 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Selective Regression Under Fairness Criteria
Oct 28, 2021
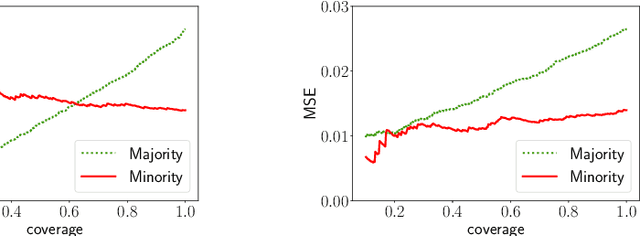
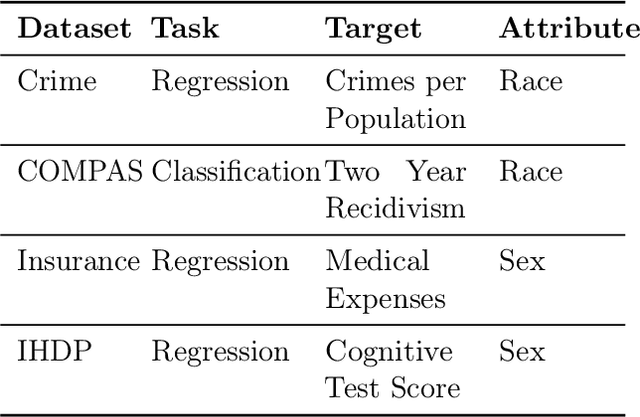
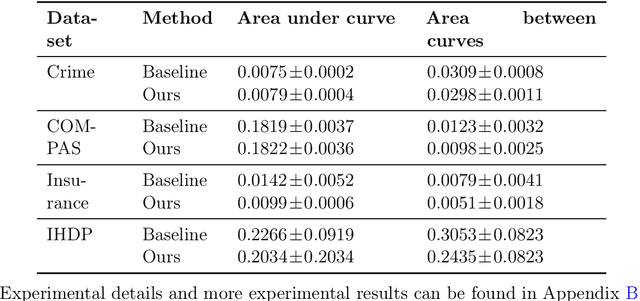
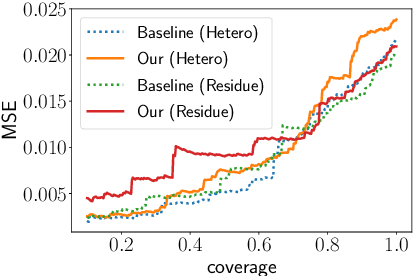
Selective regression allows abstention from prediction if the confidence to make an accurate prediction is not sufficient. In general, by allowing a reject option, one expects the performance of a regression model to increase at the cost of reducing coverage (i.e., by predicting fewer samples). However, as shown in this work, in some cases, the performance of minority group can decrease while we reduce the coverage, and thus selective regression can magnify disparities between different sensitive groups. We show that such an unwanted behavior can be avoided if we can construct features satisfying the sufficiency criterion, so that the mean prediction and the associated uncertainty are calibrated across all the groups. Further, to mitigate the disparity in the performance across groups, we introduce two approaches based on this calibration criterion: (a) by regularizing an upper bound of conditional mutual information under a Gaussian assumption and (b) by regularizing a contrastive loss for mean and uncertainty prediction. The effectiveness of these approaches are demonstrated on synthetic as well as real-world datasets.
