 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
COfEE: A Comprehensive Ontology for Event Extraction from text, with an online annotation tool
Aug 01, 2021
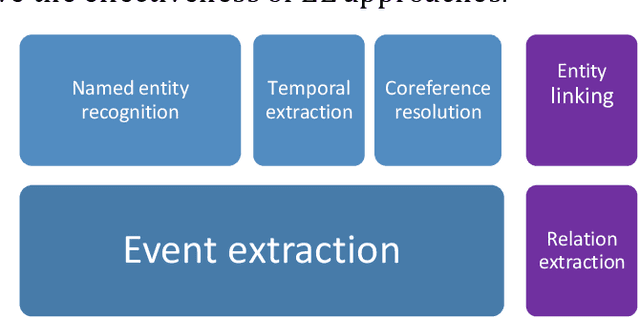

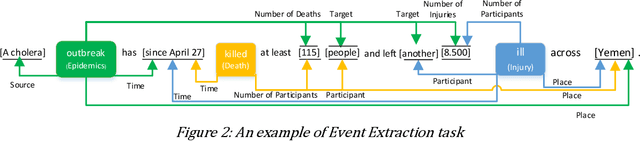
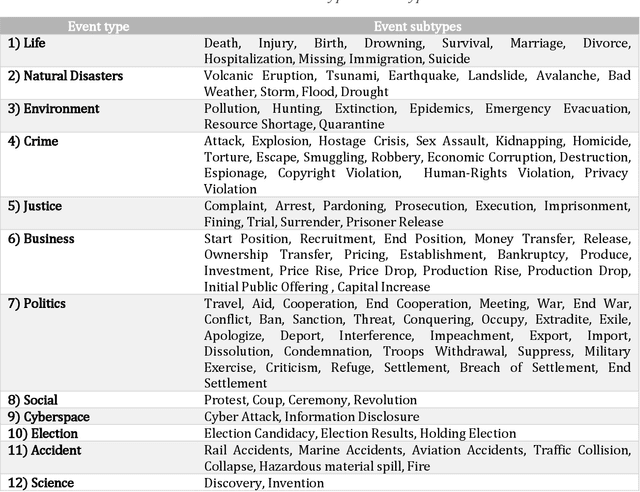
Data is published on the web over time in great volumes, but majority of the data is unstructured, making it hard to understand and difficult to interpret. Information Extraction (IE) methods extract structured information from unstructured data. One of the challenging IE tasks is Event Extraction (EE) which seeks to derive information about specific incidents and their actors from the text. EE is useful in many domains such as building a knowledge base, information retrieval, summarization and online monitoring systems. In the past decades, some event ontologies like ACE, CAMEO and ICEWS were developed to define event forms, actors and dimensions of events observed in the text. These event ontologies still have some shortcomings such as covering only a few topics like political events, having inflexible structure in defining argument roles, lack of analytical dimensions, and complexity in choosing event sub-types. To address these concerns, we propose an event ontology, namely COfEE, that incorporates both expert domain knowledge, previous ontologies and a data-driven approach for identifying events from text. COfEE consists of two hierarchy levels (event types and event sub-types) that include new categories relating to environmental issues, cyberspace, criminal activity and natural disasters which need to be monitored instantly. Also, dynamic roles according to each event sub-type are defined to capture various dimensions of events. In a follow-up experiment, the proposed ontology is evaluated on Wikipedia events, and it is shown to be general and comprehensive. Moreover, in order to facilitate the preparation of gold-standard data for event extraction, a language-independent online tool is presented based on COfEE.
