 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Hierarchical Dual Consistency for Semi-Supervised Left Atrium Segmentation on Cross-Domain Data
Sep 20, 2021
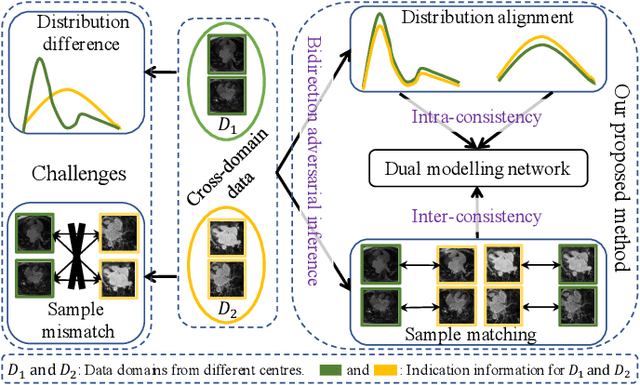
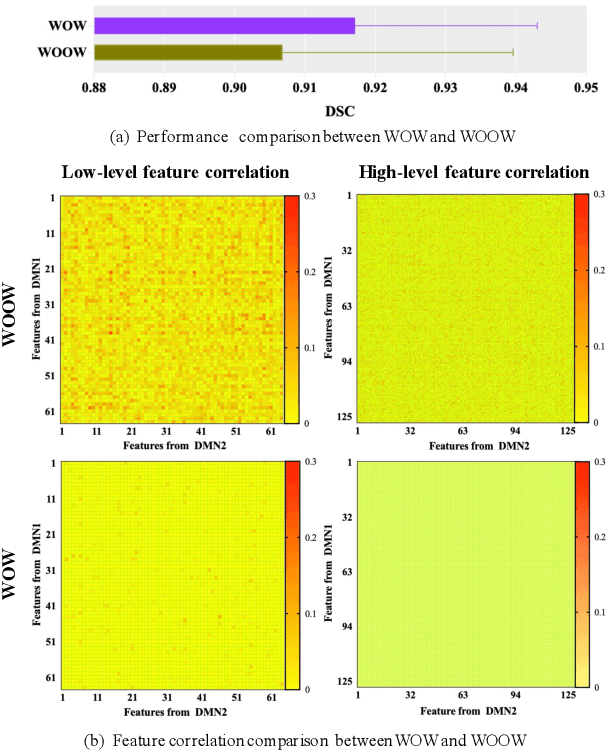
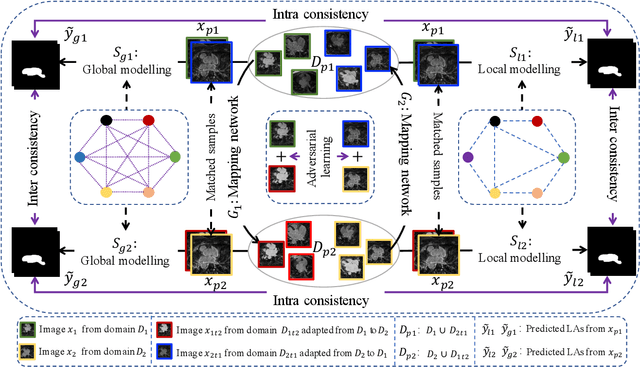
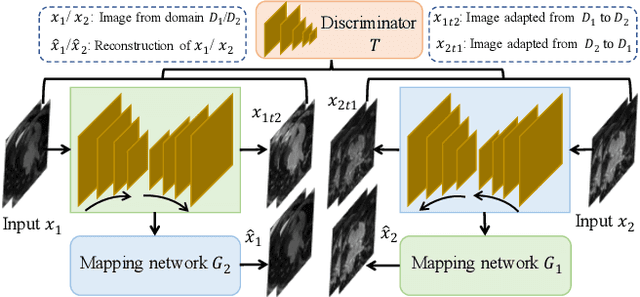
Semi-supervised learning provides great significance in left atrium (LA) segmentation model learning with insufficient labelled data. Generalising semi-supervised learning to cross-domain data is of high importance to further improve model robustness. However, the widely existing distribution difference and sample mismatch between different data domains hinder the generalisation of semi-supervised learning. In this study, we alleviate these problems by proposing an Adaptive Hierarchical Dual Consistency (AHDC) for the semi-supervised LA segmentation on cross-domain data. The AHDC mainly consists of a Bidirectional Adversarial Inference module (BAI) and a Hierarchical Dual Consistency learning module (HDC). The BAI overcomes the difference of distributions and the sample mismatch between two different domains. It mainly learns two mapping networks adversarially to obtain two matched domains through mutual adaptation. The HDC investigates a hierarchical dual learning paradigm for cross-domain semi-supervised segmentation based on the obtained matched domains. It mainly builds two dual-modelling networks for mining the complementary information in both intra-domain and inter-domain. For the intra-domain learning, a consistency constraint is applied to the dual-modelling targets to exploit the complementary modelling information. For the inter-domain learning, a consistency constraint is applied to the LAs modelled by two dual-modelling networks to exploit the complementary knowledge among different data domains. We demonstrated the performance of our proposed AHDC on four 3D late gadolinium enhancement cardiac MR (LGE-CMR) datasets from different centres and a 3D CT dataset. Compared to other state-of-the-art methods, our proposed AHDC achieved higher segmentation accuracy, which indicated its capability in the cross-domain semi-supervised LA segmentation.
