 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Traffic Forecasting on Traffic Moving Snippets
Oct 27, 2021
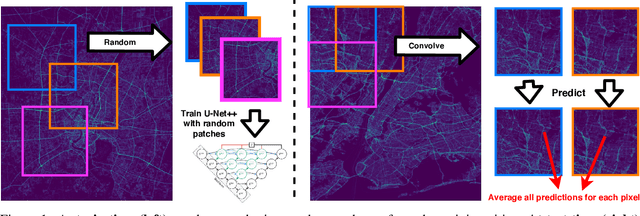

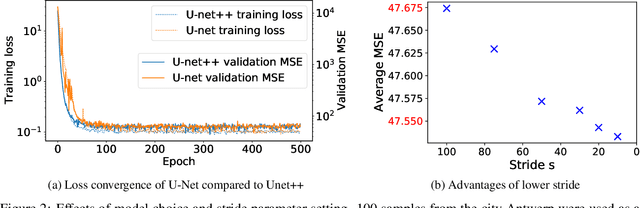
Advances in traffic forecasting technology can greatly impact urban mobility. In the traffic4cast competition, the task of short-term traffic prediction is tackled in unprecedented detail, with traffic volume and speed information available at 5 minute intervals and high spatial resolution. To improve generalization to unknown cities, as required in the 2021 extended challenge, we propose to predict small quadratic city sections, rather than processing a full-city-raster at once. At test time, breaking down the test data into spatially-cropped overlapping snippets improves stability and robustness of the final predictions, since multiple patches covering one cell can be processed independently. With the performance on the traffic4cast test data and further experiments on a validation set it is shown that patch-wise prediction indeed improves accuracy. Further advantages can be gained with a Unet++ architecture and with an increasing number of patches per sample processed at test time. We conclude that our snippet-based method, combined with other successful network architectures proposed in the competition, can leverage performance, in particular on unseen cities. All source code is available at https://github.com/NinaWie/NeurIPS2021-traffic4cast.
Information Design in Crowdfunding under Thresholding Policies
Mar 28, 2018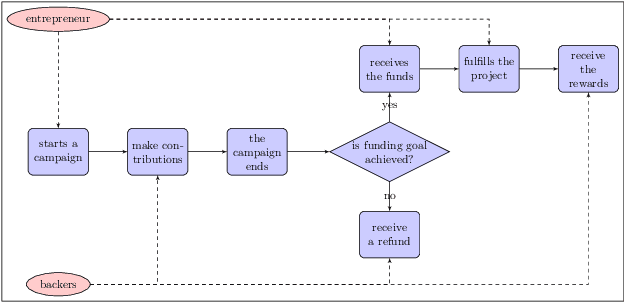
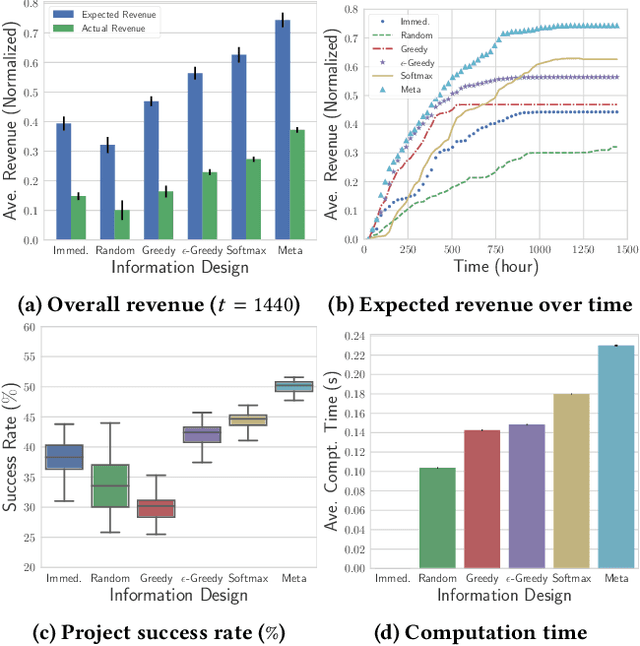
Crowdfunding has emerged as a prominent way for entrepreneurs to secure funding without sophisticated intermediation. In crowdfunding, an entrepreneur often has to decide how to disclose the campaign status in order to collect as many contributions as possible. Such decisions are difficult to make primarily due to incomplete information. We propose information design as a tool to help the entrepreneur to improve revenue by influencing backers' beliefs. We introduce a heuristic algorithm to dynamically compute information-disclosure policies for the entrepreneur, followed by an empirical evaluation to demonstrate its competitiveness over the widely-adopted immediate-disclosure policy. Our results demonstrate that the immediate-disclosure policy is not optimal when backers follow thresholding policies despite its ease of implementation. With appropriate heuristics, an entrepreneur can benefit from dynamic information disclosure. Our work sheds light on information design in a dynamic setting where agents make decisions using thresholding policies.
