 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantics-Guided Contrastive Network for Zero-Shot Object detection
Sep 04, 2021
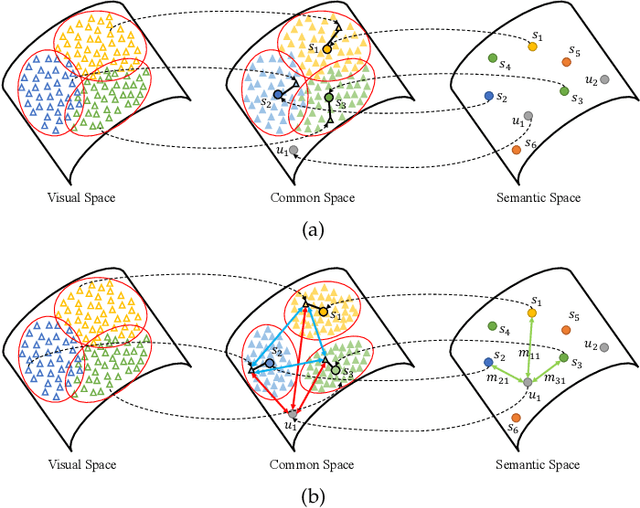
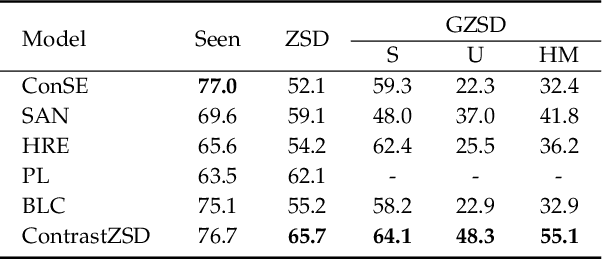
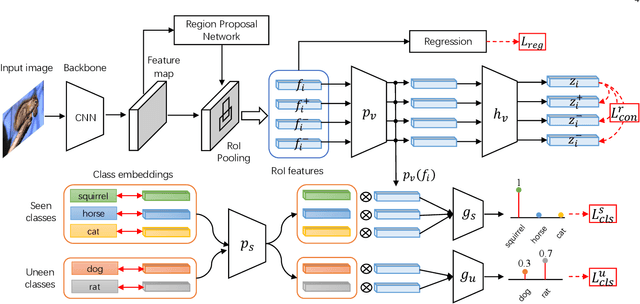
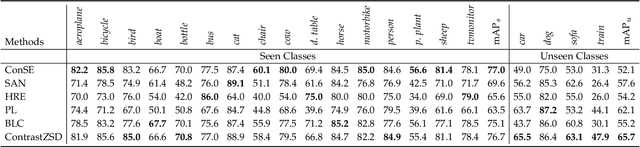
Zero-shot object detection (ZSD), the task that extends conventional detection models to detecting objects from unseen categories, has emerged as a new challenge in computer vision. Most existing approaches tackle the ZSD task with a strict mapping-transfer strategy, which may lead to suboptimal ZSD results: 1) the learning process of those models ignores the available unseen class information, and thus can be easily biased towards the seen categories; 2) the original visual feature space is not well-structured and lack of discriminative information. To address these issues, we develop a novel Semantics-Guided Contrastive Network for ZSD, named ContrastZSD, a detection framework that first brings contrastive learning mechanism into the realm of zero-shot detection. Particularly, ContrastZSD incorporates two semantics-guided contrastive learning subnets that contrast between region-category and region-region pairs respectively. The pairwise contrastive tasks take advantage of additional supervision signals derived from both ground truth label and pre-defined class similarity distribution. Under the guidance of those explicit semantic supervision, the model can learn more knowledge about unseen categories to avoid the bias problem to seen concepts, while optimizing the data structure of visual features to be more discriminative for better visual-semantic alignment. Extensive experiments are conducted on two popular benchmarks for ZSD, i.e., PASCAL VOC and MS COCO. Results show that our method outperforms the previous state-of-the-art on both ZSD and generalized ZSD tasks.
