 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhance Long Text Understanding via Distilled Gist Detector from Abstractive Summarization
Oct 10, 2021

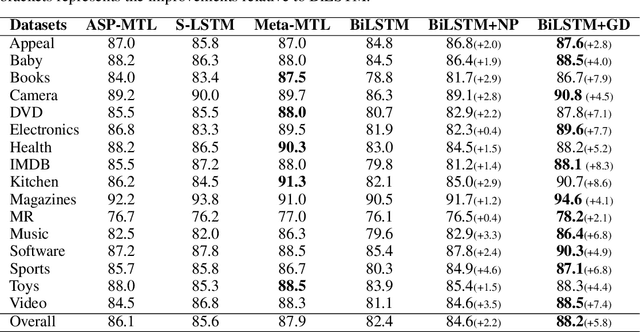
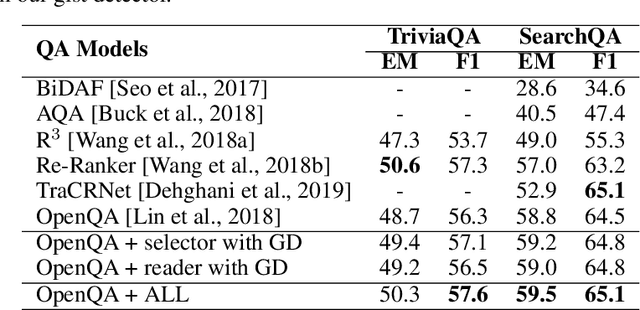
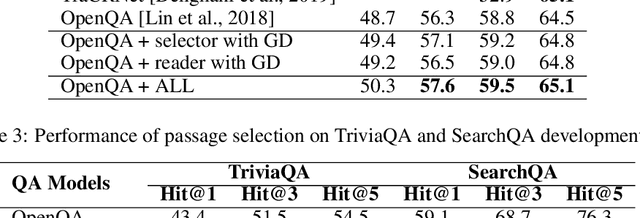
Long text understanding is important yet challenging in natural language processing. A long article or essay usually contains many redundant words that are not pertinent to its gist and sometimes can be regarded as noise. In this paper, we consider the problem of how to disentangle the gist-relevant and irrelevant information for long text understanding. With distillation mechanism, we transfer the knowledge about how to focus the salient parts from the abstractive summarization model and further integrate the distilled model, named \emph{Gist Detector}, into existing models as a supplementary component to augment the long text understanding. Experiments on document classification, distantly supervised open-domain question answering (DS-QA) and non-parallel text style transfer show that our method can significantly improve the performance of the baseline models, and achieves state-of-the-art overall results for document classification.
TabularNet: A Neural Network Architecture for Understanding Semantic Structures of Tabular Data
Jun 06, 2021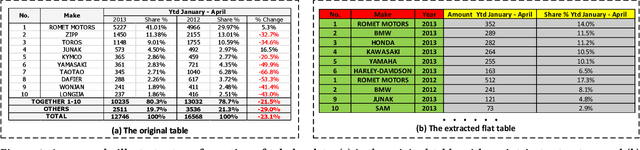
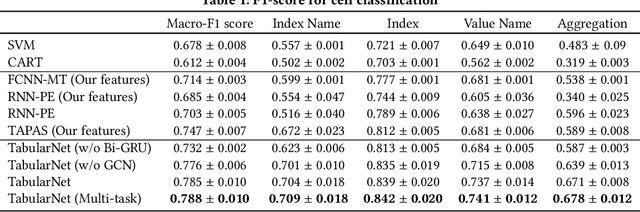
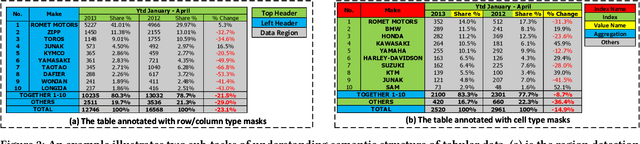
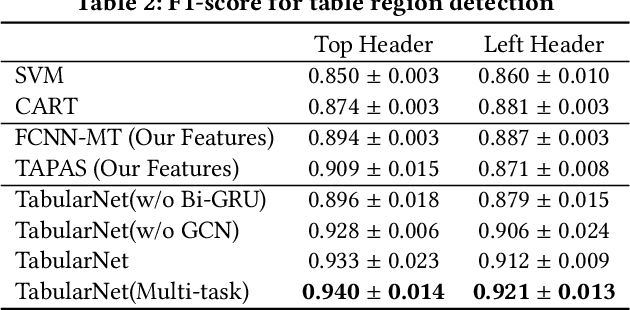
Tabular data are ubiquitous for the widespread applications of tables and hence have attracted the attention of researchers to extract underlying information. One of the critical problems in mining tabular data is how to understand their inherent semantic structures automatically. Existing studies typically adopt Convolutional Neural Network (CNN) to model the spatial information of tabular structures yet ignore more diverse relational information between cells, such as the hierarchical and paratactic relationships. To simultaneously extract spatial and relational information from tables, we propose a novel neural network