On games and simulators as a platform for development of artificial intelligence for command and control
Oct 21, 2021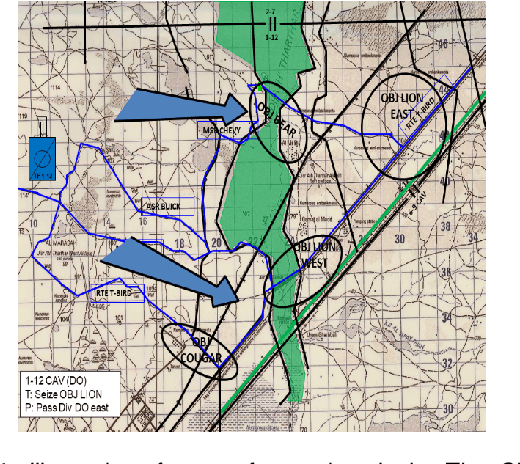

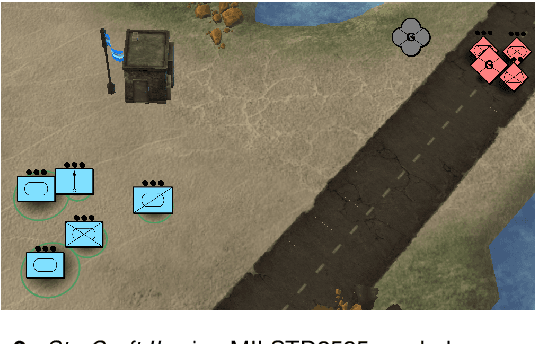
Games and simulators can be a valuable platform to execute complex multi-agent, multiplayer, imperfect information scenarios with significant parallels to military applications: multiple participants manage resources and make decisions that command assets to secure specific areas of a map or neutralize opposing forces. These characteristics have attracted the artificial intelligence (AI) community by supporting development of algorithms with complex benchmarks and the capability to rapidly iterate over new ideas. The success of artificial intelligence algorithms in real-time strategy games such as StarCraft II have also attracted the attention of the military research community aiming to explore similar techniques in military counterpart scenarios. Aiming to bridge the connection between games and military applications, this work discusses past and current efforts on how games and simulators, together with the artificial intelligence algorithms, have been adapted to simulate certain aspects of military missions and how they might impact the future battlefield. This paper also investigates how advances in virtual reality and visual augmentation systems open new possibilities in human interfaces with gaming platforms and their military parallels.
TabularNet: A Neural Network Architecture for Understanding Semantic Structures of Tabular Data
