 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
No-Reference Image Quality Assessment via Transformers, Relative Ranking, and Self-Consistency
Aug 16, 2021

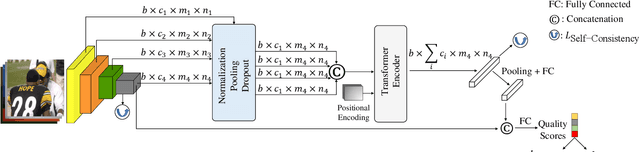
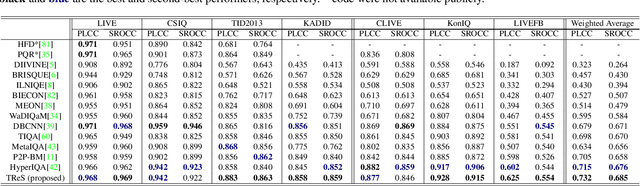
The goal of No-Reference Image Quality Assessment (NR-IQA) is to estimate the perceptual image quality in accordance with subjective evaluations, it is a complex and unsolved problem due to the absence of the pristine reference image. In this paper, we propose a novel model to address the NR-IQA task by leveraging a hybrid approach that benefits from Convolutional Neural Networks (CNNs) and self-attention mechanism in Transformers to extract both local and non-local features from the input image. We capture local structure information of the image via CNNs, then to circumvent the locality bias among the extracted CNNs features and obtain a non-local representation of the image, we utilize Transformers on the extracted features where we model them as a sequential input to the Transformer model. Furthermore, to improve the monotonicity correlation between the subjective and objective scores, we utilize the relative distance information among the images within each batch and enforce the relative ranking among them. Last but not least, we observe that the performance of NR-IQA models degrades when we apply equivariant transformations (e.g. horizontal flipping) to the inputs. Therefore, we propose a method that leverages self-consistency as a source of self-supervision to improve the robustness of NRIQA models. Specifically, we enforce self-consistency between the outputs of our quality assessment model for each image and its transformation (horizontally flipped) to utilize the rich self-supervisory information and reduce the uncertainty of the model. To demonstrate the effectiveness of our work, we evaluate it on seven standard IQA datasets (both synthetic and authentic) and show that our model achieves state-of-the-art results on various datasets.
Giga-voxel multidimensional fluorescence imaging combining single-pixel detection and data fusion
Jul 26, 2021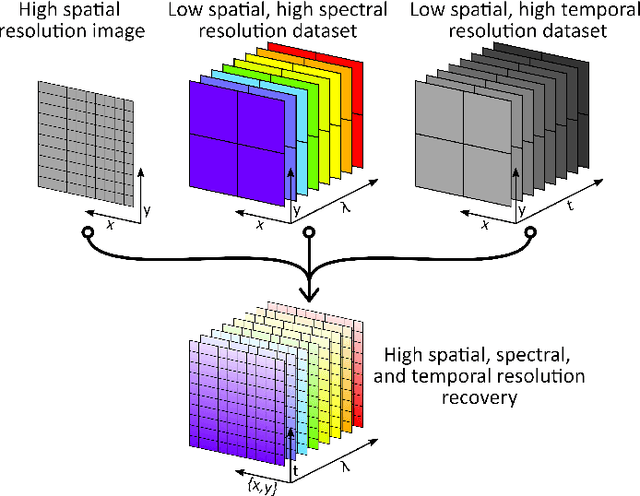
