 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mutual Information Maximization on Disentangled Representations for Differential Morph Detection
Dec 02, 2020
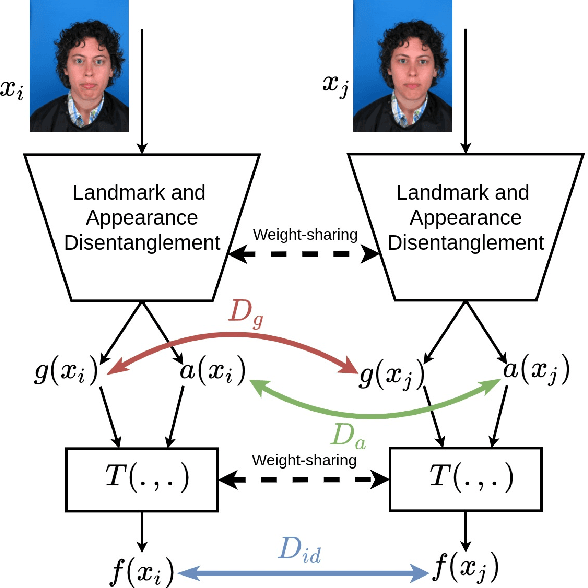
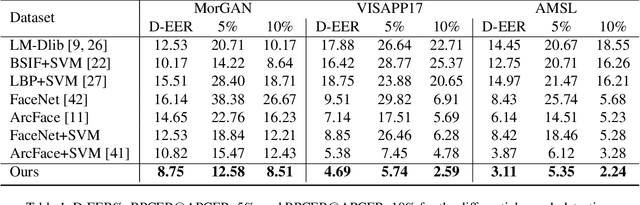
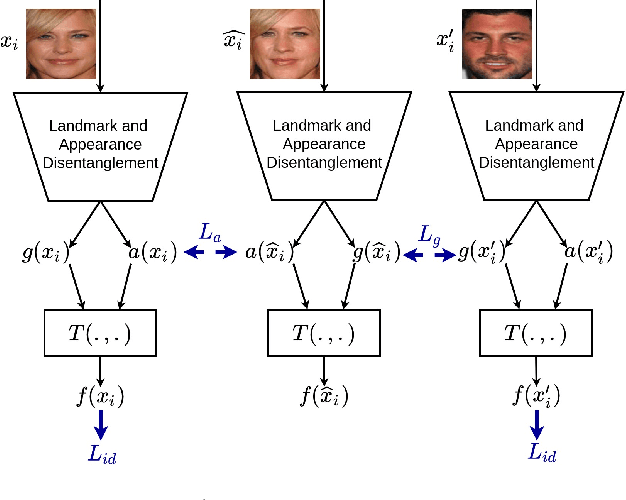
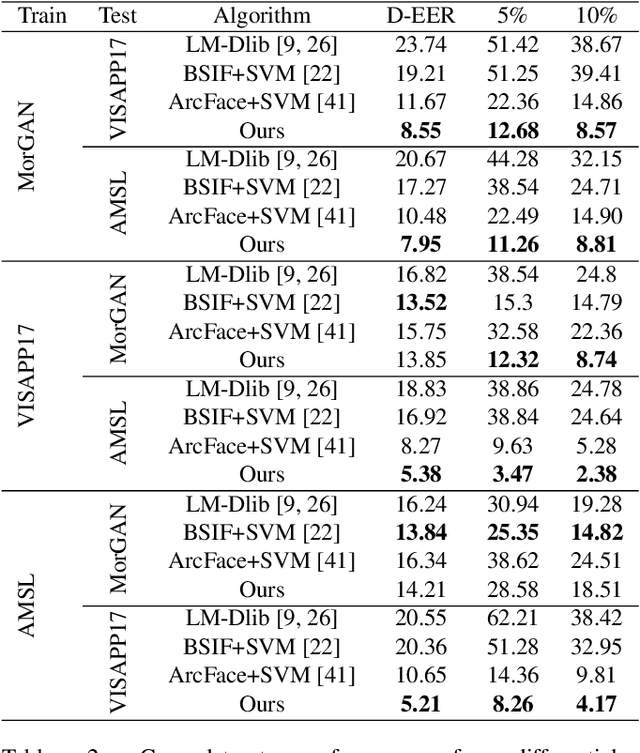
In this paper, we present a novel differential morph detection framework, utilizing landmark and appearance disentanglement. In our framework, the face image is represented in the embedding domain using two disentangled but complementary representations. The network is trained by triplets of face images, in which the intermediate image inherits the landmarks from one image and the appearance from the other image. This initially trained network is further trained for each dataset using contrastive representations. We demonstrate that, by employing appearance and landmark disentanglement, the proposed framework can provide state-of-the-art differential morph detection performance. This functionality is achieved by the using distances in landmark, appearance, and ID domains. The performance of the proposed framework is evaluated using three morph datasets generated with different methodologies.