Understanding of Kernels in CNN Models by Suppressing Irrelevant Visual Features in Images
Aug 25, 2021
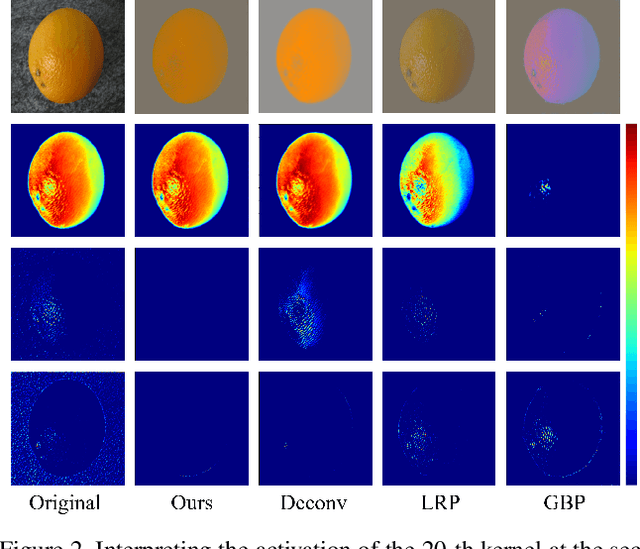


Deep learning models have shown their superior performance in various vision tasks. However, the lack of precisely interpreting kernels in convolutional neural networks (CNNs) is becoming one main obstacle to wide applications of deep learning models in real scenarios. Although existing interpretation methods may find certain visual patterns which are associated with the activation of a specific kernel, those visual patterns may not be specific or comprehensive enough for interpretation of a specific activation of kernel of interest. In this paper, a simple yet effective optimization method is proposed to interpret the activation of any kernel of interest in CNN models. The basic idea is to simultaneously preserve the activation of the specific kernel and suppress the activation of all other kernels at the same layer. In this way, only visual information relevant to the activation of the specific kernel is remained in the input. Consistent visual information from multiple modified inputs would help users understand what kind of features are specifically associated with specific kernel. Comprehensive evaluation shows that the proposed method can help better interpret activation of specific kernels than widely used methods, even when two kernels have very similar activation regions from the same input image.
