 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cooperative Multi-Agent Actor-Critic for Privacy-Preserving Load Scheduling in a Residential Microgrid
Oct 06, 2021
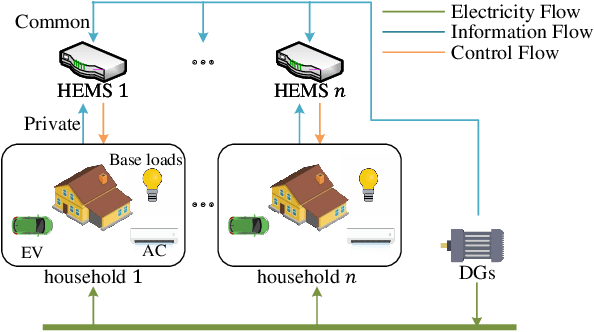
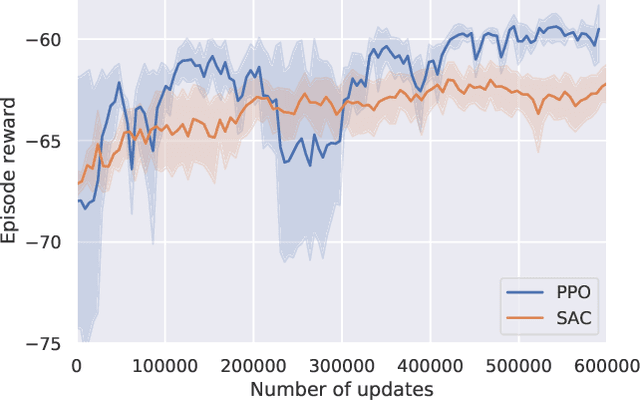
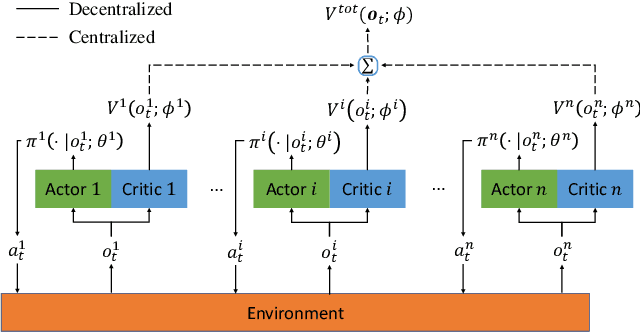
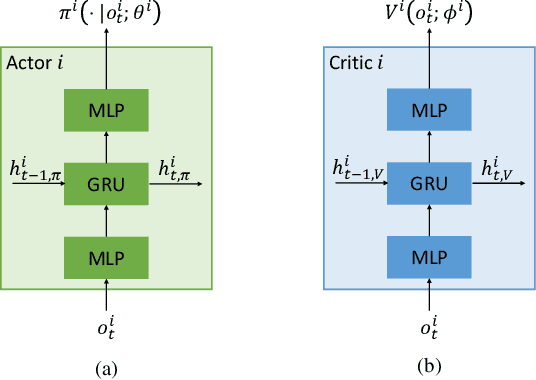
As a scalable data-driven approach, multi-agent reinforcement learning (MARL) has made remarkable advances in solving the cooperative residential load scheduling problems. However, the common centralized training strategy of MARL algorithms raises privacy risks for involved households. In this work, we propose a privacy-preserving multi-agent actor-critic framework where the decentralized actors are trained with distributed critics, such that both the decentralized execution and the distributed training do not require the global state information. The proposed framework can preserve the privacy of the households while simultaneously learn the multi-agent credit assignment mechanism implicitly. The simulation experiments demonstrate that the proposed framework significantly outperforms the existing privacy-preserving actor-critic framework, and can achieve comparable performance to the state-of-the-art actor-critic framework without privacy constraints.
