 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Time-Varying Channel Prediction for RIS-Assisted MU-MISO Networks via Deep Learning
Nov 09, 2021
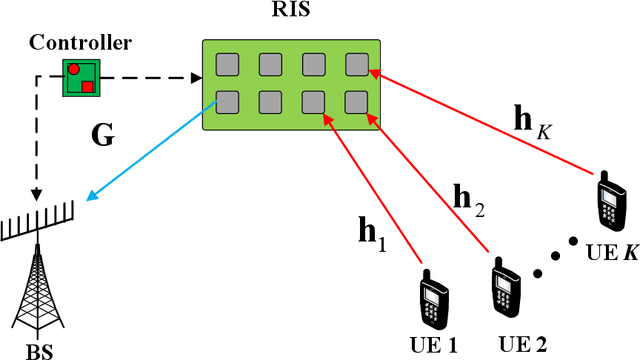
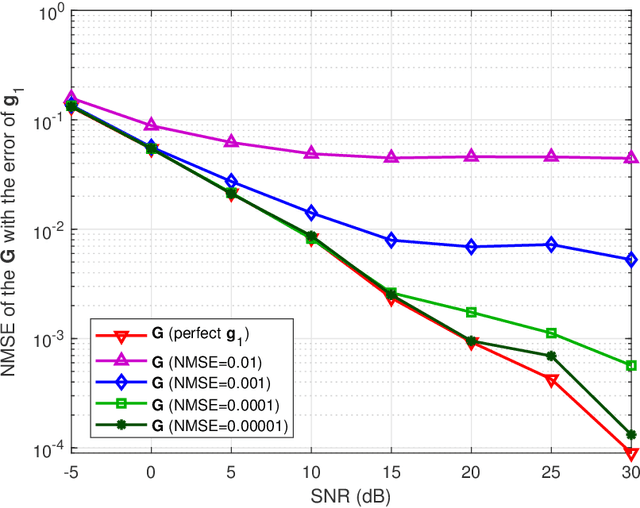
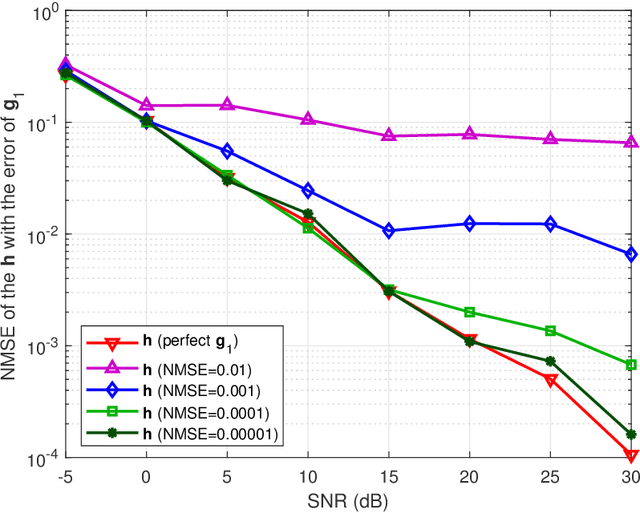
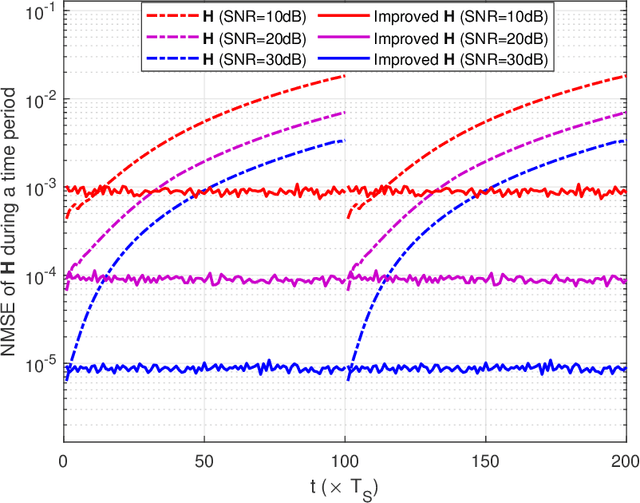
To mitigate the effects of shadow fading and obstacle blocking, reconfigurable intelligent surface (RIS) has become a promising technology to improve the signal transmission quality of wireless communications by controlling the reconfigurable passive elements with less hardware cost and lower power consumption. However, accurate, low-latency and low-pilot-overhead channel state information (CSI) acquisition remains a considerable challenge in RIS-assisted systems due to the large number of RIS passive elements. In this paper, we propose a three-stage joint channel decomposition and prediction framework to require CSI. The proposed framework exploits the two-timescale property that the base station (BS)-RIS channel is quasi-static and the RIS-user equipment (UE) channel is fast time-varying. Specifically, in the first stage, we use the full-duplex technique to estimate the channel between a BS's specific antenna and the RIS, addressing the critical scaling ambiguity problem in the channel decomposition. We then design a novel deep neural network, namely, the sparse-connected long short-term memory (SCLSTM), and propose a SCLSTM-based algorithm in the second and third stages, respectively. The algorithm can simultaneously decompose the BS-RIS channel and RIS-UE channel from the cascaded channel and capture the temporal relationship of the RIS-UE channel for prediction. Simulation results show that our proposed framework has lower pilot overhead than the traditional channel estimation algorithms, and the proposed SCLSTM-based algorithm can also achieve more accurate CSI acquisition robustly and effectively.
