 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tuna-AI: tuna biomass estimation with Machine Learning models trained on oceanography and echosounder FAD data
Sep 29, 2021
Echo-sounder data registered by buoys attached to drifting FADs provide a very valuable source of information on populations of tuna and their behaviour. This value increases whenthese data are supplemented with oceanographic data coming from CMEMS. We use these sources to develop Tuna-AI, a Machine Learning model aimed at predicting tuna biomass under a given buoy, which uses a 3-day window of echo-sounder data to capture the daily spatio-temporal patterns characteristic of tuna schools. As the supervised signal for training, we employ more than 5000 set events with their corresponding tuna catch reported by the AGAC tuna purse seine fleet.
Multi-Stream Attention Learning for Monocular Vehicle Velocity and Inter-Vehicle Distance Estimation
Oct 22, 2021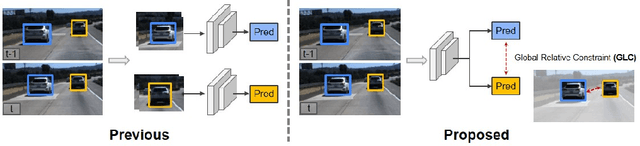
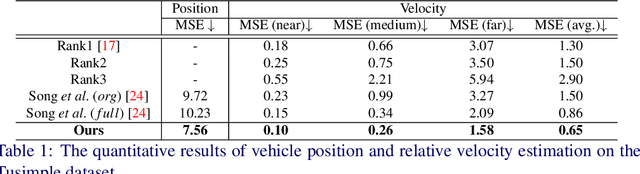
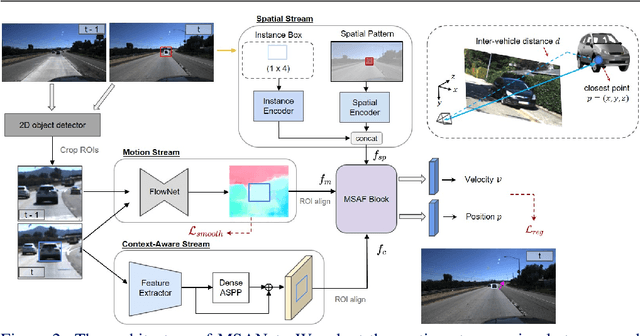

Vehicle velocity and inter-vehicle distance estimation are essential for ADAS (Advanced driver-assistance systems) and autonomous vehicles. To save the cost of expensive ranging sensors, recent studies focus on using a low-cost monocular camera to perceive the environment around the vehicle in a data-driven fashion. Existing approaches treat each vehicle independently for perception and cause inconsistent estimation. Furthermore, important information like context and spatial relation in 2D object detection is often neglected in the velocity estimation pipeline. In this paper, we explore the relationship between vehicles of the same frame with a global-relative-constraint (GLC) loss to encourage consistent estimation. A novel multi-stream attention network (MSANet) is proposed to extract different aspects of features, e.g., spatial and contextual features, for joint vehicle velocity and inter-vehicle distance estimation. Experiments show the effectiveness and robustness of our proposed approach. MSANet outperforms state-of-the-art algorithms on both the KITTI dataset and TuSimple velocity dataset.
