 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Topology-Guided Path Planning for Reliable Visual Navigation of MAVs
Jul 19, 2021

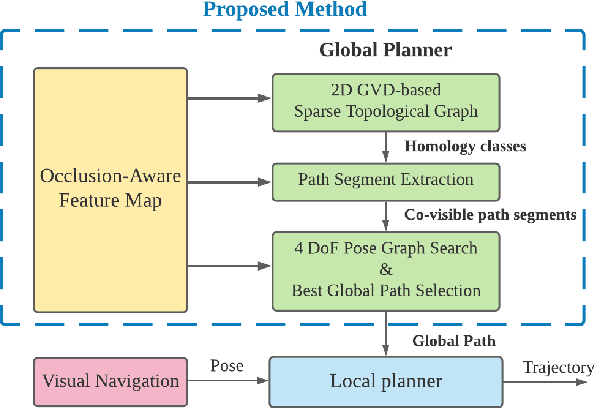
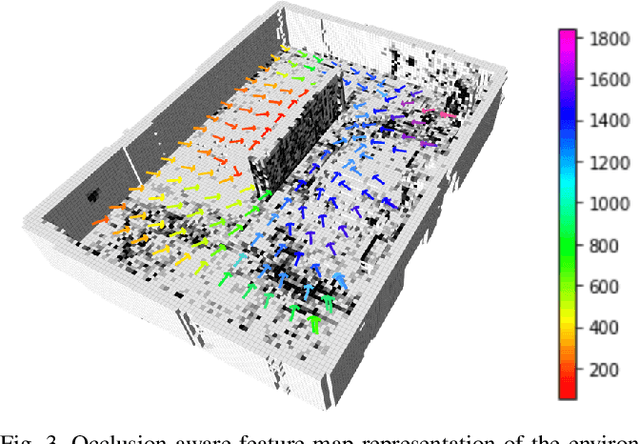
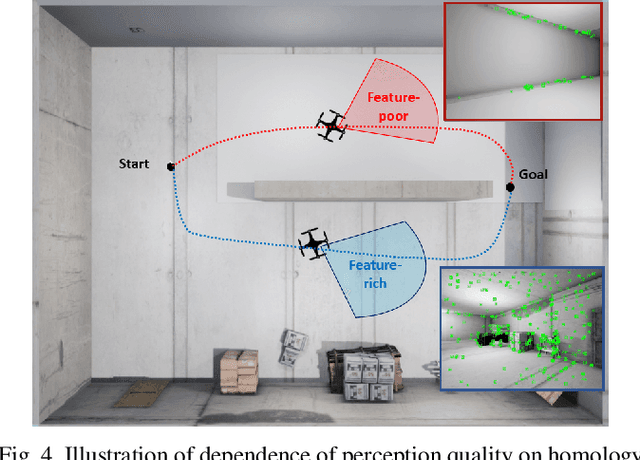
Visual navigation has been widely used for state estimation of micro aerial vehicles (MAVs). For stable visual navigation, MAVs should generate perception-aware paths which guarantee enough visible landmarks. Many previous works on perception-aware path planning focused on sampling-based planners. However, they may suffer from sample inefficiency, which leads to computational burden for finding a global optimal path. To address this issue, we suggest a perception-aware path planner which utilizes topological information of environments. Since the topological class of a path and visible landmarks during traveling the path are closely related, the proposed algorithm checks distinctive topological classes to choose the class with abundant visual information. Topological graph is extracted from the generalized Voronoi diagram of the environment and initial paths with different topological classes are found. To evaluate the perception quality of the classes, we divide the initial path into discrete segments where the points in each segment share similar visual information. The optimal class with high perception quality is selected, and a graph-based planner is utilized to generate path within the class. With simulations and real-world experiments, we confirmed that the proposed method could guarantee accurate visual navigation compared with the perception-agnostic method while showing improved computational efficiency than the sampling-based perception-aware planner.