Covert Message Passing over Public Internet Platforms Using Model-Based Format-Transforming Encryption
Oct 13, 2021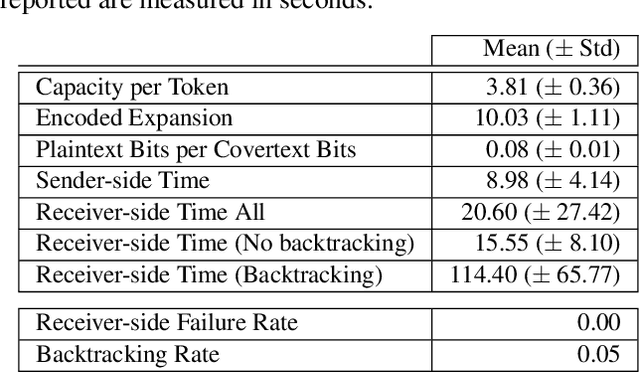
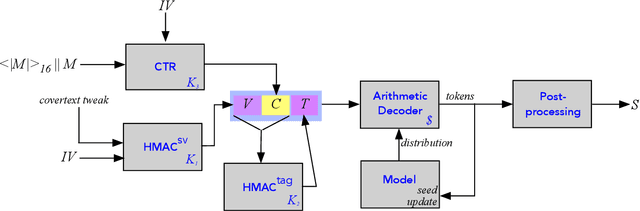
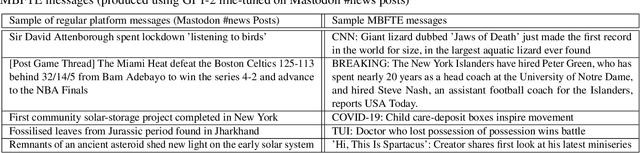
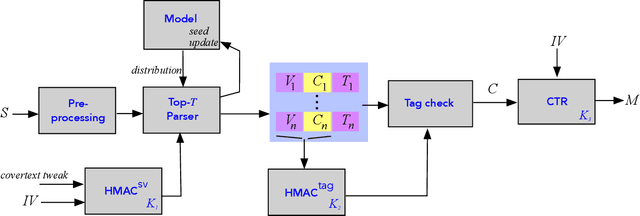
We introduce a new type of format-transforming encryption where the format of ciphertexts is implicitly encoded within a machine-learned generative model. Around this primitive, we build a system for covert messaging over large, public internet platforms (e.g., Twitter). Loosely, our system composes an authenticated encryption scheme, with a method for encoding random ciphertext bits into samples from the generative model's family of seed-indexed token-distributions. By fixing a deployment scenario, we are forced to consider system-level and algorithmic solutions to real challenges -- such as receiver-side parsing ambiguities, and the low information-carrying capacity of actual token-distributions -- that were elided in prior work. We use GPT-2 as our generative model so that our system cryptographically transforms plaintext bitstrings into natural-language covertexts suitable for posting to public platforms. We consider adversaries with full view of the internet platform's content, whose goal is to surface posts that are using our system for covert messaging. We carry out a suite of experiments to provide heuristic evidence of security and to explore tradeoffs between operational efficiency and detectability.
Bag-of-Vectors Autoencoders for Unsupervised Conditional Text Generation
Oct 13, 2021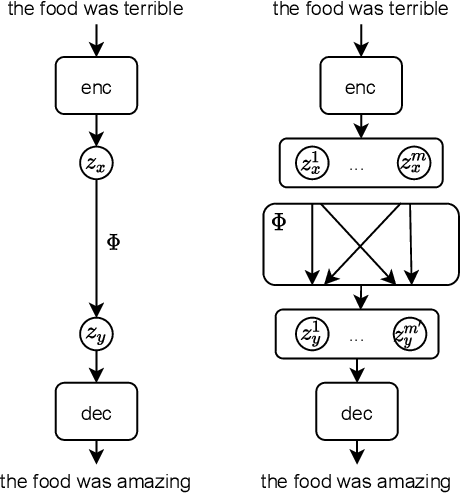
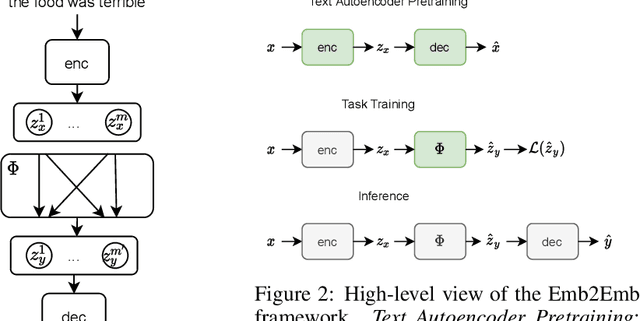
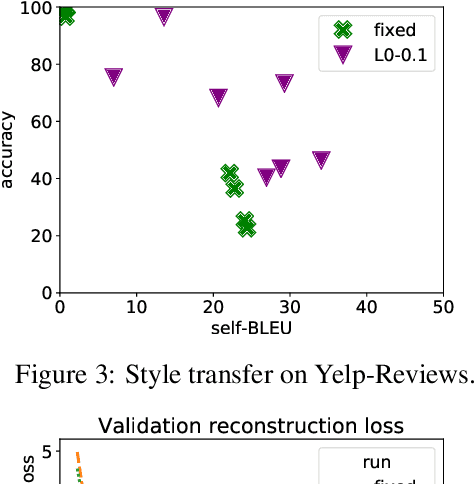
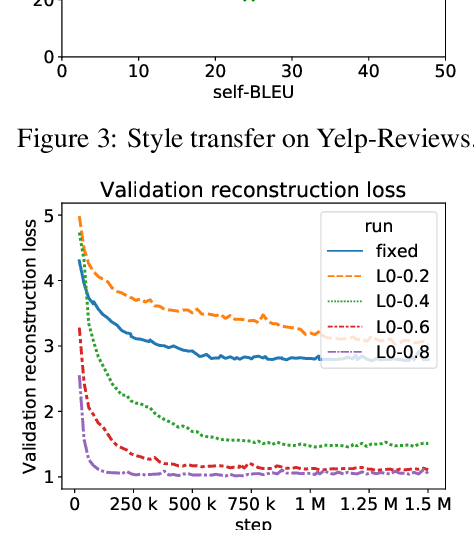
Text autoencoders are often used for unsupervised conditional text generation by applying mappings in the latent space to change attributes to the desired values. Recently, Mai et al. (2020) proposed Emb2Emb, a method to learn these mappings in the embedding space of an autoencoder. However, their method is restricted to autoencoders with a single-vector embedding, which limits how much