 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Privacy-Preserving Affect Recognition: A Two-Level Deep Learning Architecture
Nov 14, 2021
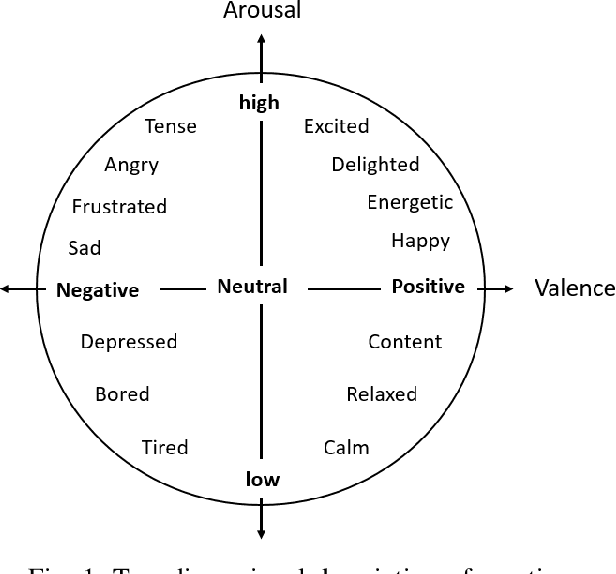
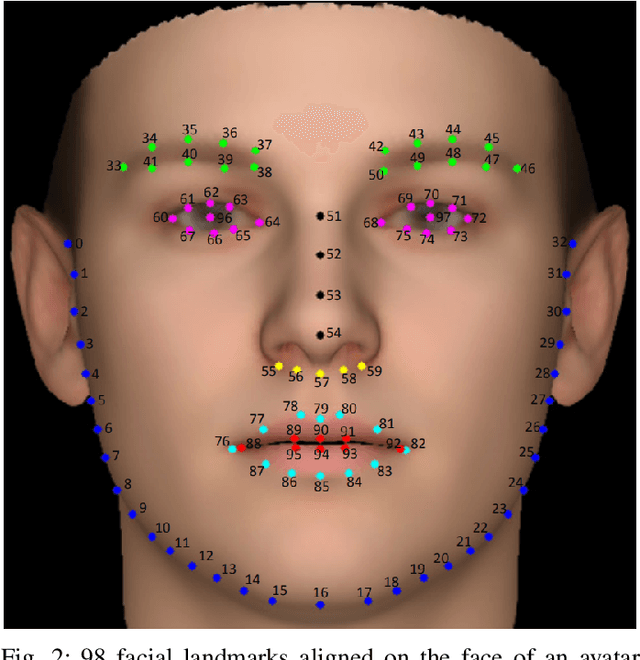
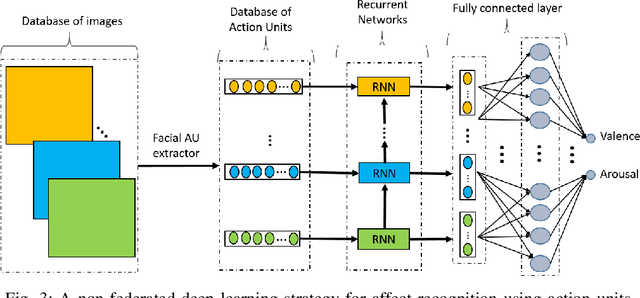
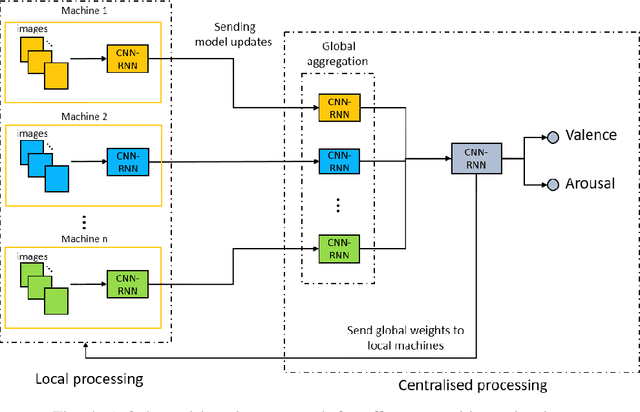
Automatically understanding and recognising human affective states using images and computer vision can improve human-computer and human-robot interaction. However, privacy has become an issue of great concern, as the identities of people used to train affective models can be exposed in the process. For instance, malicious individuals could exploit images from users and assume their identities. In addition, affect recognition using images can lead to discriminatory and algorithmic bias, as certain information such as race, gender, and age could be assumed based on facial features. Possible solutions to protect the privacy of users and avoid misuse of their identities are to: (1) extract anonymised facial features, namely action units (AU) from a database of images, discard the images and use AUs for processing and training, and (2) federated learning (FL) i.e. process raw images in users' local machines (local processing) and send the locally trained models to the main processing machine for aggregation (central processing). In this paper, we propose a two-level deep learning architecture for affect recognition that uses AUs in level 1 and FL in level 2 to protect users' identities. The architecture consists of recurrent neural networks to capture the temporal relationships amongst the features and predict valence and arousal affective states. In our experiments, we evaluate the performance of our privacy-preserving architecture using different variations of recurrent neural networks on RECOLA, a comprehensive multimodal affective database. Our results show state-of-the-art performance of $0.426$ for valence and $0.401$ for arousal using the Concordance Correlation Coefficient evaluation metric, demonstrating the feasibility of developing models for affect recognition that are both accurate and ensure privacy.
