 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the use of test smells for prediction of flaky tests
Aug 26, 2021

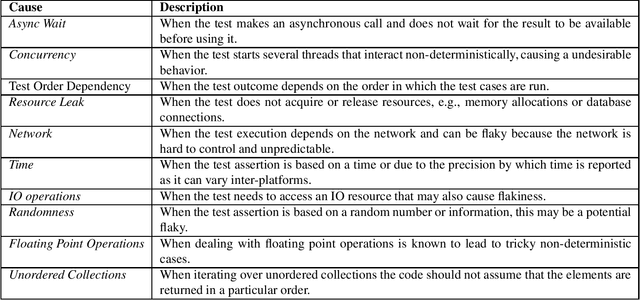
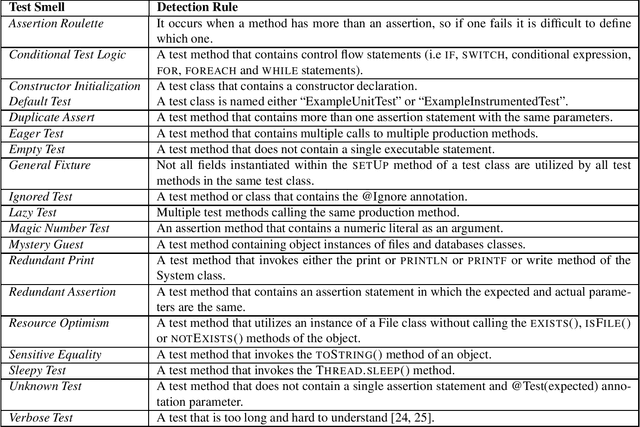
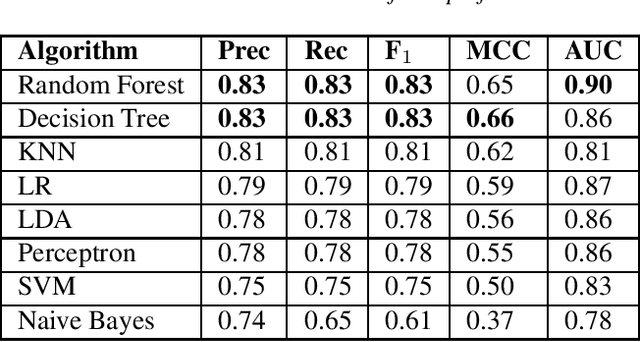
Regression testing is an important phase to deliver software with quality. However, flaky tests hamper the evaluation of test results and can increase costs. This is because a flaky test may pass or fail non-deterministically and to identify properly the flakiness of a test requires rerunning the test suite multiple times. To cope with this challenge, approaches have been proposed based on prediction models and machine learning. Existing approaches based on the use of the test case vocabulary may be context-sensitive and prone to overfitting, presenting low performance when executed in a cross-project scenario. To overcome these limitations, we investigate the use of test smells as predictors of flaky tests. We conducted an empirical study to understand if test smells have good performance as a classifier to predict the flakiness in the cross-project context, and analyzed the information gain of each test smell. We also compared the test smell-based approach with the vocabulary-based one. As a result, we obtained a classifier that had a reasonable performance (Random Forest, 0.83%) to predict the flakiness in the testing phase. This classifier presented better performance than vocabulary-based model for cross-project prediction. The Assertion Roulette and Sleepy Test test smell types are the ones associated with the best information gain values.
