 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Resilient Time-Varying Formation Tracking for Mobile Robot Networks under Deception Attacks on Positioning
Oct 20, 2021
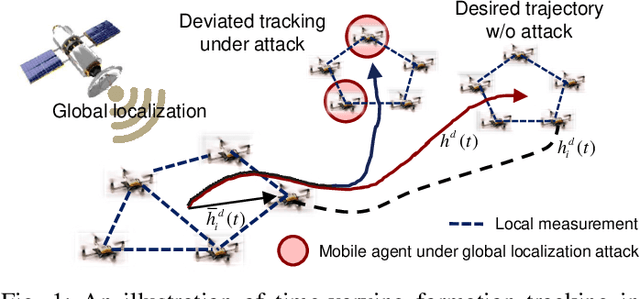
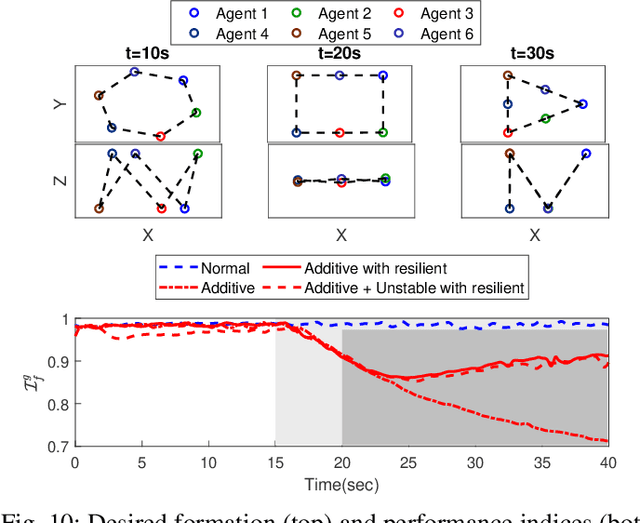
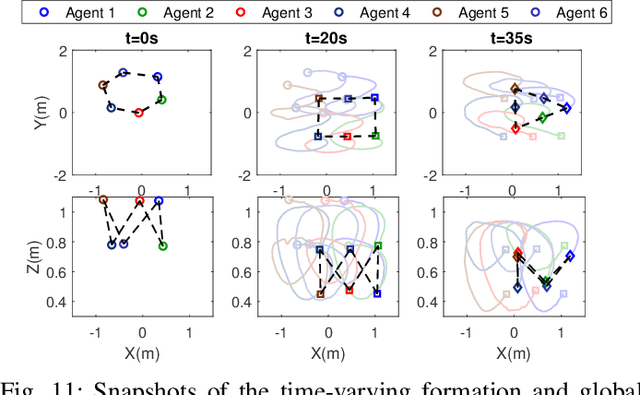
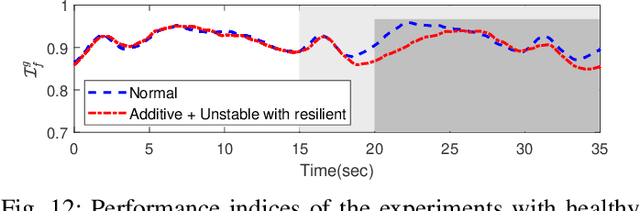
This paper investigates the resilient control, analysis, recovery, and operation of mobile robot networks in time-varying formation tracking under deception attacks on global positioning. Local and global tracking control algorithms are presented to ensure redundancy of the mobile robot network and to retain the desired functionality for better resilience. Lyapunov stability analysis is utilized to show the boundedness of the formation tracking error and the stability of the network under various attack modes. A performance index is designed to compare the efficiency of the proposed formation tracking algorithms in situations with or without positioning attacks. Subsequently, a communication-free decentralized cooperative localization approach based on extended information filters is presented for positioning estimate recovery where the identification of the positioning attacks is based on Kullback-Leibler divergence. A gain-tuning resilient operation is proposed to strategically synthesize the formation control and cooperative localization for accurate and rapid system recovery from positioning attacks. The proposed methods are tested using both numerical simulation and experimental validation with a team of quadrotors.