Pattern-based Acquisition of Scientific Entities from Scholarly Article Titles
Sep 01, 2021
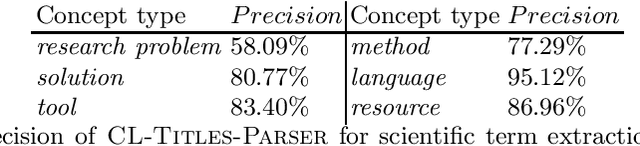

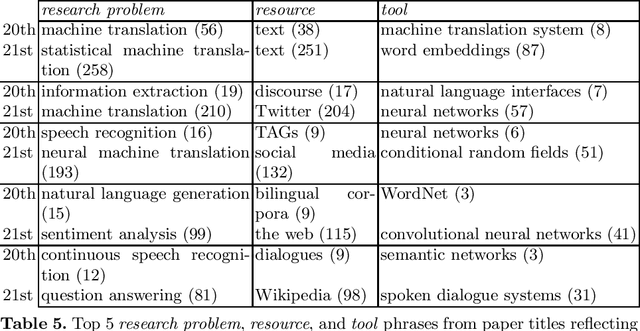
We describe a rule-based approach for the automatic acquisition of scientific entities from scholarly article titles. Two observations motivated the approach: (i) noting the concentration of an article's contribution information in its title; and (ii) capturing information pattern regularities via a system of rules that alleviate the human annotation task in creating gold standards that annotate single instances at a time. We identify a set of lexico-syntactic patterns that are easily recognizable, that occur frequently, and that generally indicates the scientific entity type of interest about the scholarly contribution. A subset of the acquisition algorithm is implemented for article titles in the Computational Linguistics (CL) scholarly domain. The tool called ORKG-Title-Parser, in its first release, identifies the following six concept types of scientific terminology from the CL paper titles, viz. research problem, solution, resource, language, tool, and method. It has been empirically evaluated on a collection of 50,237 titles that cover nearly all articles in the ACL Anthology. It has extracted 19,799 research problems; 18,111 solutions; 20,033 resources; 1,059 languages; 6,878 tools; and 21,687 methods at an average extraction precision of 75%. The code and related data resources are publicly available at https://gitlab.com/TIBHannover/orkg/orkg-title-parser. Finally, in the article, we discuss extensions and applications to areas such as scholarly knowledge graph (SKG) creation.