Benchmarking Predictive Risk Models for Emergency Departments with Large Public Electronic Health Records
Nov 22, 2021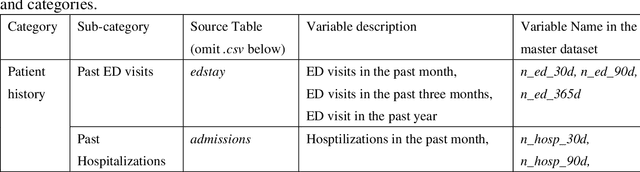
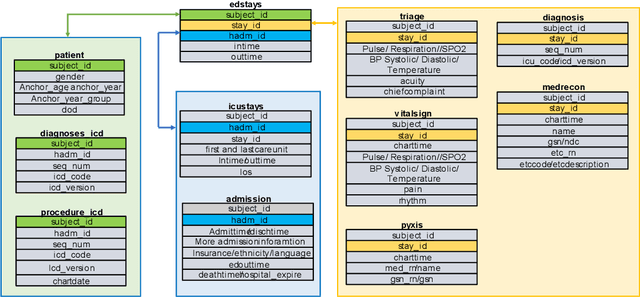
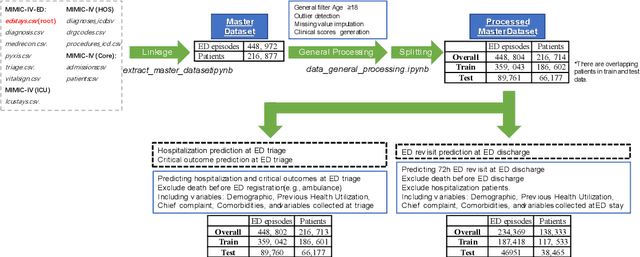
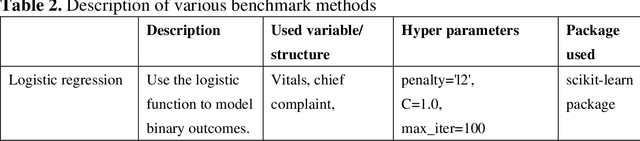
There is a continuously growing demand for emergency department (ED) services across the world, especially under the COVID-19 pandemic. Risk triaging plays a crucial role in prioritizing limited medical resources for patients who need them most. Recently the pervasive use of Electronic Health Records (EHR) has generated a large volume of stored data, accompanied by vast opportunities for the development of predictive models which could improve emergency care. However, there is an absence of widely accepted ED benchmarks based on large-scale public EHR, which new researchers could easily access. Success in filling in this gap could enable researchers to start studies on ED more quickly and conveniently without verbose data preprocessing and facilitate comparisons among different studies and methodologies. In this paper, based on the Medical Information Mart for Intensive Care IV Emergency Department (MIMIC-IV-ED) database, we proposed a public ED benchmark suite and obtained a benchmark dataset containing over 500,000 ED visits episodes from 2011 to 2019. Three ED-based prediction tasks (hospitalization, critical outcomes, and 72-hour ED revisit) were introduced, where various popular methodologies, from machine learning methods to clinical scoring systems, were implemented. The results of their performance were evaluated and compared. Our codes are open-source so that anyone with access to MIMIC-IV-ED could follow the same steps of data processing, build the benchmarks, and reproduce the experiments. This study provided insights, suggestions, as well as protocols for future researchers to process the raw data and quickly build up models for emergency care.
Wide and Narrow: Video Prediction from Context and Motion
Oct 22, 2021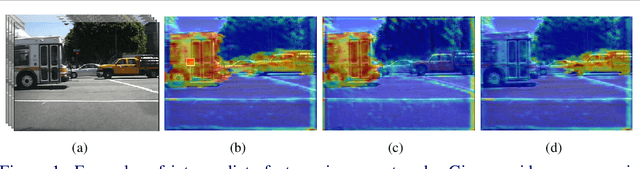

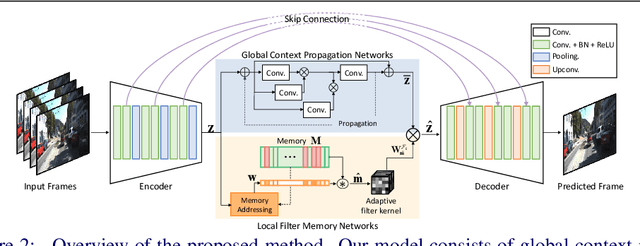
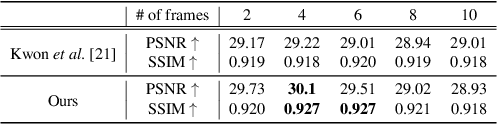
Video prediction, forecasting the future frames from a sequence of input frames, is a challenging task since the view changes are influenced by various factors, such as the global context surrounding the scene and local motion dynamics. In this paper, we propose a new framework to integrate these complementary attributes to predict complex pixel dynamics through deep networks. We present global context propagation networks that iteratively aggregate the non-local neighboring representations to preserve the contextual information over the past frames. To capture the local motion pattern of objects, we also devise local filter memory networks that generate adaptive filter kernels by storing the prototypical motion of moving objects in the memory. The proposed framework, utilizing the outputs from both networks, can address blurry predictions and color distortion. We conduct experiments on Caltech pedestrian and UCF101 datasets, and demonstrate state-of-the-art results. Especially for multi-step prediction, we obtain an outstanding performance in quantitative and qualitative evaluation.