AutoDiscern: Rating the Quality of Online Health Information with Hierarchical Encoder Attention-based Neural Networks
Dec 30, 2019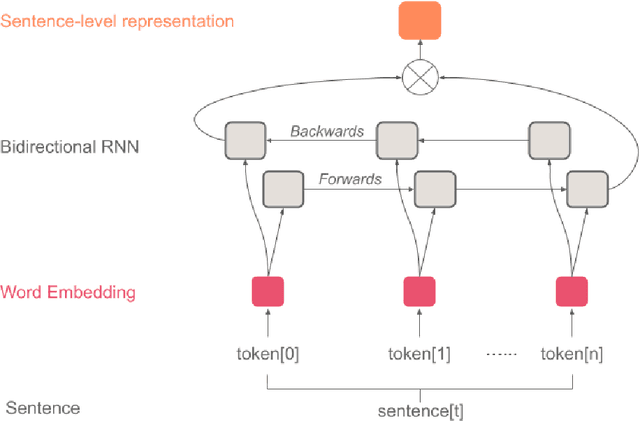
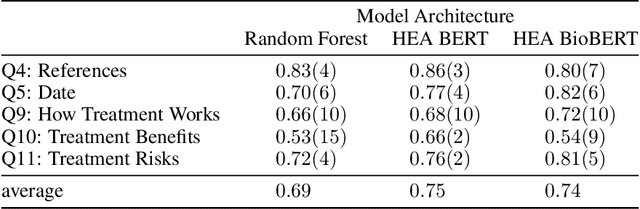
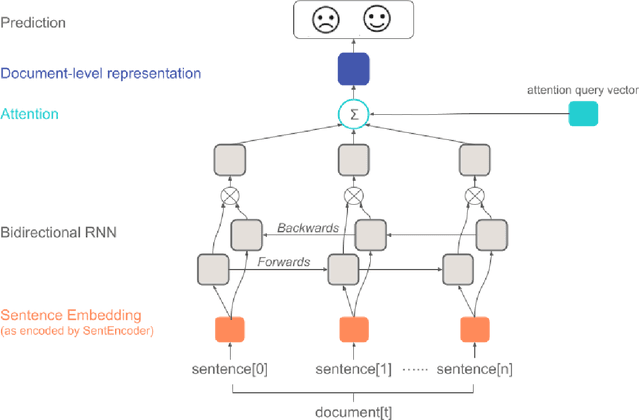
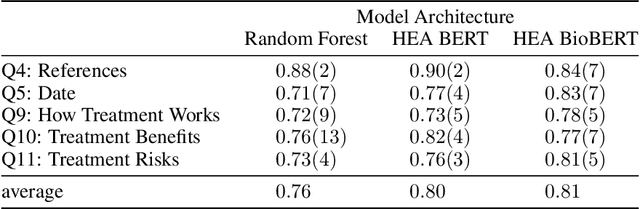
Patients increasingly turn to search engines and online content before, or in place of, talking with a health professional. Low quality health information, which is common on the internet, presents risks to the patient in the form of misinformation and a possibly poorer relationship to their physician. To address this, the DISCERN criteria (developed at University of Oxford) are used to evaluate the quality of online health information. However, patients are unlikely to take the time to apply these criteria to the health websites they visit. We built an automated implementation of the DISCERN instrument (Brief version) using machine learning models. We compared the use of a traditional model (Random Forest) with a hierarchical encoder attention-based neural network (HEA) model using two language embeddings based on BERT and BioBERT. The HEA BERT and BioBERT models achieved F1-macro scores averaging 0.75 and 0.74, respectively, on all criteria outperforming the Random Forest model (F1-macro = 0.69). Similarly, HEA BERT and BioBERT scored on average 0.8 and 0.81 (F1-micro) vs. 0.76 for the Random Forest model. Overall, the neural network based models achieved 81% and 86% average accuracy at 100% and 80% coverage, respectively, compared to 94% manual rating accuracy. The attention mechanism implemented in the HEA architectures provided 'model explainability' by identifying reasonable supporting sentences for the documents fulfilling the Brief DISCERN criteria. Our research suggests that it is feasible to automate online health information quality assessment, which is an important step towards empowering patients to become informed partners in the healthcare process.