Bayesian Sequential Optimal Experimental Design for Nonlinear Models Using Policy Gradient Reinforcement Learning
Oct 28, 2021

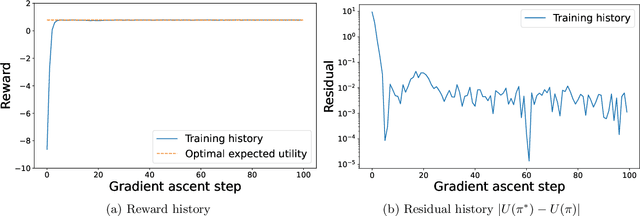
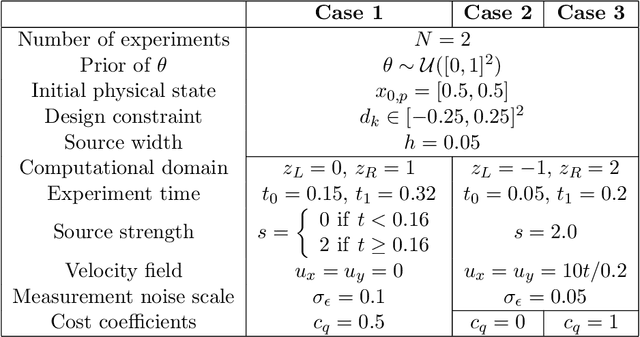
We present a mathematical framework and computational methods to optimally design a finite number of sequential experiments. We formulate this sequential optimal experimental design (sOED) problem as a finite-horizon partially observable Markov decision process (POMDP) in a Bayesian setting and with information-theoretic utilities. It is built to accommodate continuous random variables, general non-Gaussian posteriors, and expensive nonlinear forward models. sOED then seeks an optimal design policy that incorporates elements of both feedback and lookahead, generalizing the suboptimal batch and greedy designs. We solve for the sOED policy numerically via policy gradient (PG) methods from reinforcement learning, and derive and prove the PG expression for sOED. Adopting an actor-critic approach, we parameterize the policy and value functions using deep neural networks and improve them using gradient estimates produced from simulated episodes of designs and observations. The overall PG-sOED method is validated on a linear-Gaussian benchmark, and its advantages over batch and greedy designs are demonstrated through a contaminant source inversion problem in a convection-diffusion field.
MEGAN: Memory Enhanced Graph Attention Network for Space-Time Video Super-Resolution
Oct 28, 2021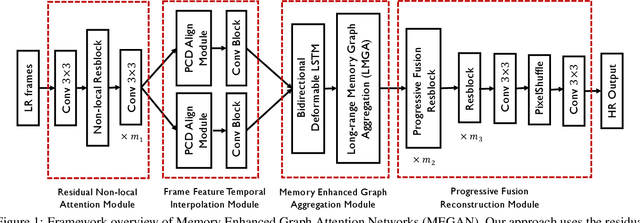
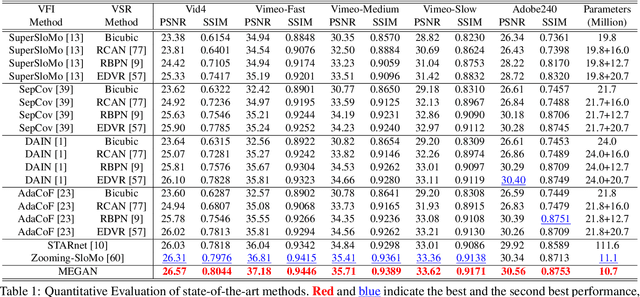
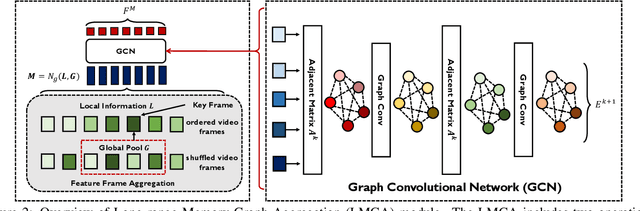
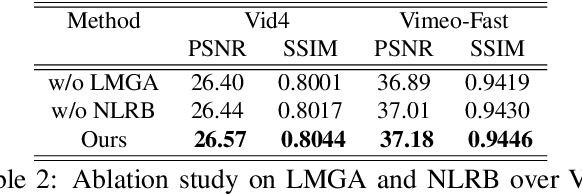
Space-time video super-resolution (STVSR) aims to construct a high space-time resolution video sequence from the corresponding low-frame-rate, low-resolution video sequence. Inspired by the recent success to consider spatial-temporal information for space-time super-resolution, our main goal in this work is to take full considerations of spatial and temporal correlations within the video sequences of fast dynamic events. To this end, we propose a novel one-stage memory enhanced graph attention network (MEGAN) for space-time video super-resolution. Specifically, we build a novel long-range memory graph aggregation (LMGA) module to dynamically capture correlations along the channel dimensions of the feature maps and adaptively aggregate channel features to enhance the feature representations. We introduce a non-local residual block, which enables each channel-wise feature to attend global spatial hierarchical features. In addition, we adopt a progressive fusion module to further enhance the representation ability by extensively exploiting spatial-temporal correlations from multiple frames. Experiment results demonstrate that our method achieves better results compared with the state-of-the-art methods quantitatively and visually.
