 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Max-Utility Based Arm Selection Strategy For Sequential Query Recommendations
Aug 31, 2021
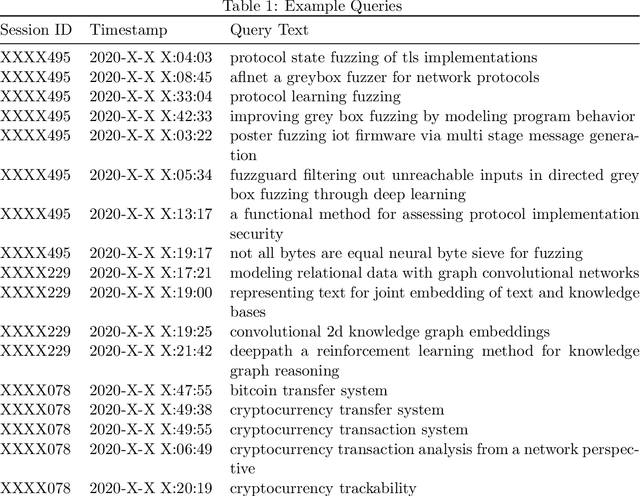
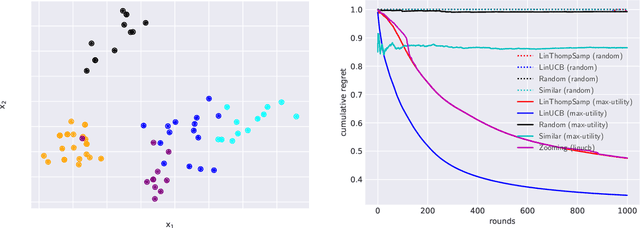

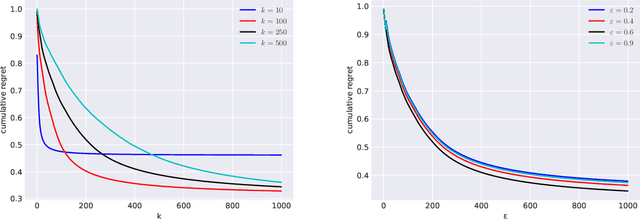
We consider the query recommendation problem in closed loop interactive learning settings like online information gathering and exploratory analytics. The problem can be naturally modelled using the Multi-Armed Bandits (MAB) framework with countably many arms. The standard MAB algorithms for countably many arms begin with selecting a random set of candidate arms and then applying standard MAB algorithms, e.g., UCB, on this candidate set downstream. We show that such a selection strategy often results in higher cumulative regret and to this end, we propose a selection strategy based on the maximum utility of the arms. We show that in tasks like online information gathering, where sequential query recommendations are employed, the sequences of queries are correlated and the number of potentially optimal queries can be reduced to a manageable size by selecting queries with maximum utility with respect to the currently executing query. Our experimental results using a recent real online literature discovery service log file demonstrate that the proposed arm selection strategy improves the cumulative regret substantially with respect to the state-of-the-art baseline algorithms. % and commonly used random selection strategy for a variety of contextual multi-armed bandit algorithms. Our data model and source code are available at ~\url{https://anonymous.4open.science/r/0e5ad6b7-ac02-4577-9212-c9d505d3dbdb/}.
