 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
uniblock: Scoring and Filtering Corpus with Unicode Block Information
Aug 26, 2019

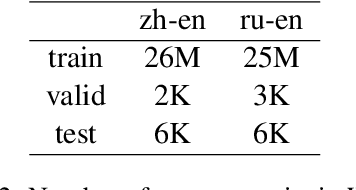
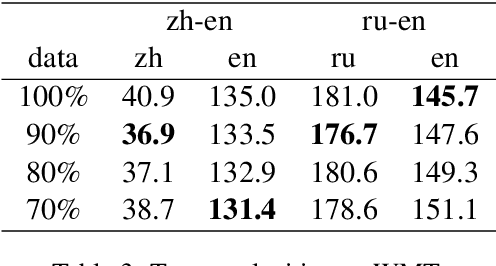
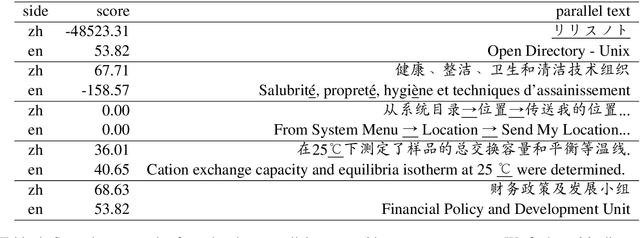
The preprocessing pipelines in Natural Language Processing usually involve a step of removing sentences consisted of illegal characters. The definition of illegal characters and the specific removal strategy depend on the task, language, domain, etc, which often lead to tiresome and repetitive scripting of rules. In this paper, we introduce a simple statistical method, uniblock, to overcome this problem. For each sentence, uniblock generates a fixed-size feature vector using Unicode block information of the characters. A Gaussian mixture model is then estimated on some clean corpus using variational inference. The learned model can then be used to score sentences and filter corpus. We present experimental results on Sentiment Analysis, Language Modeling and Machine Translation, and show the simplicity and effectiveness of our method.
Multi-sensor joint target detection, tracking and classification via Bernoulli filter
Sep 23, 2021
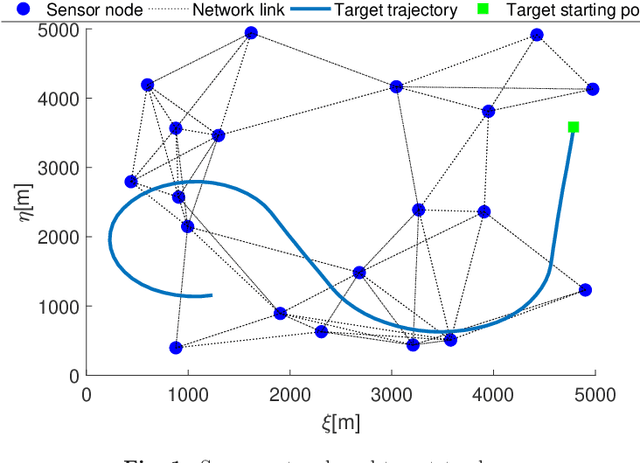

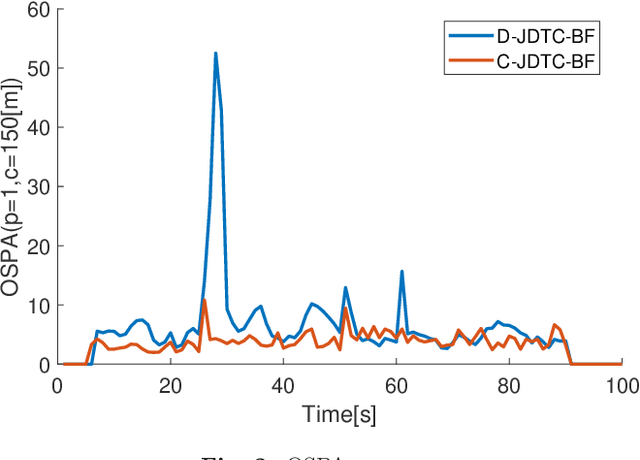
This paper focuses on \textit{joint detection, tracking and classification} (JDTC) of a target via multi-sensor fusion. The target can be present or not, can belong to different classes, and depending on its class can behave according to different kinematic modes. Accordingly, it is modeled as a suitably extended Bernoulli \textit{random finite set} (RFS) uniquely characterized by existence, classification, class-conditioned mode and class\&mode-conditioned state probability distributions. By designing suitable centralized and distributed rules for fusing information on target existence, class, mode and state from different sensor nodes, novel \textit{centralized} and \textit{distributed} JDTC \textit{Bernoulli filters} (C-JDTC-BF and D-JDTC-BF), are proposed. The performance of the proposed JDTC-BF approach is evaluated by means of simulation experiments.