Parallelised Diffeomorphic Sampling-based Motion Planning
Aug 26, 2021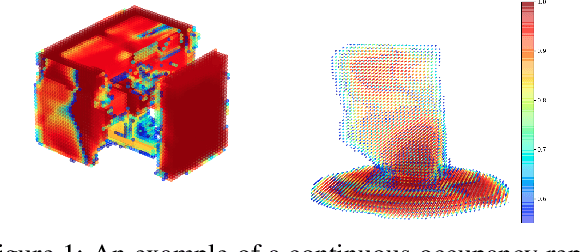
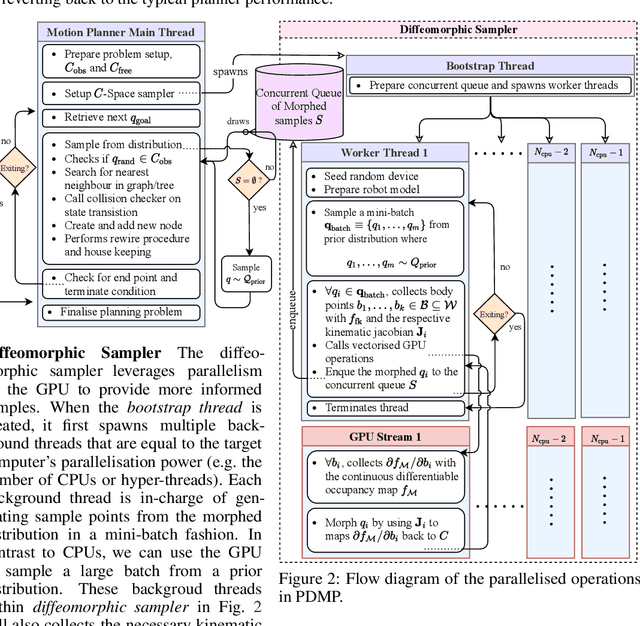
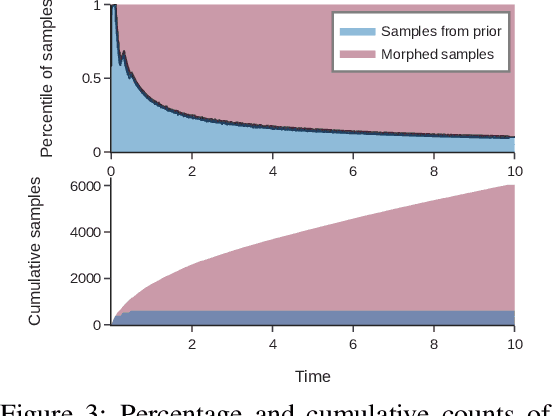
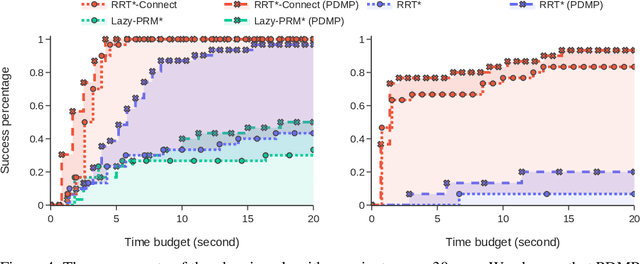
We propose Parallelised Diffeomorphic Sampling-based Motion Planning (PDMP). PDMP is a novel parallelised framework that uses bijective and differentiable mappings, or diffeomorphisms, to transform sampling distributions of sampling-based motion planners, in a manner akin to normalising flows. Unlike normalising flow models which use invertible neural network structures to represent these diffeomorphisms, we develop them from gradient information of desired costs, and encode desirable behaviour, such as obstacle avoidance. These transformed sampling distributions can then be used for sampling-based motion planning. A particular example is when we wish to imbue the sampling distribution with knowledge of the environment geometry, such that drawn samples are less prone to be in collisions. To this end, we propose to learn a continuous occupancy representation from environment occupancy data, such that gradients of the representation defines a valid diffeomorphism and is amenable to fast parallel evaluation. We use this to "morph" the sampling distribution to draw far fewer collision-prone samples. PDMP is able to leverage gradient information of costs, to inject specifications, in a manner similar to optimisation-based motion planning methods, but relies on drawing from a sampling distribution, retaining the tendency to find more global solutions, thereby bridging the gap between trajectory optimisation and sampling-based planning methods.
