 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evaluating the effectiveness of Phishing Reports on Twitter
Nov 13, 2021
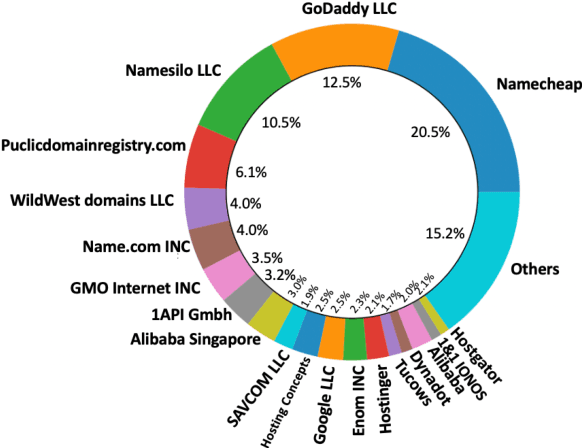
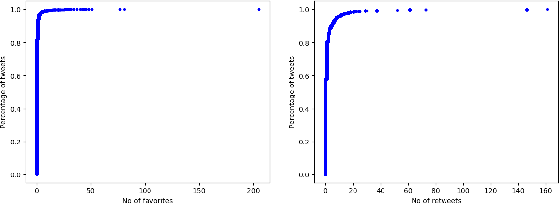
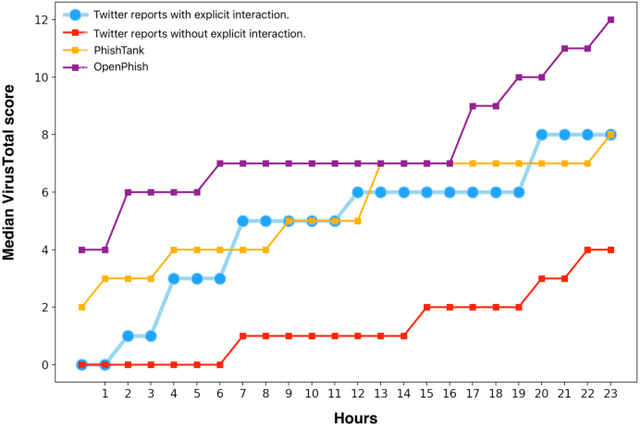
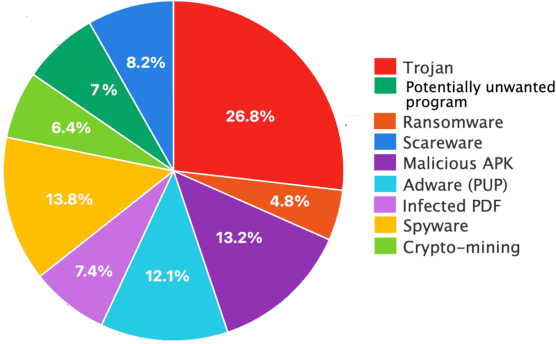
Phishing attacks are an increasingly potent web-based threat, with nearly 1.5 million websites created on a monthly basis. In this work, we present the first study towards identifying such attacks through phishing reports shared by users on Twitter. We evaluated over 16.4k such reports posted by 701 Twitter accounts between June to August 2021, which contained 11.1k unique URLs, and analyzed their effectiveness using various quantitative and qualitative measures. Our findings indicate that not only do these users share a high volume of legitimate phishing URLs, but these reports contain more information regarding the phishing websites (which can expedite the process of identifying and removing these threats), when compared to two popular open-source phishing feeds: PhishTank and OpenPhish. We also notice that the reported websites had very little overlap with the URLs existing in the other feeds, and also remained active for longer periods of time. But despite having these attributes, we found that these reports have very low interaction from other Twitter users, especially from the domains and organizations targeted by the reported URLs. Moreover, nearly 31% of these URLs were still active even after a week of them being reported, with 27% of them being detected by very few anti-phishing tools, suggesting that a large majority of these reports remain undiscovered, despite the majority of the follower base of these accounts being security focused users. Thus, this work highlights the effectiveness of the reports, and the benefits of using them as an open source knowledge base for identifying new phishing websites.