Hierarchical Bayesian Model for the Transfer of Knowledge on Spatial Concepts based on Multimodal Information
Mar 11, 2021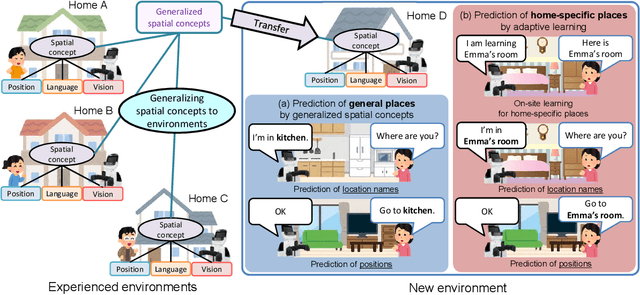

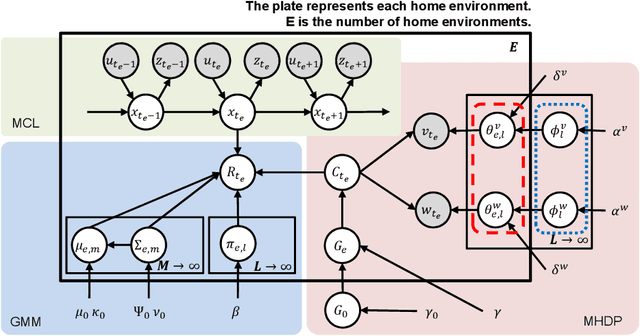
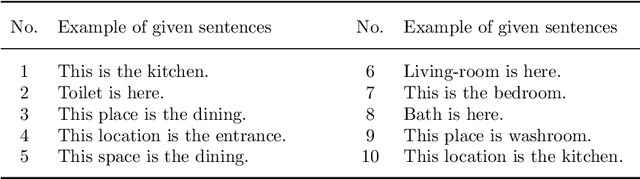
This paper proposes a hierarchical Bayesian model based on spatial concepts that enables a robot to transfer the knowledge of places from experienced environments to a new environment. The transfer of knowledge based on spatial concepts is modeled as the calculation process of the posterior distribution based on the observations obtained in each environment with the parameters of spatial concepts generalized to environments as prior knowledge. We conducted experiments to evaluate the generalization performance of spatial knowledge for general places such as kitchens and the adaptive performance of spatial knowledge for unique places such as `Emma's room' in a new environment. In the experiments, the accuracies of the proposed method and conventional methods were compared in the prediction task of location names from an image and a position, and the prediction task of positions from a location name. The experimental results demonstrated that the proposed method has a higher prediction accuracy of location names and positions than the conventional method owing to the transfer of knowledge.
Camera-Based Physiological Sensing: Challenges and Future Directions
Oct 26, 2021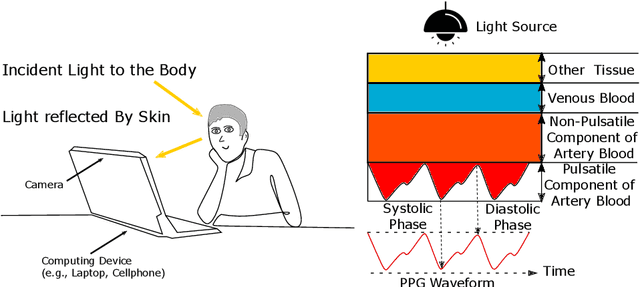
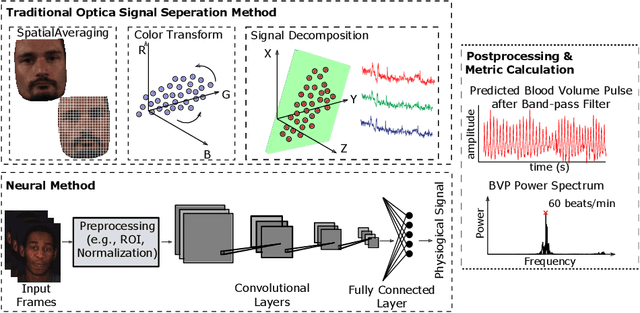
Numerous real-world applications have been driven by the recent algorithmic advancement of artificial intelligence (AI). Healthcare is no exception and AI technologies have great potential to revolutionize the industry. Non-contact camera-based physiological sensing, including remote photoplethysmography (rPPG), is a set of imaging methods that leverages ordinary RGB cameras (e.g., webcam or smartphone camera) to capture subtle changes in electromagnetic radiation (e.g., light) reflected by the body caused by physiological processes. Because of the relative ubiquity of cameras, these methods not only have the ability to measure the signals without contact with the body but also have the opportunity to capture multimodal information (e.g., facial expressions, activities and other context) from the same sensor. However, developing accessible, equitable and useful camera-based physiological sensing systems comes with various challenges. In this article, we identify four research challenges for the field of camera-based physiological sensing and broader AI driven healthcare communities and suggest future directions to tackle these. We believe solving these challenges will help deliver accurate, equitable and generalizable AI systems for healthcare that are practical in real-world and clinical contexts.