Can Q-Learning be Improved with Advice?
Oct 25, 2021Despite rapid progress in theoretical reinforcement learning (RL) over the last few years, most of the known guarantees are worst-case in nature, failing to take advantage of structure that may be known a priori about a given RL problem at hand. In this paper we address the question of whether worst-case lower bounds for regret in online learning of Markov decision processes (MDPs) can be circumvented when information about the MDP, in the form of predictions about its optimal $Q$-value function, is given to the algorithm. We show that when the predictions about the optimal $Q$-value function satisfy a reasonably weak condition we call distillation, then we can improve regret bounds by replacing the set of state-action pairs with the set of state-action pairs on which the predictions are grossly inaccurate. This improvement holds for both uniform regret bounds and gap-based ones. Further, we are able to achieve this property with an algorithm that achieves sublinear regret when given arbitrary predictions (i.e., even those which are not a distillation). Our work extends a recent line of work on algorithms with predictions, which has typically focused on simple online problems such as caching and scheduling, to the more complex and general problem of reinforcement learning.
STR-GQN: Scene Representation and Rendering for Unknown Cameras Based on Spatial Transformation Routing
Aug 06, 2021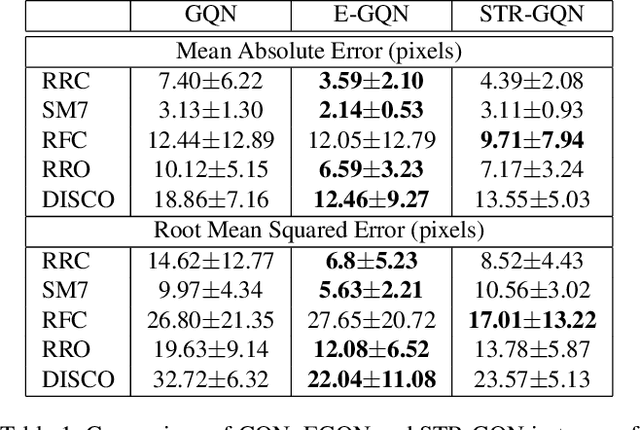
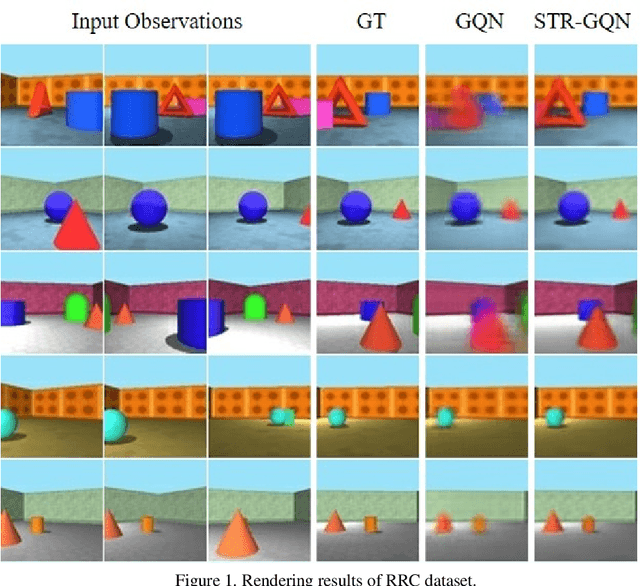
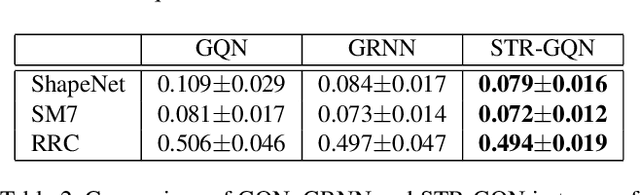

Geometry-aware modules are widely applied in recent deep learning architectures for scene representation and rendering. However, these modules require intrinsic camera information that might not be obtained accurately. In this paper, we propose a Spatial Transformation Routing (STR) mechanism to model the spatial properties without applying any geometric prior. The STR mechanism treats the spatial transformation as the message passing process, and the relation between the view poses and the routing weights is modeled by an end-to-end trainable neural network. Besides, an Occupancy Concept Mapping (OCM) framework is proposed to provide explainable rationals for scene-fusion processes. We conducted experiments on several datasets and show that the proposed STR mechanism improves the performance of the Generative Query Network (GQN). The visualization results reveal that the routing process can pass the observed information from one location of some view to the associated location in the other view, which demonstrates the advantage of the proposed model in terms of spatial cognition.