Understanding Human Reading Comprehension with Brain Signals
Aug 04, 2021
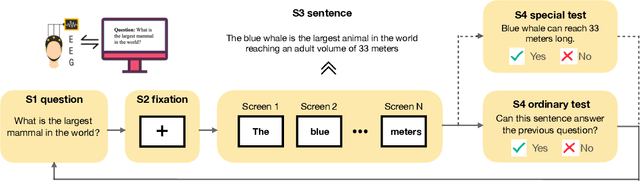
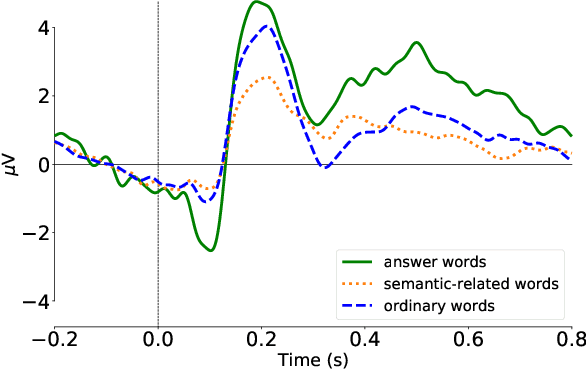

Reading comprehension is a complex cognitive process involving many human brain activities. Plenty of works have studied the reading patterns and attention allocation mechanisms in the reading process. However, little is known about what happens in human brain during reading comprehension and how we can utilize this information as implicit feedback to facilitate information acquisition performance. With the advances in brain imaging techniques such as EEG, it is possible to collect high-precision brain signals in almost real time. With neuroimaging techniques, we carefully design a lab-based user study to investigate brain activities during reading comprehension. Our findings show that neural responses vary with different types of contents, i.e., contents that can satisfy users' information needs and contents that cannot. We suggest that various cognitive activities, e.g., cognitive loading, semantic-thematic understanding, and inferential processing, at the micro-time scale during reading comprehension underpin these neural responses. Inspired by these detectable differences in cognitive activities, we construct supervised learning models based on EEG features for two reading comprehension tasks: answer sentence classification and answer extraction. Results show that it is feasible to improve their performance with brain signals. These findings imply that brain signals are valuable feedback for enhancing human-computer interactions during reading comprehension.
Towards Multi-Functional 6G Wireless Networks: Integrating Sensing, Communication and Security