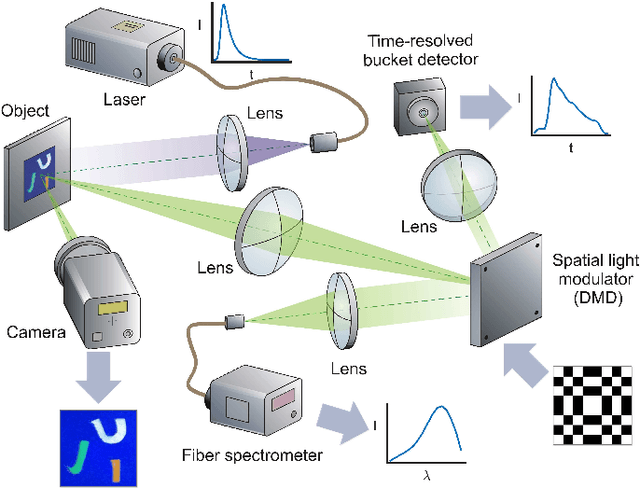
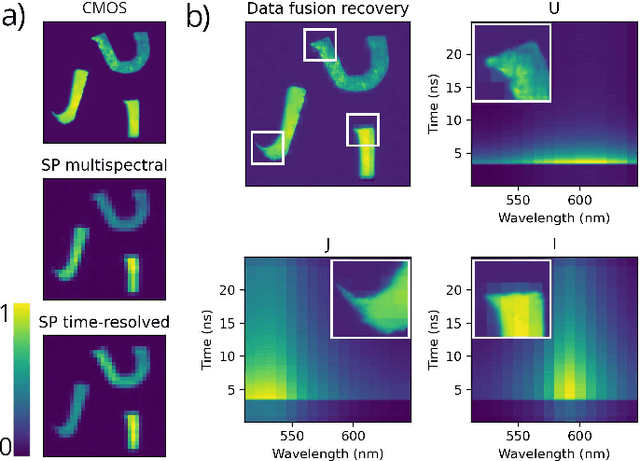
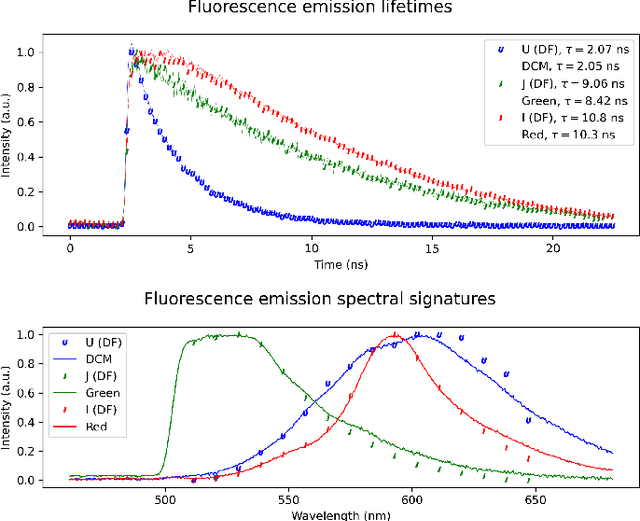
Time-resolved fluorescence imaging is a key tool in biomedical applications, as it allows to non-invasively obtain functional and structural information. However, the big amount of collected data introduces challenges in both acquisition speed and processing needs. Here, we introduce a novel technique that allows to reconstruct a Giga-voxel 4D hypercube in a fast manner while only measuring 0.03 % of the information. The system combines two single-pixel cameras and a conventional 2D array detector working in parallel. Data fusion techniques are introduced to combine the individual 2D and 3D projections acquired by each sensor in the final high-resolution 4D hypercube, which can be used to identify different fluorophore species by their spectral and temporal signatures.
Modelling and optimization of nanovector synthesis for applications in drug delivery systems
Nov 10, 2021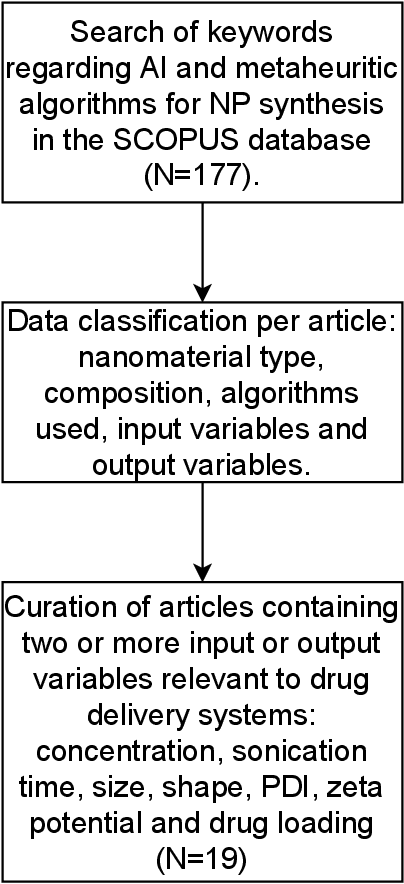

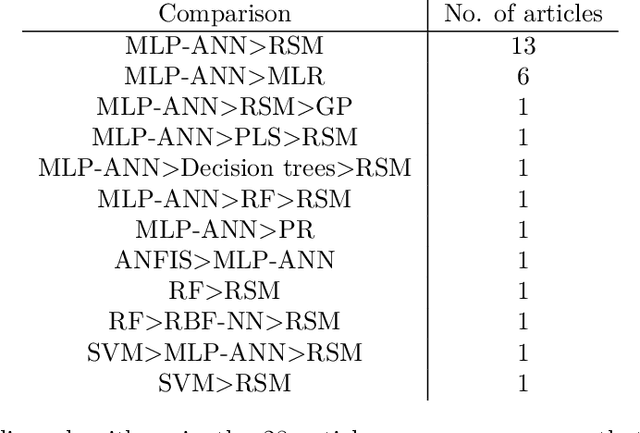
Nanovectors (NVs), based on nanostructured matter such as nanoparticles (NPs), have proven to perform as excellent drug delivery systems. However, due to the great variety of potential NVs, including NPs materials and their functionalization, in addition to the plethora of molecules that could transport, this fields presents a great challenge in terms of resources to find NVs with the most optimal physicochemical properties such as particle size and drug loading, where most of efforts rely on trial and error experimentation. In this regard, Artificial intelligence (AI) and metaheuristic algorithms offer efficient of the state-of-the-art modelling and optimization, respectively. This review focuses, through a systematic search, on the use of artificial intelligence and metaheuristic algorithms for nanoparticle synthesis in drug delivery systems. The main findings are: neural networks are better at modelling NVs properties than linear regression algorithms and response surface methodology, there is a very limited number of studies comparing AI or metaheuristic algorithm, and there is