PredProp: Bidirectional Stochastic Optimization with Precision Weighted Predictive Coding
Nov 16, 2021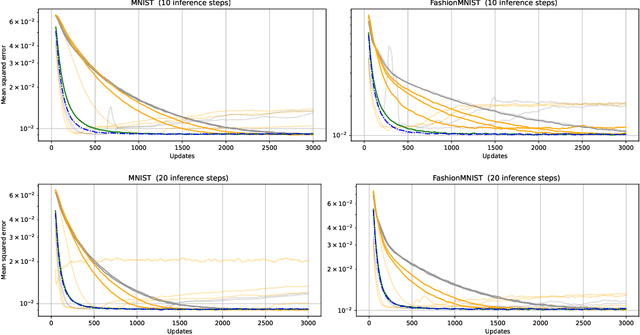
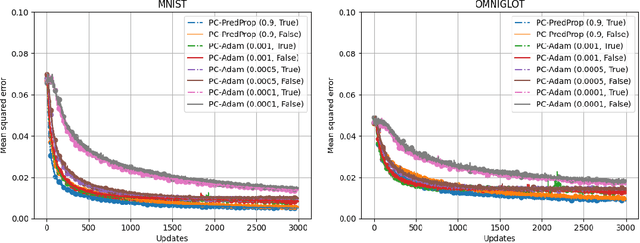
We present PredProp, a method for bidirectional, parallel and local optimisation of weights, activities and precision in neural networks. PredProp jointly addresses inference and learning, scales learning rates dynamically and weights gradients by the curvature of the loss function by optimizing prediction error precision. PredProp optimizes network parameters with Stochastic Gradient Descent and error forward propagation based strictly on prediction errors and variables locally available to each layer. Neighboring layers optimise shared activity variables so that prediction errors can propagate forward in the network, while predictions propagate backwards. This process minimises the negative Free Energy, or evidence lower bound of the entire network. We show that networks trained with PredProp resemble gradient based predictive coding when the number of weights between neighboring activity variables is one. In contrast to related work, PredProp generalizes towards backward connections of arbitrary depth and optimizes precision for any deep network architecture. Due to the analogy between prediction error precision and the Fisher information for each layer, PredProp implements a form of Natural Gradient Descent. When optimizing DNN models, layer-wise PredProp renders the model a bidirectional predictive coding network. Alternatively DNNs can parameterize the weights between two activity variables. We evaluate PredProp for dense DNNs on simple inference, learning and combined tasks. We show that, without an explicit sampling step in the network, PredProp implements a form of variational inference that allows to learn disentangled embeddings from low amounts of data and leave evaluation on more complex tasks and datasets to future work.
The IDLAB VoxCeleb Speaker Recognition Challenge 2021 System Description
Sep 09, 2021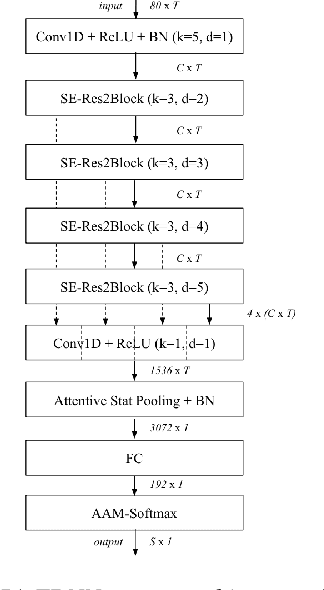
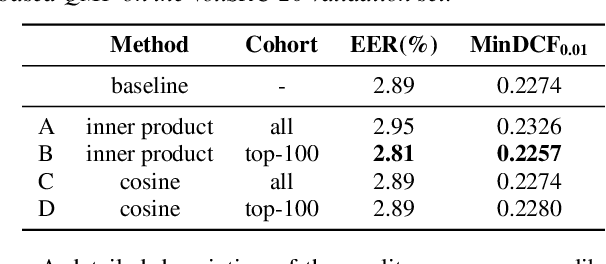
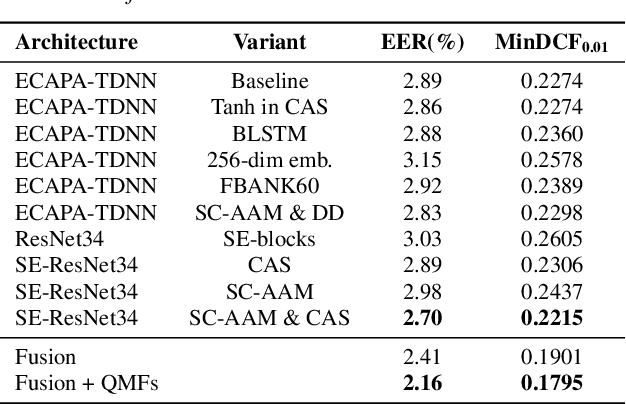
This technical report describes the IDLab submission for track 1 and 2 of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). This speaker verification competition focuses on short duration test recordings and cross-lingual trials. Currently, both Time Delay Neural Networks (TDNNs) and ResNets achieve state-of-the-art results in speaker verification. We opt to use a system fusion of hybrid architectures in our final submission. An ECAPA-TDNN baseline is enhanced with a 2D convolutional stem to transfer some of the strong characteristics of a ResNet based model to this hybrid CNN-TDNN architecture. Similarly, we incorporate absolute frequency positional information in the SE-ResNet architectures. All models are trained with a special mini-batch data sampling technique which constructs mini-batches with data that is the most challenging for the system on the level of intra-speaker variability. This intra-speaker variability is mainly caused by differences in language and background conditions between the speaker's utterances. The cross-lingual effects on the speaker verification scores are further compensated by introducing a binary cross-linguality trial feature in the logistic regression based system calibration. The final system fusion with two ECAPA CNN-TDNNs and three SE-ResNets enhanced with frequency positional information achieved a third place on the VoxSRC-21 leaderboard for both track 1 and 2 with a minDCF of 0.1291 and 0.1313 respectively.