information can be retained. We address this issue by extending their method to Bag-of-Vectors Autoencoders (BoV-AEs), which encode the text into a variable-size bag of vectors that grows with the size of the text, as in attention-based models. This allows to encode and reconstruct much longer texts than standard autoencoders. Analogous to conventional autoencoders, we propose regularization techniques that facilitate learning meaningful operations in the latent space. Finally, we adapt for a training scheme that learns to map an input bag to an output bag, including a novel loss function and neural architecture. Our experimental evaluations on unsupervised sentiment transfer and sentence summarization show that our method performs substantially better than a standard autoencoder.
Open-Domain Question-Answering for COVID-19 and Other Emergent Domains
Oct 13, 2021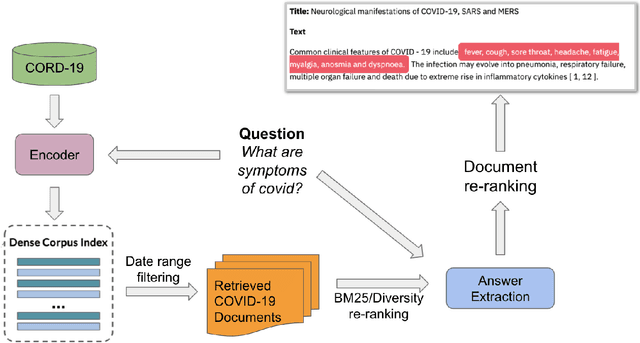
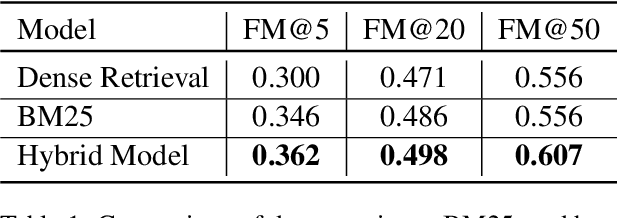
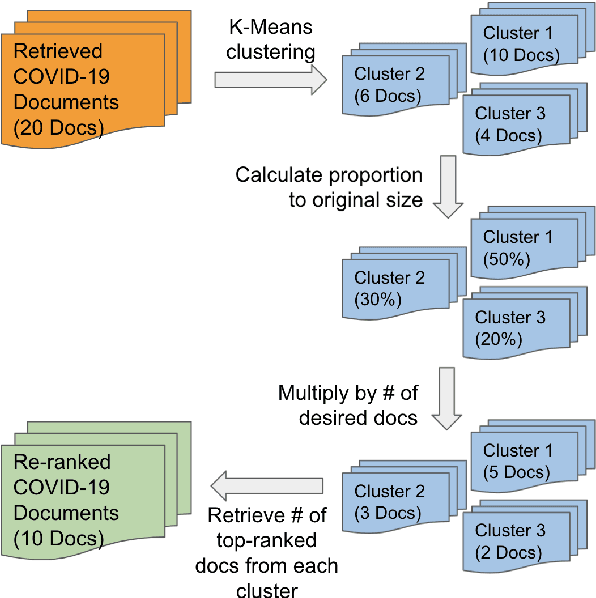
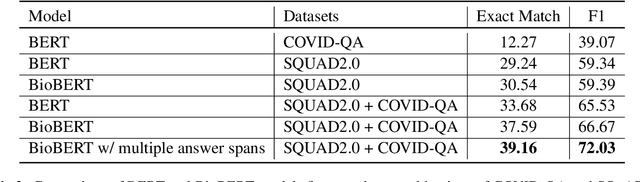
Since late 2019, COVID-19 has quickly emerged as the newest biomedical domain, resulting in a surge of new information. As with other emergent domains, the discussion surrounding the topic has been rapidly changing, leading to the spread of misinformation. This has created the need for a public space for users to ask questions and receive credible, scientific answers. To fulfill this need, we turn to the task of open-domain question-answering, which we can use to efficiently find answers to free-text questions from a large set of documents. In this work, we present such a system for the emergent domain of COVID-19. Despite the small data size available, we are able to successfully train the system to retrieve answers from a large-scale corpus of published COVID-19 scientific papers. Furthermore, we incorporate effective re-ranking and question-answering techniques, such as document diversity and multiple answer spans. Our open-domain question-answering system can further act as a model for the quick development of similar systems that can be adapted and modified for other developing emergent domains.
DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries
Oct 13, 2021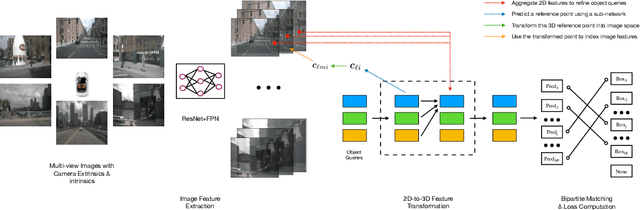
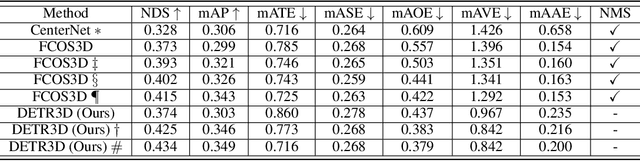
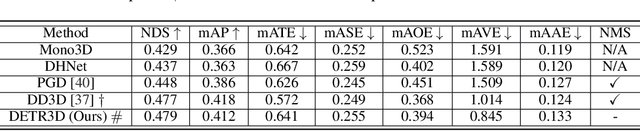
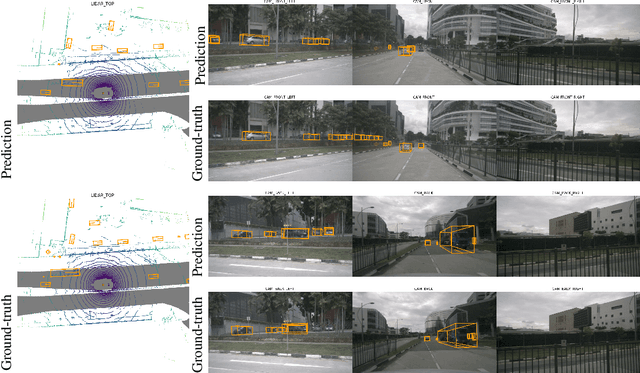
We introduce a framework for multi-camera 3D object detection. In contrast to existing works, which estimate 3D bounding boxes directly from monocular images or use depth prediction networks to generate input for 3D object detection from 2D information, our method manipulates predictions directly in 3D space. Our architecture extracts 2D features from multiple camera images and then uses a sparse set of 3D object queries to index into these 2D features, linking 3D positions to multi-view images using camera transformation matrices. Finally, our model makes a bounding box prediction per object query, using a set-to-set loss to measure the discrepancy between the ground-truth and the prediction. This top-down approach outperforms its bottom-up counterpart in which object bounding box prediction follows per-pixel depth estimation, since it does not suffer from the compounding error introduced by a depth prediction model. Moreover, our method does not require post-processing such as non-maximum suppression, dramatically improving inference speed. We achieve state-of-the-art performance on the nuScenes autonomous driving benchmark.
