 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
3D Reactive Control and Frontier-Based Exploration for Unstructured Environments
Aug 01, 2021
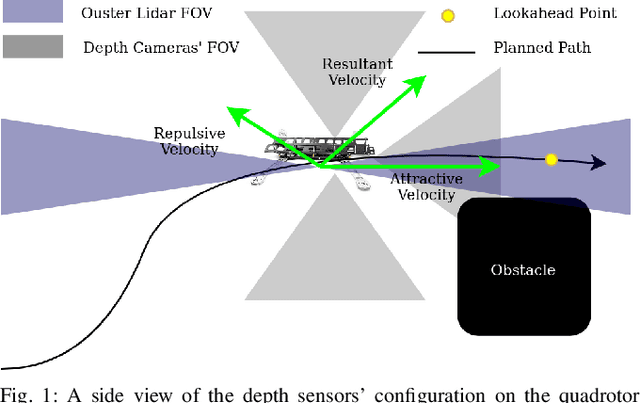
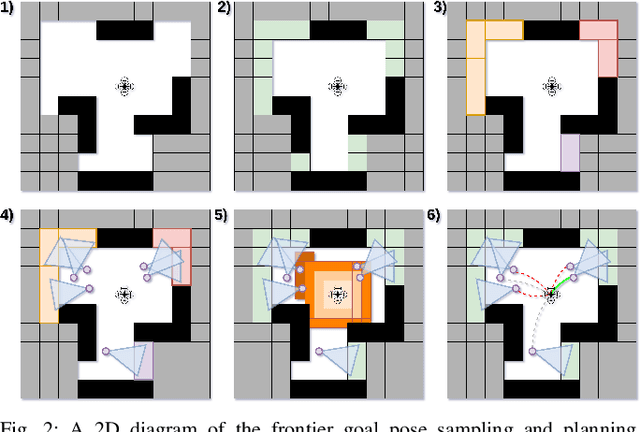
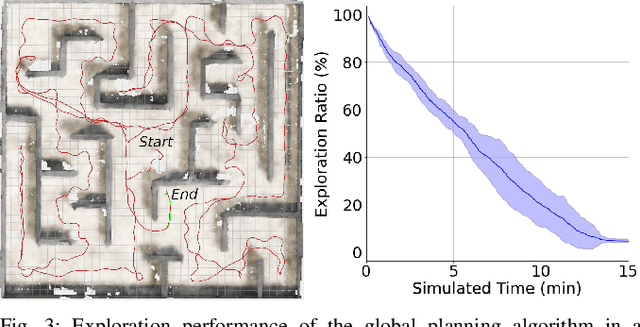

The paper proposes a reliable and robust planning solution to the long range robotic navigation problem in extremely cluttered environments. A two-layer planning architecture is proposed that leverages both the environment map and the direct depth sensor information to ensure maximal information gain out of the onboard sensors. A frontier-based pose sampling technique is used with a fast marching cost-to-go calculation to select a goal pose and plan a path to maximize robot exploration rate. An artificial potential function approach, relying on direct depth measurements, enables the robot to follow the path while simultaneously avoiding small scene obstacles that are not captured in the map due to mapping and localization uncertainties. We demonstrate the feasibility and robustness of the proposed approach through field deployments in a structurally complex warehouse using a micro-aerial vehicle (MAV) with all the sensing and computations performed onboard.