Cross Attentional Audio-Visual Fusion for Dimensional Emotion Recognition
Nov 09, 2021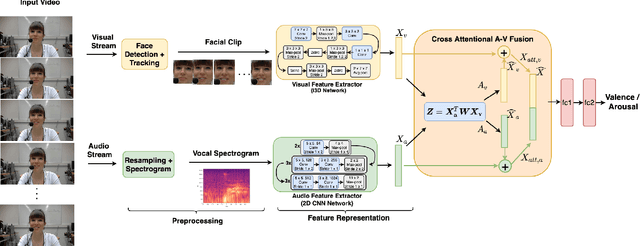
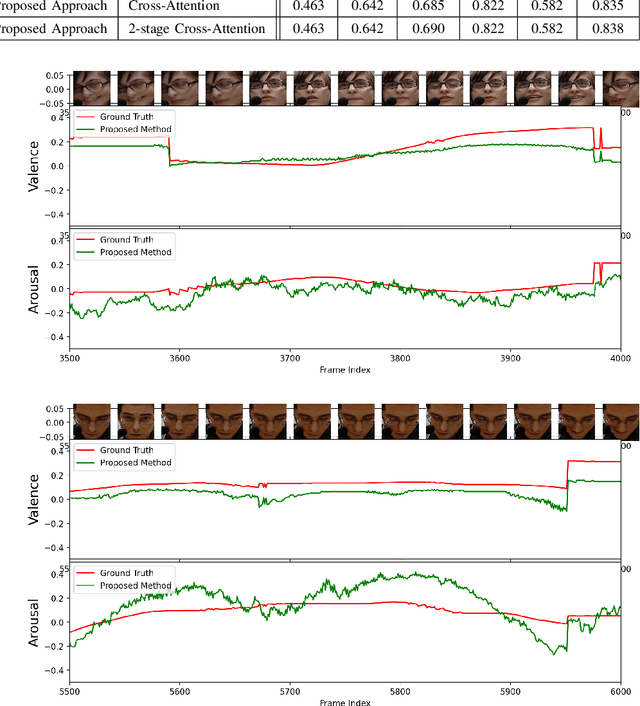
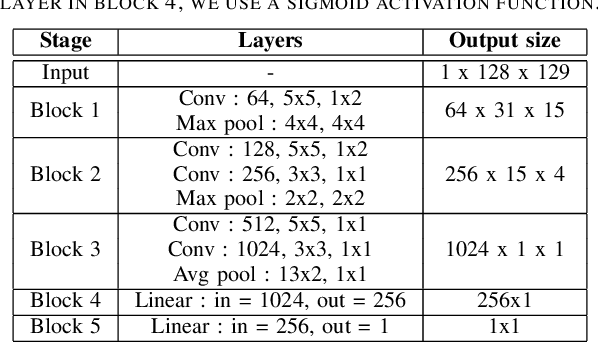
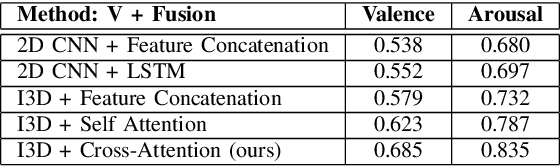
Multimodal analysis has recently drawn much interest in affective computing, since it can improve the overall accuracy of emotion recognition over isolated uni-modal approaches. The most effective techniques for multimodal emotion recognition efficiently leverage diverse and complimentary sources of information, such as facial, vocal, and physiological modalities, to provide comprehensive feature representations. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos, where complex spatiotemporal relationships may be captured. Most of the existing fusion techniques rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complimentary nature of audio-visual (A-V) modalities. We introduce a cross-attentional fusion approach to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. Our new cross-attentional A-V fusion model efficiently leverages the inter-modal relationships. In particular, it computes cross-attention weights to focus on the more contributive features across individual modalities, and thereby combine contributive feature representations, which are then fed to fully connected layers for the prediction of valence and arousal. The effectiveness of the proposed approach is validated experimentally on videos from the RECOLA and Fatigue (private) data-sets. Results indicate that our cross-attentional A-V fusion model is a cost-effective approach that outperforms state-of-the-art fusion approaches. Code is available: \url{https://github.com/praveena2j/Cross-Attentional-AV-Fusion}
