these choices. A broad range of methods is covered in the chapter, including traditional algorithms like k-nearest neighbors as well as advanced approaches based on matrix factorization, sparse coding and random walks.
Spiking Neural Networks with Improved Inherent Recurrence Dynamics for Sequential Learning
Sep 04, 2021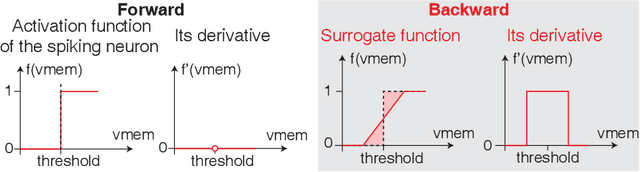
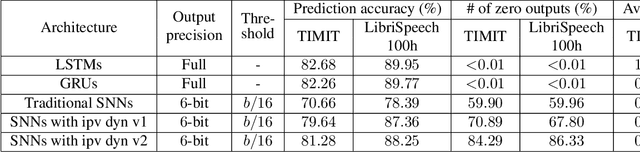
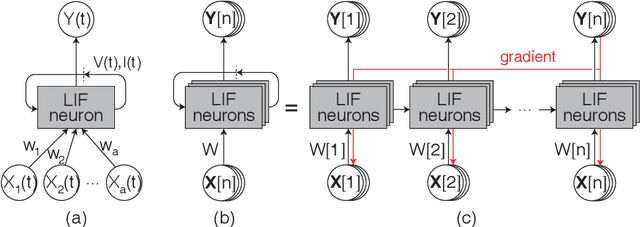
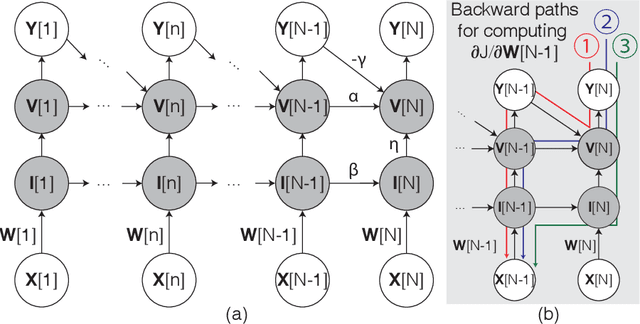
Spiking neural networks (SNNs) with leaky integrate and fire (LIF) neurons, can be operated in an event-driven manner and have internal states to retain information over time, providing opportunities for energy-efficient neuromorphic computing, especially on edge devices. Note, however, many representative works on SNNs do not fully demonstrate the usefulness of their inherent recurrence (membrane potentials retaining information about the past) for sequential learning. Most of the works train SNNs to recognize static images by artificially expanded input representation in time through rate coding. We show that SNNs can be trained for sequential tasks and propose modifications to a network of LIF neurons that enable internal states to learn long sequences and make their inherent recurrence resilient to the vanishing gradient problem. We then develop a training scheme to train the proposed SNNs with improved inherent recurrence dynamics. Our training scheme allows spiking neurons to produce multi-bit outputs (as opposed to binary spikes) which help mitigate the mismatch between a derivative of spiking neurons' activation function and a surrogate derivative used to overcome spiking neurons' non-differentiability. Our experimental results indicate that the proposed SNN architecture on TIMIT and LibriSpeech 100h dataset yields accuracy comparable to that of LSTMs (within 1.10% and 0.36%, respectively), but with 2x fewer parameters than LSTMs. The sparse SNN outputs also lead to 10.13x and 11.14x savings in multiplication operations compared to GRUs, which is generally con-sidered as a lightweight alternative to LSTMs, on TIMIT and LibriSpeech 100h datasets, respectively.
