 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Modelling and optimization of nanovector synthesis for applications in drug delivery systems
Nov 10, 2021

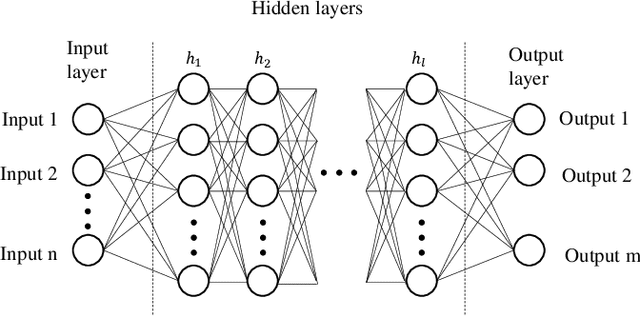
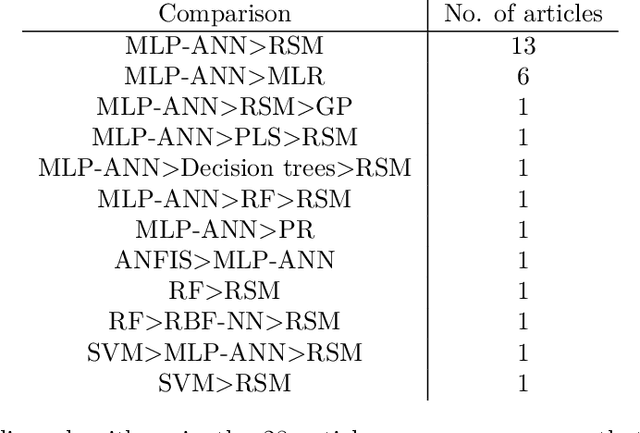
Nanovectors (NVs), based on nanostructured matter such as nanoparticles (NPs), have proven to perform as excellent drug delivery systems. However, due to the great variety of potential NVs, including NPs materials and their functionalization, in addition to the plethora of molecules that could transport, this fields presents a great challenge in terms of resources to find NVs with the most optimal physicochemical properties such as particle size and drug loading, where most of efforts rely on trial and error experimentation. In this regard, Artificial intelligence (AI) and metaheuristic algorithms offer efficient of the state-of-the-art modelling and optimization, respectively. This review focuses, through a systematic search, on the use of artificial intelligence and metaheuristic algorithms for nanoparticle synthesis in drug delivery systems. The main findings are: neural networks are better at modelling NVs properties than linear regression algorithms and response surface methodology, there is a very limited number of studies comparing AI or metaheuristic algorithm, and there is no information regarding the appropriateness of calculations of the sample size. Based on these findings, multilayer perceptron artificial neural network and adaptive neuro fuzzy inference system were tested for their modelling performance with a NV dataset; finding the latter the better algorithm. For metaheuristic algorithms, benchmark functions were optimized with cuckoo search, firefly algorithm, genetic algorithm and symbiotic organism search; finding cuckoo search and symbiotic organism search with the best performance. Finally, methods to estimate appropriate sample size for AI algorithms are discussed.
Outlining and Filling: Hierarchical Query Graph Generation for Answering Complex Questions over Knowledge Graph
Nov 01, 2021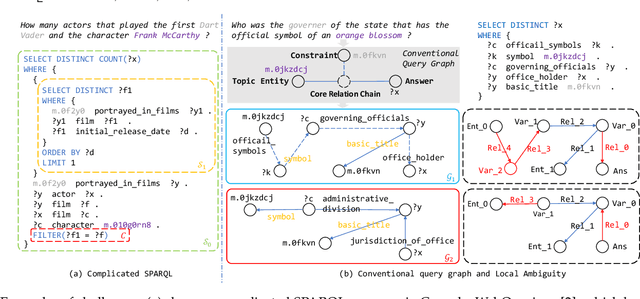
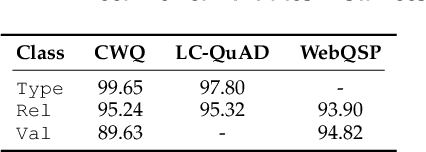
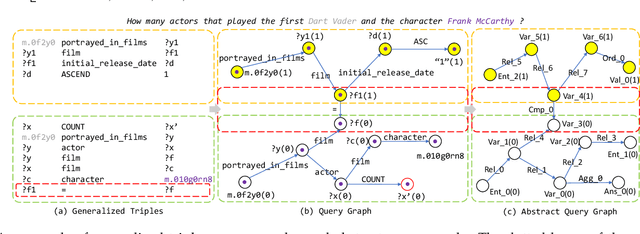
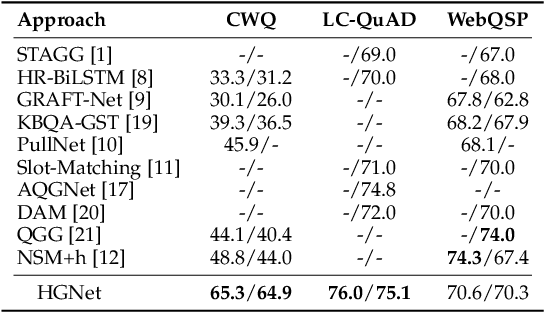
