 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automatic Polyp Segmentation via Multi-scale Subtraction Network
Aug 11, 2021
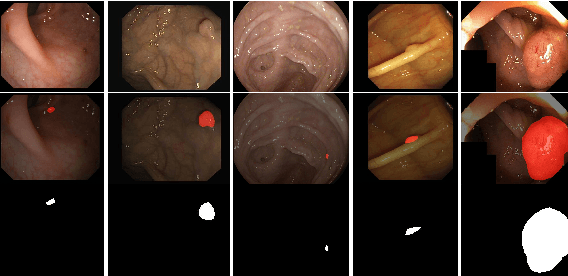
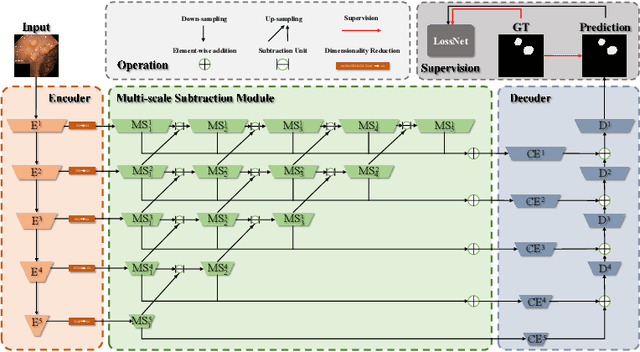
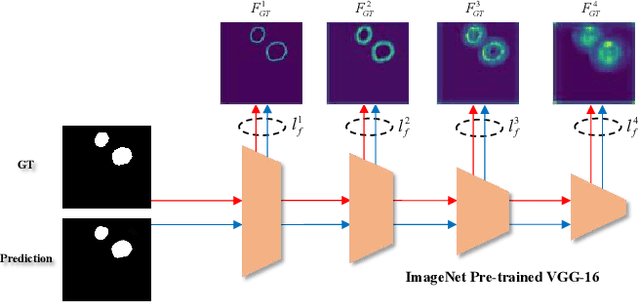
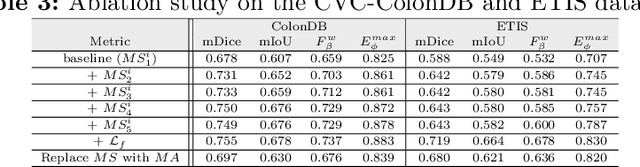
More than 90\% of colorectal cancer is gradually transformed from colorectal polyps. In clinical practice, precise polyp segmentation provides important information in the early detection of colorectal cancer. Therefore, automatic polyp segmentation techniques are of great importance for both patients and doctors. Most existing methods are based on U-shape structure and use element-wise addition or concatenation to fuse different level features progressively in decoder. However, both the two operations easily generate plenty of redundant information, which will weaken the complementarity between different level features, resulting in inaccurate localization and blurred edges of polyps. To address this challenge, we propose a multi-scale subtraction network (MSNet) to segment polyp from colonoscopy image. Specifically, we first design a subtraction unit (SU) to produce the difference features between adjacent levels in encoder. Then, we pyramidally equip the SUs at different levels with varying receptive fields, thereby obtaining rich multi-scale difference information. In addition, we build a training-free network "LossNet" to comprehensively supervise the polyp-aware features from bottom layer to top layer, which drives the MSNet to capture the detailed and structural cues simultaneously. Extensive experiments on five benchmark datasets demonstrate that our MSNet performs favorably against