Augmented Abstractive Summarization With Document-LevelSemantic Graph
Sep 13, 2021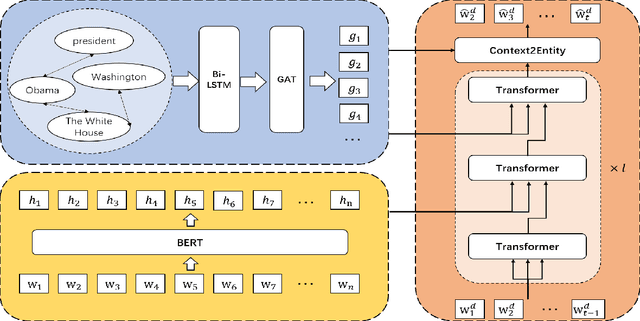
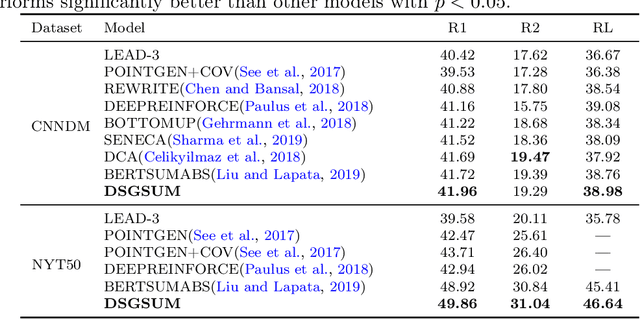

Previous abstractive methods apply sequence-to-sequence structures to generate summary without a module to assist the system to detect vital mentions and relationships within a document. To address this problem, we utilize semantic graph to boost the generation performance. Firstly, we extract important entities from each document and then establish a graph inspired by the idea of distant supervision \citep{mintz-etal-2009-distant}. Then, we combine a Bi-LSTM with a graph encoder to obtain the representation of each graph node. A novel neural decoder is presented to leverage the information of such entity graphs. Automatic and human evaluations show the effectiveness of our technique.
On Cropped versus Uncropped Training Sets in Tabular Structure Detection
Oct 07, 2021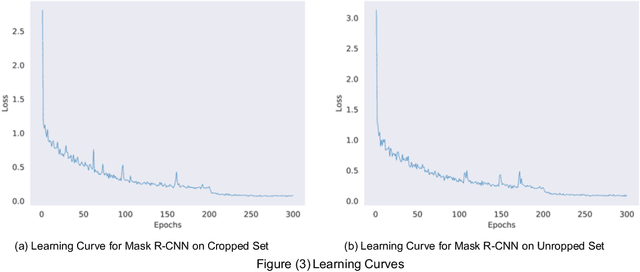
Automated document processing for tabular information extraction is highly desired in many organizations, from industry to government. Prior works have addressed this problem under table detection and table structure detection tasks. Proposed solutions leveraging deep learning approaches have been giving promising results in these tasks. However, the impact of dataset structures on table structure detection has not been investigated. In this study, we provide a comparison of table structure detection performance with cropped and uncropped datasets. The cropped set consists of only table images that are cropped from documents assuming tables are detected perfectly. The uncropped set consists of regular document images. Experiments show that deep learning models can improve the detection performance by up to 9% in average precision and average recall on the cropped versions. Furthermore, the impact of cropped images is negligible under the Intersection over Union (IoU) values of 50%-70% when compared to the uncropped versions. However, beyond 70% IoU thresholds, cropped datasets provide significantly higher detection performance.
The Computerized Classification of Micro-Motions in the Hand using Waveforms from Mobile Phone
Oct 13, 2021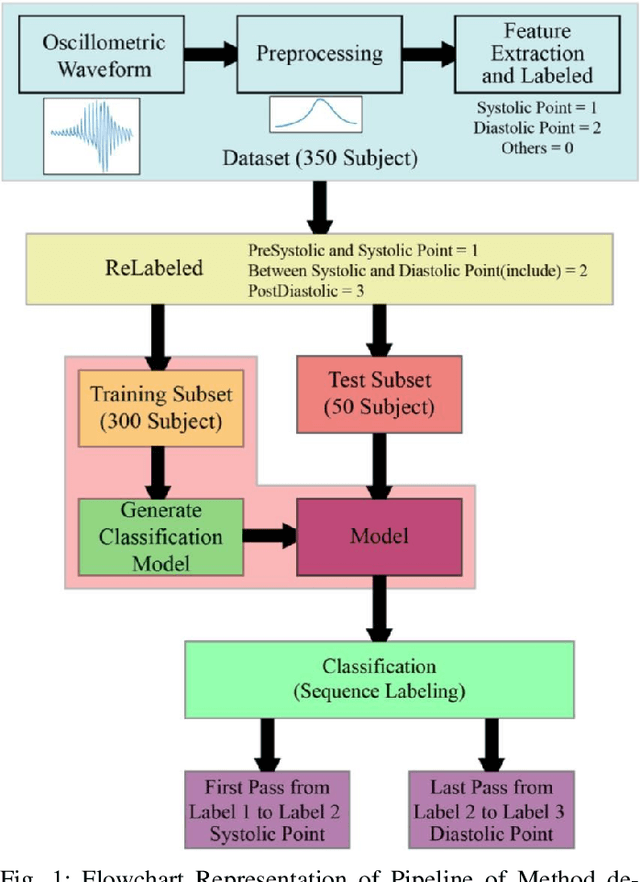

