 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Joint Inductive and Transductive Learning for Video Object Segmentation
Aug 08, 2021
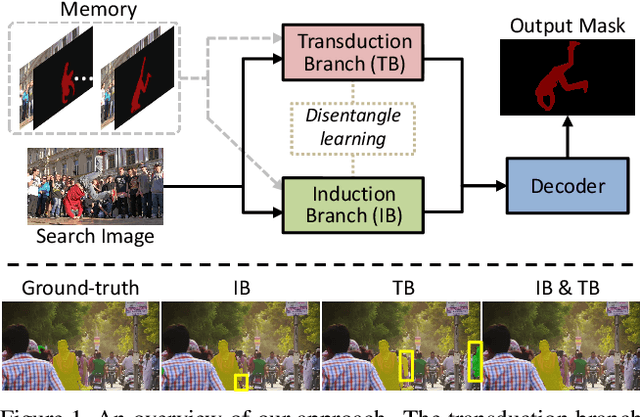
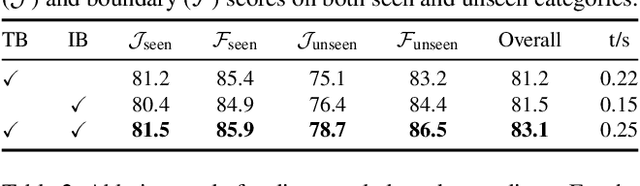
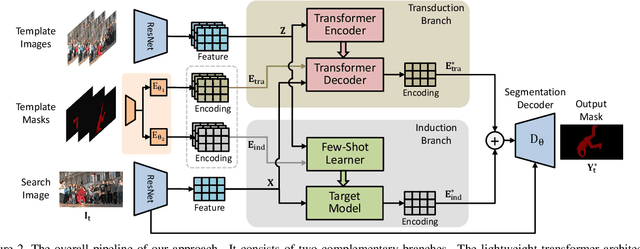
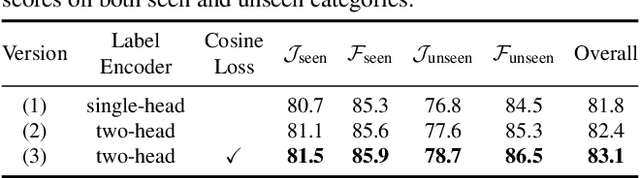
Semi-supervised video object segmentation is a task of segmenting the target object in a video sequence given only a mask annotation in the first frame. The limited information available makes it an extremely challenging task. Most previous best-performing methods adopt matching-based transductive reasoning or online inductive learning. Nevertheless, they are either less discriminative for similar instances or insufficient in the utilization of spatio-temporal information. In this work, we propose to integrate transductive and inductive learning into a unified framework to exploit the complementarity between them for accurate and robust video object segmentation. The proposed approach consists of two functional branches. The transduction branch adopts a lightweight transformer architecture to aggregate rich spatio-temporal cues while the induction branch performs online inductive learning to obtain discriminative target information. To bridge these two diverse branches, a two-head label encoder is introduced to learn the suitable target prior for each of them. The generated mask encodings are further forced to be disentangled to better retain their complementarity. Extensive experiments on several prevalent benchmarks show that, without the need of synthetic training data, the proposed approach sets a series of new state-of-the-art records. Code is available at https://github.com/maoyunyao/JOINT.
Towards Reformulating Essence Specifications for Robustness
Nov 01, 2021



The Essence language allows a user to specify a constraint problem at a level of abstraction above that at which constraint modelling decisions are made. Essence specifications are refined into constraint models using the Conjure automated modelling tool, which employs a suite of refinement rules. However, Essence is a rich language in which there are many equivalent ways to specify a given problem. A user may therefore omit the use of domain attributes or abstract types, resulting in fewer refinement rules being applicable and therefore a reduced set of output models from which to select. This paper addresses the problem of recovering this information automatically to increase the robustness of the quality of the output constraint models in the face of variation in the input Essence specification. We present reformulation rules that can change the type of a decision variable or add attributes that shrink its domain. We demonstrate the efficacy of this approach in terms of the quantity and quality of models Conjure can produce from the transformed specification compared with the original.
