 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Locally Weighted Mean Phase Angle (LWMPA) Based Tone Mapping Quality Index (TMQI-3)
Sep 17, 2021




High Dynamic Range (HDR) images are the ones that contain a greater range of luminosity as compared to the standard images. HDR images have a higher detail and clarity of structure, objects, and color, which the standard images lack. HDR images are useful in capturing scenes that pose high brightness, darker areas, and shadows, etc. An HDR image comprises multiple narrow-range-exposure images combined into one high-quality image. As these HDR images cannot be displayed on standard display devices, the real challenge comes while converting these HDR images to Low dynamic range (LDR) images. The conversion of HDR image to LDR image is performed using Tone-mapped operators (TMOs). This conversion results in the loss of much valuable information in structure, color, naturalness, and exposures. The loss of information in the LDR image may not directly be visible to the human eye. To calculate how good an LDR image is after conversion, various metrics have been proposed previously. Some are not noise resilient, some work on separate color channels (Red, Green, and Blue one by one), and some lack capacity to identify the structure. To deal with this problem, we propose a metric in this paper called the Tone Mapping Quality Index (TMQI-3), which evaluates the quality of the LDR image based on its objective score. TMQI-3 is noise resilient, takes account of structure and naturalness, and works on all three color channels combined into one luminosity component. This eliminates the need to use multiple metrics at the same time. We compute results for several HDR and LDR images from the literature and show that our quality index metric performs better than the baseline models.
Curriculum Pre-Training Heterogeneous Subgraph Transformer for Top-$N$ Recommendation
Jun 12, 2021
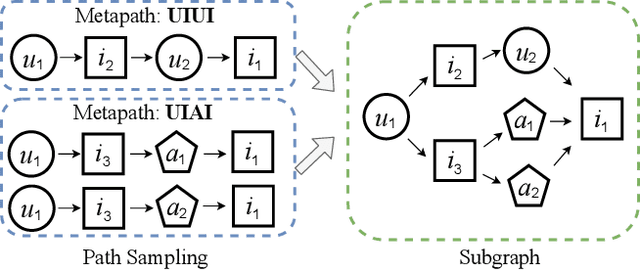
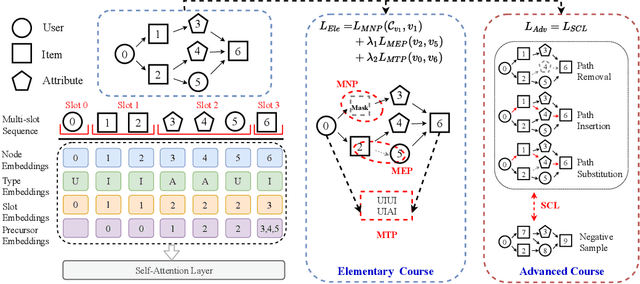
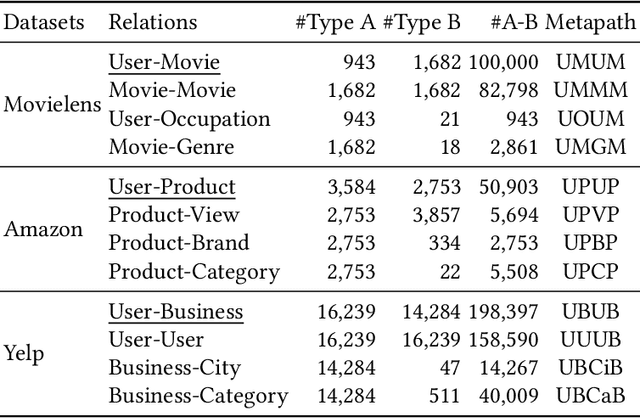
Due to the flexibility in modelling data heterogeneity, heterogeneous information network (HIN) has been adopted to characterize complex and heterogeneous auxiliary data in top-$N$ recommender systems, called \emph{HIN-based recommendation}. HIN characterizes complex, heterogeneous data relations, containing a variety of information that may not be related to the recommendation task. Therefore, it is challenging to effectively leverage useful information from HINs for improving the recommendation performance. To address the above issue, we propose a Curriculum pre-training based HEterogeneous Subgraph Transformer (called \emph{CHEST}) with new \emph{data characterization}, \emph{representation model} and \emph{learning algorithm}. Specifically, we consider extracting useful information from HIN to compose the interaction-specific heterogeneous subgraph, containing both sufficient and relevant context information for recommendation. Then we capture the rich semantics (\eg graph structure and path semantics) within the subgraph via a heterogeneous subgraph Transformer, where we encode the subgraph with multi-slot sequence representations. Besides, we design a curriculum pre-training strategy to provide an elementary-to-advanced learning process, by which we smoothly transfer basic semantics in HIN for modeling user-item interaction relation. Extensive experiments conducted on three real-world datasets demonstrate the superiority of our proposed method over a number of competitive baselines, especially when only limited training data is available.