YOLO-ReT: Towards High Accuracy Real-time Object Detection on Edge GPUs
Oct 26, 2021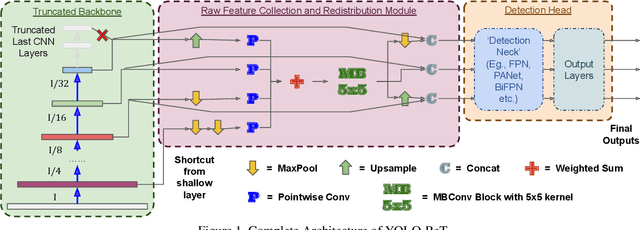
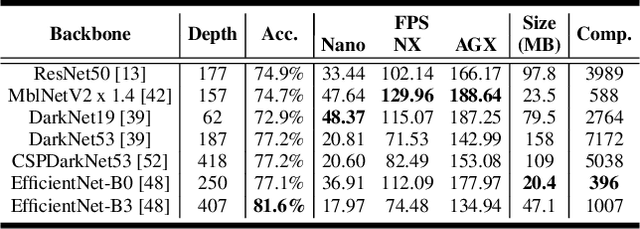
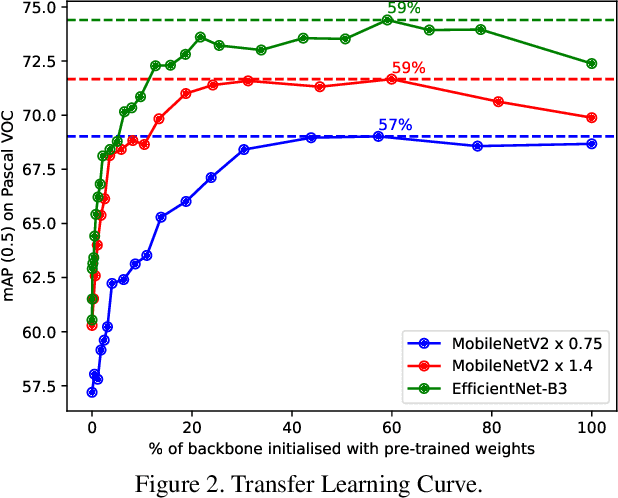
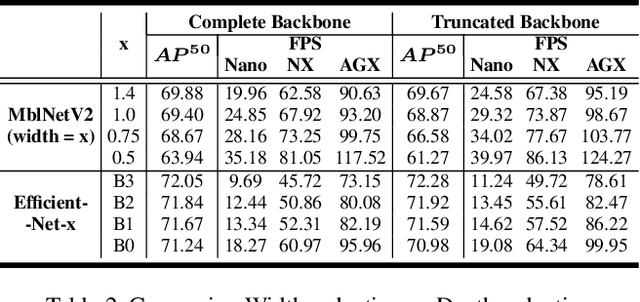
Performance of object detection models has been growing rapidly on two major fronts, model accuracy and efficiency. However, in order to map deep neural network (DNN) based object detection models to edge devices, one typically needs to compress such models significantly, thus compromising the model accuracy. In this paper, we propose a novel edge GPU friendly module for multi-scale feature interaction by exploiting missing combinatorial connections between various feature scales in existing state-of-the-art methods. Additionally, we propose a novel transfer learning backbone adoption inspired by the changing translational information flow across various tasks, designed to complement our feature interaction module and together improve both accuracy as well as execution speed on various edge GPU devices available in the market. For instance, YOLO-ReT with MobileNetV2x0.75 backbone runs real-time on Jetson Nano, and achieves 68.75 mAP on Pascal VOC and 34.91 mAP on COCO, beating its peers by 3.05 mAP and 0.91 mAP respectively, while executing faster by 3.05 FPS. Furthermore, introducing our multi-scale feature interaction module in YOLOv4-tiny and YOLOv4-tiny (3l) improves their performance to 41.5 and 48.1 mAP respectively on COCO, outperforming the original versions by 1.3 and 0.9 mAP.
