 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Time series cluster kernels to exploit informative missingness and incomplete label information
Jul 10, 2019

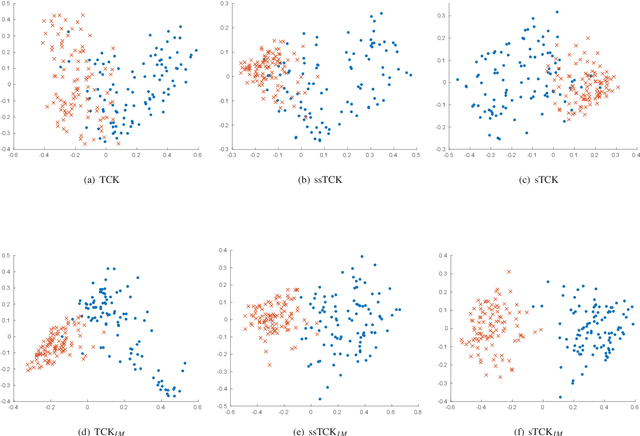
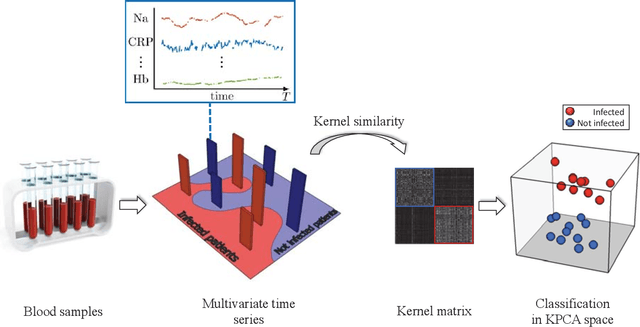
The time series cluster kernel (TCK) provides a powerful tool for analysing multivariate time series subject to missing data. TCK is designed using an ensemble learning approach in which Bayesian mixture models form the base models. Because of the Bayesian approach, TCK can naturally deal with missing values without resorting to imputation and the ensemble strategy ensures robustness to hyperparameters, making it particularly well suited for unsupervised learning. However, TCK assumes missing at random and that the underlying missingness mechanism is ignorable, i.e. uninformative, an assumption that does not hold in many real-world applications, such as e.g. medicine. To overcome this limitation, we present a kernel capable of exploiting the potentially rich information in the missing values and patterns, as well as the information from the observed data. In our approach, we create a representation of the missing pattern, which is incorporated into mixed mode mixture models in such a way that the information provided by the missing patterns is effectively exploited. Moreover, we also propose a semi-supervised kernel, capable of taking advantage of incomplete label information to learn more accurate similarities. Experiments on benchmark data, as well as a real-world case study of patients described by longitudinal electronic health record data who potentially suffer from hospital-acquired infections, demonstrate the effectiveness of the proposed methods.
MISS GAN: A Multi-IlluStrator Style Generative Adversarial Network for image to illustration translation
Aug 12, 2021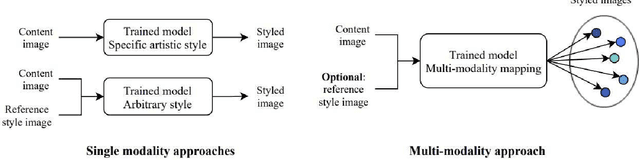
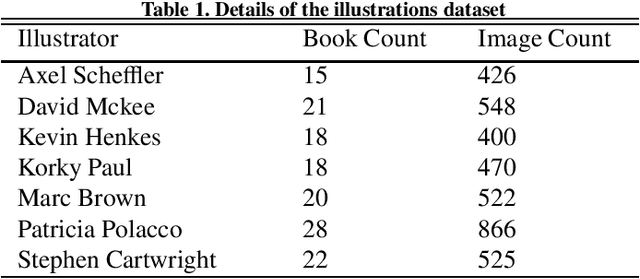
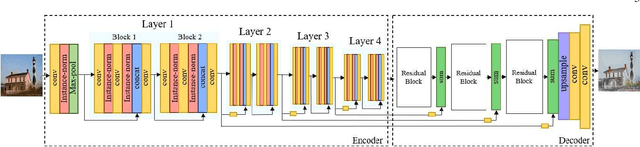

Unsupervised style transfer that supports diverse input styles using only one trained generator is a challenging and interesting task in computer vision. This paper proposes a Multi-IlluStrator Style Generative Adversarial Network (MISS GAN) that is a multi-style framework for unsupervised image-to-illustration translation, which can generate styled yet content preserving images. The illustrations dataset is a challenging one since it is comprised of illustrations of seven different illustrators, hence contains diverse styles. Existing methods require to train several generators (as the number of illustrators) to handle the different illustrators' styles, which limits their practical usage, or require to train an image specific network, which ignores the style information provided in other images of the illustrator. MISS GAN is both input image specific and uses the information of other images using only one trained model.