Jul 16, 2021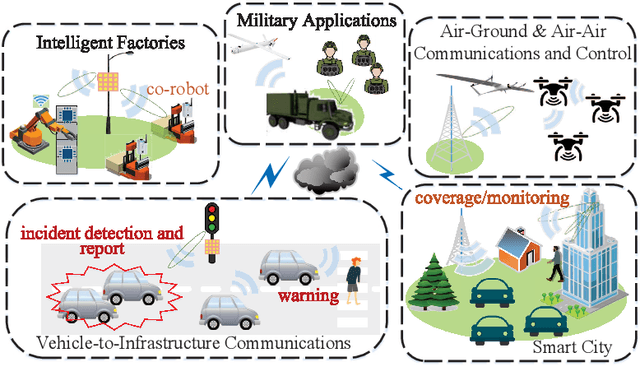
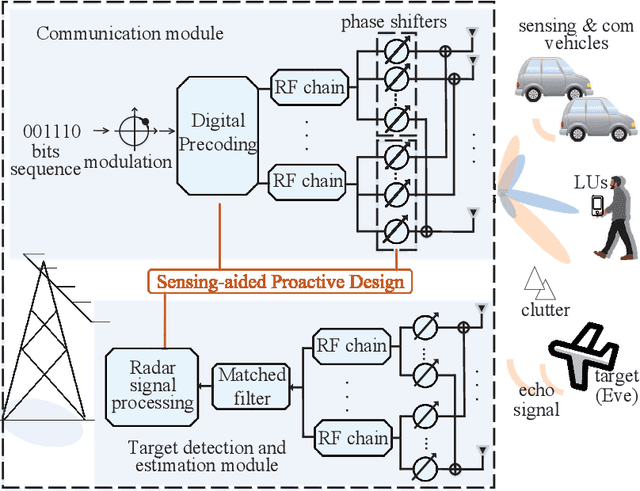
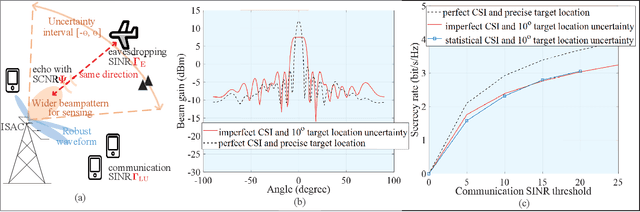
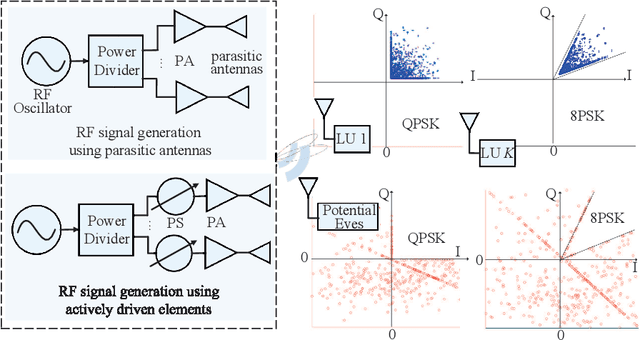
Integrated sensing and communication (ISAC) has recently emerged as a candidate 6G technology, aiming to unify the two key operations of the future network in spectrum/energy/cost efficient way. ISAC involves communicating information to receivers and simultaneously sensing targets, while both operations use the same waveforms, the same transmitter and ultimately the same network infrastructure. Nevertheless, the inclusion of information signalling into the probing waveform for target sensing raises unique and difficult challenges from the perspective of information security. At the same time, the sensing capability incorporated in the ISAC transmission offers unique opportunities to design secure ISAC techniques. This overview paper discusses these unique challenges and opportunities for the next generation of ISAC networks. We first briefly discuss the fundamentals of waveform design for sensing and communication. Then, we detail the challenges and contradictory objectives involved in securing ISAC transmission, along with state-of-the-art approaches to address them. We then identify the new opportunity of using the sensing capability to obtain knowledge of the targets, as an enabling approach against known weaknesses of PHY security. Finally, we illustrate a low-cost secure ISAC architecture, followed by a series of open research topics. This family of sensing-aided secure ISAC techniques brings a new insight on providing information security, with an eye on robust and hardware-constrained designs tailored for low-cost ISAC devices.