no information regarding the appropriateness of calculations of the sample size. Based on these findings, multilayer perceptron artificial neural network and adaptive neuro fuzzy inference system were tested for their modelling performance with a NV dataset; finding the latter the better algorithm. For metaheuristic algorithms, benchmark functions were optimized with cuckoo search, firefly algorithm, genetic algorithm and symbiotic organism search; finding cuckoo search and symbiotic organism search with the best performance. Finally, methods to estimate appropriate sample size for AI algorithms are discussed.
Artificial Association Neural Networks
Nov 22, 2021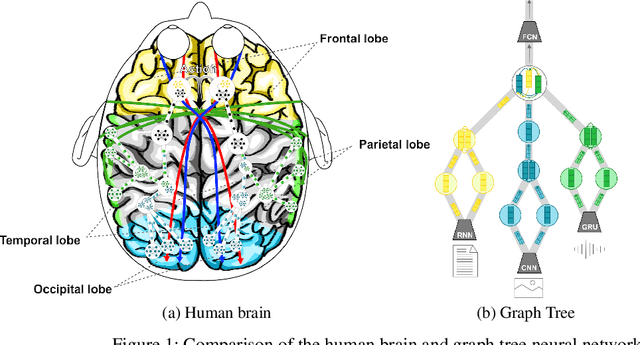
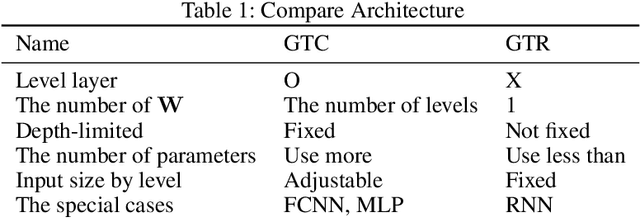
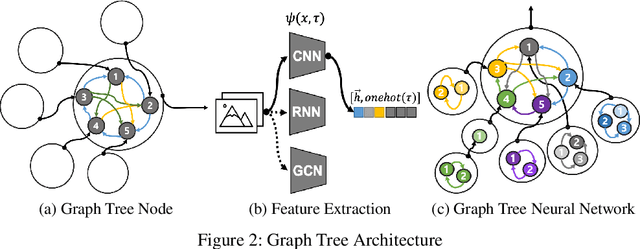
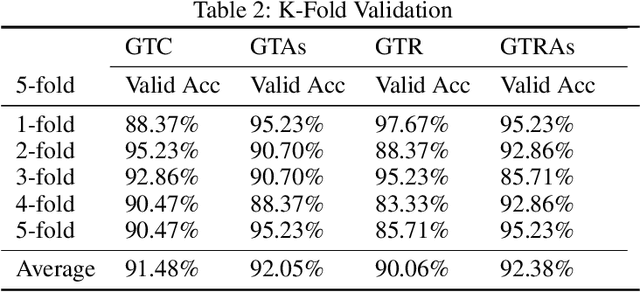
In the field of deep learning, various architectures have been developed. However, most studies are limited to specific tasks or datasets due to their fixed layer structure. This paper does not express the structure delivering information as a network model but as a data structure called an association tree(AT). And we propose two artificial association networks(AANs) designed to solve the problems of existing networks by analyzing the structure of human neural networks. Defining the starting and ending points of the path in a single graph is difficult, and a tree cannot express the relationship among sibling nodes. On the contrary, an AT can express leaf and root nodes as the starting and ending points of the path and the relationship among sibling nodes. Instead of using fixed sequence layers, we create an AT for each data and train AANs according to the tree's structure. AANs are data-driven learning in which the number of convolutions varies according to the depth of the tree. Moreover, AANs can simultaneously learn various types of datasets through the recursive learning. Depth-first convolution (DFC) encodes the interaction result from leaf nodes to the root node in a bottom-up approach, and depth-first deconvolution (DFD) decodes the interaction result from the root node to the leaf nodes in a top-down approach. We