An AI-based Solution for Enhancing Delivery of Digital Learning for Future Teachers
Nov 09, 2021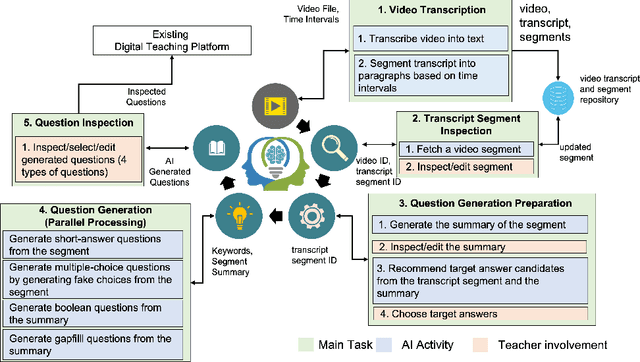

There has been a recent and rapid shift to digital learning hastened by the pandemic but also influenced by ubiquitous availability of digital tools and platforms now, making digital learning ever more accessible. An integral and one of the most difficult part of scaling digital learning and teaching is to be able to assess learner's knowledge and competency. An educator can record a lecture or create digital content that can be delivered to thousands of learners but assessing learners is extremely time consuming. In the paper, we propose an Artificial Intelligence (AI)-based solution namely VidVersityQG for generating questions automatically from pre-recorded video lectures. The solution can automatically generate different types of assessment questions (including short answer, multiple choice, true/false and fill in the blank questions) based on contextual and semantic information inferred from the videos. The proposed solution takes a human-centred approach, wherein teachers are provided the ability to modify/edit any AI generated questions. This approach encourages trust and engagement of teachers in the use and implementation of AI in education. The AI-based solution was evaluated for its accuracy in generating questions by 7 experienced teaching professionals and 117 education videos from multiple domains provided to us by our industry partner VidVersity. VidVersityQG solution showed promising results in generating high-quality questions automatically from video thereby significantly reducing the time and effort for educators in manual question generation.