Query graph building aims to build correct executable SPARQL over the knowledge graph for answering natural language questions. Although recent approaches perform well by NN-based query graph ranking, more complex questions bring three new challenges: complicated SPARQL syntax, huge search space for ranking, and noisy query graphs with local ambiguity. This paper handles these challenges. Initially, we regard common complicated SPARQL syntax as the sub-graphs comprising of vertices and edges and propose a new unified query graph grammar to adapt them. Subsequently, we propose a new two-stage approach to build query graphs. In the first stage, the top-$k$ related instances (entities, relations, etc.) are collected by simple strategies, as the candidate instances. In the second stage, a graph generation model performs hierarchical generation. It first outlines a graph structure whose vertices and edges are empty slots, and then fills the appropriate instances into the slots, thereby completing the query graph. Our approach decomposes the unbearable search space of entire query graphs into affordable sub-spaces of operations, meanwhile, leverages the global structural information to eliminate local ambiguity. The experimental results demonstrate that our approach greatly improves state-of-the-art on the hardest KGQA benchmarks and has an excellent performance on complex questions.
Online Algorithm for Unsupervised Sequential Selection with Contextual Information
Oct 23, 2020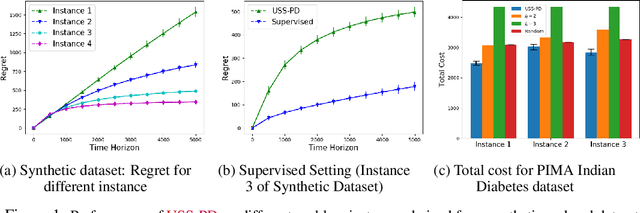
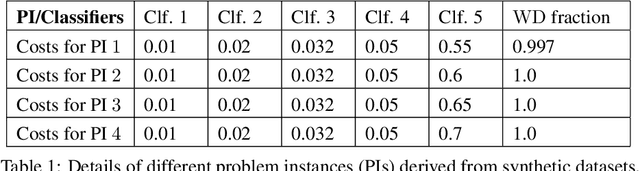
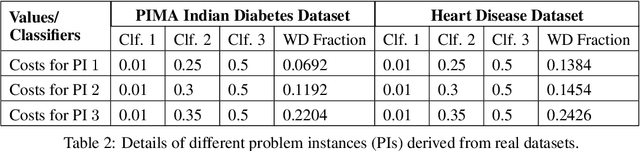
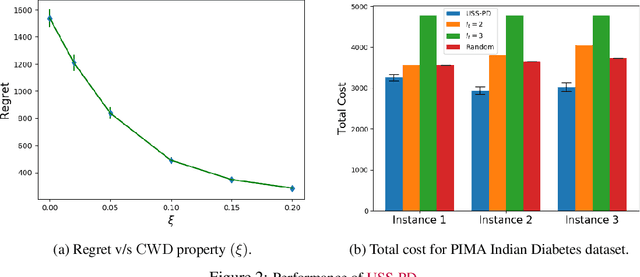
In this paper, we study Contextual Unsupervised Sequential Selection (USS), a new variant of the stochastic contextual bandits problem where the loss of an arm cannot be inferred from the observed feedback. In our setup, arms are associated with fixed costs and are ordered, forming a cascade. In each round, a context is presented, and the learner selects the arms sequentially till some depth. The total cost incurred by stopping at an arm is the sum of fixed costs of arms selected and the stochastic loss associated with the arm. The learner's goal is to learn a decision rule that maps contexts to arms with the goal of minimizing the total expected loss. The problem is challenging as we are faced with an unsupervised setting as the total loss cannot be estimated. Clearly, learning is feasible only if the optimal arm can be inferred (explicitly or implicitly) from the problem structure. We observe that learning is still possible when the problem instance satisfies the so-called 'Contextual Weak Dominance' (CWD) property. Under CWD, we propose an algorithm for the contextual USS problem and demonstrate that it has sub-linear regret. Experiments on synthetic and real datasets validate our algorithm.