Dense Prediction with Attentive Feature Aggregation
Nov 01, 2021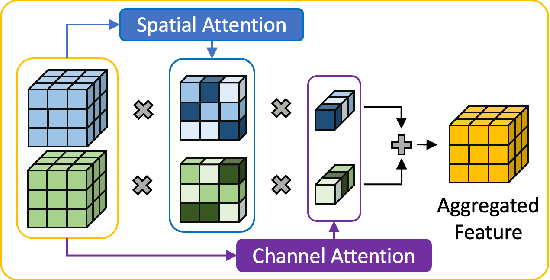

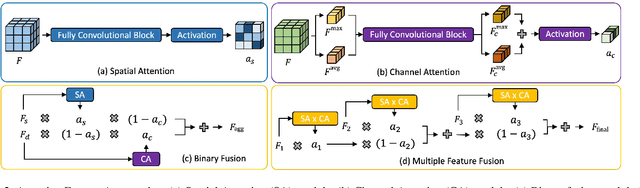
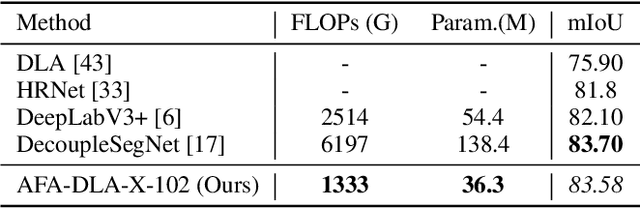
Aggregating information from features across different layers is an essential operation for dense prediction models. Despite its limited expressiveness, feature concatenation dominates the choice of aggregation operations. In this paper, we introduce Attentive Feature Aggregation (AFA) to fuse different network layers with more expressive non-linear operations. AFA exploits both spatial and channel attention to compute weighted average of the layer activations. Inspired by neural volume rendering, we extend AFA with Scale-Space Rendering (SSR) to perform late fusion of multi-scale predictions. AFA is applicable to a wide range of existing network designs. Our experiments show consistent and significant improvements on challenging semantic segmentation benchmarks, including Cityscapes, BDD100K, and Mapillary Vistas, at negligible computational and parameter overhead. In particular, AFA improves the performance of the Deep Layer Aggregation (DLA) model by nearly 6% mIoU on Cityscapes. Our experimental analyses show that AFA learns to progressively refine segmentation maps and to improve boundary details, leading to new state-of-the-art results on boundary detection benchmarks on BSDS500 and NYUDv2. Code and video resources are available at http://vis.xyz/pub/dla-afa.
Physical Layer Anonymous Precoding: The Path to Privacy-Preserving Communications
Sep 18, 2021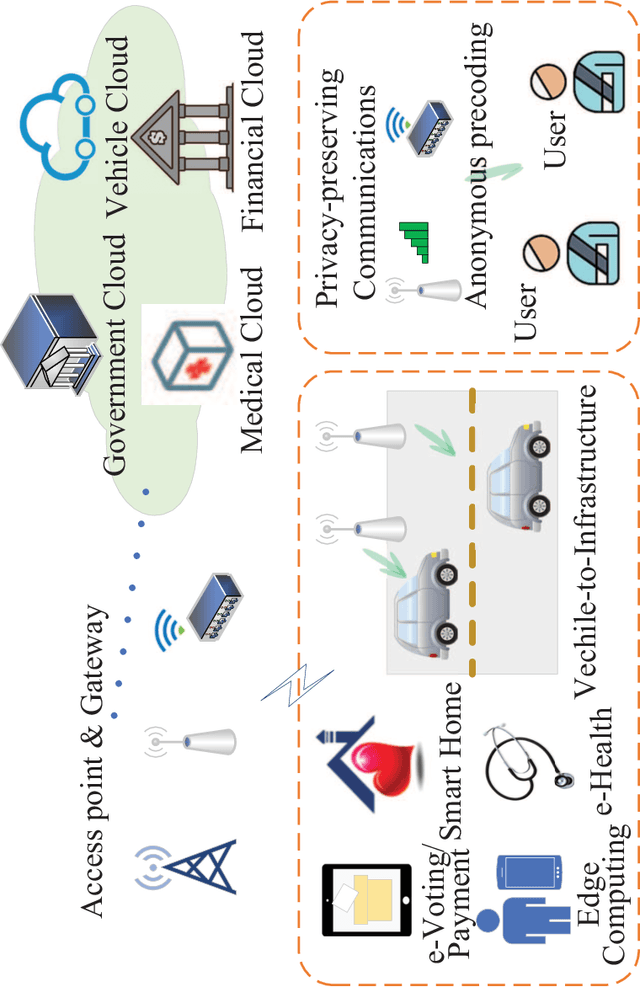
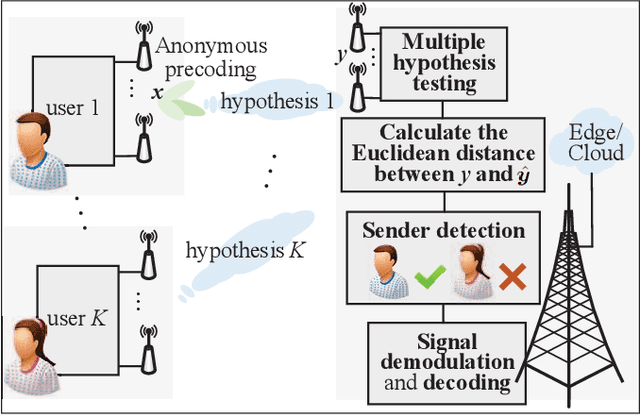
