 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Scaling Law of Deep Neural Networks
Feb 13, 2018
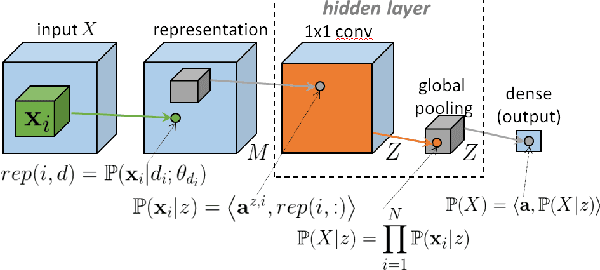
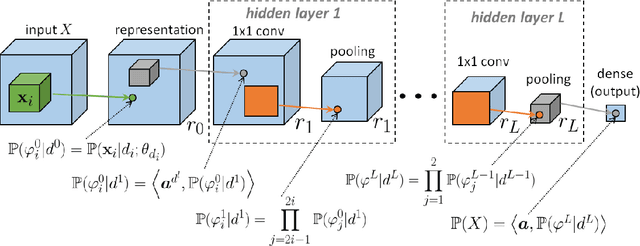
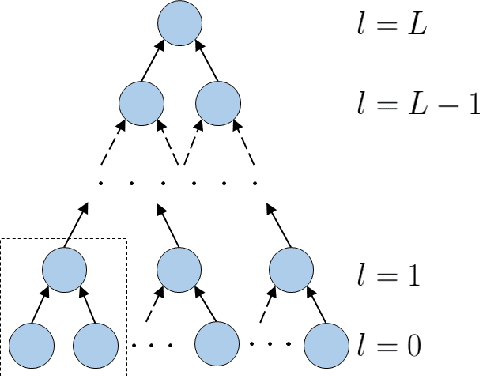
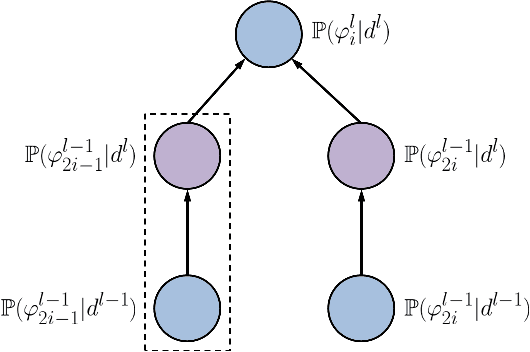
With the rapid development of Deep Neural Networks (DNNs), various network models that show strong computing power and impressive expressive power are proposed. However, there is no comprehensive informational interpretation of DNNs from the perspective of information theory. Due to the nonlinear function and the uncertain number of layers and neural units used in the DNNs, the network structure shows nonlinearity and complexity. With the typical DNNs named Convolutional Arithmetic Circuits (ConvACs), the complex DNNs can be converted into mathematical formula. Thus, we can use rigorous mathematical theory especially the information theory to analyse the complicated DNNs. In this paper, we propose a novel information scaling law scheme that can interpret the network's inner organization by information theory. First, we show the informational interpretation of the activation function. Secondly, we prove that the information entropy increases when the information is transmitted through the ConvACs. Finally, we propose the information scaling law of ConvACs through making a reasonable assumption.
