 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AnchorGAE: General Data Clustering via $O(n)$ Bipartite Graph Convolution
Nov 12, 2021
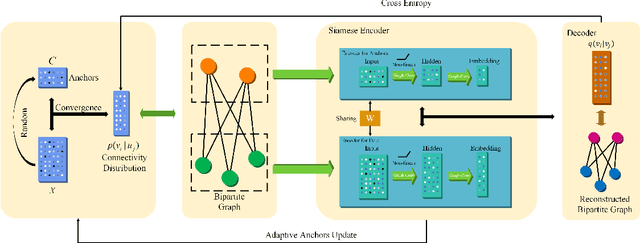
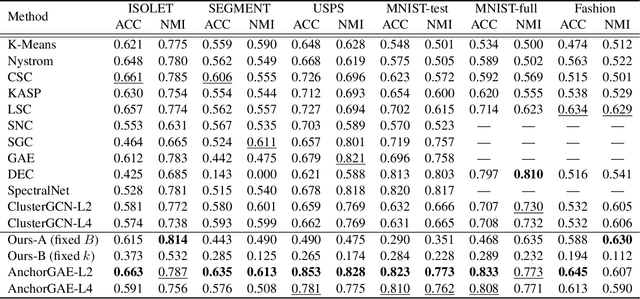

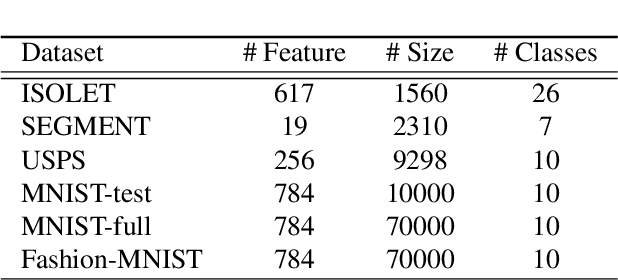
Graph-based clustering plays an important role in clustering tasks. As graph convolution network (GCN), a variant of neural networks on graph-type data, has achieved impressive performance, it is attractive to find whether GCNs can be used to augment the graph-based clustering methods on non-graph data, i.e., general data. However, given $n$ samples, the graph-based clustering methods usually need at least $O(n^2)$ time to build graphs and the graph convolution requires nearly $O(n^2)$ for a dense graph and $O(|\mathcal{E}|)$ for a sparse one with $|\mathcal{E}|$ edges. In other words, both graph-based clustering and GCNs suffer from severe inefficiency problems. To tackle this problem and further employ GCN to promote the capacity of graph-based clustering, we propose a novel clustering method, AnchorGAE. As the graph structure is not provided in general clustering scenarios, we first show how to convert a non-graph dataset into a graph by introducing the generative graph model, which is used to build GCNs. Anchors are generated from the original data to construct a bipartite graph such that the computational complexity of graph convolution is reduced from $O(n^2)$ and $O(|\mathcal{E}|)$ to $O(n)$. The succeeding steps for clustering can be easily designed as $O(n)$ operations. Interestingly, the anchors naturally lead to a siamese GCN architecture. The bipartite graph constructed by anchors is updated dynamically to exploit the high-level information behind data. Eventually, we theoretically prove that the simple update will lead to degeneration and a specific strategy is accordingly designed.
Relation-aware Video Reading Comprehension for Temporal Language Grounding
Oct 12, 2021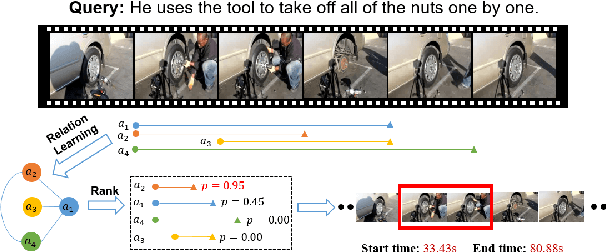
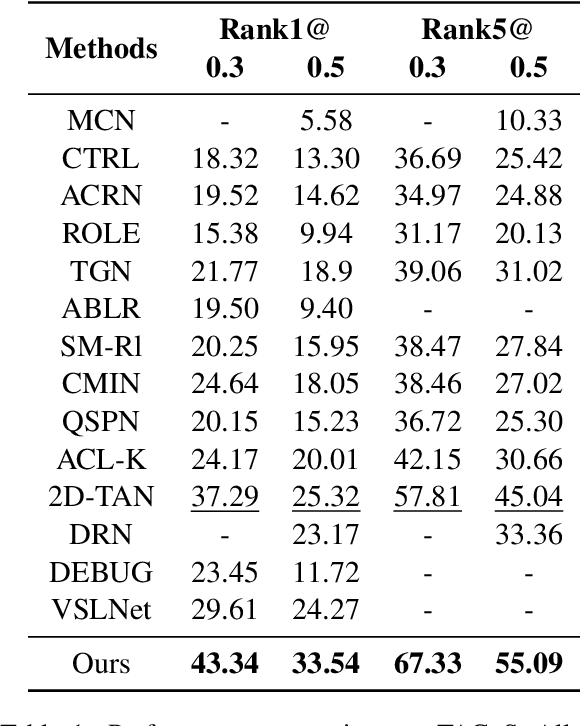
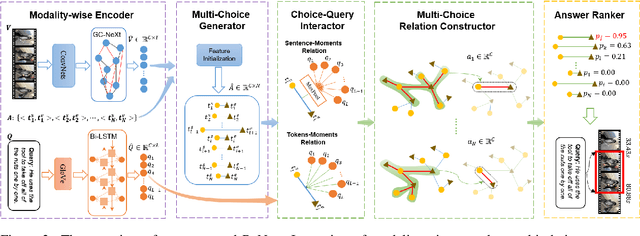
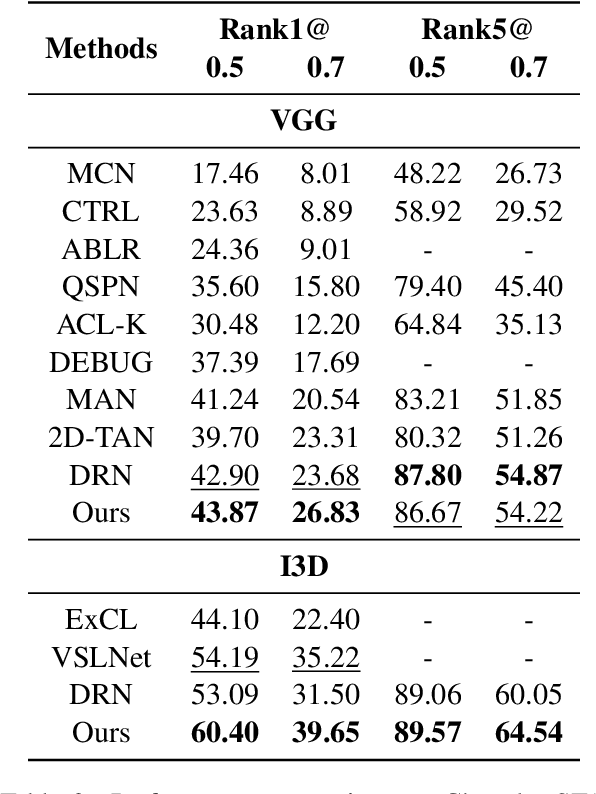