A Survey on Multi-modal Summarization
Sep 11, 2021
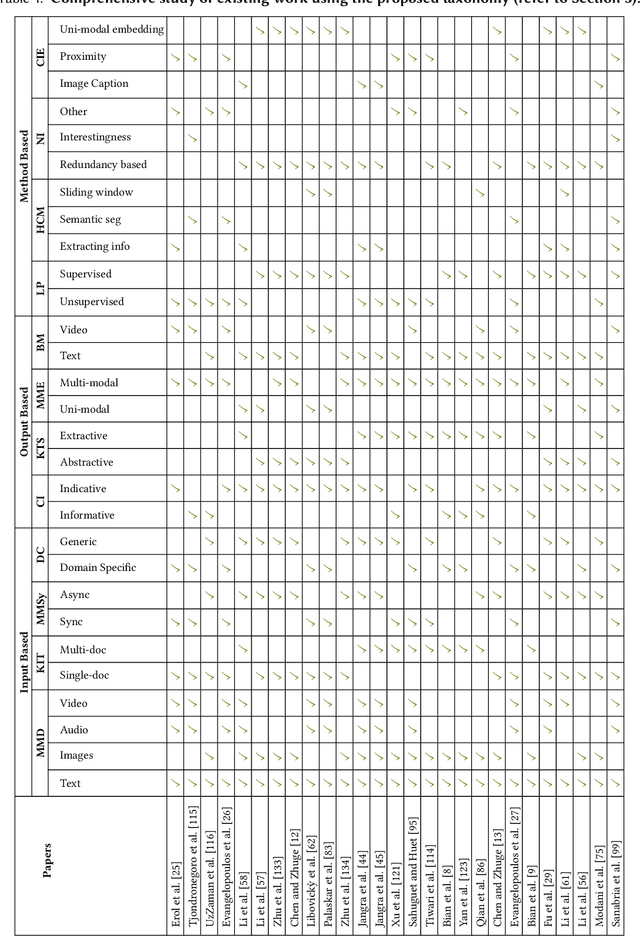
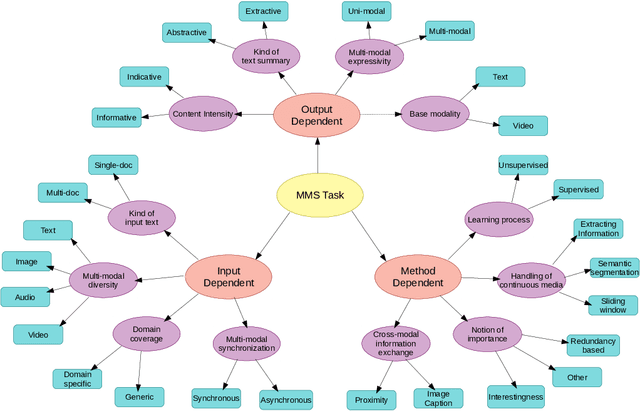

The new era of technology has brought us to the point where it is convenient for people to share their opinions over an abundance of platforms. These platforms have a provision for the users to express themselves in multiple forms of representations, including text, images, videos, and audio. This, however, makes it difficult for users to obtain all the key information about a topic, making the task of automatic multi-modal summarization (MMS) essential. In this paper, we present a comprehensive survey of the existing research in the area of MMS.
Information-Theoretic Bounds on the Moments of the Generalization Error of Learning Algorithms
Feb 03, 2021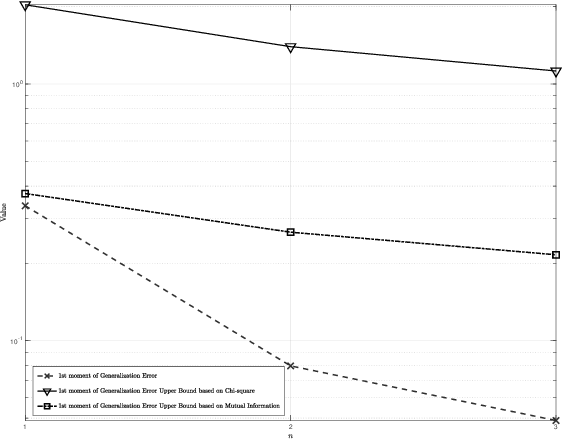
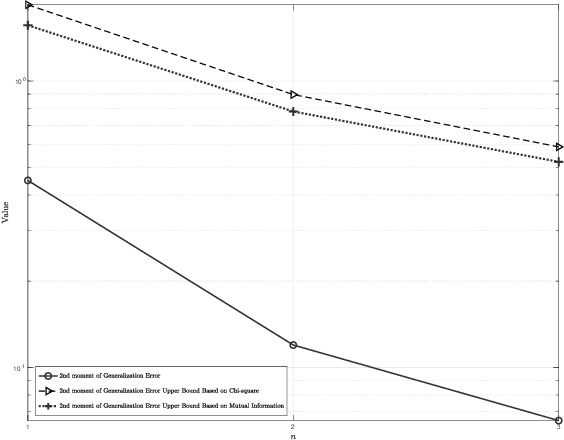
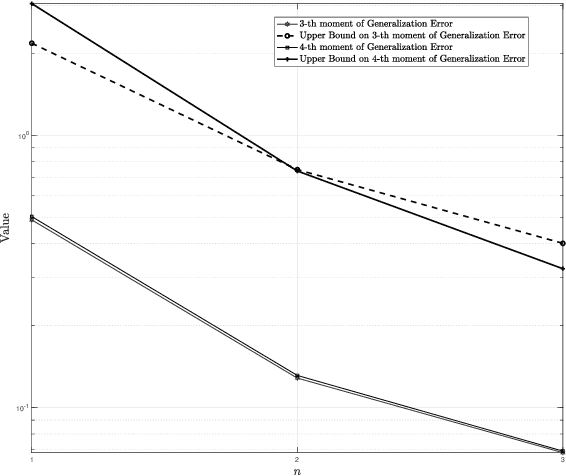
Generalization error bounds are critical to understanding the performance of machine learning models. In this work, building upon a new bound of the expected value of an arbitrary function of the population and empirical risk of a learning algorithm, we offer a more refined analysis of the generalization behaviour of a machine learning models based on a characterization of (bounds) to their generalization error moments. We discuss how the proposed bounds -- which also encompass new bounds to the expected generalization error -- relate to existing bounds in the literature. We also discuss how the proposed generalization error moment bounds can be used to construct new generalization error high-probability bounds.