Jun 06, 2021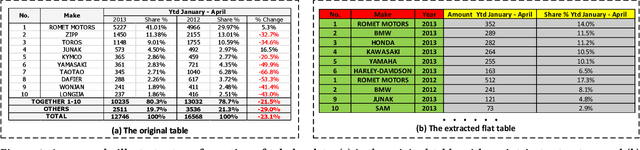
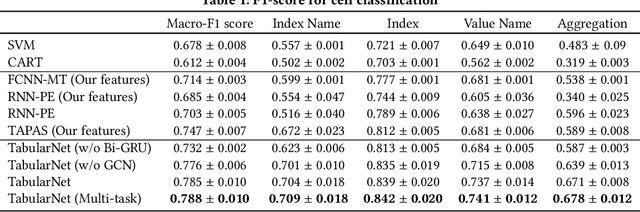
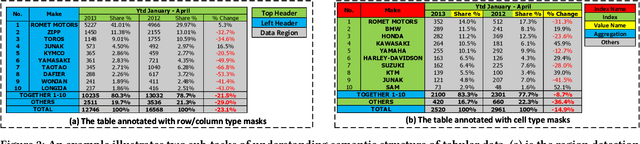
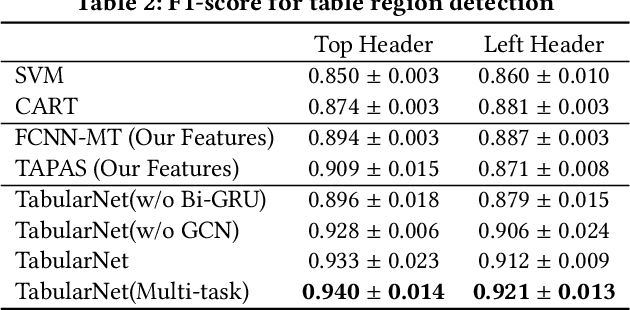
Tabular data are ubiquitous for the widespread applications of tables and hence have attracted the attention of researchers to extract underlying information. One of the critical problems in mining tabular data is how to understand their inherent semantic structures automatically. Existing studies typically adopt Convolutional Neural Network (CNN) to model the spatial information of tabular structures yet ignore more diverse relational information between cells, such as the hierarchical and paratactic relationships. To simultaneously extract spatial and relational information from tables, we propose a novel neural network architecture, TabularNet. The spatial encoder of TabularNet utilizes the row/column-level Pooling and the Bidirectional Gated Recurrent Unit (Bi-GRU) to capture statistical information and local positional correlation, respectively. For relational information, we design a new graph construction method based on the WordNet tree and adopt a Graph Convolutional Network (GCN) based encoder that focuses on the hierarchical and paratactic relationships between cells. Our neural network architecture can be a unified neural backbone for different understanding tasks and utilized in a multitask scenario. We conduct extensive experiments on three classification tasks with two real-world spreadsheet data sets, and the results demonstrate the effectiveness of our proposed TabularNet over state-of-the-art baselines.