most state-of-the-art methods under different evaluation metrics. Furthermore, MSNet runs at a real-time speed of $\sim$70fps when processing a $352 \times 352$ image. The source code will be publicly available at \url{https://github.com/Xiaoqi-Zhao-DLUT/MSNet}. \keywords{Colorectal Cancer \and Automatic Polyp Segmentation \and Subtraction \and LossNet.}
Reinforcement Learning for Systematic FX Trading
Oct 27, 2021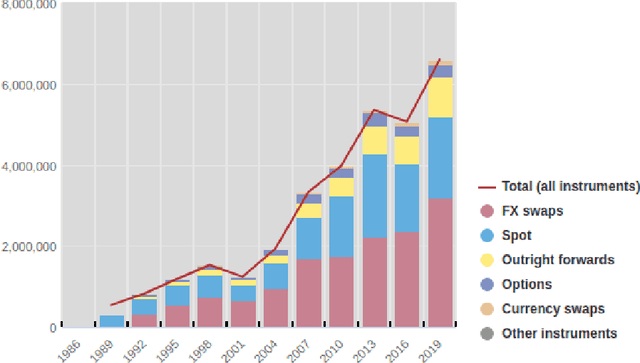
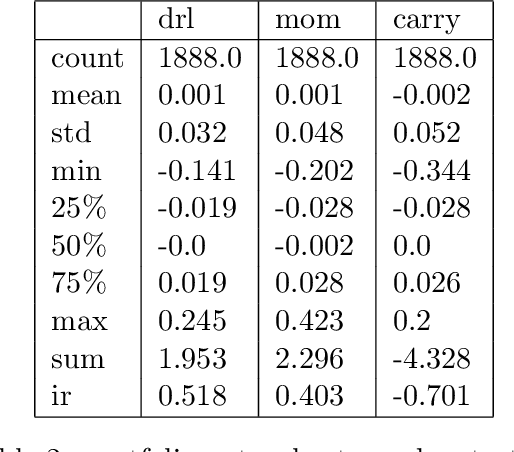
We explore online, inductive transfer learning, with a feature representation transfer from a radial basis function network, which is formed of Gaussian mixture model hidden processing units, whose output is made available to a direct, recurrent reinforcement learning agent. This recurrent reinforcement learning agent learns a desired position, via the policy gradient reinforcement learning paradigm. This transfer learner is put to work trading the major spot market currency pairs. In our experiment, we accurately account for transaction and funding costs. These sources of profit and loss, including the price trends that occur in the currency markets, are made available to the recurrent reinforcement learner via a quadratic utility, who learns to target a position directly. We improve upon earlier work by casting the problem of learning to target a risk position, in an online transfer learning context. Our agent achieves an annualised portfolio information ratio of 0.52 with compound return of 9.3\%, net of execution and funding cost, over a 7 year test set. This is despite forcing the model to trade at the close of the trading day 5pm EST, when trading costs are statistically the most expensive.
