 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decentralized Multi-Agent Reinforcement Learning: An Off-Policy Method
Oct 31, 2021
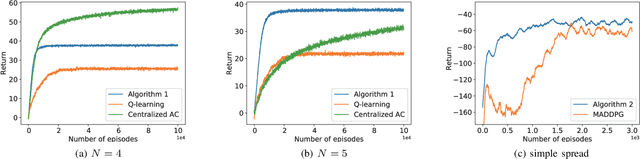
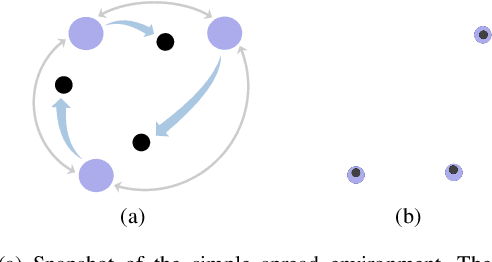
We discuss the problem of decentralized multi-agent reinforcement learning (MARL) in this work. In our setting, the global state, action, and reward are assumed to be fully observable, while the local policy is protected as privacy by each agent, and thus cannot be shared with others. There is a communication graph, among which the agents can exchange information with their neighbors. The agents make individual decisions and cooperate to reach a higher accumulated reward. Towards this end, we first propose a decentralized actor-critic (AC) setting. Then, the policy evaluation and policy improvement algorithms are designed for discrete and continuous state-action-space Markov Decision Process (MDP) respectively. Furthermore, convergence analysis is given under the discrete-space case, which guarantees that the policy will be reinforced by alternating between the processes of policy evaluation and policy improvement. In order to validate the effectiveness of algorithms, we design experiments and compare them with previous algorithms, e.g., Q-learning \cite{watkins1992q} and MADDPG \cite{lowe2017multi}. The results show that our algorithms perform better from the aspects of both learning speed and final performance. Moreover, the algorithms can be executed in an off-policy manner, which greatly improves the data efficiency compared with on-policy algorithms.
Sequential Voting with Relational Box Fields for Active Object Detection
Nov 21, 2021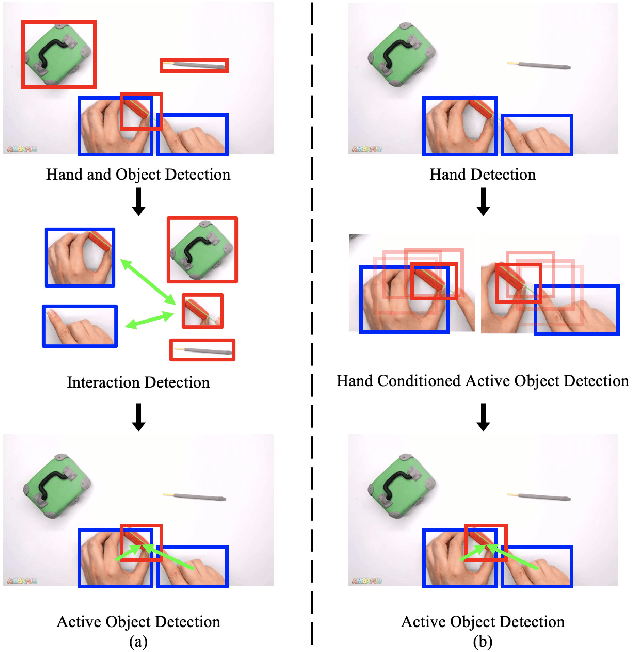

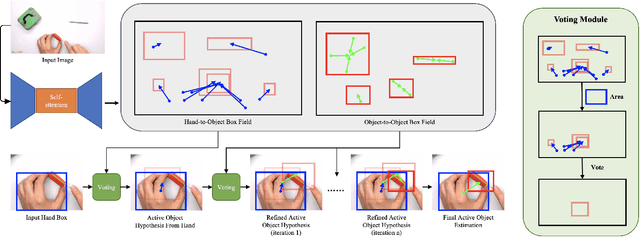