Temporal language grounding in videos aims to localize the temporal span relevant to the given query sentence. Previous methods treat it either as a boundary regression task or a span extraction task. This paper will formulate temporal language grounding into video reading comprehension and propose a Relation-aware Network (RaNet) to address it. This framework aims to select a video moment choice from the predefined answer set with the aid of coarse-and-fine choice-query interaction and choice-choice relation construction. A choice-query interactor is proposed to match the visual and textual information simultaneously in sentence-moment and token-moment levels, leading to a coarse-and-fine cross-modal interaction. Moreover, a novel multi-choice relation constructor is introduced by leveraging graph convolution to capture the dependencies among video moment choices for the best choice selection. Extensive experiments on ActivityNet-Captions, TACoS, and Charades-STA demonstrate the effectiveness of our solution. Codes will be released soon.
Extractive and Abstractive Sentence Labelling of Sentiment-bearing Topics
Aug 29, 2021
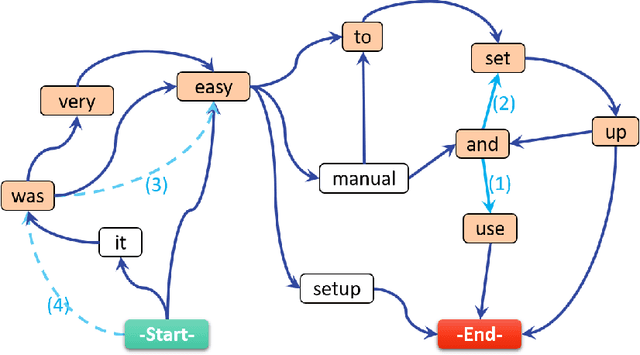

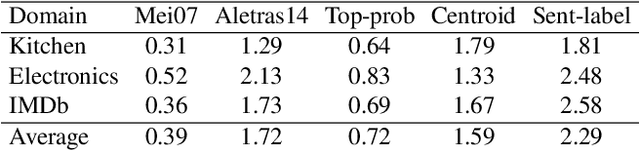
This paper tackles the problem of automatically labelling sentiment-bearing topics with descriptive sentence labels. We propose two approaches to the problem, one extractive and the other abstractive. Both approaches rely on a novel mechanism to automatically learn the relevance of each sentence in a corpus to sentiment-bearing topics extracted from that corpus. The extractive approach uses a sentence ranking algorithm for label selection which for the first time jointly optimises topic--sentence relevance as well as aspect--sentiment co-coverage. The abstractive approach instead addresses aspect--sentiment co-coverage by using sentence fusion to generate a sentential label that includes relevant content from multiple sentences. To our knowledge, we are the first to study the problem of labelling sentiment-bearing topics. Our experimental results on three real-world datasets show that both the extractive and abstractive approaches outperform four strong baselines in terms of facilitating topic understanding and interpretation. In addition, when comparing extractive and abstractive labels, our evaluation shows that our best performing abstractive method is able to provide more topic information coverage in fewer words, at the cost of generating less grammatical labels than the extractive method. We conclude that abstractive methods can effectively synthesise the rich information contained in sentiment-bearing topics.