SCORE: Spurious COrrelation REduction for Offline Reinforcement Learning
Oct 24, 2021
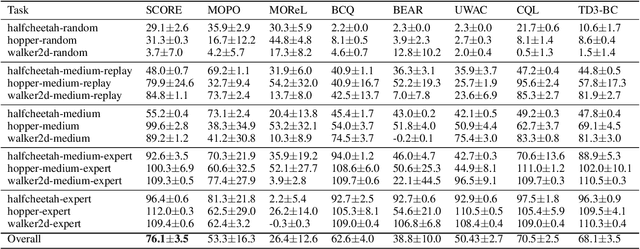
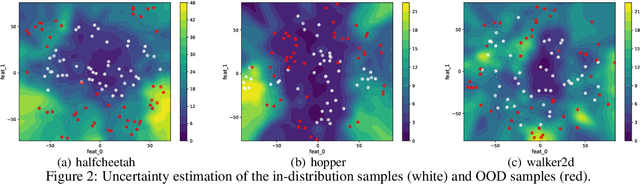

Offline reinforcement learning (RL) aims to learn the optimal policy from a pre-collected dataset without online interactions. Most of the existing studies focus on distributional shift caused by out-of-distribution actions. However, even in-distribution actions can raise serious problems. Since the dataset only contains limited information about the underlying model, offline RL is vulnerable to spurious correlations, i.e., the agent tends to prefer actions that by chance lead to high returns, resulting in a highly suboptimal policy. To address such a challenge, we propose a practical and theoretically guaranteed algorithm SCORE that reduces spurious correlations by combing an uncertainty penalty into policy evaluation. We show that this is consistent with the pessimism principle studied in theory, and the proposed algorithm converges to the optimal policy with a sublinear rate under mild assumptions. By conducting extensive experiments on existing benchmarks, we show that SCORE not only benefits from a solid theory but also obtains strong empirical results on a variety of tasks.
Investigation of Topic Modelling Methods for Understanding the Reports of the Mining Projects in Queensland
Nov 05, 2021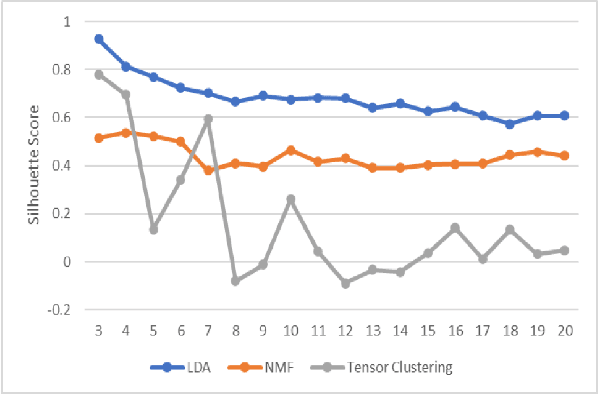
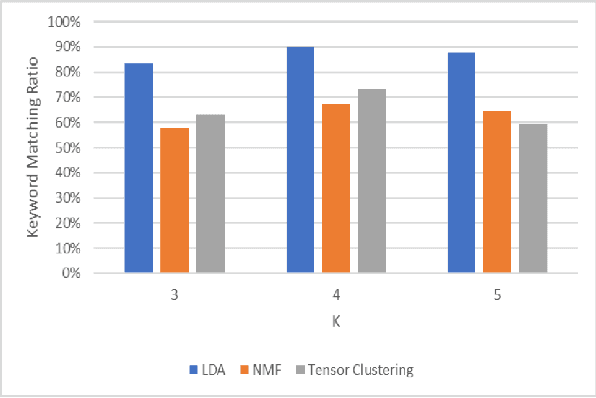
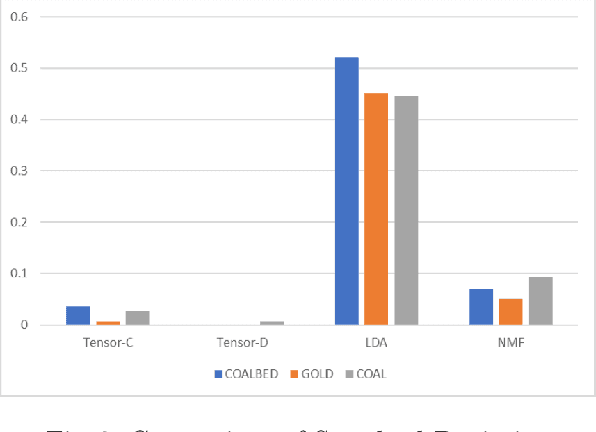
In the mining industry, many reports are generated in the project management process. These past documents are a great resource of knowledge for future success. However, it would be a tedious and challenging task to retrieve the necessary information if the documents are unorganized and unstructured. Document clustering is a powerful approach to cope with the problem, and many methods have been introduced in past studies. Nonetheless, there is no silver bullet that can perform the best for any types of documents. Thus, exploratory studies are required to apply the clustering methods for new datasets. In this study, we will investigate multiple topic modelling (TM) methods. The objectives are finding the appropriate approach for the mining project reports using the dataset of the Geological Survey of Queensland, Department of Resources, Queensland Government, and understanding the contents to get the idea of how to organise them. Three TM methods, Latent Dirichlet Allocation (LDA), Nonnegative Matrix Factorization (NMF), and Nonnegative Tensor Factorization (NTF) are compared statistically and qualitatively. After the evaluation, we conclude that the LDA performs the best for the dataset; however, the possibility remains that the other methods could be adopted with some improvements.