SOAT: A Scene- and Object-Aware Transformer for Vision-and-Language Navigation
Oct 27, 2021
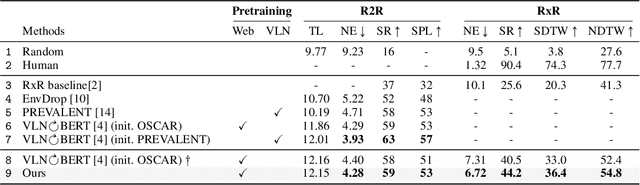
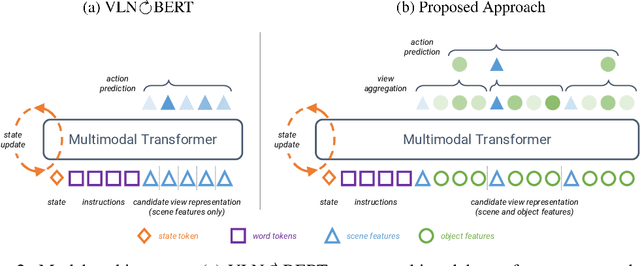
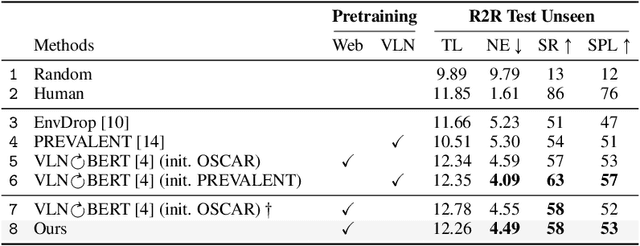
Natural language instructions for visual navigation often use scene descriptions (e.g., "bedroom") and object references (e.g., "green chairs") to provide a breadcrumb trail to a goal location. This work presents a transformer-based vision-and-language navigation (VLN) agent that uses two different visual encoders -- a scene classification network and an object detector -- which produce features that match these two distinct types of visual cues. In our method, scene features contribute high-level contextual information that supports object-level processing. With this design, our model is able to use vision-and-language pretraining (i.e., learning the alignment between images and text from large-scale web data) to substantially improve performance on the Room-to-Room (R2R) and Room-Across-Room (RxR) benchmarks. Specifically, our approach leads to improvements of 1.8% absolute in SPL on R2R and 3.7% absolute in SR on RxR. Our analysis reveals even larger gains for navigation instructions that contain six or more object references, which further suggests that our approach is better able to use object features and align them to references in the instructions.
A Robust Deep Learning-Based Beamforming Design for RIS-assisted Multiuser MISO Communications with Practical Constraints
Nov 12, 2021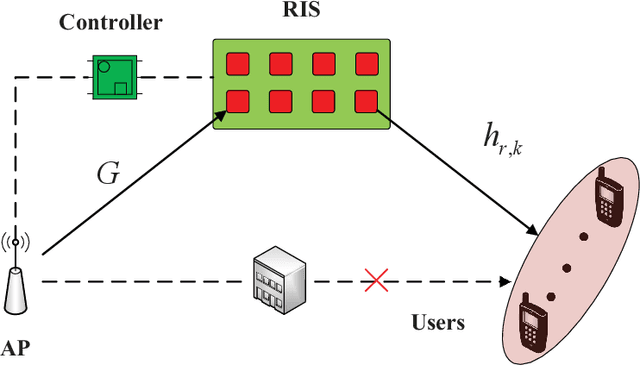
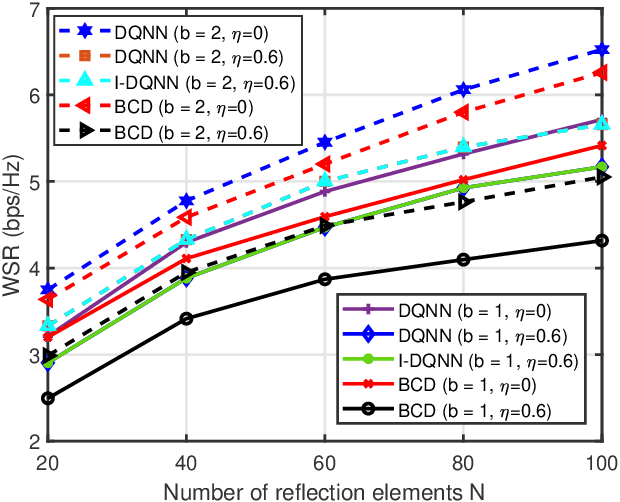