Salt and pepper noise removal method based on stationary Framelet transform with non-convex sparsity regularization
Nov 02, 2021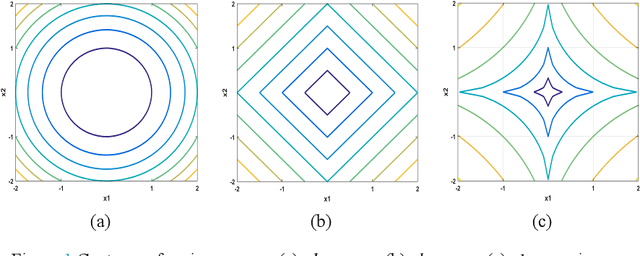
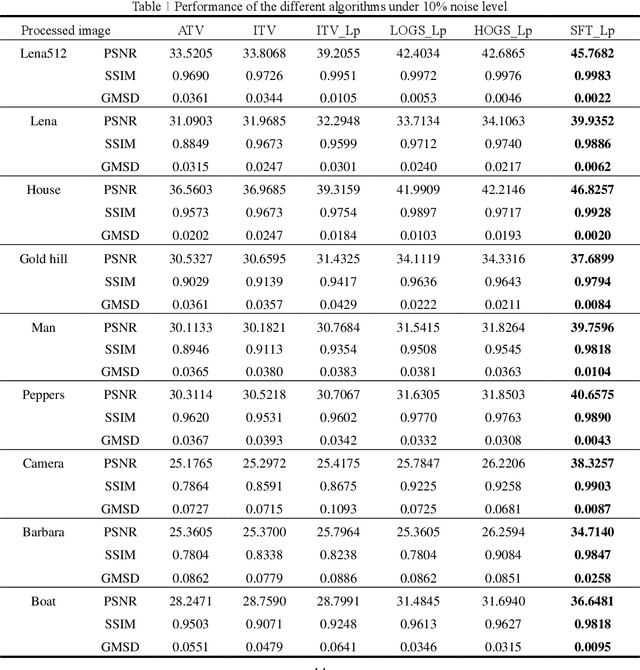
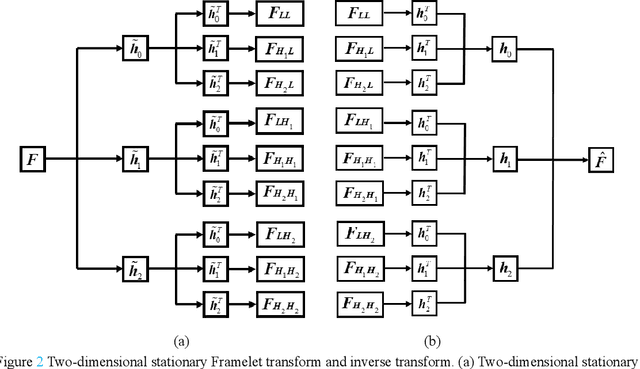
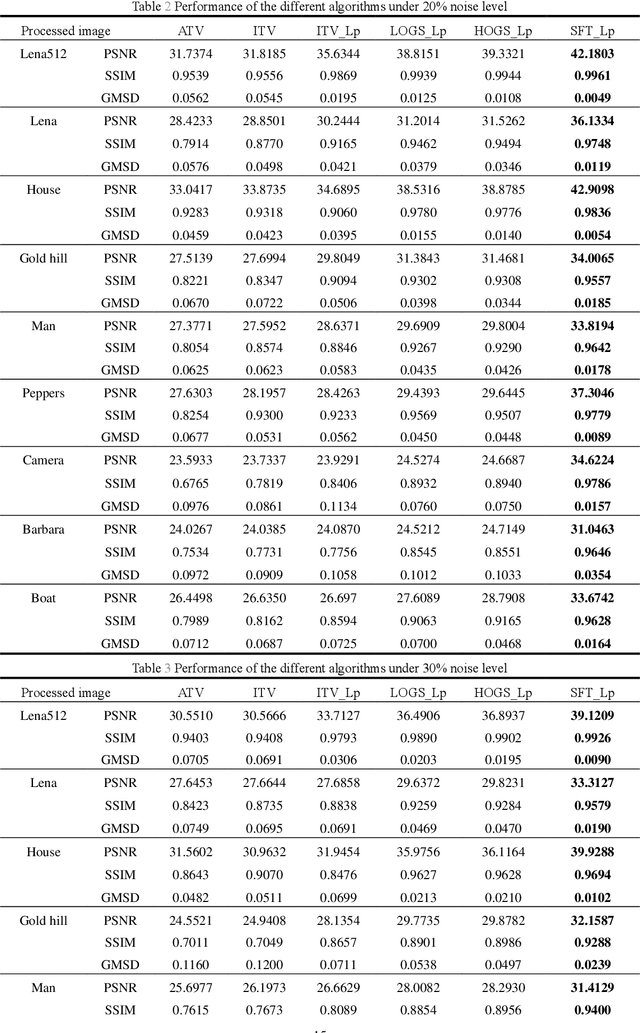
Salt and pepper noise removal is a common inverse problem in image processing. Traditional denoising methods have two limitations. First, noise characteristics are often not described accurately. For example, the noise location information is often ignored and the sparsity of the salt and pepper noise is often described by L1 norm, which cannot illustrate the sparse variables clearly. Second, conventional methods separate the contaminated image into a recovered image and a noise part, thus resulting in recovering an image with unsatisfied smooth parts and detail parts. In this study, we introduce a noise detection strategy to determine the position of the noise, and a non-convex sparsity regularization depicted by Lp quasi-norm is employed to describe the sparsity of the noise, thereby addressing the first limitation. The morphological component analysis framework with stationary Framelet transform is adopted to decompose the processed image into cartoon, texture, and noise parts to resolve the second limitation. Then, the alternating direction method of multipliers (ADMM) is employed to solve the proposed model. Finally, experiments are conducted to verify the proposed method and compare it with some current state-of-the-art denoising methods. The experimental results show that the proposed method can remove salt and pepper noise while preserving the details of the processed image.