CATRO: Channel Pruning via Class-Aware Trace Ratio Optimization
Oct 21, 2021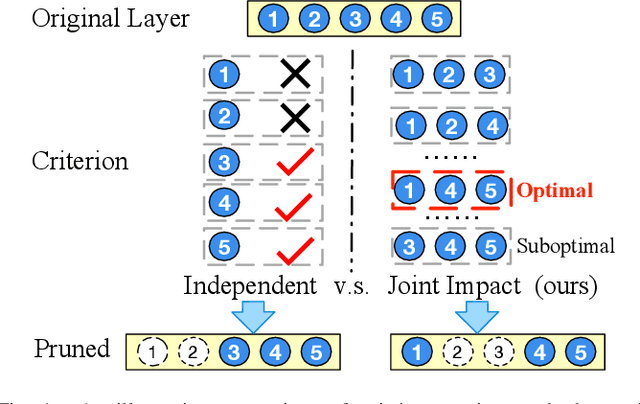
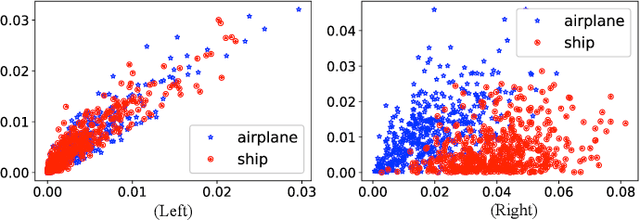
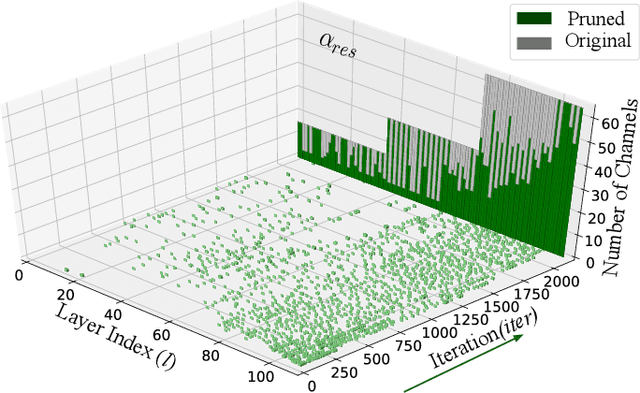
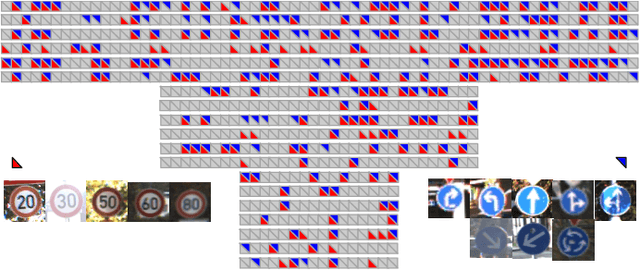
Deep convolutional neural networks are shown to be overkill with high parametric and computational redundancy in many application scenarios, and an increasing number of works have explored model pruning to obtain lightweight and efficient networks. However, most existing pruning approaches are driven by empirical heuristics and rarely consider the joint impact of channels, leading to unguaranteed and suboptimal performance. In this paper, we propose a novel channel pruning method via class-aware trace ratio optimization (CATRO) to reduce the computational burden and accelerate the model inference. Utilizing class information from a few samples, CATRO measures the joint impact of multiple channels by feature space discriminations and consolidates the layer-wise impact of preserved channels. By formulating channel pruning as a submodular set function maximization problem, CATRO solves it efficiently via a two-stage greedy iterative optimization procedure. More importantly, we present theoretical justifications on convergence and performance of CATRO. Experimental results demonstrate that CATRO achieves higher accuracy with similar computation cost or lower computation cost with similar accuracy than other state-of-the-art channel pruning algorithms. In addition, because of its class-aware property, CATRO is suitable to prune efficient networks adaptively for various classification subtasks, enhancing handy deployment and usage of deep networks in real-world applications.