Learning to Rectify for Robust Learning with Noisy Labels
Nov 08, 2021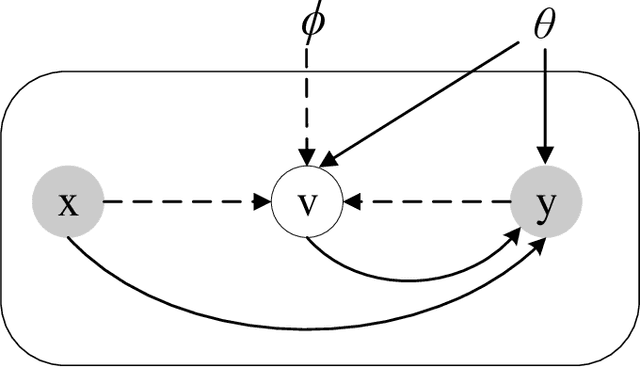
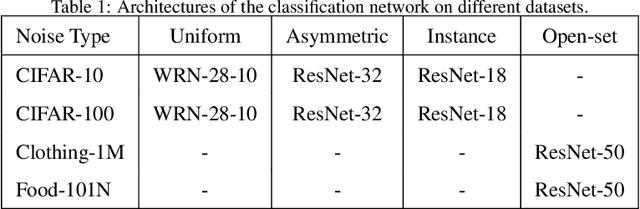
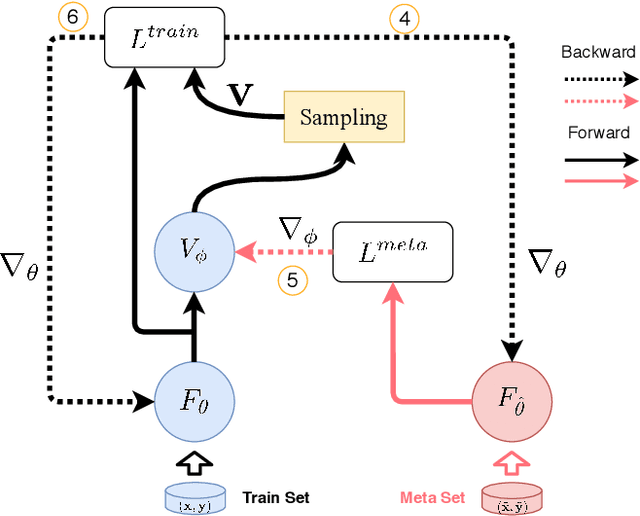
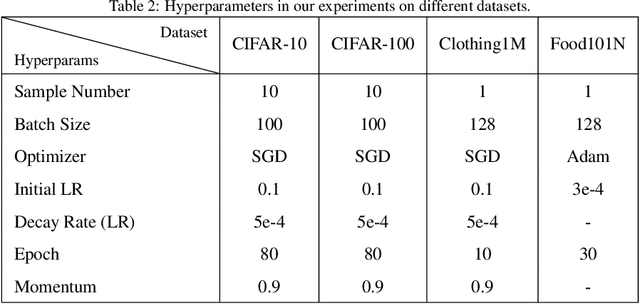
Label noise significantly degrades the generalization ability of deep models in applications. Effective strategies and approaches, \textit{e.g.} re-weighting, or loss correction, are designed to alleviate the negative impact of label noise when training a neural network. Those existing works usually rely on the pre-specified architecture and manually tuning the additional hyper-parameters. In this paper, we propose warped probabilistic inference (WarPI) to achieve adaptively rectifying the training procedure for the classification network within the meta-learning scenario. In contrast to the deterministic models, WarPI is formulated as a hierarchical probabilistic model by learning an amortization meta-network, which can resolve sample ambiguity and be therefore more robust to serious label noise. Unlike the existing approximated weighting function of directly generating weight values from losses, our meta-network is learned to estimate a rectifying vector from the input of the logits and labels, which has the capability of leveraging sufficient information lying in them. This provides an effective way to rectify the learning procedure for the classification network, demonstrating a significant improvement of the generalization ability. Besides, modeling the rectifying vector as a latent variable and learning the meta-network can be seamlessly integrated into the SGD optimization of the classification network. We evaluate WarPI on four benchmarks of robust learning with noisy labels and achieve the new state-of-the-art under variant noise types. Extensive study and analysis also demonstrate the effectiveness of our model.