Information-Theoretic Bounds on the Generalization Error and Privacy Leakage in Federated Learning
May 05, 2020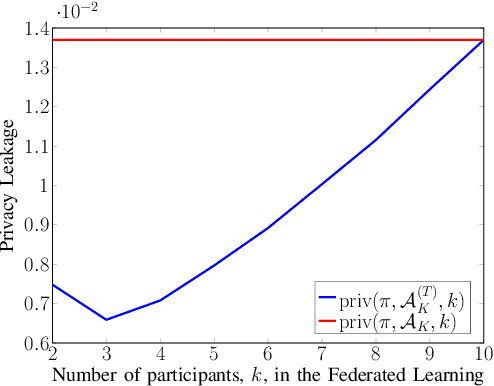
Machine learning algorithms operating on mobile networks can be characterized into three different categories. First is the classical situation in which the end-user devices send their data to a central server where this data is used to train a model. Second is the distributed setting in which each device trains its own model and send its model parameters to a central server where these model parameters are aggregated to create one final model. Third is the federated learning setting in which, at any given time $t$, a certain number of active end users train with their own local data along with feedback provided by the central server and then send their newly estimated model parameters to the central server. The server, then, aggregates these new parameters, updates its own model, and feeds the updated parameters back to all the end users, continuing this process until it converges. The main objective of this work is to provide an information-theoretic framework for all of the aforementioned learning paradigms. Moreover, using the provided framework, we develop upper and lower bounds on the generalization error together with bounds on the privacy leakage in the classical, distributed and federated learning settings. Keywords: Federated Learning, Distributed Learning, Machine Learning, Model Aggregation.
SINet: Extreme Lightweight Portrait Segmentation Networks with Spatial Squeeze Modules and Information Blocking Decoder
Dec 09, 2019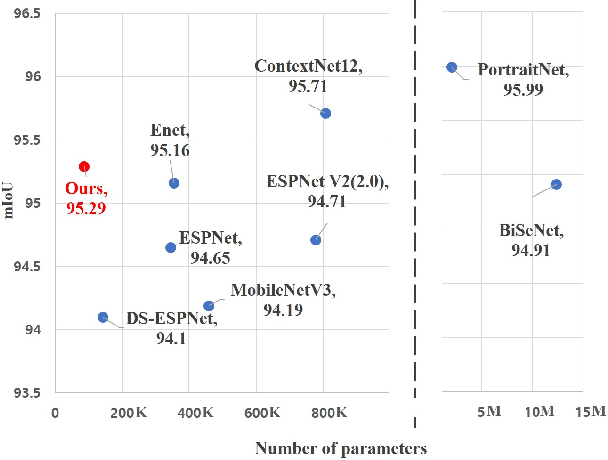


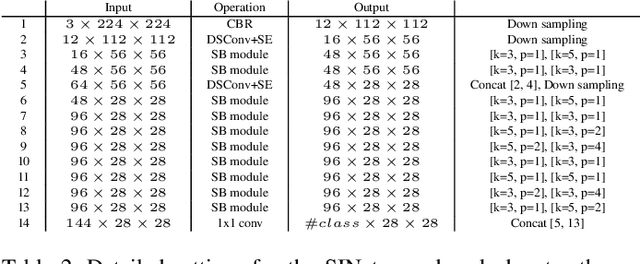
Designing a lightweight and robust portrait segmentation algorithm is an important task for a wide range of face applications. However, the problem has been considered as a subset of the object segmentation problem and less handled in the semantic segmentation field. Obviously, portrait segmentation has its unique requirements. First, because the portrait segmentation is performed in the middle of a whole process of many real-world applications, it requires extremely lightweight models. Second, there has not been any public datasets in this domain that contain a sufficient number of images with unbiased statistics. To solve the first problem, we introduce the new extremely lightweight portrait segmentation model SINet, containing an information blocking decoder and spatial