AutoDiscern: Rating the Quality of Online Health Information with Hierarchical Encoder Attention-based Neural Networks
Dec 30, 2019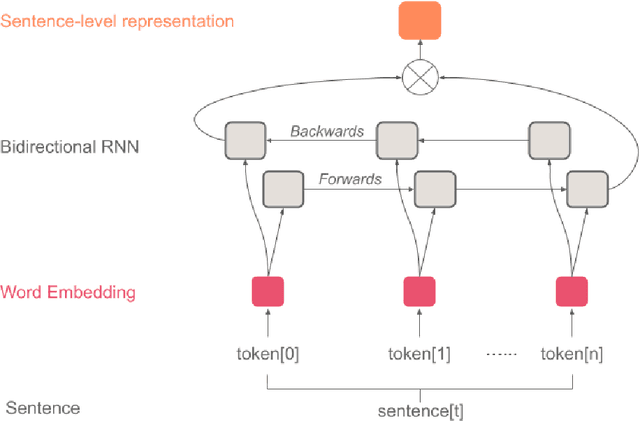
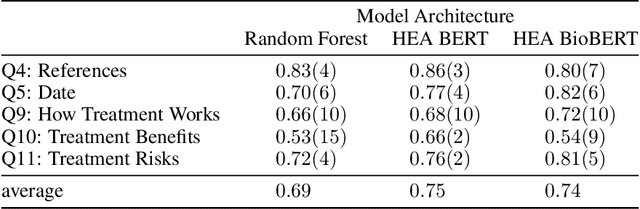
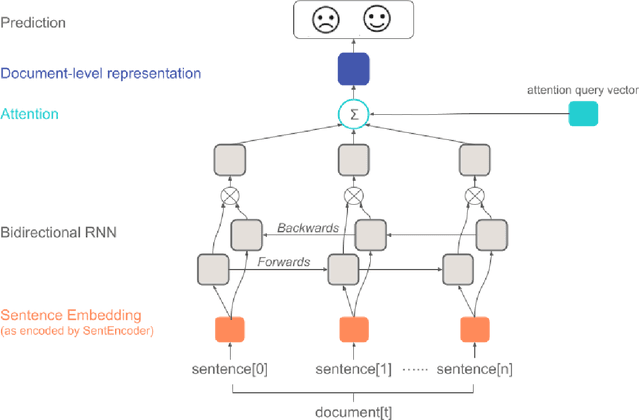
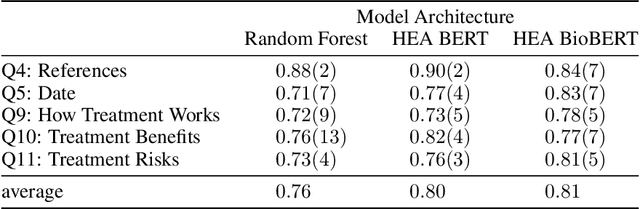
Patients increasingly turn to search engines and online content before, or in place of, talking with a health professional. Low quality health information, which is common on the internet, presents risks to the patient in the form of misinformation and a possibly poorer relationship to their physician. To address this, the DISCERN criteria (developed at University of Oxford) are used to evaluate the quality of online health information. However, patients are unlikely to take the time to apply these criteria to the health websites they visit. We built an automated implementation of the DISCERN instrument (Brief version) using machine learning models. We compared the use of a traditional model (Random Forest) with a hierarchical encoder attention-based neural network (HEA) model using two language embeddings based on BERT and BioBERT. The HEA BERT and BioBERT models achieved F1-macro scores averaging 0.75 and 0.74, respectively, on all criteria outperforming the Random Forest model (F1-macro = 0.69). Similarly, HEA BERT and BioBERT scored on average 0.8 and 0.81 (F1-micro) vs. 0.76 for the Random Forest model. Overall, the neural network based models achieved 81% and 86% average accuracy at 100% and 80% coverage, respectively, compared to 94% manual rating accuracy. The attention mechanism implemented in the HEA architectures provided 'model explainability' by identifying reasonable supporting sentences for the documents fulfilling the Brief DISCERN criteria. Our research suggests that it is feasible to automate online health information quality assessment, which is an important step towards empowering patients to become informed partners in the healthcare process.
