 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Local Explanations for Clinical Search Engine results
Oct 19, 2021
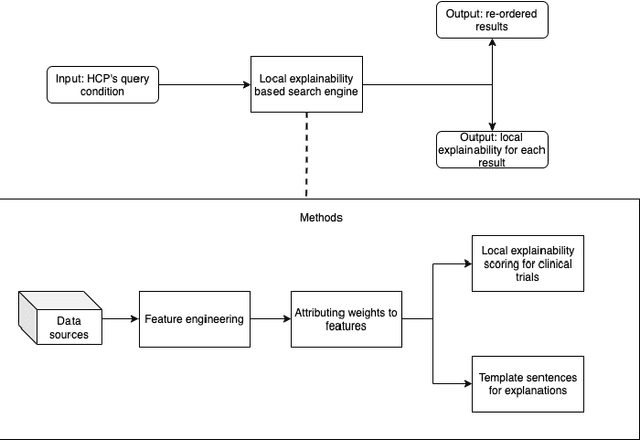
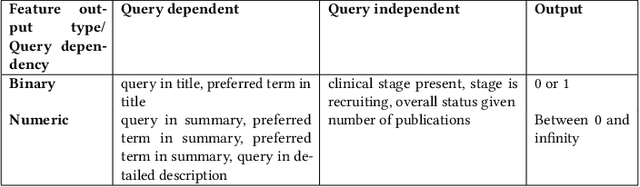
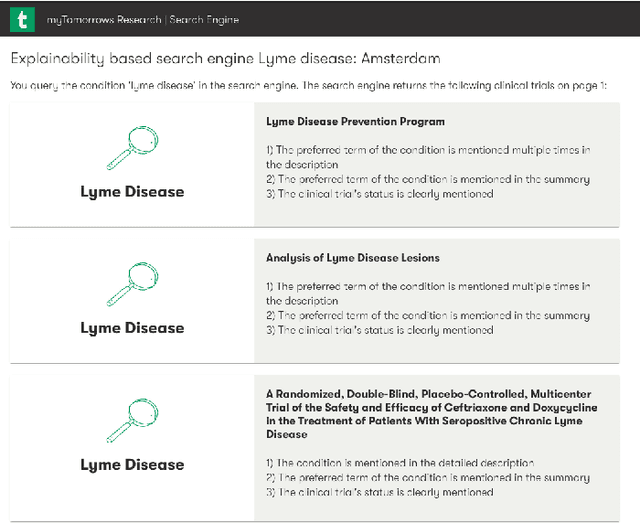
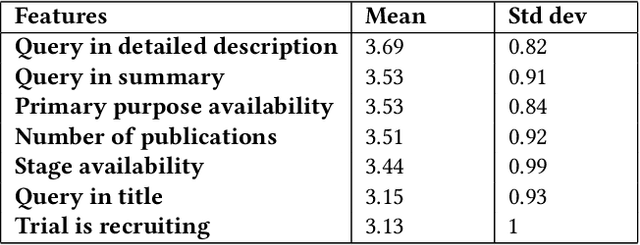
Health care professionals rely on treatment search engines to efficiently find adequate clinical trials and early access programs for their patients. However, doctors lose trust in the system if its underlying processes are unclear and unexplained. In this paper, a model-agnostic explainable method is developed to provide users with further information regarding the reasons why a clinical trial is retrieved in response to a query. To accomplish this, the engine generates features from clinical trials using by using a knowledge graph, clinical trial data and additional medical resources. and a crowd-sourcing methodology is used to determine their importance. Grounded on the proposed methodology, the rationale behind retrieving the clinical trials is explained in layman's terms so that healthcare processionals can effortlessly perceive them. In addition, we compute an explainability score for each of the retrieved items, according to which the items can be ranked. The experiments validated by medical professionals suggest that the proposed methodology induces trust in targeted as well as in non-targeted users, and provide them with reliable explanations and ranking of retrieved items.