Nonparanormal Information Estimation
Feb 24, 2017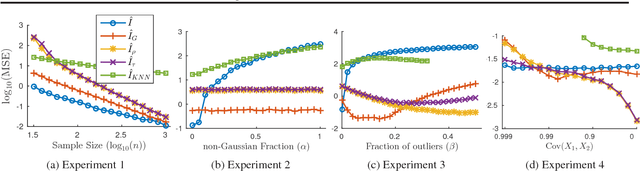
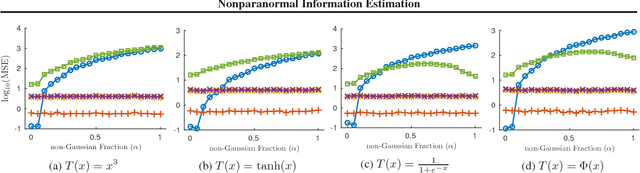
We study the problem of using i.i.d. samples from an unknown multivariate probability distribution $p$ to estimate the mutual information of $p$. This problem has recently received attention in two settings: (1) where $p$ is assumed to be Gaussian and (2) where $p$ is assumed only to lie in a large nonparametric smoothness class. Estimators proposed for the Gaussian case converge in high dimensions when the Gaussian assumption holds, but are brittle, failing dramatically when $p$ is not Gaussian. Estimators proposed for the nonparametric case fail to converge with realistic sample sizes except in very low dimensions. As a result, there is a lack of robust mutual information estimators for many realistic data. To address this, we propose estimators for mutual information when $p$ is assumed to be a nonparanormal (a.k.a., Gaussian copula) model, a semiparametric compromise between Gaussian and nonparametric extremes. Using theoretical bounds and experiments, we show these estimators strike a practical balance between robustness and scaling with dimensionality.
Environmental Information Improves Robotic Search Performance
Jun 22, 2018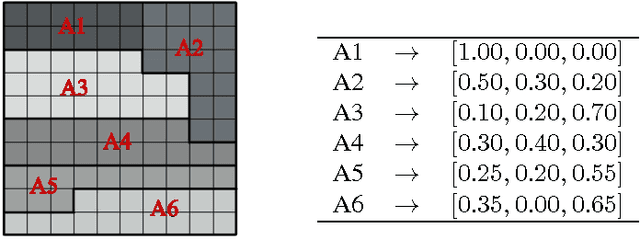
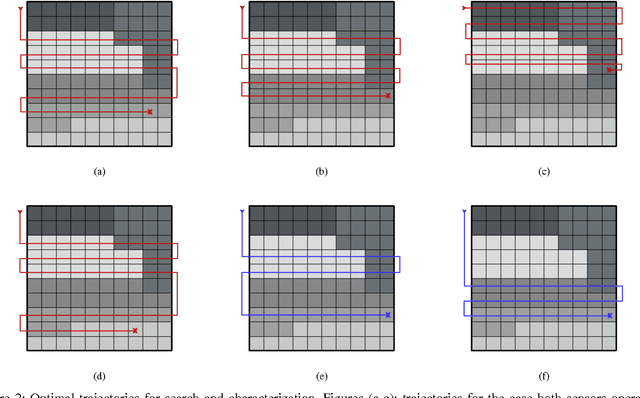
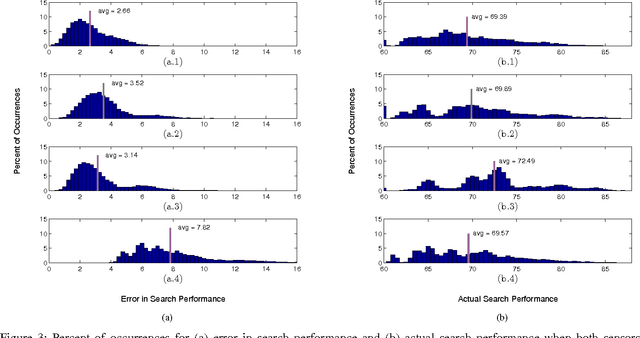
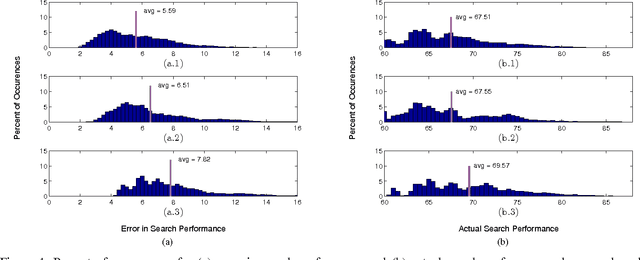
We address the problem where a mobile search agent seeks to find an unknown number of stationary objects distributed in a bounded search domain, and the search mission is subject to time/distance constraint. Our work accounts for false positives, false negatives and environmental uncertainty. We consider the case that the performance of a search sensor is dependent on the environment (e.g., clutter density), and therefore sensor performance is better in some locations than in others. We specifically consider applications where environmental information can be acquired either by a separate vehicle or by the same vehicle that performs the search task. Our main contribution in this study is to formally derive a decision-theoretic cost function to compute the locations where the environmental information should be acquired. For the cases where computing the optimal locations to sample the environment is computationally expensive, we offer an approximation approach that yields provable near-optimal paths. We show that our decision-theoretic cost function outperforms the information-maximization approach, which is often employed in similar applications.