DMRST: A Joint Framework for Document-Level Multilingual RST Discourse Segmentation and Parsing
Oct 09, 2021
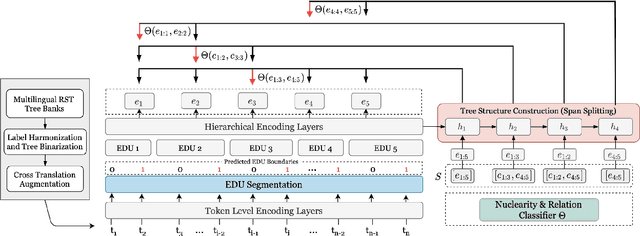
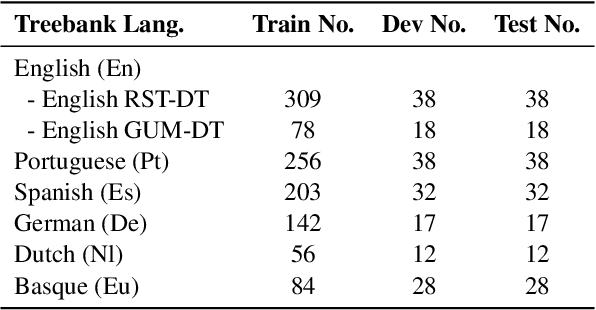
Text discourse parsing weighs importantly in understanding information flow and argumentative structure in natural language, making it beneficial for downstream tasks. While previous work significantly improves the performance of RST discourse parsing, they are not readily applicable to practical use cases: (1) EDU segmentation is not integrated into most existing tree parsing frameworks, thus it is not straightforward to apply such models on newly-coming data. (2) Most parsers cannot be used in multilingual scenarios, because they are developed only in English. (3) Parsers trained from single-domain treebanks do not generalize well on out-of-domain inputs. In this work, we propose a document-level multilingual RST discourse parsing framework, which conducts EDU segmentation and discourse tree parsing jointly. Moreover, we propose a cross-translation augmentation strategy to enable the framework to support multilingual parsing and improve its domain generality. Experimental results show that our model achieves state-of-the-art performance on document-level multilingual RST parsing in all sub-tasks.
Towards Information-Seeking Agents
Dec 08, 2016



We develop a general problem setting for training and testing the ability of agents to gather information efficiently. Specifically, we present a collection of tasks in which success requires searching through a partially-observed environment, for fragments of information which can be pieced together to accomplish various goals. We combine deep architectures with techniques from reinforcement learning to develop agents that solve our tasks. We shape the behavior of these agents by combining extrinsic and intrinsic rewards. We empirically demonstrate that these agents learn to search actively and intelligently for new information to reduce their uncertainty, and to exploit information they have already acquired.
Deep feature selection-and-fusion for RGB-D semantic segmentation
May 10, 2021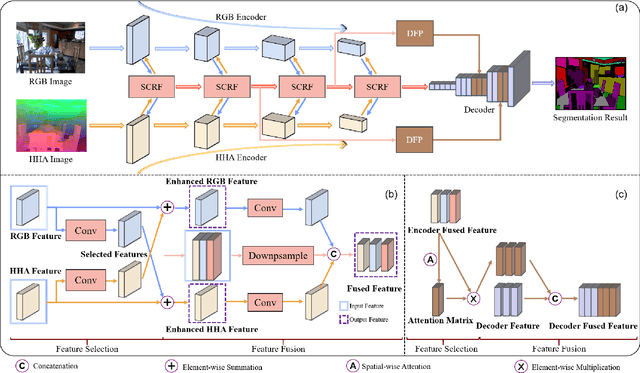
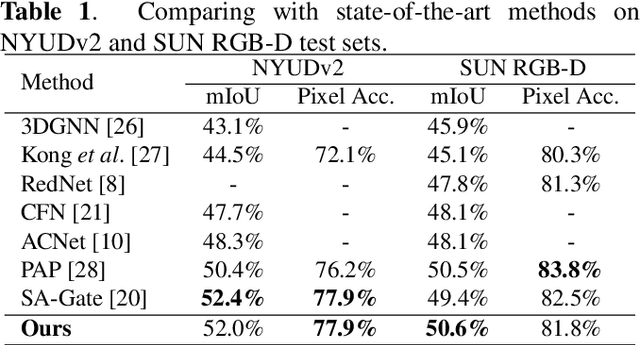
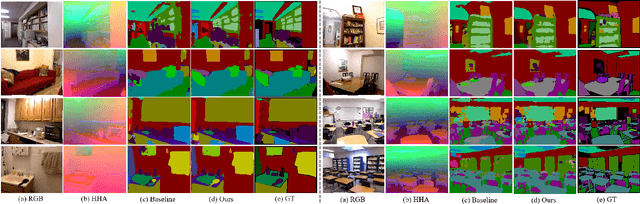
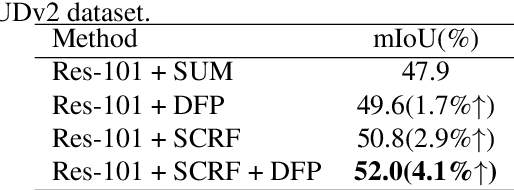