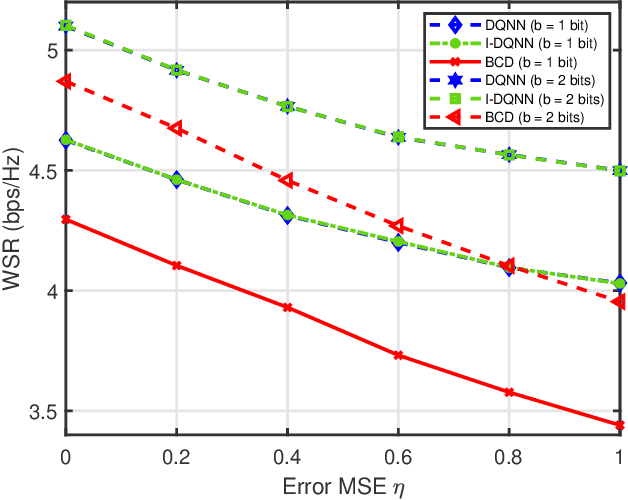
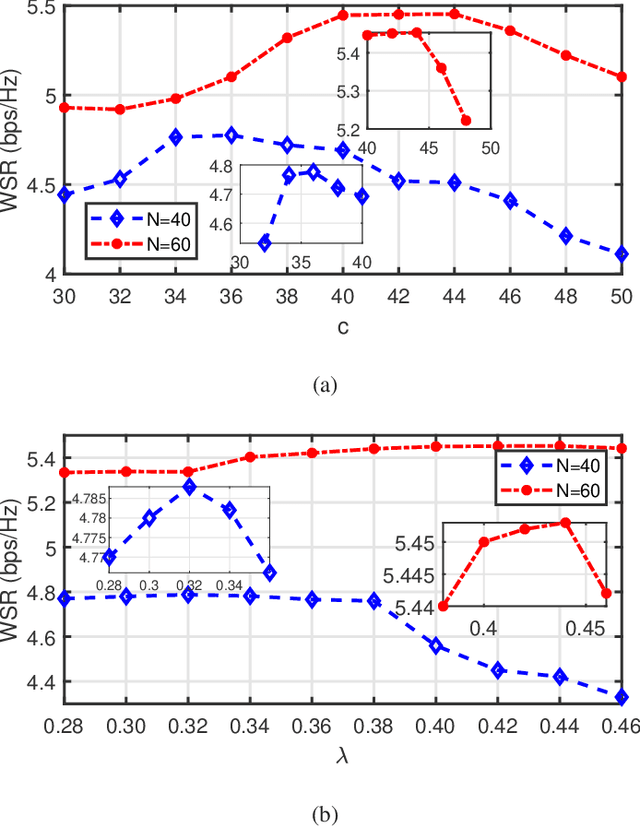
Reconfigurable intelligent surface (RIS) has become a promising technology to improve wireless communication in recent years. It steers the incident signals to create a favorable propagation environment by controlling the reconfigurable passive elements with less hardware cost and lower power consumption. In this paper, we consider a RIS-aided multiuser multiple-input single-output downlink communication system. We aim to maximize the weighted sum-rate of all users by joint optimizing the active beamforming at the access point and the passive beamforming vector of the RIS elements. Unlike most existing works, we consider the more practical situation with the discrete phase shifts and imperfect channel state information (CSI). Specifically, for the situation that the discrete phase shifts and perfect CSI are considered, we first develop a deep quantization neural network (DQNN) to simultaneously design the active and passive beamforming while most reported works design them alternatively. Then, we propose an improved structure (I-DQNN) based on DQNN to simplify the parameters decision process when the control bits of each RIS element are greater than 1 bit. Finally, we extend the two proposed DQNN-based algorithms to the case that the discrete phase shifts and imperfect CSI are considered simultaneously. Our simulation results show that the two DQNN-based algorithms have better performance than traditional algorithms in the perfect CSI case, and are also more robust in the imperfect CSI case.