Revisiting Negation in Neural Machine Translation
Jul 26, 2021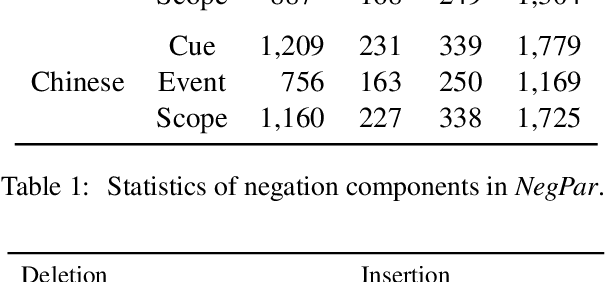
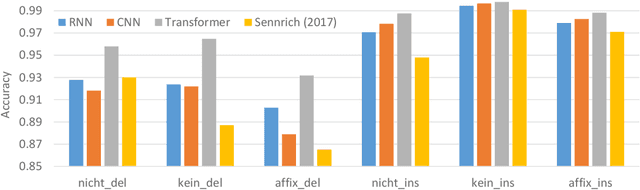

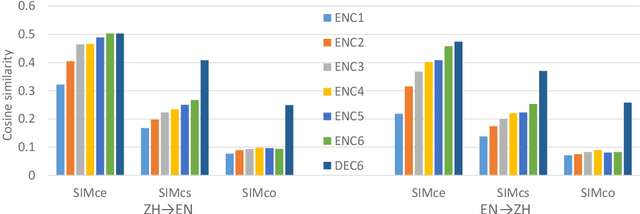
In this paper, we evaluate the translation of negation both automatically and manually, in English--German (EN--DE) and English--Chinese (EN--ZH). We show that the ability of neural machine translation (NMT) models to translate negation has improved with deeper and more advanced networks, although the performance varies between language pairs and translation directions. The accuracy of manual evaluation in EN-DE, DE-EN, EN-ZH, and ZH-EN is 95.7%, 94.8%, 93.4%, and 91.7%, respectively. In addition, we show that under-translation is the most significant error type in NMT, which contrasts with the more diverse error profile previously observed for statistical machine translation. To better understand the root of the under-translation of negation, we study the model's information flow and training data. While our information flow analysis does not reveal any deficiencies that could be used to detect or fix the under-translation of negation, we find that negation is often rephrased during training, which could make it more difficult for the model to learn a reliable link between source and target negation. We finally conduct intrinsic analysis and extrinsic probing tasks on negation, showing that NMT models can distinguish negation and non-negation tokens very well and encode a lot of information about negation in hidden states but nevertheless leave room for improvement.
Fast rates for prediction with limited expert advice
Oct 27, 2021We investigate the problem of minimizing the excess generalization error with respect to the best expert prediction in a finite family in the stochastic setting, under limited access to information. We assume that the learner only has access to a limited number of expert advices per training round, as well as for prediction. Assuming that the loss function is Lipschitz and strongly convex, we show that if we are allowed to see the advice of only one expert per round for T rounds in the training phase, or to use the advice of only one expert for prediction in the test phase, the worst-case excess risk is $\Omega$(1/ $\sqrt$ T) with probability lower bounded by a constant. However, if we are allowed to see at least two actively chosen expert advices per training round and use at least two experts for prediction, the fast rate O(1/T) can be achieved. We design novel algorithms achieving this rate in this setting, and in the setting where the learner has a budget constraint on the total number of observed expert advices, and give precise instance-dependent bounds on the number of training rounds and queries needed to achieve a given generalization error precision.
PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