Event Data Association via Robust Model Fitting for Event-based Object Tracking
Oct 25, 2021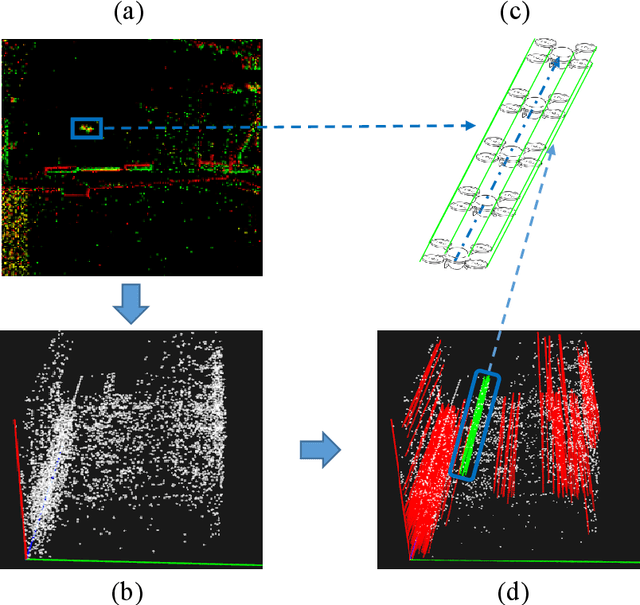
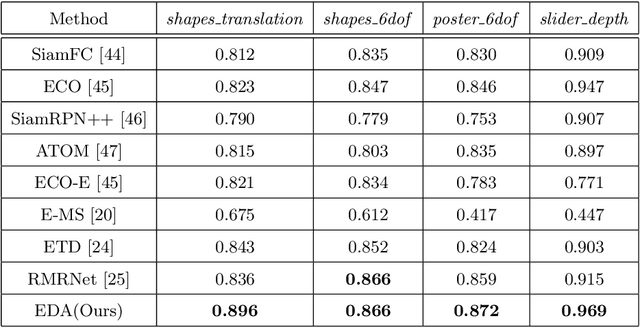
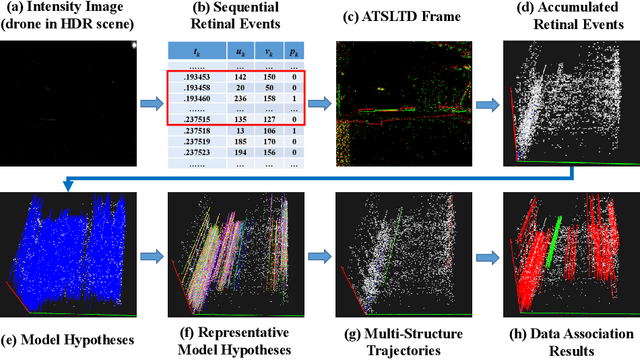
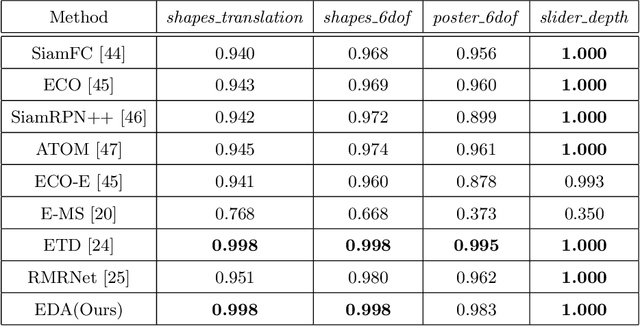
Event-based approaches, which are based on bio-inspired asynchronous event cameras, have achieved promising performance on various computer vision tasks. However, the study of the fundamental event data association problem is still in its infancy. In this paper, we propose a novel Event Data Association approach (called EDA) to explicitly address the data association problem. The proposed EDA seeks for event trajectories that best fit the event data, in order to perform unifying data association. In EDA, we first asynchronously gather the event data, based on its information entropy. Then, we introduce a deterministic model hypothesis generation strategy, which effectively generates model hypotheses from the gathered events, to represent the corresponding event trajectories. After that, we present a two-stage weighting algorithm, which robustly weighs and selects true models from the generated model hypotheses, through multi-structural geometric model fitting. Meanwhile, we also propose an adaptive model selection strategy to automatically determine the number of the true models. Finally, we use the selected true models to associate the event data, without being affected by sensor noise and irrelevant structures. We evaluate the performance of the proposed EDA on the object tracking task. The experimental results show the effectiveness of EDA under challenging scenarios, such as high speed, motion blur, and high dynamic range conditions.