A key component of understanding hand-object interactions is the ability to identify the active object -- the object that is being manipulated by the human hand. In order to accurately localize the active object, any method must reason using information encoded by each image pixel, such as whether it belongs to the hand, the object, or the background. To leverage each pixel as evidence to determine the bounding box of the active object, we propose a pixel-wise voting function. Our pixel-wise voting function takes an initial bounding box as input and produces an improved bounding box of the active object as output. The voting function is designed so that each pixel inside of the input bounding box votes for an improved bounding box, and the box with the majority vote is selected as the output. We call the collection of bounding boxes generated inside of the voting function, the Relational Box Field, as it characterizes a field of bounding boxes defined in relationship to the current bounding box. While our voting function is able to improve the bounding box of the active object, one round of voting is typically not enough to accurately localize the active object. Therefore, we repeatedly apply the voting function to sequentially improve the location of the bounding box. However, since it is known that repeatedly applying a one-step predictor (i.e., auto-regressive processing with our voting function) can cause a data distribution shift, we mitigate this issue using reinforcement learning (RL). We adopt standard RL to learn the voting function parameters and show that it provides a meaningful improvement over a standard supervised learning approach. We perform experiments on two large-scale datasets: 100DOH and MECCANO, improving AP50 performance by 8% and 30%, respectively, over the state of the art.
NoisyActions2M: A Multimedia Dataset for Video Understanding from Noisy Labels
Oct 13, 2021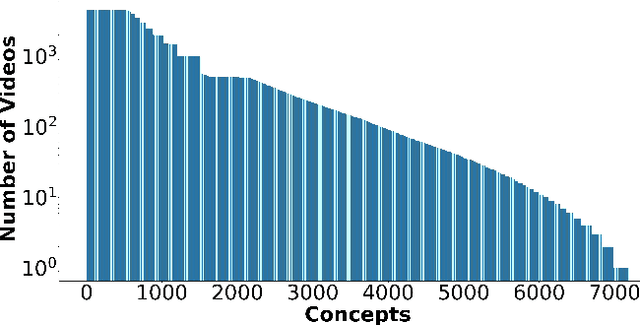
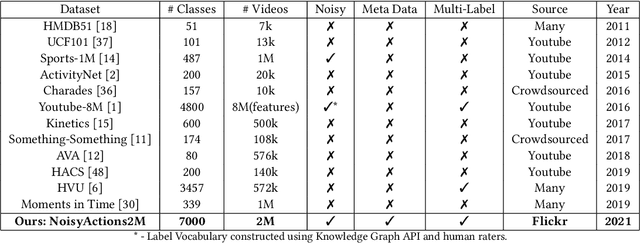
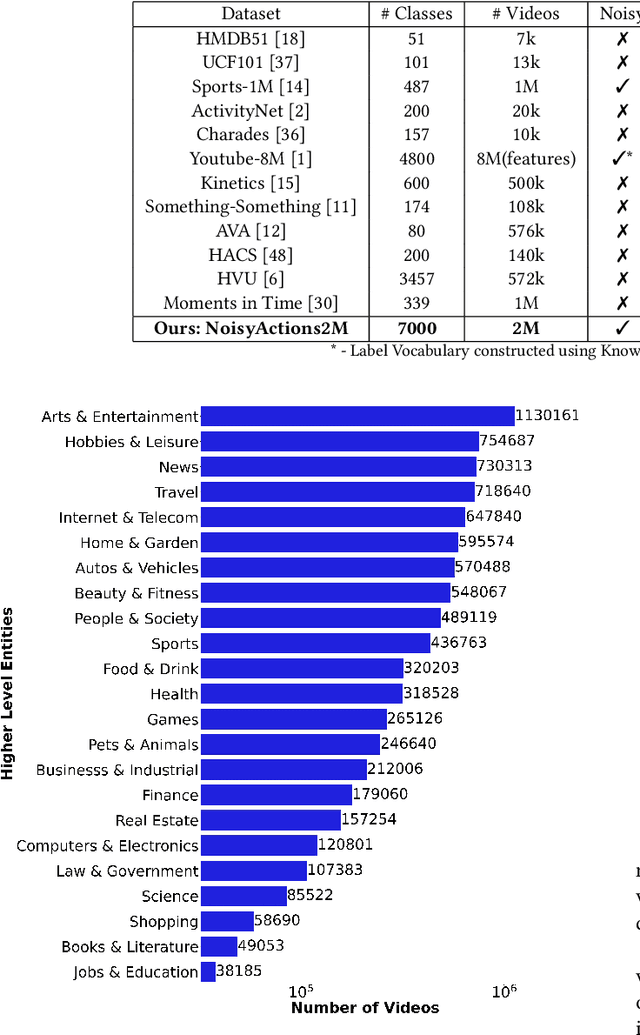