Inductive learning for product assortment graph completion
Oct 04, 2021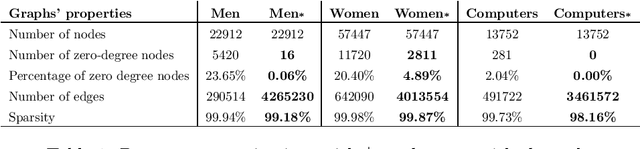
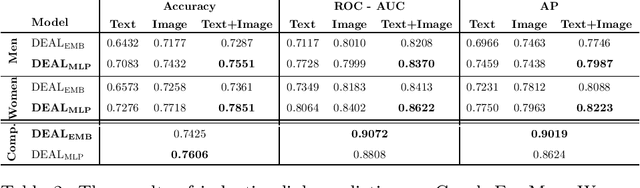
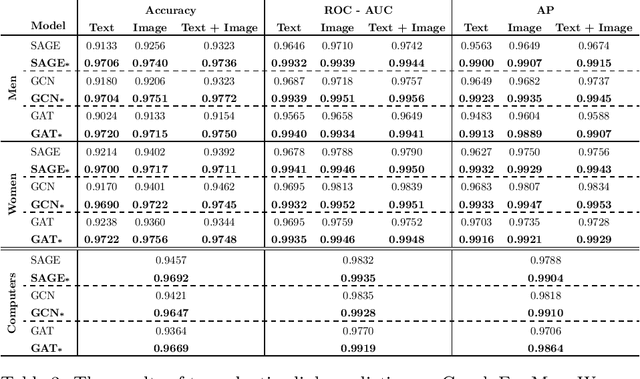
Global retailers have assortments that contain hundreds of thousands of products that can be linked by several types of relationships like style compatibility, "bought together", "watched together", etc. Graphs are a natural representation for assortments, where products are nodes and relations are edges. Relations like style compatibility are often produced by a manual process and therefore do not cover uniformly the whole graph. We propose to use inductive learning to enhance a graph encoding style compatibility of a fashion assortment, leveraging rich node information comprising textual descriptions and visual data. Then, we show how the proposed graph enhancement improves substantially the performance on transductive tasks with a minor impact on graph sparsity.