Learning Efficient Multi-agent Communication: An Information Bottleneck Approach
Nov 16, 2019
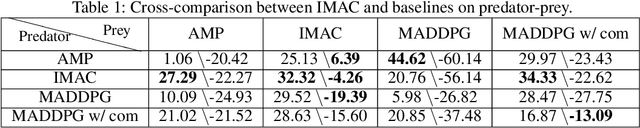
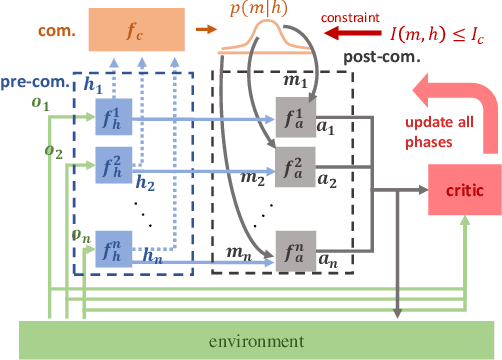
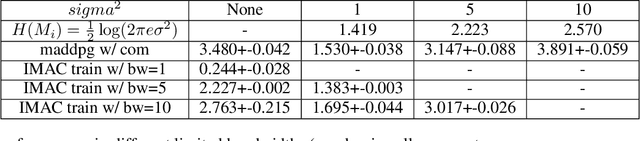
Many real-world multi-agent reinforcement learning applications require agents to communicate, assisted by a communication protocol. These applications face a common and critical issue of communication's limited bandwidth that constrains agents' ability to cooperate successfully. In this paper, rather than proposing a fixed communication protocol, we develop an Informative Multi-Agent Communication (IMAC) method to learn efficient communication protocols. Our contributions are threefold. First, we notice a fact that a limited bandwidth translates into a constraint on the communicated message entropy, thus paving the way of controlling the bandwidth. Second, we introduce a customized batch-norm layer, which controls the messages' entropy to simulate the limited bandwidth constraint. Third, we apply the information bottleneck method to discover the optimal communication protocol, which can satisfy a bandwidth constraint via training with the prior distribution in the method. To demonstrate the efficacy of our method, we conduct extensive experiments in various cooperative and competitive multi-agent tasks across two dimensions: the number of agents and different bandwidths. We show that IMAC converges fast, and leads to efficient communication among agents under the limited-bandwidth constraint as compared to many baseline methods.
An Effective Non-Autoregressive Model for Spoken Language Understanding
Aug 16, 2021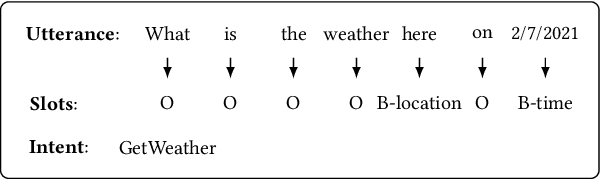
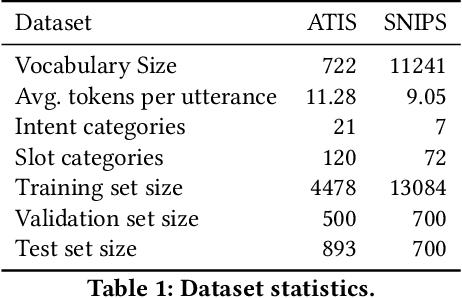
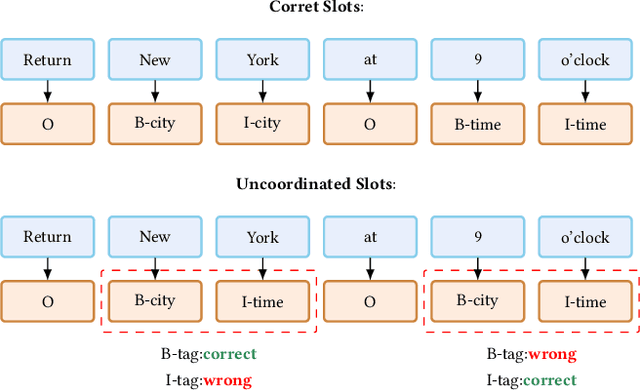
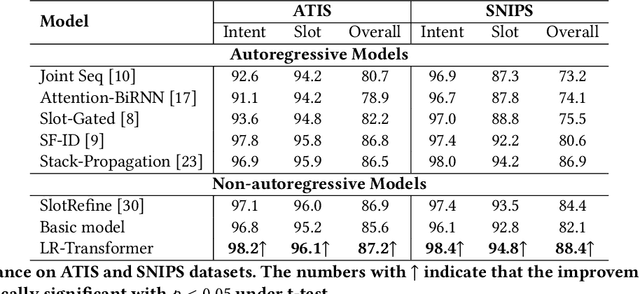
Spoken Language Understanding (SLU), a core component of the task-oriented dialogue system, expects a shorter inference latency due to the impatience of humans. Non-autoregressive SLU models clearly increase the inference speed but suffer uncoordinated-slot problems caused by the lack of sequential dependency information among each slot chunk. To gap this shortcoming, in this