InfoRL: Interpretable Reinforcement Learning using Information Maximization
May 24, 2019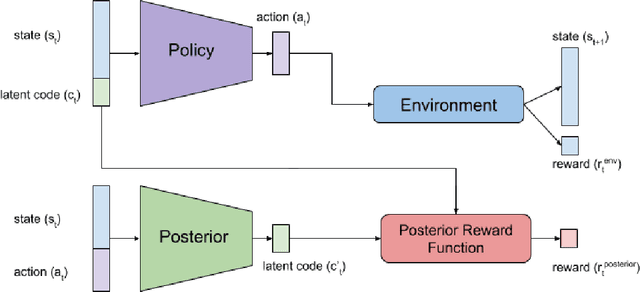

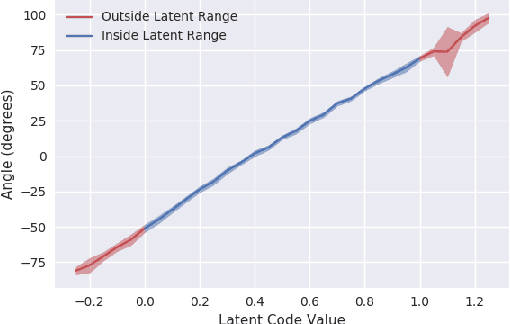
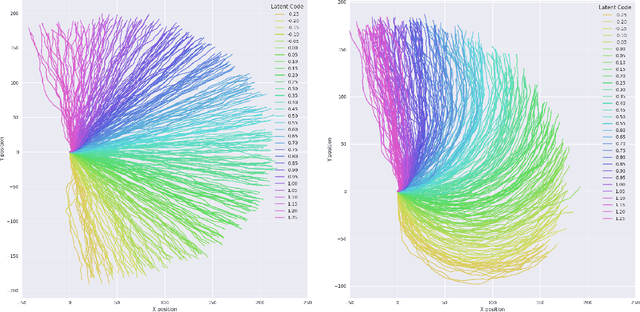
Recent advances in reinforcement learning have proved that given an environment we can learn to perform a task in that environment if we have access to some form of a reward function (dense, sparse or derived from IRL). But most of the algorithms focus on learning a single best policy to perform a given set of tasks. In this paper, we focus on an algorithm that learns to not just perform a task but different ways to perform the same task. As we know when the environment is complex enough there always exists multiple ways to perform a task. We show that using the concept of information maximization it is possible to learn latent codes for discovering multiple ways to perform any given task in an environment.