Heuristical choice of SVM parameters
Nov 03, 2021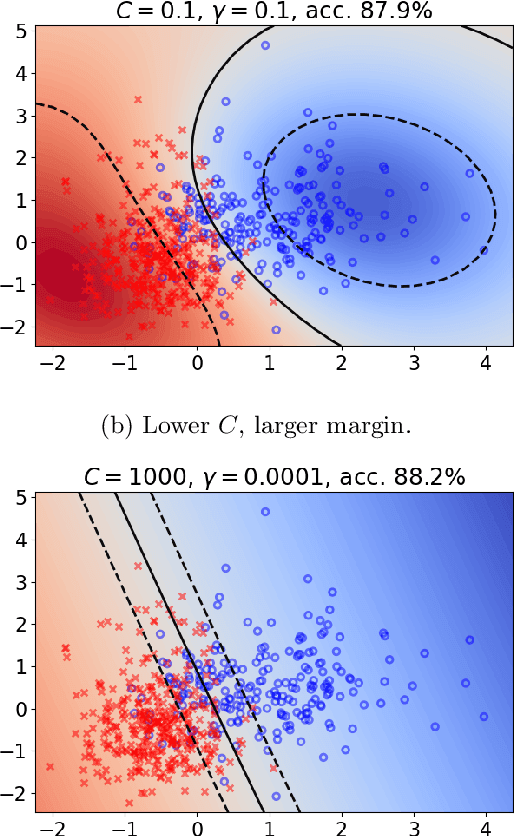
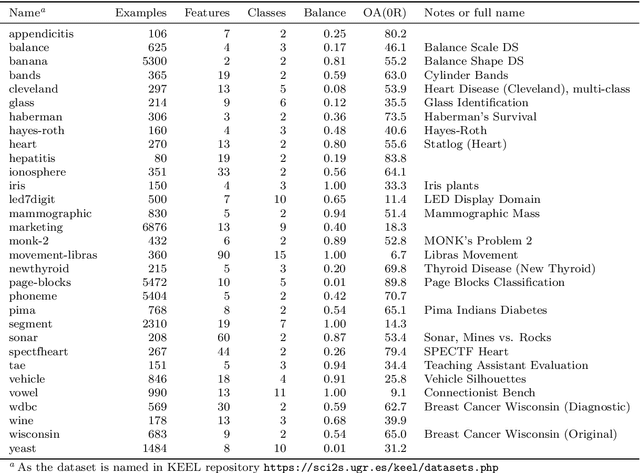
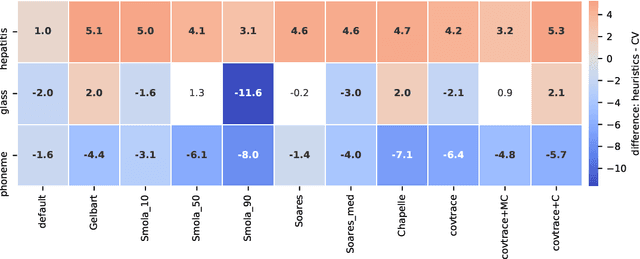
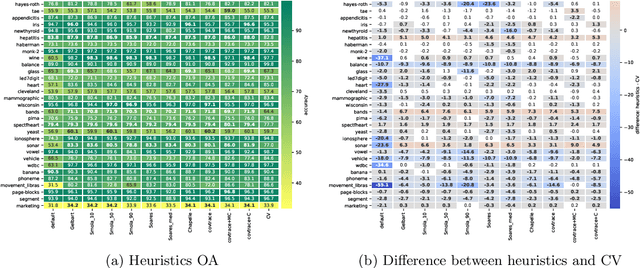
Support Vector Machine (SVM) is one of the most popular classification methods, and a de-facto reference for many Machine Learning approaches. Its performance is determined by parameter selection, which is usually achieved by a time-consuming grid search cross-validation procedure. There exist, however, several unsupervised heuristics that take advantage of the characteristics of the dataset for selecting parameters instead of using class label information. Unsupervised heuristics, while an order of magnitude faster, are scarcely used under the assumption that their results are significantly worse than those of grid search. To challenge that assumption we have conducted a wide study of various heuristics for SVM parameter selection on over thirty datasets, in both supervised and semi-supervised scenarios. In most cases, the cross-validation grid search did not achieve a significant advantage over the heuristics. In particular, heuristical parameter selection may be preferable for high dimensional and unbalanced datasets or when a small number of examples is available. Our results also show that using a heuristic to determine the starting point of further cross-validation does not yield significantly better results than the default start.
