 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BAMLD: Bayesian Active Meta-Learning by Disagreement
Oct 19, 2021
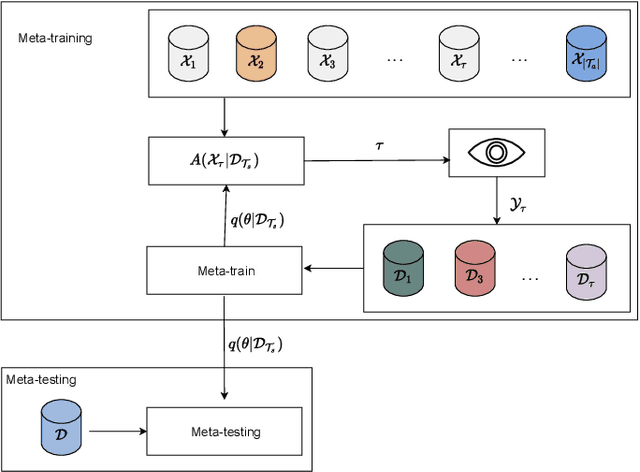
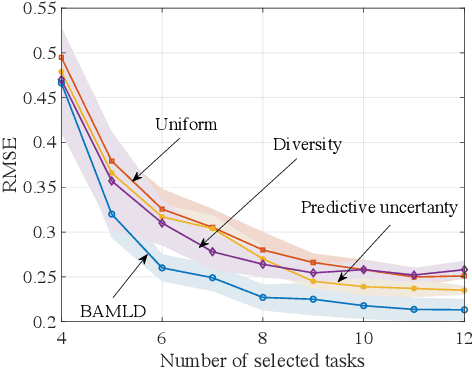
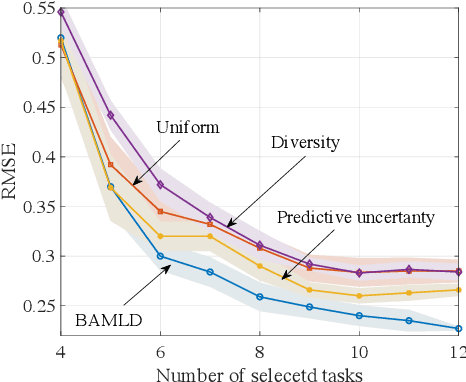
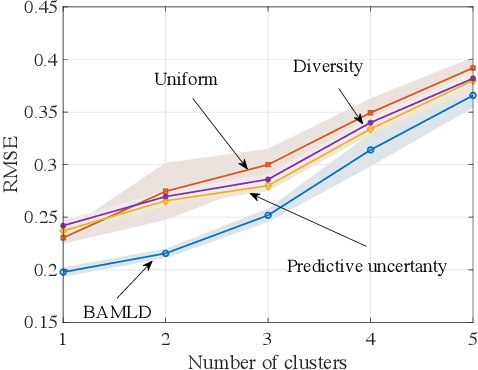
Data-efficient learning algorithms are essential in many practical applications for which data collection and labeling is expensive or infeasible, e.g., for autonomous cars. To address this problem, meta-learning infers an inductive bias from a set of meta-training tasks in order to learn new, but related, task using a small number of samples. Most studies assume the meta-learner to have access to labeled data sets from a large number of tasks. In practice, one may have available only unlabeled data sets from the tasks, requiring a costly labeling procedure to be carried out before use in standard meta-learning schemes. To decrease the number of labeling requests for meta-training tasks, this paper introduces an information-theoretic active task selection mechanism which quantifies the epistemic uncertainty via disagreements among the predictions obtained under different inductive biases. We detail an instantiation for nonparametric methods based on Gaussian Process Regression, and report its empirical performance results that compare favourably against existing heuristic acquisition mechanisms.