Topology-Guided Path Planning for Reliable Visual Navigation of MAVs
Jul 19, 2021
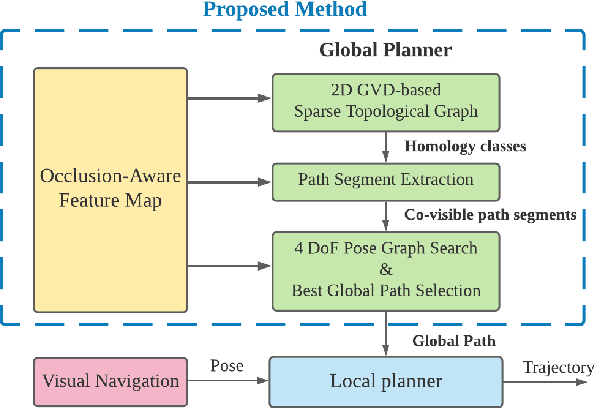
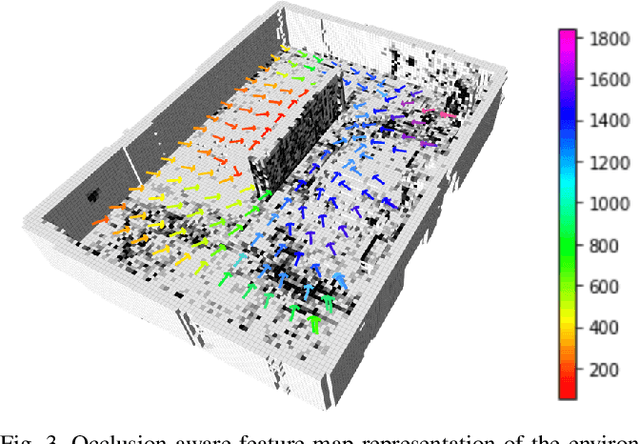
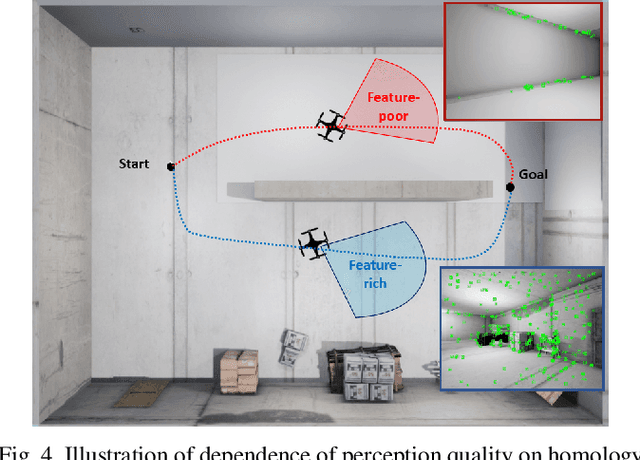
Visual navigation has been widely used for state estimation of micro aerial vehicles (MAVs). For stable visual navigation, MAVs should generate perception-aware paths which guarantee enough visible landmarks. Many previous works on perception-aware path planning focused on sampling-based planners. However, they may suffer from sample inefficiency, which leads to computational burden for finding a global optimal path. To address this issue, we suggest a perception-aware path planner which utilizes topological information of environments. Since the topological class of a path and visible landmarks during traveling the path are closely related, the proposed algorithm checks distinctive topological classes to choose the class with abundant visual information. Topological graph is extracted from the generalized Voronoi diagram of the environment and initial paths with different topological classes are found. To evaluate the perception quality of the classes, we divide the initial path into discrete segments where the points in each segment share similar visual information. The optimal class with high perception quality is selected, and a graph-based planner is utilized to generate path within the class. With simulations and real-world experiments, we confirmed that the proposed method could guarantee accurate visual navigation compared with the perception-agnostic method while showing improved computational efficiency than the sampling-based perception-aware planner.