architecture, TabularNet. The spatial encoder of TabularNet utilizes the row/column-level Pooling and the Bidirectional Gated Recurrent Unit (Bi-GRU) to capture statistical information and local positional correlation, respectively. For relational information, we design a new graph construction method based on the WordNet tree and adopt a Graph Convolutional Network (GCN) based encoder that focuses on the hierarchical and paratactic relationships between cells. Our neural network architecture can be a unified neural backbone for different understanding tasks and utilized in a multitask scenario. We conduct extensive experiments on three classification tasks with two real-world spreadsheet data sets, and the results demonstrate the effectiveness of our proposed TabularNet over state-of-the-art baselines.
Deployment of a Free-Text Analytics Platform at a UK National Health Service Research Hospital: CogStack at University College London Hospitals
Aug 15, 2021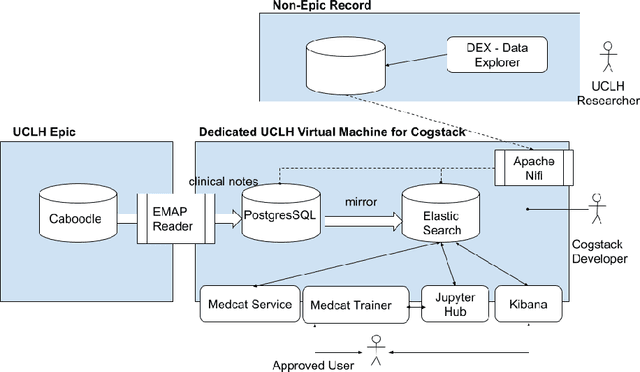
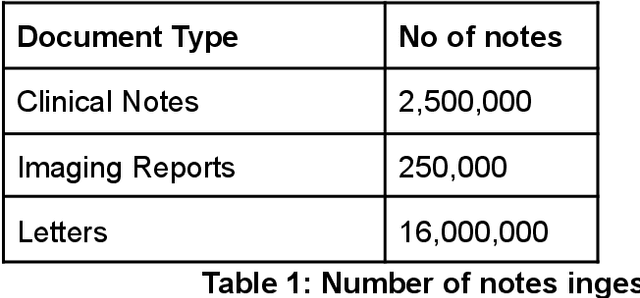
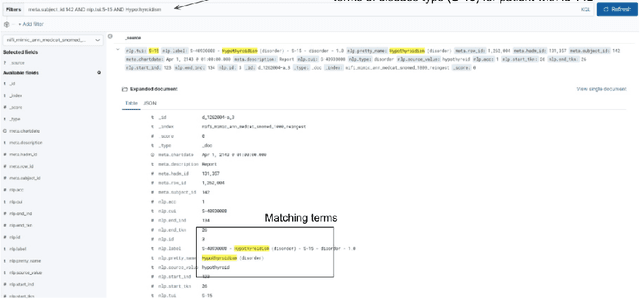
As more healthcare organisations transition to using electronic health record (EHR) systems it is important for these organisations to maximise the secondary use of their data to support service improvement and clinical research. These organisations will find it challenging to have systems which can mine information from the unstructured data fields in the record (clinical notes, letters etc) and more practically have such systems interact with all of the hospitals data systems (legacy and current). To tackle this problem at University College London Hospitals, we have deployed an enhanced version of the CogStack platform; an information retrieval platform with natural language processing capabilities which we have configured to process the hospital's existing and legacy records. The platform has improved data ingestion capabilities as well as better tools for natural language processing. To date we have processed over 18 million records and the insights produced from CogStack have informed a number of clinical research use cases at the hospitals.