M5Product: A Multi-modal Pretraining Benchmark for E-commercial Product Downstream Tasks
Sep 09, 2021
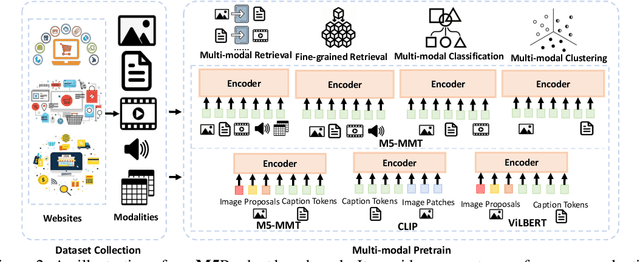
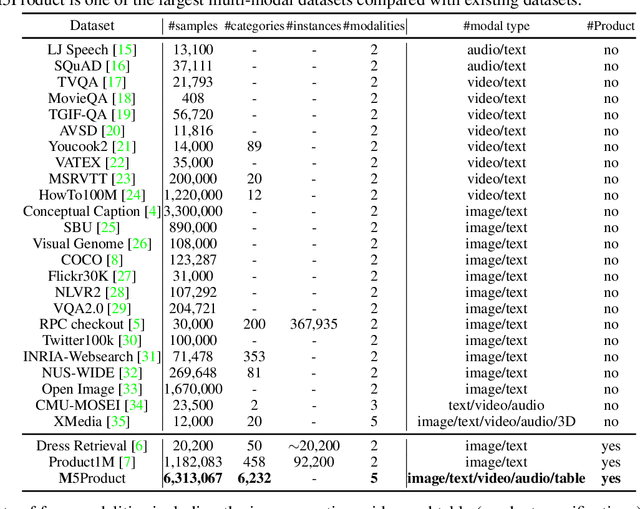
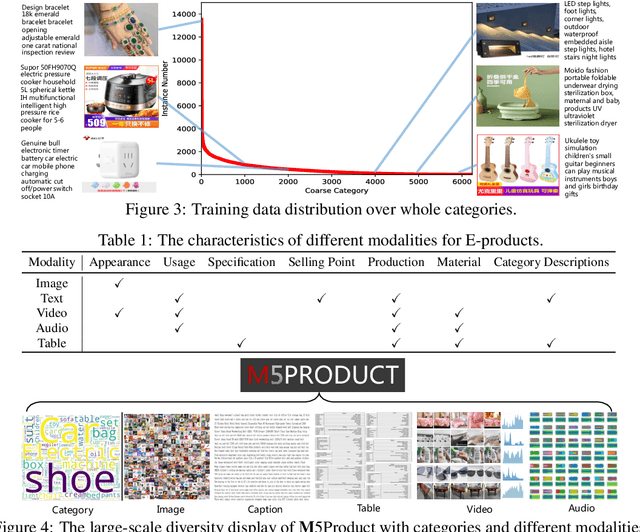
In this paper, we aim to advance the research of multi-modal pre-training on E-commerce and subsequently contribute a large-scale dataset, named M5Product, which consists of over 6 million multimodal pairs, covering more than 6,000 categories and 5,000 attributes. Generally, existing multi-modal datasets are either limited in scale or modality diversity. Differently, our M5Product is featured from the following aspects. First, the M5Product dataset is 500 times larger than the public multimodal dataset with the same number of modalities and nearly twice larger compared with the largest available text-image cross-modal dataset. Second, the dataset contains rich information of multiple modalities including image, text, table, video and audio, in which each modality can capture different views of semantic information (e.g. category, attributes, affordance, brand, preference) and complements the other. Third, to better accommodate with real-world problems, a few portion of M5Product contains incomplete modality pairs and noises while having the long-tailed distribution, which aligns well with real-world scenarios. Finally, we provide a baseline model M5-MMT that makes the first attempt to integrate the different modality configuration into an unified model for feature fusion to address the great challenge for semantic alignment. We also evaluate various multi-model pre-training state-of-the-arts for benchmarking their capabilities in learning from unlabeled data under the different number of modalities on the M5Product dataset. We conduct extensive experiments on four downstream tasks and provide some interesting findings on these modalities. Our dataset and related code are available at https://xiaodongsuper.github.io/M5Product_dataset.