* 6 pages
A Few More Examples May Be Worth Billions of Parameters
Oct 08, 2021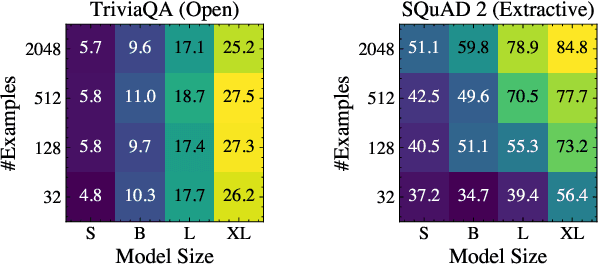
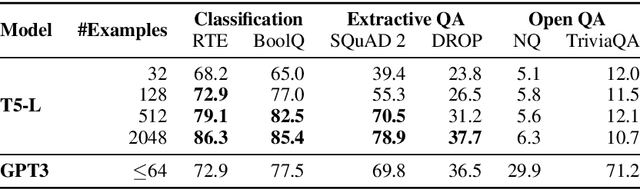
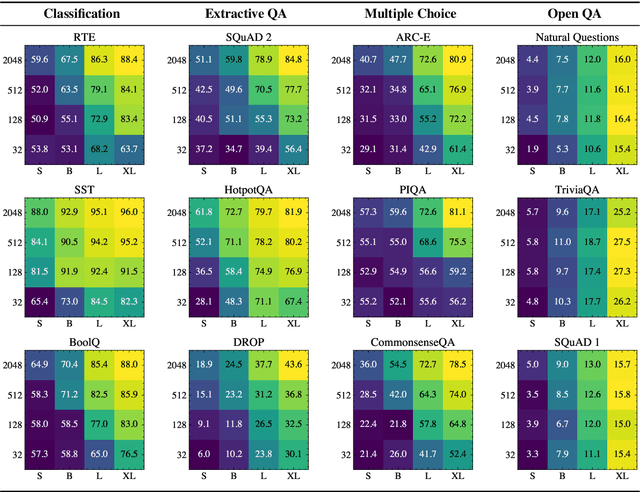
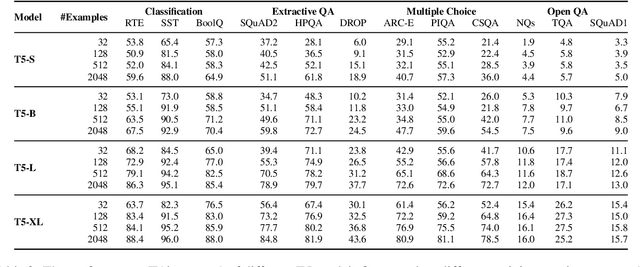
We investigate the dynamics of increasing the number of model parameters versus the number of labeled examples across a wide variety of tasks. Our exploration reveals that while scaling parameters consistently yields performance improvements, the contribution of additional examples highly depends on the task's format. Specifically, in open question answering tasks, enlarging the training set does not improve performance. In contrast, classification, extractive question answering, and multiple choice tasks benefit so much from additional examples that collecting a few hundred examples is often "worth" billions of parameters. We hypothesize that unlike open question answering, which involves recalling specific information, solving strategies for tasks with a more restricted output space transfer across examples, and can therefore be learned with small amounts of labeled data.
Residual Tree Aggregation of Layers for Neural Machine Translation
Jul 19, 2021
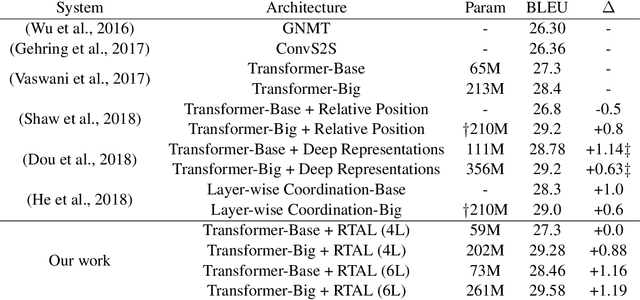
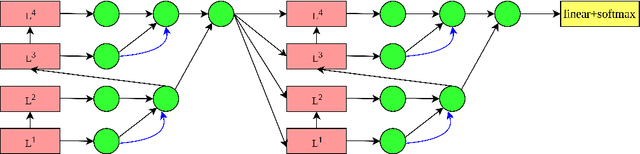

Although attention-based Neural Machine Translation has achieved remarkable progress in recent layers, it still suffers from issue of making insufficient use of the output of each layer. In transformer, it only uses the top layer of encoder and decoder in the subsequent process, which makes it impossible to take advantage of the useful information in other layers. To address this issue, we propose a residual tree aggregation of layers for Transformer(RTAL), which helps to fuse information across layers. Specifically, we try to fuse the information across layers by constructing a post-order binary tree. In additional to the last node, we add the residual connection to the process of generating