paper, we propose a novel non-autoregressive SLU model named Layered-Refine Transformer, which contains a Slot Label Generation (SLG) task and a Layered Refine Mechanism (LRM). SLG is defined as generating the next slot label with the token sequence and generated slot labels. With SLG, the non-autoregressive model can efficiently obtain dependency information during training and spend no extra time in inference. LRM predicts the preliminary SLU results from Transformer's middle states and utilizes them to guide the final prediction. Experiments on two public datasets indicate that our model significantly improves SLU performance (1.5\% on Overall accuracy) while substantially speed up (more than 10 times) the inference process over the state-of-the-art baseline.
Learning Temporally Causal Latent Processes from General Temporal Data
Oct 11, 2021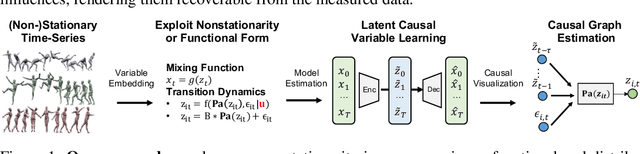
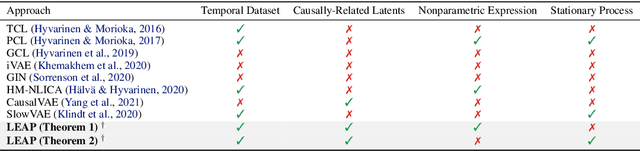
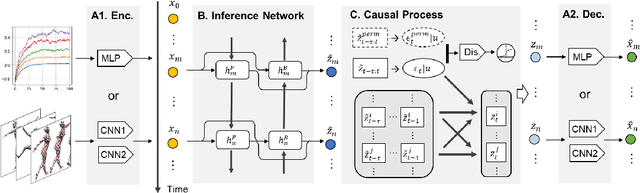
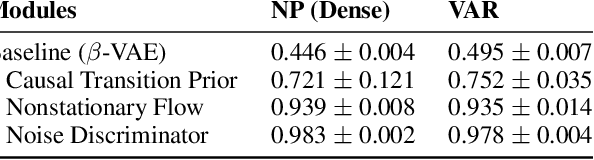
Our goal is to recover time-delayed latent causal variables and identify their relations from measured temporal data. Estimating causally-related latent variables from observations is particularly challenging as the latent variables are not uniquely recoverable in the most general case. In this work, we consider both a nonparametric, nonstationary setting and a parametric setting for the latent processes and propose two provable conditions under which temporally causal latent processes can be identified from their nonlinear mixtures. We propose LEAP, a theoretically-grounded architecture that extends Variational Autoencoders (VAEs) by enforcing our conditions through proper constraints in causal process prior. Experimental results on various data sets demonstrate that temporally causal latent processes are reliably identified from observed variables under different dependency structures and that our approach considerably outperforms baselines that do not leverage history or nonstationarity information. This is one of the first works that successfully recover time-delayed latent processes from nonlinear mixtures without using sparsity or minimality assumptions.