Our hands reveal important information such as the pulsing of our veins which help us determine the blood pressure, tremors indicative of motor control, or neurodegenerative disorders such as Essential Tremor or Parkinson's disease. The Computerized Classification of Micro-Motions in the hand using waveforms from mobile phone videos is a novel method that uses Eulerian Video Magnification, Skeletonization, Heatmapping, and the kNN machine learning model to detect the micro-motions in the human hand, synthesize their waveforms, and classify these. The pre-processing is achieved by using Eulerian Video Magnification, Skeletonization, and Heat-mapping to magnify the micro-motions, landmark essential features of the hand, and determine the extent of motion, respectively. Following pre-processing, the visible motions are manually labeled by appropriately grouping pixels to represent a particular label correctly. These labeled motions of the pixels are converted into waveforms. Finally, these waveforms are classified into four categories - hand or finger movements, vein movement, background motion, and movement of the rest of the body due to respiration using the kNN model. The final accuracy obtained was around 92 percent.
Retrieve, Caption, Generate: Visual Grounding for Enhancing Commonsense in Text Generation Models
Sep 08, 2021
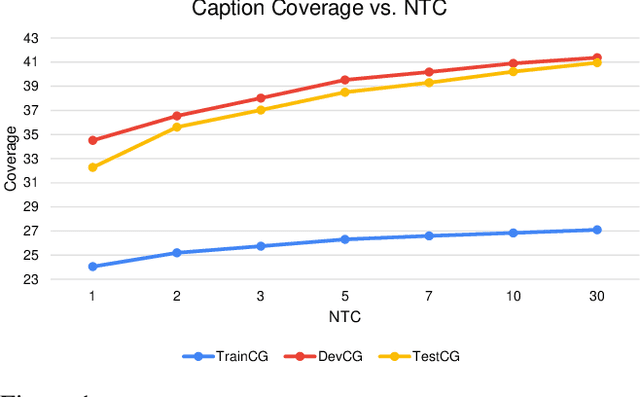
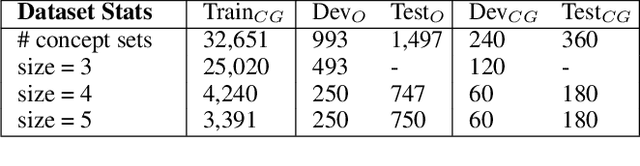
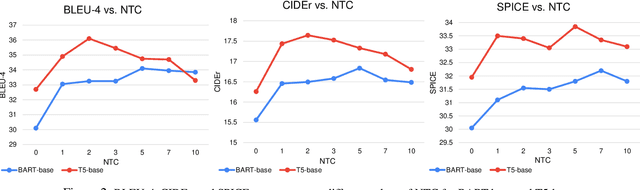
We investigate the use of multimodal information contained in images as an effective method for enhancing the commonsense of Transformer models for text generation. We perform experiments using BART and T5 on concept-to-text generation, specifically the task of generative commonsense reasoning, or CommonGen. We call our approach VisCTG: Visually Grounded Concept-to-Text Generation. VisCTG involves captioning images representing appropriate everyday scenarios, and using these captions to enrich and steer the generation process. Comprehensive evaluation and analysis demonstrate that VisCTG noticeably improves model performance while successfully addressing several issues of the baseline generations, including poor commonsense, fluency, and specificity.