child nodes. Our model is based on the Neural Machine Translation model Transformer and we conduct our experiments on WMT14 English-to-German and WMT17 English-to-France translation tasks. Experimental results across language pairs show that the proposed approach outperforms the strong baseline model significantly
FILIP: Fine-grained Interactive Language-Image Pre-Training
Nov 09, 2021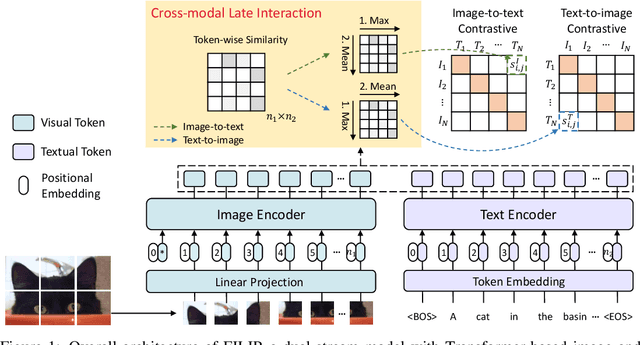
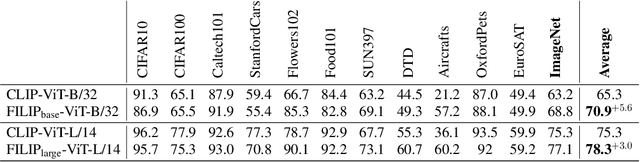
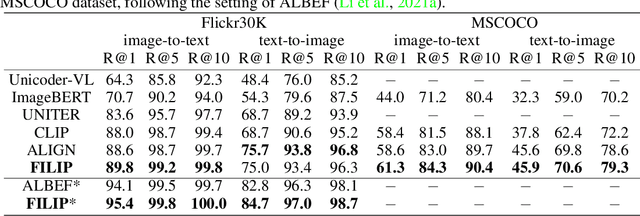

Unsupervised large-scale vision-language pre-training has shown promising advances on various downstream tasks. Existing methods often model the cross-modal interaction either via the similarity of the global feature of each modality which misses sufficient information, or finer-grained interactions using cross/self-attention upon visual and textual tokens. However, cross/self-attention suffers from inferior efficiency in both training and inference. In this paper, we introduce a large-scale Fine-grained Interactive Language-Image Pre-training (FILIP) to achieve finer-level alignment through a cross-modal late interaction mechanism, which uses a token-wise maximum similarity between visual and textual tokens to guide the contrastive objective. FILIP successfully leverages the finer-grained expressiveness between image patches and textual words by modifying only contrastive loss, while simultaneously gaining the ability to pre-compute image and text representations offline at inference, keeping both large-scale training and inference efficient. Furthermore, we construct a new large-scale image-text pair dataset called FILIP300M for pre-training. Experiments show that FILIP achieves state-of-the-art performance on multiple downstream vision-language tasks including zero-shot image classification and image-text retrieval. The visualization on word-patch alignment further shows that FILIP can learn meaningful fine-grained features with promising localization ability.