Coarse-to-fine Animal Pose and Shape Estimation
Nov 16, 2021
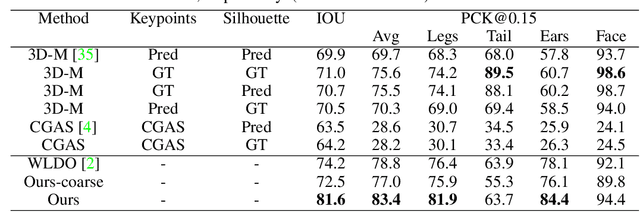

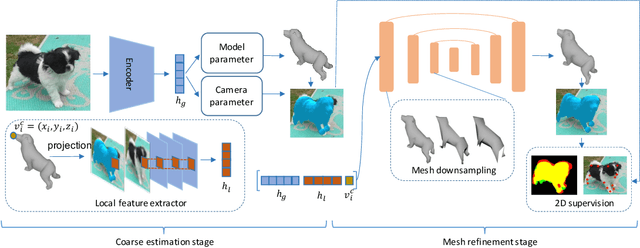
Most existing animal pose and shape estimation approaches reconstruct animal meshes with a parametric SMAL model. This is because the low-dimensional pose and shape parameters of the SMAL model makes it easier for deep networks to learn the high-dimensional animal meshes. However, the SMAL model is learned from scans of toy animals with limited pose and shape variations, and thus may not be able to represent highly varying real animals well. This may result in poor fittings of the estimated meshes to the 2D evidences, e.g. 2D keypoints or silhouettes. To mitigate this problem, we propose a coarse-to-fine approach to reconstruct 3D animal mesh from a single image. The coarse estimation stage first estimates the pose, shape and translation parameters of the SMAL model. The estimated meshes are then used as a starting point by a graph convolutional network (GCN) to predict a per-vertex deformation in the refinement stage. This combination of SMAL-based and vertex-based representations benefits from both parametric and non-parametric representations. We design our mesh refinement GCN (MRGCN) as an encoder-decoder structure with hierarchical feature representations to overcome the limited receptive field of traditional GCNs. Moreover, we observe that the global image feature used by existing animal mesh reconstruction works is unable to capture detailed shape information for mesh refinement. We thus introduce a local feature extractor to retrieve a vertex-level feature and use it together with the global feature as the input of the MRGCN. We test our approach on the StanfordExtra dataset and achieve state-of-the-art results. Furthermore, we test the generalization capacity of our approach on the Animal Pose and BADJA datasets. Our code is available at the project website.