Machine Learning based Medical Image Deepfake Detection: A Comparative Study
Sep 27, 2021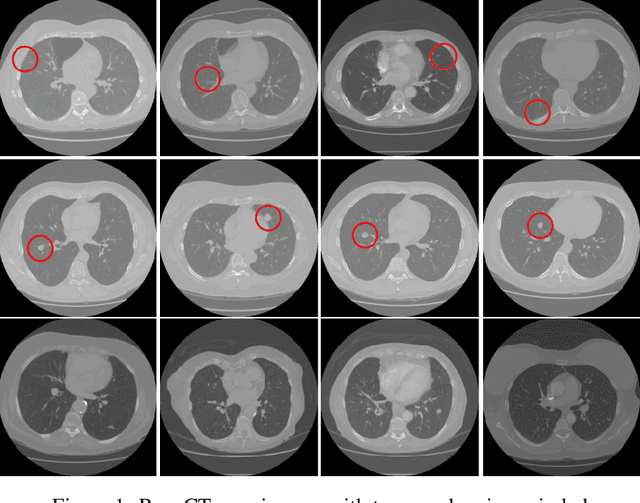
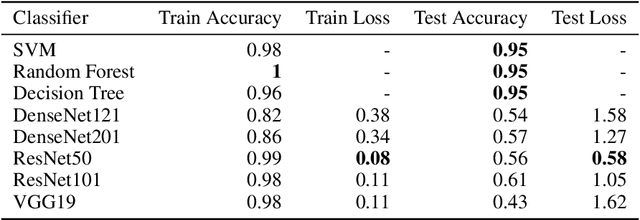
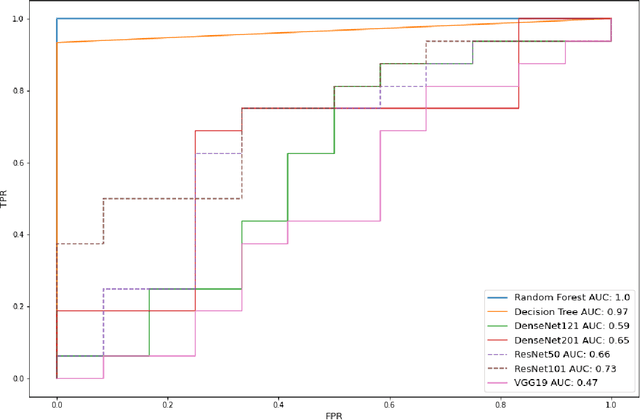
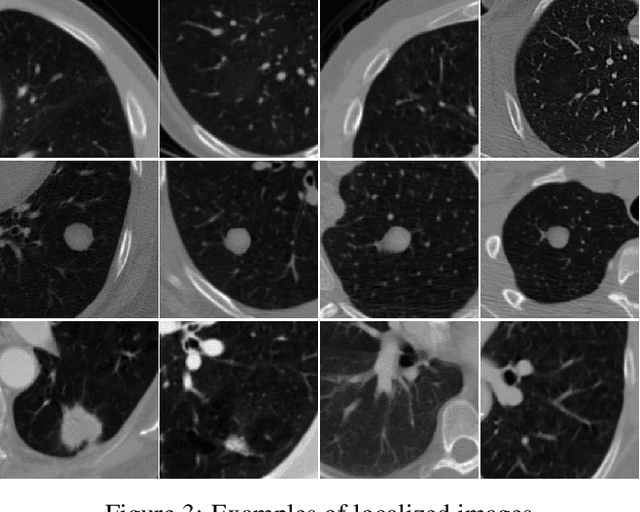
Deep generative networks in recent years have reinforced the need for caution while consuming various modalities of digital information. One avenue of deepfake creation is aligned with injection and removal of tumors from medical scans. Failure to detect medical deepfakes can lead to large setbacks on hospital resources or even loss of life. This paper attempts to address the detection of such attacks with a structured case study. We evaluate different machine learning algorithms and pretrained convolutional neural networks on distinguishing between tampered and untampered data. The findings of this work show near perfect accuracy in detecting instances of tumor injections and removals.