Exploiting Inter-pixel Correlations in Unsupervised Domain Adaptation for Semantic Segmentation
Oct 21, 2021
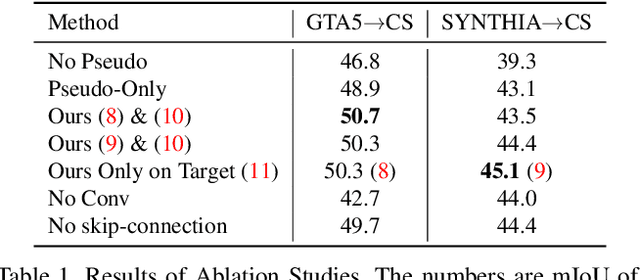
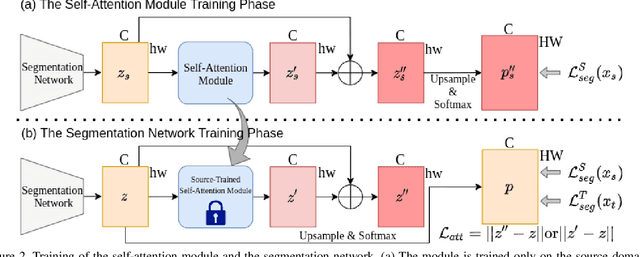
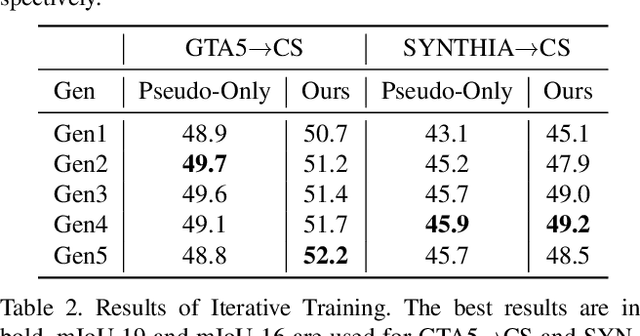
"Self-training" has become a dominant method for semantic segmentation via unsupervised domain adaptation (UDA). It creates a set of pseudo labels for the target domain to give explicit supervision. However, the pseudo labels are noisy, sparse and do not provide any information about inter-pixel correlations. We regard inter-pixel correlation quite important because semantic segmentation is a task of predicting highly structured pixel-level outputs. Therefore, in this paper, we propose a method of transferring the inter-pixel correlations from the source domain to the target domain via a self-attention module. The module takes the prediction of the segmentation network as an input and creates a self-attended prediction that correlates similar pixels. The module is trained only on the source domain to learn the domain-invariant inter-pixel correlations, then later, it is used to train the segmentation network on the target domain. The network learns not only from the pseudo labels but also by following the output of the self-attention module which provides additional knowledge about the inter-pixel correlations. Through extensive experiments, we show that our method significantly improves the performance on two standard UDA benchmarks and also can be combined with recent state-of-the-art method to achieve better performance.