MIMO for MATLAB: A Toolbox for Simulating MIMO Communication Systems
Nov 09, 2021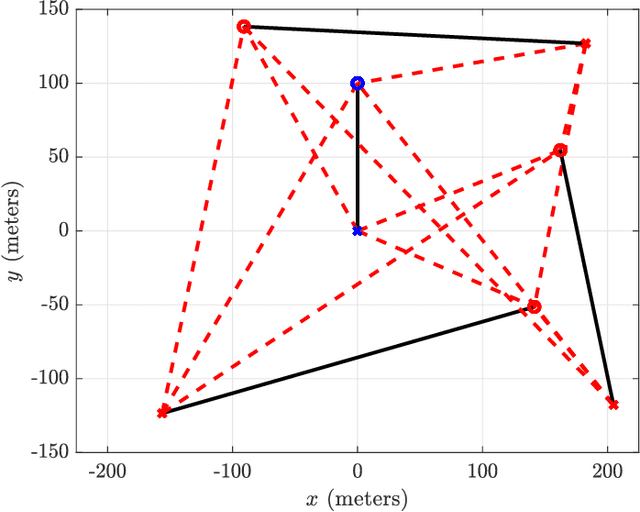
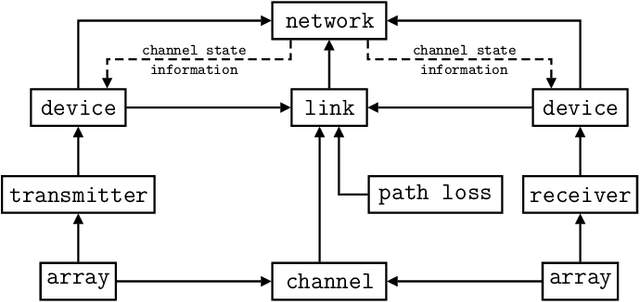
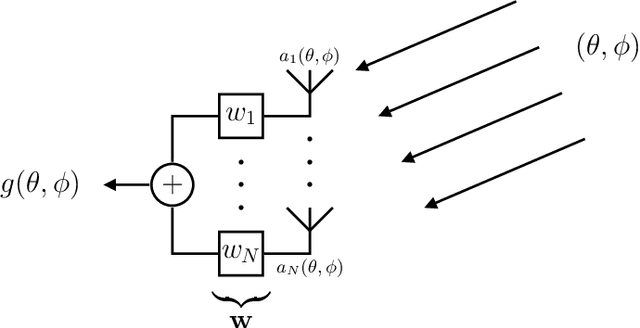
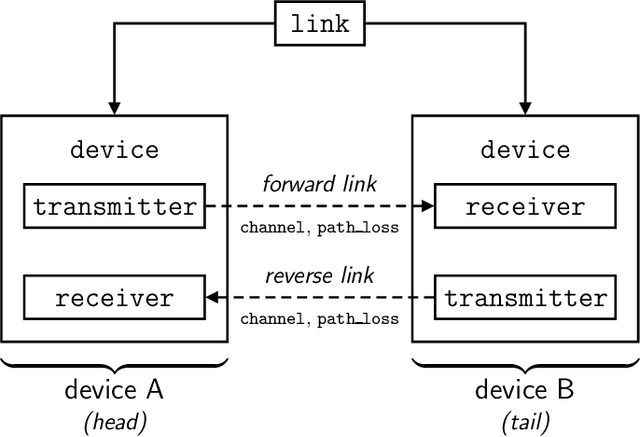
We present MIMO FOR MATLAB (MFM), a toolbox for MATLAB that aims to simplify the simulation of multiple-input multiple-output (MIMO) communication systems research while facilitating reproducibility, consistency, and community-driven customization. MFM offers users an object-oriented solution for simulating a variety of MIMO systems including sub-6 GHz, massive MIMO, millimeter wave, and terahertz communication. Out-of-the-box, MFM supplies users with widely used channel and path loss models from academic literature and wireless standards; if a particular channel or path loss model is not provided by MFM, users can create custom models by following a few simple rules. The complexity and overhead associated with simulating networks of multiple devices can be significantly reduced with MFM versus raw MATLAB code, especially when users want to investigate various channel models, path loss models, precoding/combining schemes, or other system-level parameters. MFM's heavy-lifting to automatically collect and distribute channel state information, aggregate interference, and report performance metrics relieves users of otherwise tedious tasks and instills confidence and consistency in the results of simulation. The use-cases of MFM vary widely from networks of hundreds of devices; to simple point-to-point communication; to serving as a channel generator; to radar, sonar, and underwater acoustic communication.