MMIU: Dataset for Visual Intent Understanding in Multimodal Assistants
Oct 31, 2021
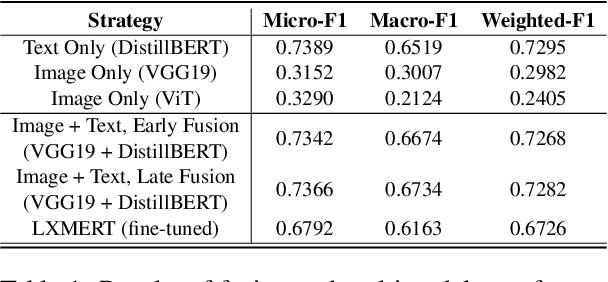


In multimodal assistant, where vision is also one of the input modalities, the identification of user intent becomes a challenging task as visual input can influence the outcome. Current digital assistants take spoken input and try to determine the user intent from conversational or device context. So, a dataset, which includes visual input (i.e. images or videos for the corresponding questions targeted for multimodal assistant use cases, is not readily available. The research in visual question answering (VQA) and visual question generation (VQG) is a great step forward. However, they do not capture questions that a visually-abled person would ask multimodal assistants. Moreover, many times questions do not seek information from external knowledge. In this paper, we provide a new dataset, MMIU (MultiModal Intent Understanding), that contains questions and corresponding intents provided by human annotators while looking at images. We, then, use this dataset for intent classification task in multimodal digital assistant. We also experiment with various approaches for combining vision and language features including the use of multimodal transformer for classification of image-question pairs into 14 intents. We provide the benchmark results and discuss the role of visual and text features for the intent classification task on our dataset.
See Yourself in Others: Attending Multiple Tasks for Own Failure Detection
Oct 06, 2021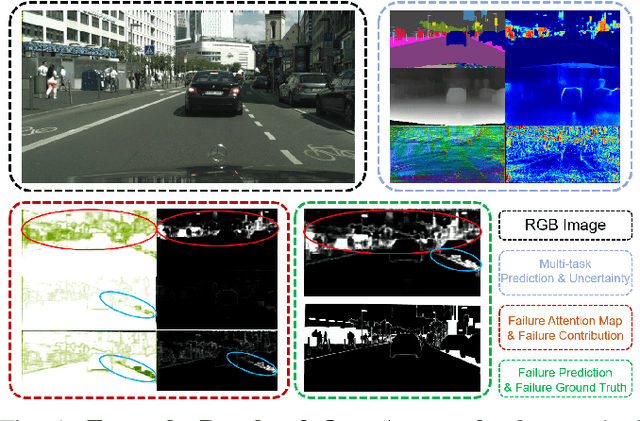
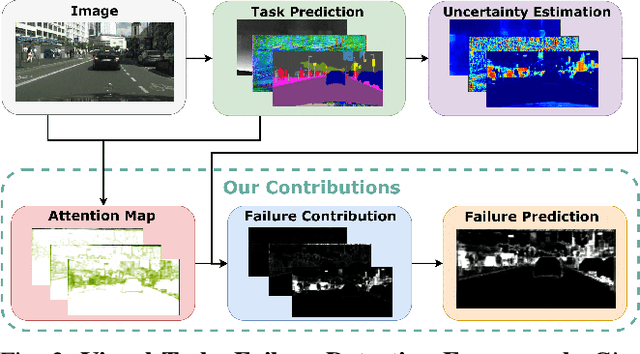
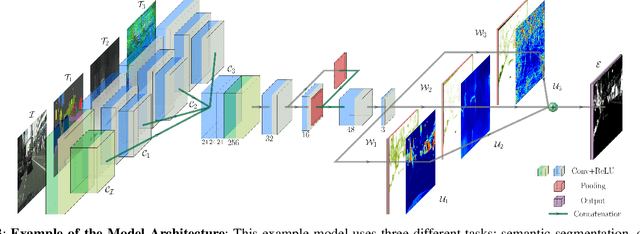
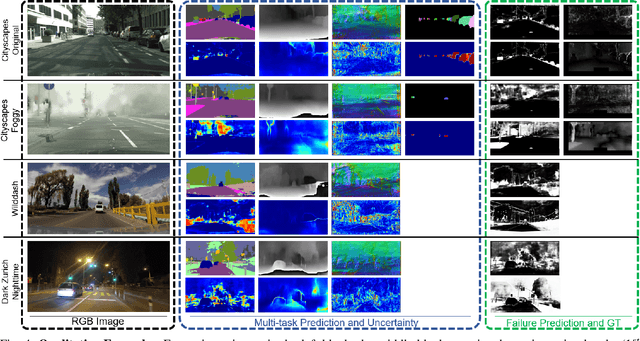
Autonomous robots deal with unexpected scenarios in real environments. Given input images, various visual perception tasks can be performed, e.g., semantic segmentation, depth estimation and normal estimation. These different tasks provide rich information for the whole robotic perception system. All tasks have their own characteristics while sharing some latent correlations. However, some of the task predictions may suffer from the unreliability dealing with complex scenes and anomalies. We propose an attention-based failure detection approach by exploiting the correlations among multiple tasks. The proposed framework infers task failures by evaluating the individual prediction, across multiple visual perception tasks for different regions in an image. The formulation of the evaluations is based on an attention network supervised by multi-task uncertainty estimation and their corresponding prediction errors. Our proposed framework generates more accurate estimations of the prediction error for the different task's predictions.