Decentralized Multi-Agent Reinforcement Learning: An Off-Policy Method
Oct 31, 2021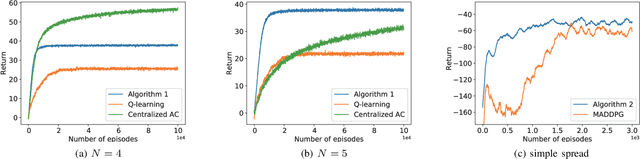
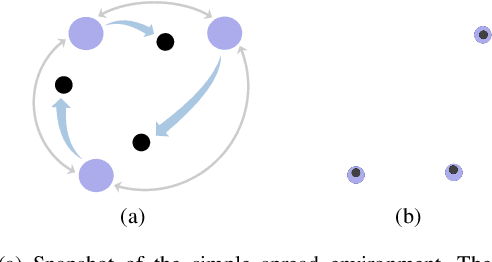
We discuss the problem of decentralized multi-agent reinforcement learning (MARL) in this work. In our setting, the global state, action, and reward are assumed to be fully observable, while the local policy is protected as privacy by each agent, and thus cannot be shared with others. There is a communication graph, among which the agents can exchange information with their neighbors. The agents make individual decisions and cooperate to reach a higher accumulated reward. Towards this end, we first propose a decentralized actor-critic (AC) setting. Then, the policy evaluation and policy improvement algorithms are designed for discrete and continuous state-action-space Markov Decision Process (MDP) respectively. Furthermore, convergence analysis is given under the discrete-space case, which guarantees that the policy will be reinforced by alternating between the processes of policy evaluation and policy improvement. In order to validate the effectiveness of algorithms, we design experiments and compare them with previous algorithms, e.g., Q-learning \cite{watkins1992q} and MADDPG \cite{lowe2017multi}. The results show that our algorithms perform better from the aspects of both learning speed and final performance. Moreover, the algorithms can be executed in an off-policy manner, which greatly improves the data efficiency compared with on-policy algorithms.
Optimization of Information-Seeking Dialogue Strategy for Argumentation-Based Dialogue System
Nov 26, 2018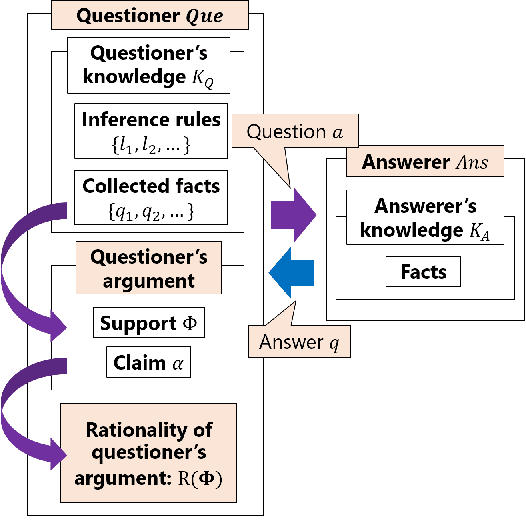
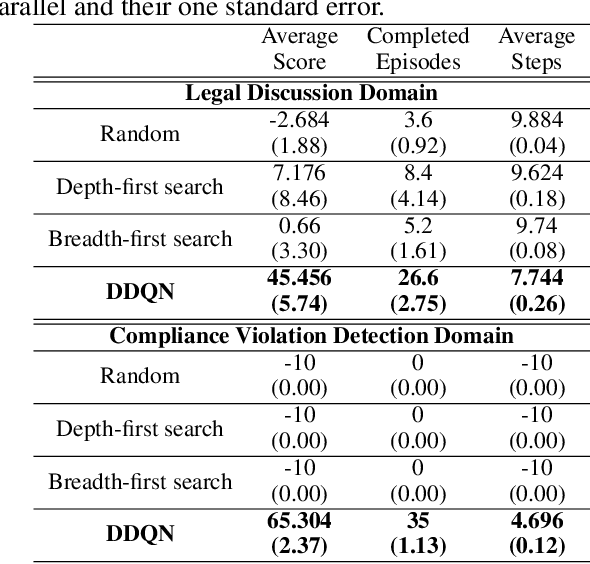
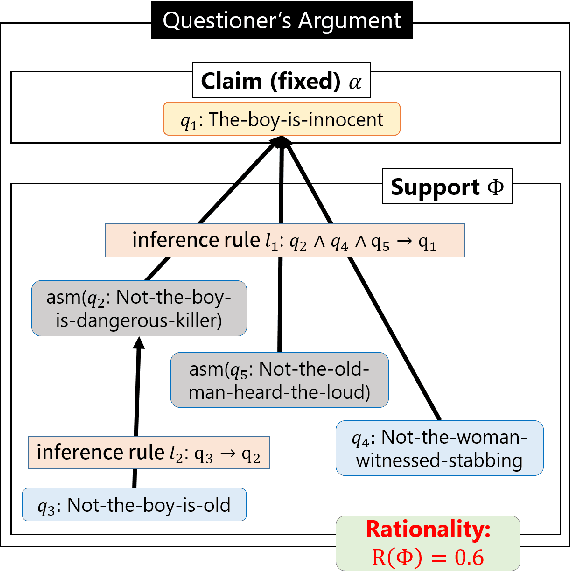