Safe Online Gain Optimization for Variable Impedance Control
Nov 01, 2021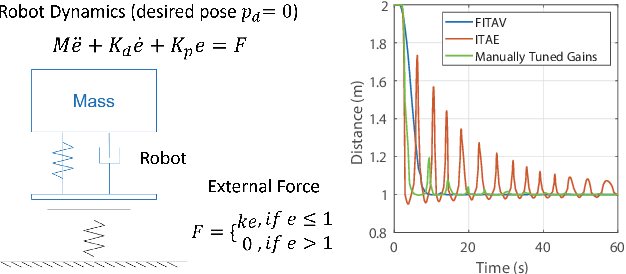
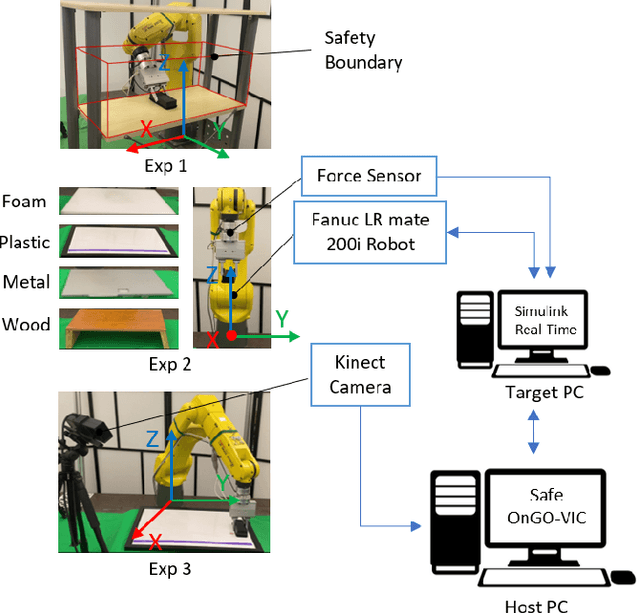
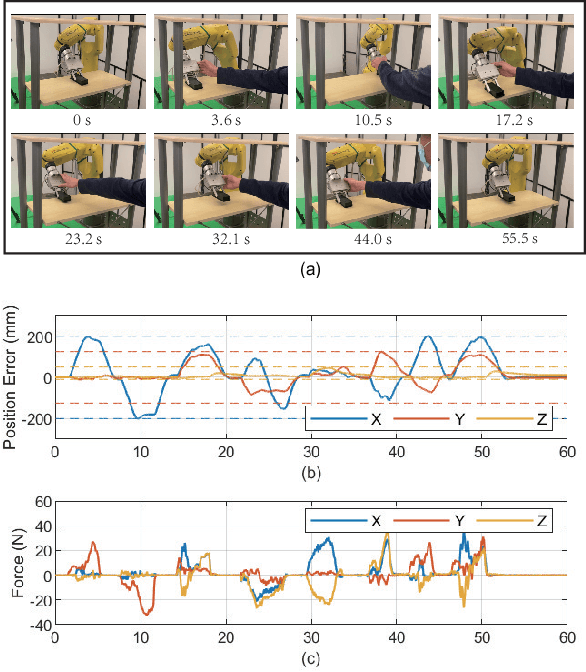
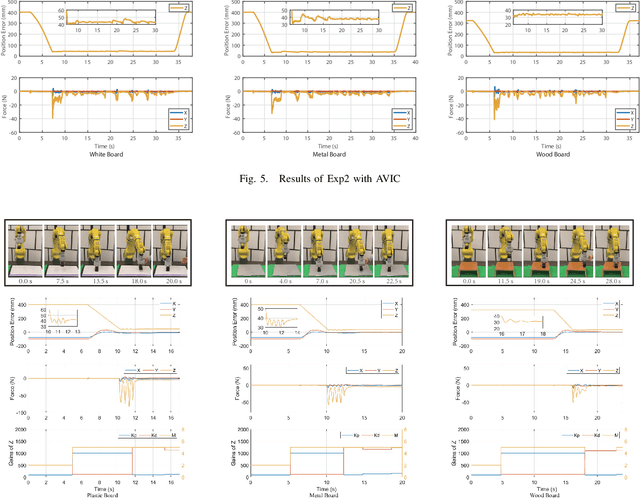
Smooth behaviors are preferable for many contact-rich manipulation tasks. Impedance control arises as an effective way to regulate robot movements by mimicking a mass-spring-damping system. Consequently, the robot behavior can be determined by the impedance gains. However, tuning the impedance gains for different tasks is tricky, especially for unstructured environments. Moreover, online adapting the optimal gains to meet the time-varying performance index is even more challenging. In this paper, we present Safe Online Gain Optimization for Variable Impedance Control (Safe OnGO-VIC). By reformulating the dynamics of impedance control as a control-affine system, in which the impedance gains are the inputs, we provide a novel perspective to understand variable impedance control. Additionally, we innovatively formulate an optimization problem with online collected force information to obtain the optimal impedance gains in real-time. Safety constraints are also embedded in the proposed framework to avoid unwanted collisions. We experimentally validated the proposed algorithm on three manipulation tasks. Comparison results with a constant gain baseline and an adaptive control method prove that the proposed algorithm is effective and generalizable to different scenarios.