Frame-Capture-Based CSI Recomposition Pertaining to Firmware-Agnostic WiFi Sensing
Oct 29, 2021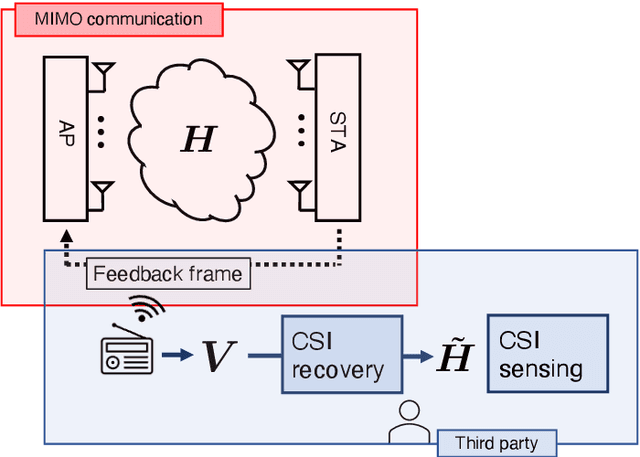
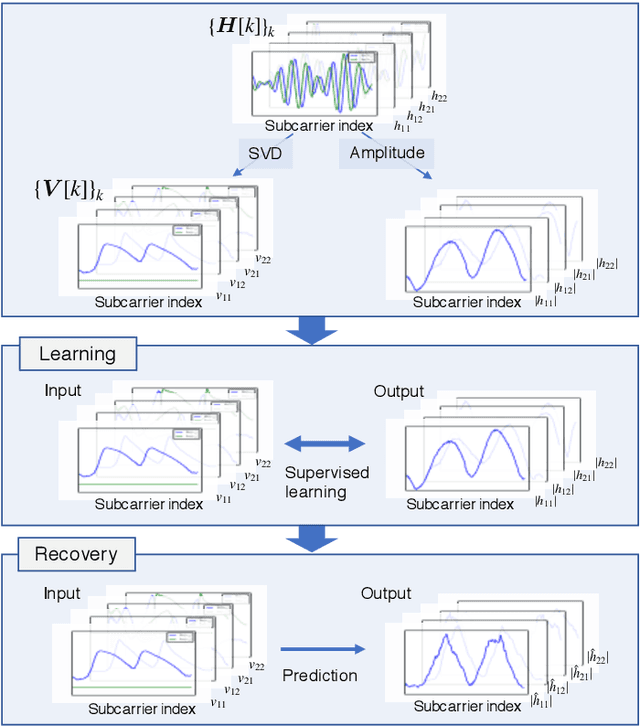
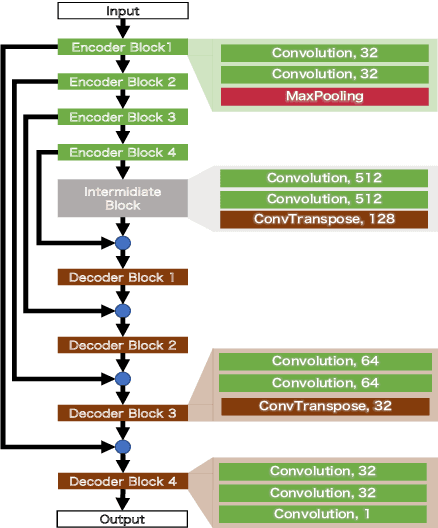
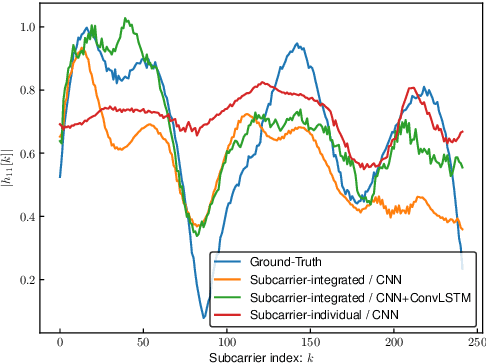
With regard to the implementation of WiFi sensing agnostic according to the availability of channel state information (CSI), we investigate the possibility of estimating a CSI matrix based on its compressed version, which is known as beamforming feedback matrix (BFM). Being different from the CSI matrix that is processed and discarded in physical layer components, the BFM can be captured using a medium-access-layer frame-capturing technique because this is exchanged among an access point (AP) and stations (STAs) over the air. This indicates that WiFi sensing that leverages the BFM matrix is more practical to implement using the pre-installed APs. However, the ability of BFM-based sensing has been evaluated in a few tasks, and more general insights into its performance should be provided. To fill this gap, we propose a CSI estimation method based on BFM, approximating the estimation function with a machine learning model. In addition, to improve the estimation accuracy, we leverage the inter-subcarrier dependency using the BFMs at multiple subcarriers in orthogonal frequency division multiplexing transmissions. Our simulation evaluation reveals that the estimated CSI matches the ground-truth amplitude. Moreover, compared to CSI estimation at each individual subcarrier, the effect of the BFMs at multiple subcarriers on the CSI estimation accuracy is validated.