Self-Supervised Radio-Visual Representation Learning for 6G Sensing
Nov 01, 2021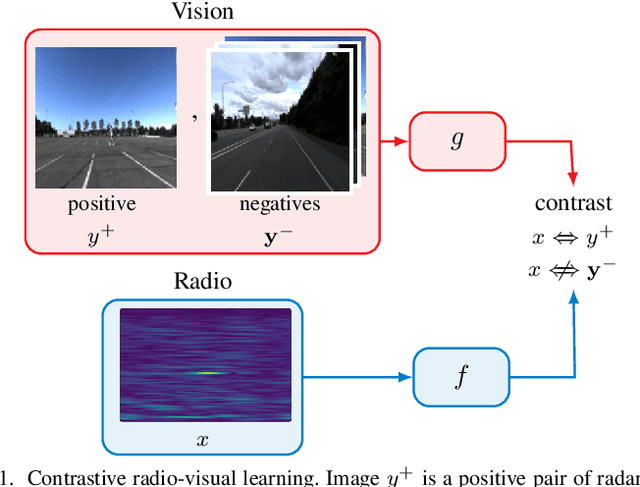
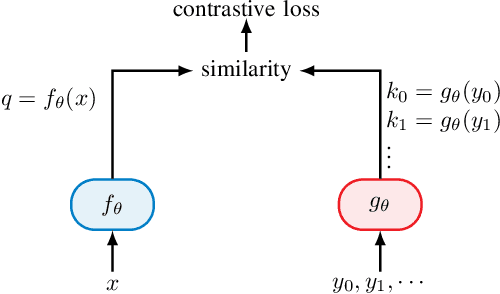
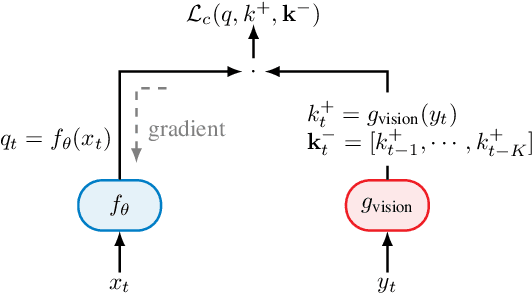
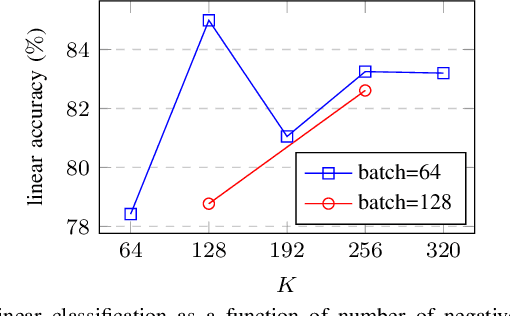
In future 6G cellular networks, a joint communication and sensing protocol will allow the network to perceive the environment, opening the door for many new applications atop a unified communication-perception infrastructure. However, interpreting the sparse radio representation of sensing scenes is challenging, which hinders the potential of these emergent systems. We propose to combine radio and vision to automatically learn a radio-only sensing model with minimal human intervention. We want to build a radio sensing model that can feed on millions of uncurated data points. To this end, we leverage recent advances in self-supervised learning and formulate a new label-free radio-visual co-learning scheme, whereby vision trains radio via cross-modal mutual information. We implement and evaluate our scheme according to the common linear classification benchmark, and report qualitative and quantitative performance metrics. In our evaluation, the representation learnt by radio-visual self-supervision works well for a downstream sensing demonstrator, and outperforms its fully-supervised counterpart when less labelled data is used. This indicates that self-supervised learning could be an important enabler for future scalable radio sensing systems.