Signal-carrying speckle in Optical Coherence Tomography: a methodological review on biomedical applications
Aug 30, 2021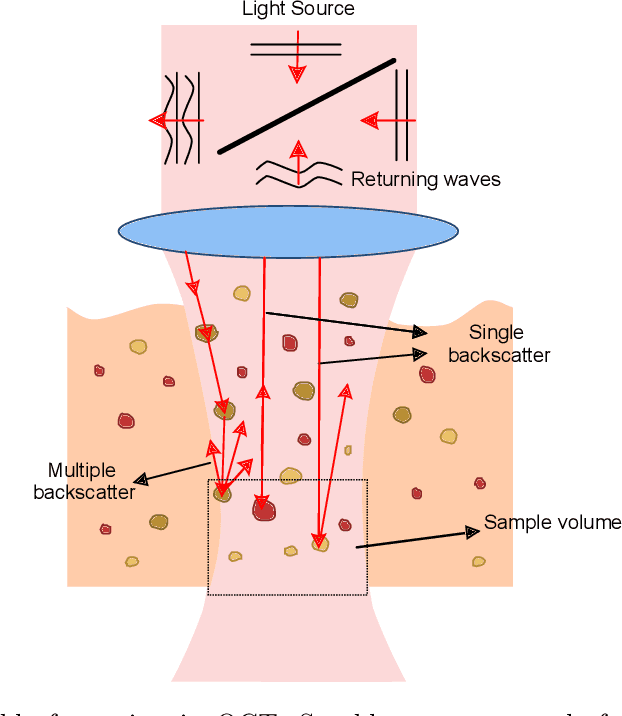
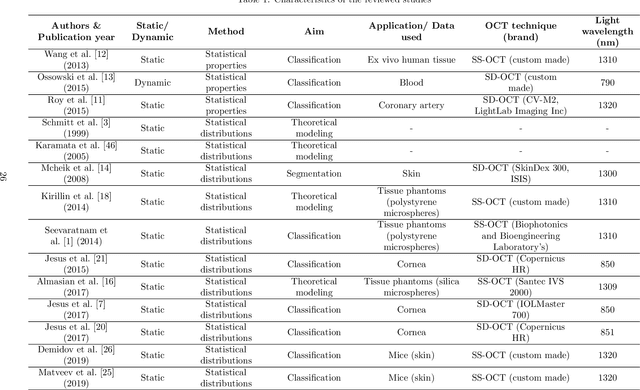
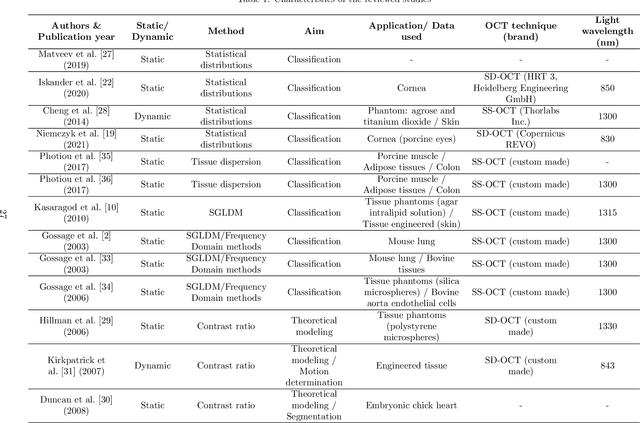
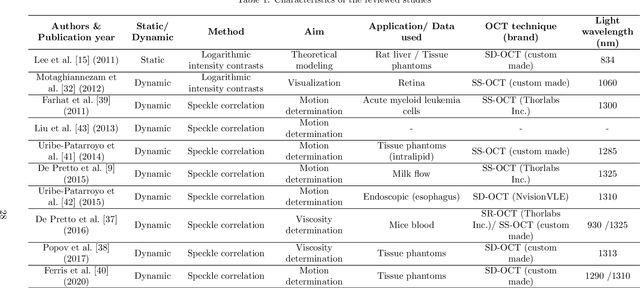
Significance: Speckle has historically been considered a source of noise in coherent light imaging. However, a number of works in optical coherence tomography (OCT) imaging have shown that speckle patterns may contain relevant information regarding sub-resolution and structural properties of the tissues from which it is originated. Aim: The objective of this work is to provide a comprehensive overview of the methods developed for retrieving speckle information in biomedical OCT applications. Approach: PubMed and Scopus databases were used to perform a systematic review on studies published until April 2021. From 134-screened studies, 37 were eligible for this review. Results: The studies have been clustered according to the nature of their analysis, namely static or dynamic, and all features were described and analysed. The results show that features retrieved from speckle can be used successfully in different applications, such as classification and segmentation. However, the results also show that speckle analysis is highly application-dependant, and the best approach varies between applications. Conclusions: Several of the reviewed analysis were only performed in a theoretical context or using phantoms, showing that signal-carrying speckle analysis in OCT imaging is still in its early stage, and further work is needed to validate its applicability and reproducibility in a clinical context.