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
Aug 24, 2021
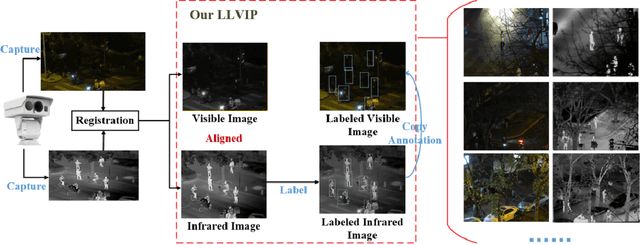
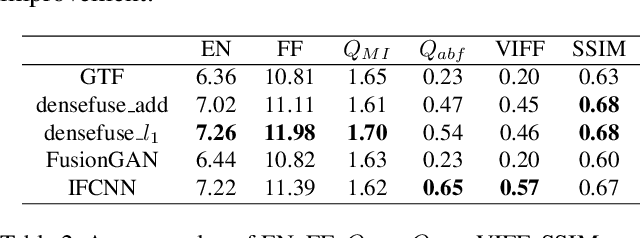

It is very challenging for various visual tasks such as image fusion, pedestrian detection and image-to-image translation in low light conditions due to the loss of effective target areas. In this case, infrared and visible images can be used together to provide both rich detail information and effective target areas. In this paper, we present LLVIP, a visible-infrared paired dataset for low-light vision. This dataset contains 33672 images, or 16836 pairs, most of which were taken at very dark scenes, and all of the images are strictly aligned in time and space. Pedestrians in the dataset are labeled. We compare the dataset with other visible-infrared datasets and evaluate the performance of some popular visual algorithms including image fusion, pedestrian detection and image-to-image translation on the dataset. The experimental results demonstrate the complementary effect of fusion on image information, and find the deficiency of existing algorithms of the three visual tasks in very low-light conditions. We believe the LLVIP dataset will contribute to the community of computer vision by promoting image fusion, pedestrian detection and image-to-image translation in very low-light applications. The dataset is being released in https://bupt-ai-cz.github.io/LLVIP.
Attention-based cross-modal fusion for audio-visual voice activity detection in musical video streams
Jun 21, 2021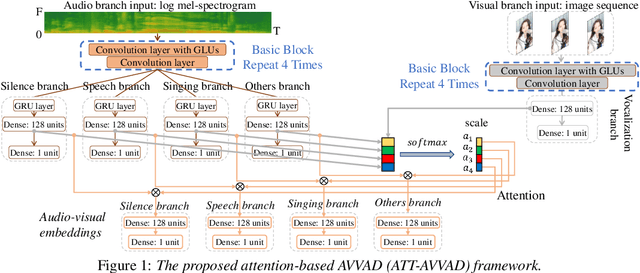

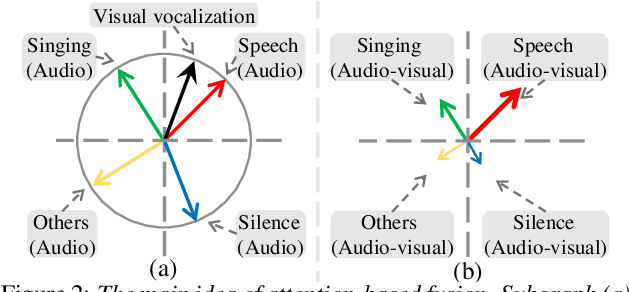
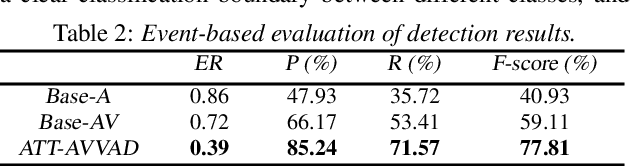
Many previous audio-visual voice-related works focus on speech, ignoring the singing voice in the growing number of musical video streams on the Internet. For processing diverse musical video data, voice activity detection is a necessary step. This paper attempts to detect the speech and singing voices of target performers in musical video streams using audiovisual information. To integrate information of audio and visual modalities, a multi-branch network is proposed to learn audio and image representations, and the representations are fused by attention based on semantic similarity to shape the acoustic representations through the probability of anchor vocalization. Experiments show the proposed audio-visual multi-branch network far outperforms the audio-only model in challenging acoustic environments, indicating the cross-modal information fusion based on semantic correlation is sensible and successful.