Decision Tree-Based Predictive Models for Academic Achievement Using College Students' Support Networks
Aug 31, 2021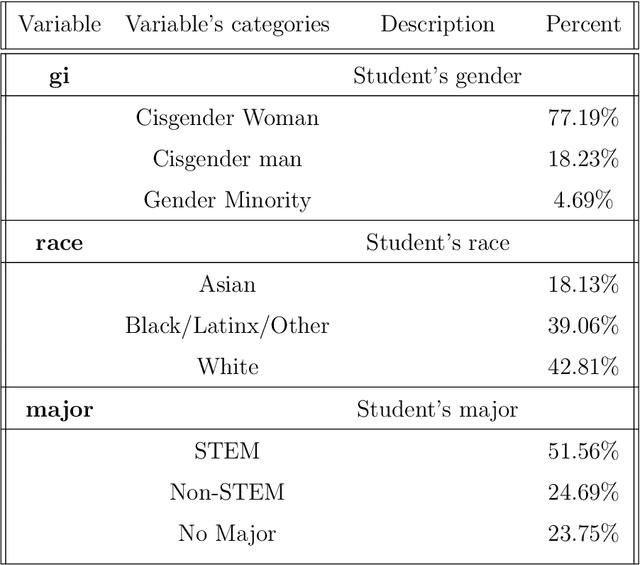

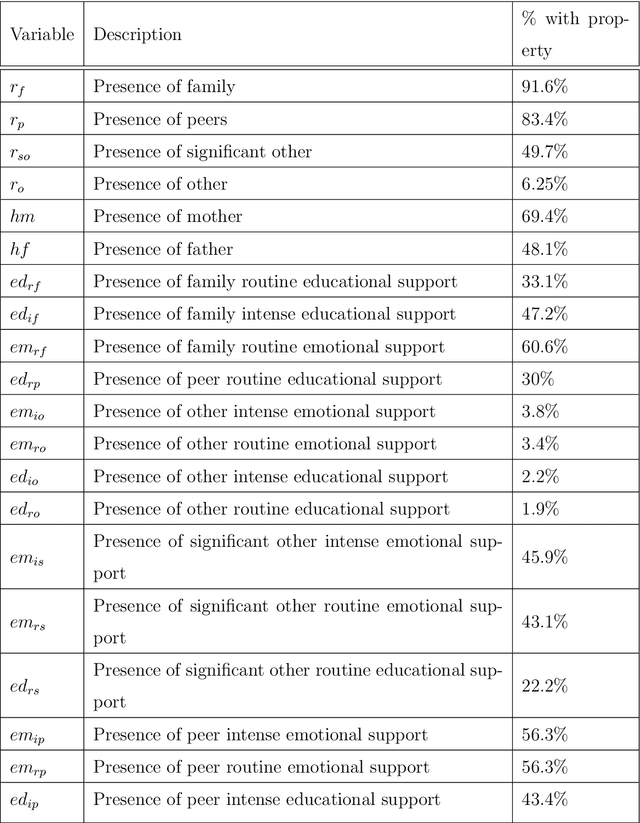

In this study, we examine a set of primary data collected from 484 students enrolled in a large public university in the Mid-Atlantic United States region during the early stages of the COVID-19 pandemic. The data, called Ties data, included students' demographic and support network information. The support network data comprised of information that highlighted the type of support, (i.e. emotional or educational; routine or intense). Using this data set, models for predicting students' academic achievement, quantified by their self-reported GPA, were created using Chi-Square Automatic Interaction Detection (CHAID), a decision tree algorithm, and cforest, a random forest algorithm that uses conditional inference trees. We compare the methods' accuracy and variation in the set of important variables suggested by each algorithm. Each algorithm found different variables important for different student demographics with some overlap. For White students, different types of educational support were important in predicting academic achievement, while for non-White students, different types of emotional support were important in predicting academic achievement. The presence of differing types of routine support were important in predicting academic achievement for cisgender women, while differing types of intense support were important in predicting academic achievement for cisgender men.