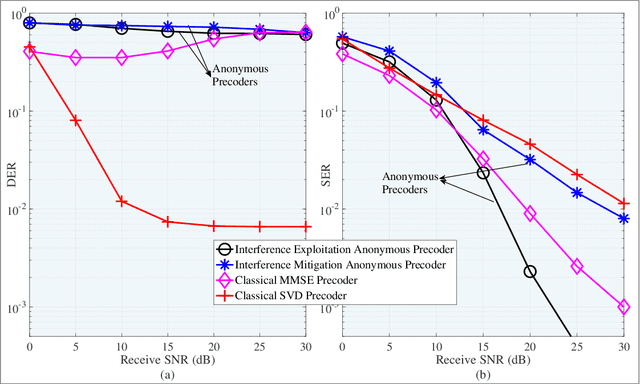
Next-generation systems aim to increase both the speed and responsiveness of wireless communications, while supporting compelling applications such as edge and cloud computing, remote-Health, vehicle-to-infrastructure communications, etc. As these applications are expected to carry confidential personal data, ensuring user privacy becomes a critical issue. In contrast to traditional security and privacy designs that aim to prevent confidential information from being eavesdropped upon by adversaries, or learned by unauthorized parties, in this paper we consider designs that mask the users' identities during communication, hence resulting in anonymous communications. In particular, we examine the recent interest in physical layer (PHY) anonymous solutions. This line of research departs from conventional higher layer anonymous authentication, encryption and routing protocols, and judiciously manipulates the signaling pattern of transmitted signals in order to mask the senders' PHY characteristics. We first discuss the concept of anonymity at the PHY, and illustrate a strategy that is able to unmask the sender's identity by analyzing his or her PHY information only, i.e., signalling patterns and the inherent fading characteristics. Subsequently, we overview the emerging area of anonymous precoding to preserve the sender's anonymity, while ensuring high receiver-side signal-to-interference-plus-noise ratio (SINR) for communication. This family of anonymous precoding designs represents a new approach to providing anonymity at the PHY, introducing a new dimension for privacy-preserving techniques.