Scene depth information can help visual information for more accurate semantic segmentation. However, how to effectively integrate multi-modality information into representative features is still an open problem. Most of the existing work uses DCNNs to implicitly fuse multi-modality information. But as the network deepens, some critical distinguishing features may be lost, which reduces the segmentation performance. This work proposes a unified and efficient feature selectionand-fusion network (FSFNet), which contains a symmetric cross-modality residual fusion module used for explicit fusion of multi-modality information. Besides, the network includes a detailed feature propagation module, which is used to maintain low-level detailed information during the forward process of the network. Compared with the state-of-the-art methods, experimental evaluations demonstrate that the proposed model achieves competitive performance on two public datasets.
Three approaches to supervised learning for compositional data with pairwise logratios
Nov 17, 2021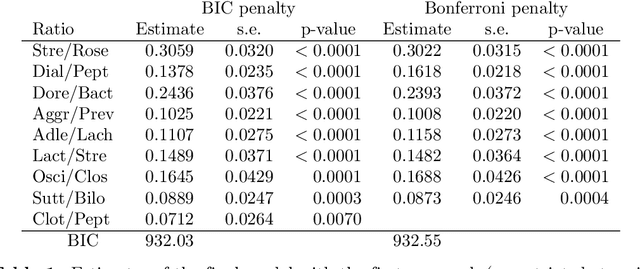
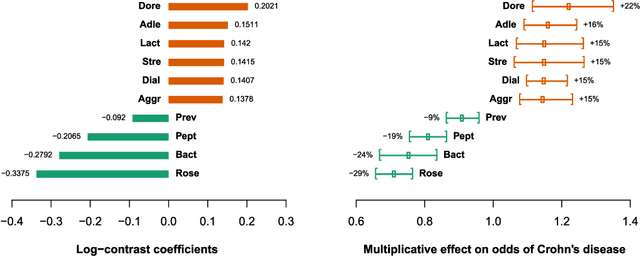
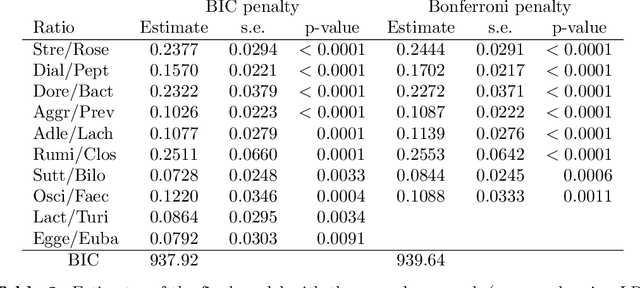
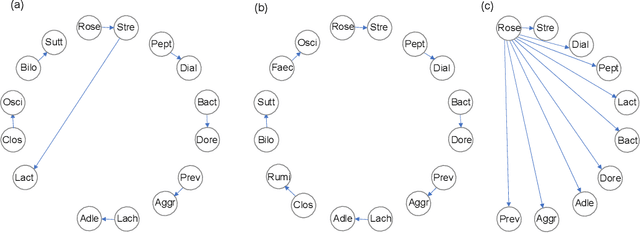
The common approach to compositional data analysis is to transform the data by means of logratios. Logratios between pairs of compositional parts (pairwise logratios) are the easiest to interpret in many research problems. When the number of parts is large, some form of logratio selection is a must, for instance by means of an unsupervised learning method based on a stepwise selection of the pairwise logratios that explain the largest percentage of the logratio variance in the compositional dataset. In this article we present three alternative stepwise supervised learning methods to select the pairwise logratios that best explain a dependent variable in a generalized linear model, each geared for a specific problem. The first method features unrestricted search, where any pairwise logratio can be selected. This method has a complex interpretation if some pairs of parts in the logratios overlap, but it leads to the most accurate predictions. The second method restricts parts to occur only once, which makes the corresponding logratios intuitively interpretable. The third method uses additive logratios, so that $K-1$ selected logratios involve exactly $K$ parts. This method in fact searches for the subcomposition with the highest explanatory power. Once the subcomposition is identified, the researcher's favourite logratio representation may be used in subsequent analyses, not only pairwise logratios. Our methodology allows logratios or non-compositional covariates to be forced into the models based on theoretical knowledge, and various stopping criteria are available based on information measures or statistical significance with the Bonferroni correction. We present an illustration of the three approaches on a dataset from a study predicting Crohn's disease. The first method excels in terms of predictive power, and the other two in interpretability.