Arbitrary Virtual Try-On Network: Characteristics Preservation and Trade-off between Body and Clothing
Nov 24, 2021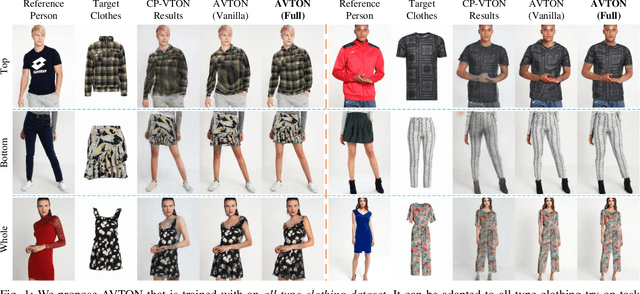
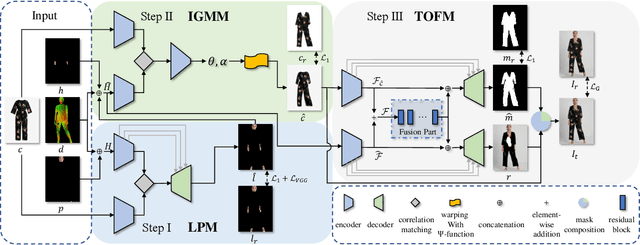


Deep learning based virtual try-on system has achieved some encouraging progress recently, but there still remain several big challenges that need to be solved, such as trying on arbitrary clothes of all types, trying on the clothes from one category to another and generating image-realistic results with few artifacts. To handle this issue, we in this paper first collect a new dataset with all types of clothes, \ie tops, bottoms, and whole clothes, each one has multiple categories with rich information of clothing characteristics such as patterns, logos, and other details. Based on this dataset, we then propose the Arbitrary Virtual Try-On Network (AVTON) that is utilized for all-type clothes, which can synthesize realistic try-on images by preserving and trading off characteristics of the target clothes and the reference person. Our approach includes three modules: 1) Limbs Prediction Module, which is utilized for predicting the human body parts by preserving the characteristics of the reference person. This is especially good for handling cross-category try-on task (\eg long sleeves \(\leftrightarrow\) short sleeves or long pants \(\leftrightarrow\) skirts, \etc), where the exposed arms or legs with the skin colors and details can be reasonably predicted; 2) Improved Geometric Matching Module, which is designed to warp clothes according to the geometry of the target person. We improve the TPS based warping method with a compactly supported radial function (Wendland's \(\Psi\)-function); 3) Trade-Off Fusion Module, which is to trade off the characteristics of the warped clothes and the reference person. This module is to make the generated try-on images look more natural and realistic based on a fine-tune symmetry of the network structure. Extensive simulations are conducted and our approach can achieve better performance compared with the state-of-the-art virtual try-on methods.
Poformer: A simple pooling transformer for speaker verification
Oct 10, 2021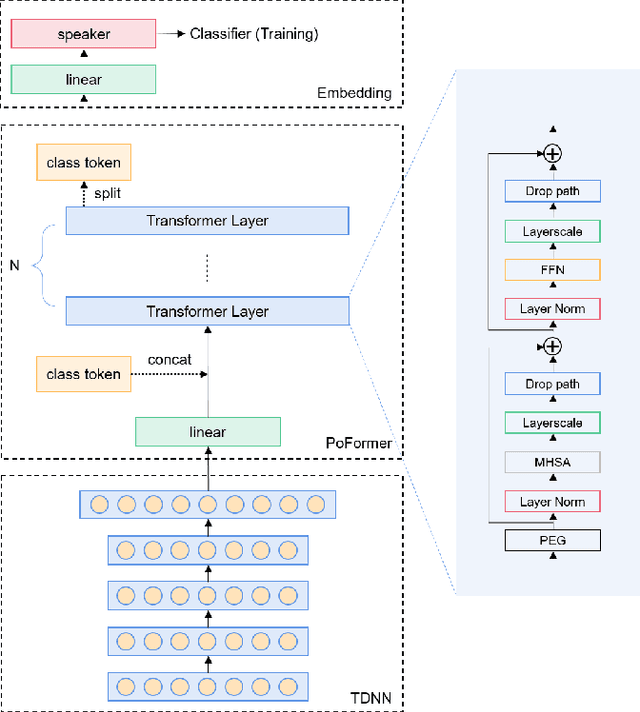
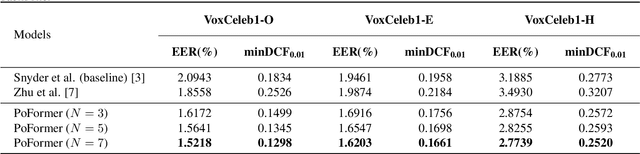
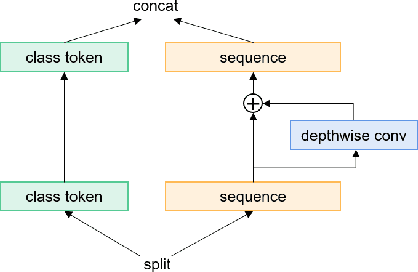
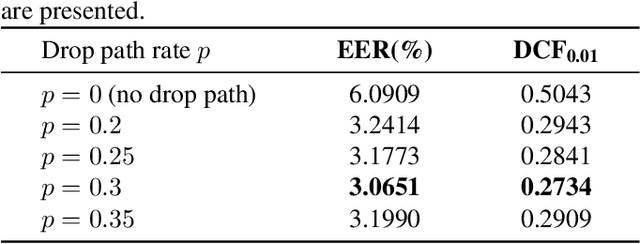