Speech Pattern based Black-box Model Watermarking for Automatic Speech Recognition
Oct 19, 2021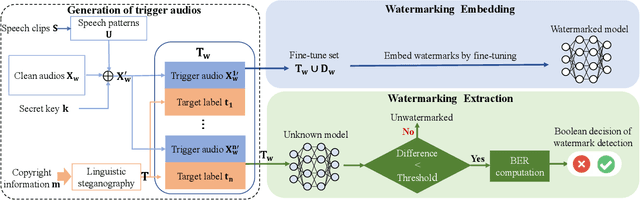

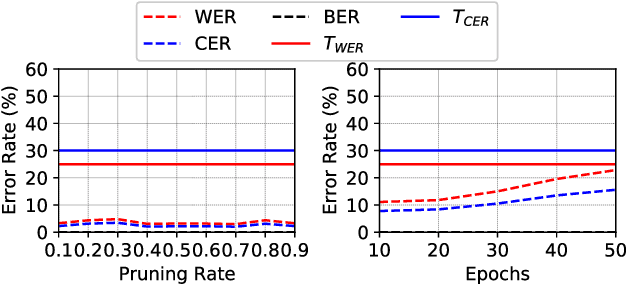

As an effective method for intellectual property (IP) protection, model watermarking technology has been applied on a wide variety of deep neural networks (DNN), including speech classification models. However, how to design a black-box watermarking scheme for automatic speech recognition (ASR) models is still an unsolved problem, which is a significant demand for protecting remote ASR Application Programming Interface (API) deployed in cloud servers. Due to conditional independence assumption and label-detection-based evasion attack risk of ASR models, the black-box model watermarking scheme for speech classification models cannot apply to ASR models. In this paper, we propose the first black-box model watermarking framework for protecting the IP of ASR models. Specifically, we synthesize trigger audios by spreading the speech clips of model owners over the entire input audios and labeling the trigger audios with the stego texts, which hides the authorship information with linguistic steganography. Experiments on the state-of-the-art open-source ASR system DeepSpeech demonstrate the feasibility of the proposed watermarking scheme, which is robust against five kinds of attacks and has little impact on accuracy.
MRI Reconstruction Using Deep Energy-Based Model
Sep 09, 2021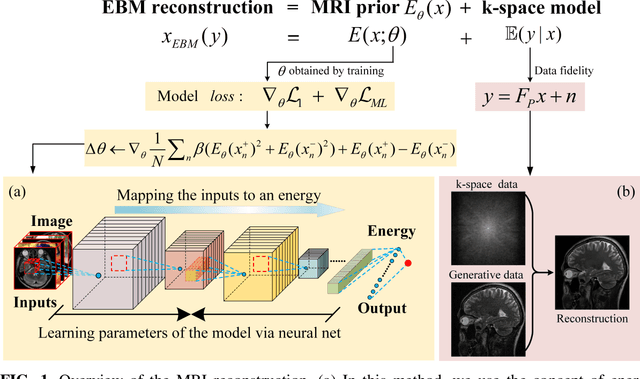
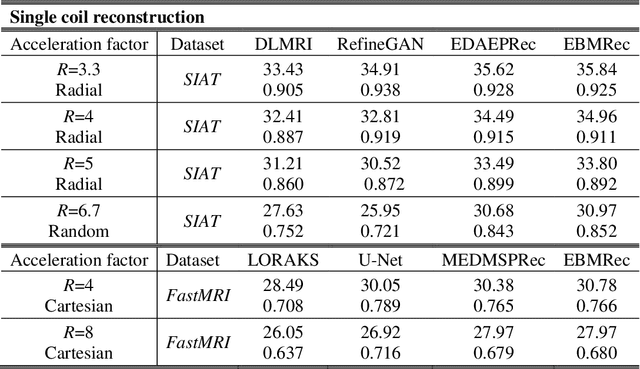
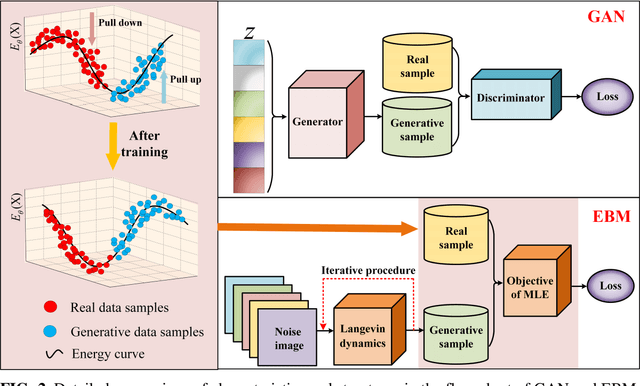
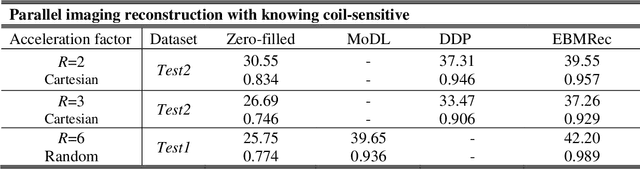
Purpose: Although recent deep energy-based generative models (EBMs) have shown encouraging results in many image generation tasks, how to take advantage of the self-adversarial cogitation in deep EBMs to boost the performance of Magnetic Resonance Imaging (MRI) reconstruction is still desired. Methods: With the successful application of deep learning in a wide range of MRI reconstruction, a line of emerging research involves formulating an optimization-based reconstruction method in the space of a generative model. Leveraging this, a novel regularization strategy is introduced in this article which takes advantage of self-adversarial cogitation of the deep energy-based model. More precisely, we advocate for alternative