Investigating Post-pretraining Representation Alignment for Cross-Lingual Question Answering
Sep 24, 2021
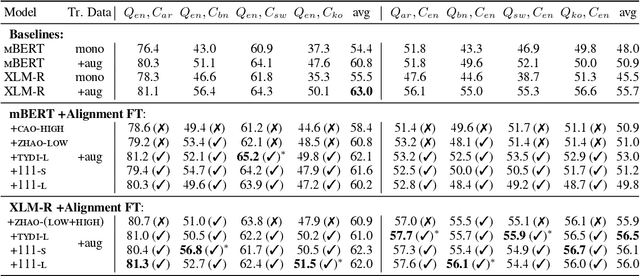
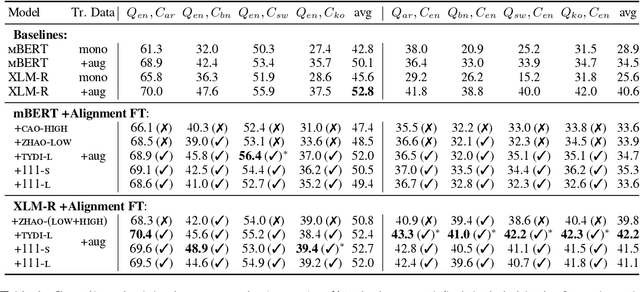
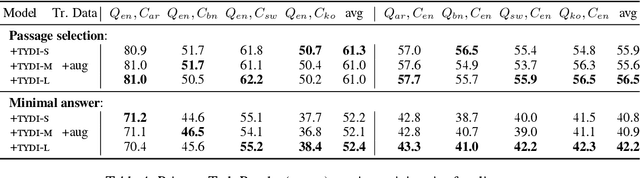
Human knowledge is collectively encoded in the roughly 6500 languages spoken around the world, but it is not distributed equally across languages. Hence, for information-seeking question answering (QA) systems to adequately serve speakers of all languages, they need to operate cross-lingually. In this work we investigate the capabilities of multilingually pre-trained language models on cross-lingual QA. We find that explicitly aligning the representations across languages with a post-hoc fine-tuning step generally leads to improved performance. We additionally investigate the effect of data size as well as the language choice in this fine-tuning step, also releasing a dataset for evaluating cross-lingual QA systems. Code and dataset are publicly available here: https://github.com/ffaisal93/aligned_qa
Automatic Detection of COVID-19 and Pneumonia from Chest X-Ray using Deep Learning
Oct 15, 2021
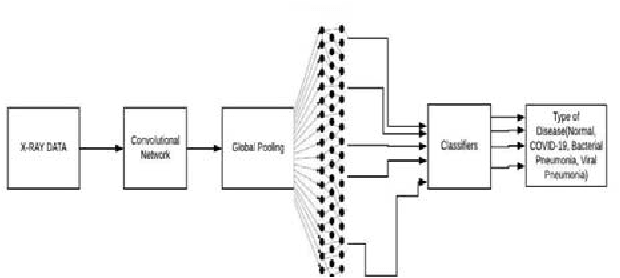

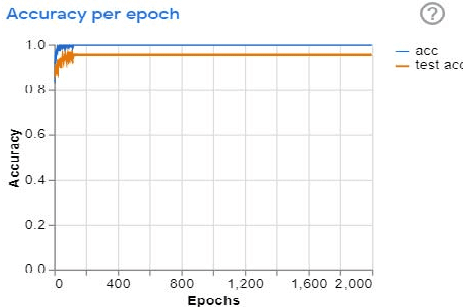
In this study, a dataset of X-ray images from patients with common viral pneumonia, bacterial pneumonia, confirmed Covid-19 disease was utilized for the automatic detection of the Coronavirus disease. The point of the investigation is to assess the exhibition of cutting edge convolutional neural system structures proposed over the ongoing years for clinical picture order. In particular, the system called Transfer Learning was received. With transfer learning, the location of different variations from the norm in little clinical picture datasets is a reachable objective, regularly yielding amazing outcomes. The datasets used in this trial. Firstly, a collection of 24000 X-ray images includes 6000 images for confirmed Covid-19 disease,6000 