On the Fairness of Machine-Assisted Human Decisions
Oct 28, 2021
When machine-learning algorithms are deployed in high-stakes decisions, we want to ensure that their deployment leads to fair and equitable outcomes. This concern has motivated a fast-growing literature that focuses on diagnosing and addressing disparities in machine predictions. However, many machine predictions are deployed to assist in decisions where a human decision-maker retains the ultimate decision authority. In this article, we therefore consider how properties of machine predictions affect the resulting human decisions. We show in a formal model that the inclusion of a biased human decision-maker can revert common relationships between the structure of the algorithm and the qualities of resulting decisions. Specifically, we document that excluding information about protected groups from the prediction may fail to reduce, and may even increase, ultimate disparities. While our concrete results rely on specific assumptions about the data, algorithm, and decision-maker, they show more broadly that any study of critical properties of complex decision systems, such as the fairness of machine-assisted human decisions, should go beyond focusing on the underlying algorithmic predictions in isolation.
Unsupervised embedding and similarity detection of microregions using public transport schedules
Nov 03, 2021
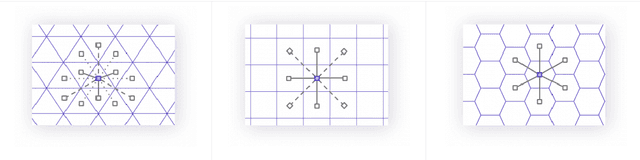
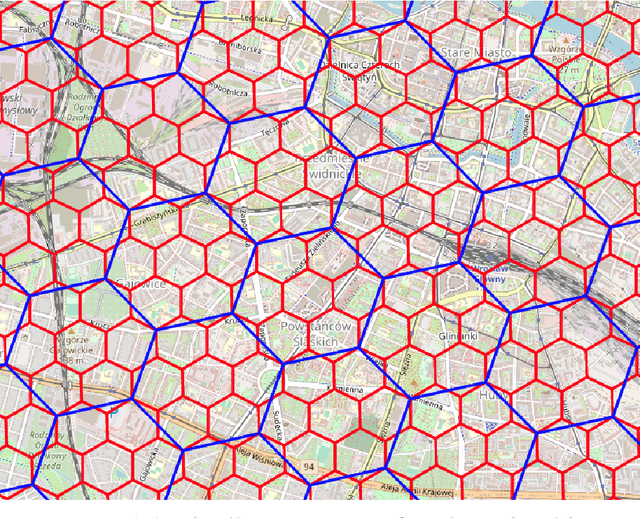
The role of spatial data in tackling city-related tasks has been growing in recent years. To use them in machine learning models, it is often necessary to transform them into a vector representation, which has led to the development in the field of spatial data representation learning. There is also a growing variety of spatial data types for which representation learning methods are proposed. Public transport timetables have so far not been used in the task of learning representations of regions in a city. In this work, a method is developed to embed public transport availability information into vector space. To conduct experiments on its application, public transport timetables were collected from 48 European cities. Using the H3 spatial indexing method, they were divided into micro-regions. A method was also proposed to identify regions with similar characteristics of public transport offers. On its basis, a multi-level typology of public transport offers in the regions was defined. This thesis shows that the proposed representation method makes it possible to identify micro-regions with similar public transport characteristics between the cities, and can be used to evaluate the quality of public transport available in a city.