TIP: Task-Informed Motion Prediction for Intelligent Systems
Oct 17, 2021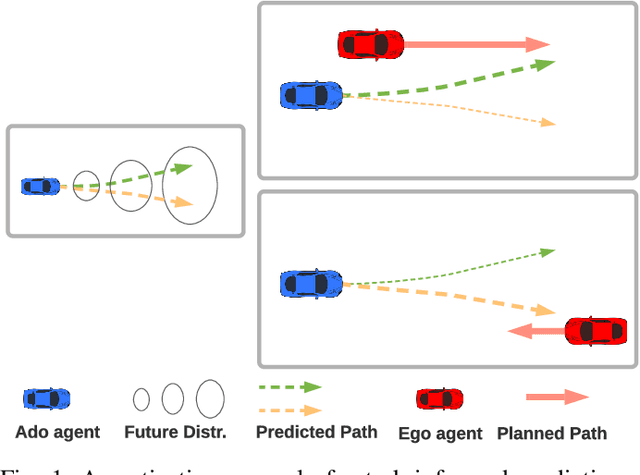
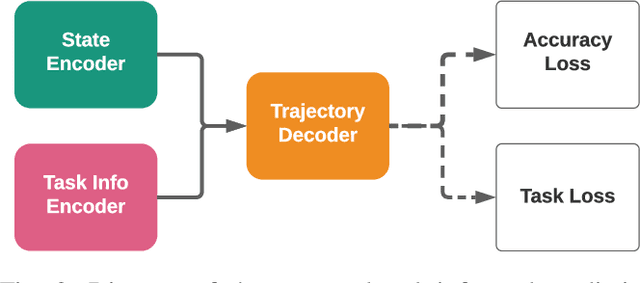

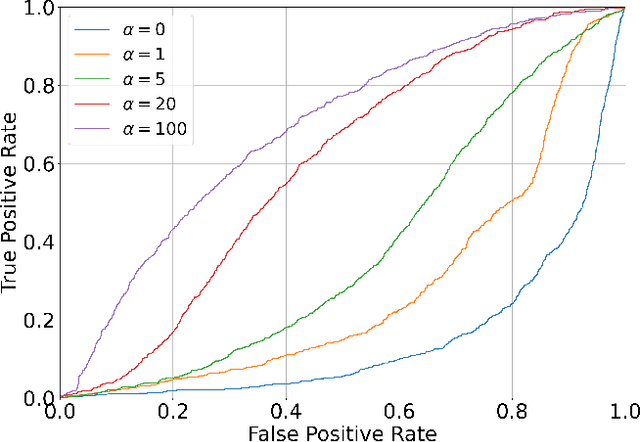
Motion prediction is important for intelligent driving systems, providing the future distributions of road agent behaviors and supporting various decision making tasks. Existing motion predictors are often optimized and evaluated via task-agnostic measures based on prediction accuracy. Such measures fail to account for the use of prediction in downstream tasks, and could result in sub-optimal task performance. We propose a task-informed motion prediction framework that jointly reasons about prediction accuracy and task utility, to better support downstream tasks through its predictions. The task utility function does not require the full task information, but rather a specification of the utility of the task, resulting in predictors that serve a wide range of downstream tasks. We demonstrate our framework on two use cases of task utilities, in the context of autonomous driving and parallel autonomy, and show the advantage of task-informed predictors over task-agnostic ones on the Waymo Open Motion dataset.