A Data-Driven Uncertainty Quantification Method for Stochastic Economic Dispatch
Sep 16, 2021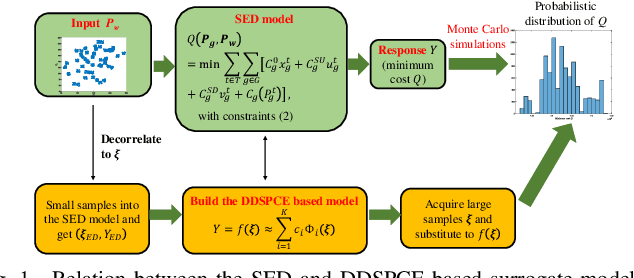
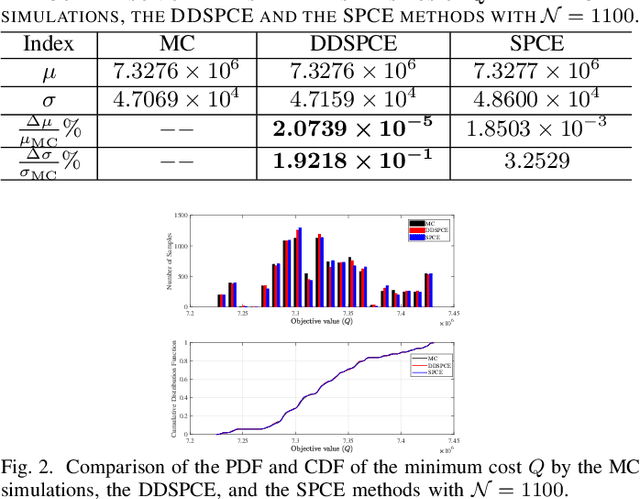
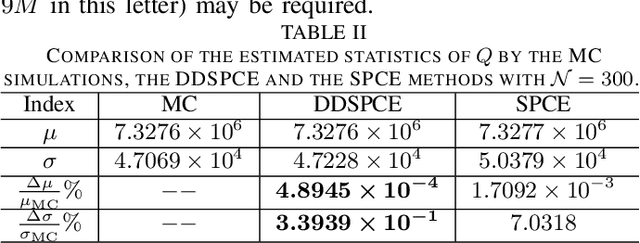
This letter proposes a data-driven sparse polynomial chaos expansion-based surrogate model for the stochastic economic dispatch problem considering uncertainty from wind power. The proposed method can provide accurate estimations for the statistical information (e.g., mean, variance, probability density function, and cumulative distribution function) for the stochastic economic dispatch solution efficiently without requiring the probability distributions of random inputs. Simulation studies on an integrated electricity and gas system (IEEE 118-bus system integrated with a 20-node gas system are presented, demonstrating the efficiency and accuracy of the proposed method compared to the Monte Carlo simulations.
Evaluating Off-the-Shelf Machine Listening and Natural Language Models for Automated Audio Captioning
Oct 14, 2021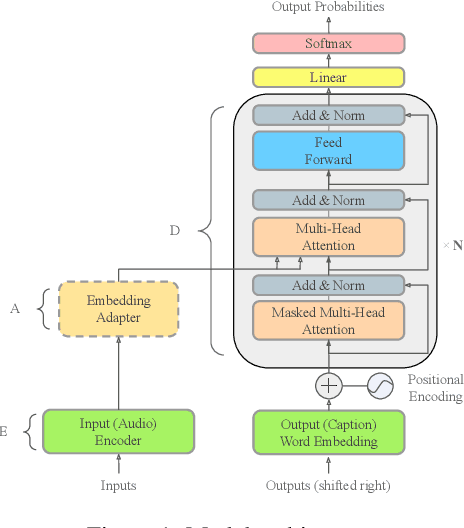
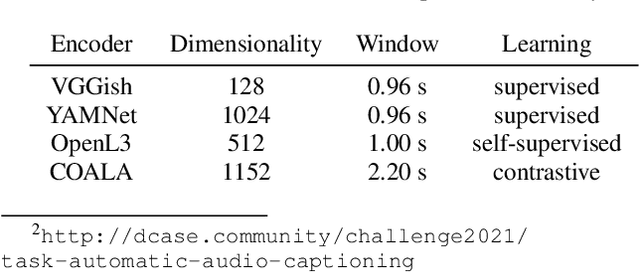
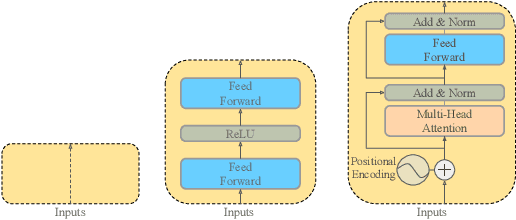
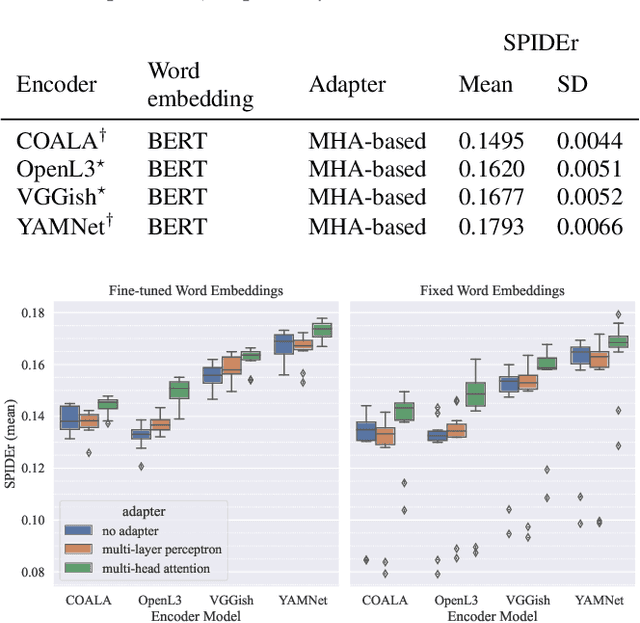
Automated audio captioning (AAC) is the task of automatically generating textual descriptions for general audio signals. A captioning system has to identify various information from the input signal and express it with natural language. Existing works mainly focus on investigating new methods and try to improve their performance measured on existing datasets. Having attracted attention only recently, very few works on AAC study the performance of existing pre-trained audio and natural language processing resources. In this paper, we evaluate the performance of off-the-shelf