A Novel Initialization Method for HybridUnderwater Optical Acoustic Networks
Sep 29, 2021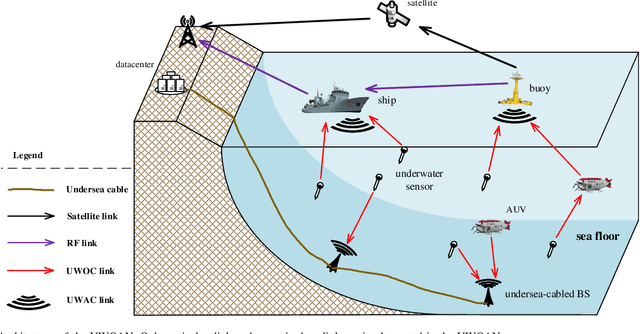
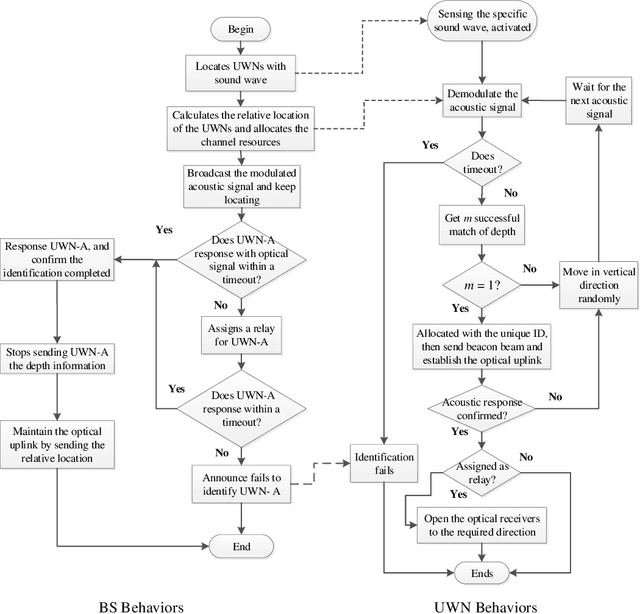
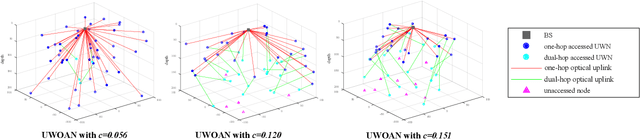
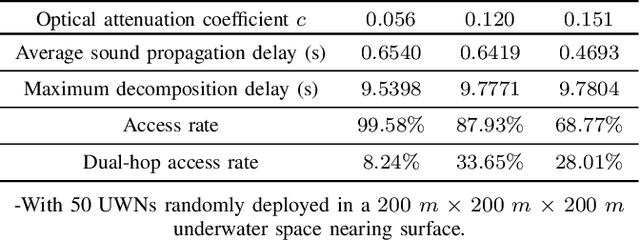
To satisfy the high data rate requirement andreliable transmission demands in underwater scenarios, it isdesirable to construct an efficient hybrid underwater opticalacoustic network (UWOAN) architecture by considering the keyfeatures and critical needs of underwater terminals. In UWOANs,optical uplinks and acoustic downlinks are configured betweenunderwater nodes (UWNs) and the base station (BS), wherethe optical beam transmits the high data rate traffic to theBS, while the acoustic waves carry the control information torealize the network management. In this paper, we focus onsolving the network initializing problem in UWOANs, which isa challenging task due to the lack of GPS service and limiteddevice payload in underwater environments. To this end, weleverage acoustic waves for node localization and propose anovel network initialization method, which consists of UWNidentification, discovery, localization, as well as decomposition.Numerical simulations are also conducted to verify the proposedinitialization method.