WhyAct: Identifying Action Reasons in Lifestyle Vlogs
Sep 09, 2021
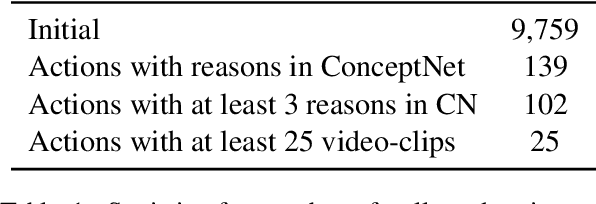

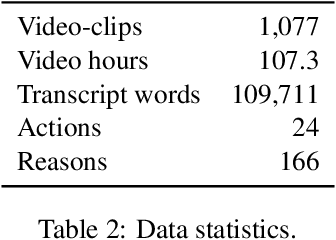
We aim to automatically identify human action reasons in online videos. We focus on the widespread genre of lifestyle vlogs, in which people perform actions while verbally describing them. We introduce and make publicly available the WhyAct dataset, consisting of 1,077 visual actions manually annotated with their reasons. We describe a multimodal model that leverages visual and textual information to automatically infer the reasons corresponding to an action presented in the video.
JPS-daprinfo: A Dataset for Japanese Dialog Act Analysis and People-related Information Detection
Mar 06, 2021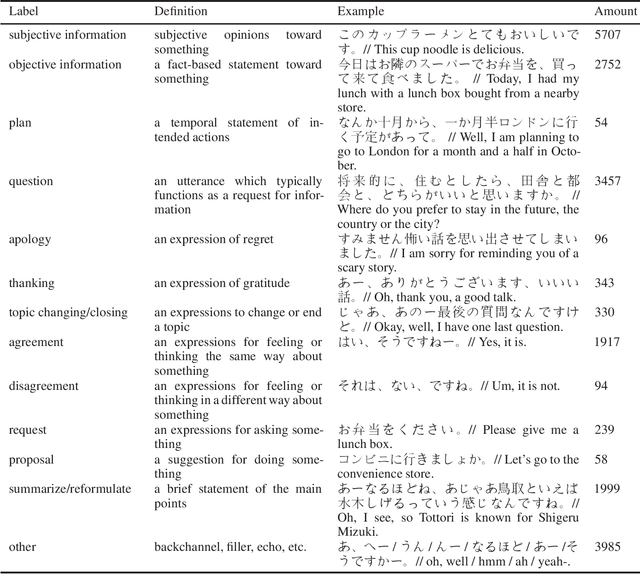
We conducted a labeling work on a spoken Japanese dataset (I-JAS) for the text classification, which contains 50 interview dialogues of two-way Japanese conversation that discuss the participants' past present and future. Each dialogue is 30 minutes long. From this dataset, we selected the interview dialogues of native Japanese speakers as the samples. Given the dataset, we annotated sentences with 13 labels. The labeling work was conducted by native Japanese speakers who have experiences with data annotation. The total amount of the annotated samples is 20130.