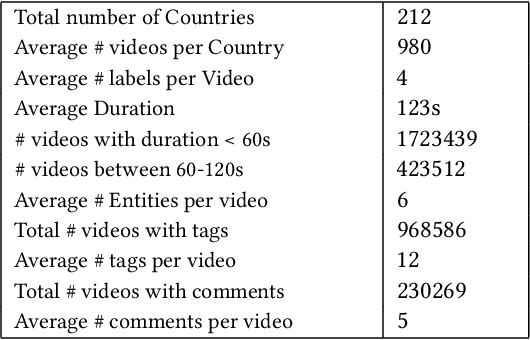
Deep learning has shown remarkable progress in a wide range of problems. However, efficient training of such models requires large-scale datasets, and getting annotations for such datasets can be challenging and costly. In this work, we explore the use of user-generated freely available labels from web videos for video understanding. We create a benchmark dataset consisting of around 2 million videos with associated user-generated annotations and other meta information. We utilize the collected dataset for action classification and demonstrate its usefulness with existing small-scale annotated datasets, UCF101 and HMDB51. We study different loss functions and two pretraining strategies, simple and self-supervised learning. We also show how a network pretrained on the proposed dataset can help against video corruption and label noise in downstream datasets. We present this as a benchmark dataset in noisy learning for video understanding. The dataset, code, and trained models will be publicly available for future research.
Neural Open Information Extraction
May 11, 2018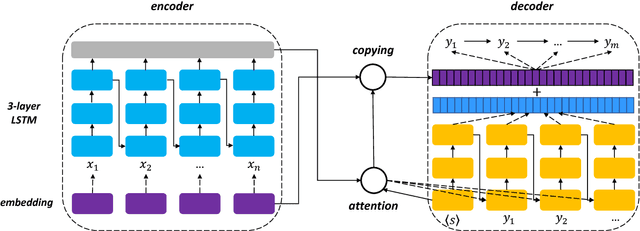
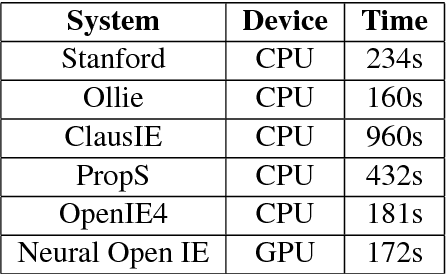
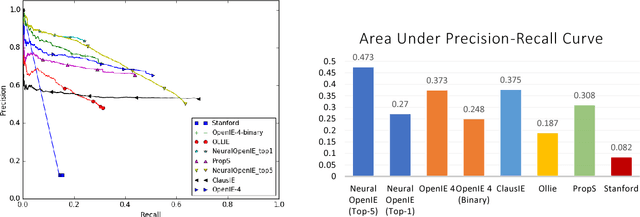
Conventional Open Information Extraction (Open IE) systems are usually built on hand-crafted patterns from other NLP tools such as syntactic parsing, yet they face problems of error propagation. In this paper, we propose a neural Open IE approach with an encoder-decoder framework. Distinct from existing methods, the neural Open IE approach learns highly confident arguments and relation tuples bootstrapped from a state-of-the-art Open IE system. An empirical study on a large benchmark dataset shows that the neural Open IE system significantly outperforms several baselines, while maintaining comparable computational efficiency.