Efficient Anomaly Detection Using Self-Supervised Multi-Cue Tasks
Nov 24, 2021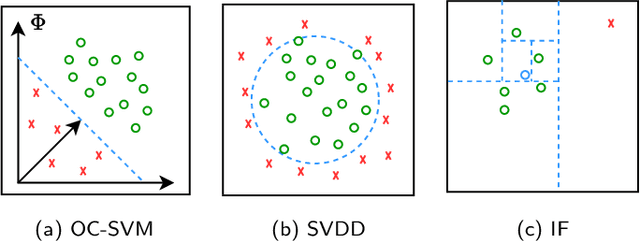
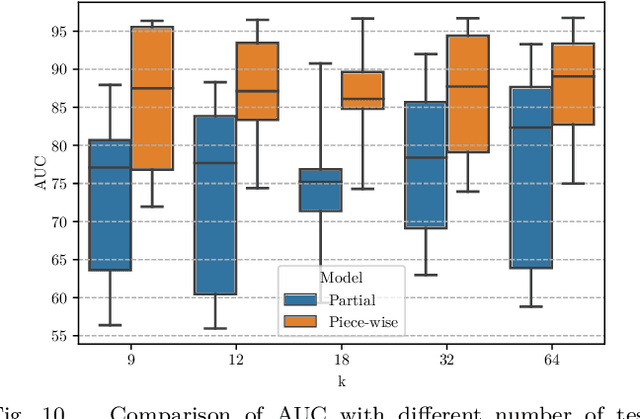
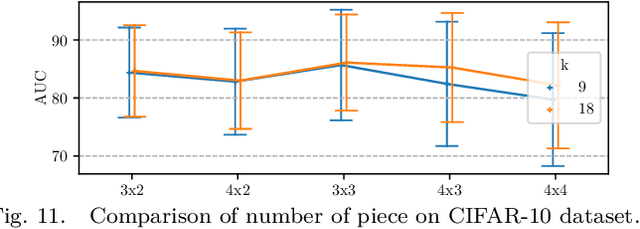
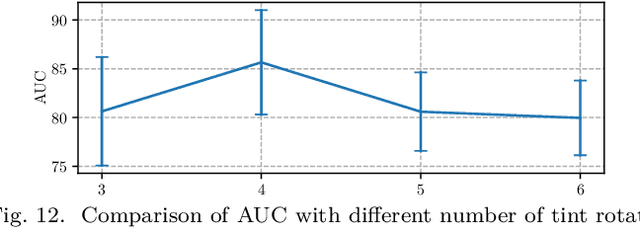
Deep anomaly detection has proven to be an efficient and robust approach in several fields. The introduction of self-supervised learning has greatly helped many methods including anomaly detection where simple geometric transformation recognition tasks are used. However these methods do not perform well on fine-grained problems since they lack finer features and are usually highly dependent on the anomaly type. In this paper, we explore each step of self-supervised anomaly detection with pretext tasks. First, we introduce novel discriminative and generative tasks which focus on different visual cues. A piece-wise jigsaw puzzle task focuses on structure cues, while a tint rotation recognition is used on each piece for colorimetry and a partial re-colorization task is performed. In order for the re-colorization task to focus more on the object rather than on the background, we propose to include the contextual color information of the image border. Then, we present a new out-of-distribution detection function and highlight its better stability compared to other out-of-distribution detection methods. Along with it, we also experiment different score fusion functions. Finally, we evaluate our method on a comprehensive anomaly detection protocol composed of object anomalies with classical object recognition, style anomalies with fine-grained classification and local anomalies with face anti-spoofing datasets. Our model can more accurately learn highly discriminative features using these self-supervised tasks. It outperforms state-of-the-art with up to 36% relative error improvement on object anomalies and 40% on face anti-spoofing problems.