Unbiased Graph Embedding with Biased Graph Observations
Oct 29, 2021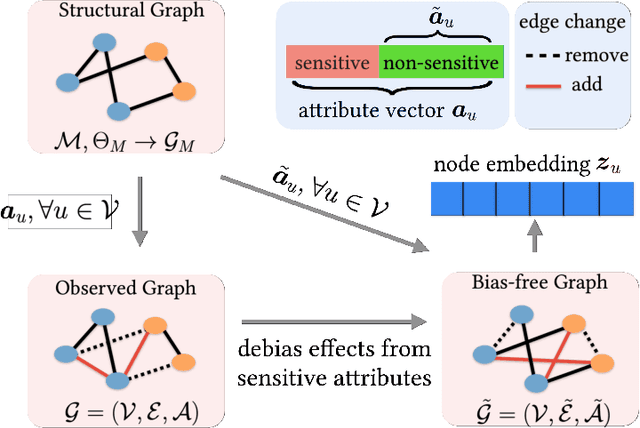
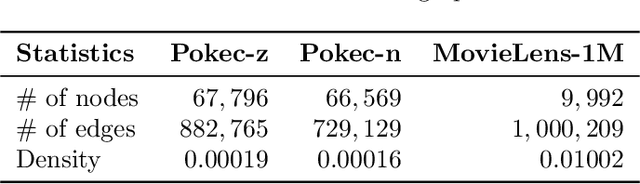
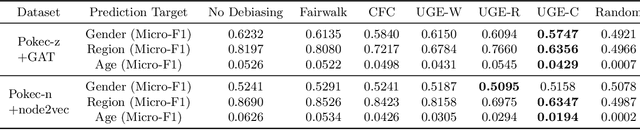
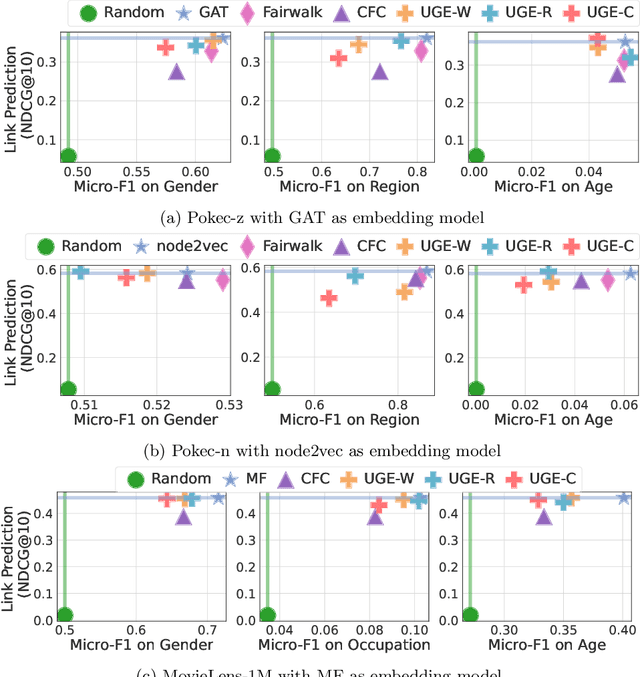
Graph embedding techniques have been increasingly employed in real-world machine learning tasks on graph-structured data, such as social recommendations and protein structure modeling. Since the generation of a graph is inevitably affected by some sensitive node attributes (such as gender and age of users in a social network), the learned graph representations can inherit such sensitive information and introduce undesirable biases in downstream tasks. Most existing works on debiasing graph representations add ad-hoc constraints on the learned embeddings to restrict their distributions, which however compromise the utility of resulting graph representations in downstream tasks. In this paper, we propose a principled new way for obtaining unbiased representations by learning from an underlying bias-free graph that is not influenced by sensitive attributes. Based on this new perspective, we propose two complementary methods for uncovering such an underlying graph with the goal of introducing minimum impact on the utility of learned representations in downstream tasks. Both our theoretical justification and extensive experiment comparisons against state-of-the-art solutions demonstrate the effectiveness of our proposed methods.