models with a Transformer-based captioning approach. We utilize the freely available Clotho dataset to compare four different pre-trained machine listening models, four word embedding models, and their combinations in many different settings. Our evaluation suggests that YAMNet combined with BERT embeddings produces the best captions. Moreover, in general, fine-tuning pre-trained word embeddings can lead to better performance. Finally, we show that sequences of audio embeddings can be processed using a Transformer encoder to produce higher-quality captions.
FR-Train: A mutual information-based approach to fair and robust training
Feb 24, 2020
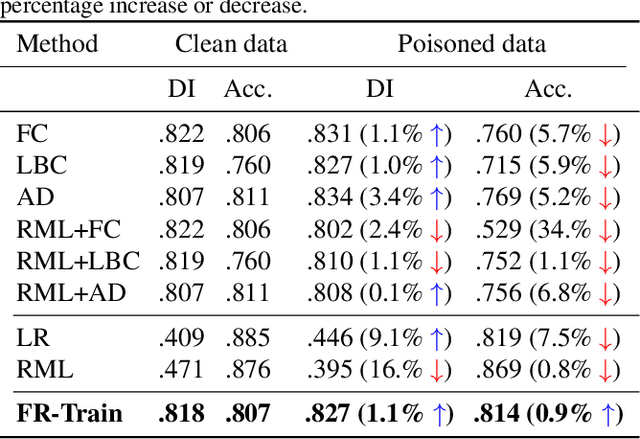
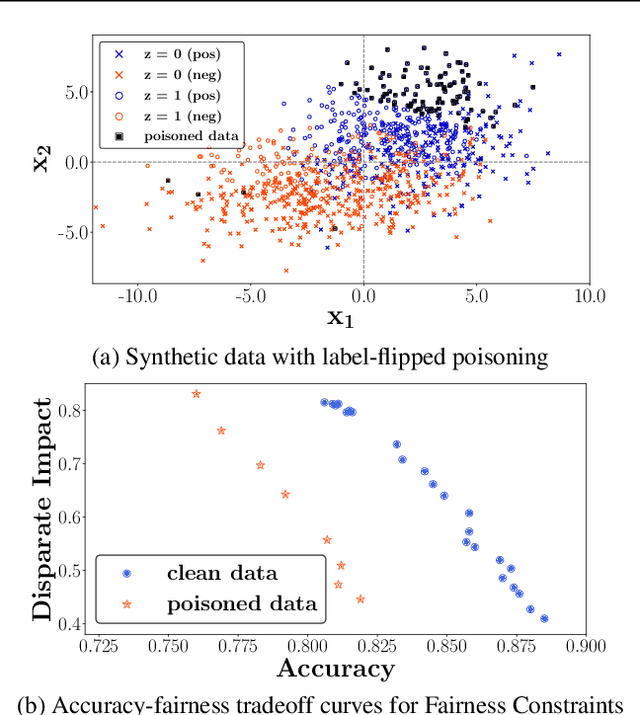
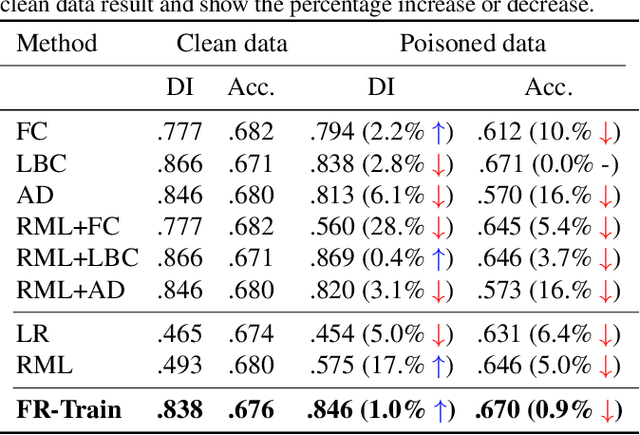
Trustworthy AI is a critical issue in machine learning where, in addition to training a model that is accurate, one must consider both fair and robust training in the presence of data bias and poisoning. However, the existing model fairness techniques mistakenly view poisoned data as an additional bias, resulting in severe performance degradation. To fix this problem, we propose FR-Train, which holistically performs fair and robust model training. We provide a mutual information-based interpretation of an existing adversarial training-based fairness-only method, and apply this idea to architect an additional discriminator that can identify poisoned data using a clean validation set and reduce its influence. In our experiments, FR-Train shows almost no decrease in fairness and accuracy in the presence of data poisoning by both mitigating the bias and defending against poisoning. We also demonstrate how to construct clean validation sets using crowdsourcing, and release new benchmark datasets.