RAANet: Range-Aware Attention Network for LiDAR-based 3D Object Detection with Auxiliary Density Level Estimation
Nov 18, 2021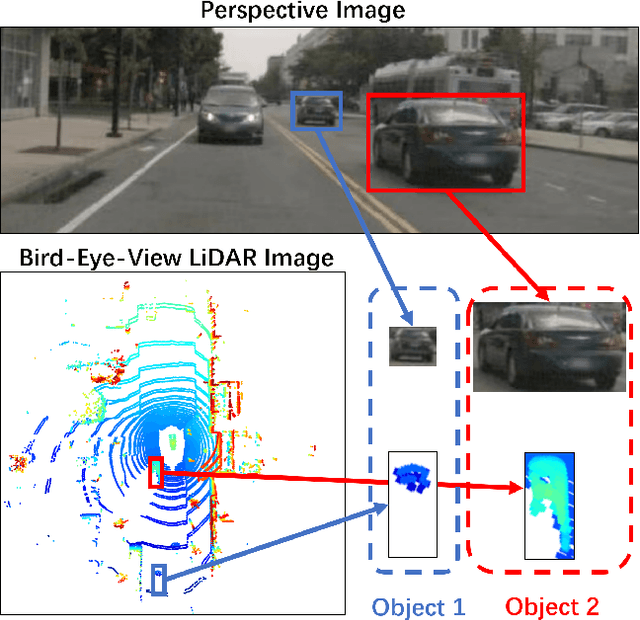
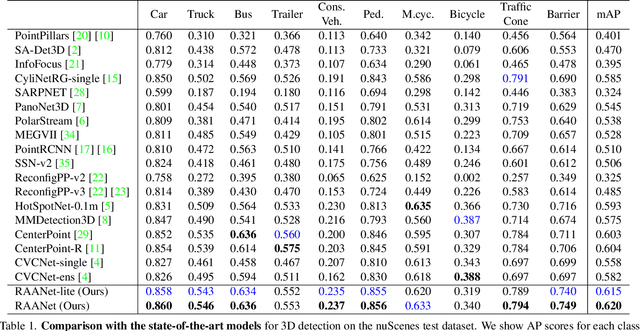
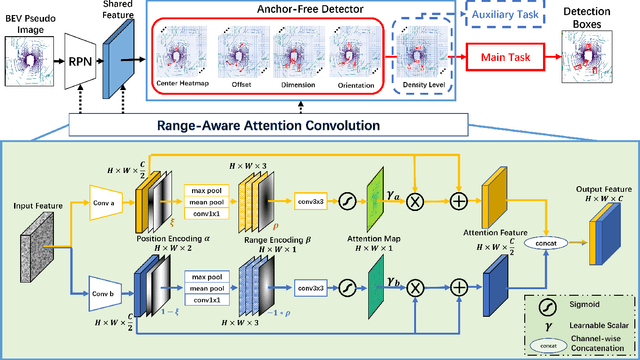

3D object detection from LiDAR data for autonomous driving has been making remarkable strides in recent years. Among the state-of-the-art methodologies, encoding point clouds into a bird's-eye view (BEV) has been demonstrated to be both effective and efficient. Different from perspective views, BEV preserves rich spatial and distance information between objects; and while farther objects of the same type do not appear smaller in the BEV, they contain sparser point cloud features. This fact weakens BEV feature extraction using shared-weight convolutional neural networks. In order to address this challenge, we propose Range-Aware Attention Network (RAANet), which extracts more powerful BEV features and generates superior 3D object detections. The range-aware attention (RAA) convolutions significantly improve feature extraction for near as well as far objects. Moreover, we propose a novel auxiliary loss for density estimation to further enhance the detection accuracy of RAANet for occluded objects. It is worth to note that our proposed RAA convolution is lightweight and compatible to be integrated into any CNN architecture used for the BEV detection. Extensive experiments on the nuScenes dataset demonstrate that our proposed approach outperforms the state-of-the-art methods for LiDAR-based 3D object detection, with real-time inference speed of 16 Hz for the full version and 22 Hz for the lite version. The code is publicly available at an anonymous Github repository https://github.com/anonymous0522/RAAN.