AnchorGAE: General Data Clustering via $O(n)$ Bipartite Graph Convolution
Nov 12, 2021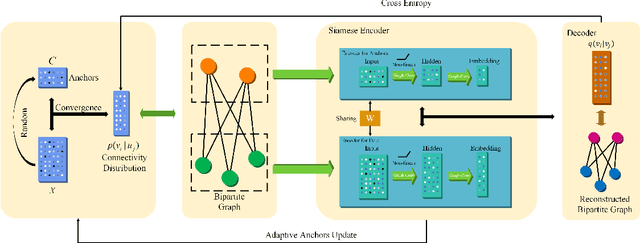
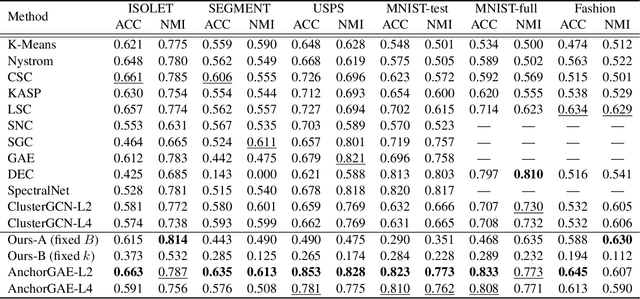

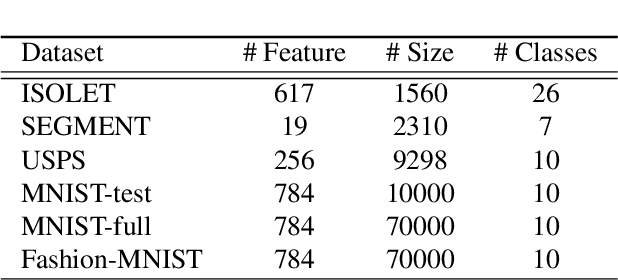
Graph-based clustering plays an important role in clustering tasks. As graph convolution network (GCN), a variant of neural networks on graph-type data, has achieved impressive performance, it is attractive to find whether GCNs can be used to augment the graph-based clustering methods on non-graph data, i.e., general data. However, given $n$ samples, the graph-based clustering methods usually need at least $O(n^2)$ time to build graphs and the graph convolution requires nearly $O(n^2)$ for a dense graph and $O(|\mathcal{E}|)$ for a sparse one with $|\mathcal{E}|$ edges. In other words, both graph-based clustering and GCNs suffer from severe inefficiency problems. To tackle this problem and further employ GCN to promote the capacity of graph-based clustering, we propose a novel clustering method, AnchorGAE. As the graph structure is not provided in general clustering scenarios, we first show how to convert a non-graph dataset into a graph by introducing the generative graph model, which is used to build GCNs. Anchors are generated from the original data to construct a bipartite graph such that the computational complexity of graph convolution is reduced from $O(n^2)$ and $O(|\mathcal{E}|)$ to $O(n)$. The succeeding steps for clustering can be easily designed as $O(n)$ operations. Interestingly, the anchors naturally lead to a siamese GCN architecture. The bipartite graph constructed by anchors is updated dynamically to exploit the high-level information behind data. Eventually, we theoretically prove that the simple update will lead to degeneration and a specific strategy is accordingly designed.