Camera-Based Physiological Sensing: Challenges and Future Directions
Oct 26, 2021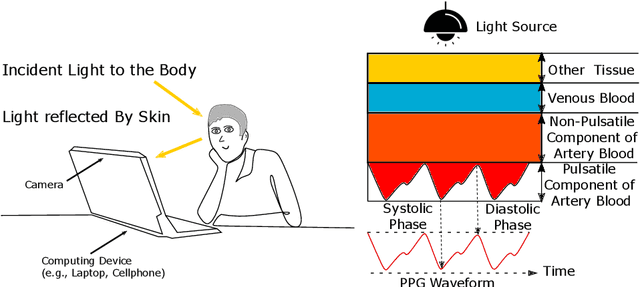
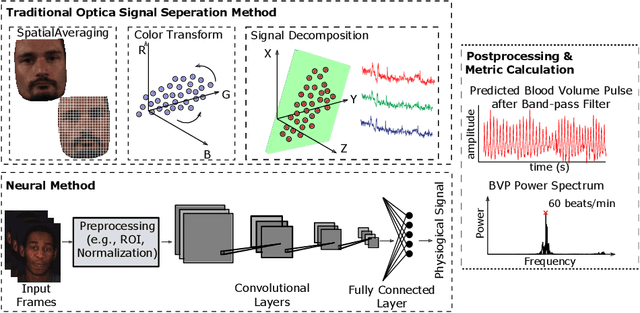
Numerous real-world applications have been driven by the recent algorithmic advancement of artificial intelligence (AI). Healthcare is no exception and AI technologies have great potential to revolutionize the industry. Non-contact camera-based physiological sensing, including remote photoplethysmography (rPPG), is a set of imaging methods that leverages ordinary RGB cameras (e.g., webcam or smartphone camera) to capture subtle changes in electromagnetic radiation (e.g., light) reflected by the body caused by physiological processes. Because of the relative ubiquity of cameras, these methods not only have the ability to measure the signals without contact with the body but also have the opportunity to capture multimodal information (e.g., facial expressions, activities and other context) from the same sensor. However, developing accessible, equitable and useful camera-based physiological sensing systems comes with various challenges. In this article, we identify four research challenges for the field of camera-based physiological sensing and broader AI driven healthcare communities and suggest future directions to tackle these. We believe solving these challenges will help deliver accurate, equitable and generalizable AI systems for healthcare that are practical in real-world and clinical contexts.