MMIU: Dataset for Visual Intent Understanding in Multimodal Assistants
Oct 31, 2021


In multimodal assistant, where vision is also one of the input modalities, the identification of user intent becomes a challenging task as visual input can influence the outcome. Current digital assistants take spoken input and try to determine the user intent from conversational or device context. So, a dataset, which includes visual input (i.e. images or videos for the corresponding questions targeted for multimodal assistant use cases, is not readily available. The research in visual question answering (VQA) and visual question generation (VQG) is a great step forward. However, they do not capture questions that a visually-abled person would ask multimodal assistants. Moreover, many times questions do not seek information from external knowledge. In this paper, we provide a new dataset, MMIU (MultiModal Intent Understanding), that contains questions and corresponding intents provided by human annotators while looking at images. We, then, use this dataset for intent classification task in multimodal digital assistant. We also experiment with various approaches for combining vision and language features including the use of multimodal transformer for classification of image-question pairs into 14 intents. We provide the benchmark results and discuss the role of visual and text features for the intent classification task on our dataset.
Local Explanations for Clinical Search Engine results
Oct 19, 2021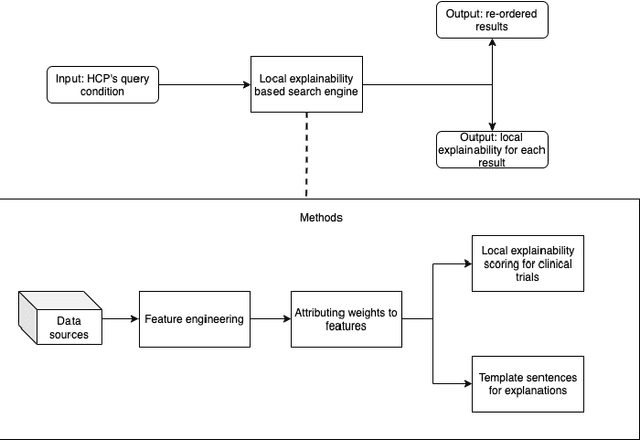
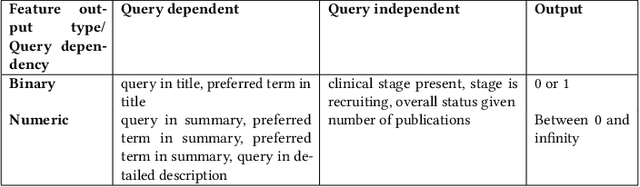
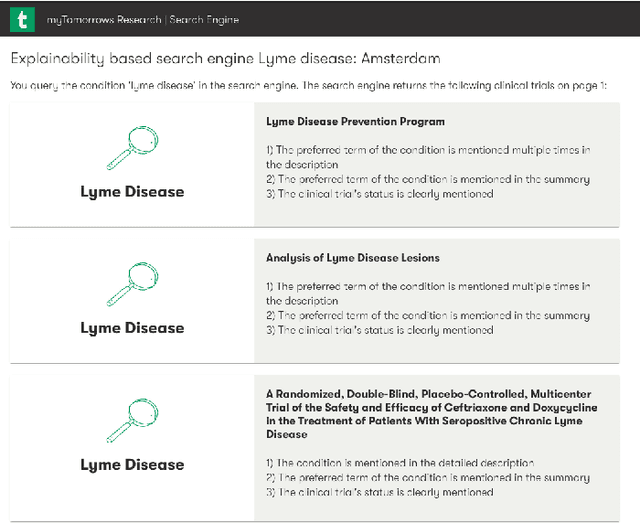
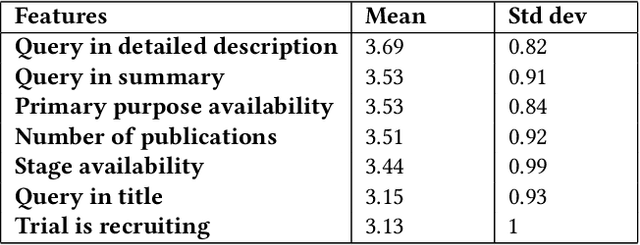
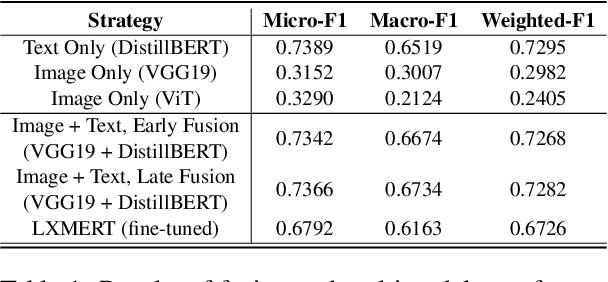