Cooperative Multi-Agent Actor-Critic for Privacy-Preserving Load Scheduling in a Residential Microgrid
Oct 06, 2021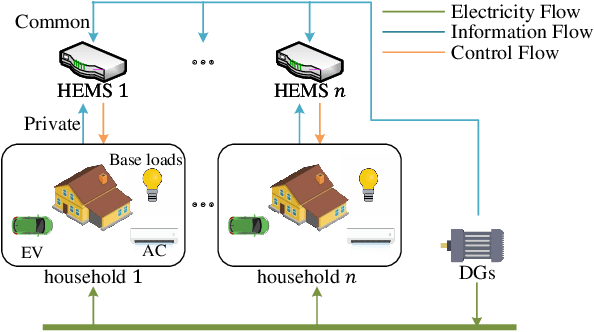
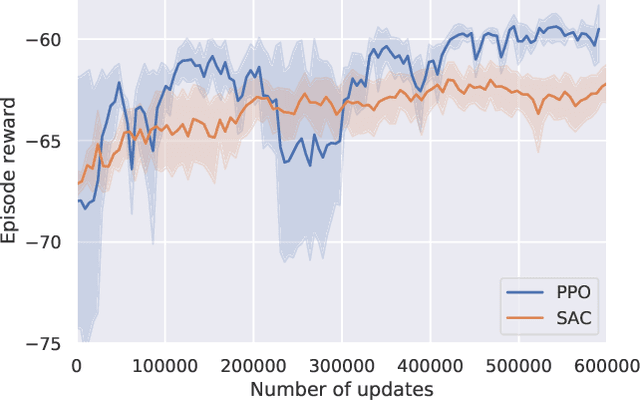
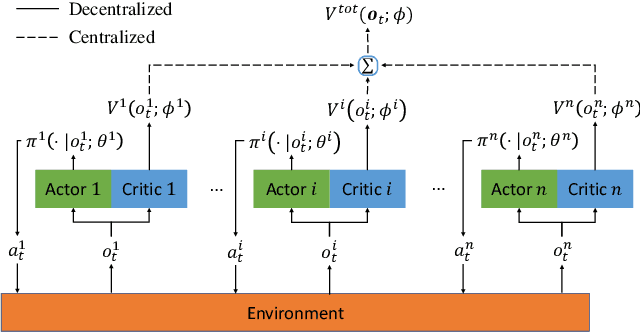
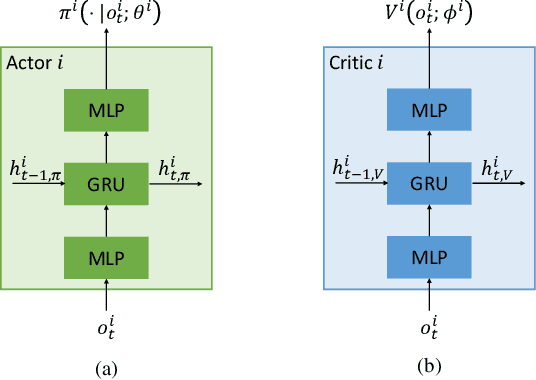
As a scalable data-driven approach, multi-agent reinforcement learning (MARL) has made remarkable advances in solving the cooperative residential load scheduling problems. However, the common centralized training strategy of MARL algorithms raises privacy risks for involved households. In this work, we propose a privacy-preserving multi-agent actor-critic framework where the decentralized actors are trained with distributed critics, such that both the decentralized execution and the distributed training do not require the global state information. The proposed framework can preserve the privacy of the households while simultaneously learn the multi-agent credit assignment mechanism implicitly. The simulation experiments demonstrate that the proposed framework significantly outperforms the existing privacy-preserving actor-critic framework, and can achieve comparable performance to the state-of-the-art actor-critic framework without privacy constraints.
An Improved StarGAN for Emotional Voice Conversion: Enhancing Voice Quality and Data Augmentation
Jul 18, 2021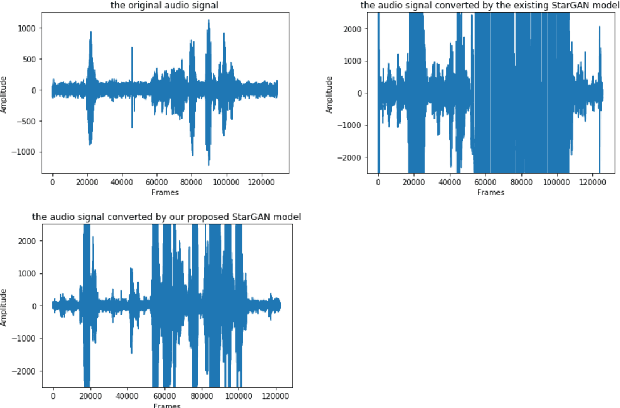



Emotional Voice Conversion (EVC) aims to convert the emotional style of a source speech signal to a target style while preserving its content and speaker identity information. Previous emotional conversion studies do not disentangle emotional information from emotion-independent information that should be preserved, thus transforming it all in a monolithic manner and generating audio of low quality, with linguistic distortions. To address this distortion problem, we propose a novel StarGAN framework along with a two-stage training process that separates emotional features from those independent of emotion by using an autoencoder with two encoders as the generator of the Generative Adversarial Network (GAN). The proposed model achieves favourable results in both the objective evaluation and the subjective evaluation in terms of distortion, which reveals that the proposed model can effectively reduce distortion. Furthermore, in data augmentation experiments for end-to-end speech emotion recognition, the proposed StarGAN model achieves an increase of 2% in Micro-F1 and 5% in Macro-F1 compared to the baseline StarGAN model, which indicates that the proposed model is more valuable for data augmentation.