SINet: Extreme Lightweight Portrait Segmentation Networks with Spatial Squeeze Modules and Information Blocking Decoder
Nov 26, 2019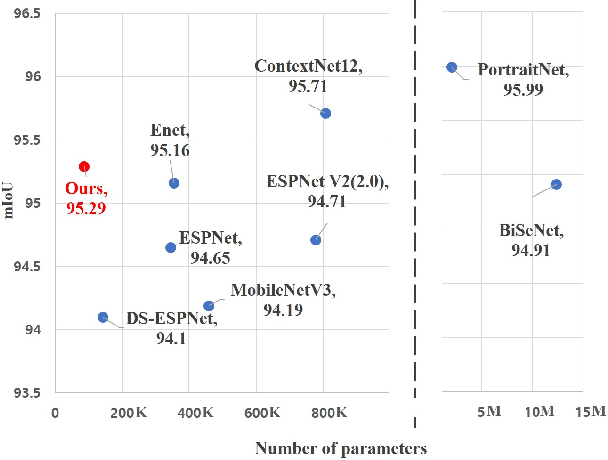


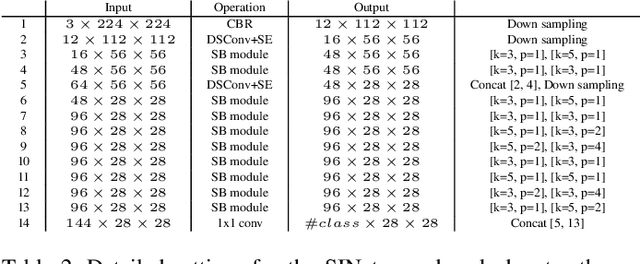
Designing a lightweight and robust portrait segmentation algorithm is an important task for a wide range of face applications. However, the problem has been considered as a subset of the object segmentation problem and less handled in the semantic segmentation field. Obviously, portrait segmentation has its unique requirements. First, because the portrait segmentation is performed in the middle of a whole process of many real-world applications, it requires extremely lightweight models. Second, there has not been any public datasets in this domain that contain a sufficient number of images with unbiased statistics. To solve the first problem, we introduce the new extremely lightweight portrait segmentation model SINet, containing an information blocking decoder and spatial squeeze modules. The information blocking decoder uses confidence estimates to recover local spatial information without spoiling global consistency. The spatial squeeze module uses multiple receptive fields to cope with various sizes of consistency in the image. To tackle the second problem, we propose a simple method to create additional portrait segmentation data which can improve accuracy on the EG1800 dataset. In our qualitative and quantitative analysis on the EG1800 dataset, we show that our method outperforms various existing lightweight segmentation models. Our method reduces the number of parameters from2.1M to 86.9K (around 95.9% reduction), while maintaining the accuracy under an 1% margin from the state-of-the-art portrait segmentation method. We also show our model is successfully executed on a real mobile device with 100.6 FPS. In addition, we demonstrate that our method can be used for general semantic segmentation on the Cityscape dataset. The code is available inhttps://github.com/HYOJINPARK/ExtPortraitSeg
Communicating Inferred Goals with Passive Augmented Reality and Active Haptic Feedback
Sep 03, 2021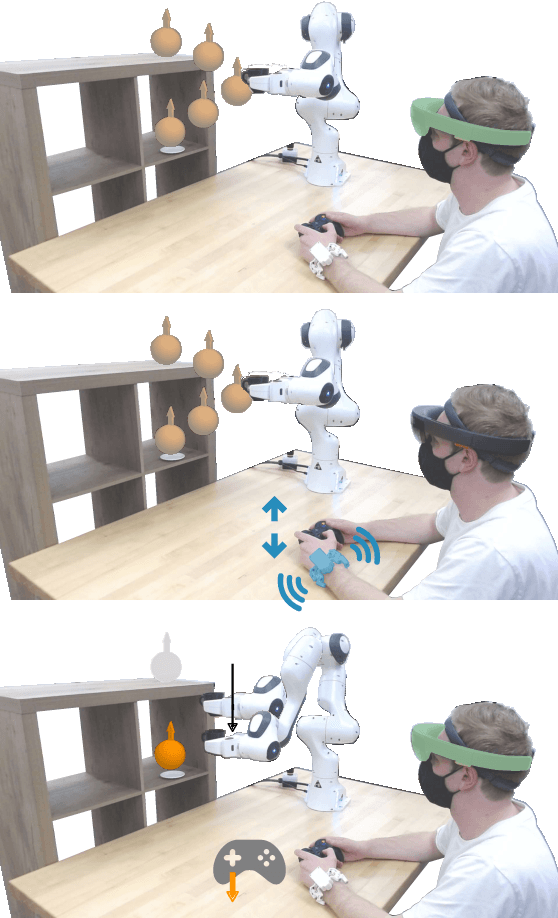
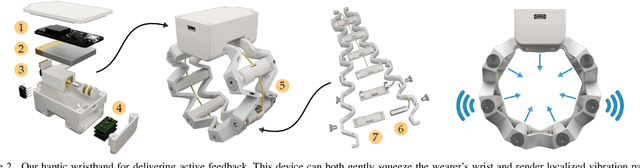

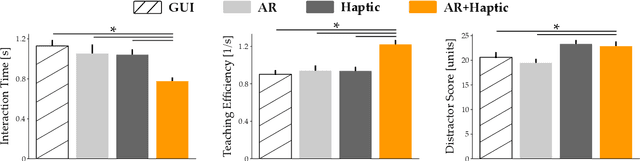
Robots learn as they interact with humans. Consider a human teleoperating an assistive robot arm: as the human guides and corrects the arm's motion, the robot gathers information about the human's desired task. But how does the human know what their robot has inferred? Today's approaches often focus on conveying intent: for instance, upon legible motions or gestures to indicate what the robot is planning. However, closing the loop on robot inference requires more than just revealing the robot's current policy: the robot should also display the alternatives it thinks are likely, and prompt the human teacher when additional guidance is necessary. In this paper we propose a multimodal approach for