Detecting Important Patterns Using Conceptual Relevance Interestingness Measure
Oct 21, 2021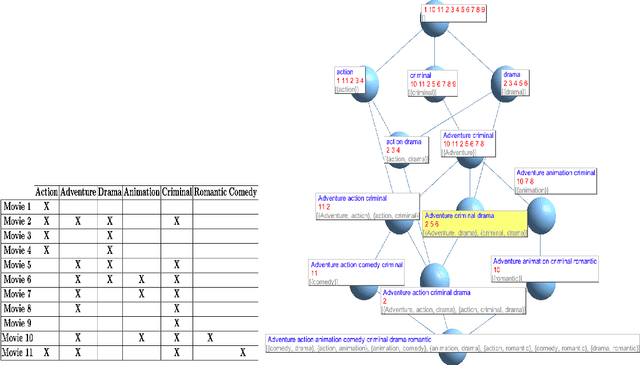
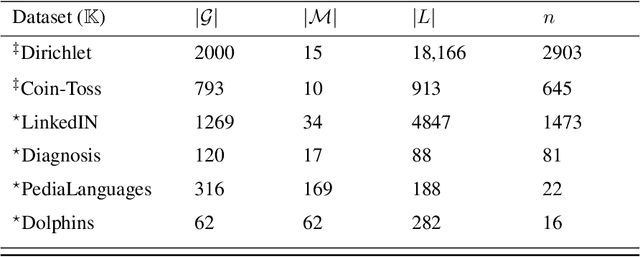
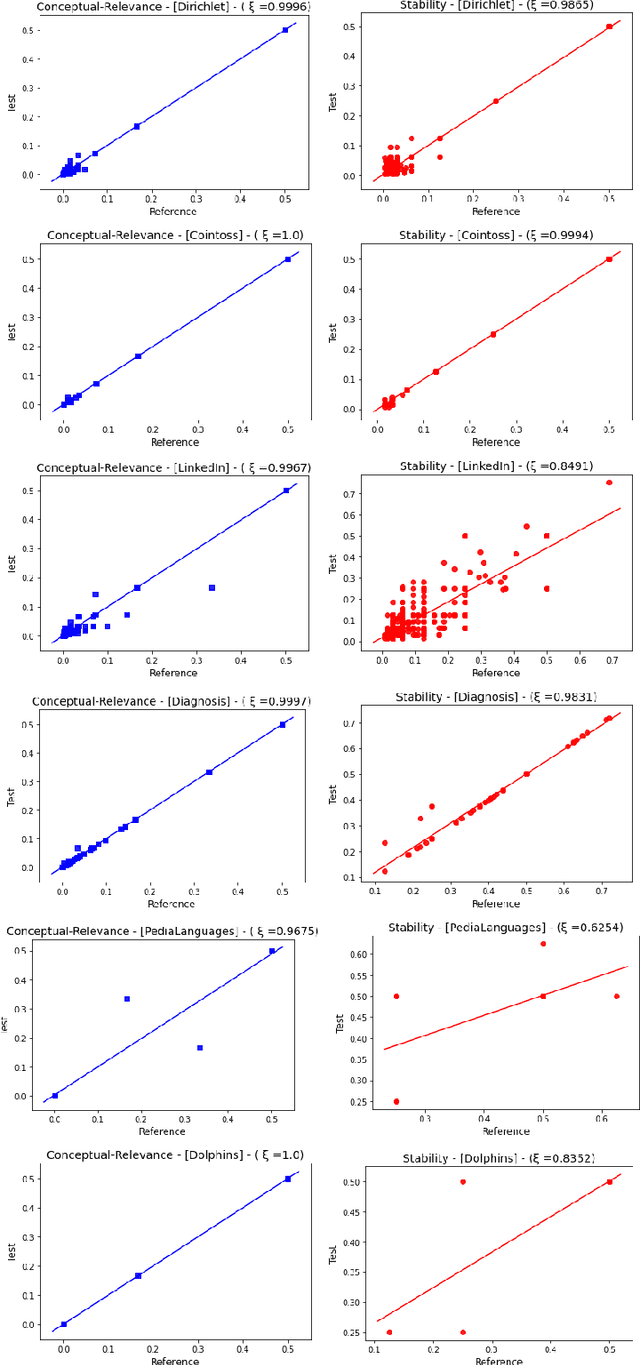
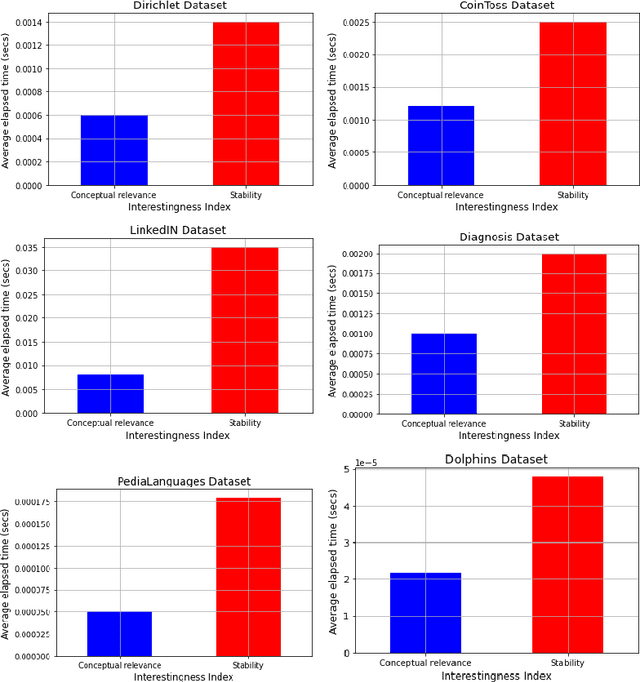
Discovering meaningful conceptual structures is a substantial task in data mining and knowledge discovery applications. While off-the-shelf interestingness indices defined in Formal Concept Analysis may provide an effective relevance evaluation in several situations, they frequently give inadequate results when faced with massive formal contexts (and concept lattices), and in the presence of irrelevant concepts. In this paper, we introduce the Conceptual Relevance (CR) score, a new scalable interestingness measurement for the identification of actionable concepts. From a conceptual perspective, the minimal generators provide key information about their associated concept intent. Furthermore, the relevant attributes of a concept are those that maintain the satisfaction of its closure condition. Thus, the guiding idea of CR exploits the fact that minimal generators and relevant attributes can be efficiently used to assess concept relevance. As such, the CR index quantifies both the amount of conceptually relevant attributes and the number of the minimal generators per concept intent. Our experiments on synthetic and real-world datasets show the efficiency of this measure over the well-known stability index.