Significance of Speaker Embeddings and Temporal Context for Depression Detection
Jul 24, 2021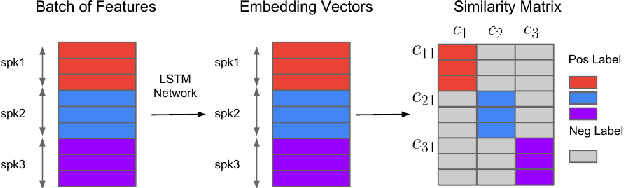
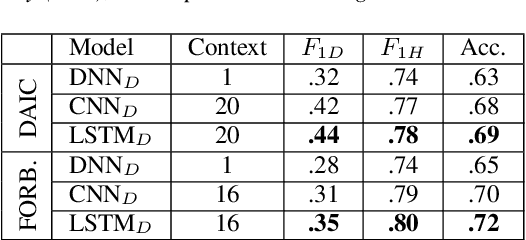
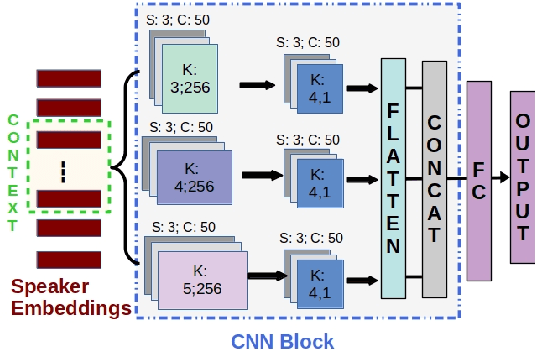
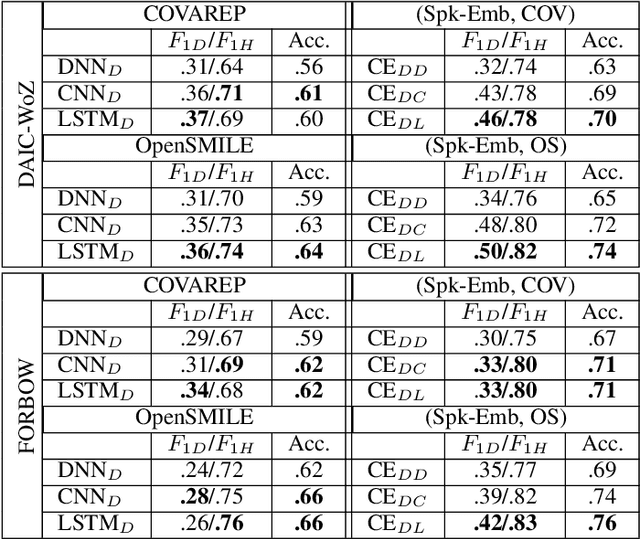
Depression detection from speech has attracted a lot of attention in recent years. However, the significance of speaker-specific information in depression detection has not yet been explored. In this work, we analyze the significance of speaker embeddings for the task of depression detection from speech. Experimental results show that the speaker embeddings provide important cues to achieve state-of-the-art performance in depression detection. We also show that combining conventional OpenSMILE and COVAREP features, which carry complementary information, with speaker embeddings further improves the depression detection performance. The significance of temporal context in the training of deep learning models for depression detection is also analyzed in this paper.