Learning to maximize global influence from local observations
Sep 24, 2021We study a family online influence maximization problems where in a sequence of rounds $t=1,\ldots,T$, a decision maker selects one from a large number of agents with the goal of maximizing influence. Upon choosing an agent, the decision maker shares a piece of information with the agent, which information then spreads in an unobserved network over which the agents communicate. The goal of the decision maker is to select the sequence of agents in a way that the total number of influenced nodes in the network. In this work, we consider a scenario where the networks are generated independently for each $t$ according to some fixed but unknown distribution, so that the set of influenced nodes corresponds to the connected component of the random graph containing the vertex corresponding to the selected agent. Furthermore, we assume that the decision maker only has access to limited feedback: instead of making the unrealistic assumption that the entire network is observable, we suppose that the available feedback is generated based on a small neighborhood of the selected vertex. Our results show that such partial local observations can be sufficient for maximizing global influence. We model the underlying random graph as a sparse inhomogeneous Erd\H{o}s--R\'enyi graph, and study three specific families of random graph models in detail: stochastic block models, Chung--Lu models and Kronecker random graphs. We show that in these cases one may learn to maximize influence by merely observing the degree of the selected vertex in the generated random graph. We propose sequential learning algorithms that aim at maximizing influence, and provide their theoretical analysis in both the subcritical and supercritical regimes of all considered models.
Background-Aware 3D Point Cloud Segmentationwith Dynamic Point Feature Aggregation
Nov 14, 2021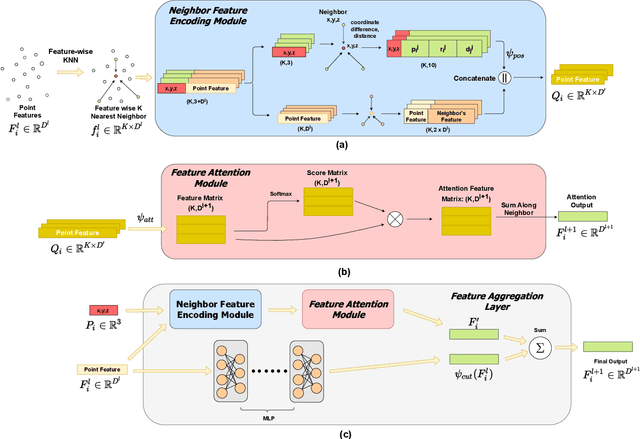
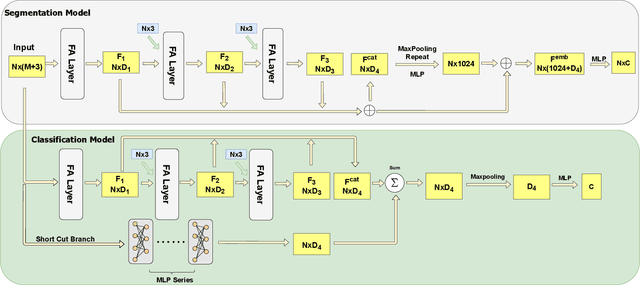
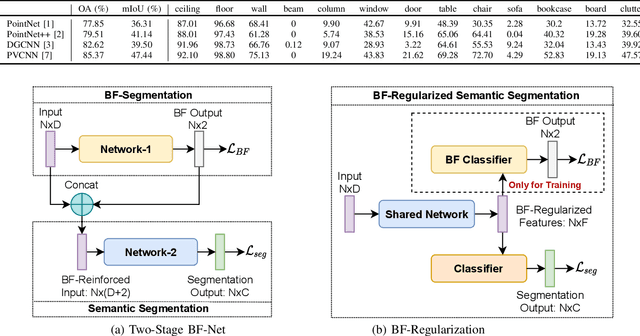

With the proliferation of Lidar sensors and 3D vision cameras, 3D point cloud analysis has attracted significant attention in recent years. After the success of the pioneer work PointNet, deep learning-based methods have been increasingly applied to various tasks, including 3D point cloud segmentation and 3D object classification. In this paper, we propose a novel 3D point cloud learning network, referred to as Dynamic Point Feature Aggregation Network (DPFA-Net), by selectively performing the neighborhood feature aggregation with dynamic pooling and an attention mechanism. DPFA-Net has two variants for semantic segmentation and classification of 3D point clouds. As the core module of the DPFA-Net, we propose a Feature Aggregation layer, in which features of the dynamic neighborhood of each point are aggregated via a self-attention mechanism. In contrast to other segmentation models, which aggregate features from fixed neighborhoods, our approach can aggregate features from different neighbors in different layers providing a more selective and broader view to the query points, and focusing more on the relevant features in a local neighborhood. In addition, to further improve the performance of the proposed semantic segmentation model, we present two novel approaches, namely Two-Stage BF-Net and BF-Regularization to exploit the background-foreground information. Experimental results show that the proposed DPFA-Net achieves the state-of-the-art overall accuracy score for semantic segmentation on the S3DIS dataset, and provides a consistently satisfactory performance across different tasks of semantic segmentation, part segmentation, and 3D object classification. It is also computationally more efficient compared to other methods.