Human Pose Transfer with Disentangled Feature Consistency
Jul 23, 2021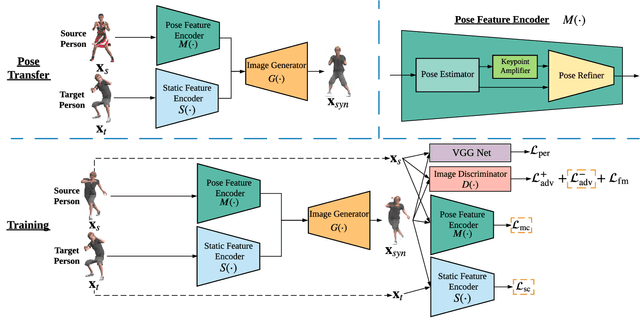



Deep generative models have made great progress in synthesizing images with arbitrary human poses and transferring poses of one person to others. However, most existing approaches explicitly leverage the pose information extracted from the source images as a conditional input for the generative networks. Meanwhile, they usually focus on the visual fidelity of the synthesized images but neglect the inherent consistency, which further confines their performance of pose transfer. To alleviate the current limitations and improve the quality of the synthesized images, we propose a pose transfer network with Disentangled Feature Consistency (DFC-Net) to facilitate human pose transfer. Given a pair of images containing the source and target person, DFC-Net extracts pose and static information from the source and target respectively, then synthesizes an image of the target person with the desired pose from the source. Moreover, DFC-Net leverages disentangled feature consistency losses in the adversarial training to strengthen the transfer coherence and integrates the keypoint amplifier to enhance the pose feature extraction. Additionally, an unpaired support dataset Mixamo-Sup providing more extra pose information has been further utilized during the training to improve the generality and robustness of DFC-Net. Extensive experimental results on Mixamo-Pose and EDN-10k have demonstrated DFC-Net achieves state-of-the-art performance on pose transfer.
GraspLook: a VR-based Telemanipulation System with R-CNN-driven Augmentation of Virtual Environment
Oct 24, 2021
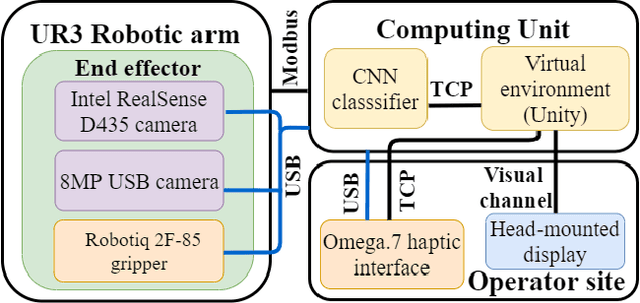
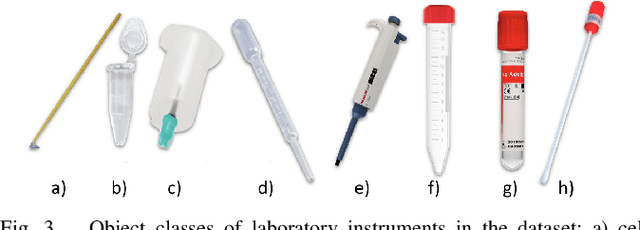
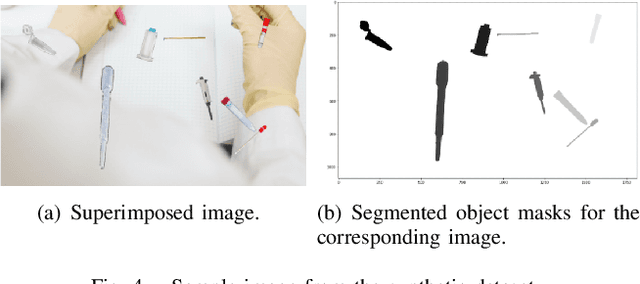
The teleoperation of robotic systems in medical applications requires stable and convenient visual feedback for the operator. The most accessible approach to delivering visual information from the remote area is using cameras to transmit a video stream from the environment. However, such systems are sensitive to the camera resolution, limited viewpoints, and cluttered environment bringing additional mental demands to the human operator. The paper proposes a novel system of teleoperation based on an augmented virtual environment (VE). The region-based convolutional neural network (R-CNN) is applied to detect the laboratory instrument and estimate its position in the remote environment to display further its digital twin in the VE, which is necessary for dexterous telemanipulation. The experimental results revealed that the developed system allows users to operate the robot smoother, which leads to a decrease in task execution time when manipulating test tubes. In addition, the participants evaluated the developed system as less mentally demanding (by 11%) and requiring less effort (by 16%) to accomplish the task than the camera-based teleoperation approach and highly assessed their performance in the augmented VE. The proposed technology can be potentially applied for conducting laboratory tests in remote areas when operating with infectious and poisonous reagents.