Image-free single-pixel segmentation
Aug 24, 2021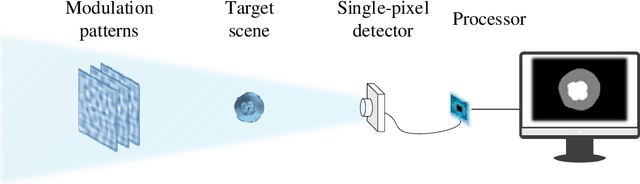
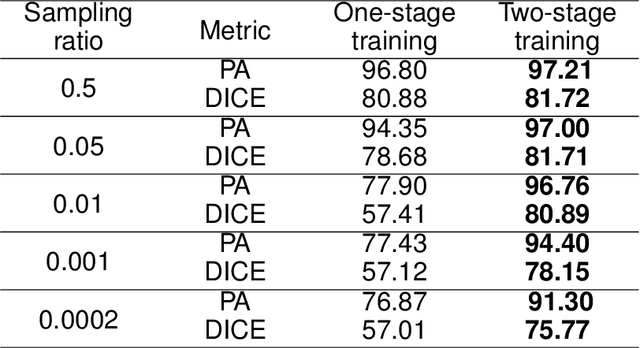
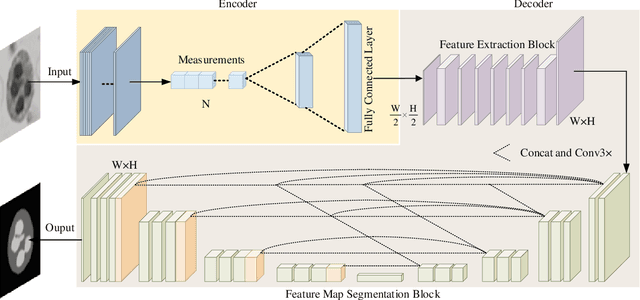

The existing segmentation techniques require high-fidelity images as input to perform semantic segmentation. Since the segmentation results contain most of edge information that is much less than the acquired images, the throughput gap leads to both hardware and software waste. In this letter, we report an image-free single-pixel segmentation technique. The technique combines structured illumination and single-pixel detection together, to efficiently samples and multiplexes scene's segmentation information into compressed one-dimensional measurements. The illumination patterns are optimized together with the subsequent reconstruction neural network, which directly infers segmentation maps from the single-pixel measurements. The end-to-end encoding-and-decoding learning framework enables optimized illumination with corresponding network, which provides both high acquisition and segmentation efficiency. Both simulation and experimental results validate that accurate segmentation can be achieved using two-order-of-magnitude less input data. When the sampling ratio is 1%, the Dice coefficient reaches above 80% and the pixel accuracy reaches above 96%. We envision that this image-free segmentation technique can be widely applied in various resource-limited platforms such as UAV and unmanned vehicle that require real-time sensing.