Health care professionals rely on treatment search engines to efficiently find adequate clinical trials and early access programs for their patients. However, doctors lose trust in the system if its underlying processes are unclear and unexplained. In this paper, a model-agnostic explainable method is developed to provide users with further information regarding the reasons why a clinical trial is retrieved in response to a query. To accomplish this, the engine generates features from clinical trials using by using a knowledge graph, clinical trial data and additional medical resources. and a crowd-sourcing methodology is used to determine their importance. Grounded on the proposed methodology, the rationale behind retrieving the clinical trials is explained in layman's terms so that healthcare processionals can effortlessly perceive them. In addition, we compute an explainability score for each of the retrieved items, according to which the items can be ranked. The experiments validated by medical professionals suggest that the proposed methodology induces trust in targeted as well as in non-targeted users, and provide them with reliable explanations and ranking of retrieved items.
Neural networks based post-equalization in coherent optical systems: regression versus classification
Sep 28, 2021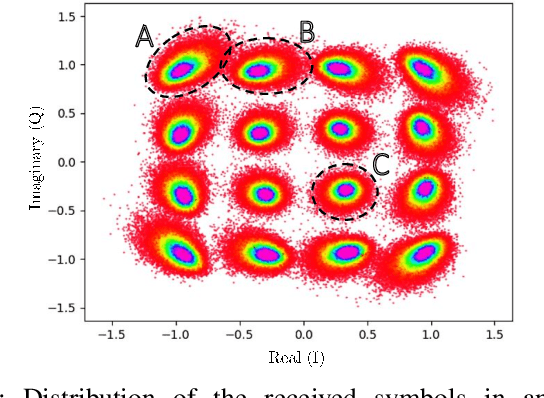
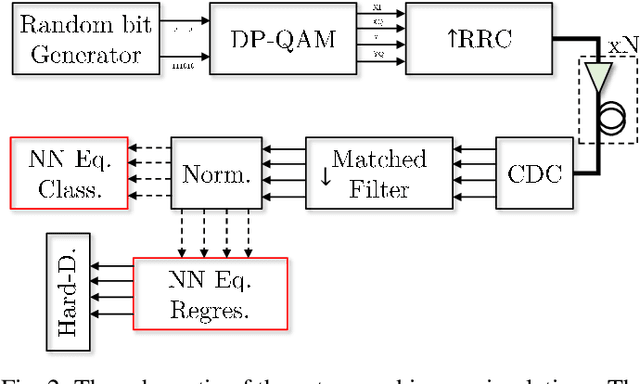
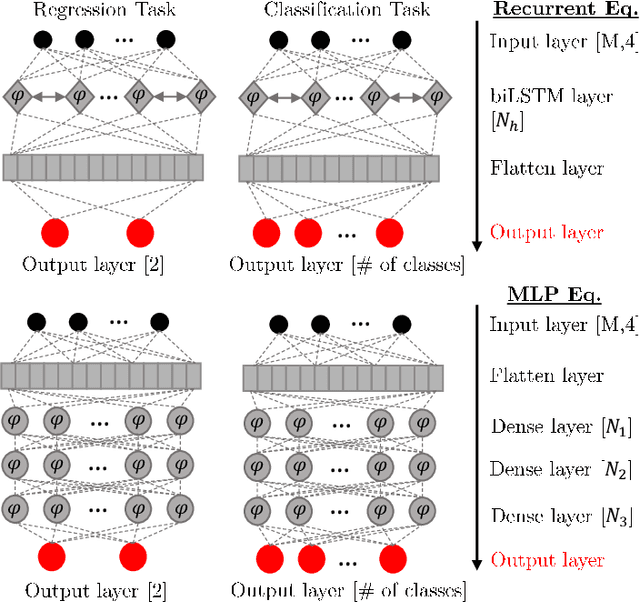
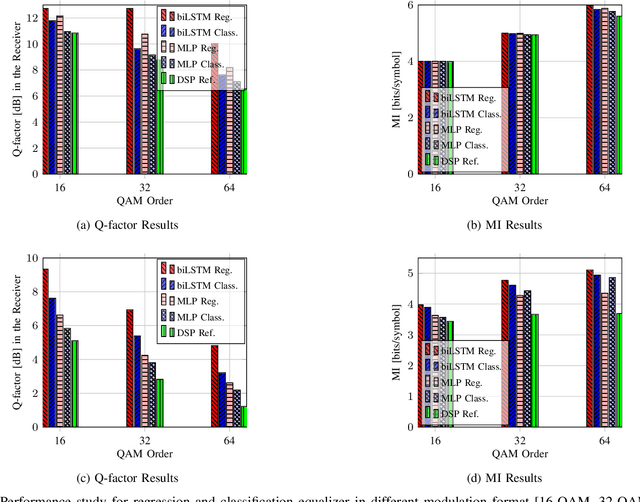
In this paper, we address the question of which type of predictive modeling, classification, or regression, fits better the task of equalization using neural networks (NN) based post-processing in coherent optical communication, where the transmission channel is nonlinear and dispersive. For the first time, we presented some possible drawbacks in using each type of predictive task in a machine learning context for the nonlinear channel equalization problem. We studied two