learning a more powerful energy-based model with maximum likelihood estimation to obtain the deep energy-based information, represented as image prior. Simultaneously, implicit inference with Langevin dynamics is a unique property of re-construction. In contrast to other generative models for reconstruction, the proposed method utilizes deep energy-based information as the image prior in reconstruction to improve the quality of image. Results: Experiment results that imply the proposed technique can obtain remarkable performance in terms of high reconstruction accuracy that is competitive with state-of-the-art methods, and does not suffer from mode collapse. Conclusion: Algorithmically, an iterative approach was presented to strengthen EBM training with the gradient of energy network. The robustness and the reproducibility of the algorithm were also experimentally validated. More importantly, the proposed reconstruction framework can be generalized for most MRI reconstruction scenarios.
Meta Learning Low Rank Covariance Factors for Energy-Based Deterministic Uncertainty
Oct 12, 2021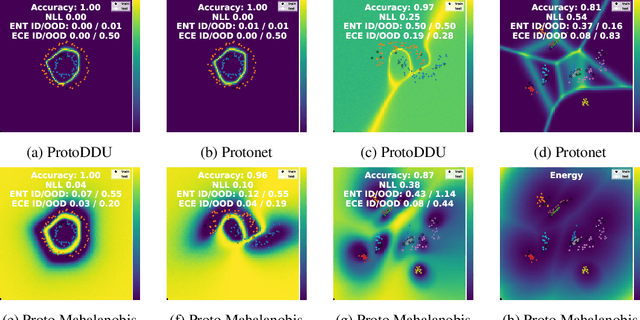
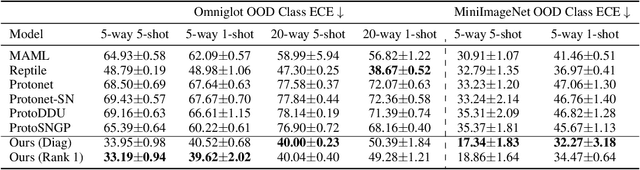
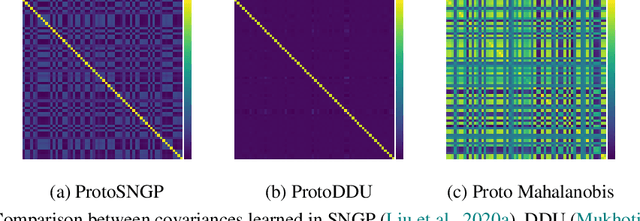
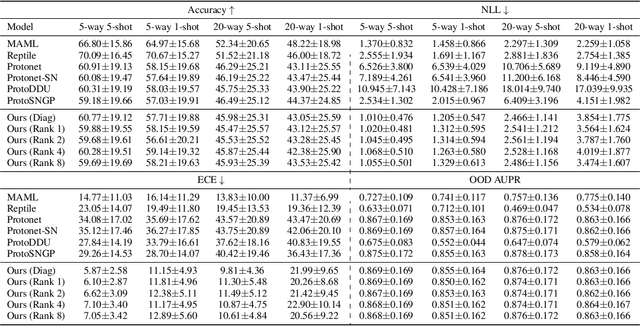
Numerous recent works utilize bi-Lipschitz regularization of neural network layers to preserve relative distances between data instances in the feature spaces of each layer. This distance sensitivity with respect to the data aids in tasks such as uncertainty calibration and out-of-distribution (OOD) detection. In previous works, features extracted with a distance sensitive model are used to construct feature covariance matrices which are used in deterministic uncertainty estimation or OOD detection. However, in cases where there is a distribution over tasks, these methods result in covariances which are sub-optimal, as they may not leverage all of the meta information which can be shared among tasks. With the use of an attentive set encoder, we propose to meta learn either diagonal or diagonal plus low-rank factors to efficiently construct task specific covariance matrices. Additionally, we propose an inference procedure which utilizes scaled energy to achieve a final predictive distribution which can better separate OOD data, and is well calibrated under a distributional dataset shift.