Logsig-RNN: a novel network for robust and efficient skeleton-based action recognition
Nov 01, 2021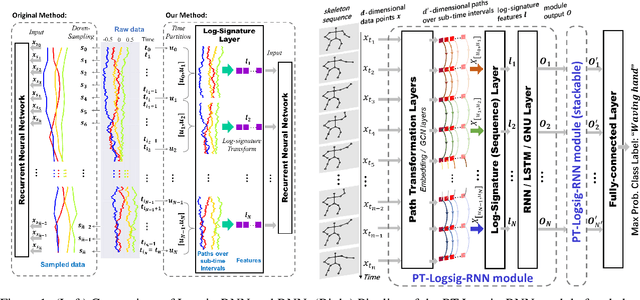
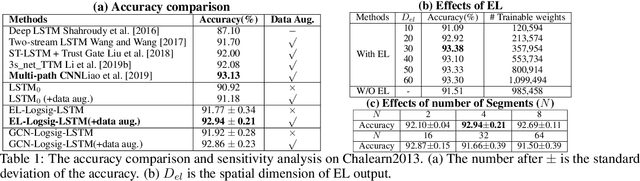


This paper contributes to the challenge of skeleton-based human action recognition in videos. The key step is to develop a generic network architecture to extract discriminative features for the spatio-temporal skeleton data. In this paper, we propose a novel module, namely Logsig-RNN, which is the combination of the log-signature layer and recurrent type neural networks (RNNs). The former one comes from the mathematically principled technology of signatures and log-signatures as representations for streamed data, which can manage high sample rate streams, non-uniform sampling and time series of variable length. It serves as an enhancement of the recurrent layer, which can be conveniently plugged into neural networks. Besides we propose two path transformation layers to significantly reduce path dimension while retaining the essential information fed into the Logsig-RNN module. Finally, numerical results demonstrate that replacing the RNN module by the Logsig-RNN module in SOTA networks consistently improves the performance on both Chalearn gesture data and NTU RGB+D 120 action data in terms of accuracy and robustness. In particular, we achieve the state-of-the-art accuracy on Chalearn2013 gesture data by combining simple path transformation layers with the Logsig-RNN. Codes are available at https://github.com/steveliao93/GCN_LogsigRNN.
Cross Modification Attention Based Deliberation Model for Image Captioning
Sep 17, 2021
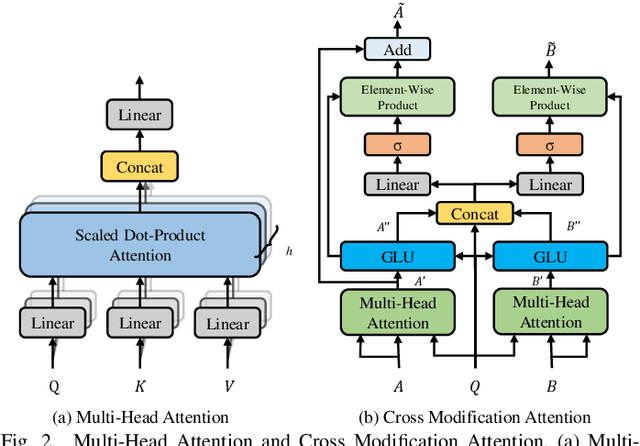
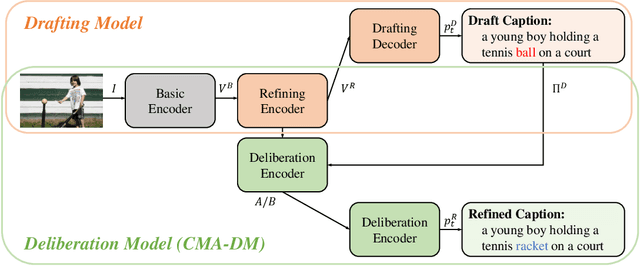
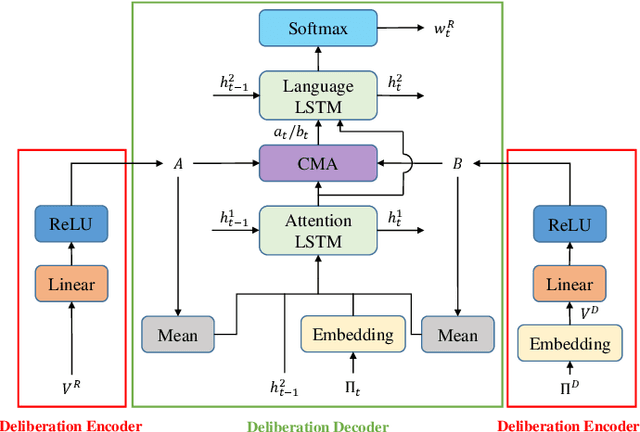
The conventional encoder-decoder framework for image captioning generally adopts a single-pass decoding process, which predicts the target descriptive sentence word by word in temporal order. Despite the great success of this framework, it still suffers from two serious disadvantages. Firstly, it is unable to correct the mistakes in the predicted words, which may mislead the subsequent prediction and result in error accumulation problem. Secondly, such a framework can only leverage the already generated words but not the possible future words, and thus lacks the ability of global planning on linguistic information. To overcome these limitations, we explore a universal two-pass decoding framework, where a single-pass decoding based model serving as the Drafting Model first generates a draft caption according to an input image, and a Deliberation Model then performs the polishing process to refine the draft caption to a better image description. Furthermore, inspired from the complementarity between different modalities, we propose a novel Cross Modification Attention (CMA) module to enhance the semantic expression of the image features and filter out error information from the draft captions. We integrate CMA with the decoder of our Deliberation Model and name it as Cross Modification Attention based Deliberation Model (CMA-DM). We train our proposed framework by jointly optimizing all trainable components from scratch with a trade-off coefficient. Experiments on MS COCO dataset demonstrate that our approach obtains significant improvements over single-pass decoding baselines and achieves competitive performances compared with other state-of-the-art two-pass decoding based methods.