Few-shot Learning with Global Relatedness Decoupled-Distillation
Jul 12, 2021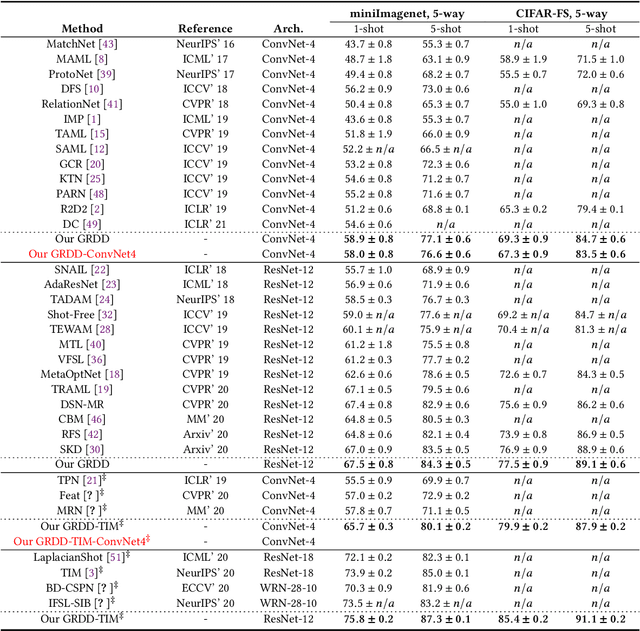
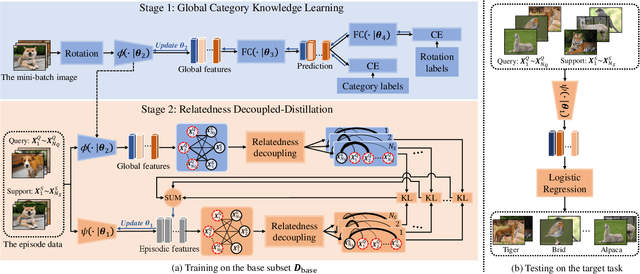
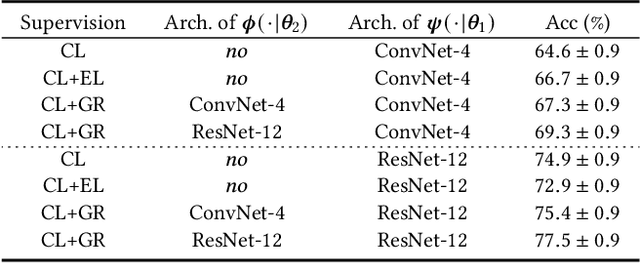
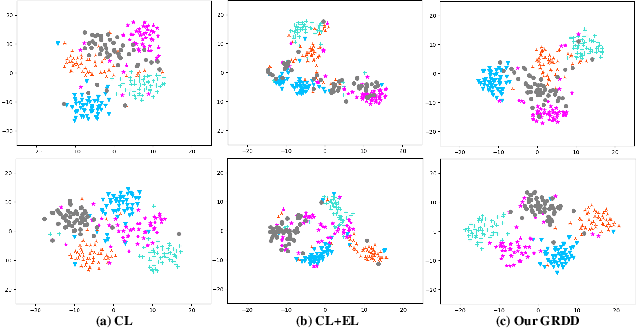
Despite the success that metric learning based approaches have achieved in few-shot learning, recent works reveal the ineffectiveness of their episodic training mode. In this paper, we point out two potential reasons for this problem: 1) the random episodic labels can only provide limited supervision information, while the relatedness information between the query and support samples is not fully exploited; 2) the meta-learner is usually constrained by the limited contextual information of the local episode. To overcome these problems, we propose a new Global Relatedness Decoupled-Distillation (GRDD) method using the global category knowledge and the Relatedness Decoupled-Distillation (RDD) strategy. Our GRDD learns new visual concepts quickly by imitating the habit of humans, i.e. learning from the deep knowledge distilled from the teacher. More specifically, we first train a global learner on the entire base subset using category labels as supervision to leverage the global context information of the categories. Then, the well-trained global learner is used to simulate the query-support relatedness in global dependencies. Finally, the distilled global query-support relatedness is explicitly used to train the meta-learner using the RDD strategy, with the goal of making the meta-learner more discriminative. The RDD strategy aims to decouple the dense query-support relatedness into the groups of sparse decoupled relatedness. Moreover, only the relatedness of a single support sample with other query samples is considered in each group. By distilling the sparse decoupled relatedness group by group, sharper relatedness can be effectively distilled to the meta-learner, thereby facilitating the learning of a discriminative meta-learner. We conduct extensive experiments on the miniImagenet and CIFAR-FS datasets, which show the state-of-the-art performance of our GRDD method.