Similarity-Aware Fusion Network for 3D Semantic Segmentation
Jul 06, 2021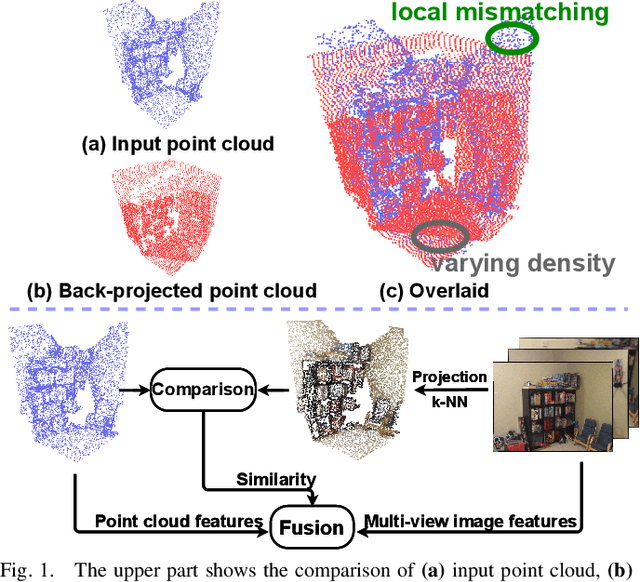
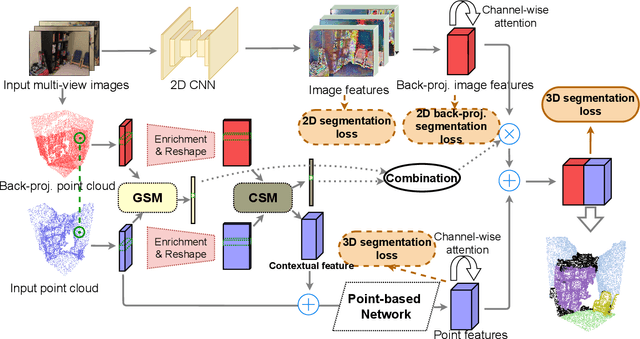
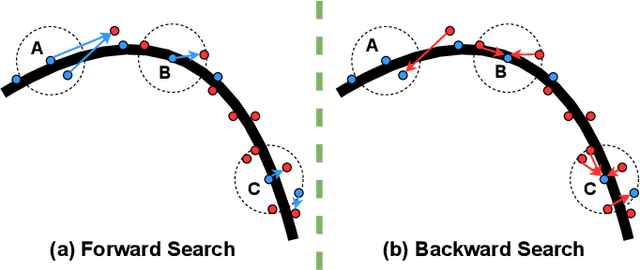
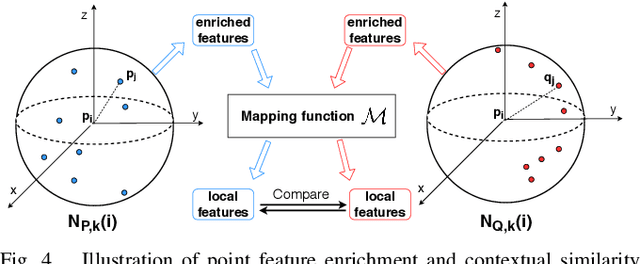
In this paper, we propose a similarity-aware fusion network (SAFNet) to adaptively fuse 2D images and 3D point clouds for 3D semantic segmentation. Existing fusion-based methods achieve remarkable performances by integrating information from multiple modalities. However, they heavily rely on the correspondence between 2D pixels and 3D points by projection and can only perform the information fusion in a fixed manner, and thus their performances cannot be easily migrated to a more realistic scenario where the collected data often lack strict pair-wise features for prediction. To address this, we employ a late fusion strategy where we first learn the geometric and contextual similarities between the input and back-projected (from 2D pixels) point clouds and utilize them to guide the fusion of two modalities to further exploit complementary information. Specifically, we employ a geometric similarity module (GSM) to directly compare the spatial coordinate distributions of pair-wise 3D neighborhoods, and a contextual similarity module (CSM) to aggregate and compare spatial contextual information of corresponding central points. The two proposed modules can effectively measure how much image features can help predictions, enabling the network to adaptively adjust the contributions of two modalities to the final prediction of each point. Experimental results on the ScanNetV2 benchmark demonstrate that SAFNet significantly outperforms existing state-of-the-art fusion-based approaches across various data integrity.