A Graph Data Augmentation Strategy with Entropy Preserving
Jul 13, 2021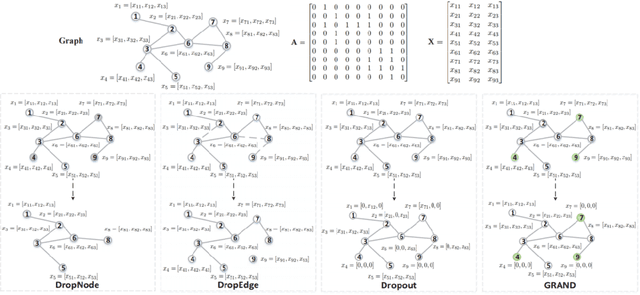
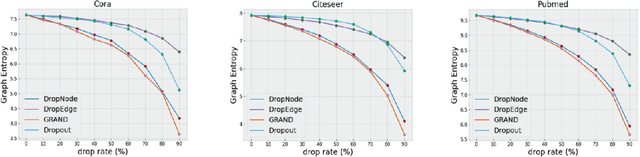
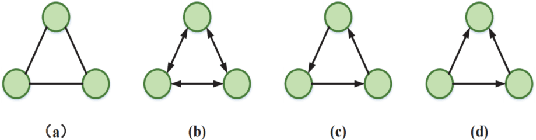
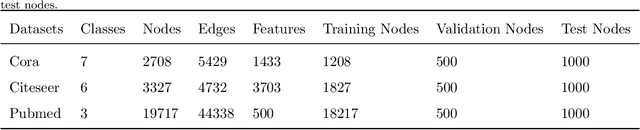
The Graph Convolutional Networks (GCNs) proposed by Kipf and Welling are effective models for semi-supervised learning, but facing the obstacle of over-smoothing, which will weaken the representation ability of GCNs. Recently some works are proposed to tackle with above limitation by randomly perturbing graph topology or feature matrix to generate data augmentations as input for training. However, these operations have to pay the price of information structure integrity breaking, and inevitably sacrifice information stochastically from original graph. In this paper, we introduce a novel graph entropy definition as an quantitative index to evaluate feature information diffusion among a graph. Under considerations of preserving graph entropy, we propose an effective strategy to generate perturbed training data using a stochastic mechanism but guaranteeing graph topology integrity and with only a small amount of graph entropy decaying. Extensive experiments have been conducted on real-world datasets and the results verify the effectiveness of our proposed method in improving semi-supervised node classification accuracy compared with a surge of baselines. Beyond that, our proposed approach significantly enhances the robustness and generalization ability of GCNs during the training process.
End-to-End Urban Driving by Imitating a Reinforcement Learning Coach
Aug 18, 2021End-to-end approaches to autonomous driving commonly rely on expert demonstrations. Although humans are good drivers, they are not good coaches for end-to-end algorithms that demand dense on-policy supervision. On the contrary, automated experts that leverage privileged information can efficiently generate large scale on-policy and off-policy demonstrations. However, existing automated experts for urban driving make heavy use of hand-crafted rules and perform suboptimally even on driving simulators, where ground-truth information is available. To address these issues, we train a reinforcement learning expert that maps bird's-eye view images to continuous low-level actions. While setting a new performance upper-bound on CARLA, our expert is also a better coach that provides informative supervision signals for imitation learning agents to learn from. Supervised by our reinforcement learning coach, a baseline end-to-end agent with monocular camera-input achieves expert-level performance. Our end-to-end agent achieves a 78% success rate while generalizing to a new town and new weather on the NoCrash-dense benchmark and state-of-the-art performance on the more challenging CARLA LeaderBoard.
Click-through Rate Prediction with Auto-Quantized Contrastive Learning
Sep 27, 2021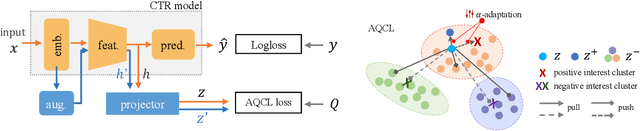
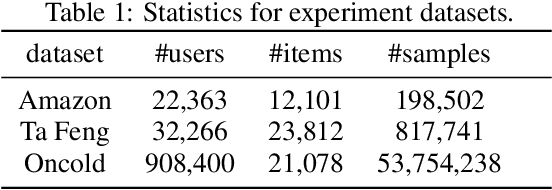
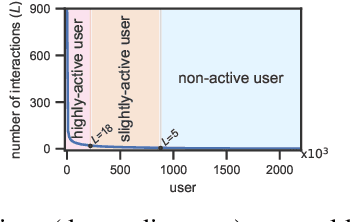
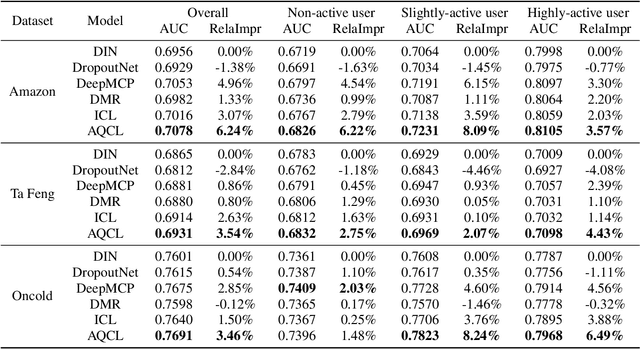
Click-through rate (CTR) prediction becomes indispensable in ubiquitous web recommendation applications. Nevertheless, the current methods are struggling under the cold-start scenarios where the user interactions are extremely sparse. We consider this problem as an automatic identification about whether the user behaviors are rich enough to capture the interests for prediction, and propose an Auto-Quantized Contrastive Learning (AQCL) loss to regularize the model. Different from previous methods, AQCL explores both the instance-instance and the instance-cluster similarity to robustify the latent representation, and automatically reduces the information loss to the active users due to the quantization. The proposed framework is agnostic to different model architectures and can be trained in an end-to-end fashion. Extensive results show that it consistently improves the current state-of-the-art CTR models.