Facial Recognition in Collaborative Learning Videos
Oct 25, 2021
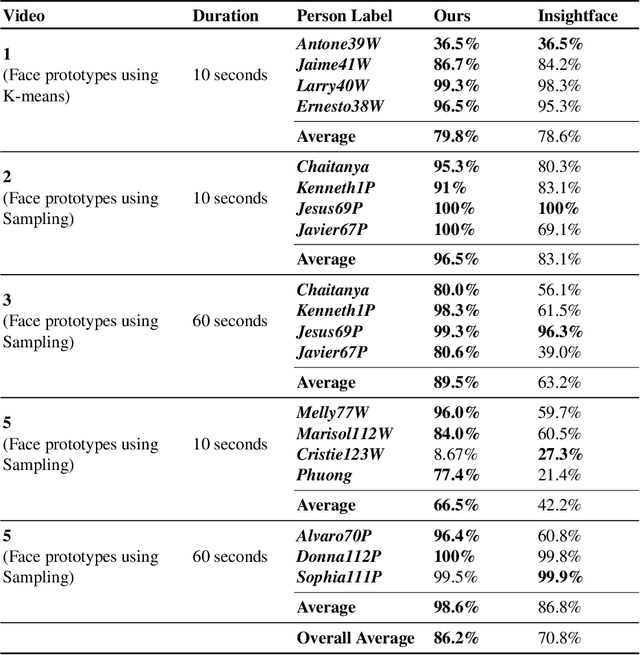
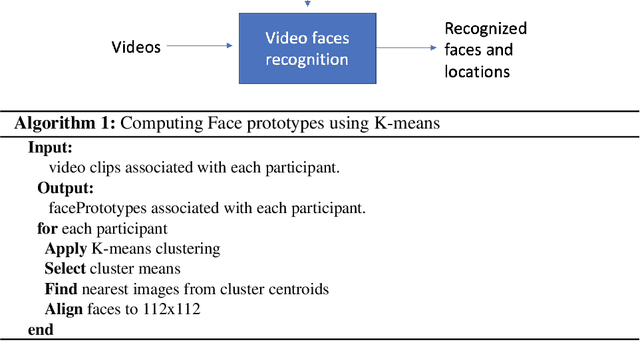
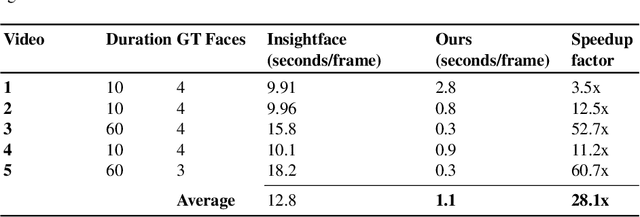
Face recognition in collaborative learning videos presents many challenges. In collaborative learning videos, students sit around a typical table at different positions to the recording camera, come and go, move around, get partially or fully occluded. Furthermore, the videos tend to be very long, requiring the development of fast and accurate methods. We develop a dynamic system of recognizing participants in collaborative learning systems. We address occlusion and recognition failures by using past information about the face detection history. We address the need for detecting faces from different poses and the need for speed by associating each participant with a collection of prototype faces computed through sampling or K-means clustering. Our results show that the proposed system is proven to be very fast and accurate. We also compare our system against a baseline system that uses InsightFace [2] and the original training video segments. We achieved an average accuracy of 86.2% compared to 70.8% for the baseline system. On average, our recognition rate was 28.1 times faster than the baseline system.