Seeing biodiversity: perspectives in machine learning for wildlife conservation
Oct 25, 2021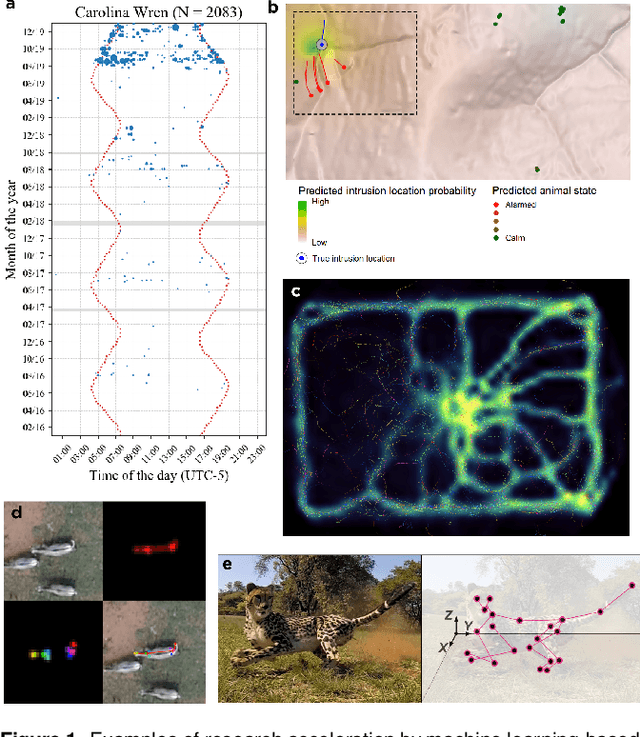
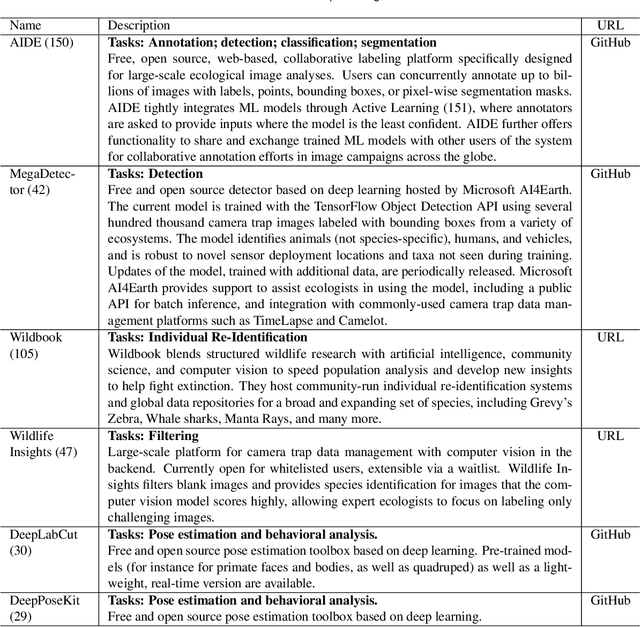

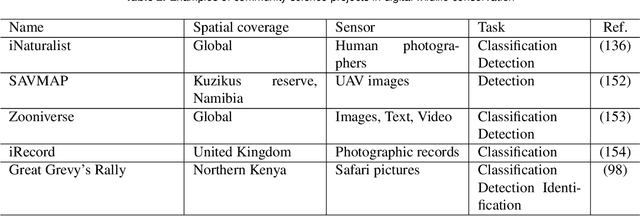
Data acquisition in animal ecology is rapidly accelerating due to inexpensive and accessible sensors such as smartphones, drones, satellites, audio recorders and bio-logging devices. These new technologies and the data they generate hold great potential for large-scale environmental monitoring and understanding, but are limited by current data processing approaches which are inefficient in how they ingest, digest, and distill data into relevant information. We argue that machine learning, and especially deep learning approaches, can meet this analytic challenge to enhance our understanding, monitoring capacity, and conservation of wildlife species. Incorporating machine learning into ecological workflows could improve inputs for population and behavior models and eventually lead to integrated hybrid modeling tools, with ecological models acting as constraints for machine learning models and the latter providing data-supported insights. In essence, by combining new machine learning approaches with ecological domain knowledge, animal ecologists can capitalize on the abundance of data generated by modern sensor technologies in order to reliably estimate population abundances, study animal behavior and mitigate human/wildlife conflicts. To succeed, this approach will require close collaboration and cross-disciplinary education between the computer science and animal ecology communities in order to ensure the quality of machine learning approaches and train a new generation of data scientists in ecology and conservation.