Approaching the Limit of Image Rescaling via Flow Guidance
Nov 09, 2021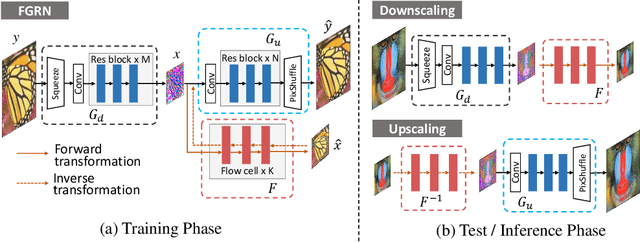
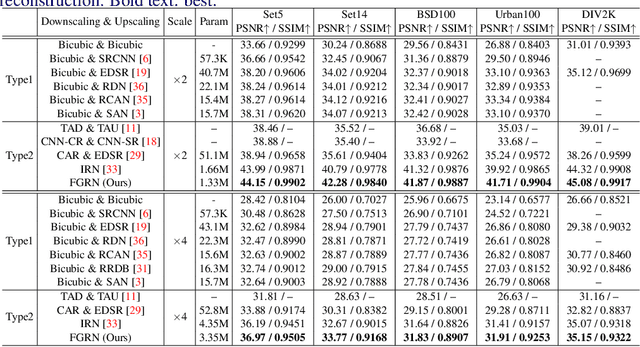
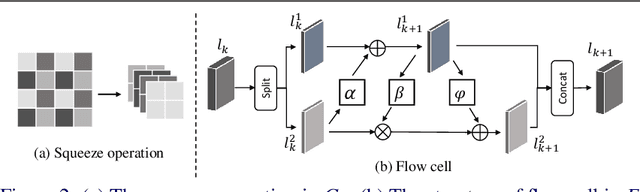
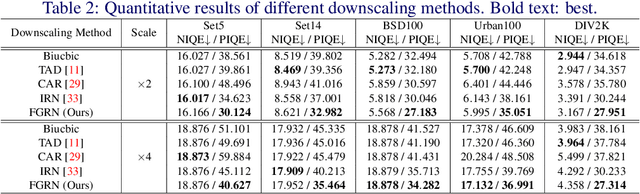
Image downscaling and upscaling are two basic rescaling operations. Once the image is downscaled, it is difficult to be reconstructed via upscaling due to the loss of information. To make these two processes more compatible and improve the reconstruction performance, some efforts model them as a joint encoding-decoding task, with the constraint that the downscaled (i.e. encoded) low-resolution (LR) image must preserve the original visual appearance. To implement this constraint, most methods guide the downscaling module by supervising it with the bicubically downscaled LR version of the original high-resolution (HR) image. However, this bicubic LR guidance may be suboptimal for the subsequent upscaling (i.e. decoding) and restrict the final reconstruction performance. In this paper, instead of directly applying the LR guidance, we propose an additional invertible flow guidance module (FGM), which can transform the downscaled representation to the visually plausible image during downscaling and transform it back during upscaling. Benefiting from the invertibility of FGM, the downscaled representation could get rid of the LR guidance and would not disturb the downscaling-upscaling process. It allows us to remove the restrictions on the downscaling module and optimize the downscaling and upscaling modules in an end-to-end manner. In this way, these two modules could cooperate to maximize the HR reconstruction performance. Extensive experiments demonstrate that the proposed method can achieve state-of-the-art (SotA) performance on both downscaled and reconstructed images.
Deep Hybrid Self-Prior for Full 3D Mesh Generation
Aug 24, 2021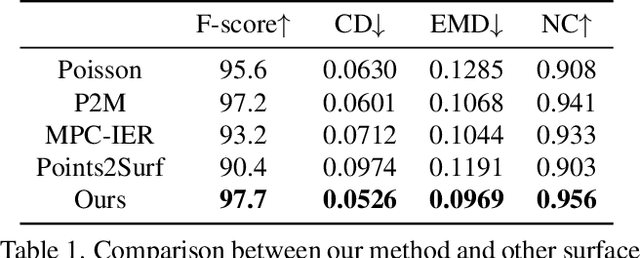
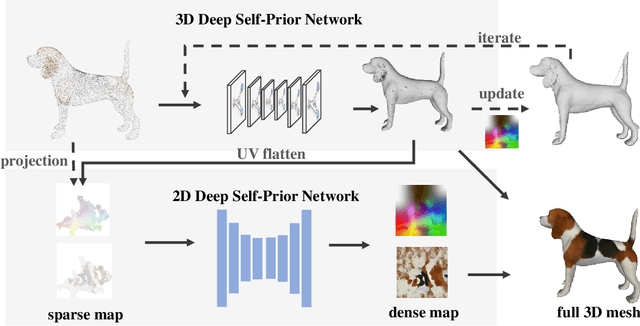
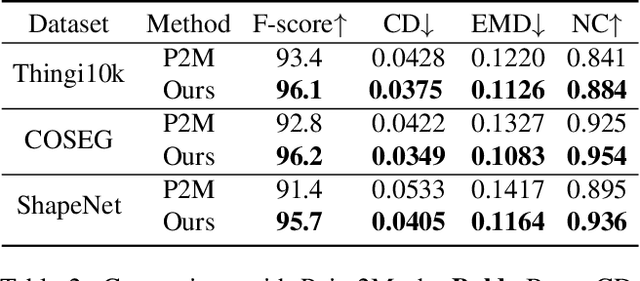
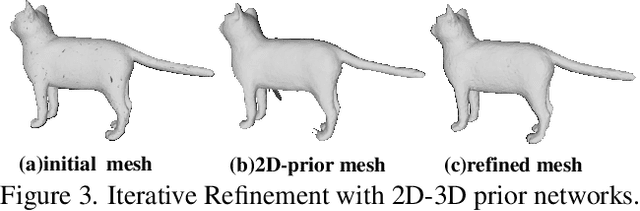