Speech Enhancement Based on Cyclegan with Noise-informed Training
Oct 19, 2021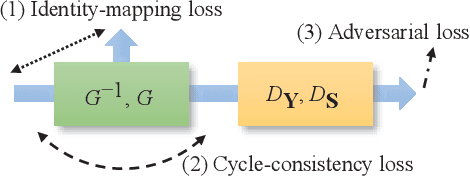
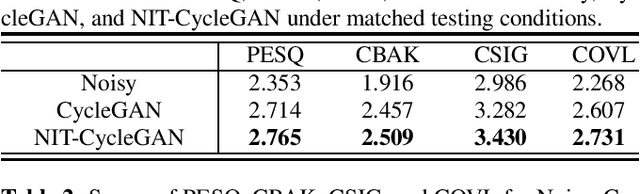
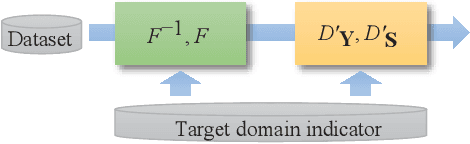
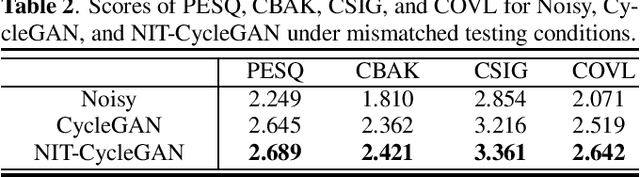
Speech enhancement (SE) approaches can be classified into supervised and unsupervised categories. For unsupervised SE, a well-known cycle-consistent generative adversarial network (CycleGAN) model, which comprises two generators and two discriminators, has been shown to provide a powerful nonlinear mapping ability and thus achieve a promising noise-suppression capability. However, a low-efficiency training process along with insufficient knowledge between noisy and clean speech may limit the enhancement performance of the CycleGAN SE at runtime. In this study, we propose a novel noise-informed-training CycleGAN approach that incorporates additional inputs into the generators and discriminators to assist the CycleGAN in learning a more accurate transformation of speech signals between the noise and clean domains. The additional input feature serves as an indicator that provides more information during the CycleGAN training stage. Experiment results confirm that the proposed approach can improve the CycleGAN SE model while achieving a better sound quality and fewer signal distortions.
Bilateral-ViT for Robust Fovea Localization
Oct 19, 2021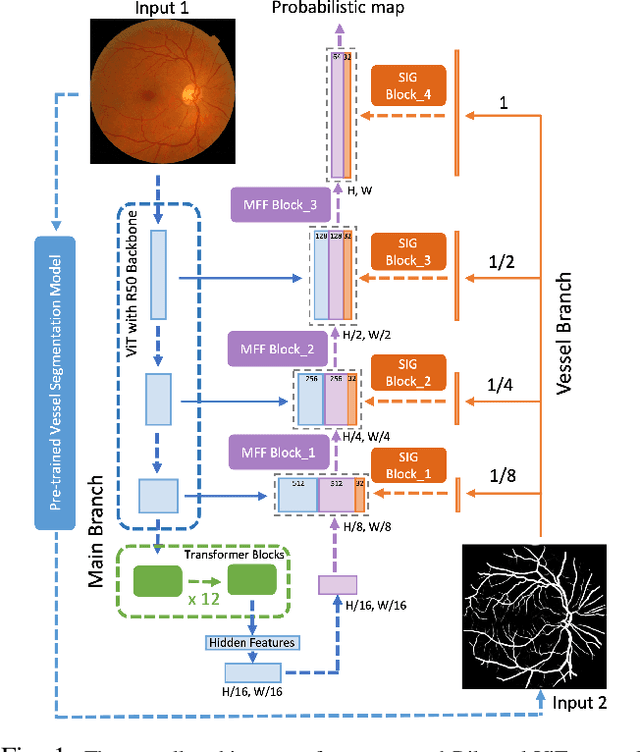
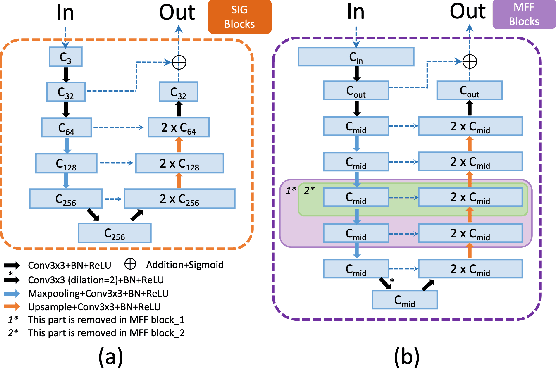
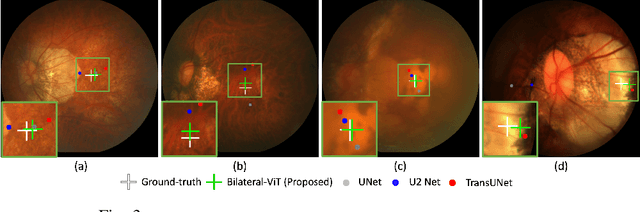
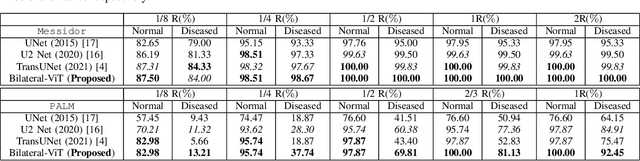
The fovea is an important anatomical landmark of the retina. Detecting the location of the fovea is essential for the analysis of many retinal diseases. However, robust fovea localization remains a challenging problem, as the fovea region often appears fuzzy, and retina diseases may further obscure its appearance. This paper proposes a novel vision transformer (ViT) approach that integrates information both inside and outside the fovea region to achieve robust fovea localization. Our proposed network named Bilateral-Vision-Transformer (Bilateral-ViT) consists of two network branches: a transformer-based main network branch