Predicting Adverse Media Risk using a Heterogeneous Information Network
Nov 09, 2018
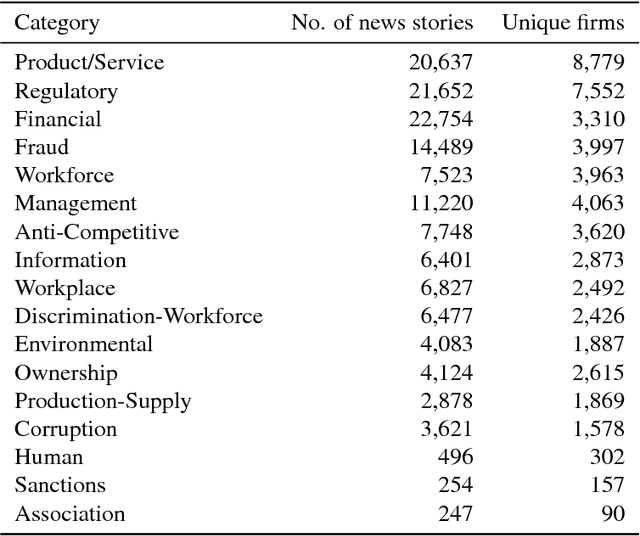
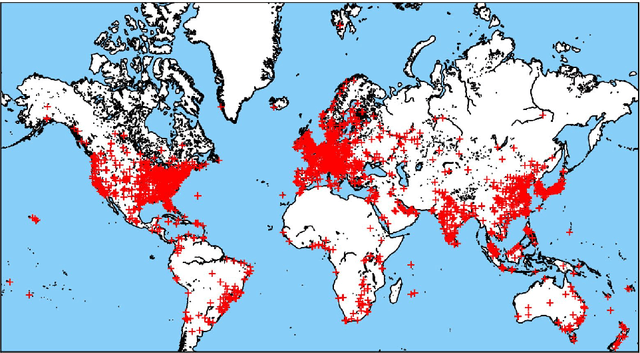

The media plays a central role in monitoring powerful institutions and identifying any activities harmful to the public interest. In the investing sphere constituted of 46,583 officially listed domestic firms on the stock exchanges worldwide, there is a growing interest `to do the right thing', i.e., to put pressure on companies to improve their environmental, social and government (ESG) practices. However, how to overcome the sparsity of ESG data from non-reporting firms, and how to identify the relevant information in the annual reports of this large universe? Here, we construct a vast heterogeneous information network that covers the necessary information surrounding each firm, which is assembled using seven professionally curated datasets and two open datasets, resulting in about 50 million nodes and 400 million edges in total. Exploiting this heterogeneous information network, we propose a model that can learn from past adverse media coverage patterns and predict the occurrence of future adverse media coverage events on the whole universe of firms. Our approach is tested using the adverse media coverage data of more than 35,000 firms worldwide from January 2012 to May 2018. Comparing with state-of-the-art methods with and without the network, we show that the predictive accuracy is substantially improved when using the heterogeneous information network. This work suggests new ways to consolidate the diffuse information contained in big data in order to monitor dominant institutions on a global scale for more socially responsible investment, better risk management, and the surveillance of powerful institutions.