RGB-D Salient Object Detection with Ubiquitous Target Awareness
Sep 08, 2021

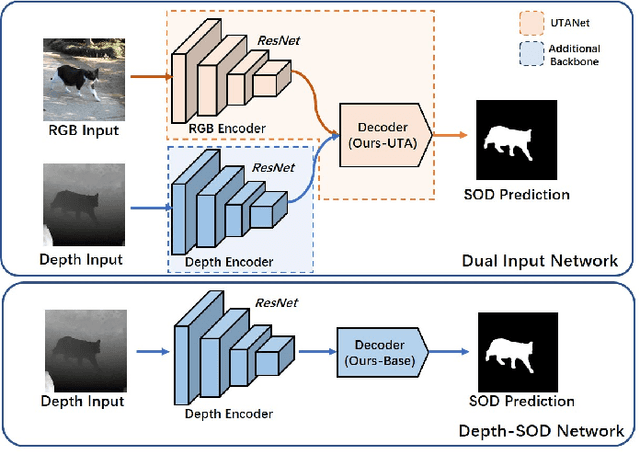

Conventional RGB-D salient object detection methods aim to leverage depth as complementary information to find the salient regions in both modalities. However, the salient object detection results heavily rely on the quality of captured depth data which sometimes are unavailable. In this work, we make the first attempt to solve the RGB-D salient object detection problem with a novel depth-awareness framework. This framework only relies on RGB data in the testing phase, utilizing captured depth data as supervision for representation learning. To construct our framework as well as achieving accurate salient detection results, we propose a Ubiquitous Target Awareness (UTA) network to solve three important challenges in RGB-D SOD task: 1) a depth awareness module to excavate depth information and to mine ambiguous regions via adaptive depth-error weights, 2) a spatial-aware cross-modal interaction and a channel-aware cross-level interaction, exploiting the low-level boundary cues and amplifying high-level salient channels, and 3) a gated multi-scale predictor module to perceive the object saliency in different contextual scales. Besides its high performance, our proposed UTA network is depth-free for inference and runs in real-time with 43 FPS. Experimental evidence demonstrates that our proposed network not only surpasses the state-of-the-art methods on five public RGB-D SOD benchmarks by a large margin, but also verifies its extensibility on five public RGB SOD benchmarks.
Explainable Fact-checking through Question Answering
Oct 11, 2021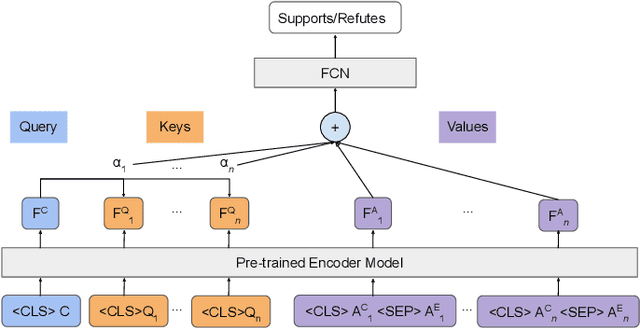
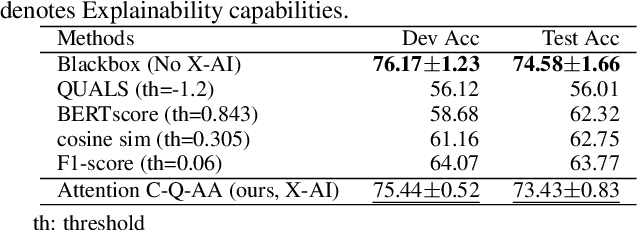

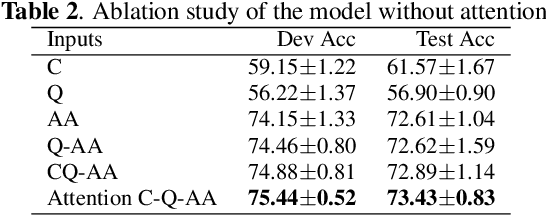
Misleading or false information has been creating chaos in some places around the world. To mitigate this issue, many researchers have proposed automated fact-checking methods to fight the spread of fake news. However, most methods cannot explain the reasoning behind their decisions, failing to build trust between machines and humans using such technology. Trust is essential for fact-checking to be applied in the real world. Here, we address fact-checking explainability through question answering. In particular, we propose generating questions and answers from claims and answering the same questions from evidence. We also propose an answer comparison model with an attention mechanism attached to each question. Leveraging question answering as a proxy, we break down automated fact-checking into several steps -- this separation aids models' explainability as it allows for more detailed analysis of their decision-making processes. Experimental results show that the proposed model can achieve state-of-the-art performance while providing reasonable explainable capabilities.