for integrating global context across the entire fundus image and a vessel branch for explicitly incorporating the structure of blood vessels. The encoded features from both network branches are subsequently merged with a customized multi-scale feature fusion (MFF) module. Our comprehensive experiments demonstrate that the proposed approach is significantly more robust for diseased images and establishes the new state of the arts on both Messidor and PALM datasets.
The Possibilistic Horn Non-Clausal Knowledge Bases
Nov 15, 2021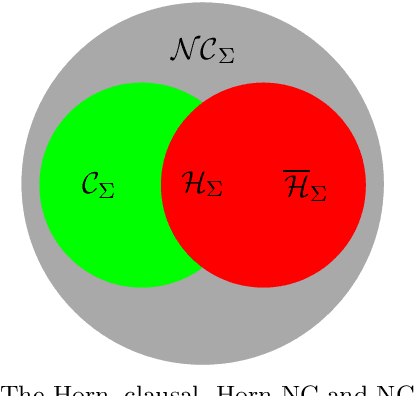
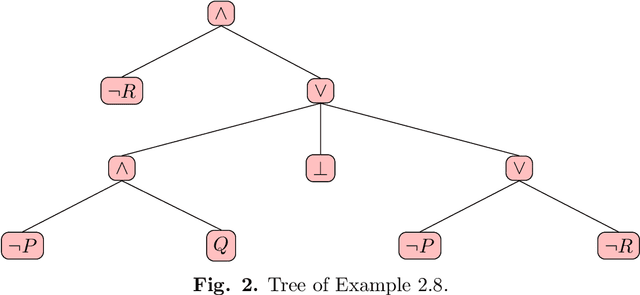
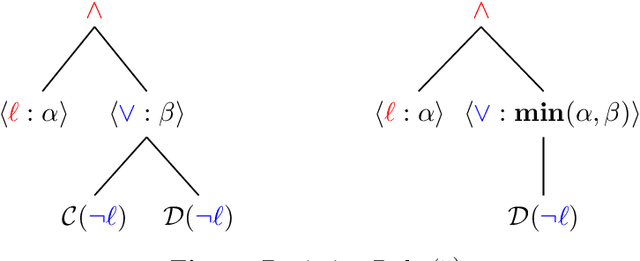
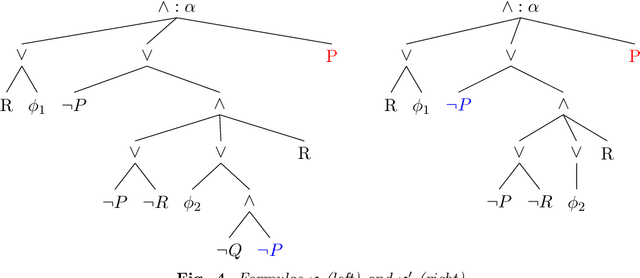
Posibilistic logic is the most extended approach to handle uncertain and partially inconsistent information. Regarding normal forms, advances in possibilistic reasoning are mostly focused on clausal form. Yet, the encoding of real-world problems usually results in a non-clausal (NC) formula and NC-to-clausal translators produce severe drawbacks that heavily limit the practical performance of clausal reasoning. Thus, by computing formulas in its original NC form, we propose several contributions showing that notable advances are also possible in possibilistic non-clausal reasoning. {\em Firstly,} we define the class of {\em Possibilistic Horn Non-Clausal Knowledge Bases,} or $\mathcal{\overline{H}}_\Sigma$, which subsumes the classes: possibilistic Horn and propositional Horn-NC. $\mathcal{\overline{H}}_\Sigma $ is shown to be a kind of NC analogous of the standard Horn class. {\em Secondly}, we define {\em Possibilistic Non-Clausal Unit-Resolution,} or $ \mathcal{UR}_\Sigma $, and prove that $ \mathcal{UR}_\Sigma $ correctly computes the inconsistency degree of $\mathcal{\overline{H}}_\Sigma $members. $\mathcal{UR}_\Sigma $ had not been proposed before and is formulated in a clausal-like manner, which eases its understanding, formal proofs and future extension towards non-clausal resolution. {\em Thirdly}, we prove that computing the inconsistency degree of $\mathcal{\overline{H}}_\Sigma $ members takes polynomial time. Although there already exist tractable classes in possibilistic logic, all of them are clausal, and thus, $\mathcal{\overline{H}}_\Sigma $ turns out to be the first characterized polynomial non-clausal class within possibilistic reasoning.