conducted three experiments. The first experiment verified whether it could be processed by combining AANs and feature extraction networks. In the second, we compared the performance of networks that separately learned image, sound, and tree, graph structure datasets with the performance simultaneously learned by connecting these networks. In the third, we verified whether the output of AANs can embed all data in the AT. As a result, AATs learned without significant performance degradation.
Outlining and Filling: Hierarchical Query Graph Generation for Answering Complex Questions over Knowledge Graph
Nov 01, 2021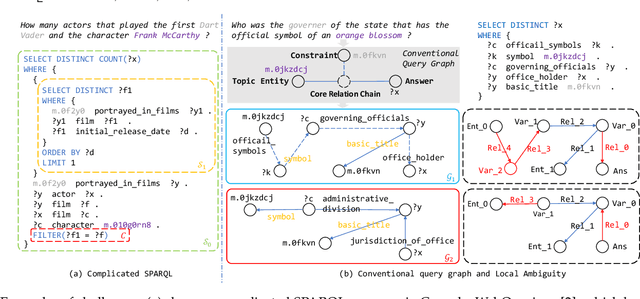
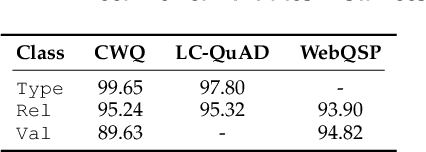
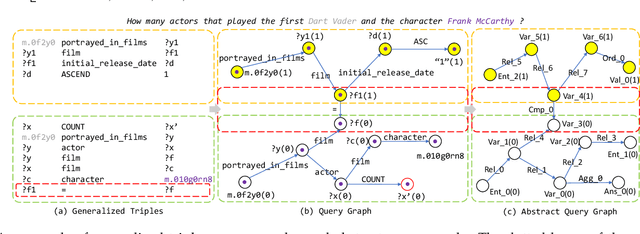
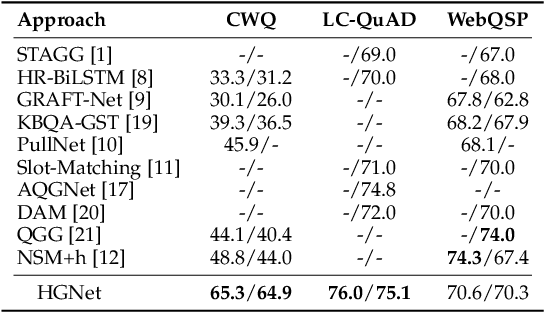
Query graph building aims to build correct executable SPARQL over the knowledge graph for answering natural language questions. Although recent approaches perform well by NN-based query graph ranking, more complex questions bring three new challenges: complicated SPARQL syntax, huge search space for ranking, and noisy query graphs with local ambiguity. This paper handles these challenges. Initially, we regard common complicated SPARQL syntax as the sub-graphs comprising of vertices and edges and propose a new unified query graph grammar to adapt them. Subsequently, we propose a new two-stage approach to build query graphs. In the first stage, the top-$k$ related instances (entities, relations, etc.) are collected by simple strategies, as the candidate instances. In the second stage, a graph generation model performs hierarchical generation. It first outlines a graph structure whose vertices and edges are empty slots, and then fills the appropriate instances into the slots, thereby completing the query graph. Our approach decomposes the unbearable search space of entire query graphs into affordable sub-spaces of operations, meanwhile, leverages the global structural information to eliminate local ambiguity. The experimental results demonstrate that our approach greatly improves state-of-the-art on the hardest KGQA benchmarks and has an excellent performance on complex questions.