Most recent speaker verification systems are based on extracting speaker embeddings using a deep neural network. The pooling layer in the network aims to aggregate frame-level features extracted by the backbone. In this paper, we propose a new transformer based pooling structure called PoFormer to enhance the ability of the pooling layer to capture information along the whole time axis. Different from previous works that apply attention mechanism in a simple way or implement the multi-head mechanism in serial instead of in parallel, PoFormer follows the initial transformer structure with some minor modifications like a positional encoding generator, drop path and LayerScale to make the training procedure more stable and to prevent overfitting. Evaluated on various datasets, PoFormer outperforms the existing pooling system with at least a 13.00% improvement in EER and a 9.12% improvement in minDCF.
Adaptive Transmit Waveform Design
Nov 16, 2021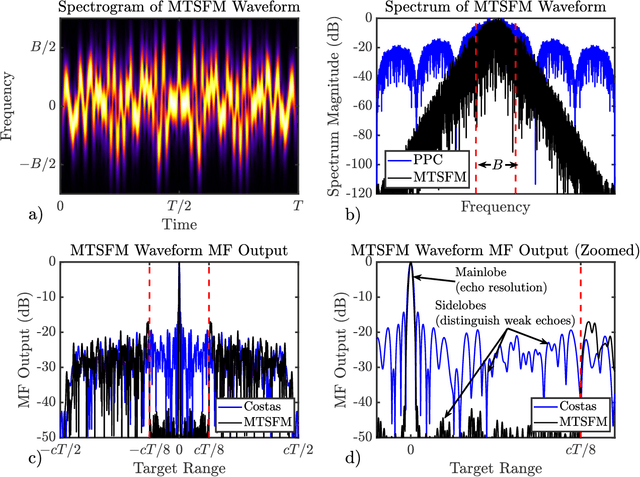
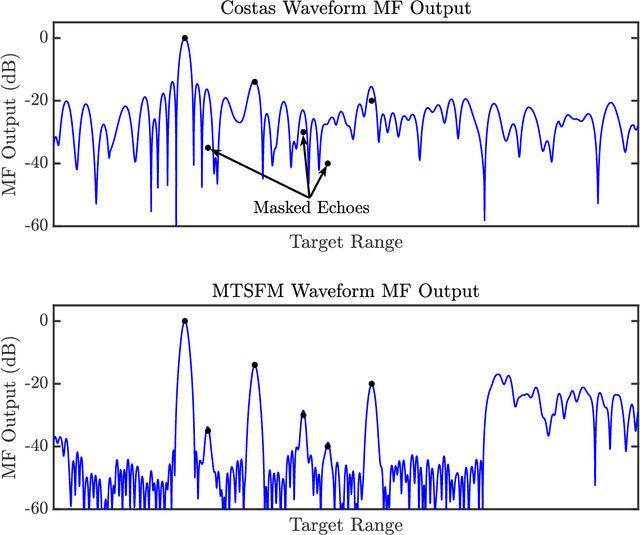
Recent research efforts in the Anti-Submarine Warfare (ASW) community have focused on developing sonar systems that adapt to their acoustic environment, referred to as "cognitive" sonars. Cognitive active sonar systems utilize principles of the perception action cycle of cognition to leverage information gathered from earlier sensing interactions with the underwater acoustic environment. This in turn informs the selection of system parameters to optimize target detection, classification, localization, and tracking performance in that acoustic environment. Of the many system parameters such a cognitive sonar system could potentially adapt, the acoustic signal transmitted into the medium, also known as the transmit waveform, has a profound impact on system performance. Many of the physical characteristics of the acoustic environment are contained in the return echo signal that is composed of amplitude scaled (target strength), time-delayed (target range) and Doppler shifted (target range-rate) echoes of the transmit waveform. This paper briefly describes a spectrally compact adaptive FM waveform model using Multi-Tone Sinusoidal Frequency Modulation (MTSFM). The MTSFM waveform's frequency and phase modulation functions are composed of a finite set of weighted sinusoidal harmonics. The weights for each harmonic are utilized as a discrete set of design coefficients. Adjusting these coefficients results in constant amplitude, spectrally compact FM waveforms with unique characteristics. The adaptability of the MTSFM combined with its transmitter friendly properties make it an attractive waveform type for a variety of active sonar applications and may provide a cognitive sonar system the ability to generate a complementary set of finely tuned waveforms for the novel scenarios and environments that it may encounter.