Oct 16, 2021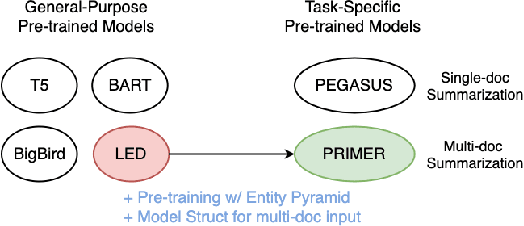
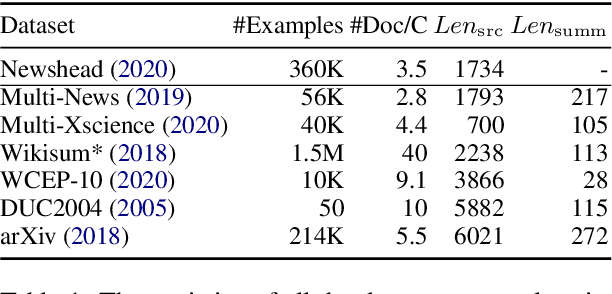
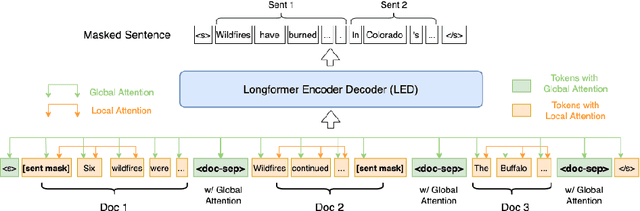
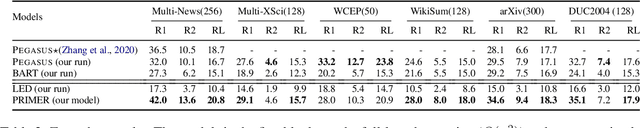
Recently proposed pre-trained generation models achieve strong performance on single-document summarization benchmarks. However, most of them are pre-trained with general-purpose objectives and mainly aim to process single document inputs. In this paper, we propose PRIMER, a pre-trained model for multi-document representation with focus on summarization that reduces the need for dataset-specific architectures and large amounts of fine-tuning labeled data. Specifically, we adopt the Longformer architecture with proper input transformation and global attention to fit for multi-document inputs, and we use Gap Sentence Generation objective with a new strategy to select salient sentences for the whole cluster, called Entity Pyramid, to teach the model to select and aggregate information across a cluster of related documents. With extensive experiments on 6 multi-document summarization datasets from 3 different domains on the zero-shot, few-shot, and full-supervised settings, our model, PRIMER, outperforms current state-of-the-art models on most of these settings with large margins. Code and pre-trained models are released at https://github.com/allenai/PRIMER
On the use of test smells for prediction of flaky tests
Aug 26, 2021
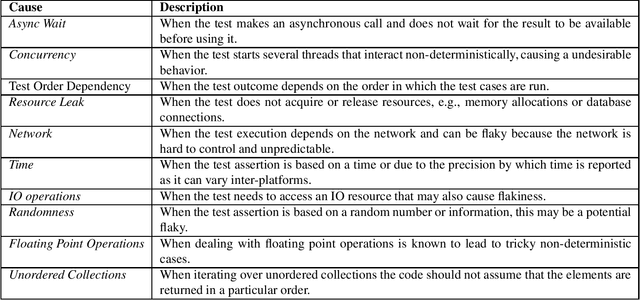
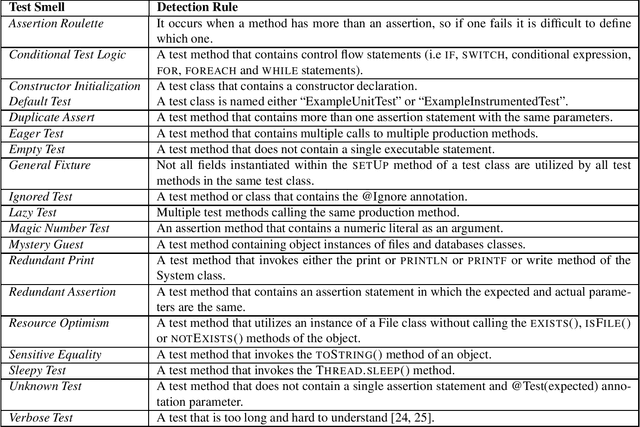
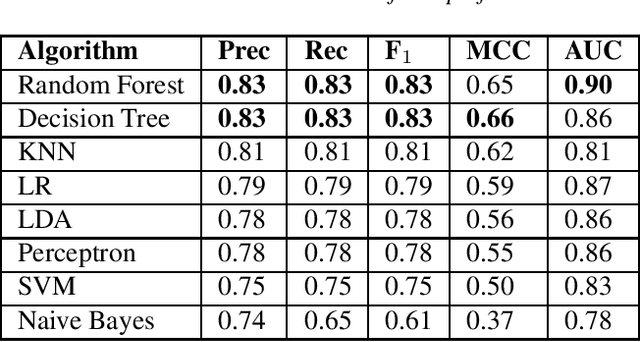
Regression testing is an important phase to deliver software with quality. However, flaky tests hamper the evaluation of test results and can increase costs. This is because a flaky test may pass or fail non-deterministically and to identify properly the flakiness of a test requires rerunning the test suite multiple times. To cope with this challenge, approaches have been proposed based on prediction models and machine learning. Existing approaches based on the use of the test case vocabulary may be context-sensitive and prone to overfitting, presenting low performance when executed in a cross-project scenario. To overcome these limitations, we investigate the use of test smells as predictors of flaky tests. We conducted an empirical study to understand if test smells have good performance as a classifier to predict the flakiness in the cross-project context, and analyzed the information gain of each test smell. We also compared the test smell-based approach with the vocabulary-based one. As a result, we obtained a classifier that had a reasonable performance (Random Forest, 0.83%) to predict the flakiness in the testing phase. This classifier presented better performance than vocabulary-based model for cross-project prediction. The Assertion Roulette and Sleepy Test test smell types are the ones associated with the best information gain values.