ALL Dolphins Are Intelligent and SOME Are Friendly: Probing BERT for Nouns' Semantic Properties and their Prototypicality
Oct 12, 2021
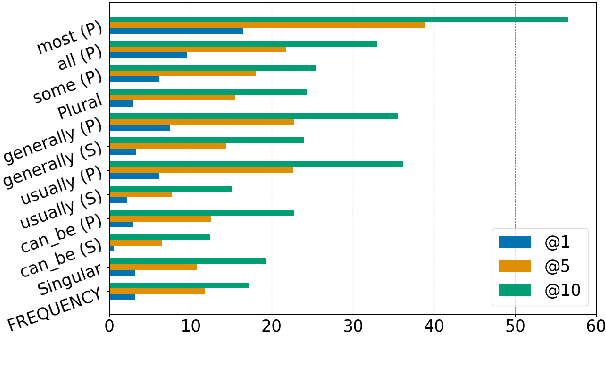

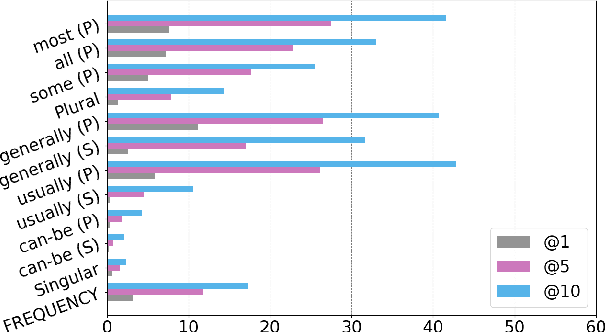
Large scale language models encode rich commonsense knowledge acquired through exposure to massive data during pre-training, but their understanding of entities and their semantic properties is unclear. We probe BERT (Devlin et al., 2019) for the properties of English nouns as expressed by adjectives that do not restrict the reference scope of the noun they modify (as in "red car"), but instead emphasise some inherent aspect ("red strawberry"). We base our study on psycholinguistics datasets that capture the association strength between nouns and their semantic features. We probe BERT using cloze tasks and in a classification setting, and show that the model has marginal knowledge of these features and their prevalence as expressed in these datasets. We discuss factors that make evaluation challenging and impede drawing general conclusions about the models' knowledge of noun properties. Finally, we show that when tested in a fine-tuning setting addressing entailment, BERT successfully leverages the information needed for reasoning about the meaning of adjective-noun constructions outperforming previous methods.