Argumentation-based dialogue systems, which can handle and exchange arguments through dialogue, have been widely researched. It is required that these systems have sufficient supporting information to argue their claims rationally; however, the systems often do not have enough of such information in realistic situations. One way to fill in the gap is acquiring such missing information from dialogue partners (information-seeking dialogue). Existing information-seeking dialogue systems are based on handcrafted dialogue strategies that exhaustively examine missing information. However, the proposed strategies are not specialized in collecting information for constructing rational arguments. Moreover, the number of system's inquiry candidates grows in accordance with the size of the argument set that the system deal with. In this paper, we formalize the process of information-seeking dialogue as Markov decision processes (MDPs) and apply deep reinforcement learning (DRL) for automatically optimizing a dialogue strategy. By utilizing DRL, our dialogue strategy can successfully minimize objective functions, the number of turns it takes for our system to collect necessary information in a dialogue. We conducted dialogue experiments using two datasets from different domains of argumentative dialogue. Experimental results show that the proposed formalization based on MDP works well, and the policy optimized by DRL outperformed existing heuristic dialogue strategies.
Privacy-Preserving Multi-Target Multi-Domain Recommender Systems with Assisted AutoEncoders
Oct 26, 2021
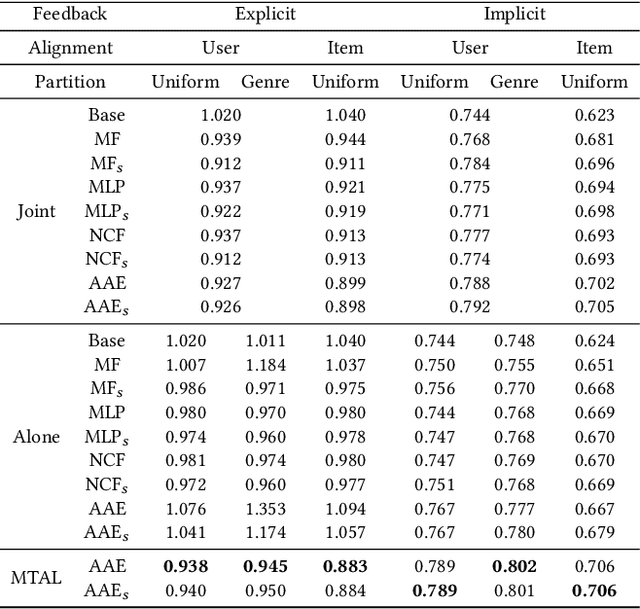
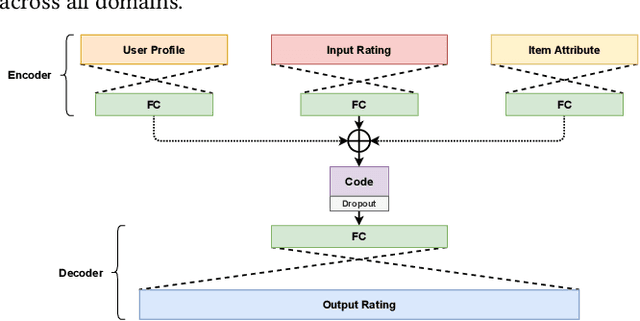
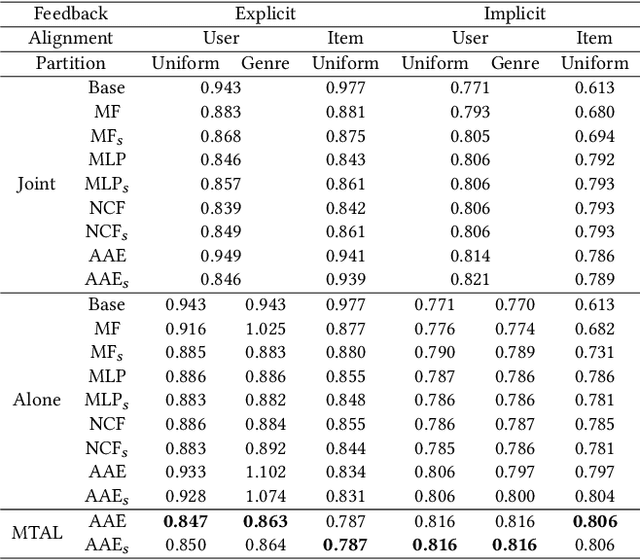