Learning Perceptual Concepts by Bootstrapping from Human Queries
Nov 09, 2021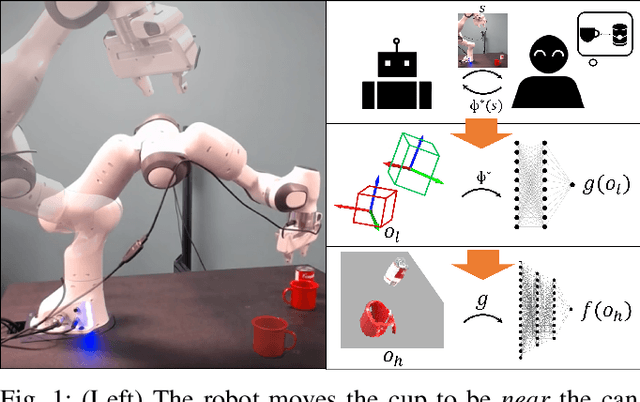
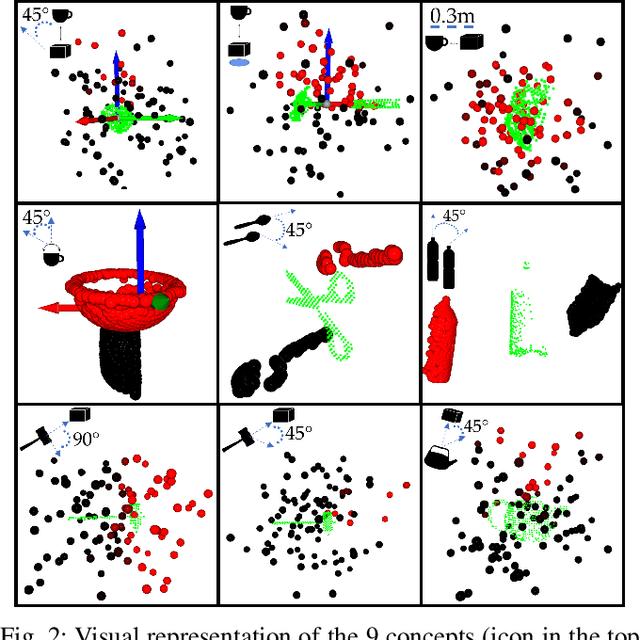
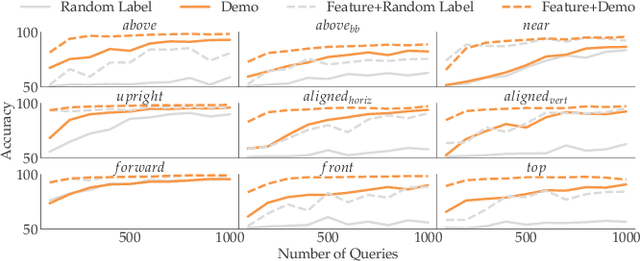
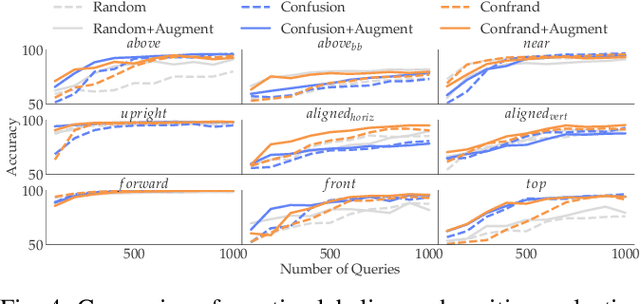
Robots need to be able to learn concepts from their users in order to adapt their capabilities to each user's unique task. But when the robot operates on high-dimensional inputs, like images or point clouds, this is impractical: the robot needs an unrealistic amount of human effort to learn the new concept. To address this challenge, we propose a new approach whereby the robot learns a low-dimensional variant of the concept and uses it to generate a larger data set for learning the concept in the high-dimensional space. This lets it take advantage of semantically meaningful privileged information only accessible at training time, like object poses and bounding boxes, that allows for richer human interaction to speed up learning. We evaluate our approach by learning prepositional concepts that describe object state or multi-object relationships, like above, near, or aligned, which are key to user specification of task goals and execution constraints for robots. Using a simulated human, we show that our approach improves sample complexity when compared to learning concepts directly in the high-dimensional space. We also demonstrate the utility of the learned concepts in motion planning tasks on a 7-DoF Franka Panda robot.