Learning protein sequence embeddings using information from structure
Feb 22, 2019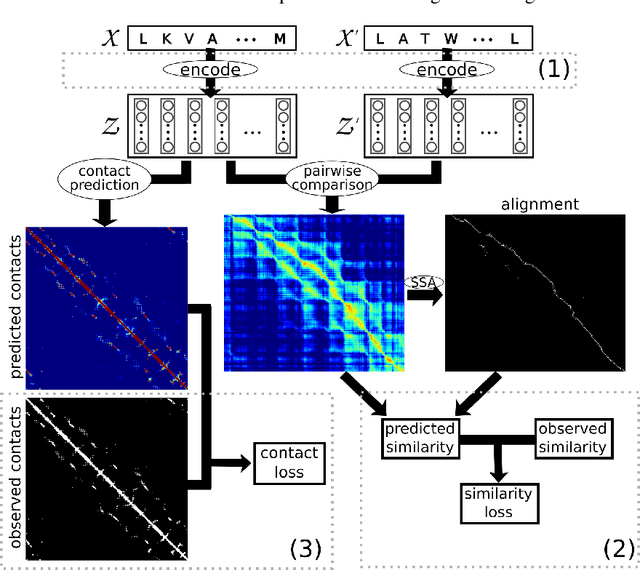
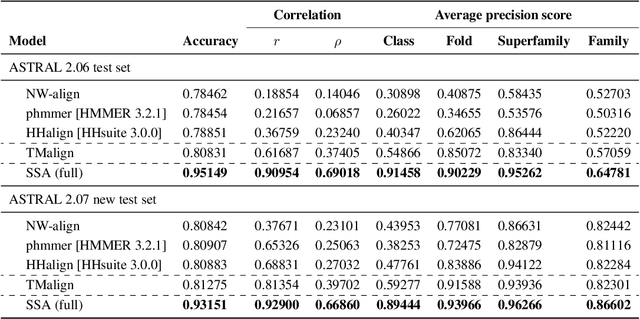
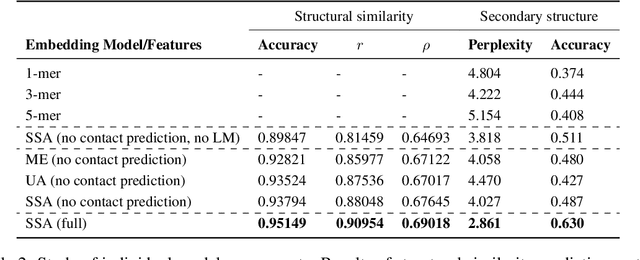
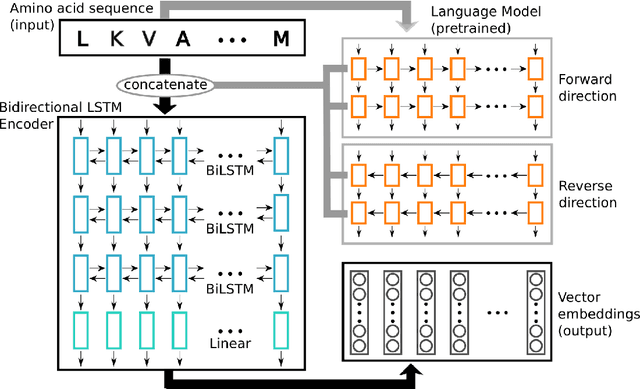
Inferring the structural properties of a protein from its amino acid sequence is a challenging yet important problem in biology. Structures are not known for the vast majority of protein sequences, but structure is critical for understanding function. Existing approaches for detecting structural similarity between proteins from sequence are unable to recognize and exploit structural patterns when sequences have diverged too far, limiting our ability to transfer knowledge between structurally related proteins. We newly approach this problem through the lens of representation learning. We introduce a framework that maps any protein sequence to a sequence of vector embeddings --- one per amino acid position --- that encode structural information. We train bidirectional long short-term memory (LSTM) models on protein sequences with a two-part feedback mechanism that incorporates information from (i) global structural similarity between proteins and (ii) pairwise residue contact maps for individual proteins. To enable learning from structural similarity information, we define a novel similarity measure between arbitrary-length sequences of vector embeddings based on a soft symmetric alignment (SSA) between them. Our method is able to learn useful position-specific embeddings despite lacking direct observations of position-level correspondence between sequences. We show empirically that our multi-task framework outperforms other sequence-based methods and even a top-performing structure-based alignment method when predicting structural similarity, our goal. Finally, we demonstrate that our learned embeddings can be transferred to other protein sequence problems, improving the state-of-the-art in transmembrane domain prediction.
* 17 pages, 3 figures, 8 tables, proceedings of ICLR 2019