Parallelised Diffeomorphic Sampling-based Motion Planning
Aug 26, 2021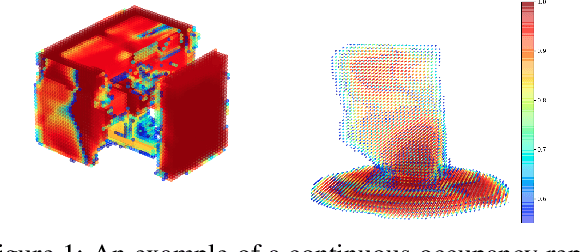
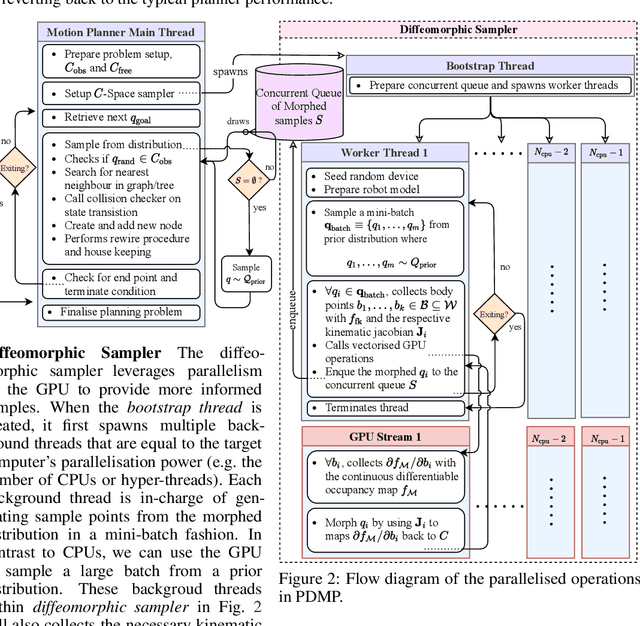
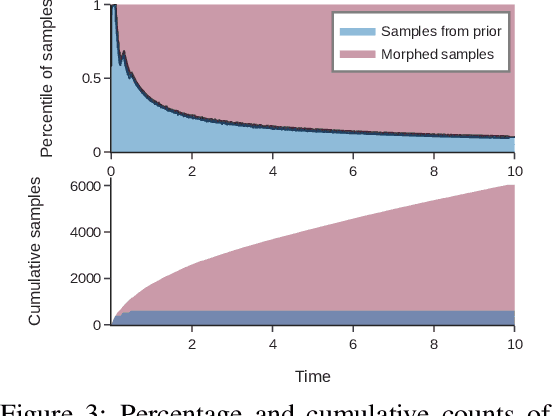
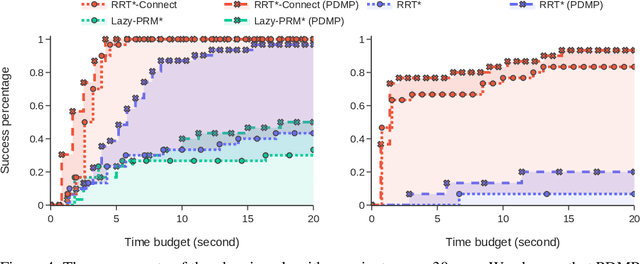
We propose Parallelised Diffeomorphic Sampling-based Motion Planning (PDMP). PDMP is a novel parallelised framework that uses bijective and differentiable mappings, or diffeomorphisms, to transform sampling distributions of sampling-based motion planners, in a manner akin to normalising flows. Unlike normalising flow models which use invertible neural network structures to represent these diffeomorphisms, we develop them from gradient information of desired costs, and encode desirable behaviour, such as obstacle avoidance. These transformed sampling distributions can then be used for sampling-based motion planning. A particular example is when we wish to imbue the sampling distribution with knowledge of the environment geometry, such that drawn samples are less prone to be in collisions. To this end, we propose to learn a continuous occupancy representation from environment occupancy data, such that gradients of the representation defines a valid diffeomorphism and is amenable to fast parallel evaluation. We use this to "morph" the sampling distribution to draw far fewer collision-prone samples. PDMP is able to leverage gradient information of costs, to inject specifications, in a manner similar to optimisation-based motion planning methods, but relies on drawing from a sampling distribution, retaining the tendency to find more global solutions, thereby bridging the gap between trajectory optimisation and sampling-based planning methods.