WaveBeat: End-to-end beat and downbeat tracking in the time domain
Oct 04, 2021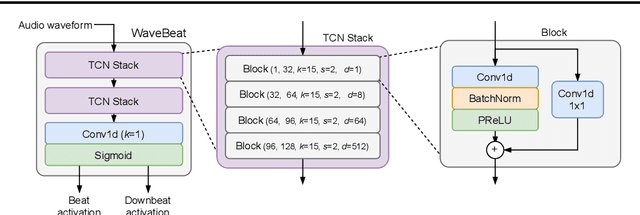
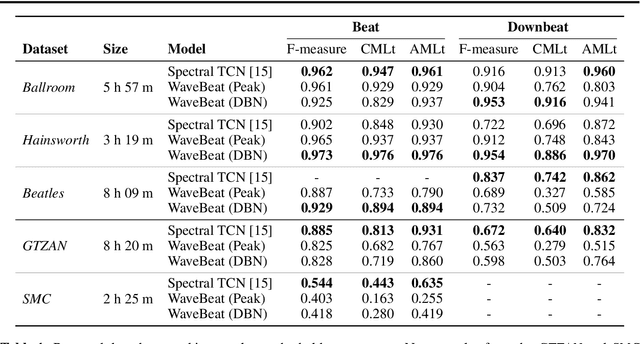
Deep learning approaches for beat and downbeat tracking have brought advancements. However, these approaches continue to rely on hand-crafted, subsampled spectral features as input, restricting the information available to the model. In this work, we propose WaveBeat, an end-to-end approach for joint beat and downbeat tracking operating directly on waveforms. This method forgoes engineered spectral features, and instead, produces beat and downbeat predictions directly from the waveform, the first of its kind for this task. Our model utilizes temporal convolutional networks (TCNs) operating on waveforms that achieve a very large receptive field ($\geq$ 30 s) at audio sample rates in a memory efficient manner by employing rapidly growing dilation factors with fewer layers. With a straightforward data augmentation strategy, our method outperforms previous state-of-the-art methods on some datasets, while producing comparable results on others, demonstrating the potential for time domain approaches.
SpeechT5: Unified-Modal Encoder-Decoder Pre-training for Spoken Language Processing
Oct 14, 2021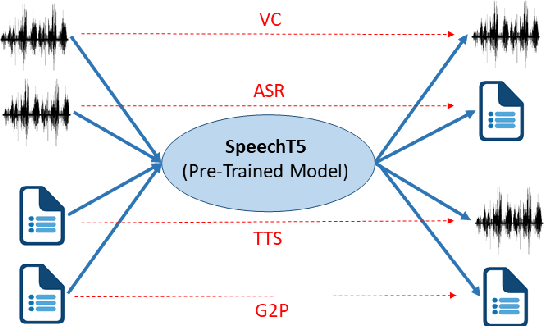
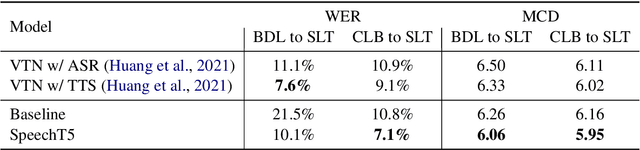
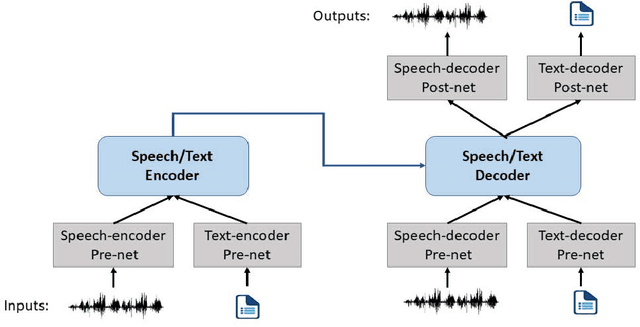
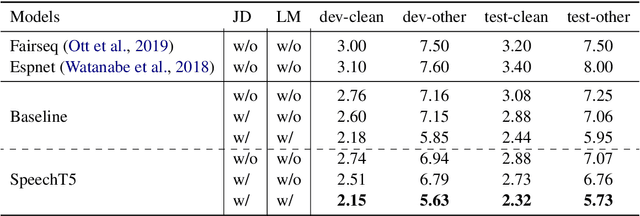
Motivated by the success of T5 (Text-To-Text Transfer Transformer) in pre-training natural language processing models, we propose a unified-modal SpeechT5 framework that explores the encoder-decoder pre-training for self-supervised speech/text representation learning. The SpeechT5 framework consists of a shared encoder-decoder network and six modal-specific (speech/text) pre/post-nets. After preprocessing the speech/text input through the pre-nets, the shared encoder-decoder network models the sequence to sequence transformation, and then the post-nets generate the output in the speech/text modality based on the decoder output. Particularly, SpeechT5 can pre-train on a large scale of unlabeled speech and text data to improve the capability of the speech and textual modeling. To align the textual and speech information into a unified semantic space, we propose a cross-modal vector quantization method with random mixing-up to bridge speech and text. Extensive evaluations on a wide variety of spoken language processing tasks, including voice conversion, automatic speech recognition, text to speech, and speaker identification, show the superiority of the proposed SpeechT5 framework.