Enhanced Language Representation with Label Knowledge for Span Extraction
Nov 01, 2021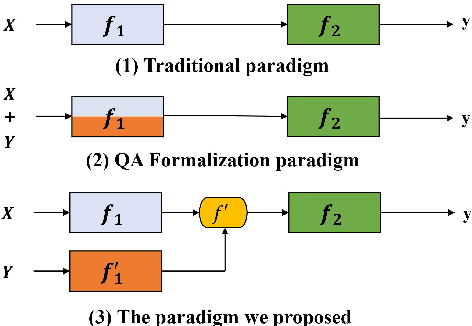


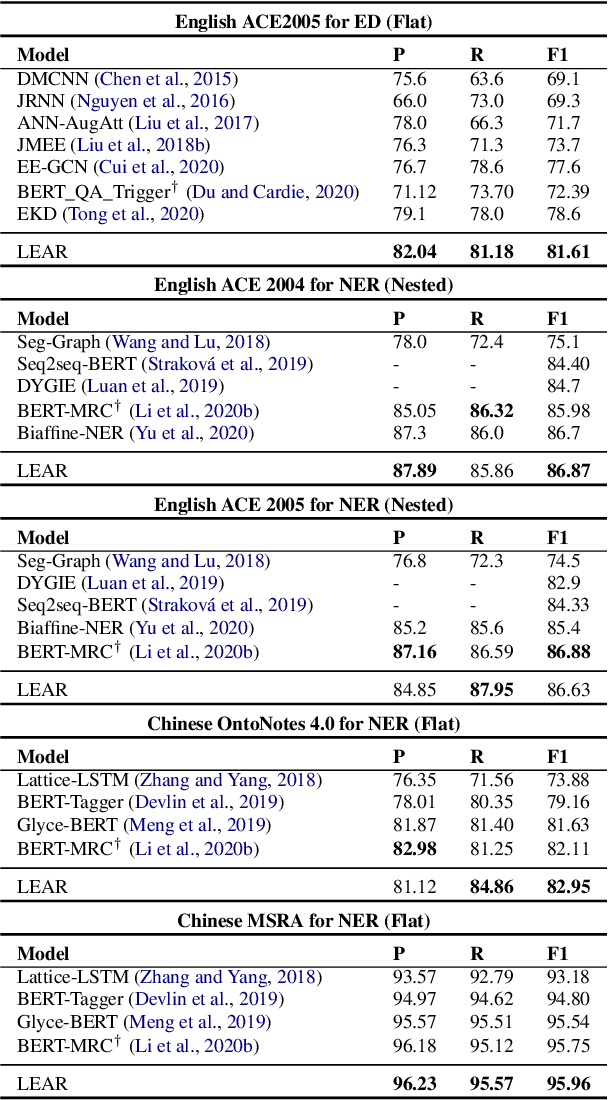
Span extraction, aiming to extract text spans (such as words or phrases) from plain texts, is a fundamental process in Information Extraction. Recent works introduce the label knowledge to enhance the text representation by formalizing the span extraction task into a question answering problem (QA Formalization), which achieves state-of-the-art performance. However, QA Formalization does not fully exploit the label knowledge and suffers from low efficiency in training/inference. To address those problems, we introduce a new paradigm to integrate label knowledge and further propose a novel model to explicitly and efficiently integrate label knowledge into text representations. Specifically, it encodes texts and label annotations independently and then integrates label knowledge into text representation with an elaborate-designed semantics fusion module. We conduct extensive experiments on three typical span extraction tasks: flat NER, nested NER, and event detection. The empirical results show that 1) our method achieves state-of-the-art performance on four benchmarks, and 2) reduces training time and inference time by 76% and 77% on average, respectively, compared with the QA Formalization paradigm. Our code and data are available at https://github.com/Akeepers/LEAR.