CNewSum: A Large-scale Chinese News Summarization Dataset with Human-annotated Adequacy and Deducibility Level
Oct 21, 2021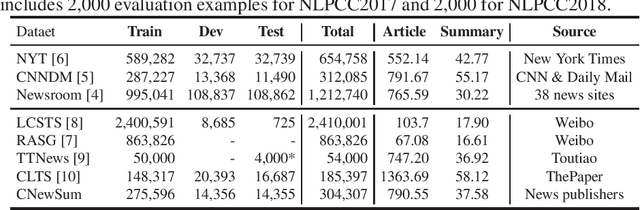

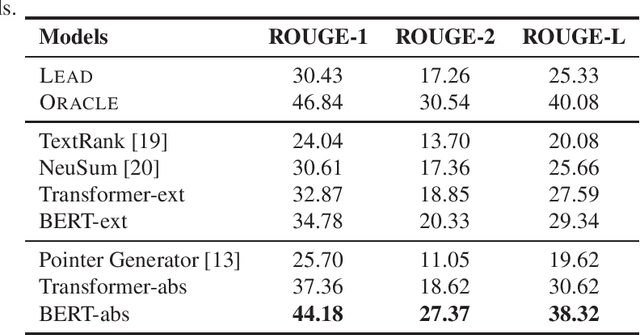
Automatic text summarization aims to produce a brief but crucial summary for the input documents. Both extractive and abstractive methods have witnessed great success in English datasets in recent years. However, there has been a minimal exploration of text summarization in Chinese, limited by the lack of large-scale datasets. In this paper, we present a large-scale Chinese news summarization dataset CNewSum, which consists of 304,307 documents and human-written summaries for the news feed. It has long documents with high-abstractive summaries, which can encourage document-level understanding and generation for current summarization models. An additional distinguishing feature of CNewSum is that its test set contains adequacy and deducibility annotations for the summaries. The adequacy level measures the degree of summary information covered by the document, and the deducibility indicates the reasoning ability the model needs to generate the summary. These annotations can help researchers analyze and target their model performance bottleneck. We examine recent methods on CNewSum and release our dataset to provide a solid testbed for automatic Chinese summarization research.
Automatic Polyp Segmentation via Multi-scale Subtraction Network
Aug 11, 2021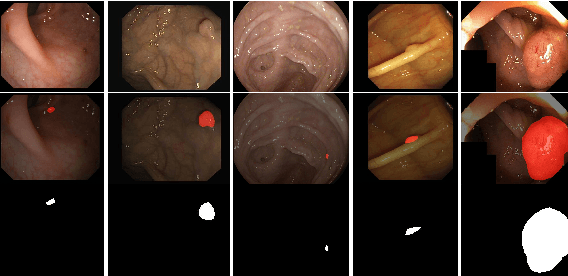
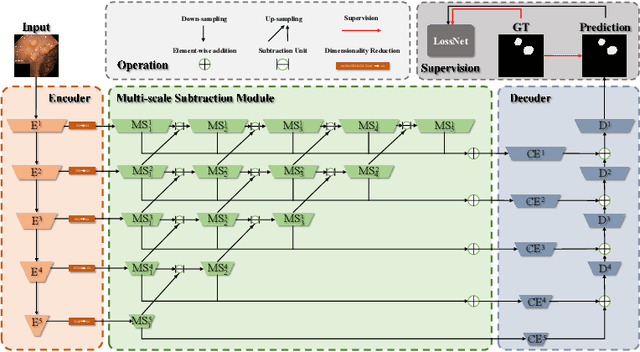
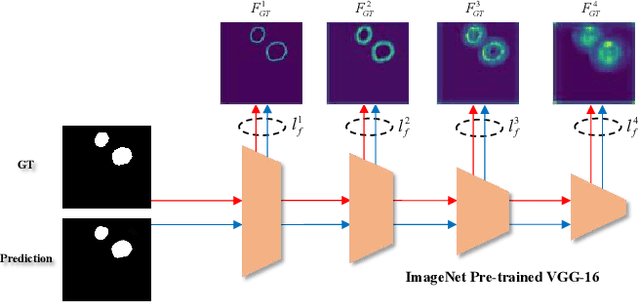
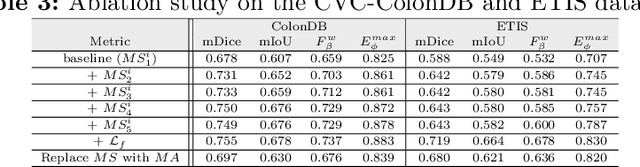
More than 90\% of colorectal cancer is gradually transformed from colorectal polyps. In clinical practice, precise polyp segmentation provides important information in the early detection of colorectal cancer. Therefore, automatic polyp segmentation techniques are of great importance for both patients and doctors. Most existing methods are based on U-shape structure and use element-wise addition or concatenation to fuse different level features progressively in decoder. However, both the two operations easily generate plenty of redundant information, which will weaken the