A long-standing challenge in Recommender Systems (RCs) is the data sparsity problem that often arises when users rate very few items. Multi-Target Multi-Domain Recommender Systems (MTMDR) aim to improve the recommendation performance in multiple domains simultaneously. The existing works assume that the data of different domains can be fully shared, and the computation can be performed in a centralized manner. However, in many realistic scenarios, separate recommender systems are operated by different organizations, which do not allow the sharing of private data, models, and recommendation tasks. This work proposes an MTMDR based on Assisted AutoEncoders (AAE) and Multi-Target Assisted Learning (MTAL) to help organizational learners improve their recommendation performance simultaneously without sharing sensitive assets. Moreover, AAE has a broad application scope since it allows explicit or implicit feedback, user- or item-based alignment, and with or without side information. Extensive experiments demonstrate that our method significantly outperforms the case where each domain is locally trained, and it performs competitively with the centralized training where all data are shared. As a result, AAE can effectively integrate organizations from different domains to form a community of shared interest.
Collaborative Visual Inertial SLAM for Multiple Smart Phones
Jun 23, 2021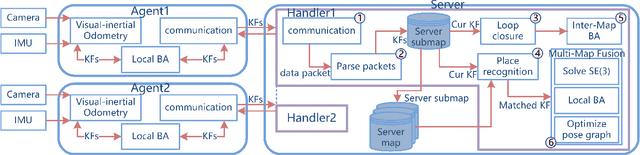
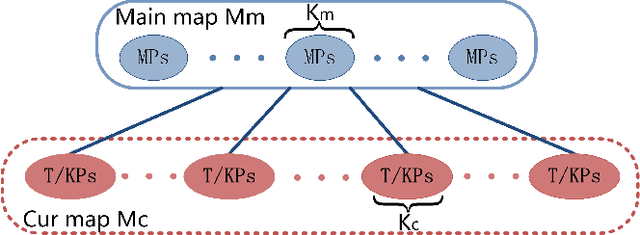
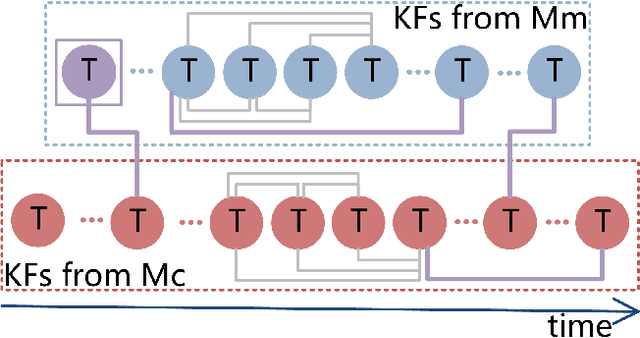
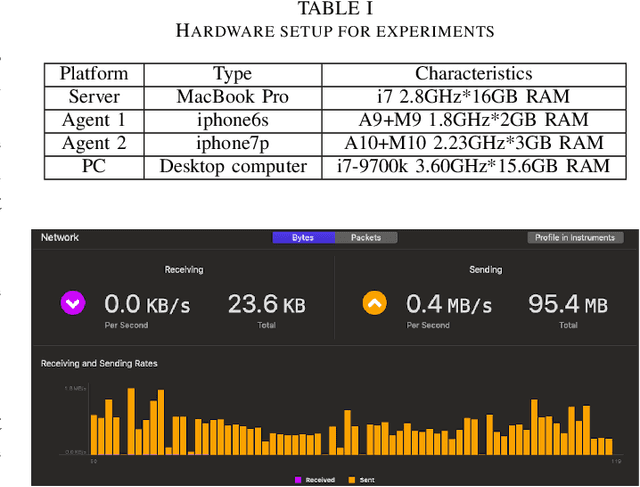
The efficiency and accuracy of mapping are crucial in a large scene and long-term AR applications. Multi-agent cooperative SLAM is the precondition of multi-user AR interaction. The cooperation of multiple smart phones has the potential to improve efficiency and robustness of task completion and can complete tasks that a single agent