Cross-modal Variational Auto-encoder for Content-based Micro-video Background Music Recommendation
Jul 15, 2021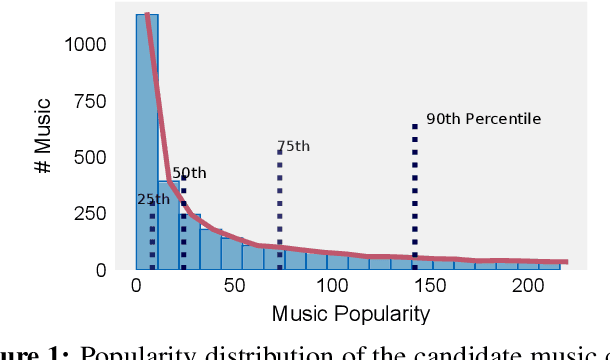
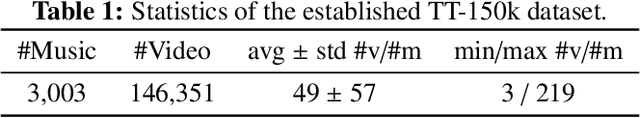

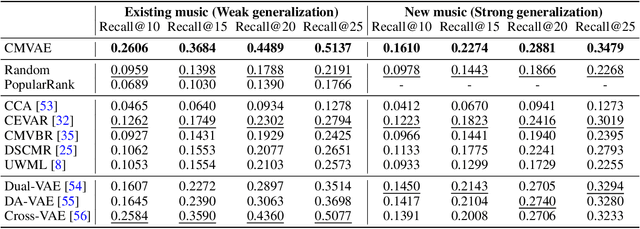
In this paper, we propose a cross-modal variational auto-encoder (CMVAE) for content-based micro-video background music recommendation. CMVAE is a hierarchical Bayesian generative model that matches relevant background music to a micro-video by projecting these two multimodal inputs into a shared low-dimensional latent space, where the alignment of two corresponding embeddings of a matched video-music pair is achieved by cross-generation. Moreover, the multimodal information is fused by the product-of-experts (PoE) principle, where the semantic information in visual and textual modalities of the micro-video are weighted according to their variance estimations such that the modality with a lower noise level is given more weights. Therefore, the micro-video latent variables contain less irrelevant information that results in a more robust model generalization. Furthermore, we establish a large-scale content-based micro-video background music recommendation dataset, TT-150k, composed of approximately 3,000 different background music clips associated to 150,000 micro-videos from different users. Extensive experiments on the established TT-150k dataset demonstrate the effectiveness of the proposed method. A qualitative assessment of CMVAE by visualizing some recommendation results is also included.