Comprehensive Multi-Agent Epistemic Planning
Sep 17, 2021
Over the last few years, the concept of Artificial Intelligence has become central in different tasks concerning both our daily life and several working scenarios. Among these tasks automated planning has always been central in the AI research community. In particular, this manuscript is focused on a specialized kind of planning known as Multi-agent Epistemic Planning (MEP). Epistemic Planning (EP) refers to an automated planning setting where the agent reasons in the space of knowledge/beliefs states and tries to find a plan to reach a desirable state from a starting one. Its general form, the MEP problem, involves multiple agents who need to reason about both the state of the world and the information flows between agents. To tackle the MEP problem several tools have been developed and, while the diversity of approaches has led to a deeper understanding of the problem space, each proposed tool lacks some abilities and does not allow for a comprehensive investigation of the information flows. That is why, the objective of our work is to formalize an environment where a complete characterization of the agents' knowledge/beliefs interaction and update is possible. In particular, we aim to achieve such goal by defining a new action-based language for multi-agent epistemic planning and to implement an epistemic planner based on it. This solver should provide a tool flexible enough to reason on different domains, e.g., economy, security, justice and politics, where considering others' knowledge/beliefs could lead to winning strategies.
* In Proceedings ICLP 2021, arXiv:2109.07914. arXiv admin note: substantial text overlap with arXiv:1909.08259
MLBiNet: A Cross-Sentence Collective Event Detection Network
May 20, 2021
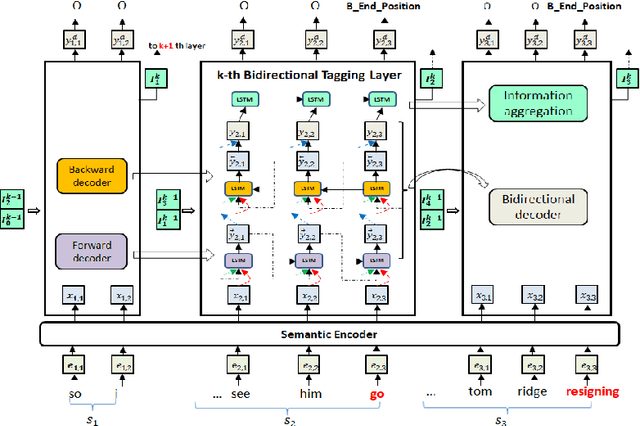
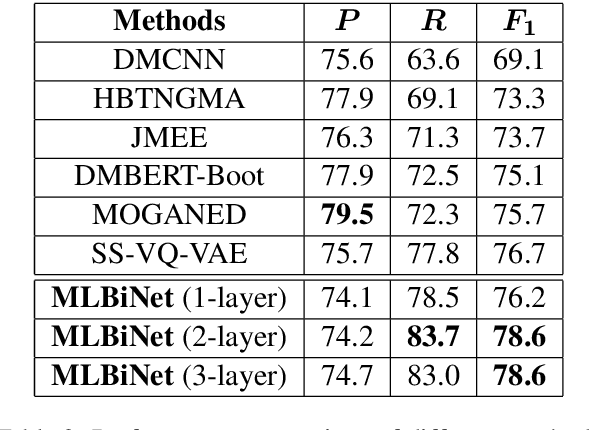
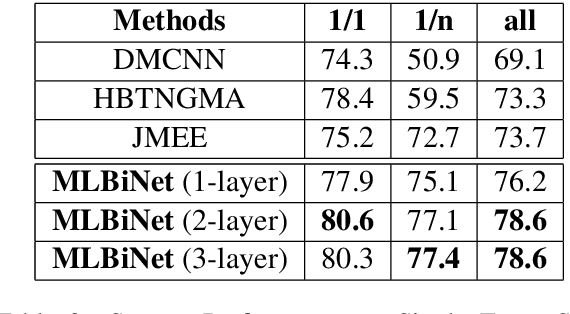