cannot do. However, it depends on robust communication, efficient location detection, robust mapping, and efficient information sharing among agents. We propose a multi-intelligence collaborative monocular visual-inertial SLAM deployed on multiple ios mobile devices with a centralized architecture. Each agent can independently explore the environment, run a visual-inertial odometry module online, and then send all the measurement information to a central server with higher computing resources. The server manages all the information received, detects overlapping areas, merges and optimizes the map, and shares information with the agents when needed. We have verified the performance of the system in public datasets and real environments. The accuracy of mapping and fusion of the proposed system is comparable to VINS-Mono which requires higher computing resources.
Gaussian Process Bandit Optimization with Few Batches
Oct 26, 2021
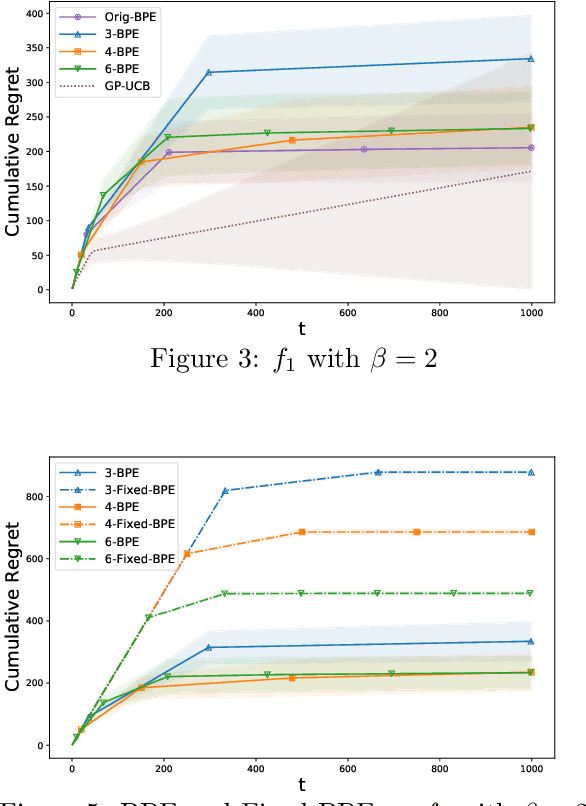
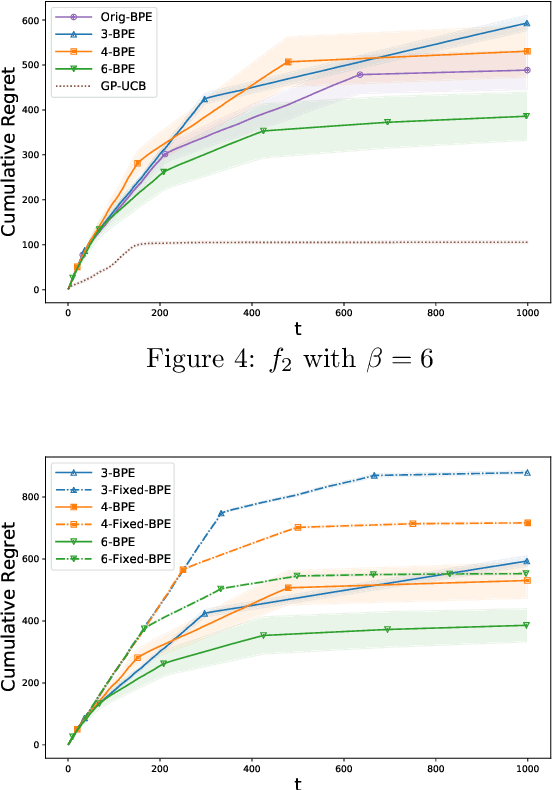
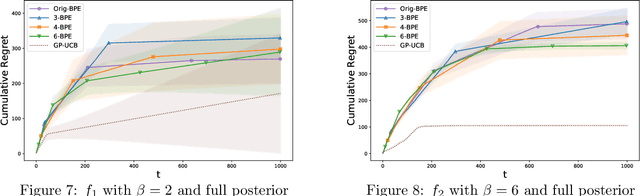
In this paper, we consider the problem of black-box optimization using Gaussian Process (GP) bandit optimization with a small number of batches. Assuming the unknown function has a low norm in the Reproducing Kernel Hilbert Space (RKHS), we introduce a batch algorithm inspired by batched finite-arm bandit algorithms, and show that it achieves the cumulative regret upper bound $O^\ast(\sqrt{T\gamma_T})$ using $O(\log\log T)$ batches within time horizon $T$, where the $O^\ast(\cdot)$ notation hides dimension-independent logarithmic factors and $\gamma_T$ is the maximum information gain associated with the kernel. This bound is near-optimal for several kernels of interest and improves on the typical $O^\ast(\sqrt{T}\gamma_T)$ bound, and our approach is arguably the simplest among algorithms attaining this improvement. In addition, in the case of a constant number of batches (not depending on $T$), we propose a modified version of our algorithm, and characterize how the regret is impacted by the number of batches, focusing on the squared exponential and Mat\'ern kernels. The algorithmic upper bounds are shown to be nearly minimax optimal via analogous algorithm-independent lower bounds.
Attention-based Multi-Reference Learning for Image Super-Resolution
Aug 31, 2021
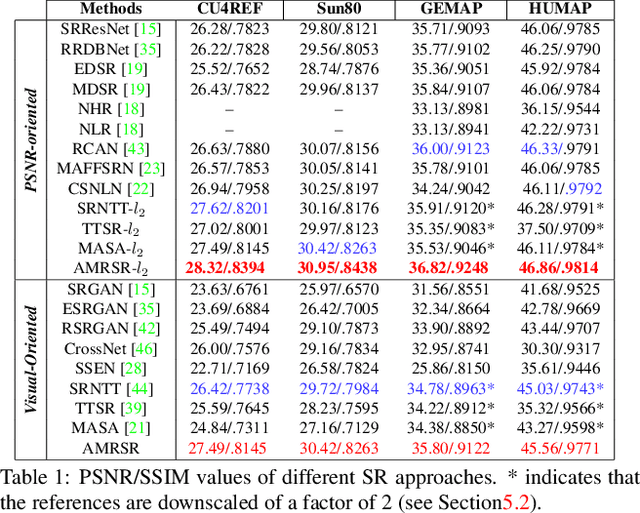
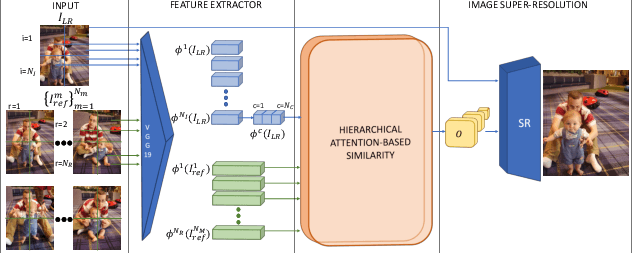
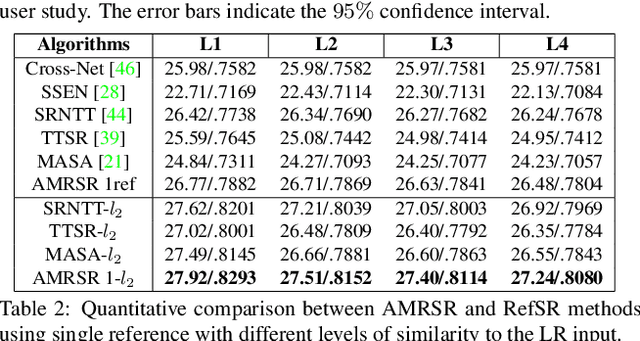
This paper proposes a novel Attention-based Multi-Reference Super-resolution network (AMRSR) that, given a low-resolution image, learns to adaptively transfer the most similar texture from multiple reference images to the super-resolution output whilst maintaining spatial coherence. The use of multiple reference images together with attention-based sampling is demonstrated to achieve significantly improved performance over state-of-the-art reference super-resolution approaches on multiple benchmark datasets. Reference super-resolution approaches have recently been proposed to overcome the ill-posed problem of image super-resolution by providing additional information from a high-resolution reference image. Multi-reference super-resolution extends this approach by providing a more diverse pool of image features to overcome the inherent information deficit whilst maintaining memory efficiency. A novel hierarchical attention-based sampling approach is introduced to learn the similarity between low-resolution image features and multiple reference images based on a perceptual loss. Ablation demonstrates the