Belief Evolution Network: Probability Transformation of Basic Belief Assignment and Fusion Conflict Probability
Oct 07, 2021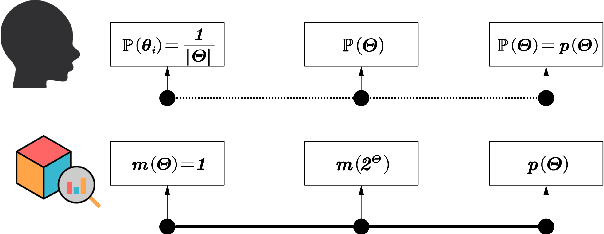
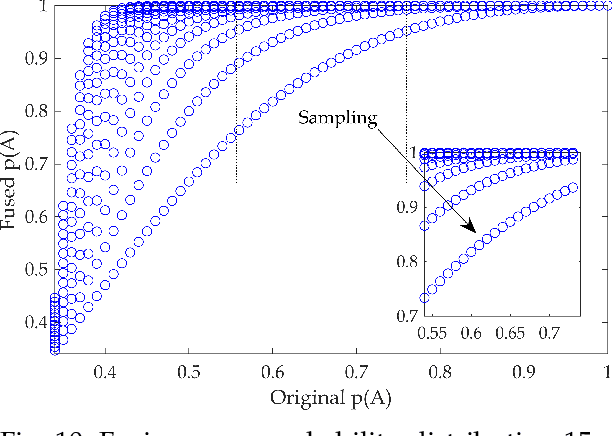
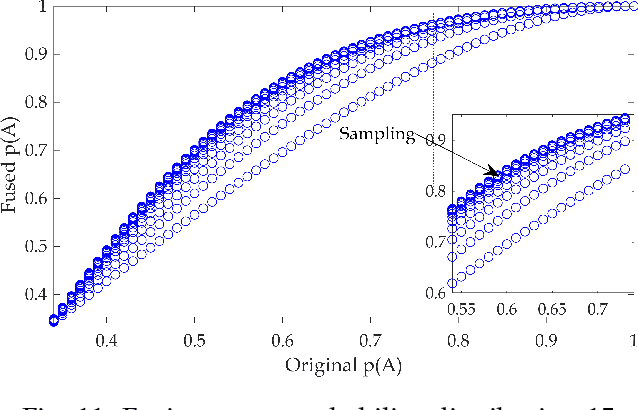
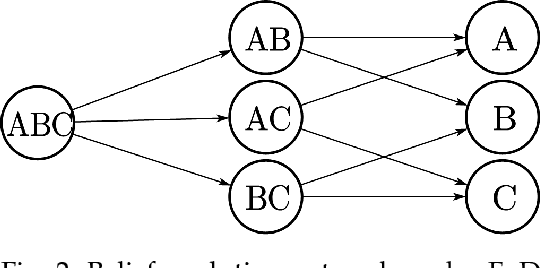
We give a new interpretation of basic belief assignment transformation into probability distribution, and use directed acyclic network called belief evolution network to describe the causality between the focal elements of a BBA. On this basis, a new probability transformations method called full causality probability transformation is proposed, and this method is superior to all previous method after verification from the process and the result. In addition, using this method combined with disjunctive combination rule, we propose a new probabilistic combination rule called disjunctive transformation combination rule. It has an excellent ability to merge conflicts and an interesting pseudo-Matthew effect, which offer a new idea to information fusion besides the combination rule of Dempster.