Learning De-identified Representations of Prosody from Raw Audio
Jul 17, 2021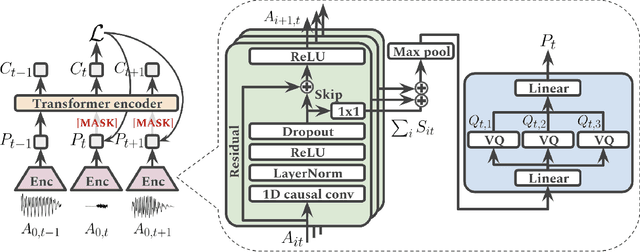
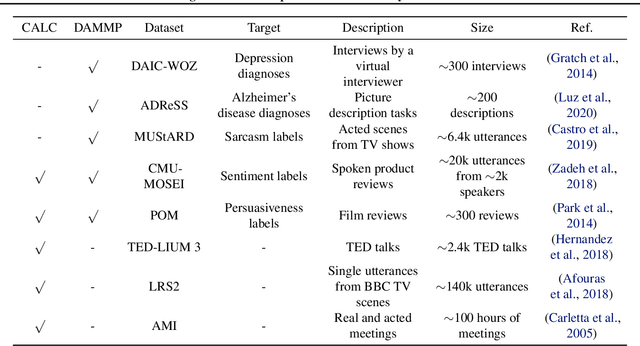
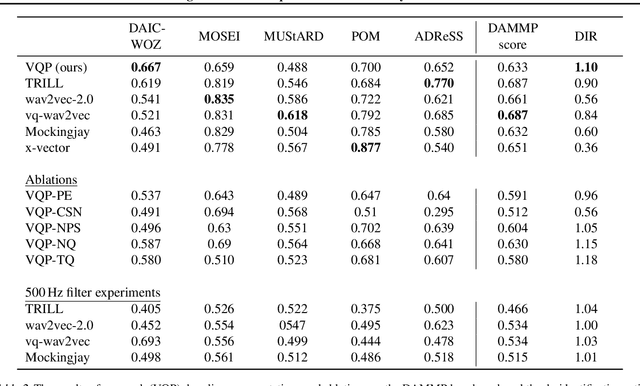
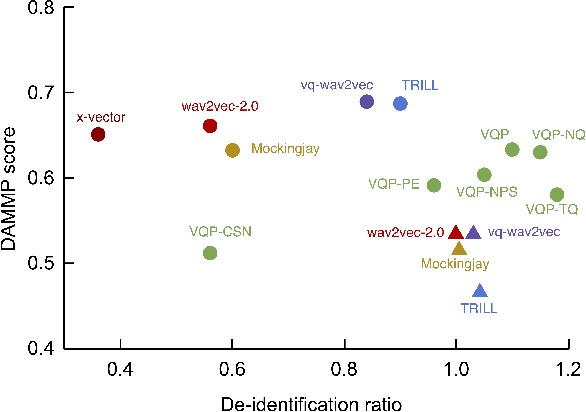
We propose a method for learning de-identified prosody representations from raw audio using a contrastive self-supervised signal. Whereas prior work has relied on conditioning models on bottlenecks, we introduce a set of inductive biases that exploit the natural structure of prosody to minimize timbral information and decouple prosody from speaker representations. Despite aggressive downsampling of the input and having no access to linguistic information, our model performs comparably to state-of-the-art speech representations on DAMMP, a new benchmark we introduce for spoken language understanding. We use minimum description length probing to show that our representations have selectively learned the subcomponents of non-timbral prosody, and that the product quantizer naturally disentangles them without using bottlenecks. We derive an information-theoretic definition of speech de-identifiability and use it to demonstrate that our prosody representations are less identifiable than other speech representations.
* ICML 2021
Conversational speech recognition leveraging effective fusion methods for cross-utterance language modeling