CNNC: A Visual Analytics System for Comparative Studies of Deep Convolutional Neural Networks
Oct 25, 2021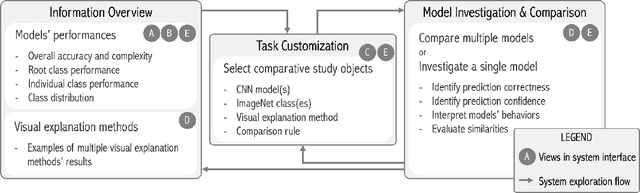
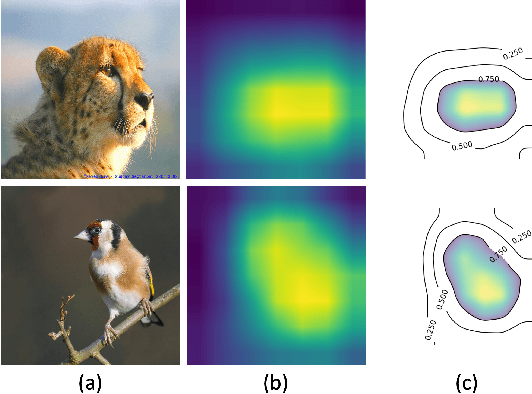

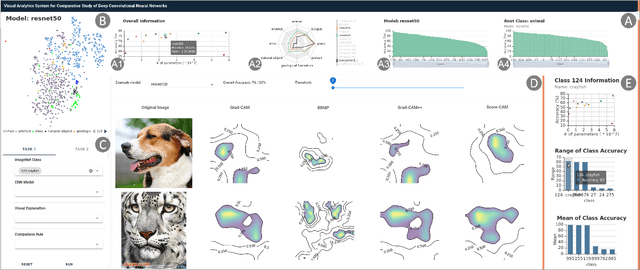
The rapid development of Convolutional Neural Networks (CNNs) in recent years has triggered significant breakthroughs in many machine learning (ML) applications. The ability to understand and compare various CNN models available is thus essential. The conventional approach with visualizing each model's quantitative features, such as classification accuracy and computational complexity, is not sufficient for a deeper understanding and comparison of the behaviors of different models. Moreover, most of the existing tools for assessing CNN behaviors only support comparison between two models and lack the flexibility of customizing the analysis tasks according to user needs. This paper presents a visual analytics system, CNN Comparator (CNNC), that supports the in-depth inspection of a single CNN model as well as comparative studies of two or more models. The ability to compare a larger number of (e.g., tens of) models especially distinguishes our system from previous ones. With a carefully designed model visualization and explaining support, CNNC facilitates a highly interactive workflow that promptly presents both quantitative and qualitative information at each analysis stage. We demonstrate CNNC's effectiveness for assisting ML practitioners in evaluating and comparing multiple CNN models through two use cases and one preliminary evaluation study using the image classification tasks on the ImageNet dataset.