Privacy-Preserving Multi-Target Multi-Domain Recommender Systems with Assisted AutoEncoders
Oct 26, 2021
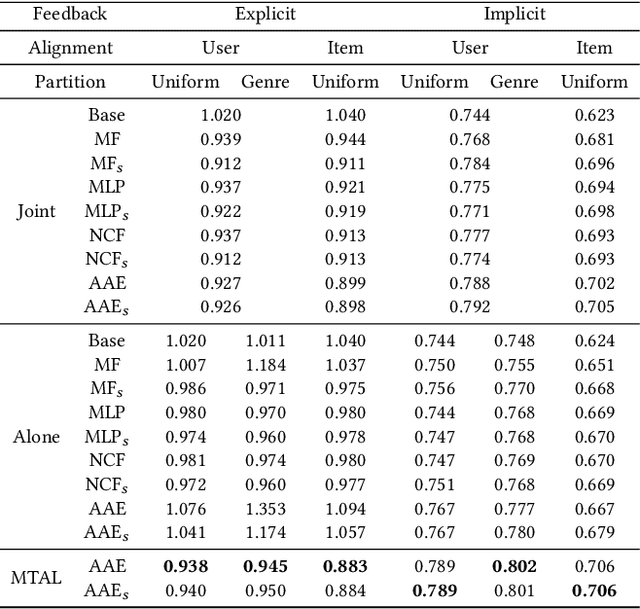
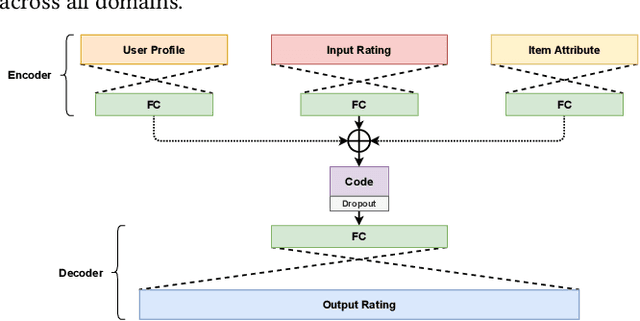
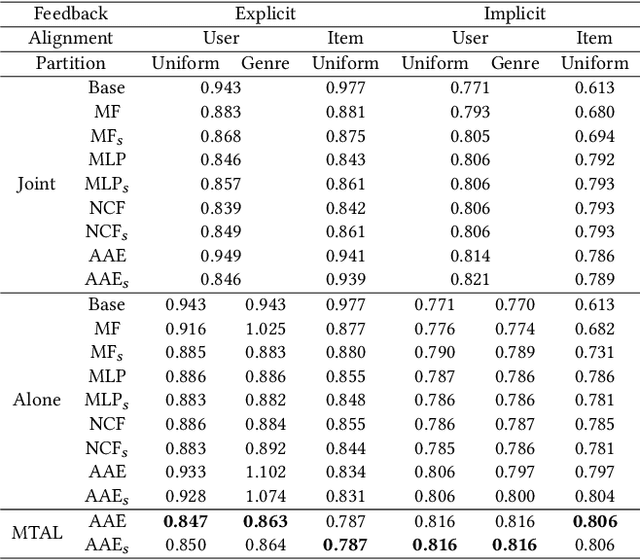
A long-standing challenge in Recommender Systems (RCs) is the data sparsity problem that often arises when users rate very few items. Multi-Target Multi-Domain Recommender Systems (MTMDR) aim to improve the recommendation performance in multiple domains simultaneously. The existing works assume that the data of different domains can be fully shared, and the computation can be performed in a centralized manner. However, in many realistic scenarios, separate recommender systems are operated by different organizations, which do not allow the sharing of private data, models, and recommendation tasks. This work proposes an MTMDR based on Assisted AutoEncoders (AAE) and Multi-Target Assisted Learning (MTAL) to help organizational learners improve their recommendation performance simultaneously without sharing sensitive assets. Moreover, AAE has a broad application scope since it allows explicit or implicit feedback, user- or item-based alignment, and with or without side information. Extensive experiments demonstrate that our method significantly outperforms the case where each domain is locally trained, and it performs competitively with the centralized training where all data are shared. As a result, AAE can effectively integrate organizations from different domains to form a community of shared interest.