Hyper Meta-Path Contrastive Learning for Multi-Behavior Recommendation
Sep 07, 2021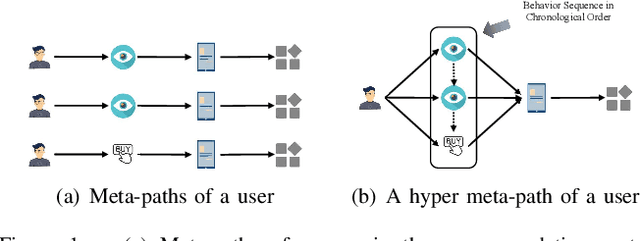
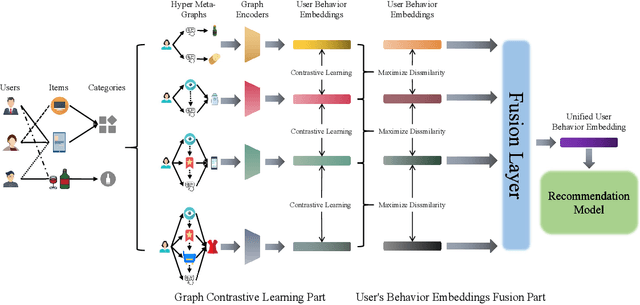
User purchasing prediction with multi-behavior information remains a challenging problem for current recommendation systems. Various methods have been proposed to address it via leveraging the advantages of graph neural networks (GNNs) or multi-task learning. However, most existing works do not take the complex dependencies among different behaviors of users into consideration. They utilize simple and fixed schemes, like neighborhood information aggregation or mathematical calculation of vectors, to fuse the embeddings of different user behaviors to obtain a unified embedding to represent a user's behavioral patterns which will be used in downstream recommendation tasks. To tackle the challenge, in this paper, we first propose the concept of hyper meta-path to construct hyper meta-paths or hyper meta-graphs to explicitly illustrate the dependencies among different behaviors of a user. How to obtain a unified embedding for a user from hyper meta-paths and avoid the previously mentioned limitations simultaneously is critical. Thanks to the recent success of graph contrastive learning, we leverage it to learn embeddings of user behavior patterns adaptively instead of assigning a fixed scheme to understand the dependencies among different behaviors. A new graph contrastive learning based framework is proposed by coupling with hyper meta-paths, namely HMG-CR, which consistently and significantly outperforms all baselines in extensive comparison experiments.
RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching
Sep 15, 2021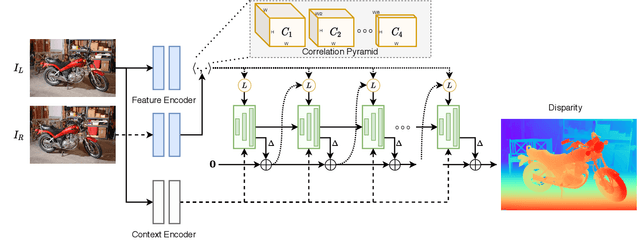
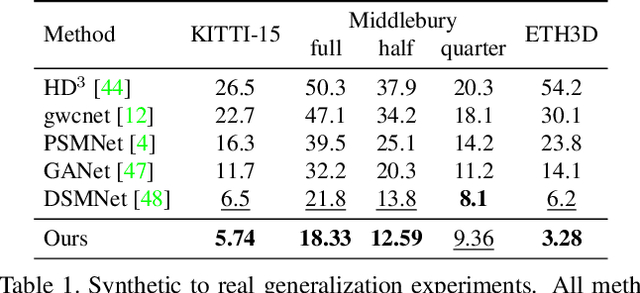
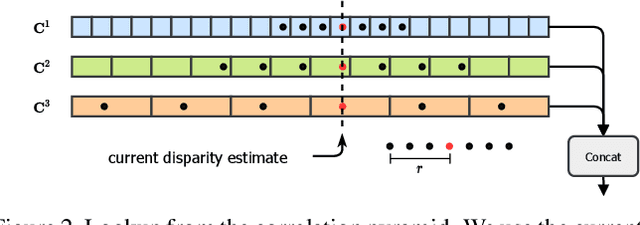
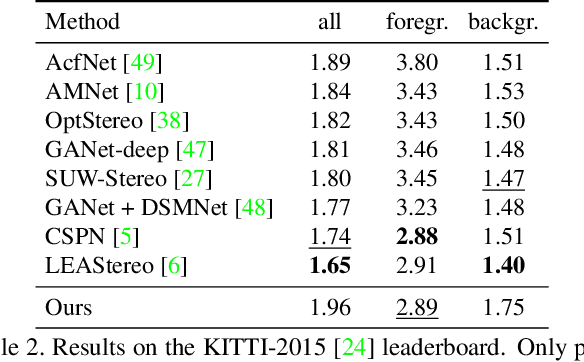
We introduce RAFT-Stereo, a new deep architecture for rectified stereo based on the optical flow network RAFT. We introduce multi-level convolutional GRUs, which more efficiently propagate information across the image. A modified version of RAFT-Stereo can perform accurate real-time inference. RAFT-stereo ranks first on the Middlebury leaderboard, outperforming the next best method on 1px error by 29% and outperforms all published work on the ETH3D two-view stereo benchmark. Code is available at https://github.com/princeton-vl/RAFT-Stereo.
LayoutReader: Pre-training of Text and Layout for Reading Order Detection
Aug 26, 2021
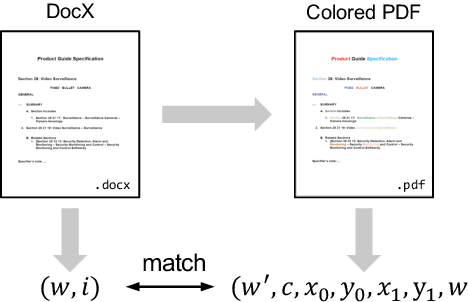

Reading order detection is the cornerstone to understanding visually-rich documents (e.g., receipts and forms). Unfortunately, no existing work took advantage of advanced deep learning models because it is too laborious to annotate a large enough dataset. We observe that the reading order of WORD documents is embedded in their XML metadata; meanwhile, it is easy to convert WORD documents to PDFs or images. Therefore, in an automated manner, we construct ReadingBank, a benchmark dataset that contains reading order, text, and layout information for 500,000 document images covering a wide spectrum of document types. This first-ever large-scale dataset unleashes the power of deep neural networks for reading order detection. Specifically, our proposed LayoutReader captures the text and layout information for reading order prediction using the seq2seq model. It performs almost perfectly in reading order detection and significantly improves both open-source and commercial OCR engines in ordering text lines in their results in our experiments. We will release the dataset and model at \url{https://aka.ms/readingbank}.
Finite-Time Error Bounds for Distributed Linear Stochastic Approximation
Nov 24, 2021This paper considers a novel multi-agent linear stochastic approximation algorithm driven by Markovian noise and general consensus-type interaction, in which each agent evolves according to its local stochastic approximation process which depends on the information from its neighbors. The interconnection structure among the agents is described by a time-varying directed graph. While the convergence of consensus-based stochastic approximation algorithms when the interconnection among the agents is described by doubly stochastic matrices (at least in expectation) has been studied, less is known about the case when the interconnection matrix is simply stochastic. For any uniformly strongly connected graph sequences whose associated interaction matrices are stochastic, the paper derives finite-time bounds on the mean-square error, defined as the deviation of the output of the algorithm from the unique equilibrium point of the associated ordinary differential equation. For the case of interconnection matrices being stochastic, the equilibrium point can be any unspecified convex combination of the local equilibria of all the agents in the absence of communication. Both the cases with constant and time-varying step-sizes are considered. In the case when the convex combination is required to be a straight average and interaction between any pair of neighboring agents may be uni-directional, so that doubly stochastic matrices cannot be implemented in a distributed manner, the paper proposes a push-sum-type distributed stochastic approximation algorithm and provides its finite-time bound for the time-varying step-size case by leveraging the analysis for the consensus-type algorithm with stochastic matrices and developing novel properties of the push-sum algorithm.