RiWNet: A moving object instance segmentation Network being Robust in adverse Weather conditions
Sep 04, 2021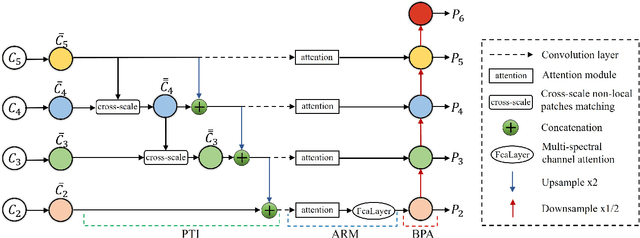

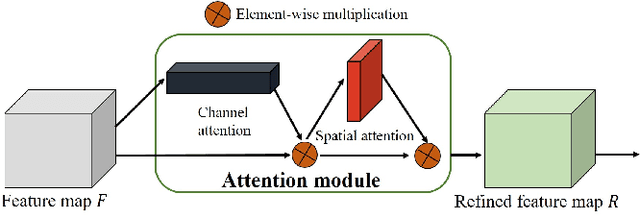
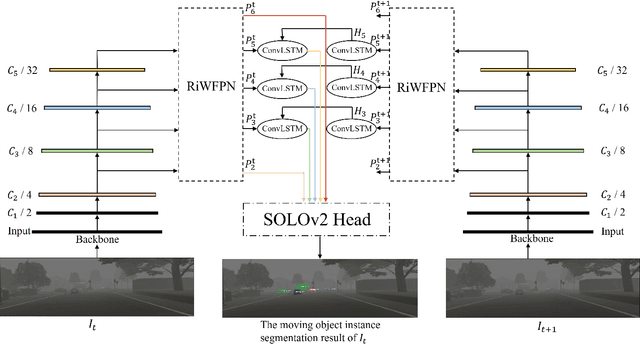
Segmenting each moving object instance in a scene is essential for many applications. But like many other computer vision tasks, this task performs well in optimal weather, but then adverse weather tends to fail. To be robust in weather conditions, the usual way is to train network in data of given weather pattern or to fuse multiple sensors. We focus on a new possibility, that is, to improve its resilience to weather interference through the network's structural design. First, we propose a novel FPN structure called RiWFPN with a progressive top-down interaction and attention refinement module. RiWFPN can directly replace other FPN structures to improve the robustness of the network in non-optimal weather conditions. Then we extend SOLOV2 to capture temporal information in video to learn motion information, and propose a moving object instance segmentation network with RiWFPN called RiWNet. Finally, in order to verify the effect of moving instance segmentation in different weather disturbances, we propose a VKTTI-moving dataset which is a moving instance segmentation dataset based on the VKTTI dataset, taking into account different weather scenes such as rain, fog, sunset, morning as well as overcast. The experiment proves how RiWFPN improves the network's resilience to adverse weather effects compared to other FPN structures. We compare RiWNet to several other state-of-the-art methods in some challenging datasets, and RiWNet shows better performance especially under adverse weather conditions.
Self Supervision to Distillation for Long-Tailed Visual Recognition
Sep 09, 2021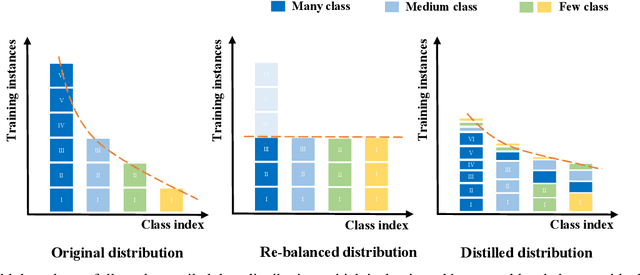
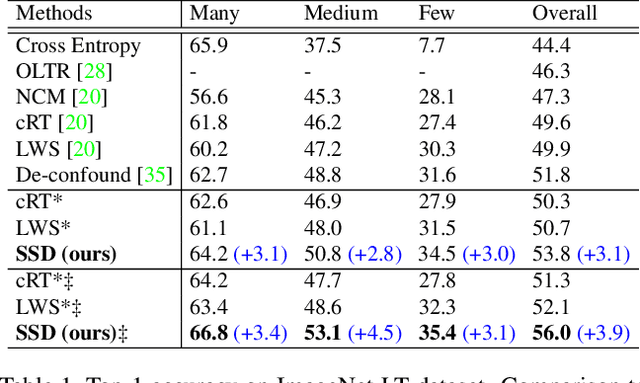
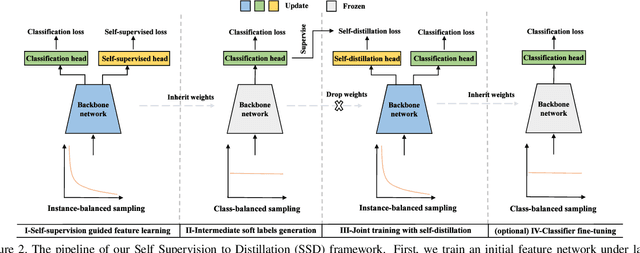
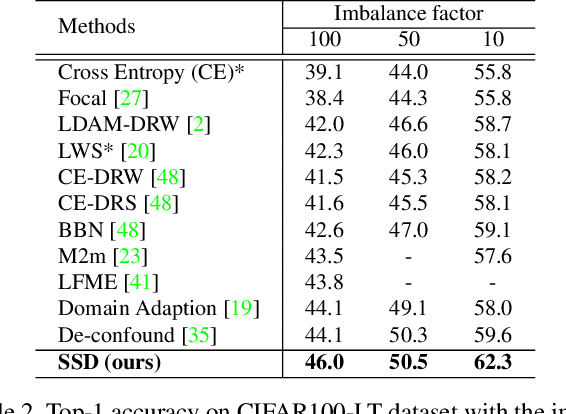
Deep learning has achieved remarkable progress for visual recognition on large-scale balanced datasets but still performs poorly on real-world long-tailed data. Previous methods often adopt class re-balanced training strategies to effectively alleviate the imbalance issue, but might be a risk of over-fitting tail classes. The recent decoupling method overcomes over-fitting issues by using a multi-stage training scheme, yet, it is still incapable