AI-based Radio Resource Management and Trajectory Design for PD-NOMA Communication in IRS-UAV Assisted Networks
Nov 06, 2021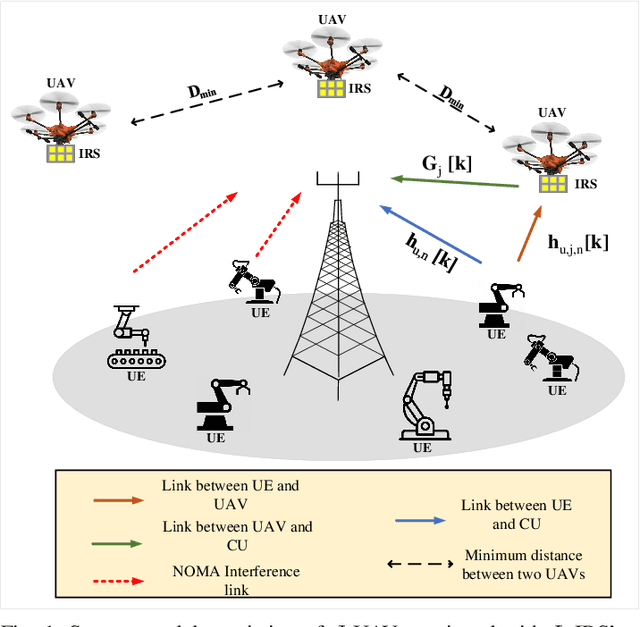
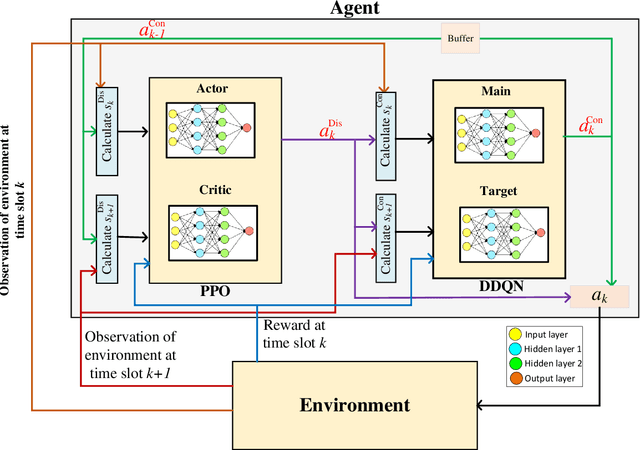
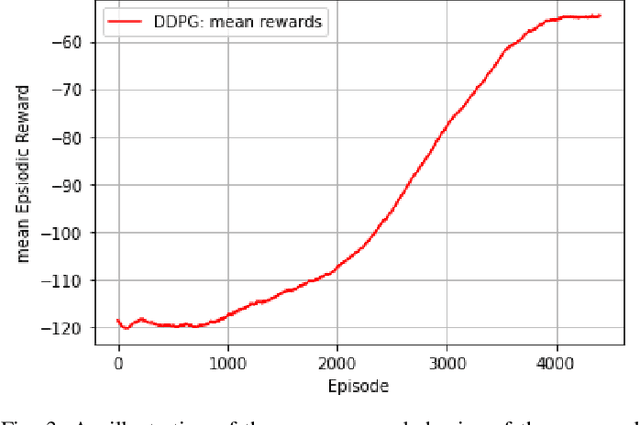
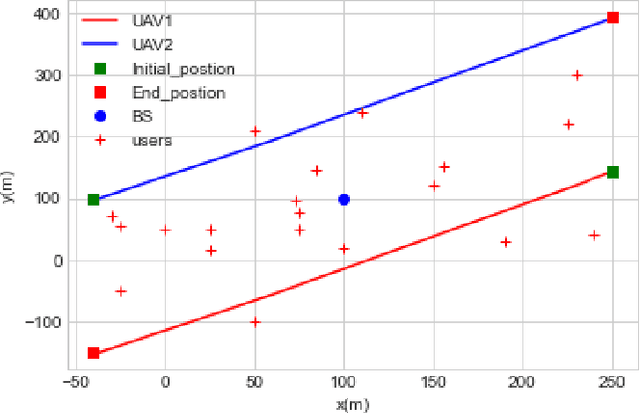
In this paper, we consider that the unmanned aerial vehicles (UAVs) with attached intelligent reflecting surfaces (IRSs) play the role of flying reflectors that reflect the signal of users to the destination, and utilize the power-domain non-orthogonal multiple access (PD-NOMA) scheme in the uplink. We investigate the benefits of the UAV-IRS on the internet of things (IoT) networks that improve the freshness of collected data of the IoT devices via optimizing power, sub-carrier, and trajectory variables, as well as, the phase shift matrix elements. We consider minimizing the average age-of-information (AAoI) of users subject to the maximum transmit power limitations, PD-NOMA-related restriction, and the constraints related to UAV's movement. The optimization problem consists of discrete and continuous variables. Hence, we divide the resource allocation problem into two sub-problems and use two different reinforcement learning (RL) based algorithms to solve them, namely the double deep Qnetwork (DDQN) and a proximal policy optimization (PPO). Our numerical results illustrate the performance gains that can be achieved for IRS enabled UAV communication systems. Moreover, we compare our deep RL (DRL) based algorithm with matching algorithm and random trajectory, showing the combination of DDQN and PPO algorithm proposed in this paper performs 10% and 15% better than matching algorithm and random-trajectory algorithm, respectively.