SINet: Extreme Lightweight Portrait Segmentation Networks with Spatial Squeeze Modules and Information Blocking Decoder
Dec 09, 2019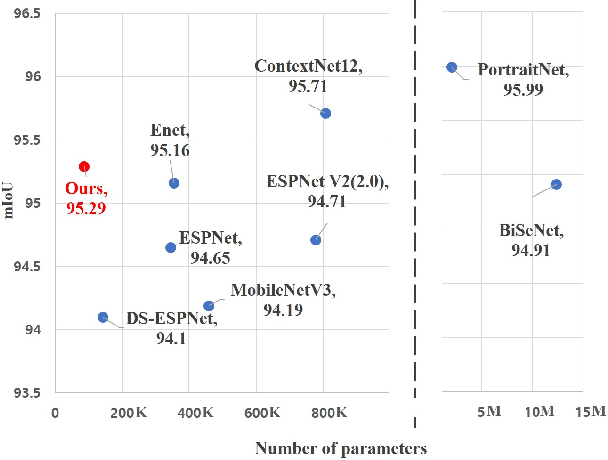


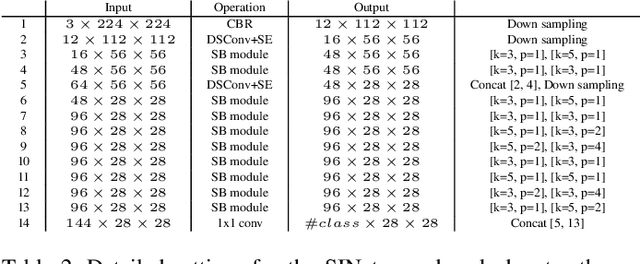
Designing a lightweight and robust portrait segmentation algorithm is an important task for a wide range of face applications. However, the problem has been considered as a subset of the object segmentation problem and less handled in the semantic segmentation field. Obviously, portrait segmentation has its unique requirements. First, because the portrait segmentation is performed in the middle of a whole process of many real-world applications, it requires extremely lightweight models. Second, there has not been any public datasets in this domain that contain a sufficient number of images with unbiased statistics. To solve the first problem, we introduce the new extremely lightweight portrait segmentation model SINet, containing an information blocking decoder and spatial squeeze modules. The information blocking decoder uses confidence estimates to recover local spatial information without spoiling global consistency. The spatial squeeze module uses multiple receptive fields to cope with various sizes of consistency in the image. To tackle the second problem, we propose a simple method to create additional portrait segmentation data which can improve accuracy on the EG1800 dataset. In our qualitative and quantitative analysis on the EG1800 dataset, we show that our method outperforms various existing lightweight segmentation models. Our method reduces the number of parameters from 2.1M to 86.9K (around 95.9% reduction), while maintaining the accuracy under an 1% margin from the state-of-the-art portrait segmentation method. We also show our model is successfully executed on a real mobile device with 100.6 FPS. In addition, we demonstrate that our method can be used for general semantic segmentation on the Cityscapes dataset. The code and dataset are available in https://github.com/HYOJINPARK/ExtPortraitSeg .