We consider the problem of collectively detecting multiple events, particularly in cross-sentence settings. The key to dealing with the problem is to encode semantic information and model event inter-dependency at a document-level. In this paper, we reformulate it as a Seq2Seq task and propose a Multi-Layer Bidirectional Network (MLBiNet) to capture the document-level association of events and semantic information simultaneously. Specifically, a bidirectional decoder is firstly devised to model event inter-dependency within a sentence when decoding the event tag vector sequence. Secondly, an information aggregation module is employed to aggregate sentence-level semantic and event tag information. Finally, we stack multiple bidirectional decoders and feed cross-sentence information, forming a multi-layer bidirectional tagging architecture to iteratively propagate information across sentences. We show that our approach provides significant improvement in performance compared to the current state-of-the-art results.
Collaborative Visual Inertial SLAM for Multiple Smart Phones
Jun 23, 2021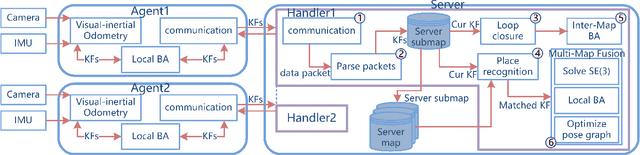
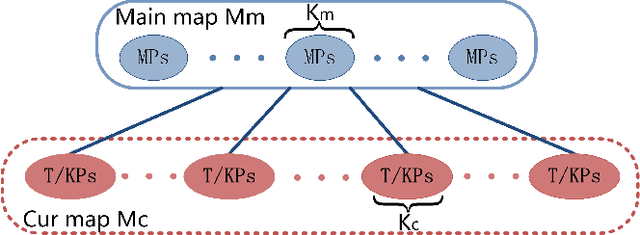
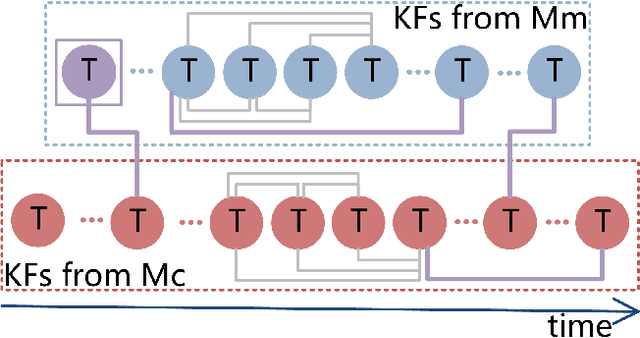
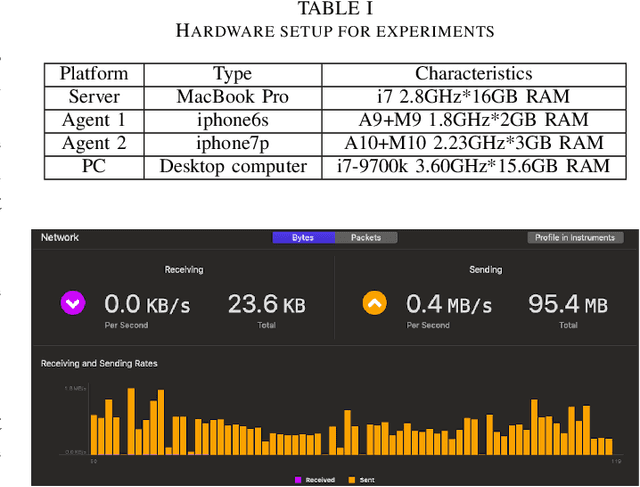
The efficiency and accuracy of mapping are crucial in a large scene and long-term AR applications. Multi-agent cooperative SLAM is the precondition of multi-user AR interaction. The cooperation of multiple smart phones has the potential to improve efficiency and robustness of task completion and can complete tasks that a single agent cannot do. However, it depends on robust communication, efficient location detection, robust mapping, and efficient information sharing among agents. We propose a multi-intelligence collaborative monocular visual-inertial SLAM deployed on multiple ios mobile devices with a centralized architecture. Each agent can independently explore the environment, run a visual-inertial odometry module online, and then send all the measurement information to a central server with higher computing resources. The server manages all the information received, detects overlapping areas, merges and optimizes the map, and shares information with the agents when needed. We have verified the performance of the system in public datasets and real environments. The accuracy of mapping and fusion of the proposed system is comparable to VINS-Mono which requires higher computing resources.