Fully Polarimetric SAR and Single-Polarization SAR Image Fusion Network
Jul 18, 2021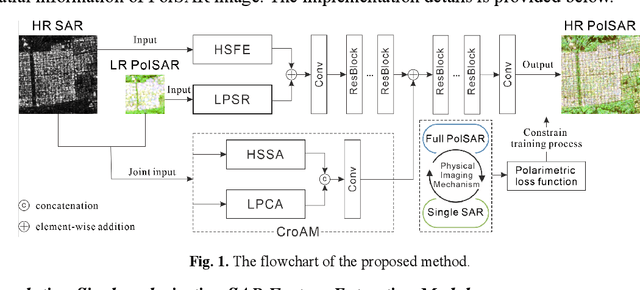
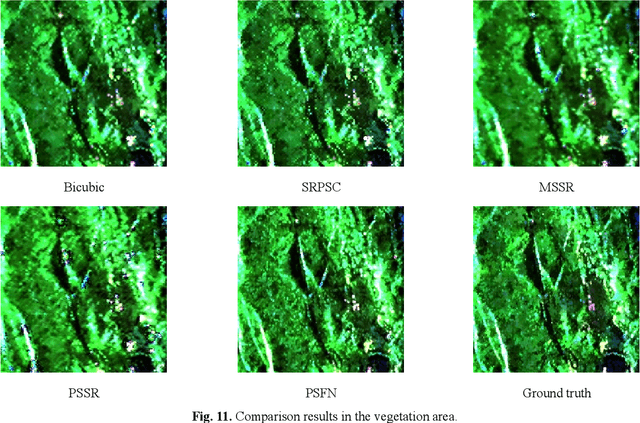

The data fusion technology aims to aggregate the characteristics of different data and obtain products with multiple data advantages. To solves the problem of reduced resolution of PolSAR images due to system limitations, we propose a fully polarimetric synthetic aperture radar (PolSAR) images and single-polarization synthetic aperture radar SAR (SinSAR) images fusion network to generate high-resolution PolSAR (HR-PolSAR) images. To take advantage of the polarimetric information of the low-resolution PolSAR (LR-PolSAR) image and the spatial information of the high-resolution single-polarization SAR (HR-SinSAR) image, we propose a fusion framework for joint LR-PolSAR image and HR-SinSAR image and design a cross-attention mechanism to extract features from the joint input data. Besides, based on the physical imaging mechanism, we designed the PolSAR polarimetric loss function for constrained network training. The experimental results confirm the superiority of fusion network over traditional algorithms. The average PSNR is increased by more than 3.6db, and the average MAE is reduced to less than 0.07. Experiments on polarimetric decomposition and polarimetric signature show that it maintains polarimetric information well.
Improving Camouflaged Object Detection with the Uncertainty of Pseudo-edge Labels
Oct 29, 2021
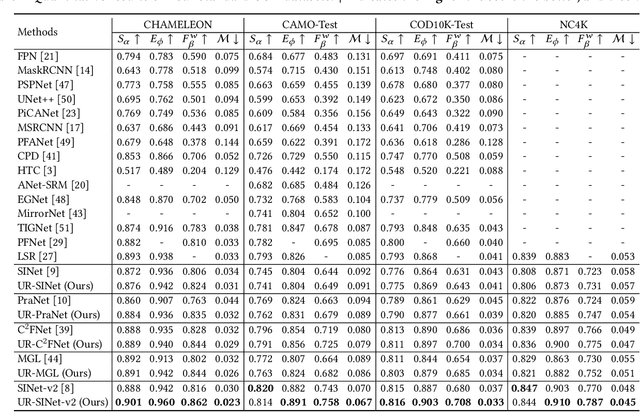
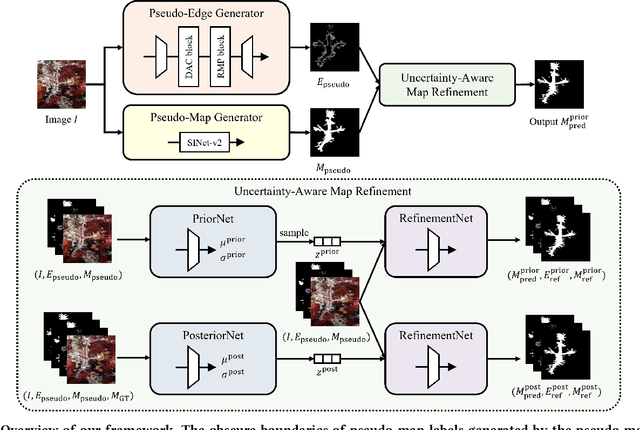

This paper focuses on camouflaged object detection (COD), which is a task to detect objects hidden in the background. Most of the current COD models aim to highlight the target object directly while outputting ambiguous camouflaged boundaries. On the other hand, the performance of the models considering edge information is not yet satisfactory. To this end, we propose a new framework that makes full use of multiple visual cues, i.e., saliency as well as edges, to refine the predicted camouflaged map. This framework consists of three key components, i.e., a pseudo-edge generator, a pseudo-map