Beamforming Design for Intelligent Reflecting Surface-Enhanced Symbiotic Radio Systems
Oct 20, 2021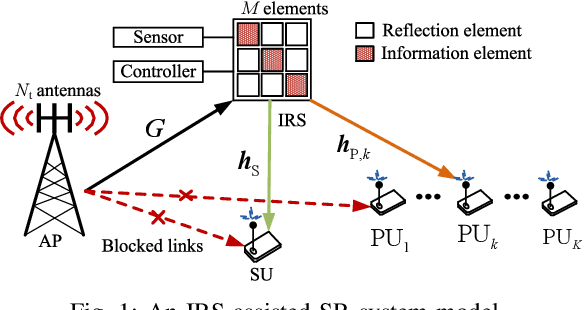
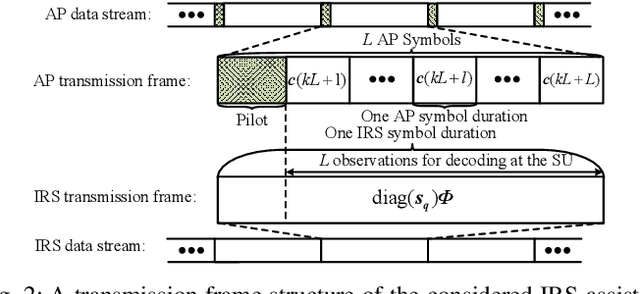
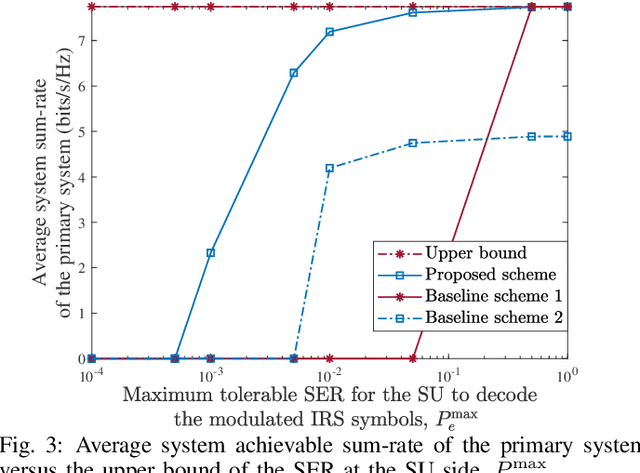
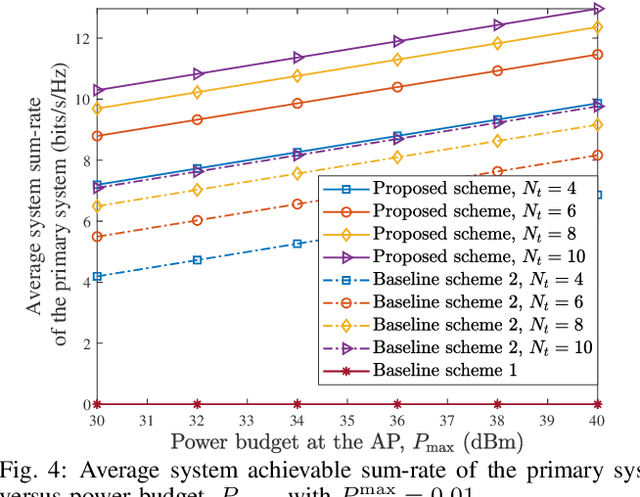
This paper investigates multiuser multi-input single-output downlink symbiotic radio communication systems assisted by an intelligent reflecting surface (IRS). Different from existing methods ideally assuming the secondary user (SU) can jointly decode information symbols from both the access point (AP) and the IRS via multiuser detection, we consider a more practical SU that only non-coherent detection is available. To characterize the non-coherent decoding performance, a practical upper bound of the average symbol error rate (SER) is derived. Subsequently, we jointly optimize the beamformer at the AP and the phase shifts at the IRS to maximize the average sum-rate of the primary system taking into account the maximum tolerable SER constraint for the SU. To circumvent the couplings of variables, we exploit the Schur complement that facilitates the design of a suboptimal beamforming algorithm based on successive convex approximation. Our simulation results show that compared with various benchmark algorithms, the proposed scheme significantly improves the average sum-rate of the primary system, while guaranteeing the decoding performance of the secondary system.