squeeze modules. The information blocking decoder uses confidence estimates to recover local spatial information without spoiling global consistency. The spatial squeeze module uses multiple receptive fields to cope with various sizes of consistency in the image. To tackle the second problem, we propose a simple method to create additional portrait segmentation data which can improve accuracy on the EG1800 dataset. In our qualitative and quantitative analysis on the EG1800 dataset, we show that our method outperforms various existing lightweight segmentation models. Our method reduces the number of parameters from 2.1M to 86.9K (around 95.9% reduction), while maintaining the accuracy under an 1% margin from the state-of-the-art portrait segmentation method. We also show our model is successfully executed on a real mobile device with 100.6 FPS. In addition, we demonstrate that our method can be used for general semantic segmentation on the Cityscapes dataset. The code and dataset are available in https://github.com/HYOJINPARK/ExtPortraitSeg .
GlassNet: Label Decoupling-based Three-stream Neural Network for Robust Image Glass Detection
Aug 25, 2021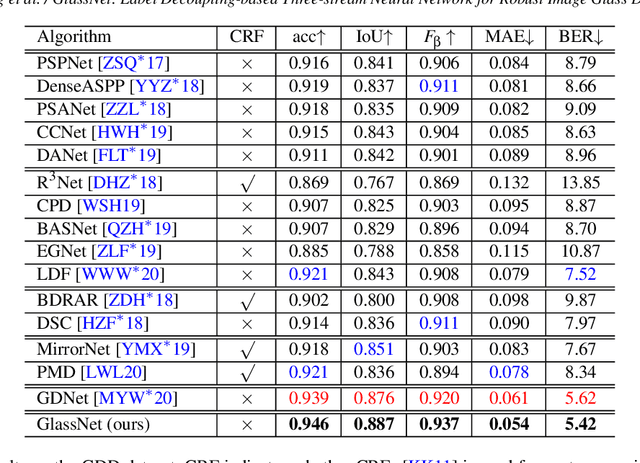

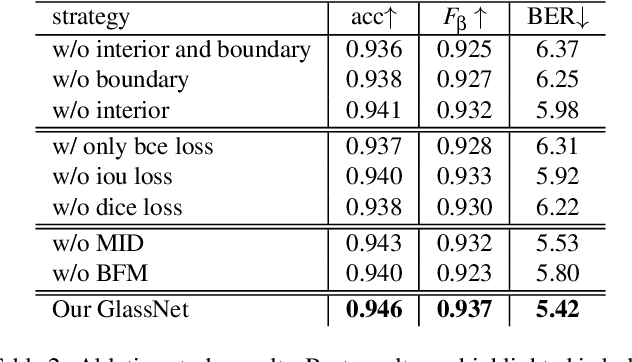

Most of the existing object detection methods generate poor glass detection results, due to the fact that the transparent glass shares the same appearance with arbitrary objects behind it in an image. Different from traditional deep learning-based wisdoms that simply use the object boundary as auxiliary supervision, we exploit label decoupling to decompose the original labeled ground-truth (GT) map into an interior-diffusion map and a boundary-diffusion map. The GT map in collaboration with the two newly generated maps breaks the imbalanced distribution of the object boundary, leading to improved glass detection quality. We have three key contributions to solve the transparent glass detection problem: (1) We propose a three-stream neural network (call GlassNet for short) to fully absorb beneficial features in the three maps. (2) We design a multi-scale interactive dilation module to explore a wider range of contextual information. (3) We develop an attention-based boundary-aware feature Mosaic module to integrate multi-modal information. Extensive experiments on the benchmark dataset exhibit clear improvements of our method over SOTAs, in terms of both the overall glass detection accuracy and boundary clearness.