3D AGSE-VNet: An Automatic Brain Tumor MRI Data Segmentation Framework
Jul 26, 2021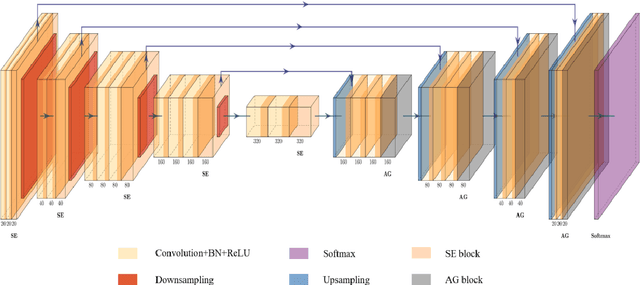
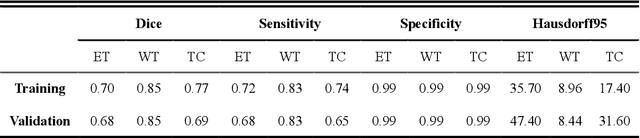
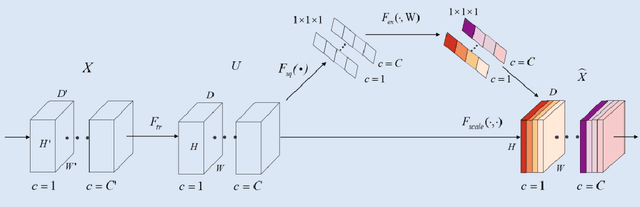
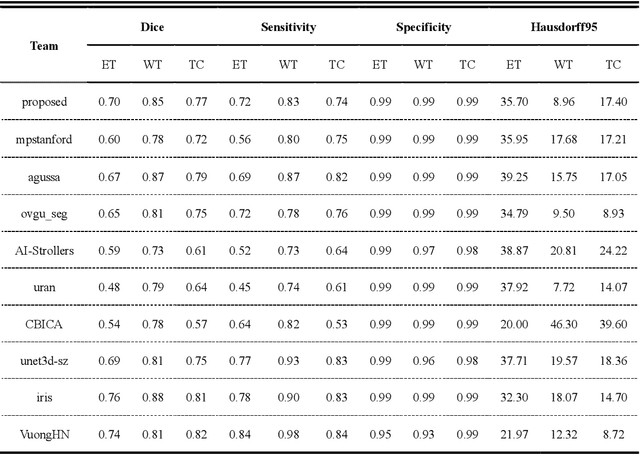
Background: Glioma is the most common brain malignant tumor, with a high morbidity rate and a mortality rate of more than three percent, which seriously endangers human health. The main method of acquiring brain tumors in the clinic is MRI. Segmentation of brain tumor regions from multi-modal MRI scan images is helpful for treatment inspection, post-diagnosis monitoring, and effect evaluation of patients. However, the common operation in clinical brain tumor segmentation is still manual segmentation, lead to its time-consuming and large performance difference between different operators, a consistent and accurate automatic segmentation method is urgently needed. Methods: To meet the above challenges, we propose an automatic brain tumor MRI data segmentation framework which is called AGSE-VNet. In our study, the Squeeze and Excite (SE) module is added to each encoder, the Attention Guide Filter (AG) module is added to each decoder, using the channel relationship to automatically enhance the useful information in the channel to suppress the useless information, and use the attention mechanism to guide the edge information and remove the influence of irrelevant information such as noise. Results: We used the BraTS2020 challenge online verification tool to evaluate our approach. The focus of verification is that the Dice scores of the whole tumor (WT), tumor core (TC) and enhanced tumor (ET) are 0.68, 0.85 and 0.70, respectively. Conclusion: Although MRI images have different intensities, AGSE-VNet is not affected by the size of the tumor, and can more accurately extract the features of the three regions, it has achieved impressive results and made outstanding contributions to the clinical diagnosis and treatment of brain tumor patients.