ProTo: Program-Guided Transformer for Program-Guided Tasks
Oct 02, 2021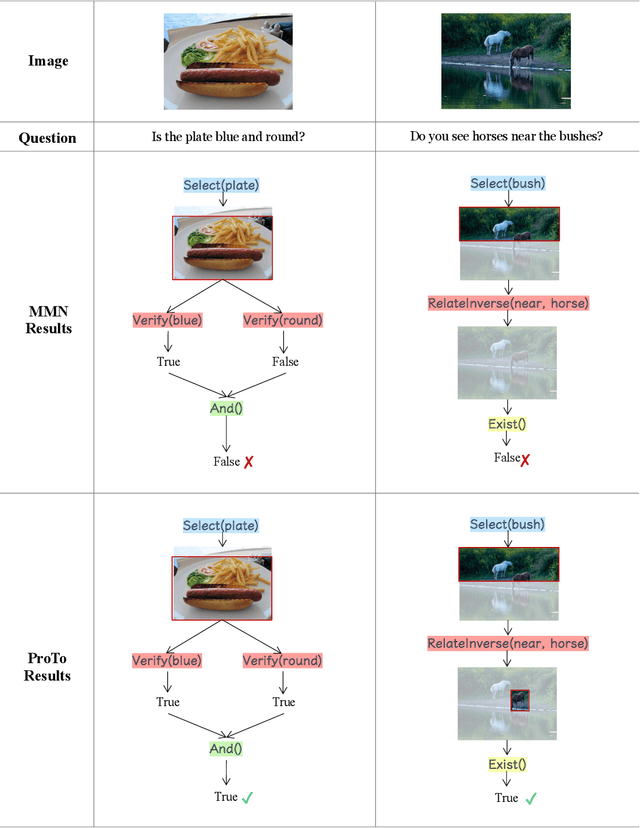
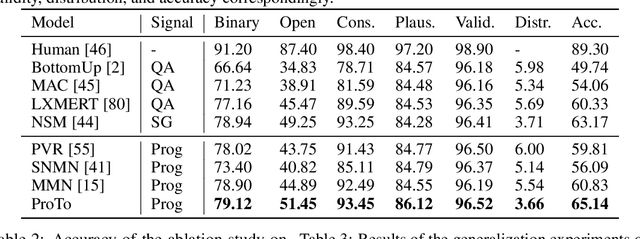
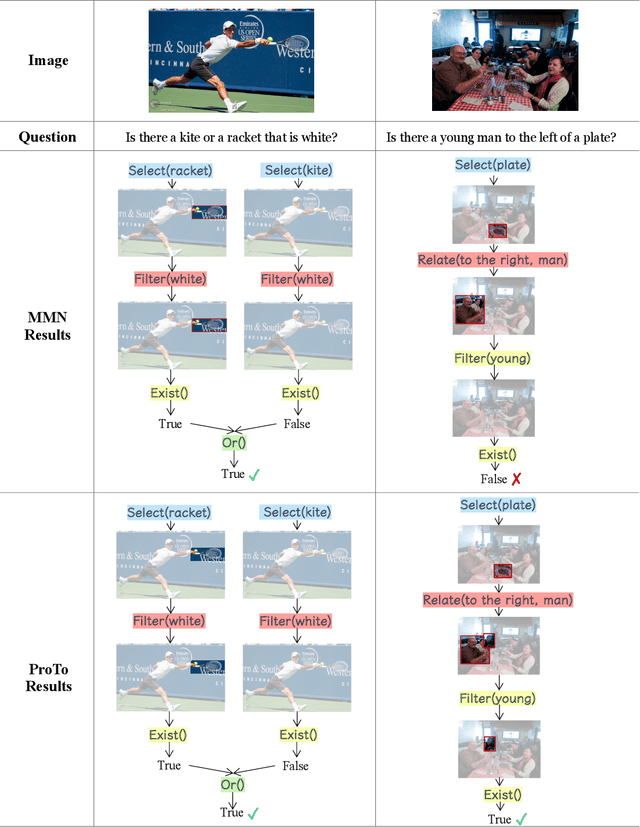
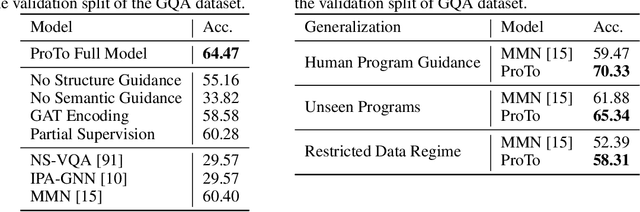
Programs, consisting of semantic and structural information, play an important role in the communication between humans and agents. Towards learning general program executors to unify perception, reasoning, and decision making, we formulate program-guided tasks which require learning to execute a given program on the observed task specification. Furthermore, we propose the Program-guided Transformer (ProTo), which integrates both semantic and structural guidance of a program by leveraging cross-attention and masked self-attention to pass messages between the specification and routines in the program. ProTo executes a program in a learned latent space and enjoys stronger representation ability than previous neural-symbolic approaches. We demonstrate that ProTo significantly outperforms the previous state-of-the-art methods on GQA visual reasoning and 2D Minecraft policy learning datasets. Additionally, ProTo demonstrates better generalization to unseen, complex, and human-written programs.