Towards Robust Monocular Visual Odometry for Flying Robots on Planetary Missions
Sep 12, 2021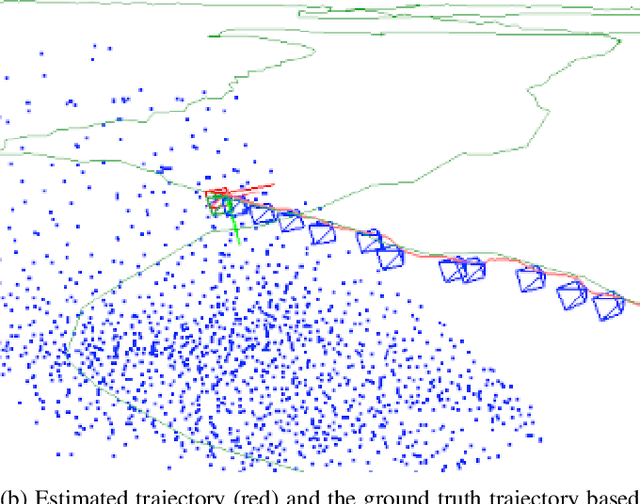
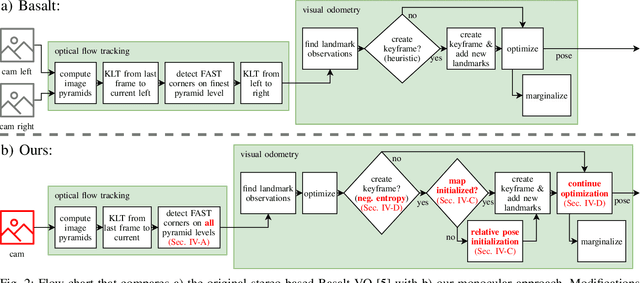
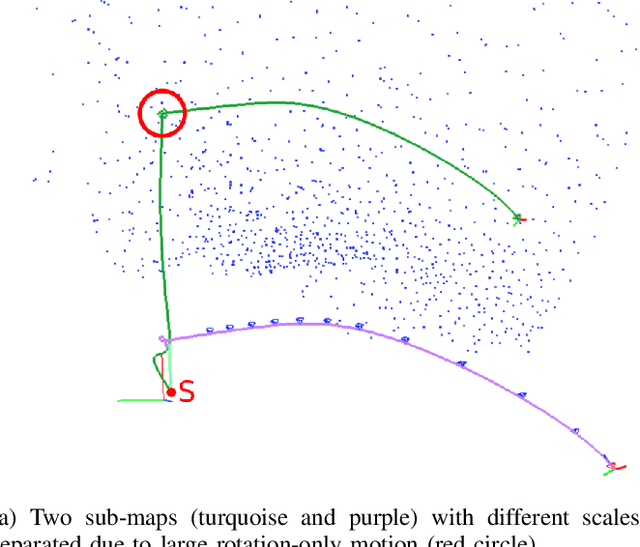
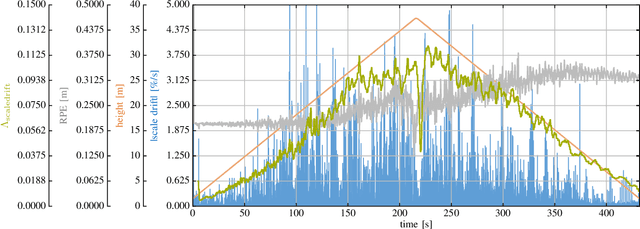
In the future, extraterrestrial expeditions will not only be conducted by rovers but also by flying robots. The technical demonstration drone Ingenuity, that just landed on Mars, will mark the beginning of a new era of exploration unhindered by terrain traversability. Robust self-localization is crucial for that. Cameras that are lightweight, cheap and information-rich sensors are already used to estimate the ego-motion of vehicles. However, methods proven to work in man-made environments cannot simply be deployed on other planets. The highly repetitive textures present in the wastelands of Mars pose a huge challenge to descriptor matching based approaches. In this paper, we present an advanced robust monocular odometry algorithm that uses efficient optical flow tracking to obtain feature correspondences between images and a refined keyframe selection criterion. In contrast to most other approaches, our framework can also handle rotation-only motions that are particularly challenging for monocular odometry systems. Furthermore, we present a novel approach to estimate the current risk of scale drift based on a principal component analysis of the relative translation information matrix. This way we obtain an implicit measure of uncertainty. We evaluate the validity of our approach on all sequences of a challenging real-world dataset captured in a Mars-like environment and show that it outperforms state-of-the-art approaches.