complementarity between different level features, resulting in inaccurate localization and blurred edges of polyps. To address this challenge, we propose a multi-scale subtraction network (MSNet) to segment polyp from colonoscopy image. Specifically, we first design a subtraction unit (SU) to produce the difference features between adjacent levels in encoder. Then, we pyramidally equip the SUs at different levels with varying receptive fields, thereby obtaining rich multi-scale difference information. In addition, we build a training-free network "LossNet" to comprehensively supervise the polyp-aware features from bottom layer to top layer, which drives the MSNet to capture the detailed and structural cues simultaneously. Extensive experiments on five benchmark datasets demonstrate that our MSNet performs favorably against most state-of-the-art methods under different evaluation metrics. Furthermore, MSNet runs at a real-time speed of $\sim$70fps when processing a $352 \times 352$ image. The source code will be publicly available at \url{https://github.com/Xiaoqi-Zhao-DLUT/MSNet}. \keywords{Colorectal Cancer \and Automatic Polyp Segmentation \and Subtraction \and LossNet.}
Regressing Location on Text for Probabilistic Geocoding
Jun 30, 2021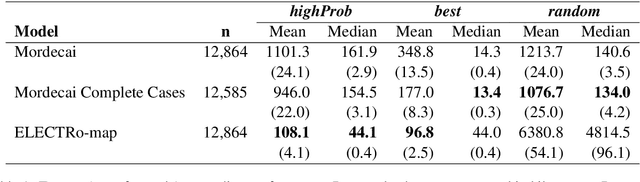
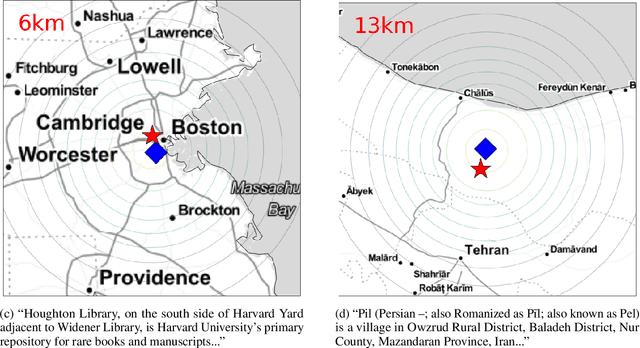
Text data are an important source of detailed information about social and political events. Automated systems parse large volumes of text data to infer or extract structured information that describes actors, actions, dates, times, and locations. One of these sub-tasks is geocoding: predicting the geographic coordinates associated with events or locations described by a given text. We present an end-to-end probabilistic model for geocoding text data. Additionally, we collect a novel data set for evaluating the performance of geocoding systems. We compare the model-based solution, called ELECTRo-map, to the current state-of-the-art open source system for geocoding texts for event data. Finally, we discuss the benefits of end-to-end model-based geocoding, including principled uncertainty estimation and the ability of these models to leverage contextual information.