Modality and Negation in Event Extraction
Sep 20, 2021
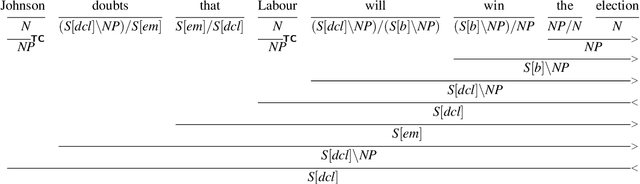
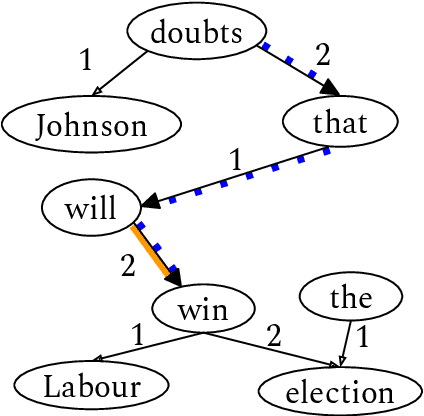
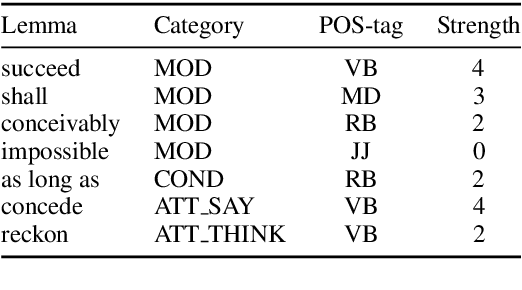
Language provides speakers with a rich system of modality for expressing thoughts about events, without being committed to their actual occurrence. Modality is commonly used in the political news domain, where both actual and possible courses of events are discussed. NLP systems struggle with these semantic phenomena, often incorrectly extracting events which did not happen, which can lead to issues in downstream applications. We present an open-domain, lexicon-based event extraction system that captures various types of modality. This information is valuable for Question Answering, Knowledge Graph construction and Fact-checking tasks, and our evaluation shows that the system is sufficiently strong to be used in downstream applications.
* S. Bijl de Vroe, L. Guillou, M. Stanojevi\'c, N. McKenna, and M. Steedman. 2021. Modality and Negation in Event Extraction. In Proceedings of the 4th Workshop on Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2021), pages 31-42, online. Association for Computational Linguistics
FR-Train: A mutual information-based approach to fair and robust training
Feb 24, 2020
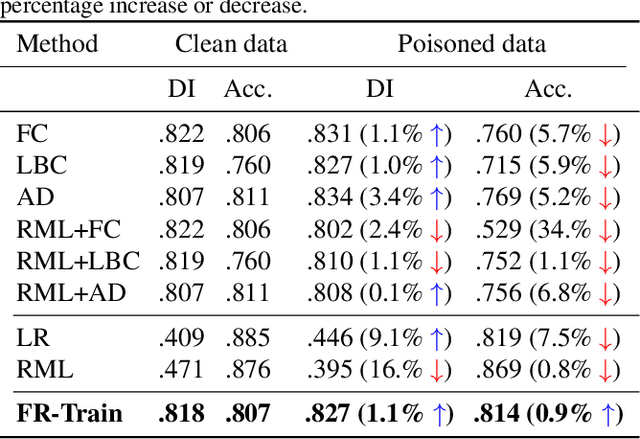
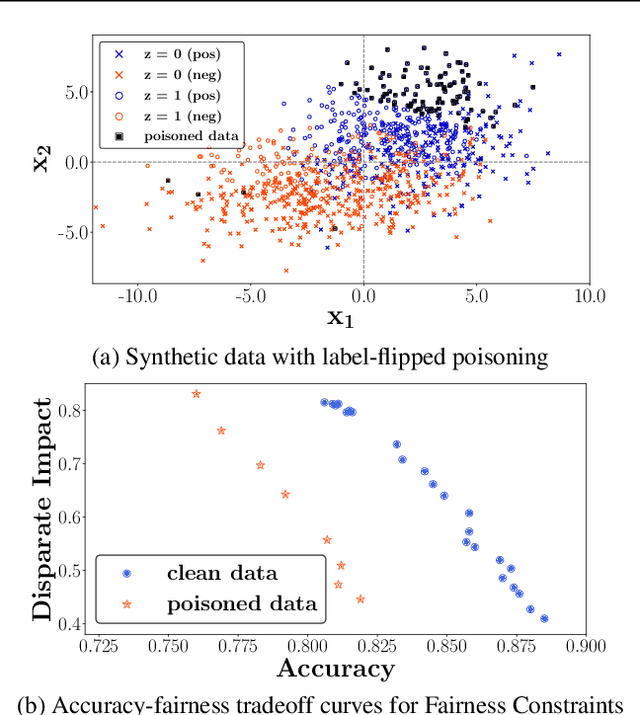
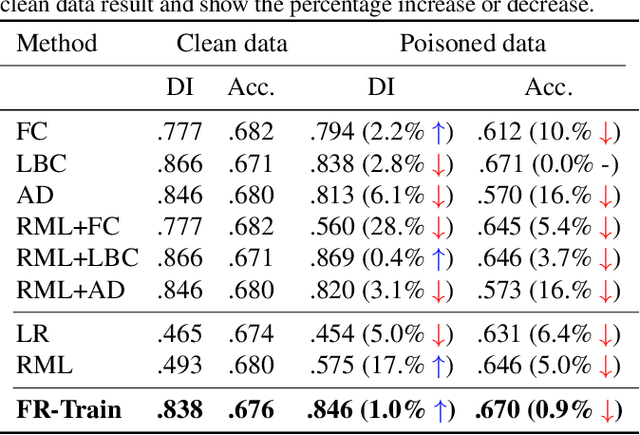
Trustworthy AI is a critical issue in machine learning where, in addition to training a model that is accurate, one must consider both fair and robust training in the presence of data bias and poisoning. However, the existing model fairness techniques mistakenly view poisoned data as an additional bias, resulting in severe performance degradation. To fix this problem, we propose FR-Train, which