Towards the D-Optimal Online Experiment Design for Recommender Selection
Oct 23, 2021
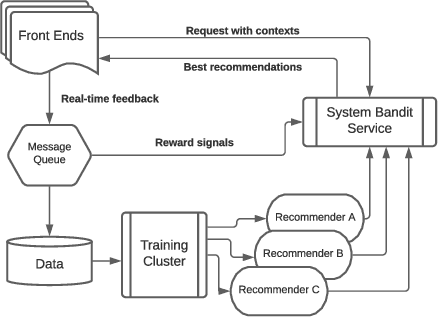
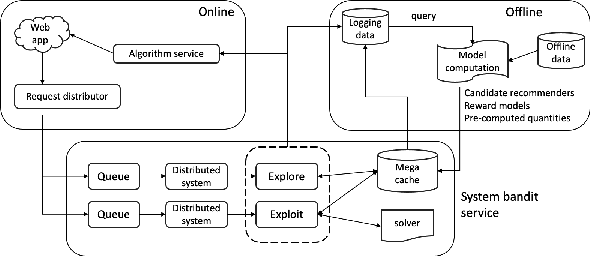
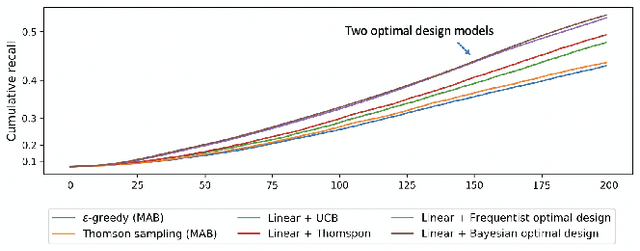
Selecting the optimal recommender via online exploration-exploitation is catching increasing attention where the traditional A/B testing can be slow and costly, and offline evaluations are prone to the bias of history data. Finding the optimal online experiment is nontrivial since both the users and displayed recommendations carry contextual features that are informative to the reward. While the problem can be formalized via the lens of multi-armed bandits, the existing solutions are found less satisfactorily because the general methodologies do not account for the case-specific structures, particularly for the e-commerce recommendation we study. To fill in the gap, we leverage the \emph{D-optimal design} from the classical statistics literature to achieve the maximum information gain during exploration, and reveal how it fits seamlessly with the modern infrastructure of online inference. To demonstrate the effectiveness of the optimal designs, we provide semi-synthetic simulation studies with published code and data for reproducibility purposes. We then use our deployment example on Walmart.com to fully illustrate the practical insights and effectiveness of the proposed methods.