Direct source and early reflections localization using deep deconvolution network under reverberant environment
Oct 22, 2021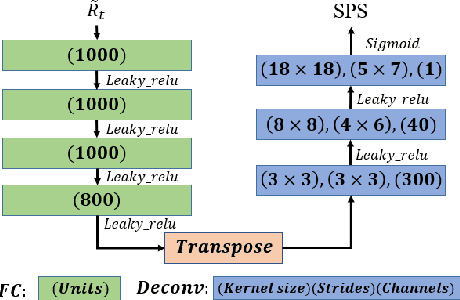
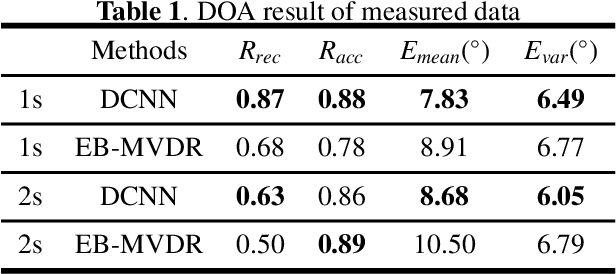
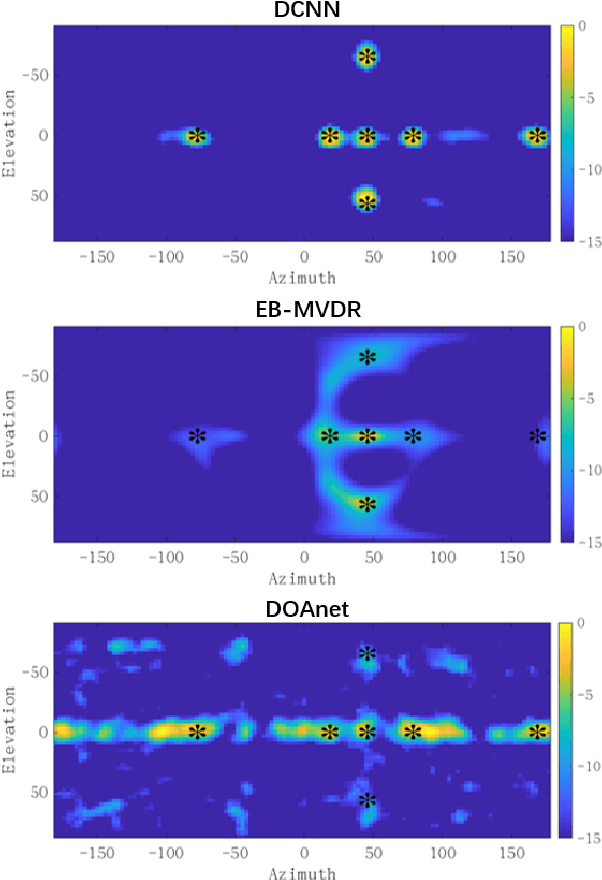
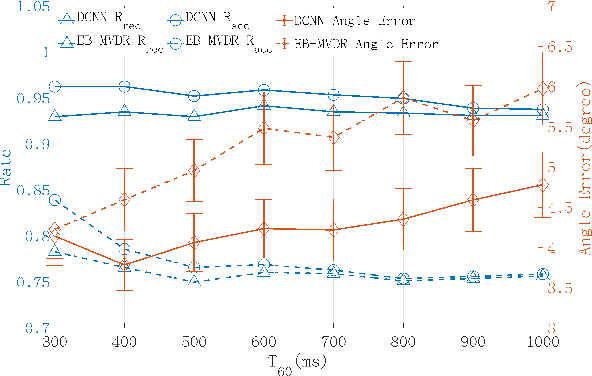
This paper proposes a deconvolution-based network (DCNN) model for DOA estimation of direct source and early reflections under reverberant scenarios. Considering that the first-order reflections of the sound source also contain spatial directivity like the direct source, we treat both of them as the sources in the learning process. We use the covariance matrix of high order Ambisonics (HOA) signals in the time domain as the input feature of the network, which is concise while containing precise spatial information under reverberant scenarios. Besides, we use the deconvolution-based network for the spatial pseudo-spectrum (SPS) reconstruction in the 2D polar space, based on which the spatial relationship between elevation and azimuth can be depicted. We have carried out a series of experiments based on simulated and measured data under different reverberant scenarios, which prove the robustness and accuracy of the proposed DCNN model.