Unsupervised Part Discovery from Contrastive Reconstruction
Nov 11, 2021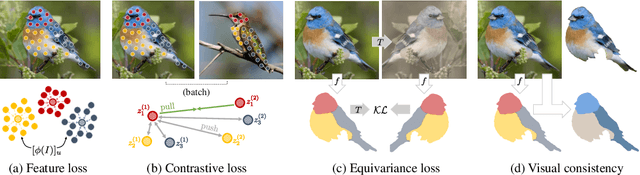
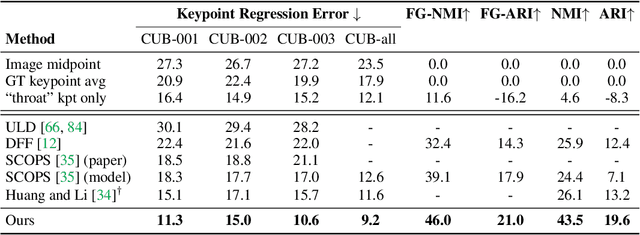

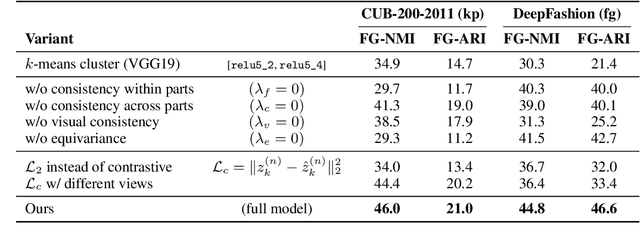
The goal of self-supervised visual representation learning is to learn strong, transferable image representations, with the majority of research focusing on object or scene level. On the other hand, representation learning at part level has received significantly less attention. In this paper, we propose an unsupervised approach to object part discovery and segmentation and make three contributions. First, we construct a proxy task through a set of objectives that encourages the model to learn a meaningful decomposition of the image into its parts. Secondly, prior work argues for reconstructing or clustering pre-computed features as a proxy to parts; we show empirically that this alone is unlikely to find meaningful parts; mainly because of their low resolution and the tendency of classification networks to spatially smear out information. We suggest that image reconstruction at the level of pixels can alleviate this problem, acting as a complementary cue. Lastly, we show that the standard evaluation based on keypoint regression does not correlate well with segmentation quality and thus introduce different metrics, NMI and ARI, that better characterize the decomposition of objects into parts. Our method yields semantic parts which are consistent across fine-grained but visually distinct categories, outperforming the state of the art on three benchmark datasets. Code is available at the project page: https://www.robots.ox.ac.uk/~vgg/research/unsup-parts/.
An Attack on Feature Level-based Facial Soft-biometric Privacy Enhancement
Nov 24, 2021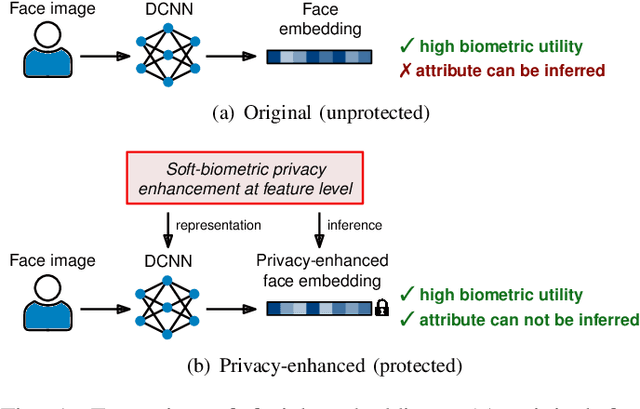
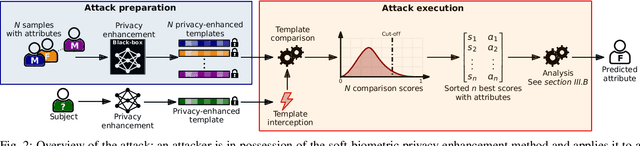
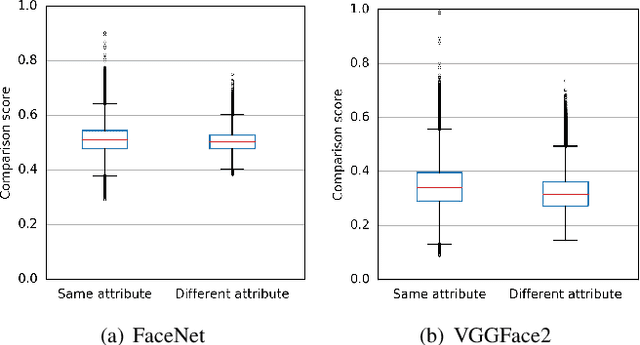
In the recent past, different researchers have proposed novel privacy-enhancing face recognition systems designed to conceal soft-biometric information at feature level. These works have reported impressive results, but usually do not consider specific attacks in their analysis of privacy protection. In most cases, the privacy protection capabilities of these schemes are tested through simple machine learning-based classifiers and visualisations of dimensionality reduction tools. In this work, we introduce an attack on feature level-based facial soft-biometric privacy-enhancement techniques. The attack is based on two observations: (1) to achieve high recognition accuracy, certain similarities between facial representations have to be retained in their privacy-enhanced versions; (2) highly similar facial representations usually originate from face images with similar soft-biometric attributes. Based on these observations, the proposed attack compares a privacy-enhanced face representation against a set of privacy-enhanced face representations with known soft-biometric attributes. Subsequently, the best obtained similarity scores are analysed to infer the unknown soft-biometric attributes of the attacked privacy-enhanced face representation. That is, the attack only requires a relatively small database of arbitrary face images and the privacy-enhancing face recognition algorithm as a black-box. In the experiments, the attack is applied to two representative approaches which have previously been reported to reliably conceal the gender in privacy-enhanced face representations. It is shown that the presented attack is able to circumvent the privacy enhancement to a considerable degree and is able to correctly classify gender with an accuracy of up to approximately 90% for both of the analysed privacy-enhancing face recognition systems.