Shapley variable importance clouds for interpretable machine learning
Oct 06, 2021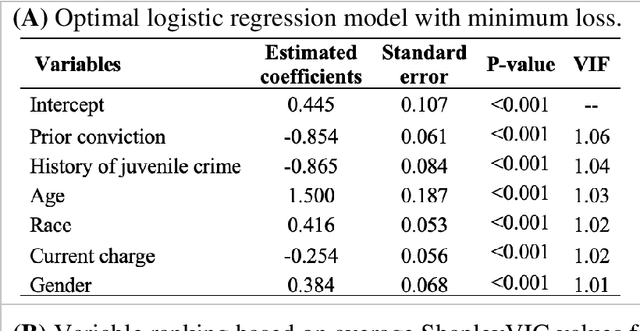
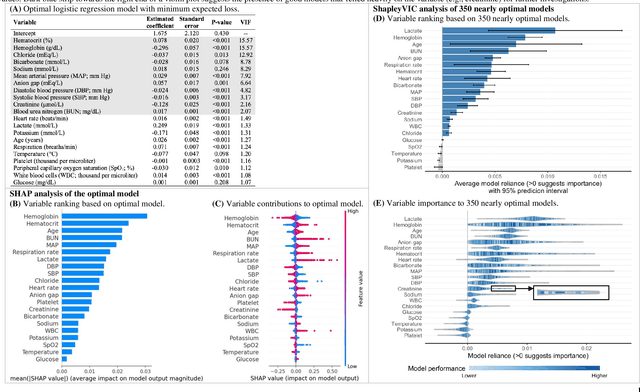
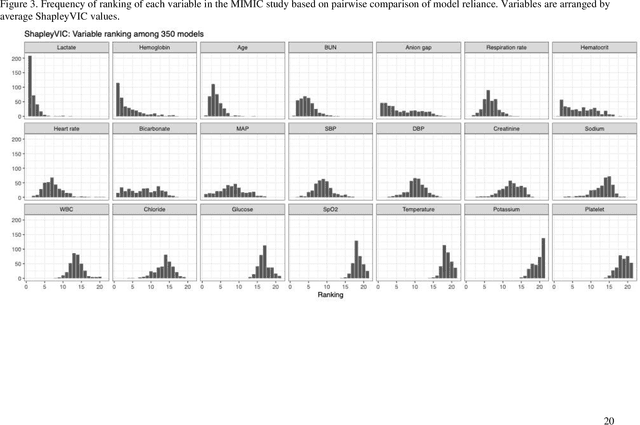
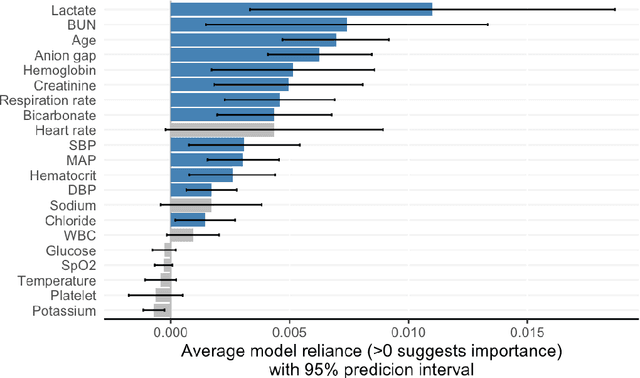
Interpretable machine learning has been focusing on explaining final models that optimize performance. The current state-of-the-art is the Shapley additive explanations (SHAP) that locally explains variable impact on individual predictions, and it is recently extended for a global assessment across the dataset. Recently, Dong and Rudin proposed to extend the investigation to models from the same class as the final model that are "good enough", and identified a previous overclaim of variable importance based on a single model. However, this method does not directly integrate with existing Shapley-based interpretations. We close this gap by proposing a Shapley variable importance cloud that pools information across good models to avoid biased assessments in SHAP analyses of final models, and communicate the findings via novel visualizations. We demonstrate the additional insights gain compared to conventional explanations and Dong and Rudin's method using criminal justice and electronic medical records data.