A Precision Diagnostic Framework of Renal Cell Carcinoma on Whole-Slide Images using Deep Learning
Oct 26, 2021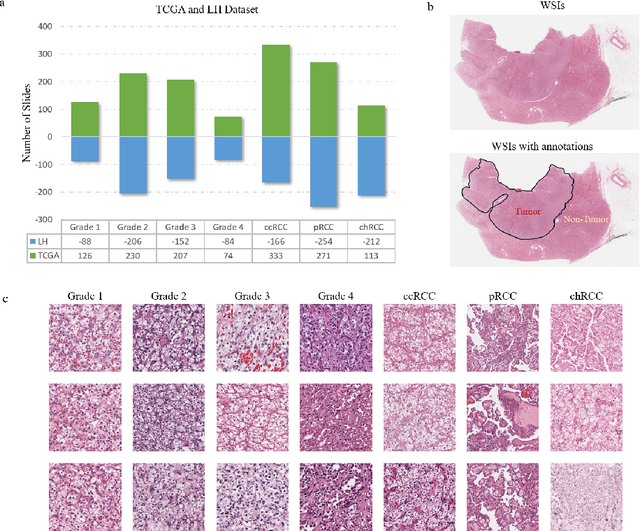
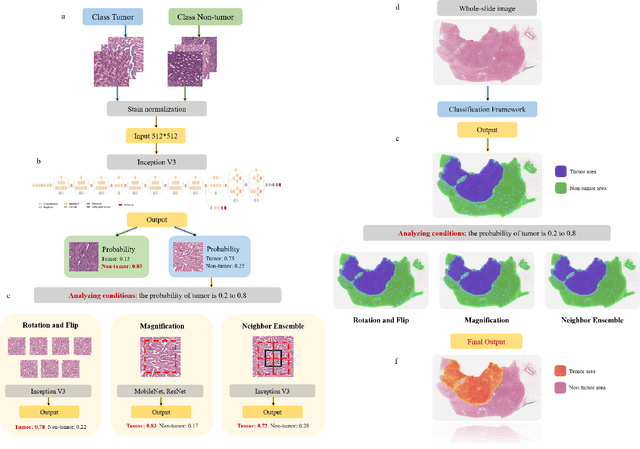
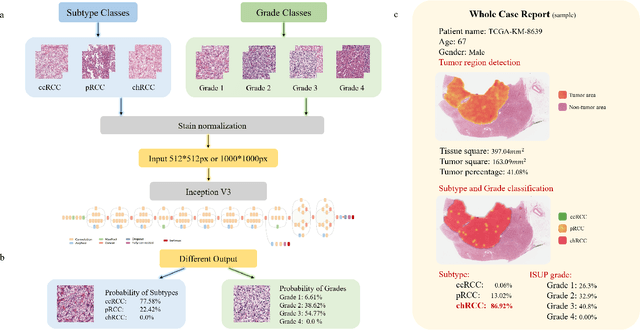
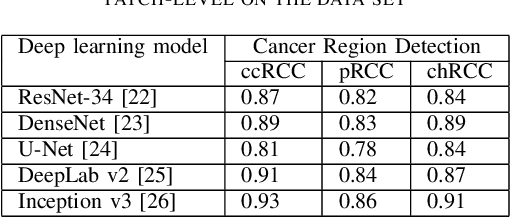
Diagnostic pathology, which is the basis and gold standard of cancer diagnosis, provides essential information on the prognosis of the disease and vital evidence for clinical treatment. Tumor region detection, subtype and grade classification are the fundamental diagnostic indicators for renal cell carcinoma (RCC) in whole-slide images (WSIs). However, pathological diagnosis is subjective, differences in observation and diagnosis between pathologists is common in hospitals with inadequate diagnostic capacity. The main challenge for developing deep learning based RCC diagnostic system is the lack of large-scale datasets with precise annotations. In this work, we proposed a deep learning-based framework for analyzing histopathological images of patients with renal cell carcinoma, which has the potential to achieve pathologist-level accuracy in diagnosis. A deep convolutional neural network (InceptionV3) was trained on the high-quality annotated dataset of The Cancer Genome Atlas (TCGA) whole-slide histopathological image for accurate tumor area detection, classification of RCC subtypes, and ISUP grades classification of clear cell carcinoma subtypes. These results suggest that our framework can help pathologists in the detection of cancer region and classification of subtypes and grades, which could be applied to any cancer type, providing auxiliary diagnosis and promoting clinical consensus.