A unifying framework for $n$-dimensional quasi-conformal mappings
Oct 20, 2021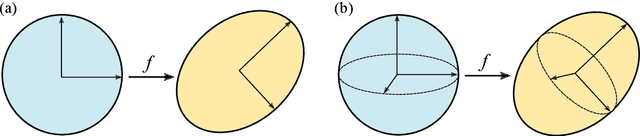
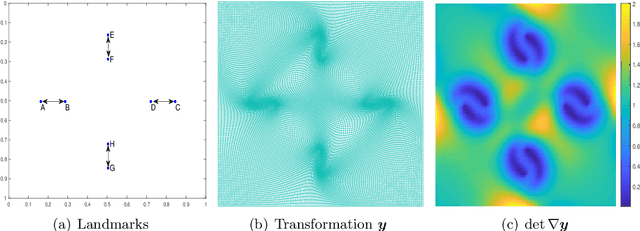
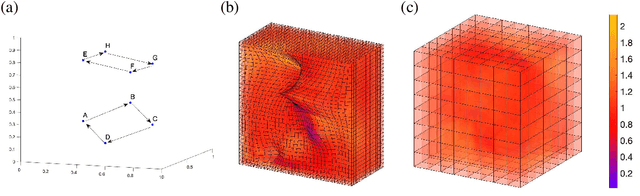
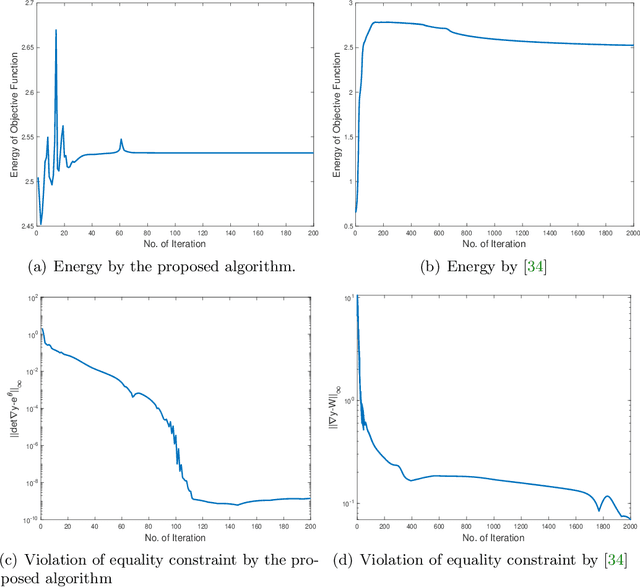
With the advancement of computer technology, there is a surge of interest in effective mapping methods for objects in higher-dimensional spaces. To establish a one-to-one correspondence between objects, higher-dimensional quasi-conformal theory can be utilized for ensuring the bijectivity of the mappings. In addition, it is often desirable for the mappings to satisfy certain prescribed geometric constraints and possess low distortion in conformality or volume. In this work, we develop a unifying framework for computing $n$-dimensional quasi-conformal mappings. More specifically, we propose a variational model that integrates quasi-conformal distortion, volumetric distortion, landmark correspondence, intensity mismatch and volume prior information to handle a large variety of deformation problems. We further prove the existence of a minimizer for the proposed model and devise efficient numerical methods to solve the optimization problem. We demonstrate the effectiveness of the proposed framework using various experiments in two- and three-dimensions, with applications to medical image registration, adaptive remeshing and shape modeling.