We present a deep learning pipeline that leverages network self-prior to recover a full 3D model consisting of both a triangular mesh and a texture map from the colored 3D point cloud. Different from previous methods either exploiting 2D self-prior for image editing or 3D self-prior for pure surface reconstruction, we propose to exploit a novel hybrid 2D-3D self-prior in deep neural networks to significantly improve the geometry quality and produce a high-resolution texture map, which is typically missing from the output of commodity-level 3D scanners. In particular, we first generate an initial mesh using a 3D convolutional neural network with 3D self-prior, and then encode both 3D information and color information in the 2D UV atlas, which is further refined by 2D convolutional neural networks with the self-prior. In this way, both 2D and 3D self-priors are utilized for the mesh and texture recovery. Experiments show that, without the need of any additional training data, our method recovers the 3D textured mesh model of high quality from sparse input, and outperforms the state-of-the-art methods in terms of both the geometry and texture quality.
2D Multi-Class Model for Gray and White Matter Segmentation of the Cervical Spinal Cord at 7T
Oct 13, 2021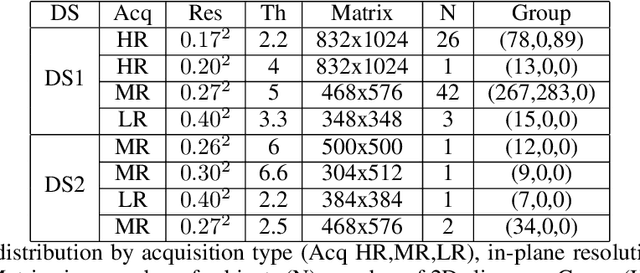
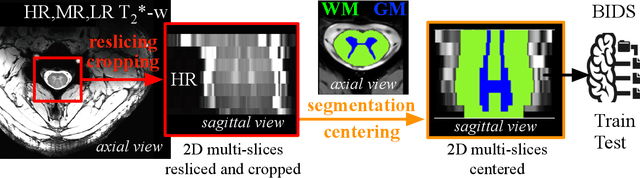
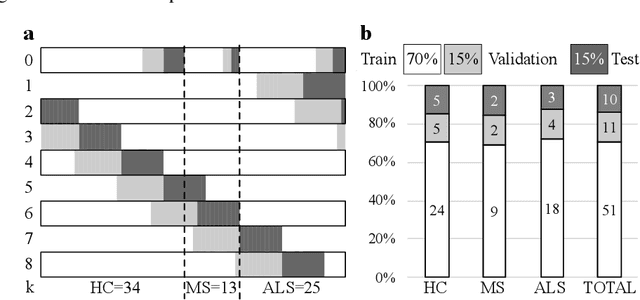
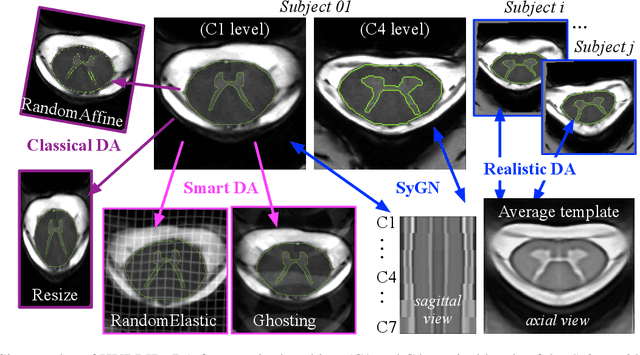
The spinal cord (SC), which conveys information between the brain and the peripheral nervous system, plays a key role in various neurological disorders such as multiple sclerosis (MS) and amyotrophic lateral sclerosis (ALS), in which both gray matter (GM) and white matter (WM) may be impaired. While automated methods for WM/GM segmentation are now largely available, these techniques, developed for conventional systems (3T or lower) do not necessarily perform well on 7T MRI data, which feature finer details, contrasts, but also different artifacts or signal dropout. The primary goal of this study is thus to propose a new deep learning model that allows robust SC/GM multi-class segmentation based on ultra-high resolution 7T T2*-w MR images. The second objective is to highlight the relevance of implementing a specific data augmentation (DA) strategy, in particular to generate a generic model that could be used for multi-center studies at 7T.