Landslide Detection in Real-Time Social Media Image Streams
Oct 03, 2021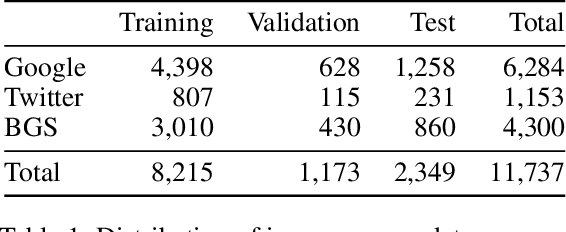

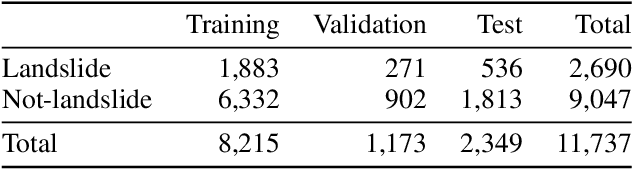
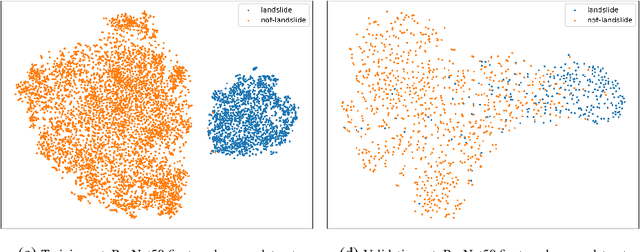
Lack of global data inventories obstructs scientific modeling of and response to landslide hazards which are oftentimes deadly and costly. To remedy this limitation, new approaches suggest solutions based on citizen science that requires active participation. However, as a non-traditional data source, social media has been increasingly used in many disaster response and management studies in recent years. Inspired by this trend, we propose to capitalize on social media data to mine landslide-related information automatically with the help of artificial intelligence (AI) techniques. Specifically, we develop a state-of-the-art computer vision model to detect landslides in social media image streams in real time. To that end, we create a large landslide image dataset labeled by experts and conduct extensive model training experiments. The experimental results indicate that the proposed model can be deployed in an online fashion to support global landslide susceptibility maps and emergency response.
The Multi-layer Information Bottleneck Problem
Nov 14, 2017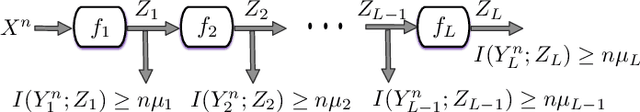
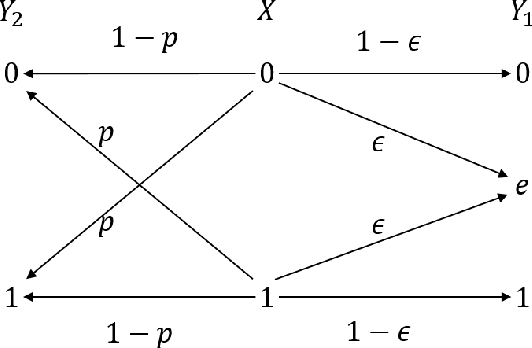
The muti-layer information bottleneck (IB) problem, where information is propagated (or successively refined) from layer to layer, is considered. Based on information forwarded by the preceding layer, each stage of the network is required to preserve a certain level of relevance with regards to a specific hidden variable, quantified by the mutual information. The hidden variables and the source can be arbitrarily correlated. The optimal trade-off between rates of relevance and compression (or complexity) is obtained through a single-letter characterization, referred to as the rate-relevance region. Conditions of successive refinabilty are given. Binary source with BSC hidden variables and binary source with BSC/BEC mixed hidden variables are both proved to be successively refinable. We further extend our result to Guassian models. A counterexample of successive refinability is also provided.