Training Cross-Lingual embeddings for Setswana and Sepedi
Nov 11, 2021African languages still lag in the advances of Natural Language Processing techniques, one reason being the lack of representative data, having a technique that can transfer information between languages can help mitigate against the lack of data problem. This paper trains Setswana and Sepedi monolingual word vectors and uses VecMap to create cross-lingual embeddings for Setswana-Sepedi in order to do a cross-lingual transfer. Word embeddings are word vectors that represent words as continuous floating numbers where semantically similar words are mapped to nearby points in n-dimensional space. The idea of word embeddings is based on the distribution hypothesis that states, semantically similar words are distributed in similar contexts (Harris, 1954). Cross-lingual embeddings leverages monolingual embeddings by learning a shared vector space for two separately trained monolingual vectors such that words with similar meaning are represented by similar vectors. In this paper, we investigate cross-lingual embeddings for Setswana-Sepedi monolingual word vector. We use the unsupervised cross lingual embeddings in VecMap to train the Setswana-Sepedi cross-language word embeddings. We evaluate the quality of the Setswana-Sepedi cross-lingual word representation using a semantic evaluation task. For the semantic similarity task, we translated the WordSim and SimLex tasks into Setswana and Sepedi. We release this dataset as part of this work for other researchers. We evaluate the intrinsic quality of the embeddings to determine if there is improvement in the semantic representation of the word embeddings.
CBIR using Pre-Trained Neural Networks
Oct 27, 2021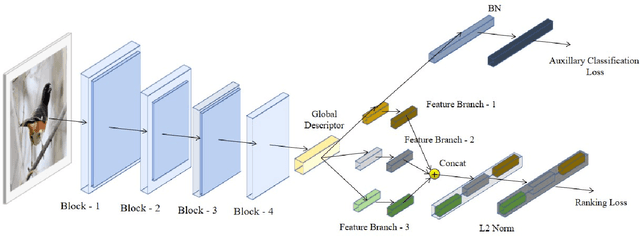

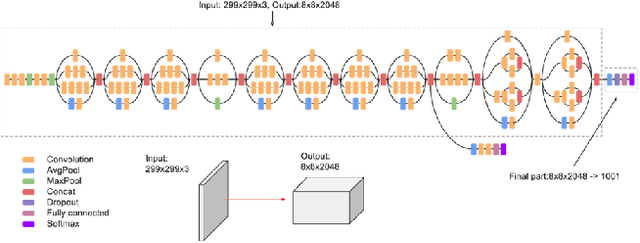
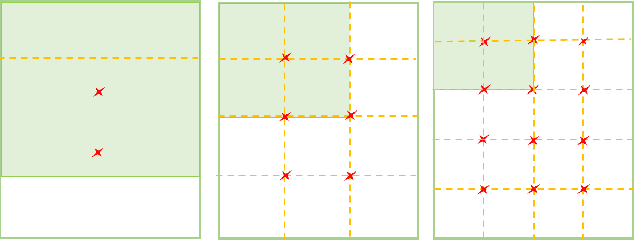
Much of the recent research work in image retrieval, has been focused around using Neural Networks as the core component. Many of the papers in other domain have shown that training multiple models, and then combining their outcomes, provide good results. This is since, a single Neural Network model, may not extract sufficient information from the input. In this paper, we aim to follow a different approach. Instead of the using a single model, we use a pretrained Inception V3 model, and extract activation of its last fully connected layer, which forms a low dimensional representation of the image. This feature matrix, is then divided into branches and separate feature extraction is done for each branch, to obtain multiple features flattened into a vector. Such individual vectors are then combined, to get a single combined feature. We make use of CUB200-2011 Dataset, which comprises of 200 birds classes to train the model on. We achieved a training accuracy of 99.46% and validation accuracy of 84.56% for the same. On further use of 3 branched global descriptors, we improve the validation accuracy to 88.89%. For this, we made use of MS-RMAC feature extraction method.