Learning Meta Representations for Agents in Multi-Agent Reinforcement Learning
Aug 30, 2021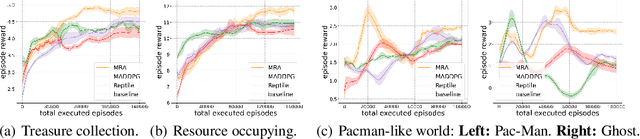
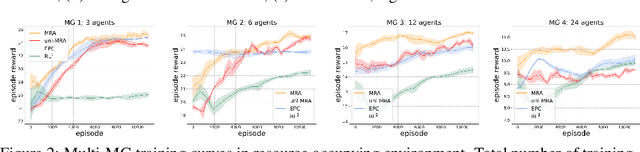

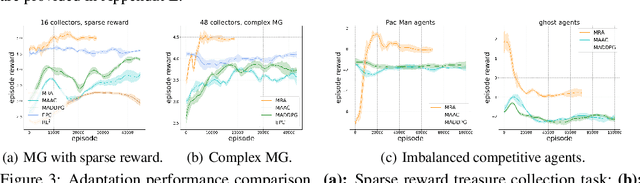
In multi-agent reinforcement learning, the behaviors that agents learn in a single Markov Game (MG) are typically confined to the given agent number (i.e., population size). Every single MG induced by varying population sizes may possess distinct optimal joint strategies and game-specific knowledge, which are modeled independently in modern multi-agent algorithms. In this work, we focus on creating agents that generalize across population-varying MGs. Instead of learning a unimodal policy, each agent learns a policy set that is formed by effective strategies across a variety of games. We propose Meta Representations for Agents (MRA) that explicitly models the game-common and game-specific strategic knowledge. By representing the policy sets with multi-modal latent policies, the common strategic knowledge and diverse strategic modes are discovered with an iterative optimization procedure. We prove that as an approximation to a constrained mutual information maximization objective, the learned policies can reach Nash Equilibrium in every evaluation MG under the assumption of Lipschitz game on a sufficiently large latent space. When deploying it at practical latent models with limited size, fast adaptation can be achieved by leveraging the first-order gradient information. Extensive experiments show the effectiveness of MRA on both training performance and generalization ability in hard and unseen games.
Hierarchical Bayesian Model for the Transfer of Knowledge on Spatial Concepts based on Multimodal Information
Mar 11, 2021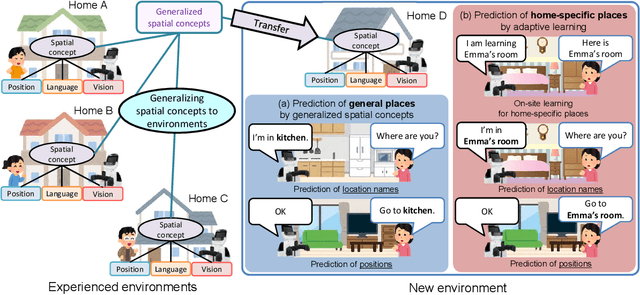

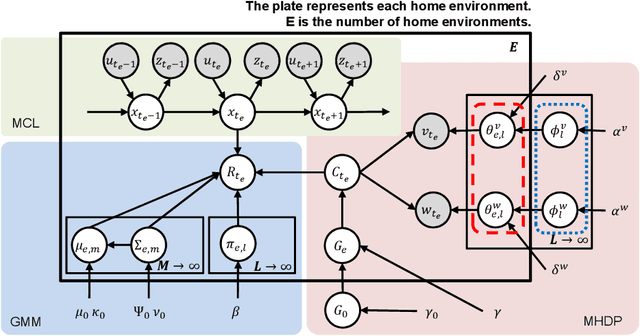
This paper proposes a hierarchical Bayesian model based on spatial concepts that enables a robot to transfer the knowledge of places from experienced environments to a new environment. The transfer of knowledge based on spatial concepts is modeled as the calculation process of the posterior distribution based on the observations obtained in each environment with the parameters of spatial concepts generalized to environments as prior knowledge. We conducted experiments to evaluate the generalization performance of spatial knowledge for general places such as kitchens and the adaptive performance of spatial knowledge for unique places such as `Emma's room' in a new environment. In the experiments, the accuracies of the proposed method and conventional methods were compared in the prediction task of location names from an image and a position, and the prediction task of positions from a location name. The experimental results demonstrated that the proposed method has a higher prediction accuracy of location names and positions than the conventional method owing to the transfer of knowledge.