Managed Forgetting to Support Information Management and Knowledge Work
Nov 17, 2018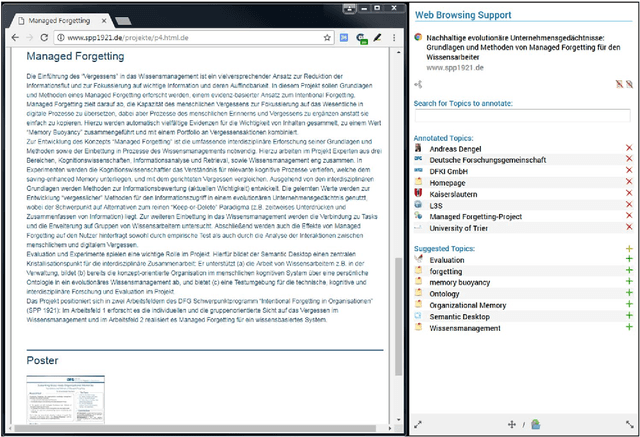
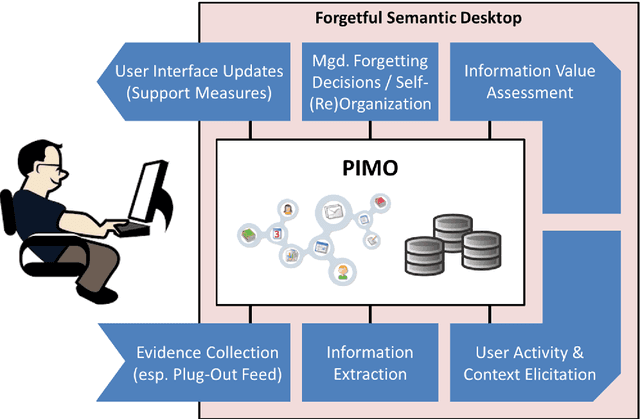
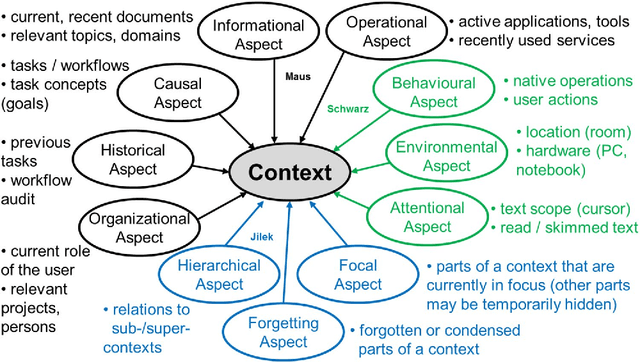
Trends like digital transformation even intensify the already overwhelming mass of information knowledge workers face in their daily life. To counter this, we have been investigating knowledge work and information management support measures inspired by human forgetting. In this paper, we give an overview of solutions we have found during the last five years as well as challenges that still need to be tackled. Additionally, we share experiences gained with the prototype of a first forgetful information system used 24/7 in our daily work for the last three years. We also address the untapped potential of more explicated user context as well as features inspired by Memory Inhibition, which is our current focus of research.