confirmed common bacterial pneumonia and 6000 images of normal conditions. The information was gathered and expanded from the accessible X-Ray pictures on open clinical stores. The outcomes recommend that Deep Learning with X-Ray imaging may separate noteworthy biological markers identified with the Covid-19 sickness, while the best precision, affectability, and particularity acquired is 97.83%, 96.81%, and 98.56% individually.
Revisiting Negation in Neural Machine Translation
Jul 26, 2021
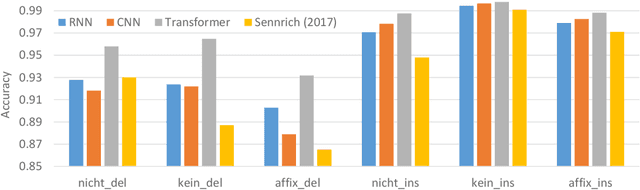

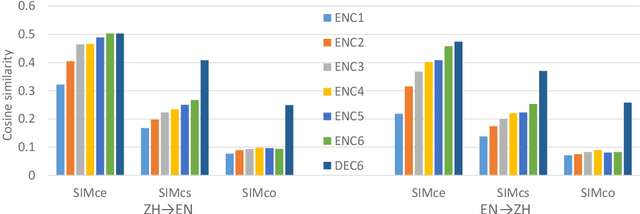
In this paper, we evaluate the translation of negation both automatically and manually, in English--German (EN--DE) and English--Chinese (EN--ZH). We show that the ability of neural machine translation (NMT) models to translate negation has improved with deeper and more advanced networks, although the performance varies between language pairs and translation directions. The accuracy of manual evaluation in EN-DE, DE-EN, EN-ZH, and ZH-EN is 95.7%, 94.8%, 93.4%, and 91.7%, respectively. In addition, we show that under-translation is the most significant error type in NMT, which contrasts with the more diverse error profile previously observed for statistical machine translation. To better understand the root of the under-translation of negation, we study the model's information flow and training data. While our information flow analysis does not reveal any deficiencies that could be used to detect or fix the under-translation of negation, we find that negation is often rephrased during training, which could make it more difficult for the model to learn a reliable link between source and target negation. We finally conduct intrinsic analysis and extrinsic probing tasks on negation, showing that NMT models can distinguish negation and non-negation tokens very well and encode a lot of information about negation in hidden states but nevertheless leave room for improvement.