Pairwise Emotional Relationship Recognition in Drama Videos: Dataset and Benchmark
Sep 23, 2021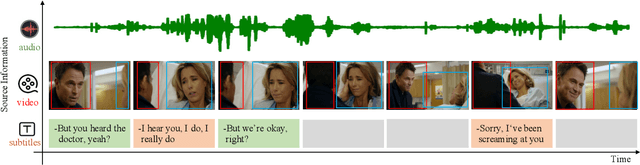
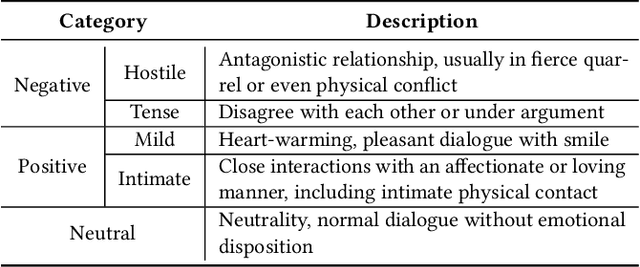
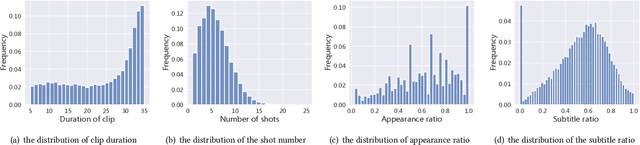
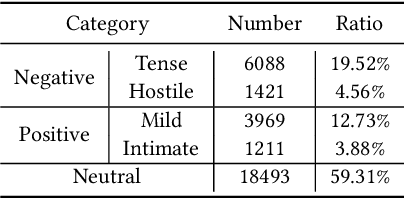
Recognizing the emotional state of people is a basic but challenging task in video understanding. In this paper, we propose a new task in this field, named Pairwise Emotional Relationship Recognition (PERR). This task aims to recognize the emotional relationship between the two interactive characters in a given video clip. It is different from the traditional emotion and social relation recognition task. Varieties of information, consisting of character appearance, behaviors, facial emotions, dialogues, background music as well as subtitles contribute differently to the final results, which makes the task more challenging but meaningful in developing more advanced multi-modal models. To facilitate the task, we develop a new dataset called Emotional RelAtionship of inTeractiOn (ERATO) based on dramas and movies. ERATO is a large-scale multi-modal dataset for PERR task, which has 31,182 video clips, lasting about 203 video hours. Different from the existing datasets, ERATO contains interaction-centric videos with multi-shots, varied video length, and multiple modalities including visual, audio and text. As a minor contribution, we propose a baseline model composed of Synchronous Modal-Temporal Attention (SMTA) unit to fuse the multi-modal information for the PERR task. In contrast to other prevailing attention mechanisms, our proposed SMTA can steadily improve the performance by about 1\%. We expect the ERATO as well as our proposed SMTA to open up a new way for PERR task in video understanding and further improve the research of multi-modal fusion methodology.
Contextual Combinatorial Volatile Bandits with Satisfying via Gaussian Processes
Nov 29, 2021
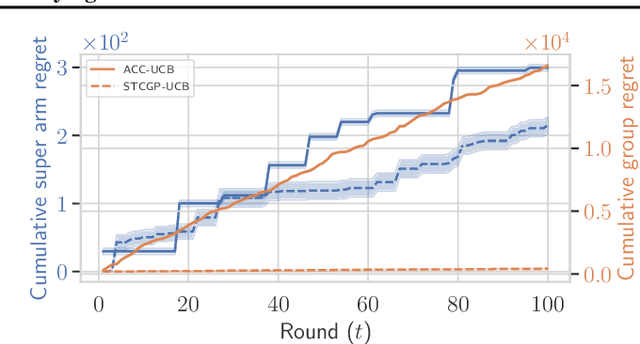
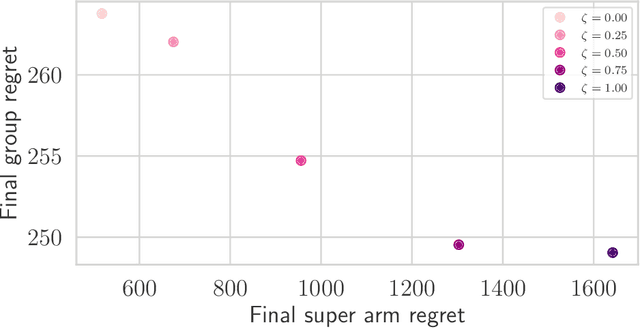
In many real-world applications of combinatorial bandits such as content caching, rewards must be maximized while satisfying minimum service requirements. In addition, base arm availabilities vary over time, and actions need to be adapted to the situation to maximize the rewards. We propose a new bandit model called Contextual Combinatorial Volatile Bandits with Group Thresholds to address these challenges. Our model subsumes combinatorial bandits by considering super arms to be subsets of groups of base arms. We seek to maximize super arm rewards while satisfying thresholds of all base arm groups that constitute a super arm. To this end, we define a new notion of regret that merges super arm reward maximization with group reward satisfaction. To facilitate learning, we assume that the mean outcomes of base arms are samples from a Gaussian Process indexed by the context set ${\cal X}$, and the expected reward is Lipschitz continuous in expected base arm outcomes. We propose an algorithm, called Thresholded Combinatorial Gaussian Process Upper Confidence Bounds (TCGP-UCB), that balances between maximizing cumulative reward and satisfying group reward thresholds and prove that it incurs $\tilde{O}(K\sqrt{T\overline{\gamma}_{T}} )$ regret with high probability, where $\overline{\gamma}_{T}$ is the maximum information gain associated with the set of base arm contexts that appeared in the first $T$ rounds and $K$ is the maximum super arm cardinality of any feasible action over all rounds. We show in experiments that our algorithm accumulates a reward comparable with that of the state-of-the-art combinatorial bandit algorithm while picking actions whose groups satisfy their thresholds.