Randomized Classifiers vs Human Decision-Makers: Trustworthy AI May Have to Act Randomly and Society Seems to Accept This
Nov 15, 2021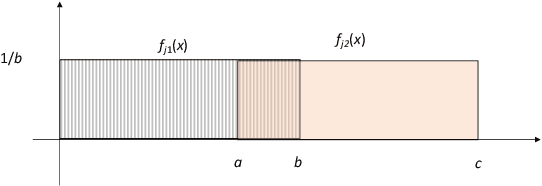
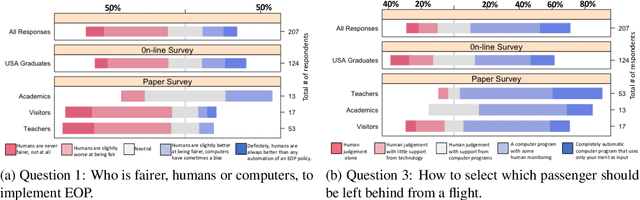
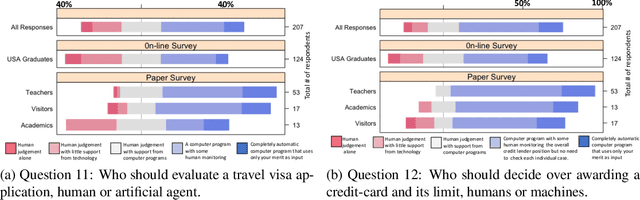
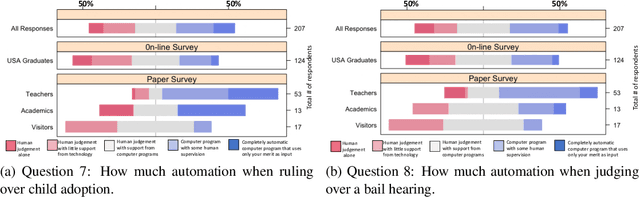
As \emph{artificial intelligence} (AI) systems are increasingly involved in decisions affecting our lives, ensuring that automated decision-making is fair and ethical has become a top priority. Intuitively, we feel that akin to human decisions, judgments of artificial agents should necessarily be grounded in some moral principles. Yet a decision-maker (whether human or artificial) can only make truly ethical (based on any ethical theory) and fair (according to any notion of fairness) decisions if full information on all the relevant factors on which the decision is based are available at the time of decision-making. This raises two problems: (1) In settings, where we rely on AI systems that are using classifiers obtained with supervised learning, some induction/generalization is present and some relevant attributes may not be present even during learning. (2) Modeling such decisions as games reveals that any -- however ethical -- pure strategy is inevitably susceptible to exploitation. Moreover, in many games, a Nash Equilibrium can only be obtained by using mixed strategies, i.e., to achieve mathematically optimal outcomes, decisions must be randomized. In this paper, we argue that in supervised learning settings, there exist random classifiers that perform at least as well as deterministic classifiers, and may hence be the optimal choice in many circumstances. We support our theoretical results with an empirical study indicating a positive societal attitude towards randomized artificial decision-makers, and discuss some policy and implementation issues related to the use of random classifiers that relate to and are relevant for current AI policy and standardization initiatives.