Max-Utility Based Arm Selection Strategy For Sequential Query Recommendations
Aug 31, 2021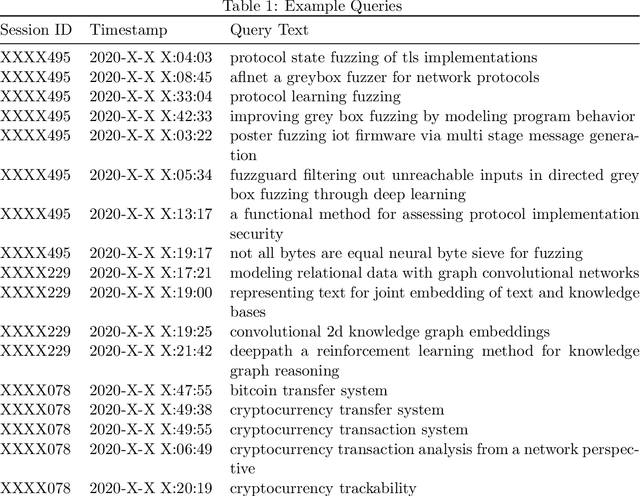
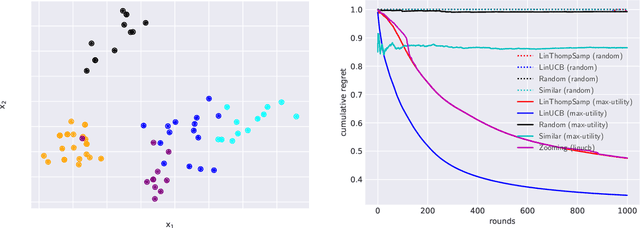

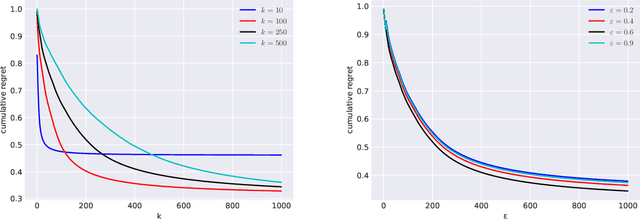
We consider the query recommendation problem in closed loop interactive learning settings like online information gathering and exploratory analytics. The problem can be naturally modelled using the Multi-Armed Bandits (MAB) framework with countably many arms. The standard MAB algorithms for countably many arms begin with selecting a random set of candidate arms and then applying standard MAB algorithms, e.g., UCB, on this candidate set downstream. We show that such a selection strategy often results in higher cumulative regret and to this end, we propose a selection strategy based on the maximum utility of the arms. We show that in tasks like online information gathering, where sequential query recommendations are employed, the sequences of queries are correlated and the number of potentially optimal queries can be reduced to a manageable size by selecting queries with maximum utility with respect to the currently executing query. Our experimental results using a recent real online literature discovery service log file demonstrate that the proposed arm selection strategy improves the cumulative regret substantially with respect to the state-of-the-art baseline algorithms. % and commonly used random selection strategy for a variety of contextual multi-armed bandit algorithms. Our data model and source code are available at ~\url{https://anonymous.4open.science/r/0e5ad6b7-ac02-4577-9212-c9d505d3dbdb/}.