Frame-Capture-Based CSI Recomposition Pertaining to Firmware-Agnostic WiFi Sensing
Oct 29, 2021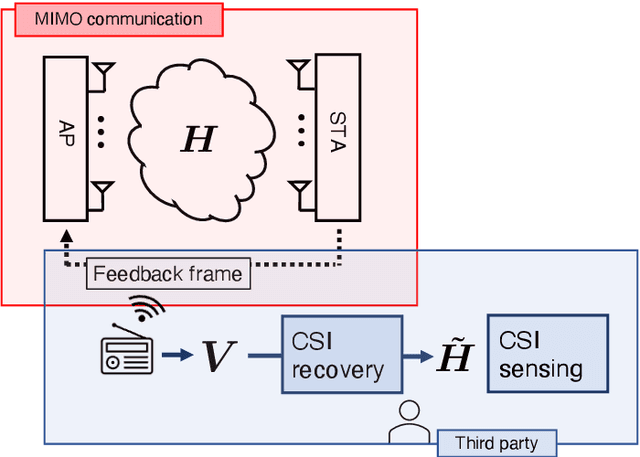
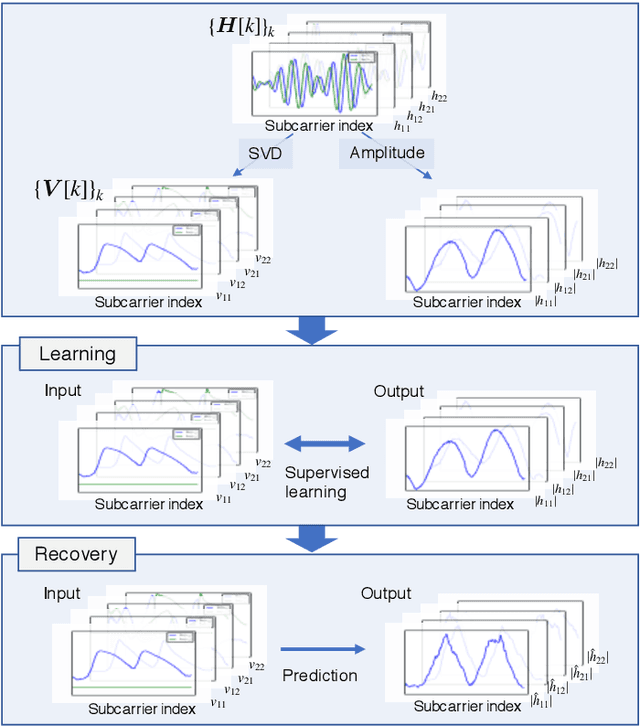
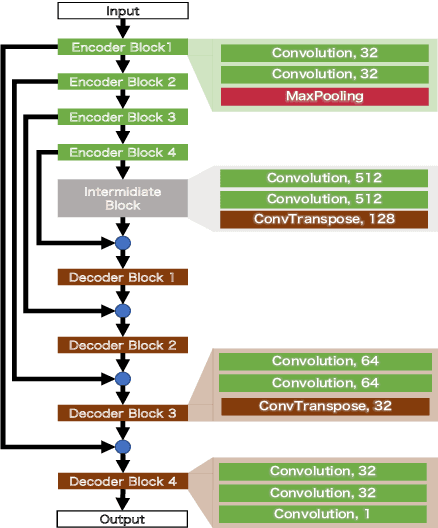
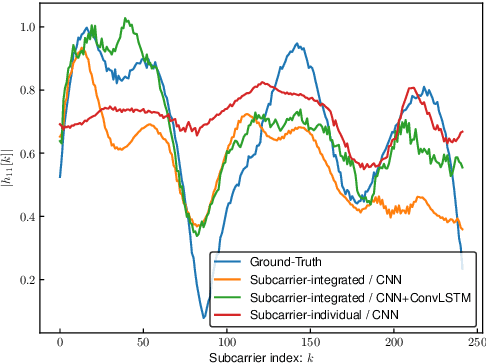
With regard to the implementation of WiFi sensing agnostic according to the availability of channel state information (CSI), we investigate the possibility of estimating a CSI matrix based on its compressed version, which is known as beamforming feedback matrix (BFM). Being different from the CSI matrix that is processed and discarded in physical layer components, the BFM can be captured using a medium-access-layer frame-capturing technique because this is exchanged among an access point (AP) and stations (STAs) over the air. This indicates that WiFi sensing that leverages the BFM matrix is more practical to implement using the pre-installed APs. However, the ability of BFM-based sensing has been evaluated in a few tasks, and more general insights into its performance should be provided. To fill this gap, we propose a CSI estimation method based on BFM, approximating the estimation function with a machine learning model. In addition, to improve the estimation accuracy, we leverage the inter-subcarrier dependency using the BFMs at multiple subcarriers in orthogonal frequency division multiplexing transmissions. Our simulation evaluation reveals that the estimated CSI matches the ground-truth amplitude. Moreover, compared to CSI estimation at each individual subcarrier, the effect of the BFMs at multiple subcarriers on the CSI estimation accuracy is validated.
Graphing else matters: exploiting aspect opinions and ratings in explainable graph-based recommendations
Jul 07, 2021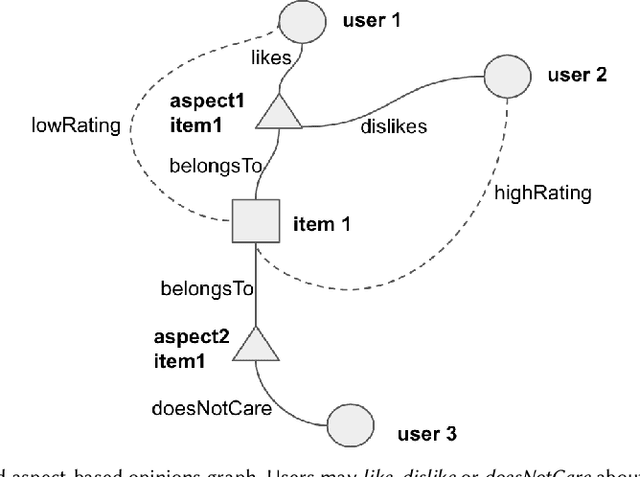

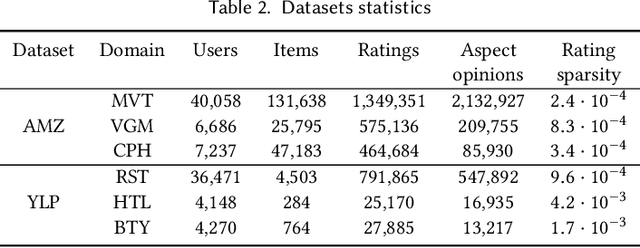
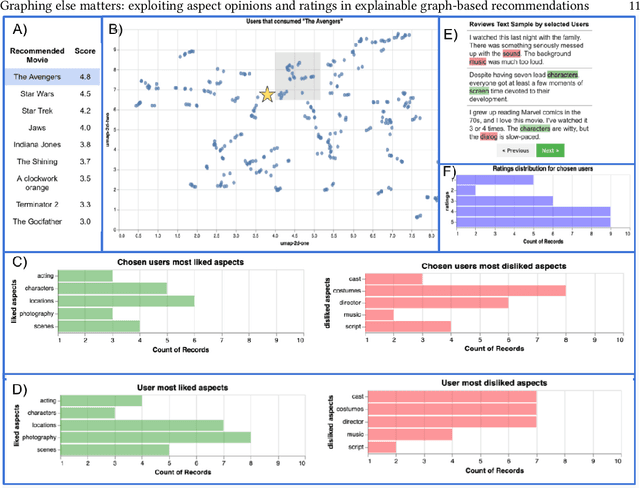