The CAT SET on the MAT: Cross Attention for Set Matching in Bipartite Hypergraphs
Oct 30, 2021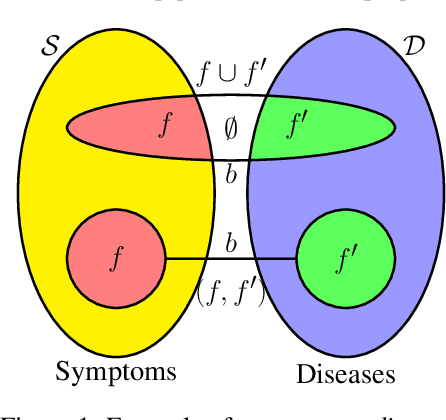

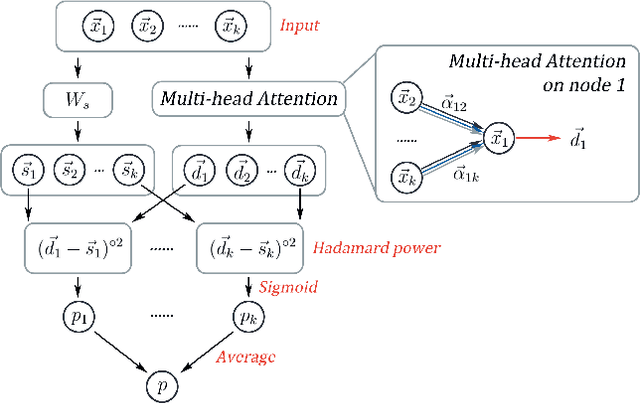
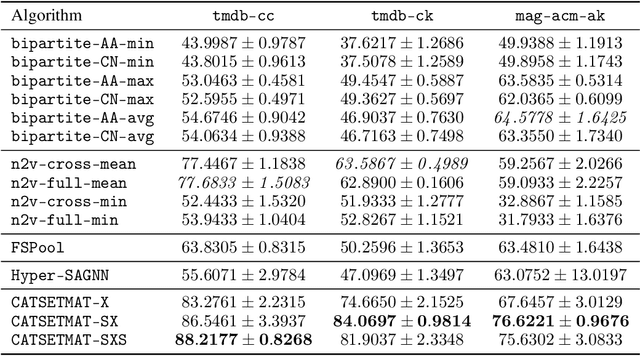
Usual relations between entities could be captured using graphs; but those of a higher-order -- more so between two different types of entities (which we term "left" and "right") -- calls for a "bipartite hypergraph". For example, given a left set of symptoms and right set of diseases, the relation between a set subset of symptoms (that a patient experiences at a given point of time) and a subset of diseases (that he/she might be diagnosed with) could be well-represented using a bipartite hyperedge. The state-of-the-art in embedding nodes of a hypergraph is based on learning the self-attention structure between node-pairs from a hyperedge. In the present work, given a bipartite hypergraph, we aim at capturing relations between node pairs from the cross-product between the left and right hyperedges, and term it a "cross-attention" (CAT) based model. More precisely, we pose "bipartite hyperedge link prediction" as a set-matching (SETMAT) problem and propose a novel neural network architecture called CATSETMAT for the same. We perform extensive experiments on multiple bipartite hypergraph datasets to show the superior performance of CATSETMAT, which we compare with multiple techniques from the state-of-the-art. Our results also elucidate information flow in self- and cross-attention scenarios.
DetectorNet: Transformer-enhanced Spatial Temporal Graph Neural Network for Traffic Prediction
Oct 19, 2021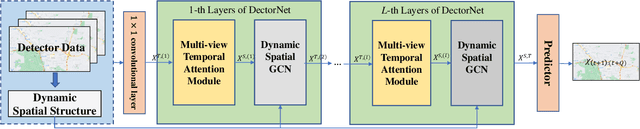

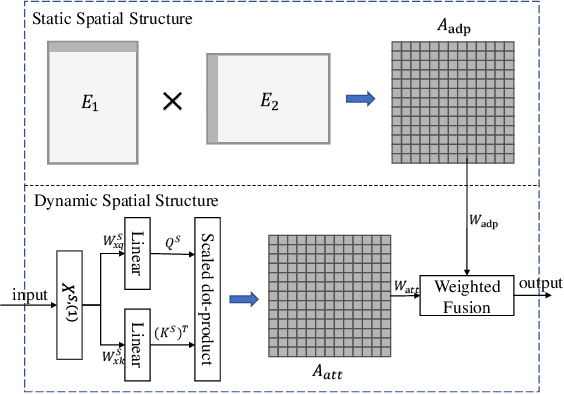
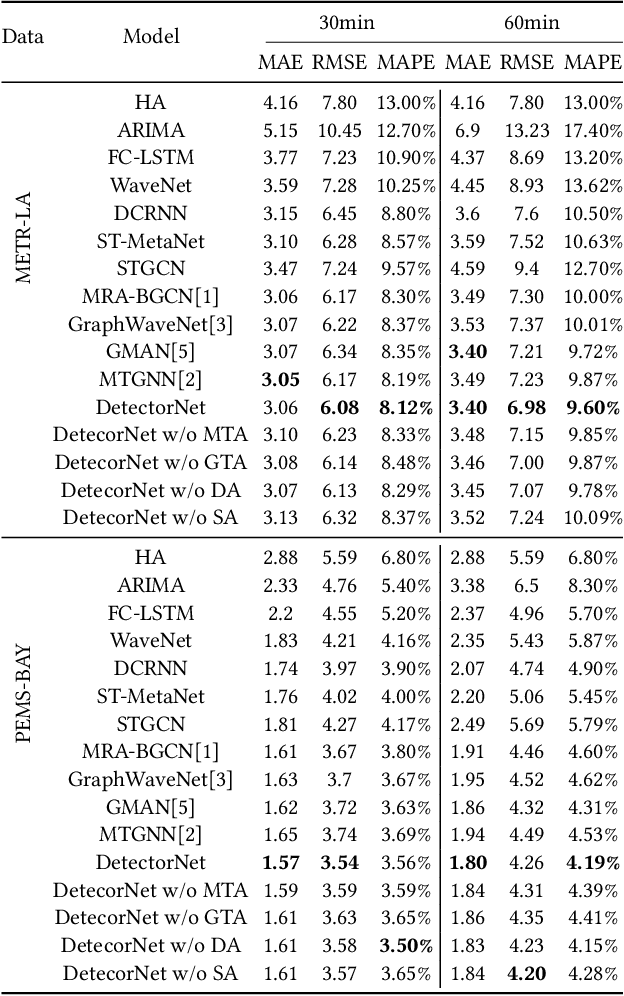