An Approach for Combining Multimodal Fusion and Neural Architecture Search Applied to Knowledge Tracing
Nov 08, 2021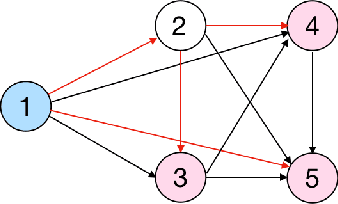
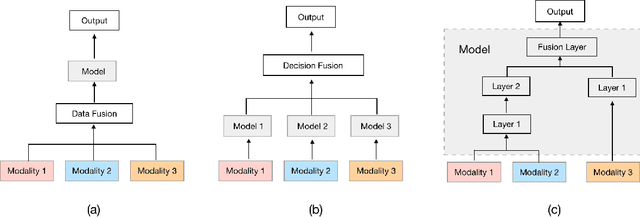
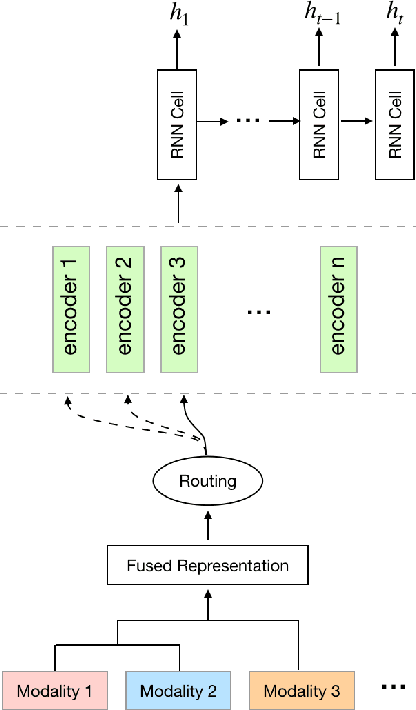
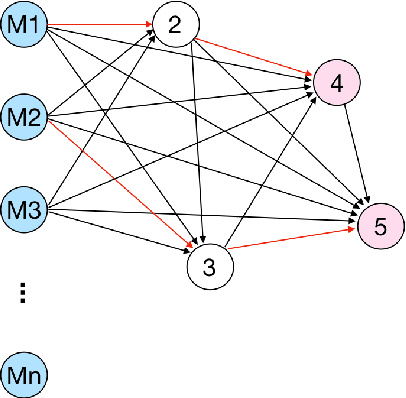
Knowledge Tracing is the process of tracking mastery level of different skills of students for a given learning domain. It is one of the key components for building adaptive learning systems and has been investigated for decades. In parallel with the success of deep neural networks in other fields, we have seen researchers take similar approaches in the learning science community. However, most existing deep learning based knowledge tracing models either: (1) only use the correct/incorrect response (ignoring useful information from other modalities) or (2) design their network architectures through domain expertise via trial and error. In this paper, we propose a sequential model based optimization approach that combines multimodal fusion and neural architecture search within one framework. The commonly used neural architecture search technique could be considered as a special case of our proposed approach when there is only one modality involved. We further propose to use a new metric called time-weighted Area Under the Curve (weighted AUC) to measure how a sequence model performs with time. We evaluate our methods on two public real datasets showing the discovered model is able to achieve superior performance. Unlike most existing works, we conduct McNemar's test on the model predictions and the results are statistically significant.
A Data Bootstrapping Recipe for Low Resource Multilingual Relation Classification
Oct 18, 2021

Relation classification (sometimes called 'extraction') requires trustworthy datasets for fine-tuning large language models, as well as for evaluation. Data collection is challenging for Indian languages, because they are syntactically and morphologically diverse, as well as different from resource-rich languages like English. Despite recent interest in deep generative models for Indian languages, relation classification is still not well served by public data sets. In response, we present IndoRE, a dataset with 21K entity and relation tagged gold sentences in three Indian languages, plus English. We start with a multilingual BERT (mBERT) based system that captures entity span positions and type information and provides competitive monolingual relation classification. Using this system, we explore and compare transfer mechanisms between languages. In particular, we study the accuracy efficiency tradeoff between expensive gold instances vs. translated and aligned 'silver' instances. We release the dataset for future research.