The success of neural network embeddings has entailed a renewed interest in using knowledge graphs for a wide variety of machine learning and information retrieval tasks. In particular, current recommendation methods based on graph embeddings have shown state-of-the-art performance. These methods commonly encode latent rating patterns and content features. Different from previous work, in this paper, we propose to exploit embeddings extracted from graphs that combine information from ratings and aspect-based opinions expressed in textual reviews. We then adapt and evaluate state-of-the-art graph embedding techniques over graphs generated from Amazon and Yelp reviews on six domains, outperforming baseline recommenders. Our approach has the advantage of providing explanations which leverage aspect-based opinions given by users about recommended items. Furthermore, we also provide examples of the applicability of recommendations utilizing aspect opinions as explanations in a visualization dashboard, which allows obtaining information about the most and least liked aspects of similar users obtained from the embeddings of an input graph.
IFCNet: A Benchmark Dataset for IFC Entity Classification
Jun 17, 2021
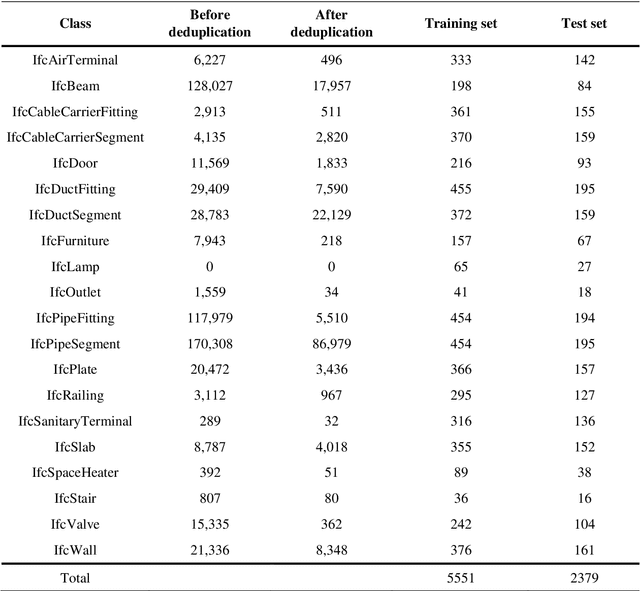

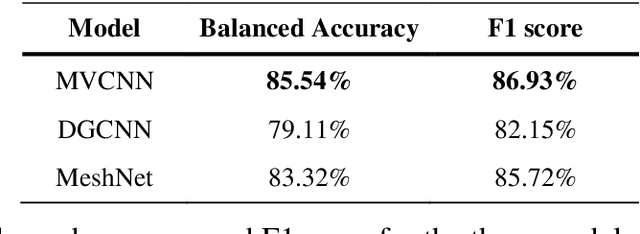
Enhancing interoperability and information exchange between domain-specific software products for BIM is an important aspect in the Architecture, Engineering, Construction and Operations industry. Recent research started investigating methods from the areas of machine and deep learning for semantic enrichment of BIM models. However, training and evaluation of these machine learning algorithms requires sufficiently large and comprehensive datasets. This work presents IFCNet, a dataset of single-entity IFC files spanning a broad range of IFC classes containing both geometric and semantic information. Using only the geometric information of objects, the experiments show that three different deep learning models are able to achieve good classification performance.