Exploiting Scene Graphs for Human-Object Interaction Detection
Aug 19, 2021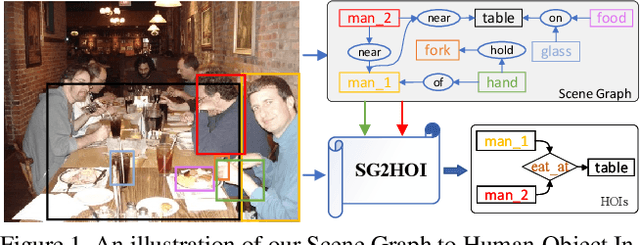
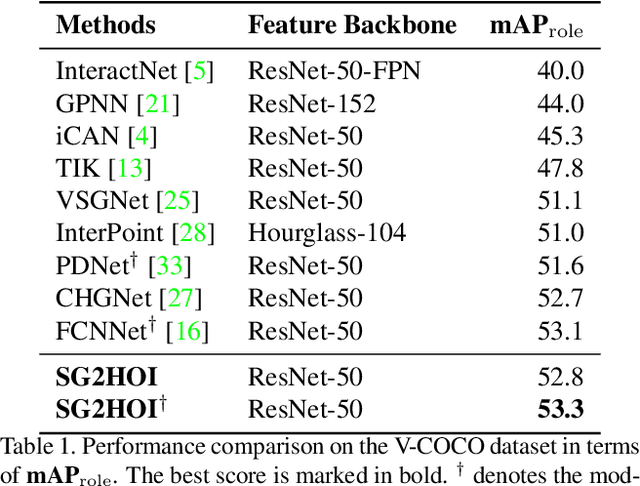
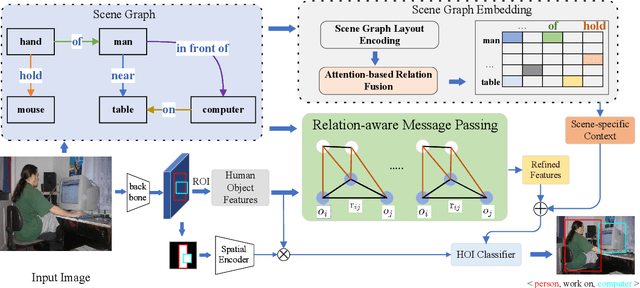
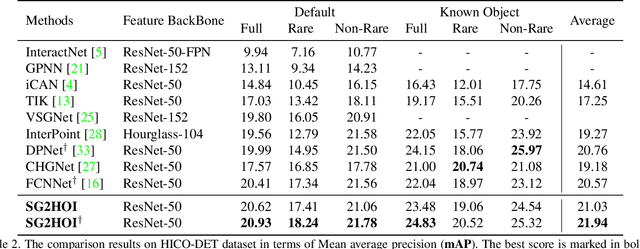
Human-Object Interaction (HOI) detection is a fundamental visual task aiming at localizing and recognizing interactions between humans and objects. Existing works focus on the visual and linguistic features of humans and objects. However, they do not capitalise on the high-level and semantic relationships present in the image, which provides crucial contextual and detailed relational knowledge for HOI inference. We propose a novel method to exploit this information, through the scene graph, for the Human-Object Interaction (SG2HOI) detection task. Our method, SG2HOI, incorporates the SG information in two ways: (1) we embed a scene graph into a global context clue, serving as the scene-specific environmental context; and (2) we build a relation-aware message-passing module to gather relationships from objects' neighborhood and transfer them into interactions. Empirical evaluation shows that our SG2HOI method outperforms the state-of-the-art methods on two benchmark HOI datasets: V-COCO and HICO-DET. Code will be available at https://github.com/ht014/SG2HOI.