Detectors with high coverage have direct and far-reaching benefits for road users in route planning and avoiding traffic congestion, but utilizing these data presents unique challenges including: the dynamic temporal correlation, and the dynamic spatial correlation caused by changes in road conditions. Although the existing work considers the significance of modeling with spatial-temporal correlation, what it has learned is still a static road network structure, which cannot reflect the dynamic changes of roads, and eventually loses much valuable potential information. To address these challenges, we propose DetectorNet enhanced by Transformer. Differs from previous studies, our model contains a Multi-view Temporal Attention module and a Dynamic Attention module, which focus on the long-distance and short-distance temporal correlation, and dynamic spatial correlation by dynamically updating the learned knowledge respectively, so as to make accurate prediction. In addition, the experimental results on two public datasets and the comparison results of four ablation experiments proves that the performance of DetectorNet is better than the eleven advanced baselines.
PAMA-TTS: Progression-Aware Monotonic Attention for Stable Seq2Seq TTS With Accurate Phoneme Duration Control
Oct 09, 2021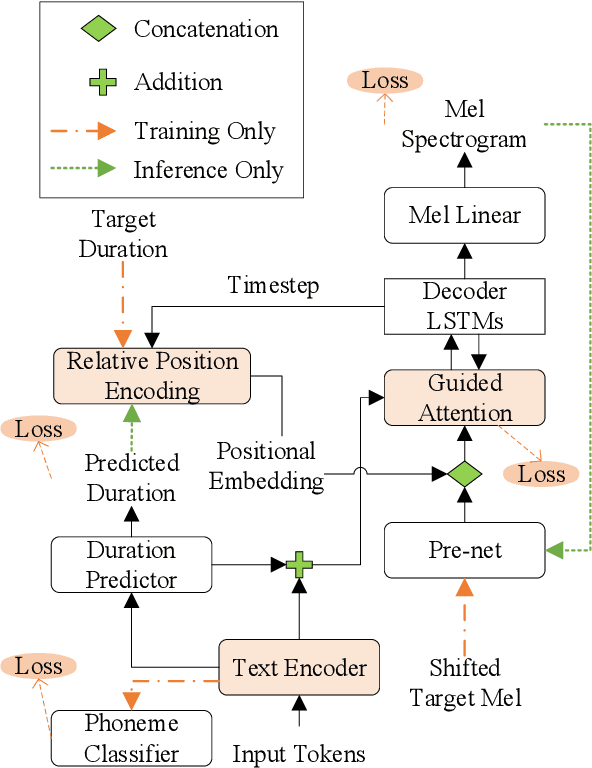
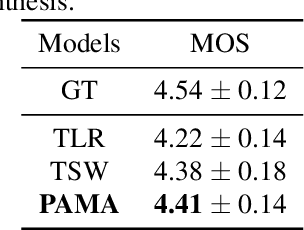
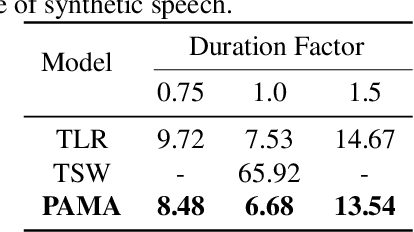
Sequence expansion between encoder and decoder is a critical challenge in sequence-to-sequence TTS. Attention-based methods achieve great naturalness but suffer from unstable issues like missing and repeating phonemes, not to mention accurate duration control. Duration-informed methods, on the contrary, seem to easily adjust phoneme duration but show obvious degradation in speech naturalness. This paper proposes PAMA-TTS to address the problem. It takes the advantage of both flexible