Machine Learning-Based Soft Sensors for Vacuum Distillation Unit
Nov 19, 2021
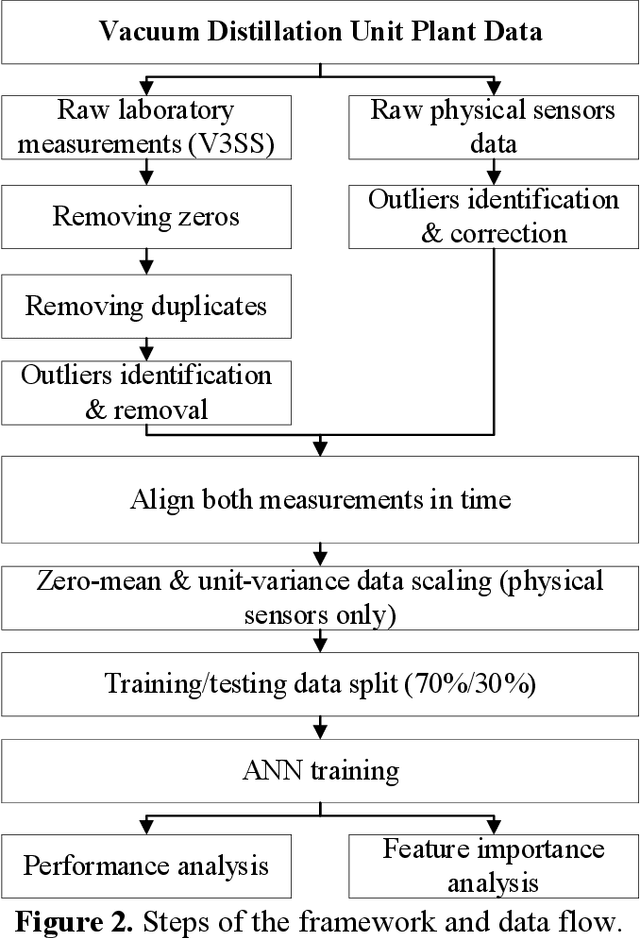
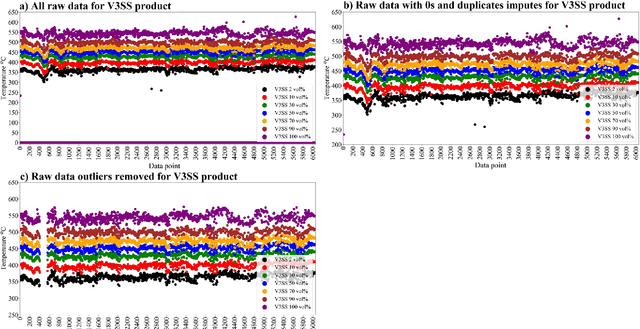
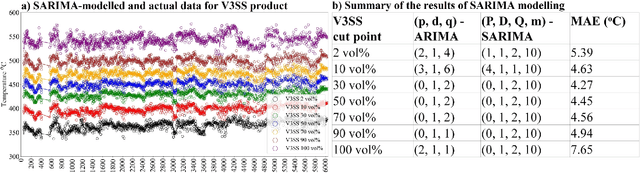
Product quality assessment in the petroleum processing industry can be difficult and time-consuming, e.g. due to a manual collection of liquid samples from the plant and subsequent chemical laboratory analysis of the samples. The product quality is an important property that informs whether the products of the process are within the specifications. In particular, the delays caused by sample processing (collection, laboratory measurements, results analysis, reporting) can lead to detrimental economic effects. One of the strategies to deal with this problem is soft sensors. Soft sensors are a collection of models that can be used to predict and forecast some infrequently measured properties (such as laboratory measurements of petroleum products) based on more frequent measurements of quantities like temperature, pressure and flow rate provided by physical sensors. Soft sensors short-cut the pathway to obtain relevant information about the product quality, often providing measurements as frequently as every minute. One of the applications of soft sensors is for the real-time optimization of a chemical process by a targeted adaptation of operating parameters. Models used for soft sensors can have various forms, however, among the most common are those based on artificial neural networks (ANNs). While soft sensors can deal with some of the issues in the refinery processes, their development and deployment can pose other challenges that are addressed in this paper. Firstly, it is important to enhance the quality of both sets of data (laboratory measurements and physical sensors) in a data pre-processing stage (as described in Methodology section). Secondly, once the data sets are pre-processed, different models need to be tested against prediction error and the model's interpretability. In this work, we present a framework for soft sensor development from raw data to ready-to-use models.