Robust Feature Learning on Long-Duration Sounds for Acoustic Scene Classification
Aug 11, 2021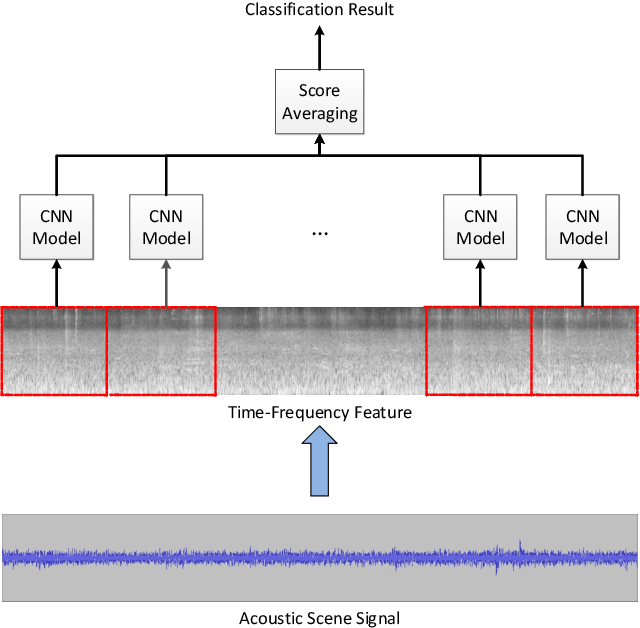
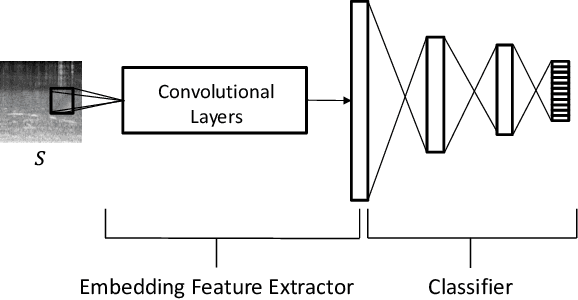
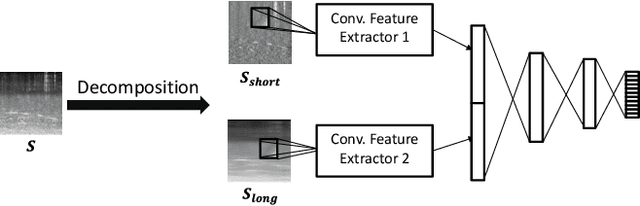
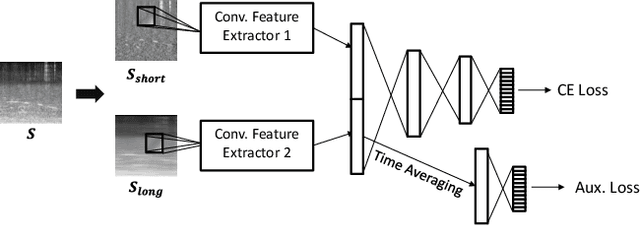
Acoustic scene classification (ASC) aims to identify the type of scene (environment) in which a given audio signal is recorded. The log-mel feature and convolutional neural network (CNN) have recently become the most popular time-frequency (TF) feature representation and classifier in ASC. An audio signal recorded in a scene may include various sounds overlapping in time and frequency. The previous study suggests that separately considering the long-duration sounds and short-duration sounds in CNN may improve ASC accuracy. This study addresses the problem of the generalization ability of acoustic scene classifiers. In practice, acoustic scene signals' characteristics may be affected by various factors, such as the choice of recording devices and the change of recording locations. When an established ASC system predicts scene classes on audios recorded in unseen scenarios, its accuracy may drop significantly. The long-duration sounds not only contain domain-independent acoustic scene information, but also contain channel information determined by the recording conditions, which is prone to over-fitting. For a more robust ASC system, We propose a robust feature learning (RFL) framework to train the CNN. The RFL framework down-weights CNN learning specifically on long-duration sounds. The proposed method is to train an auxiliary classifier with only long-duration sound information as input. The auxiliary classifier is trained with an auxiliary