Artificial Association Neural Networks
Nov 22, 2021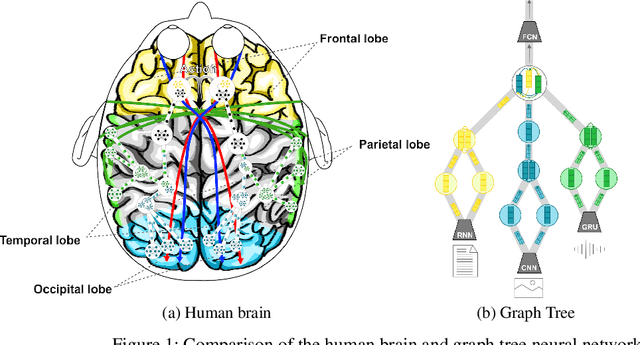
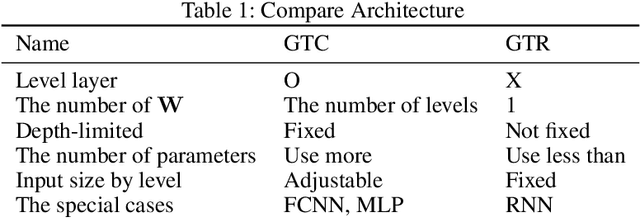
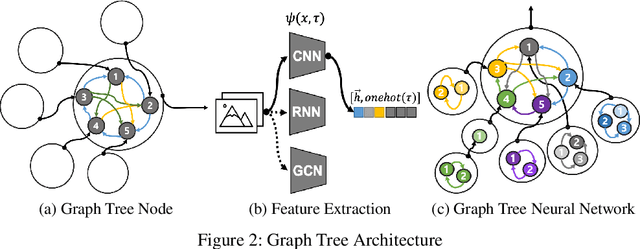
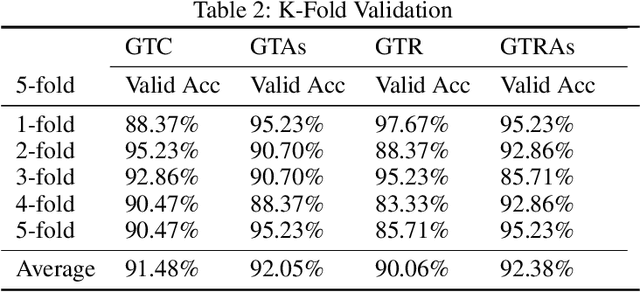
In the field of deep learning, various architectures have been developed. However, most studies are limited to specific tasks or datasets due to their fixed layer structure. This paper does not express the structure delivering information as a network model but as a data structure called an association tree(AT). And we propose two artificial association networks(AANs) designed to solve the problems of existing networks by analyzing the structure of human neural networks. Defining the starting and ending points of the path in a single graph is difficult, and a tree cannot express the relationship among sibling nodes. On the contrary, an AT can express leaf and root nodes as the starting and ending points of the path and the relationship among sibling nodes. Instead of using fixed sequence layers, we create an AT for each data and train AANs according to the tree's structure. AANs are data-driven learning in which the number of convolutions varies according to the depth of the tree. Moreover, AANs can simultaneously learn various types of datasets through the recursive learning. Depth-first convolution (DFC) encodes the interaction result from leaf nodes to the root node in a bottom-up approach, and depth-first deconvolution (DFD) decodes the interaction result from the root node to the leaf nodes in a top-down approach. We conducted three experiments. The first experiment verified whether it could be processed by combining AANs and feature extraction networks. In the second, we compared the performance of networks that separately learned image, sound, and tree, graph structure datasets with the performance simultaneously learned by connecting these networks. In the third, we verified whether the output of AANs can embed all data in the AT. As a result, AATs learned without significant performance degradation.