Data Driven based Dynamic Correction Prediction Model for NOx Emission of Coal Fired Boiler
Oct 29, 2021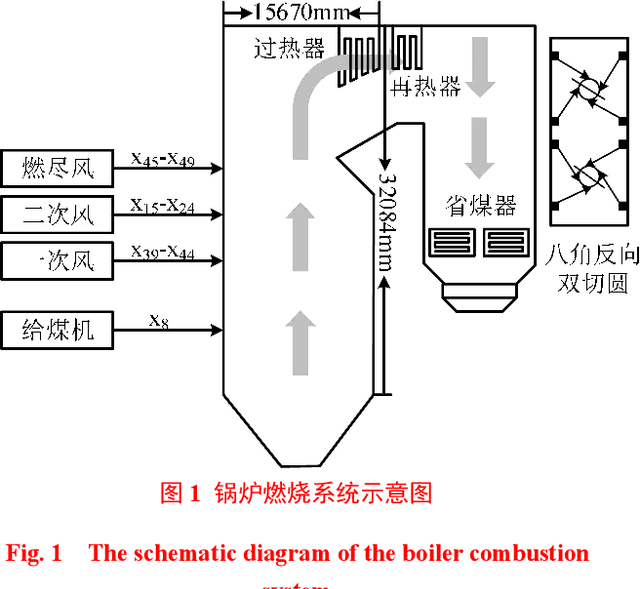
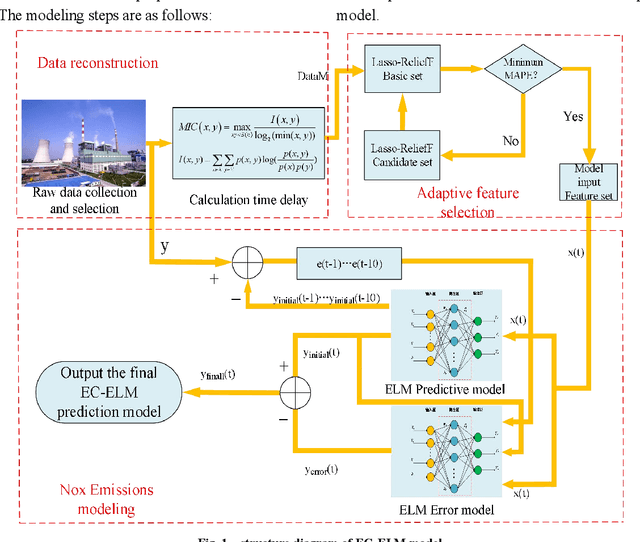
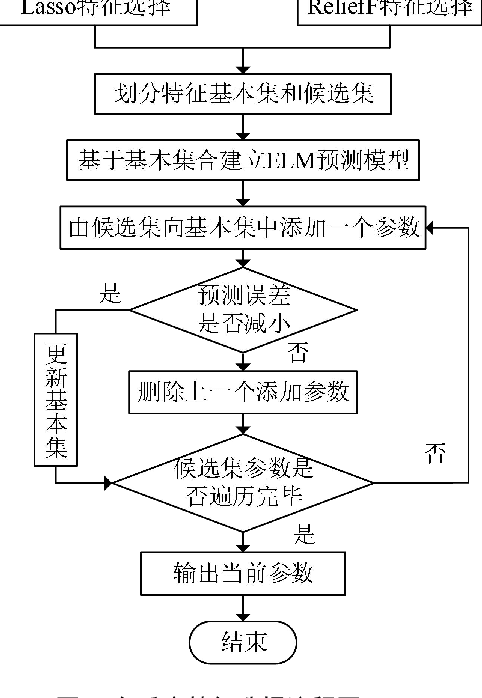
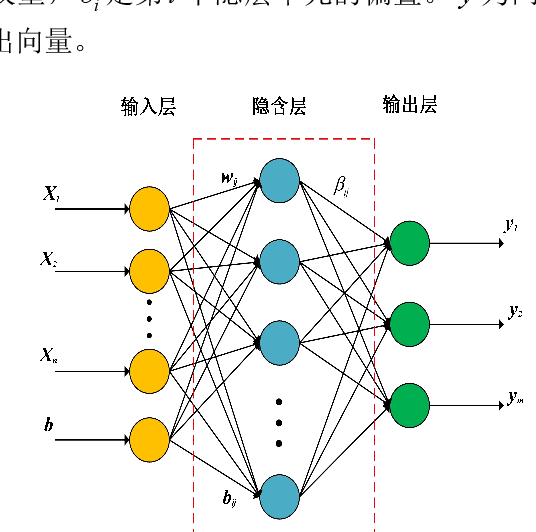
The real-time prediction of NOx emissions is of great significance for pollutant emission control and unit operation of coal-fired power plants. Aiming at dealing with the large time delay and strong nonlinear characteristics of the combustion process, a dynamic correction prediction model considering the time delay is proposed. First, the maximum information coefficient (MIC) is used to calculate the delay time between related parameters and NOx emissions, and the modeling data set is reconstructed; then, an adaptive feature selection algorithm based on Lasso and ReliefF is constructed to filter out the high correlation with NOx emissions. Parameters; Finally, an extreme learning machine (ELM) model combined with error correction was established to achieve the purpose of dynamically predicting the concentration of nitrogen oxides. Experimental results based on actual data show that the same variable has different delay times under load conditions such as rising, falling, and steady; and there are differences in model characteristic variables under different load conditions; dynamic error correction strategies effectively improve modeling accuracy; proposed The prediction error of the algorithm under different working conditions is less than 2%, which can accurately predict the NOx concentration at the combustion outlet, and provide guidance for NOx emission monitoring and combustion process optimization.