Idiomatic Expression Identification using Semantic Compatibility
Oct 19, 2021
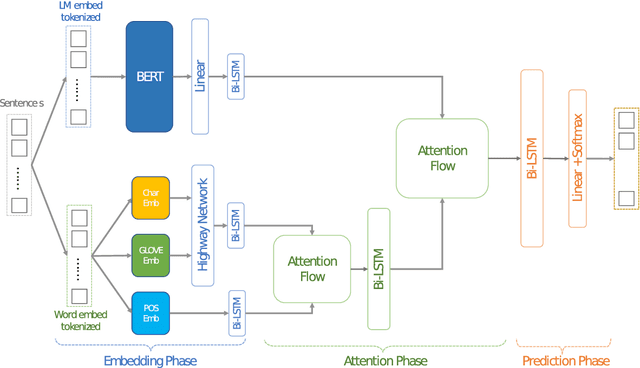
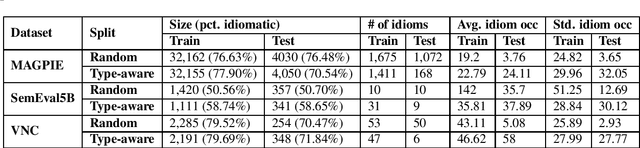
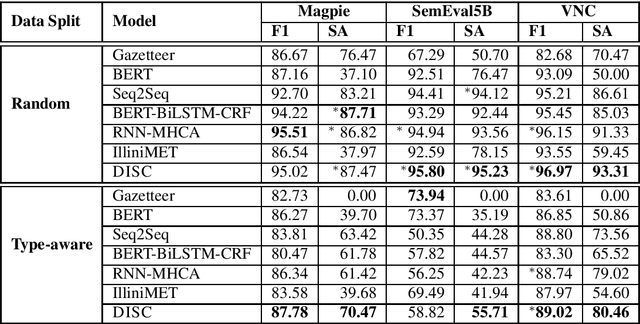
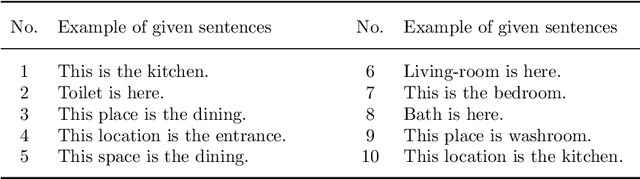
Idiomatic expressions are an integral part of natural language and constantly being added to a language. Owing to their non-compositionality and their ability to take on a figurative or literal meaning depending on the sentential context, they have been a classical challenge for NLP systems. To address this challenge, we study the task of detecting whether a sentence has an idiomatic expression and localizing it. Prior art for this task had studied specific classes of idiomatic expressions offering limited views of their generalizability to new idioms. We propose a multi-stage neural architecture with the attention flow mechanism for identifying these expressions. The network effectively fuses contextual and lexical information at different levels using word and sub-word representations. Empirical evaluations on three of the largest benchmark datasets with idiomatic expressions of varied syntactic patterns and degrees of non-compositionality show that our proposed model achieves new state-of-the-art results. A salient feature of the model is its ability to identify idioms unseen during training with gains from 1.4% to 30.8% over competitive baselines on the largest dataset.