Closed-loop Feedback Registration for Consecutive Images of Moving Flexible Targets
Oct 20, 2021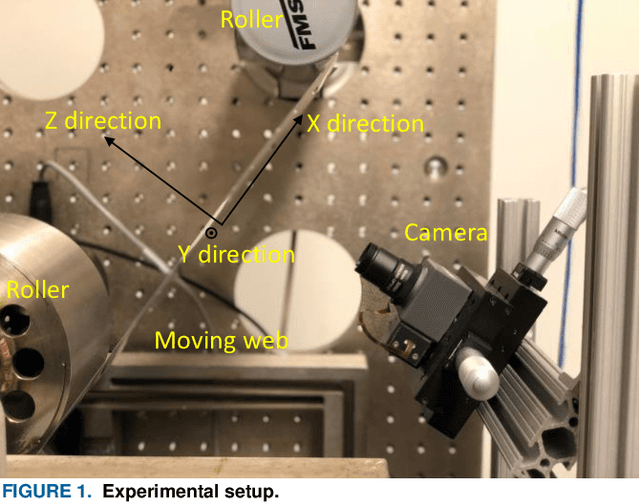

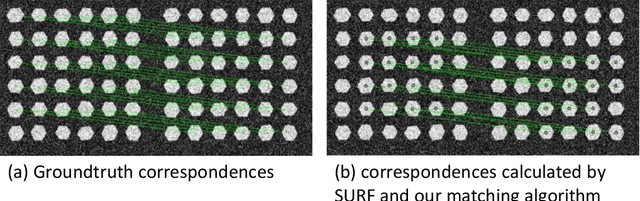
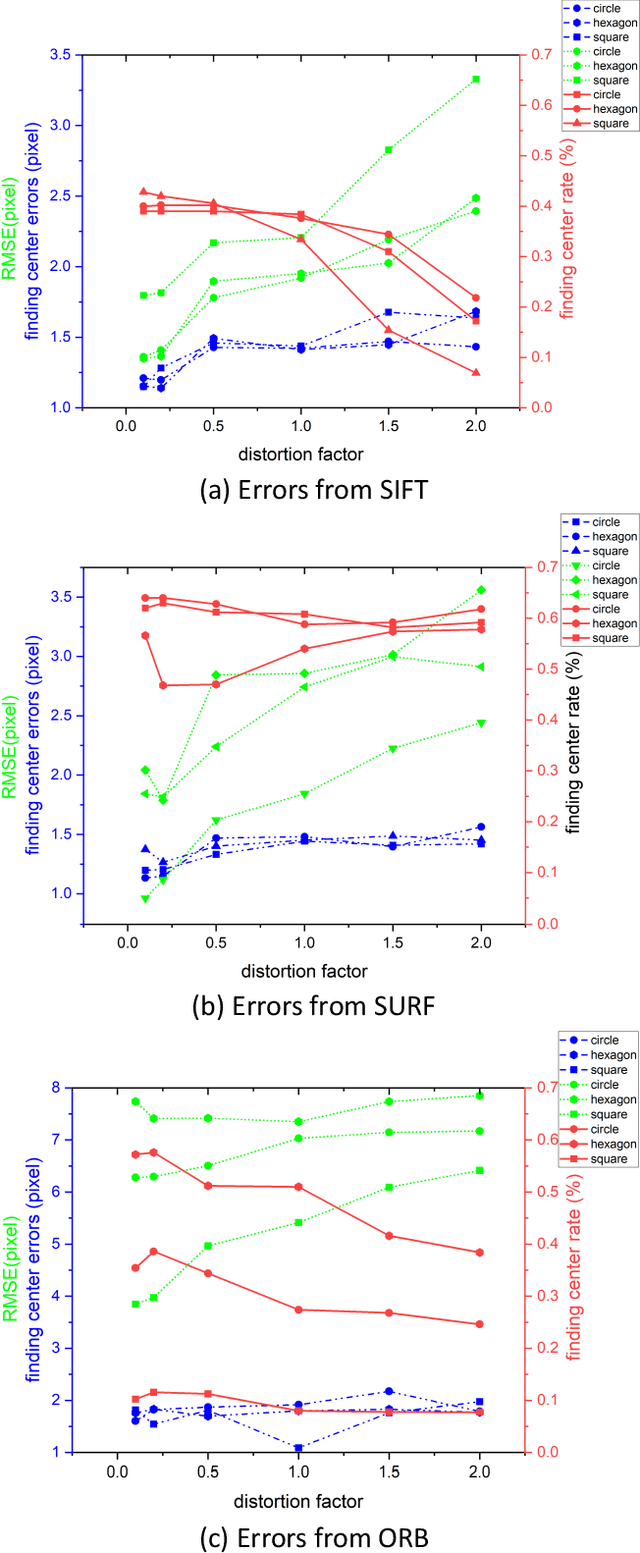
Advancement of imaging techniques enables consecutive image sequences to be acquired for quality monitoring of manufacturing production lines. Registration for these image sequences is essential for in-line pattern inspection and metrology, e.g., in the printing process of flexible electronics. However, conventional image registration algorithms cannot produce accurate results when the images contain many similar and deformable patterns in the manufacturing process. Such a failure originates from a fact that the conventional algorithms only use the spatial and pixel intensity information for registration. Considering the nature of temporal continuity and consecution of the product images, in this paper, we propose a closed-loop feedback registration algorithm for matching and stitching the deformable printed patterns on a moving flexible substrate. The algorithm leverages the temporal and spatial relationships of the consecutive images and the continuity of the image sequence for fast, accurate, and robust point matching. Our experimental results show that our algorithm can find more matching point pairs with a lower root mean squared error (RMSE) compared to other state-of-the-art algorithms while offering significant improvements to running time.