Mac Users Do It Differently: the Role of Operating System and Individual Differences in File Management
Sep 30, 2021
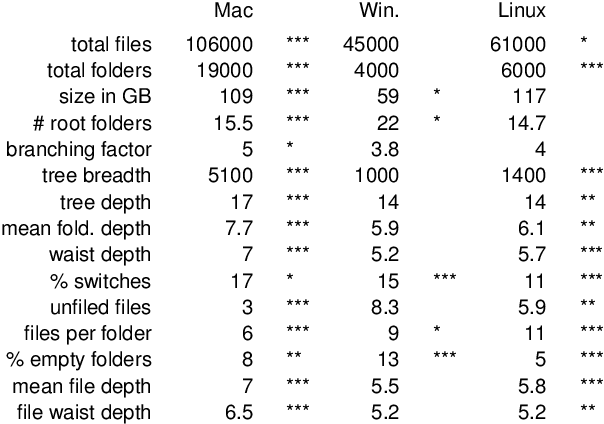
Despite much discussion in HCI research about how individual differences likely determine computer users' personal information management (PIM) practices, the extent of the influence of several important factors remains unclear, including users' personalities, spatial abilities, and the different software used to manage their collections. We therefore analyse data from prior CHI work to explore (1) associations of people's file collections with personality and spatial ability, and (2) differences between collections managed with different operating systems and file managers. We find no notable associations between users' attributes and their collections, and minimal predictive power, but do find considerable and surprising differences across operating systems. We discuss these findings and how they can inform future research.
* ACM CHI '20 conference paper ('late-breaking work' category), 8 pages
Multichannel Speech Enhancement without Beamforming
Oct 25, 2021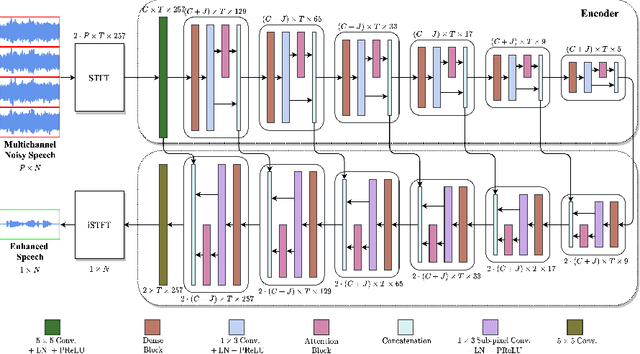
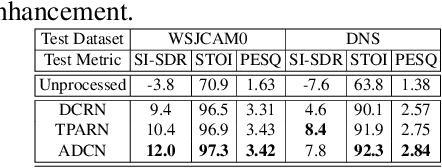
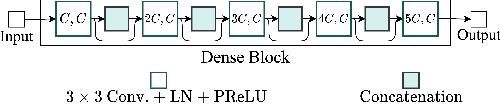
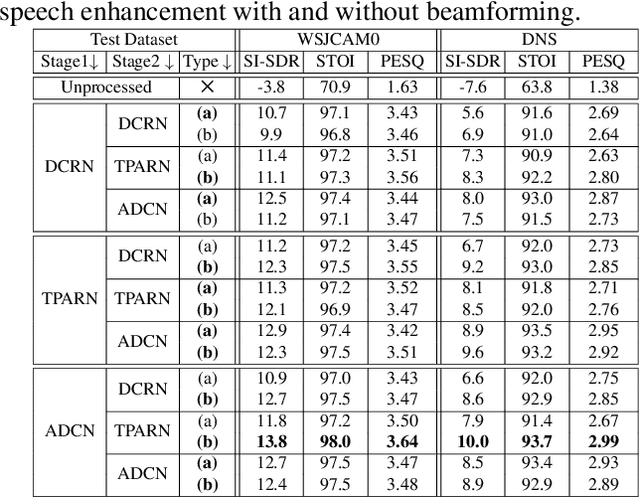
Deep neural networks are often coupled with traditional spatial filters, such as MVDR beamformers for effectively exploiting spatial information. Even though single-stage end-to-end supervised models can obtain impressive enhancement, combining them with a beamformer and a DNN-based post-filter in a multistage processing provides additional improvements. In this work, we