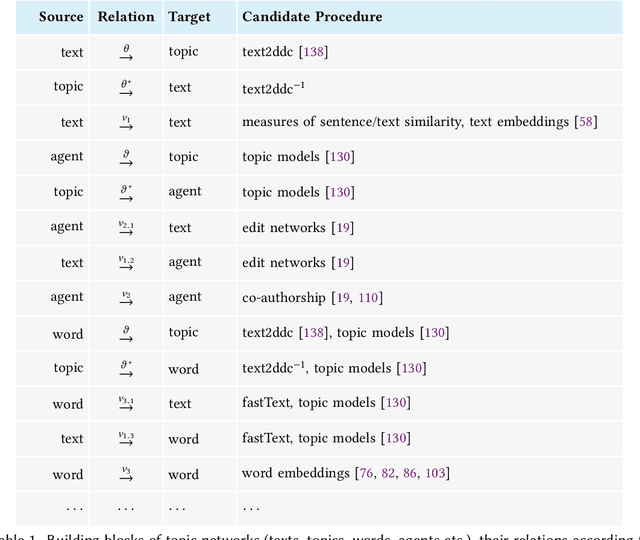
From Topic Networks to Distributed Cognitive Maps: Zipfian Topic Universes in the Area of Volunteered Geographic Information
Feb 04, 2020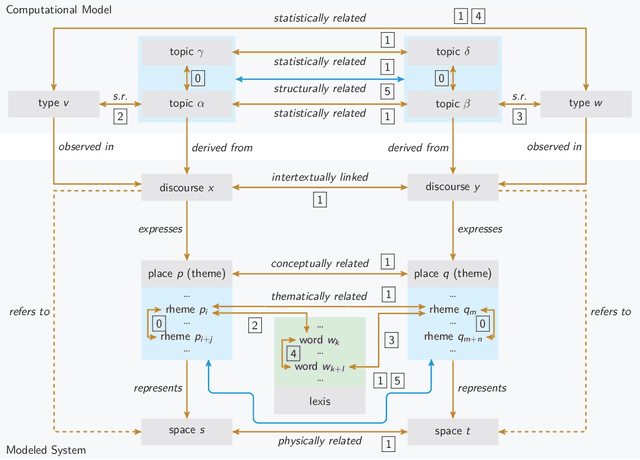
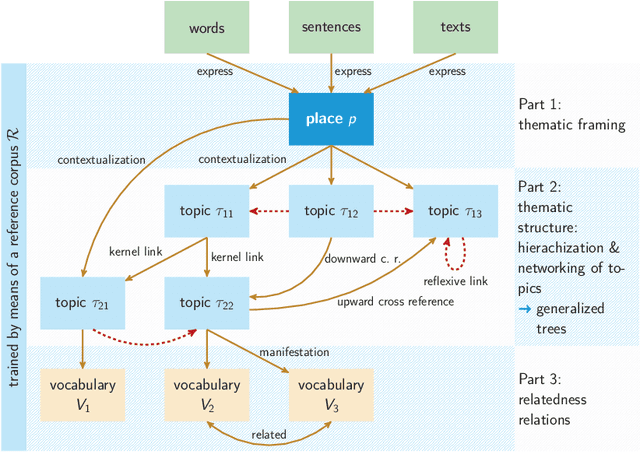
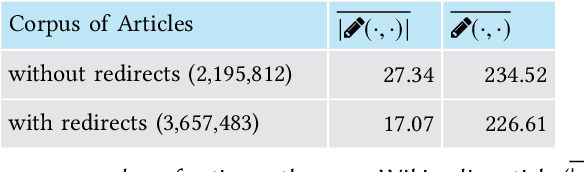
Are nearby places (e.g. cities) described by related words? In this article we transfer this research question in the field of lexical encoding of geographic information onto the level of intertextuality. To this end, we explore Volunteered Geographic Information (VGI) to model texts addressing places at the level of cities or regions with the help of so-called topic networks. This is done to examine how language encodes and networks geographic information on the aboutness level of texts. Our hypothesis is that the networked thematizations of places are similar - regardless of their distances and the underlying communities of authors. To investigate this we introduce Multiplex Topic Networks (MTN), which we automatically derive from Linguistic Multilayer Networks (LMN) as a novel model, especially of thematic networking in text corpora. Our study shows a Zipfian organization of the thematic universe in which geographical places (especially cities) are located in online communication. We interpret this finding in the context of cognitive maps, a notion which we extend by so-called thematic maps. According to our interpretation of this finding, the organization of thematic maps as part of cognitive maps results from a tendency of authors to generate shareable content that ensures the continued existence of the underlying media. We test our hypothesis by example of special wikis and extracts of Wikipedia. In this way we come to the conclusion: Places, whether close to each other or not, are located in neighboring places that span similar subnetworks in the topic universe.