types of equalizers based on the feed-forward and recurrent neural networks over several different transmission scenarios, in linear and nonlinear regimes of the optical channel. We observed in all those cases that the training based on regression results in faster convergence and finally a superior performance, in terms of Q-factor and achievable information rate.
DeepPanoContext: Panoramic 3D Scene Understanding with Holistic Scene Context Graph and Relation-based Optimization
Aug 24, 2021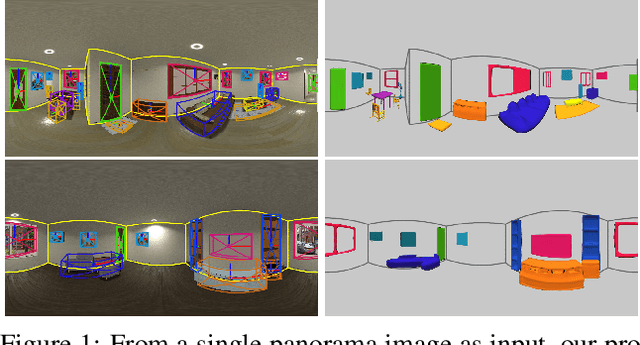

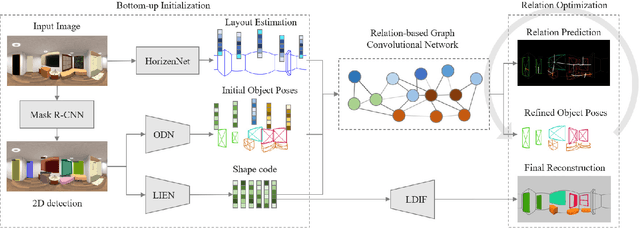

Panorama images have a much larger field-of-view thus naturally encode enriched scene context information compared to standard perspective images, which however is not well exploited in the previous scene understanding methods. In this paper, we propose a novel method for panoramic 3D scene understanding which recovers the 3D room layout and the shape, pose, position, and semantic category for each object from a single full-view panorama image. In order to fully utilize the rich context information, we design a novel graph neural network based context model to predict the relationship among objects and room layout, and a differentiable relationship-based optimization module to optimize object arrangement with well-designed objective functions on-the-fly. Realizing the existing data are either with incomplete ground truth or overly-simplified scene, we present a new synthetic dataset with good diversity in room layout and furniture placement, and realistic image quality for total panoramic 3D scene understanding. Experiments demonstrate that our method outperforms existing methods on panoramic scene understanding in terms of both geometry accuracy and object arrangement. Code is available at https://chengzhag.github.io/publication/dpc.