loss function that assigns less learning weight to poorly classified examples than the standard cross-entropy loss. The experimental results show that the proposed RFL framework can obtain a more robust acoustic scene classifier towards unseen devices and cities.
On games and simulators as a platform for development of artificial intelligence for command and control
Oct 21, 2021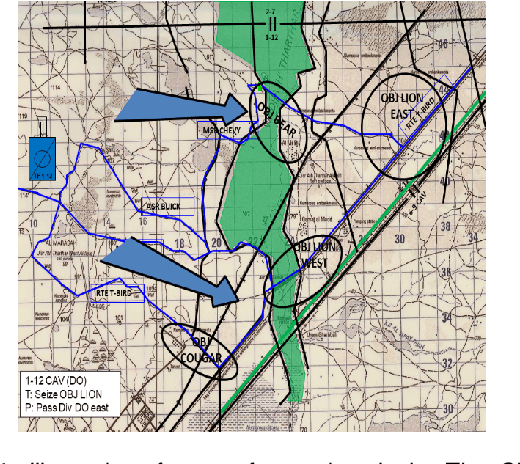

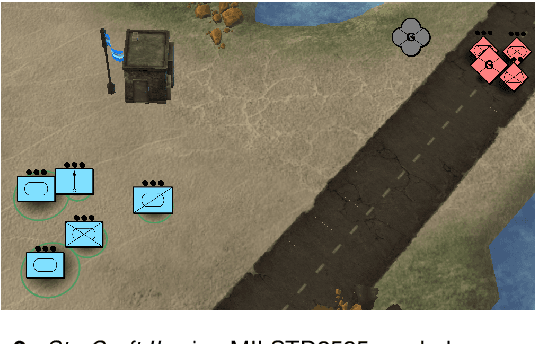
Games and simulators can be a valuable platform to execute complex multi-agent, multiplayer, imperfect information scenarios with significant parallels to military applications: multiple participants manage resources and make decisions that command assets to secure specific areas of a map or neutralize opposing forces. These characteristics have attracted the artificial intelligence (AI) community by supporting development of algorithms with complex benchmarks and the capability to rapidly iterate over new ideas. The success of artificial intelligence algorithms in real-time strategy games such as StarCraft II have also attracted the attention of the military research community aiming to explore similar techniques in military counterpart scenarios. Aiming to bridge the connection between games and military applications, this work discusses past and current efforts on how games and simulators, together with the artificial intelligence algorithms, have been adapted to simulate certain aspects of military missions and how they might impact the future battlefield. This paper also investigates how advances in virtual reality and visual augmentation systems open new possibilities in human interfaces with gaming platforms and their military parallels.