Repaint: Improving the Generalization of Down-Stream Visual Tasks by Generating Multiple Instances of Training Examples
Oct 20, 2021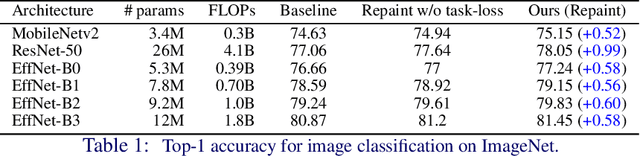
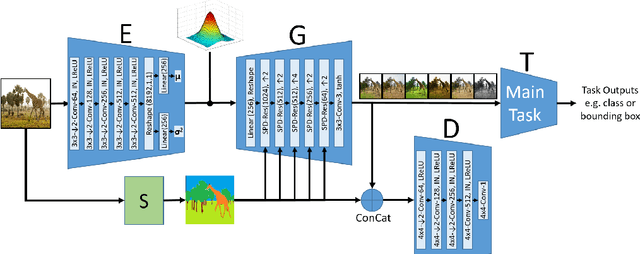
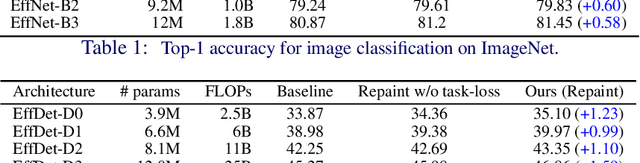
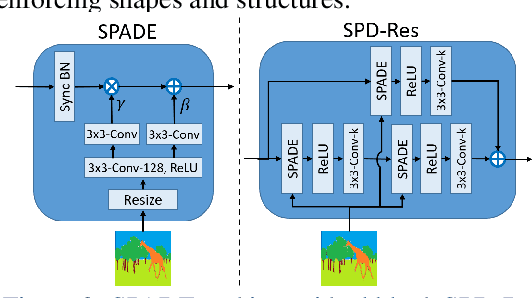
Convolutional Neural Networks (CNNs) for visual tasks are believed to learn both the low-level textures and high-level object attributes, throughout the network depth. This paper further investigates the `texture bias' in CNNs. To this end, we regenerate multiple instances of training examples from each original image, through a process we call `repainting'. The repainted examples preserve the shape and structure of the regions and objects within the scenes, but diversify their texture and color. Our method can regenerate a same image at different daylight, season, or weather conditions, can have colorization or de-colorization effects, or even bring back some texture information from blacked-out areas. The in-place repaint allows us to further use these repainted examples for improving the generalization of CNNs. Through an extensive set of experiments, we demonstrate the usefulness of the repainted examples in training, for the tasks of image classification (ImageNet) and object detection (COCO), over several state-of-the-art network architectures at different capacities, and across different data availability regimes.