Nov 05, 2021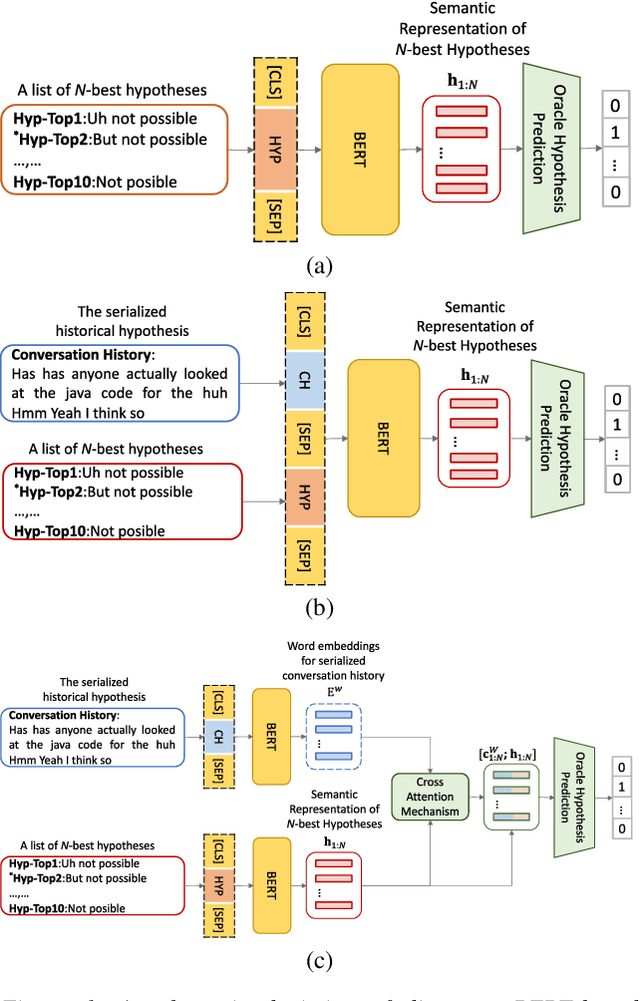
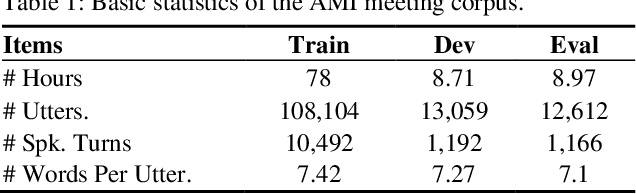
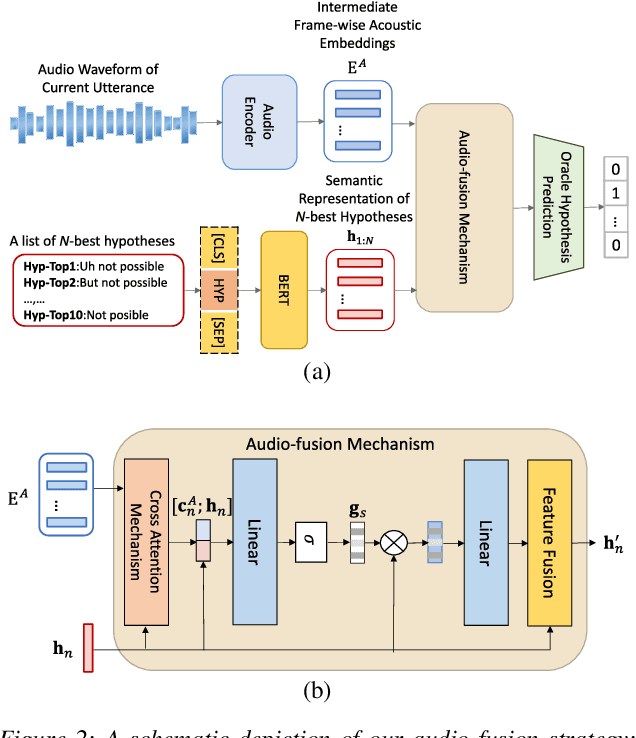

Conversational speech normally is embodied with loose syntactic structures at the utterance level but simultaneously exhibits topical coherence relations across consecutive utterances. Prior work has shown that capturing longer context information with a recurrent neural network or long short-term memory language model (LM) may suffer from the recent bias while excluding the long-range context. In order to capture the long-term semantic interactions among words and across utterances, we put forward disparate conversation history fusion methods for language modeling in automatic speech recognition (ASR) of conversational speech. Furthermore, a novel audio-fusion mechanism is introduced, which manages to fuse and utilize the acoustic embeddings of a current utterance and the semantic content of its corresponding conversation history in a cooperative way. To flesh out our ideas, we frame the ASR N-best hypothesis rescoring task as a prediction problem, leveraging BERT, an iconic pre-trained LM, as the ingredient vehicle to facilitate selection of the oracle hypothesis from a given N-best hypothesis list. Empirical experiments conducted on the AMI benchmark dataset seem to demonstrate the feasibility and efficacy of our methods in relation to some current top-of-line methods.
ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers
Oct 13, 2021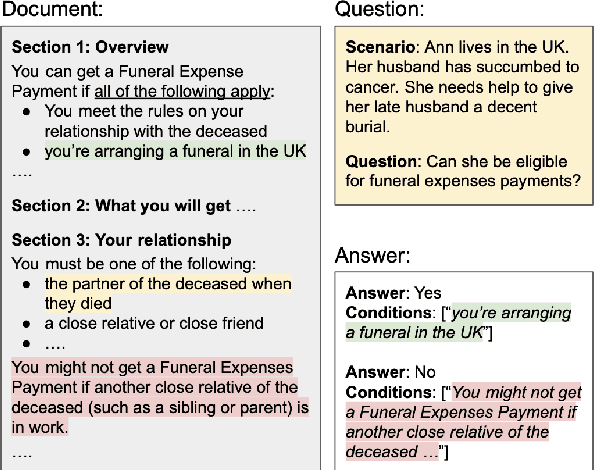
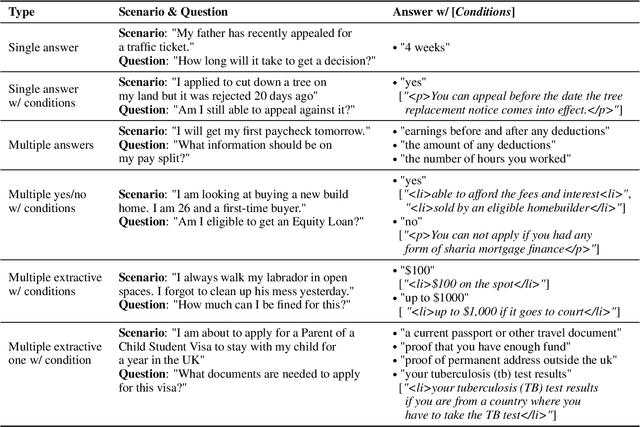
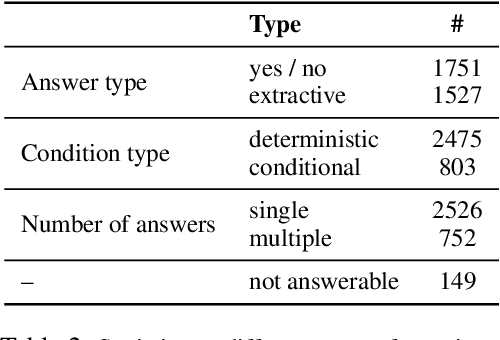
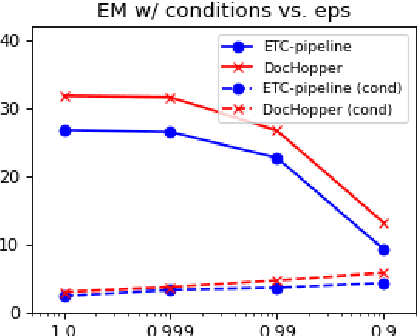
We describe a Question Answering (QA) dataset that contains complex questions with conditional answers, i.e. the answers are only applicable when certain conditions apply. We call this dataset ConditionalQA. In addition to conditional answers, the dataset also features: (1) long context documents with information that is related in logically complex ways; (2) multi-hop questions that require compositional logical reasoning; (3) a combination of extractive questions, yes/no questions, questions with multiple answers, and not-answerable questions; (4) questions asked without knowing the answers. We show that ConditionalQA is challenging for many of the existing QA models, especially in selecting answer conditions. We believe that this dataset will motivate further research in answering complex questions over long documents. Data and leaderboard are publicly available at \url{https://github.com/haitian-sun/ConditionalQA}.
MSFNet:Multi-scale features network for monocular depth estimation
Jul 14, 2021
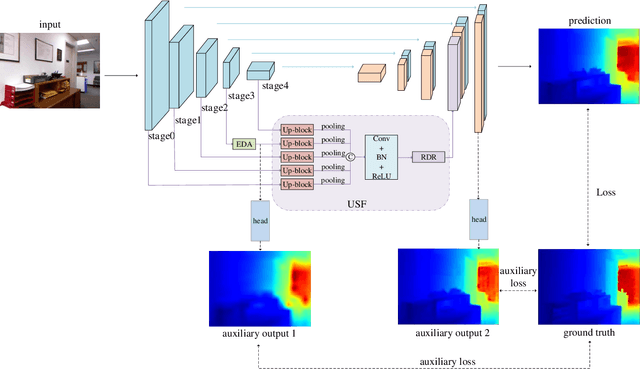
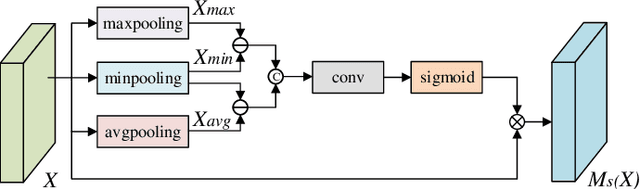
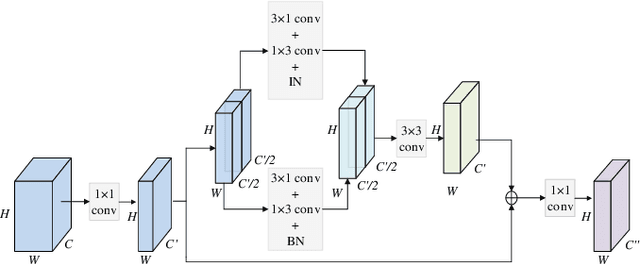
In recent years, monocular depth estimation is applied to understand the surrounding 3D environment and has made great progress. However, there is an ill-posed problem on how to gain depth information directly from a single image. With the rapid development of deep learning, this problem is possible to be solved. Although more and more approaches are proposed one after another, most of existing methods inevitably lost details due to continuous downsampling when mapping from RGB space to depth space. To the end, we design a Multi-scale Features Network (MSFNet), which consists of Enhanced Diverse Attention (EDA) module and Upsample-Stage Fusion (USF) module. The EDA module employs the spatial attention method to learn significant spatial information, while USF module complements low-level detail information with high-level semantic information from the perspective of multi-scale feature fusion to improve the predicted effect. In addition, since the simple samples are always trained to a better effect first, the hard samples are difficult to converge. Therefore, we design a batch-loss to assign large loss factors to the harder samples in a batch. Experiments on NYU-Depth V2 dataset and KITTI dataset demonstrate that our proposed approach is more competitive with the state-of-the-art methods in both qualitative and quantitative evaluation.