contribution of both multi-reference and hierarchical attention-based sampling to overall performance. Perceptual and quantitative ground-truth evaluation demonstrates significant improvement in performance even when the reference images deviate significantly from the target image. The project website can be found at https://marcopesavento.github.io/AMRSR/
Repaint: Improving the Generalization of Down-Stream Visual Tasks by Generating Multiple Instances of Training Examples
Oct 20, 2021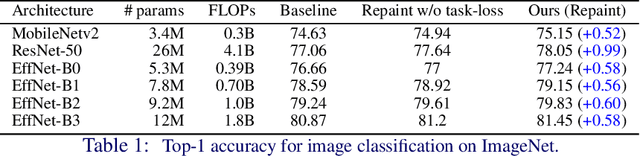
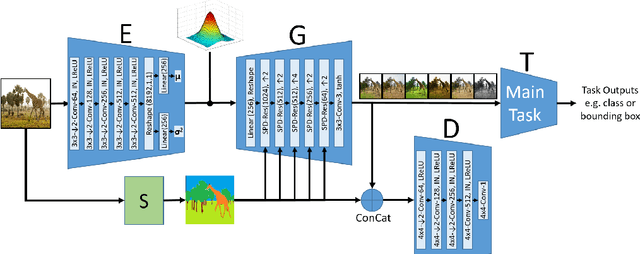
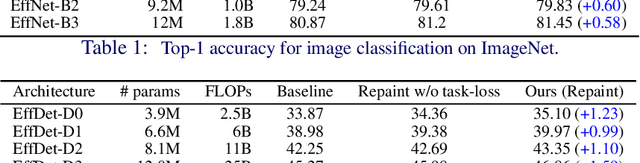
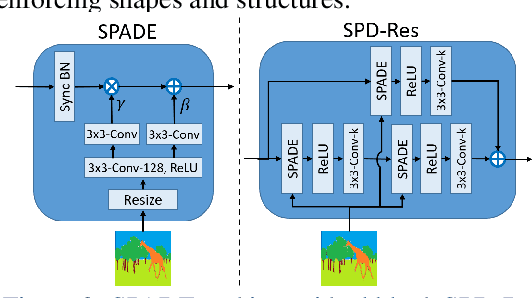
Convolutional Neural Networks (CNNs) for visual tasks are believed to learn both the low-level textures and high-level object attributes, throughout the network depth. This paper further investigates the `texture bias' in CNNs. To this end, we regenerate multiple instances of training examples from each original image, through a process we call `repainting'. The repainted examples preserve the shape and structure of the regions and objects within the scenes, but diversify their texture and color. Our method can regenerate a same image at different daylight, season, or weather conditions, can have colorization or de-colorization effects, or even bring back some texture information from blacked-out areas. The in-place repaint allows us to further use these repainted examples for improving the generalization of CNNs. Through an extensive set of experiments, we demonstrate the usefulness of the repainted examples in training, for the tasks of image classification (ImageNet) and object detection (COCO), over several state-of-the-art network architectures at different capacities, and across different data availability regimes.