communicating robot inference that combines both passive and active feedback. Specifically, we leverage information-rich augmented reality to passively visualize what the robot has inferred, and attention-grabbing haptic wristbands to actively prompt and direct the human's teaching. We apply our system to shared autonomy tasks where the robot must infer the human's goal in real-time. Within this context, we integrate passive and active modalities into a single algorithmic framework that determines when and which type of feedback to provide. Combining both passive and active feedback experimentally outperforms single modality baselines; during an in-person user study, we demonstrate that our integrated approach increases how efficiently humans teach the robot while simultaneously decreasing the amount of time humans spend interacting with the robot. Videos here: https://youtu.be/swq_u4iIP-g
Fingerprint Presentation Attack Detection by Channel-wise Feature Denoising
Nov 15, 2021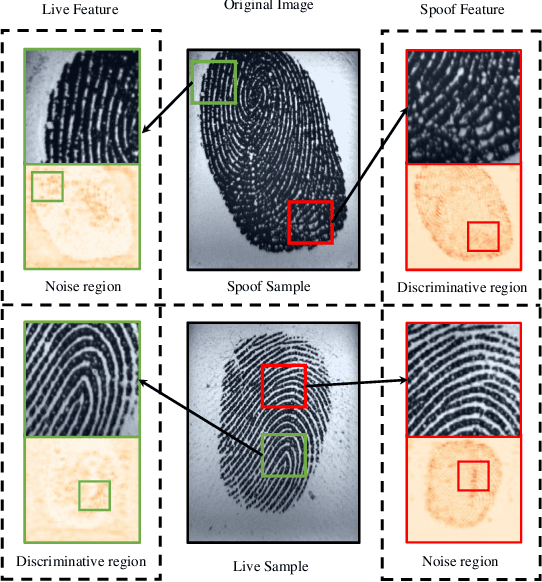
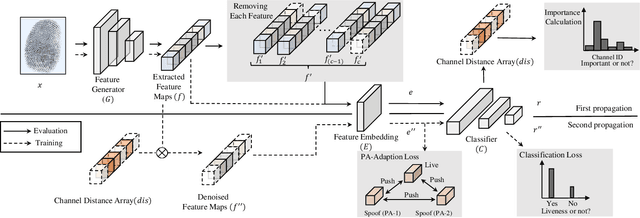
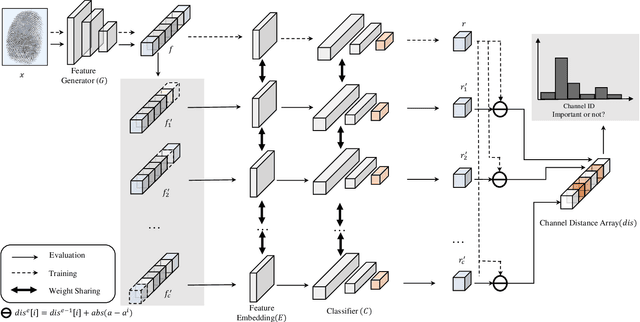
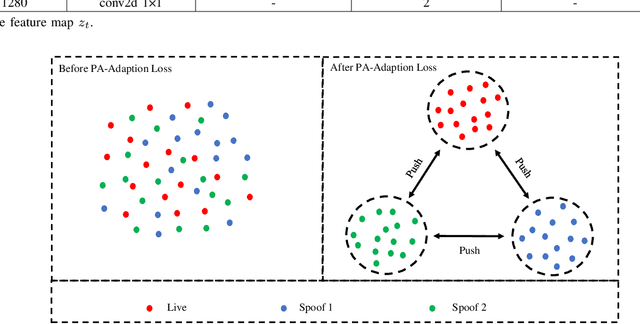
Due to the diversity of attack materials, fingerprint recognition systems (AFRSs) are vulnerable to malicious attacks. It is of great importance to propose effective Fingerprint Presentation Attack Detection (PAD) methods for the safety and reliability of AFRSs. However, current PAD methods often have poor robustness under new attack materials or sensor settings. This paper thus proposes a novel Channel-wise Feature Denoising fingerprint PAD (CFD-PAD) method by considering handling the redundant "noise" information which ignored in previous works. The proposed method learned important features of fingerprint images by weighting the importance of each channel and finding those discriminative channels and "noise" channels. Then, the propagation of "noise" channels is suppressed in the feature map to reduce interference. Specifically, a PA-Adaption loss is designed to constrain the feature distribution so as to make the feature distribution of live fingerprints more aggregate and spoof fingerprints more disperse. Our experimental results evaluated on LivDet 2017 showed that our proposed CFD-PAD can achieve 2.53% ACE and 93.83% True Detection Rate when the False Detection Rate equals to 1.0% (TDR@FDR=1%) and it outperforms the best single model based methods in terms of ACE (2.53% vs. 4.56%) and TDR@FDR=1%(93.83% vs. 73.32\%) significantly, which proves the effectiveness of the proposed method. Although we have achieved a comparable result compared with the state-of-the-art multiple model based method, there still achieves an increase of TDR@FDR=1% from 91.19% to 93.83% by our method. Besides, our model is simpler, lighter and, more efficient and has achieved a 74.76% reduction in time-consuming compared with the state-of-the-art multiple model based method. Code will be publicly available.