FedTriNet: A Pseudo Labeling Method with Three Players for Federated Semi-supervised Learning
Sep 12, 2021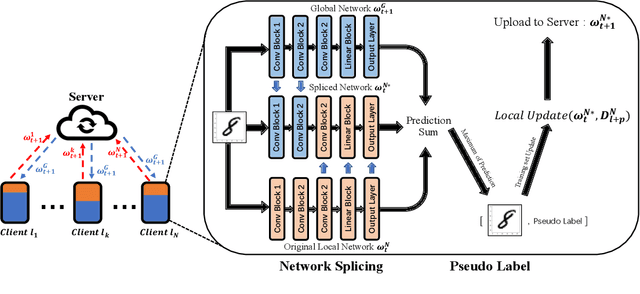
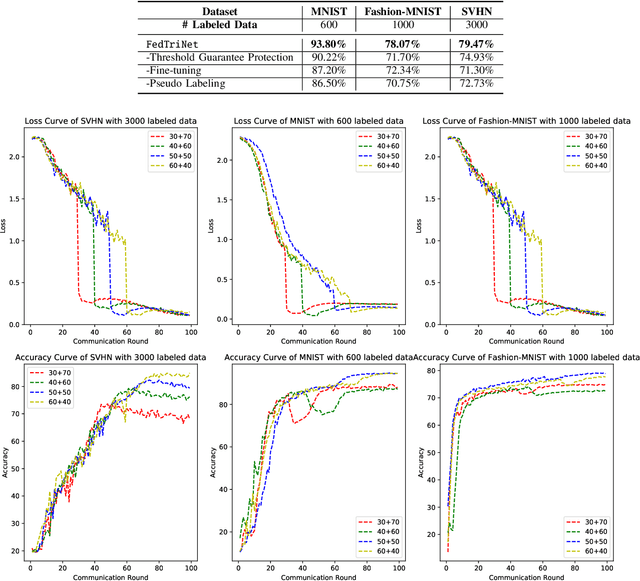
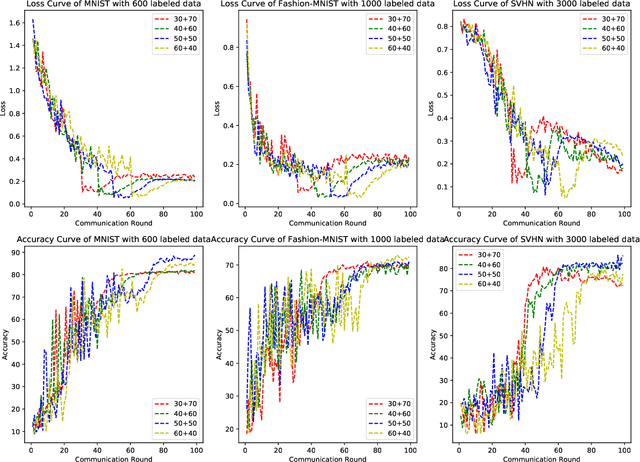

Federated Learning has shown great potentials for the distributed data utilization and privacy protection. Most existing federated learning approaches focus on the supervised setting, which means all the data stored in each client has labels. However, in real-world applications, the client data are impossible to be fully labeled. Thus, how to exploit the unlabeled data should be a new challenge for federated learning. Although a few studies are attempting to overcome this challenge, they may suffer from information leakage or misleading information usage problems. To tackle these issues, in this paper, we propose a novel federated semi-supervised learning method named FedTriNet, which consists of two learning phases. In the first phase, we pre-train FedTriNet using labeled data with FedAvg. In the second phase, we aim to make most of the unlabeled data to help model learning. In particular, we propose to use three networks and a dynamic quality control mechanism to generate high-quality pseudo labels for unlabeled data, which are added to the training set. Finally, FedTriNet uses the new training set to retrain the model. Experimental results on three publicly available datasets show that the proposed FedTriNet outperforms state-of-the-art baselines under both IID and Non-IID settings.