of capturing tail class information in the feature learning stage. In this paper, we show that soft label can serve as a powerful solution to incorporate label correlation into a multi-stage training scheme for long-tailed recognition. The intrinsic relation between classes embodied by soft labels turns out to be helpful for long-tailed recognition by transferring knowledge from head to tail classes. Specifically, we propose a conceptually simple yet particularly effective multi-stage training scheme, termed as Self Supervised to Distillation (SSD). This scheme is composed of two parts. First, we introduce a self-distillation framework for long-tailed recognition, which can mine the label relation automatically. Second, we present a new distillation label generation module guided by self-supervision. The distilled labels integrate information from both label and data domains that can model long-tailed distribution effectively. We conduct extensive experiments and our method achieves the state-of-the-art results on three long-tailed recognition benchmarks: ImageNet-LT, CIFAR100-LT and iNaturalist 2018. Our SSD outperforms the strong LWS baseline by from $2.7\%$ to $4.5\%$ on various datasets. The code is available at https://github.com/MCG-NJU/SSD-LT.
WaveBeat: End-to-end beat and downbeat tracking in the time domain
Oct 04, 2021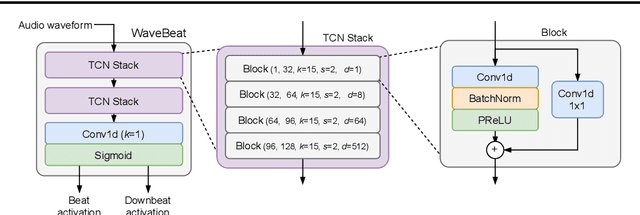
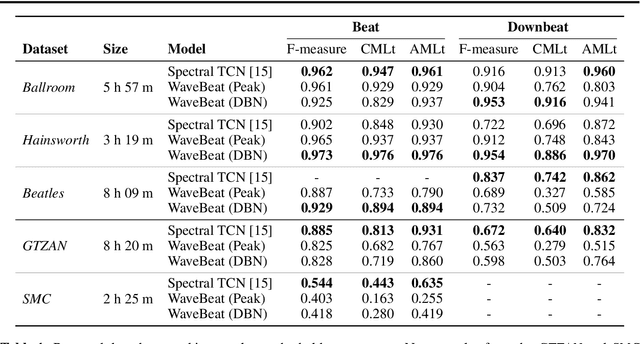
Deep learning approaches for beat and downbeat tracking have brought advancements. However, these approaches continue to rely on hand-crafted, subsampled spectral features as input, restricting the information available to the model. In this work, we propose WaveBeat, an end-to-end approach for joint beat and downbeat tracking operating directly on waveforms. This method forgoes engineered spectral features, and instead, produces beat and downbeat predictions directly from the waveform, the first of its kind for this task. Our model utilizes temporal convolutional networks (TCNs) operating on waveforms that achieve a very large receptive field ($\geq$ 30 s) at audio sample rates in a memory efficient manner by employing rapidly growing dilation factors with fewer layers. With a straightforward data augmentation strategy, our method outperforms previous state-of-the-art methods on some datasets, while producing comparable results on others, demonstrating the potential for time domain approaches.