propose a two-stage strategy for multi-channel speech enhancement that does not need a beamformer for additional performance. First, we propose a novel attentive dense convolutional network (ADCN) for predicting real and imaginary parts of complex spectrogram. ADCN obtains state-of-the-art results among single-stage models. Next, we use ADCN in the proposed strategy with a recently proposed triple-path attentive recurrent network (TPARN) for predicting waveform samples. The proposed strategy uses two insights; first, using different approaches in two stages; and second, using a stronger model in the first stage. We illustrate the efficacy of our strategy by evaluating multiple models in a two-stage approach with and without beamformer.
InfoRL: Interpretable Reinforcement Learning using Information Maximization
May 24, 2019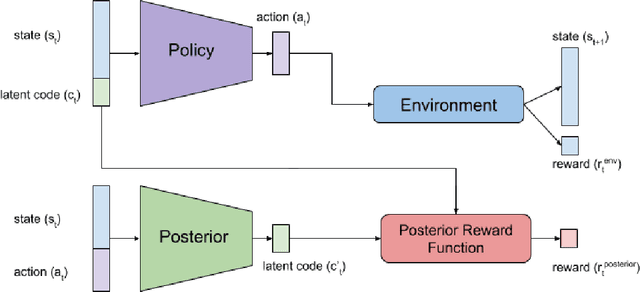

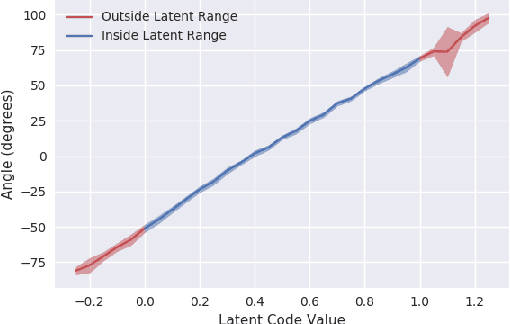
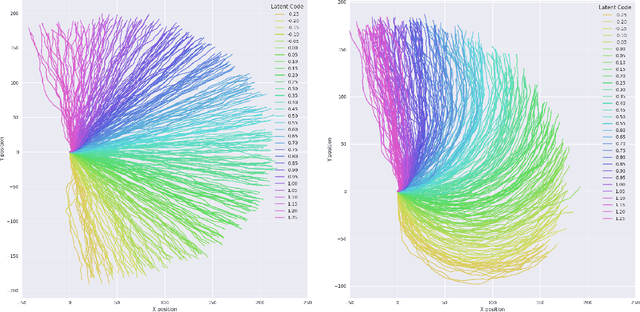
Recent advances in reinforcement learning have proved that given an environment we can learn to perform a task in that environment if we have access to some form of a reward function (dense, sparse or derived from IRL). But most of the algorithms focus on learning a single best policy to perform a given set of tasks. In this paper, we focus on an algorithm that learns to not just perform a task but different ways to perform the same task. As we know when the environment is complex enough there always exists multiple ways to perform a task. We show that using the concept of information maximization it is possible to learn latent codes for discovering multiple ways to perform any given task in an environment.