generator, and an uncertainty-aware refinement module. In particular, the pseudo-edge generator estimates the boundary that outputs the pseudo-edge label, and the conventional COD method serves as the pseudo-map generator that outputs the pseudo-map label. Then, we propose an uncertainty-based module to reduce the uncertainty and noise of such two pseudo labels, which takes both pseudo labels as input and outputs an edge-accurate camouflaged map. Experiments on various COD datasets demonstrate the effectiveness of our method with superior performance to the existing state-of-the-art methods.
Cause-effect inference through spectral independence in linear dynamical systems: theoretical foundations
Oct 29, 2021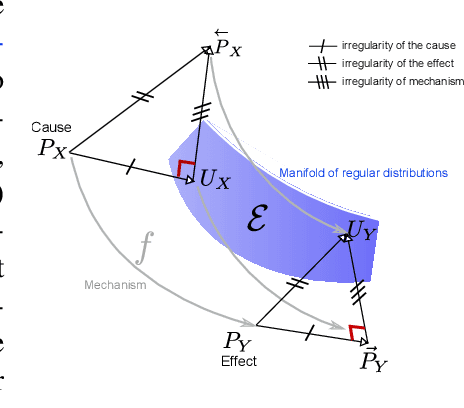
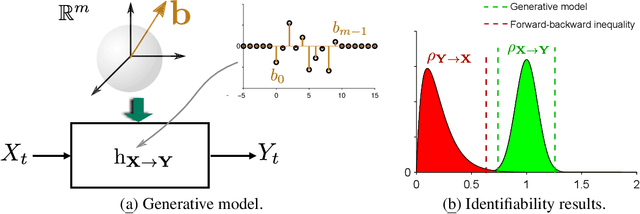
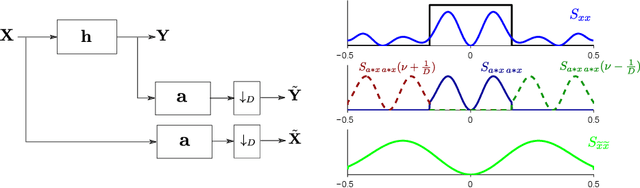
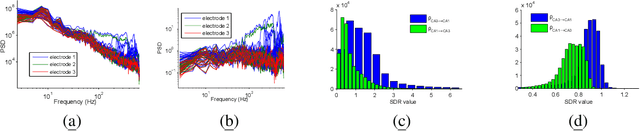
Distinguishing between cause and effect using time series observational data is a major challenge in many scientific fields. A new perspective has been provided based on the principle of Independence of Causal Mechanisms (ICM), leading to the Spectral Independence Criterion (SIC), postulating that the power spectral density (PSD) of the cause time series is uncorrelated with the squared modulus of the frequency response of the filter generating the effect. Since SIC rests on methods and assumptions in stark contrast with most causal discovery methods for time series, it raises questions regarding what theoretical grounds justify its use. In this paper, we provide answers covering several key aspects. After providing an information theoretic interpretation of SIC, we present an identifiability result that sheds light on the context for which this approach is expected to perform well. We further demonstrate the robustness of SIC to downsampling - an obstacle that can spoil Granger-based inference. Finally, an invariance perspective allows to explore the limitations of the spectral independence assumption and how to generalize it. Overall, these results support the postulate of Spectral Independence is a well grounded leading principle for causal inference based on empirical time series.