holistically performs fair and robust model training. We provide a mutual information-based interpretation of an existing adversarial training-based fairness-only method, and apply this idea to architect an additional discriminator that can identify poisoned data using a clean validation set and reduce its influence. In our experiments, FR-Train shows almost no decrease in fairness and accuracy in the presence of data poisoning by both mitigating the bias and defending against poisoning. We also demonstrate how to construct clean validation sets using crowdsourcing, and release new benchmark datasets.
Plugging Self-Supervised Monocular Depth into Unsupervised Domain Adaptation for Semantic Segmentation
Oct 13, 2021



Although recent semantic segmentation methods have made remarkable progress, they still rely on large amounts of annotated training data, which are often infeasible to collect in the autonomous driving scenario. Previous works usually tackle this issue with Unsupervised Domain Adaptation (UDA), which entails training a network on synthetic images and applying the model to real ones while minimizing the discrepancy between the two domains. Yet, these techniques do not consider additional information that may be obtained from other tasks. Differently, we propose to exploit self-supervised monocular depth estimation to improve UDA for semantic segmentation. On one hand, we deploy depth to realize a plug-in component which can inject complementary geometric cues into any existing UDA method. We further rely on depth to generate a large and varied set of samples to Self-Train the final model. Our whole proposal allows for achieving state-of-the-art performance (58.8 mIoU) in the GTA5->CS benchmark benchmark. Code is available at https://github.com/CVLAB-Unibo/d4-dbst.