PSGR: Pixel-wise Sparse Graph Reasoning for COVID-19 Pneumonia Segmentation in CT Images
Aug 09, 2021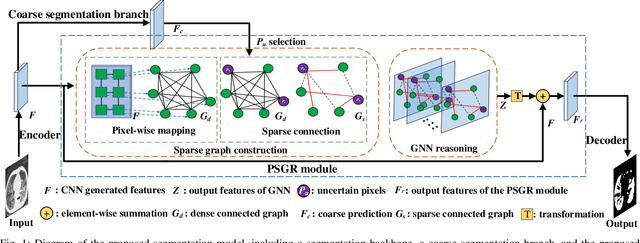
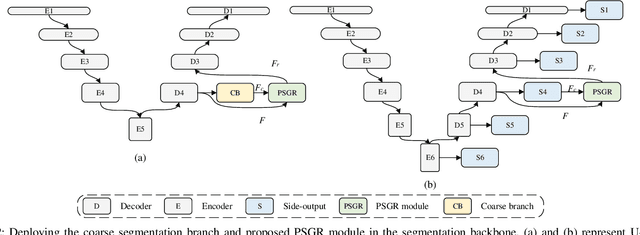

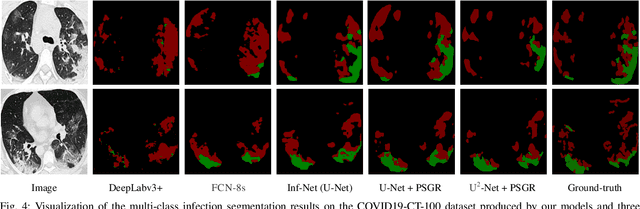
Automated and accurate segmentation of the infected regions in computed tomography (CT) images is critical for the prediction of the pathological stage and treatment response of COVID-19. Several deep convolutional neural networks (DCNNs) have been designed for this task, whose performance, however, tends to be suppressed by their limited local receptive fields and insufficient global reasoning ability. In this paper, we propose a pixel-wise sparse graph reasoning (PSGR) module and insert it into a segmentation network to enhance the modeling of long-range dependencies for COVID-19 infected region segmentation in CT images. In the PSGR module, a graph is first constructed by projecting each pixel on a node based on the features produced by the segmentation backbone, and then converted into a sparsely-connected graph by keeping only K strongest connections to each uncertain pixel. The long-range information reasoning is performed on the sparsely-connected graph to generate enhanced features. The advantages of this module are two-fold: (1) the pixel-wise mapping strategy not only avoids imprecise pixel-to-node projections but also preserves the inherent information of each pixel for global reasoning; and (2) the sparsely-connected graph construction results in effective information retrieval and reduction of the noise propagation. The proposed solution has been evaluated against four widely-used segmentation models on three public datasets. The results show that the segmentation model equipped with our PSGR module can effectively segment COVID-19 infected regions in CT images, outperforming all other competing models.