Self-Supervised Learning for MRI Reconstruction with a Parallel Network Training Framework
Sep 26, 2021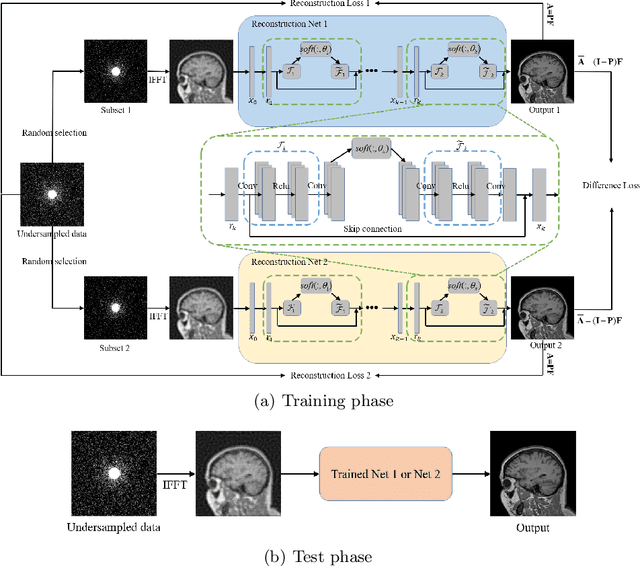
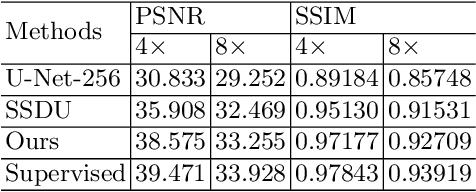

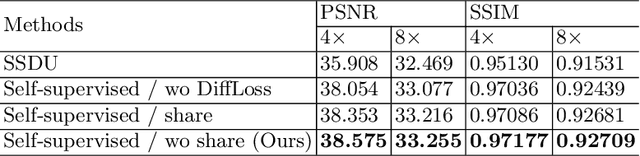
Image reconstruction from undersampled k-space data plays an important role in accelerating the acquisition of MR data, and a lot of deep learning-based methods have been exploited recently. Despite the achieved inspiring results, the optimization of these methods commonly relies on the fully-sampled reference data, which are time-consuming and difficult to collect. To address this issue, we propose a novel self-supervised learning method. Specifically, during model optimization, two subsets are constructed by randomly selecting part of k-space data from the undersampled data and then fed into two parallel reconstruction networks to perform information recovery. Two reconstruction losses are defined on all the scanned data points to enhance the network's capability of recovering the frequency information. Meanwhile, to constrain the learned unscanned data points of the network, a difference loss is designed to enforce consistency between the two parallel networks. In this way, the reconstruction model can be properly trained with only the undersampled data. During the model evaluation, the undersampled data are treated as the inputs and either of the two trained networks is expected to reconstruct the high-quality results. The proposed method is flexible and can be employed in any existing deep learning-based method. The effectiveness of the method is evaluated on an open brain MRI dataset. Experimental results demonstrate that the proposed self-supervised method can achieve competitive reconstruction performance compared to the corresponding supervised learning method at high acceleration rates (4 and 8). The code is publicly available at \url{https://github.com/chenhu96/Self-Supervised-MRI-Reconstruction}.