Not Color Blind: AI Predicts Racial Identity from Black and White Retinal Vessel Segmentations
Sep 28, 2021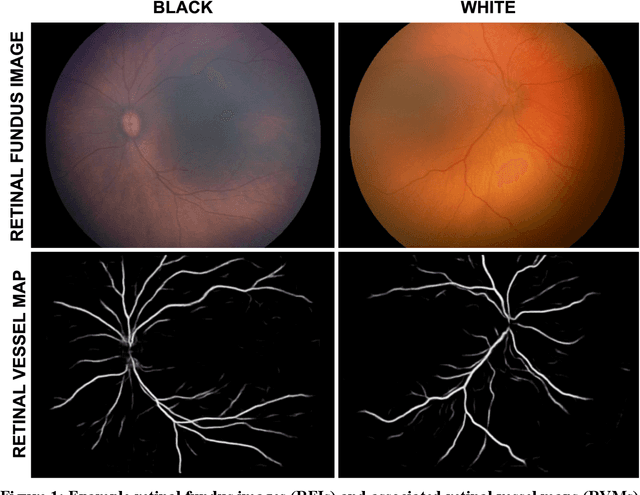
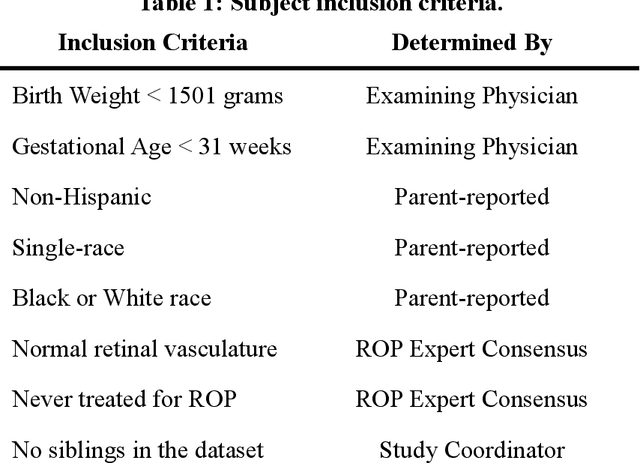
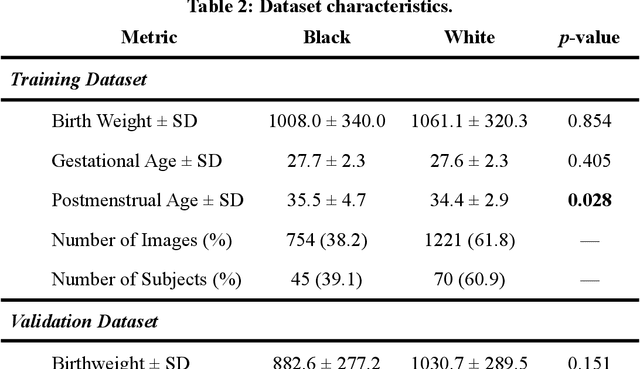
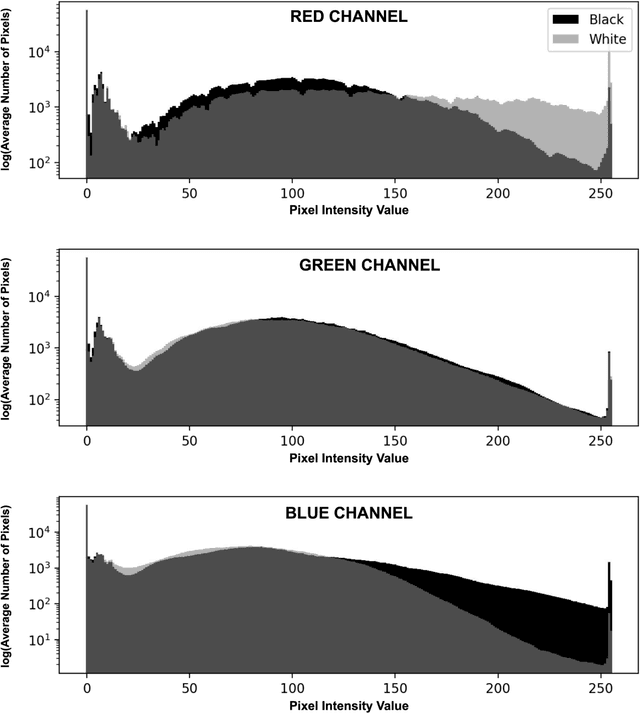
Background: Artificial intelligence (AI) may demonstrate racial bias when skin or choroidal pigmentation is present in medical images. Recent studies have shown that convolutional neural networks (CNNs) can predict race from images that were not previously thought to contain race-specific features. We evaluate whether grayscale retinal vessel maps (RVMs) of patients screened for retinopathy of prematurity (ROP) contain race-specific features. Methods: 4095 retinal fundus images (RFIs) were collected from 245 Black and White infants. A U-Net generated RVMs from RFIs, which were subsequently thresholded, binarized, or skeletonized. To determine whether RVM differences between Black and White eyes were physiological, CNNs were trained to predict race from color RFIs, raw RVMs, and thresholded, binarized, or skeletonized RVMs. Area under the precision-recall curve (AUC-PR) was evaluated. Findings: CNNs predicted race from RFIs near perfectly (image-level AUC-PR: 0.999, subject-level AUC-PR: 1.000). Raw RVMs were almost as informative as color RFIs (image-level AUC-PR: 0.938, subject-level AUC-PR: 0.995). Ultimately, CNNs were able to detect whether RFIs or RVMs were from Black or White babies, regardless of whether images contained color, vessel segmentation brightness differences were nullified, or vessel segmentation widths were normalized. Interpretation: AI can detect race from grayscale RVMs that were not thought to contain racial information. Two potential explanations for these findings are that: retinal vessels physiologically differ between Black and White babies or the U-Net segments the retinal vasculature differently for various fundus pigmentations. Either way, the implications remain the same: AI algorithms have potential to demonstrate racial bias in practice, even when preliminary attempts to remove such information from the underlying images appear to be successful.