Evaluating the effectiveness of Phishing Reports on Twitter
Nov 13, 2021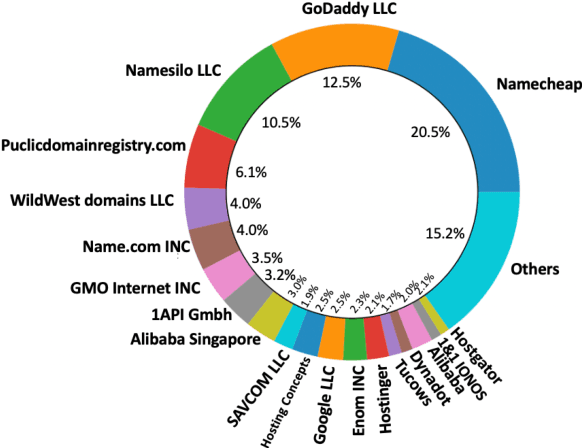
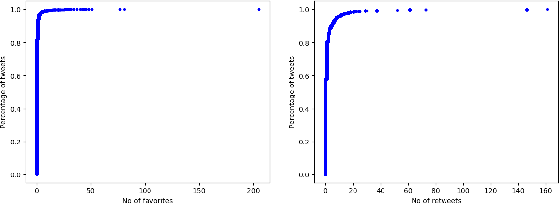
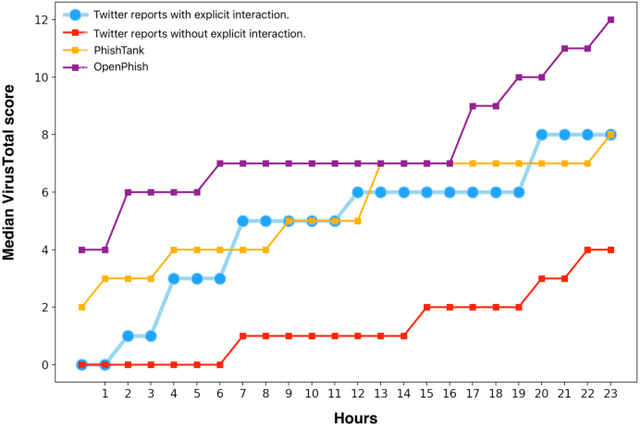
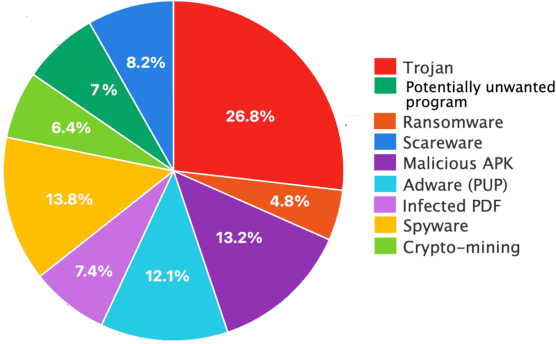
Phishing attacks are an increasingly potent web-based threat, with nearly 1.5 million websites created on a monthly basis. In this work, we present the first study towards identifying such attacks through phishing reports shared by users on Twitter. We evaluated over 16.4k such reports posted by 701 Twitter accounts between June to August 2021, which contained 11.1k unique URLs, and analyzed their effectiveness using various quantitative and qualitative measures. Our findings indicate that not only do these users share a high volume of legitimate phishing URLs, but these reports contain more information regarding the phishing websites (which can expedite the process of identifying and removing these threats), when compared to two popular open-source phishing feeds: PhishTank and OpenPhish. We also notice that the reported websites had very little overlap with the URLs existing in the other feeds, and also remained active for longer periods of time. But despite having these attributes, we found that these reports have very low interaction from other Twitter users, especially from the domains and organizations targeted by the reported URLs. Moreover, nearly 31% of these URLs were still active even after a week of them being reported, with 27% of them being detected by very few anti-phishing tools, suggesting that a large majority of these reports remain undiscovered, despite the majority of the follower base of these accounts being security focused users. Thus, this work highlights the effectiveness of the reports, and the benefits of using them as an open source knowledge base for identifying new phishing websites.