End-to-End Urban Driving by Imitating a Reinforcement Learning Coach
Aug 26, 2021End-to-end approaches to autonomous driving commonly rely on expert demonstrations. Although humans are good drivers, they are not good coaches for end-to-end algorithms that demand dense on-policy supervision. On the contrary, automated experts that leverage privileged information can efficiently generate large scale on-policy and off-policy demonstrations. However, existing automated experts for urban driving make heavy use of hand-crafted rules and perform suboptimally even on driving simulators, where ground-truth information is available. To address these issues, we train a reinforcement learning expert that maps bird's-eye view images to continuous low-level actions. While setting a new performance upper-bound on CARLA, our expert is also a better coach that provides informative supervision signals for imitation learning agents to learn from. Supervised by our reinforcement learning coach, a baseline end-to-end agent with monocular camera-input achieves expert-level performance. Our end-to-end agent achieves a 78% success rate while generalizing to a new town and new weather on the NoCrash-dense benchmark and state-of-the-art performance on the more challenging CARLA LeaderBoard.
COfEE: A Comprehensive Ontology for Event Extraction from text, with an online annotation tool
Jul 21, 2021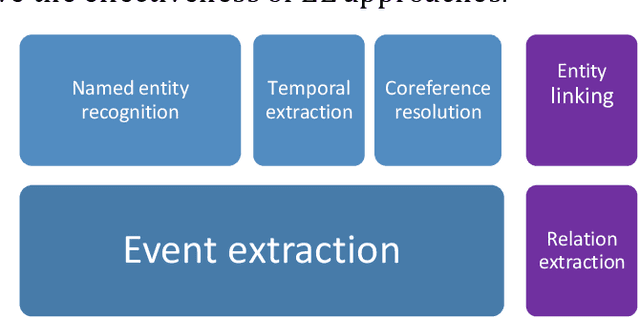

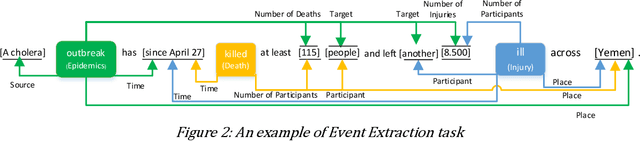
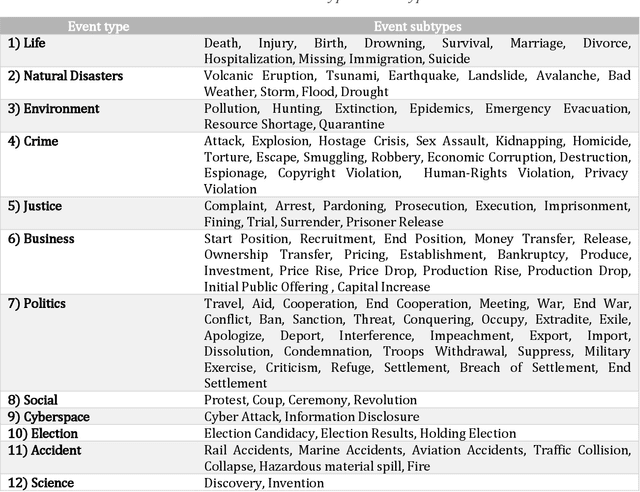
Data is published on the web over time in great volumes, but majority of the data is unstructured, making it hard to understand and difficult to interpret. Information Extraction (IE) methods extract structured information from unstructured data. One of the challenging IE tasks is Event Extraction (EE) which seeks to derive information about specific incidents and their actors from the text. EE is useful in many domains such as building a knowledge base, information retrieval, summarization and online monitoring systems. In the past decades, some event ontologies like ACE, CAMEO and ICEWS were developed to define event forms, actors and dimensions of events observed in the text. These event ontologies still have some shortcomings such as covering only a few topics like political events, having inflexible structure in defining argument roles, lack of analytical dimensions, and complexity in choosing event sub-types. To address these concerns, we propose an event ontology, namely COfEE, that incorporates both expert domain knowledge, previous ontologies and a data-driven approach for identifying events from text. COfEE consists of two hierarchy levels (event types and event sub-types) that include new categories relating to environmental issues, cyberspace, criminal activity and natural disasters which need to be monitored instantly. Also, dynamic roles according to each event sub-type are defined to capture various dimensions of events. In a follow-up experiment, the proposed ontology is evaluated on Wikipedia events, and it is shown to be general and comprehensive. Moreover, in order to facilitate the preparation of gold-standard data for event extraction, a language-independent online tool is presented based on COfEE.