Description-based Label Attention Classifier for Explainable ICD-9 Classification
Sep 24, 2021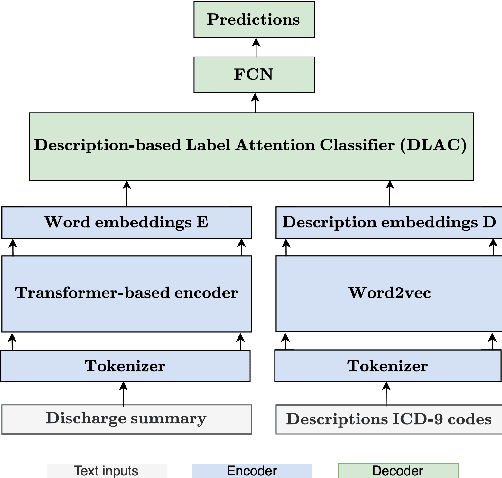
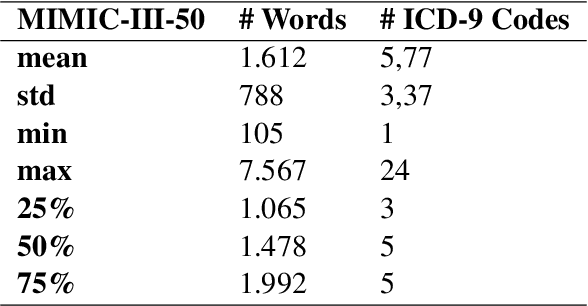
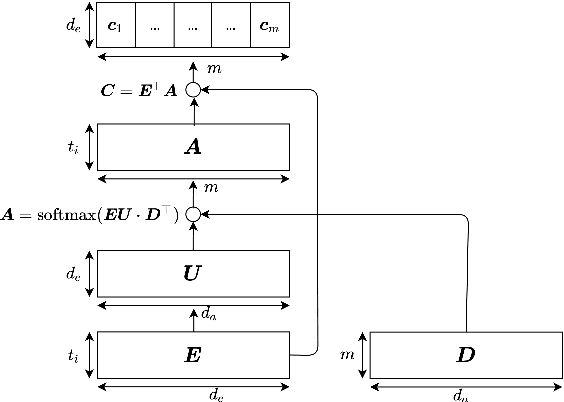
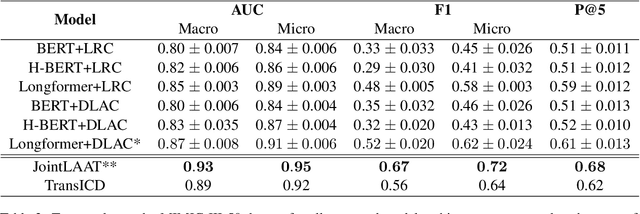
ICD-9 coding is a relevant clinical billing task, where unstructured texts with information about a patient's diagnosis and treatments are annotated with multiple ICD-9 codes. Automated ICD-9 coding is an active research field, where CNN- and RNN-based model architectures represent the state-of-the-art approaches. In this work, we propose a description-based label attention classifier to improve the model explainability when dealing with noisy texts like clinical notes. We evaluate our proposed method with different transformer-based encoders on the MIMIC-III-50 dataset. Our method achieves strong results together with augmented explainablilty.