OCKELM+: Kernel Extreme Learning Machine based One-class Classification using Privileged Information (or KOC+: Kernel Ridge Regression or Least Square SVM with zero bias based One-class Classification using Privileged Information)
Apr 13, 2019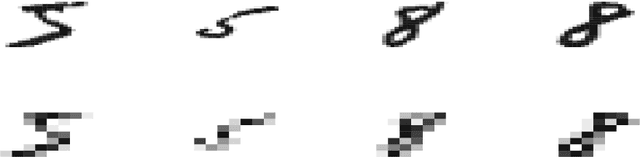
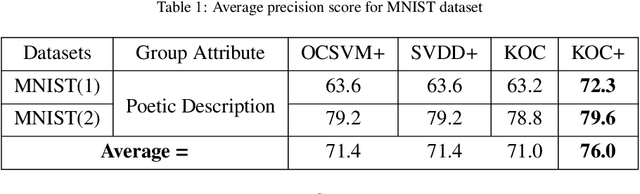
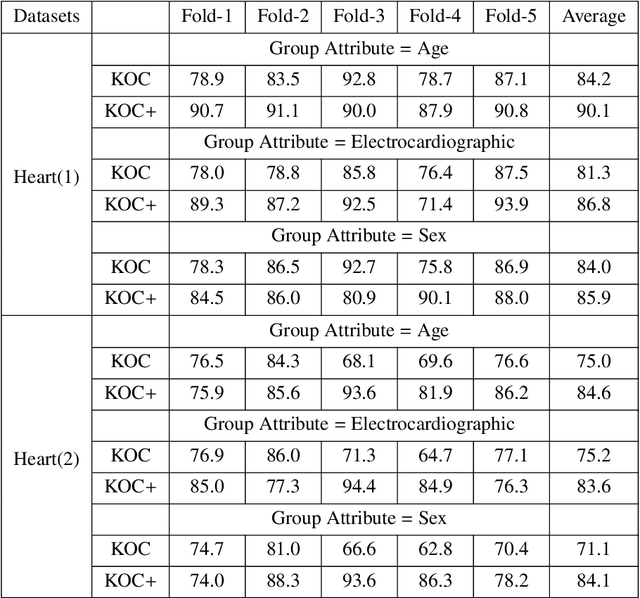
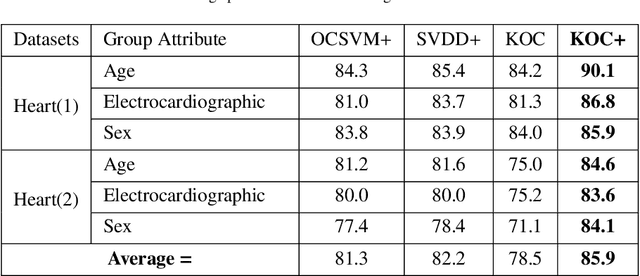
Kernel method-based one-class classifier is mainly used for outlier or novelty detection. In this letter, kernel ridge regression (KRR) based one-class classifier (KOC) has been extended for learning using privileged information (LUPI). LUPI-based KOC method is referred to as KOC+. This privileged information is available as a feature with the dataset but only for training (not for testing). KOC+ utilizes the privileged information differently compared to normal feature information by using a so-called correction function. Privileged information helps KOC+ in achieving better generalization performance which is exhibited in this letter by testing the classifiers with and without privileged information. Existing and proposed classifiers are evaluated on the datasets from UCI machine learning repository and also on MNIST dataset. Moreover, experimental results evince the advantage of KOC+ over KOC and support vector machine (SVM) based one-class classifiers.