Sub-band coding of hexagonal images
Oct 06, 2021

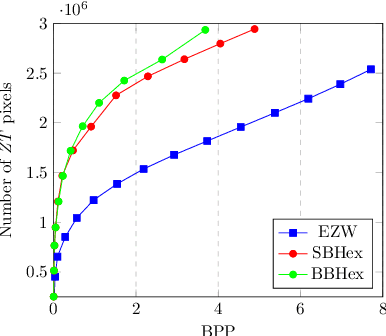
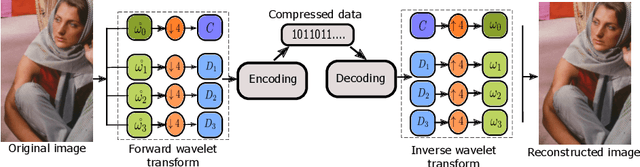
According to the circle-packing theorem, the packing efficiency of a hexagonal lattice is higher than an equivalent square tessellation. Consequently, in several contexts, hexagonally sampled images compared to their Cartesian counterparts are better at preserving information content. In this paper, novel mapping techniques alongside the wavelet compression scheme are presented for hexagonal images. Specifically, we introduce two tree-based coding schemes, referred to as SBHex (spirally-mapped branch-coding for hexagonal images) and BBHex (breadth-first block-coding for hexagonal images). Both of these coding schemes respect the geometry of the hexagonal lattice and yield better compression results. Our empirical results show that the proposed algorithms for hexagonal images produce better reconstruction quality at low bits per pixel representations compared to the tree-based coding counterparts for the Cartesian grid.
* Accepted Manuscript
Accelerating non-LTE synthesis and inversions with graph networks
Nov 20, 2021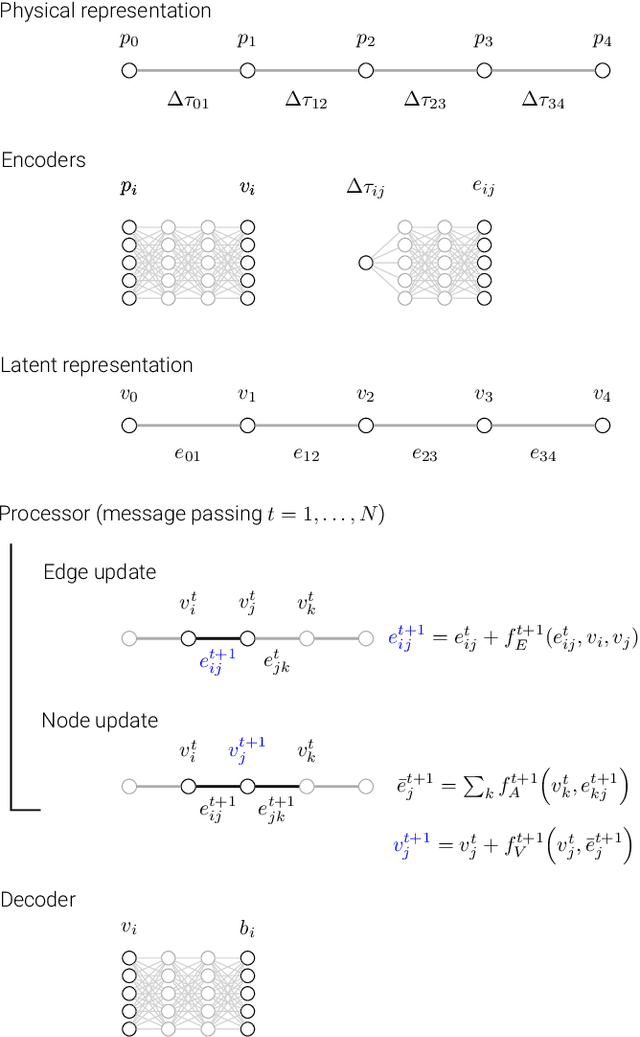
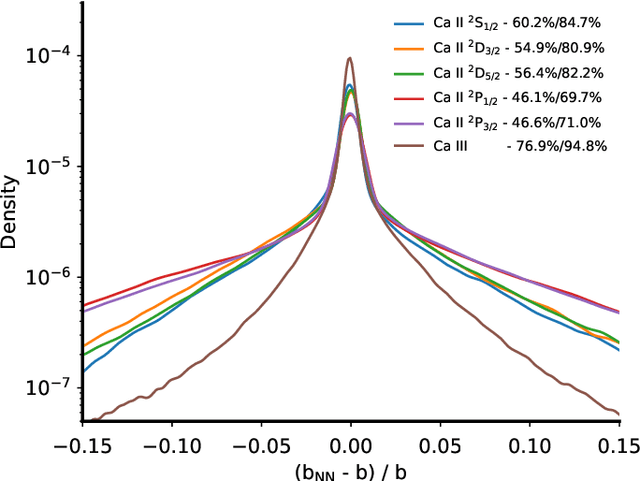
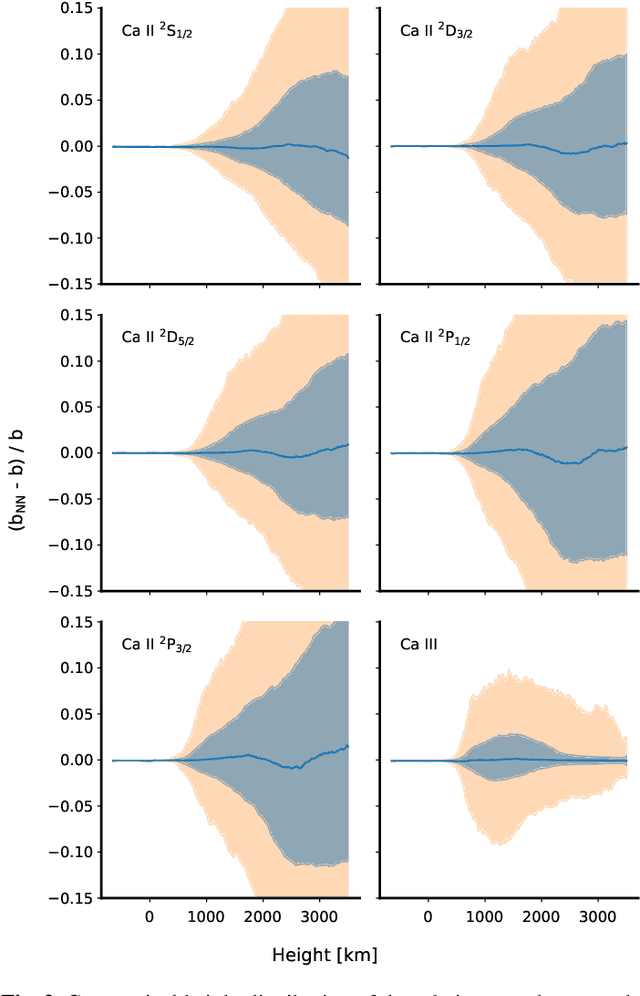
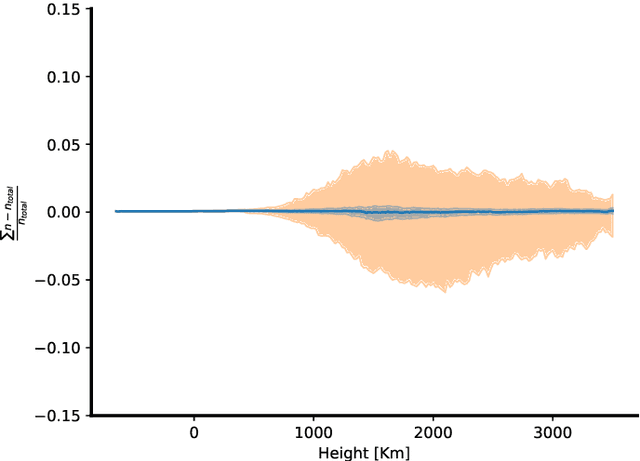
Context: The computational cost of fast non-LTE synthesis is one of the challenges that limits the development of 2D and 3D inversion codes. It also makes the interpretation of observations of lines formed in the chromosphere and transition region a slow and computationally costly process, which limits the inference of the physical properties on rather small fields of view. Having access to a fast way of computing the deviation from the LTE regime through the departure coefficients could largely alleviate this problem. Aims: We propose to build and train a graph network that quickly predicts the atomic level populations without solving the non-LTE problem. Methods: We find an optimal architecture for the graph network for predicting the departure coefficients of the levels of an atom from the physical conditions of a model atmosphere. A suitable dataset with a representative sample of potential model atmospheres is used for training. This dataset has been computed using existing non-LTE synthesis codes. Results: The graph network has been integrated into existing synthesis and inversion codes for the particular case of \caii. We demonstrate orders of magnitude gain in computing speed. We analyze the generalization capabilities of the graph network and demonstrate that it produces good predicted departure coefficients for unseen models. We implement this approach in \hazel\ and show how the inversions nicely compare with those obtained with standard non-LTE inversion codes. Our approximate method opens up the possibility of extracting physical information from the chromosphere on large fields-of-view with time evolution. This allows us to understand better this region of the Sun, where large spatial and temporal scales are crucial.