Concurrent Discrimination and Alignment for Self-Supervised Feature Learning
Aug 19, 2021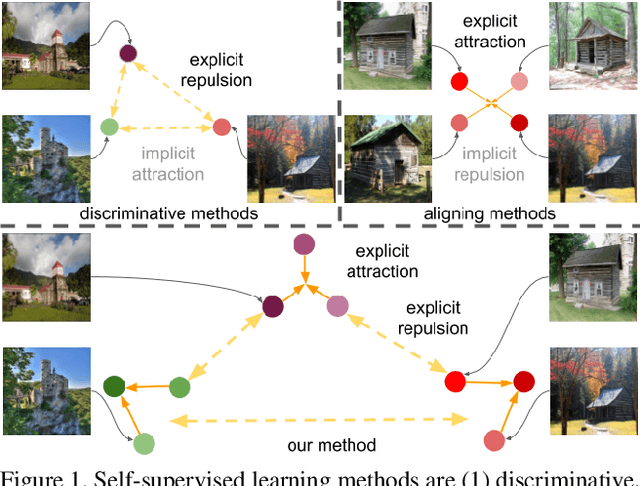

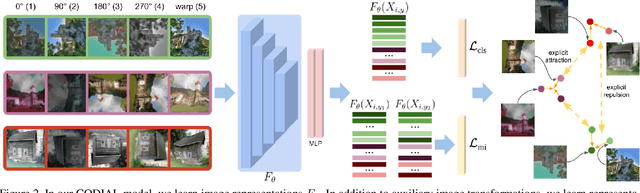
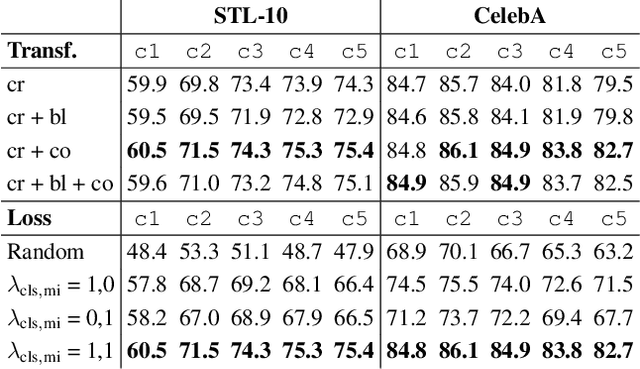
Existing self-supervised learning methods learn representation by means of pretext tasks which are either (1) discriminating that explicitly specify which features should be separated or (2) aligning that precisely indicate which features should be closed together, but ignore the fact how to jointly and principally define which features to be repelled and which ones to be attracted. In this work, we combine the positive aspects of the discriminating and aligning methods, and design a hybrid method that addresses the above issue. Our method explicitly specifies the repulsion and attraction mechanism respectively by discriminative predictive task and concurrently maximizing mutual information between paired views sharing redundant information. We qualitatively and quantitatively show that our proposed model learns better features that are more effective for the diverse downstream tasks ranging from classification to semantic segmentation. Our experiments on nine established benchmarks show that the proposed model consistently outperforms the existing state-of-the-art results of self-supervised and transfer learning protocol.
LSTA-Net: Long short-term Spatio-Temporal Aggregation Network for Skeleton-based Action Recognition
Nov 01, 2021
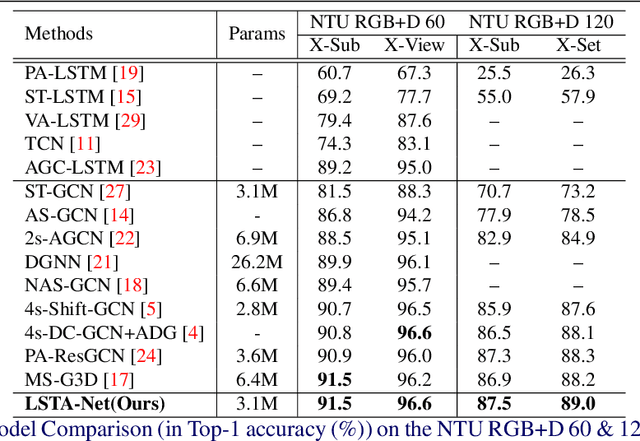


Modelling various spatio-temporal dependencies is the key to recognising human actions in skeleton sequences. Most existing methods excessively relied on the design of traversal rules or graph topologies to draw the dependencies of the dynamic joints, which is inadequate to reflect the relationships of the distant yet important joints. Furthermore, due to the locally adopted operations, the important long-range temporal information is therefore not well explored in existing works. To address this issue, in this work we propose LSTA-Net: a novel Long short-term Spatio-Temporal Aggregation Network, which can effectively capture the long/short-range dependencies in a spatio-temporal manner. We devise our model into a pure factorised architecture which can alternately perform spatial feature aggregation and temporal feature aggregation. To improve the feature aggregation effect, a channel-wise attention mechanism is also designed and employed. Extensive experiments were conducted on three public benchmark datasets, and the results suggest that our approach can capture both long-and-short range dependencies in the space and time domain, yielding higher results than other state-of-the-art methods. Code available at https://github.com/tailin1009/LSTA-Net.