Making the Last Iterate of SGD Information Theoretically Optimal
Apr 29, 2019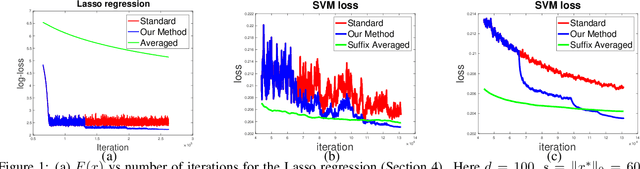
Stochastic gradient descent (SGD) is one of the most widely used algorithms for large scale optimization problems. While classical theoretical analysis of SGD for convex problems studies (suffix) \emph{averages} of iterates and obtains information theoretically optimal bounds on suboptimality, the \emph{last point} of SGD is, by far, the most preferred choice in practice. The best known results for last point of SGD~\cite{shamir2013stochastic} however, are suboptimal compared to information theoretic lower bounds by a $\log T$ factor, where $T$ is the number of iterations.~\cite{harvey2018tight} shows that in fact, this additional $\log T$ factor is tight for standard step size sequences of $\OTheta{\frac{1}{\sqrt{t}}}$ and $\OTheta{\frac{1}{t}}$ for non-strongly convex and strongly convex settings, respectively. Similarly, even for subgradient descent (GD) when applied to non-smooth, convex functions, the best known step-size sequences still lead to $O(\log T)$-suboptimal convergence rates (on the final iterate). The main contribution of this work is to design new step size sequences that enjoy information theoretically optimal bounds on the suboptimality of \emph{last point} of SGD as well as GD. We achieve this by designing a modification scheme, that converts one sequence of step sizes to another so that the last point of SGD/GD with modified sequence has the same suboptimality guarantees as the average of SGD/GD with original sequence. We also show that our result holds with high-probability. We validate our results through simulations which demonstrate that the new step size sequence indeed improves the final iterate significantly compared to the standard step size sequences.
Understanding of Kernels in CNN Models by Suppressing Irrelevant Visual Features in Images
Aug 25, 2021
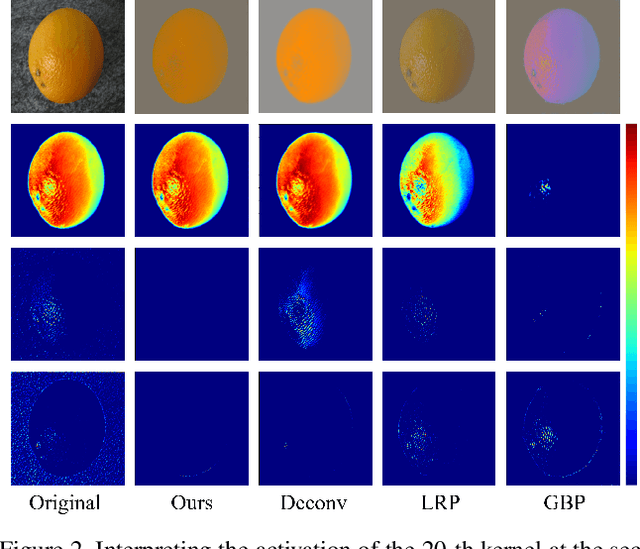


Deep learning models have shown their superior performance in various vision tasks. However, the lack of precisely interpreting kernels in convolutional neural networks (CNNs) is becoming one main obstacle to wide applications of deep learning models in real scenarios. Although existing interpretation methods may find certain visual patterns which are associated with the activation of a specific kernel, those visual patterns may not be specific or comprehensive enough for interpretation of a specific activation of kernel of interest. In this paper, a simple yet effective optimization method is proposed to interpret the activation of any kernel of interest in CNN models. The basic idea is to simultaneously preserve the activation of the specific kernel and suppress the activation of all other kernels at the same layer. In this way, only visual information relevant to the activation of the specific kernel is remained in the input. Consistent visual information from multiple modified inputs would help users understand what kind of features are specifically associated with specific kernel. Comprehensive evaluation shows that the proposed method can help better interpret activation of specific kernels than widely used methods, even when two kernels have very similar activation regions from the same input image.