Gaussian Process Bandit Optimization with Few Batches
Oct 26, 2021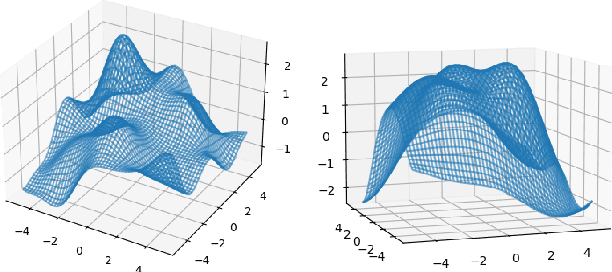
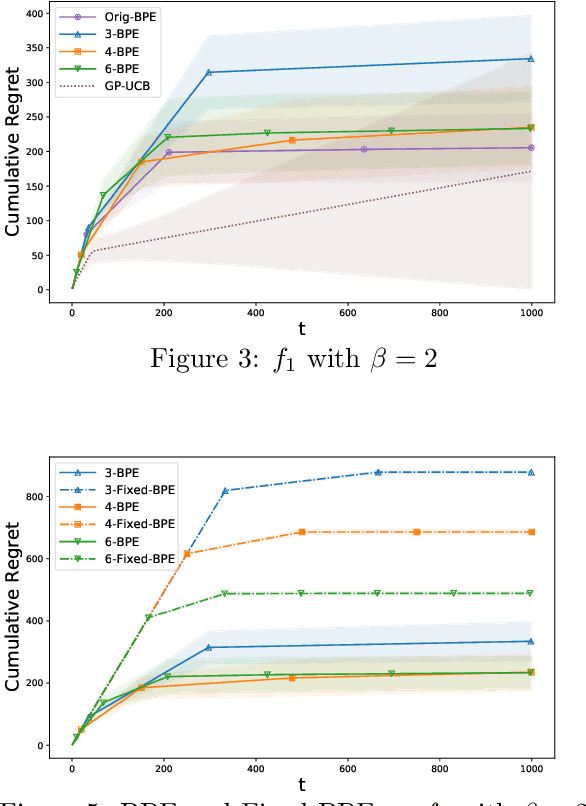
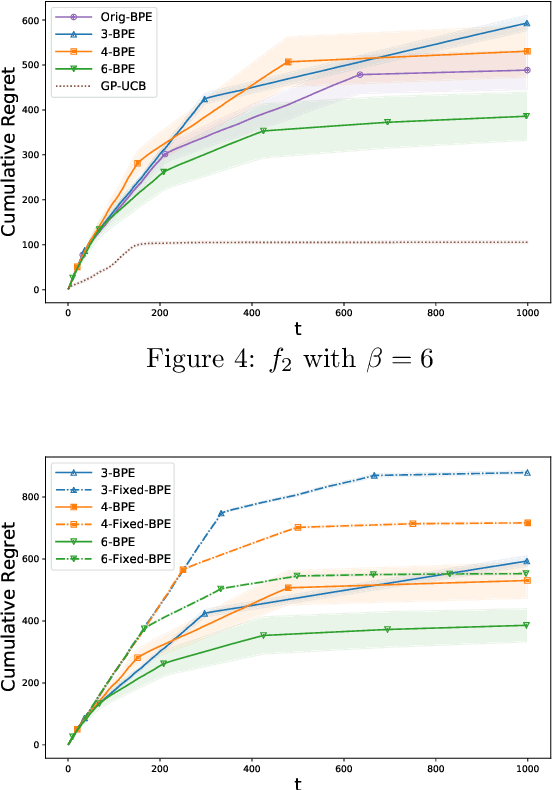
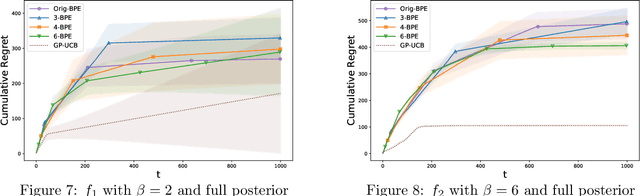
In this paper, we consider the problem of black-box optimization using Gaussian Process (GP) bandit optimization with a small number of batches. Assuming the unknown function has a low norm in the Reproducing Kernel Hilbert Space (RKHS), we introduce a batch algorithm inspired by batched finite-arm bandit algorithms, and show that it achieves the cumulative regret upper bound $O^\ast(\sqrt{T\gamma_T})$ using $O(\log\log T)$ batches within time horizon $T$, where the $O^\ast(\cdot)$ notation hides dimension-independent logarithmic factors and $\gamma_T$ is the maximum information gain associated with the kernel. This bound is near-optimal for several kernels of interest and improves on the typical $O^\ast(\sqrt{T}\gamma_T)$ bound, and our approach is arguably the simplest among algorithms attaining this improvement. In addition, in the case of a constant number of batches (not depending on $T$), we propose a modified version of our algorithm, and characterize how the regret is impacted by the number of batches, focusing on the squared exponential and Mat\'ern kernels. The algorithmic upper bounds are shown to be nearly minimax optimal via analogous algorithm-independent lower bounds.