FakeTransformer: Exposing Face Forgery From Spatial-Temporal Representation Modeled By Facial Pixel Variations
Nov 15, 2021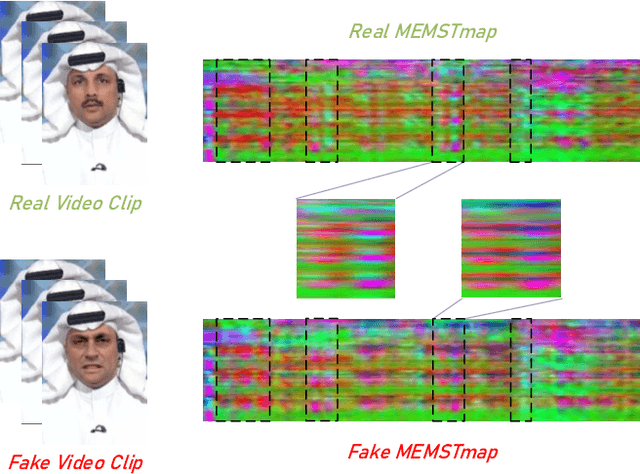
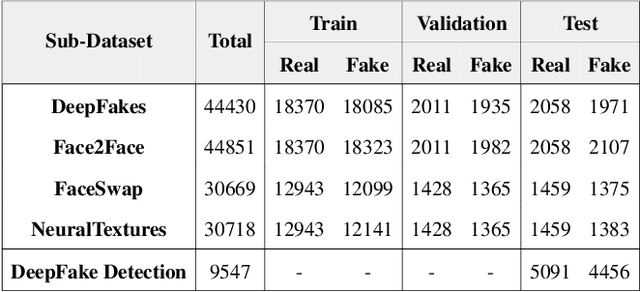
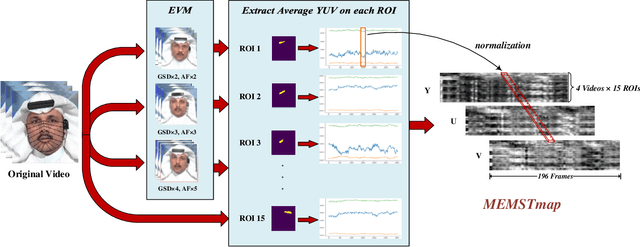
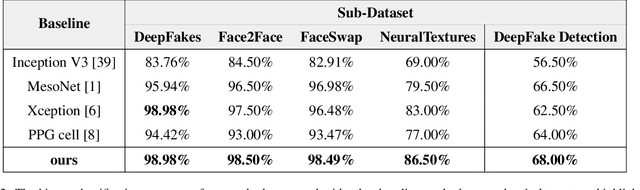
With the rapid development of generation model, AI-based face manipulation technology, which called DeepFakes, has become more and more realistic. This means of face forgery can attack any target, which poses a new threat to personal privacy and property security. Moreover, the misuse of synthetic video shows potential dangers in many areas, such as identity harassment, pornography and news rumors. Inspired by the fact that the spatial coherence and temporal consistency of physiological signal are destroyed in the generated content, we attempt to find inconsistent patterns that can distinguish between real videos and synthetic videos from the variations of facial pixels, which are highly related to physiological information. Our approach first applies Eulerian Video Magnification (EVM) at multiple Gaussian scales to the original video to enlarge the physiological variations caused by the change of facial blood volume, and then transform the original video and magnified videos into a Multi-Scale Eulerian Magnified Spatial-Temporal map (MEMSTmap), which can represent time-varying physiological enhancement sequences on different octaves. Then, these maps are reshaped into frame patches in column units and sent to the vision Transformer to learn the spatio-time descriptors of frame levels. Finally, we sort out the feature embedding and output the probability of judging whether the video is real or fake. We validate our method on the FaceForensics++ and DeepFake Detection datasets. The results show that our model achieves excellent performance in forgery detection, and also show outstanding generalization capability in cross-data domain.