FDGATII : Fast Dynamic Graph Attention with Initial Residual and Identity Mapping
Oct 25, 2021
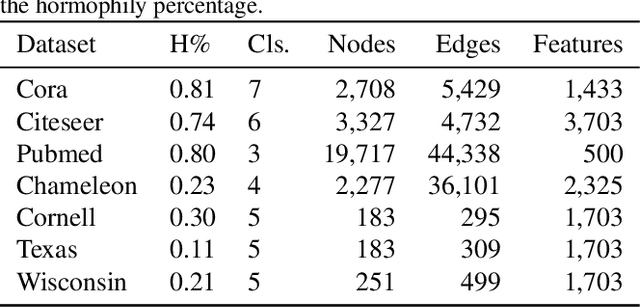
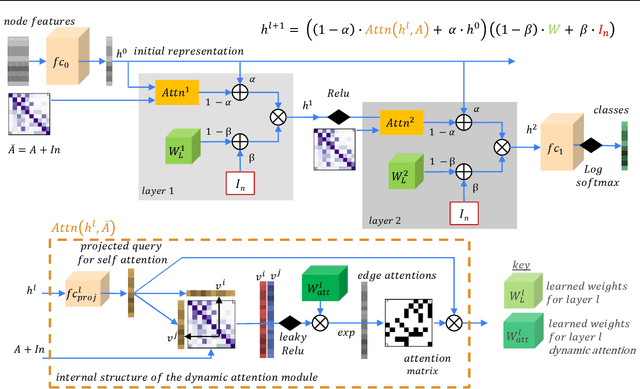
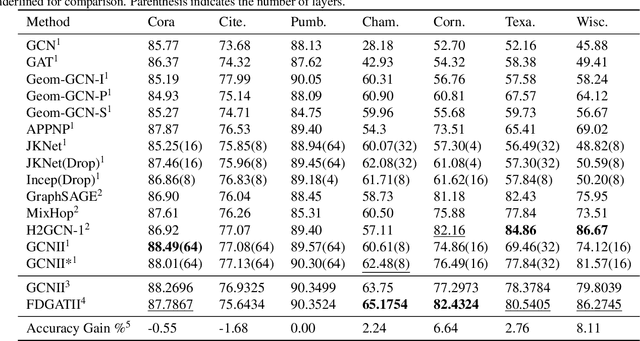
While Graph Neural Networks have gained popularity in multiple domains, graph-structured input remains a major challenge due to (a) over-smoothing, (b) noisy neighbours (heterophily), and (c) the suspended animation problem. To address all these problems simultaneously, we propose a novel graph neural network FDGATII, inspired by attention mechanism's ability to focus on selective information supplemented with two feature preserving mechanisms. FDGATII combines Initial Residuals and Identity Mapping with the more expressive dynamic self-attention to handle noise prevalent from the neighbourhoods in heterophilic data sets. By using sparse dynamic attention, FDGATII is inherently parallelizable in design, whist efficient in operation; thus theoretically able to scale to arbitrary graphs with ease. Our approach has been extensively evaluated on 7 datasets. We show that FDGATII outperforms GAT and GCN based benchmarks in accuracy and performance on fully supervised tasks, obtaining state-of-the-art results on Chameleon and Cornell datasets with zero domain-specific graph pre-processing, and demonstrate its versatility and fairness.