Task Affinity with Maximum Bipartite Matching in Few-Shot Learning
Oct 05, 2021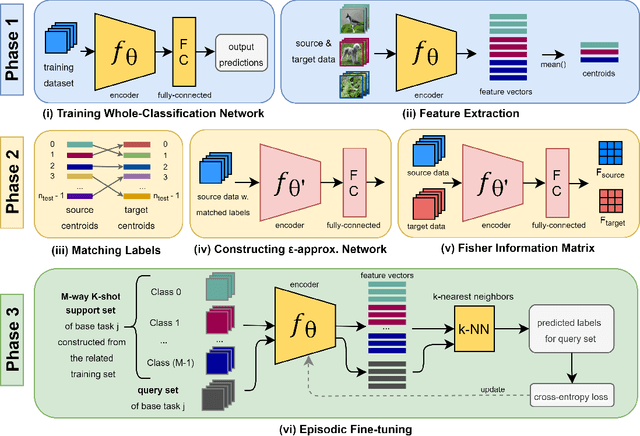
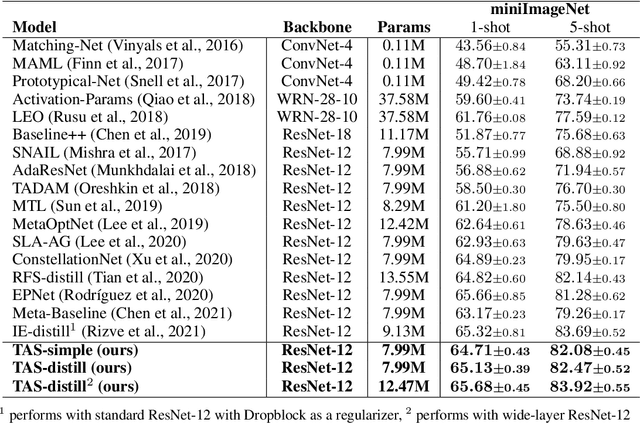
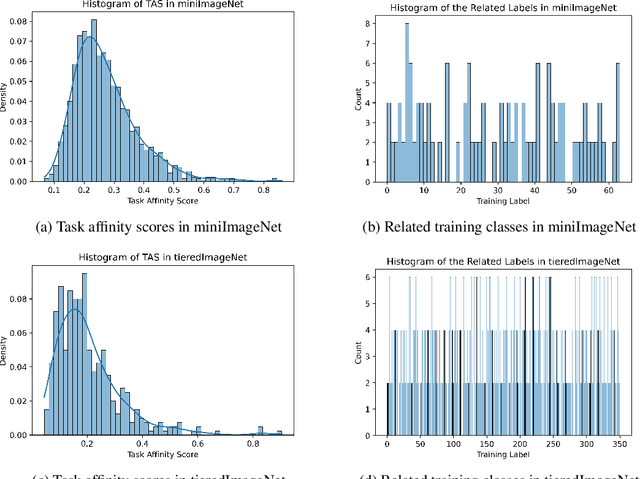
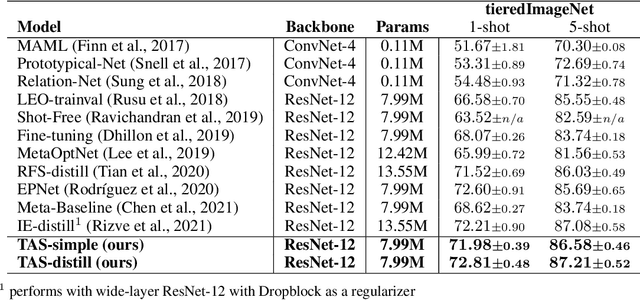
We propose an asymmetric affinity score for representing the complexity of utilizing the knowledge of one task for learning another one. Our method is based on the maximum bipartite matching algorithm and utilizes the Fisher Information matrix. We provide theoretical analyses demonstrating that the proposed score is mathematically well-defined, and subsequently use the affinity score to propose a novel algorithm for the few-shot learning problem. In particular, using this score, we find relevant training data labels to the test data and leverage the discovered relevant data for episodically fine-tuning a few-shot model. Results on various few-shot benchmark datasets demonstrate the efficacy of the proposed approach by improving the classification accuracy over the state-of-the-art methods even when using smaller models.