Contrastive Learning for Cold-Start Recommendation
Jul 15, 2021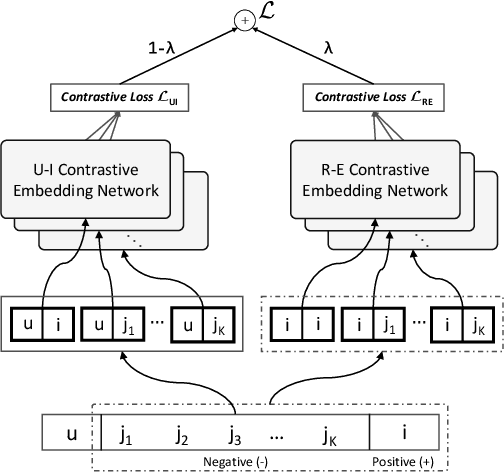
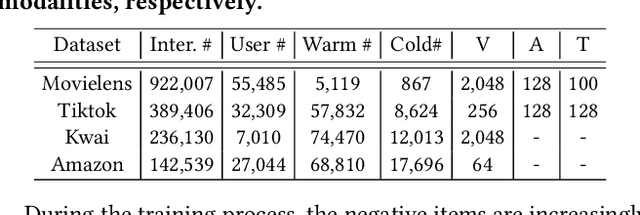
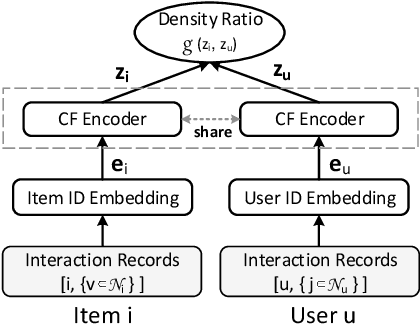
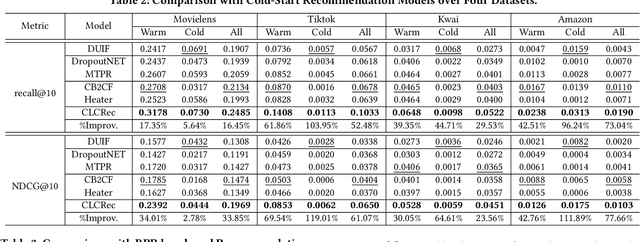
Recommending cold-start items is a long-standing and fundamental challenge in recommender systems. Without any historical interaction on cold-start items, CF scheme fails to use collaborative signals to infer user preference on these items. To solve this problem, extensive studies have been conducted to incorporate side information into the CF scheme. Specifically, they employ modern neural network techniques (e.g., dropout, consistency constraint) to discover and exploit the coalition effect of content features and collaborative representations. However, we argue that these works less explore the mutual dependencies between content features and collaborative representations and lack sufficient theoretical supports, thus resulting in unsatisfactory performance. In this work, we reformulate the cold-start item representation learning from an information-theoretic standpoint. It aims to maximize the mutual dependencies between item content and collaborative signals. Specifically, the representation learning is theoretically lower-bounded by the integration of two terms: mutual information between collaborative embeddings of users and items, and mutual information between collaborative embeddings and feature representations of items. To model such a learning process, we devise a new objective function founded upon contrastive learning and develop a simple yet effective Contrastive Learning-based Cold-start Recommendation framework(CLCRec). In particular, CLCRec consists of three components: contrastive pair organization, contrastive embedding, and contrastive optimization modules. It allows us to preserve collaborative signals in the content representations for both warm and cold-start items. Through extensive experiments on four publicly accessible datasets, we observe that CLCRec achieves significant improvements over state-of-the-art approaches in both warm- and cold-start scenarios.
Differential Privacy in Personalized Pricing with Nonparametric Demand Models
Sep 10, 2021In the recent decades, the advance of information technology and abundant personal data facilitate the application of algorithmic personalized pricing. However, this leads to the growing concern of potential violation of privacy due to adversarial attack. To address the privacy issue, this paper studies a dynamic personalized pricing problem with \textit{unknown} nonparametric demand models under data privacy protection. Two concepts of data privacy, which have been widely applied in practices, are introduced: \textit{central differential privacy (CDP)} and \textit{local differential privacy (LDP)}, which is proved to be stronger than CDP in many cases. We develop two algorithms which make pricing decisions and learn the unknown demand on the fly, while satisfying the CDP and LDP gurantees respectively. In particular, for the algorithm with CDP guarantee, the regret is proved to be at most $\tilde O(T^{(d+2)/(d+4)}+\varepsilon^{-1}T^{d/(d+4)})$. Here, the parameter $T$ denotes the length of the time horizon, $d$ is the dimension of the personalized information vector, and the key parameter $\varepsilon>0$ measures the strength of privacy (smaller $\varepsilon$ indicates a stronger privacy protection). On the other hand, for the algorithm with LDP guarantee, its regret is proved to be at most $\tilde O(\varepsilon^{-2/(d+2)}T^{(d+1)/(d+2)})$, which is near-optimal as we prove a lower bound of $\Omega(\varepsilon^{-2/(d+2)}T^{(d+1)/(d+2)})$ for any algorithm with LDP guarantee.