attention and explicit duration models. Based on the monotonic attention mechanism, PAMA-TTS also leverages token duration and relative position of a frame, especially countdown information, i.e. in how many future frames the present phoneme will end. They help the attention to move forward along the token sequence in a soft but reliable control. Experimental results prove that PAMA-TTS achieves the highest naturalness, while has on-par or even better duration controllability than the duration-informed model.
Cross-Vendor CT Image Data Harmonization Using CVH-CT
Oct 19, 2021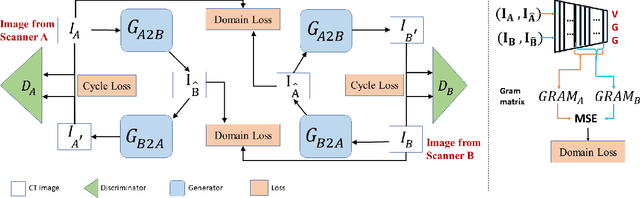

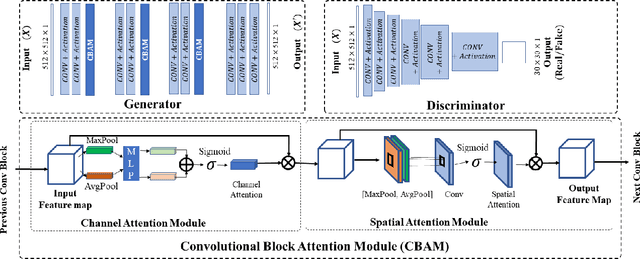
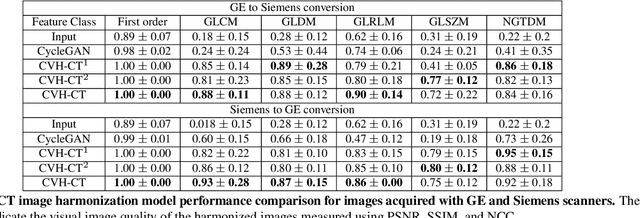
While remarkable advances have been made in Computed Tomography (CT), most of the existing efforts focus on imaging enhancement while reducing radiation dose. How to harmonize CT image data captured using different scanners is vital in cross-center large-scale radiomics studies but remains the boundary to explore. Furthermore, the lack of paired training image problem makes it computationally challenging to adopt existing deep learning models. %developed for CT image standardization. %this problem more challenging. We propose a novel deep learning approach called CVH-CT for harmonizing CT images captured using scanners from different vendors. The generator of CVH-CT uses a self-attention mechanism to learn the scanner-related information. We also propose a VGG feature-based domain loss to effectively extract texture properties from unpaired image data to learn the scanner-based texture distributions. The experimental results show that CVH-CT is clearly better than the baselines because of the use of the proposed domain loss, and CVH-CT can effectively reduce the scanner-related variability in terms of radiomic features.