 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contrastive Multi-Modal Clustering
Jun 21, 2021
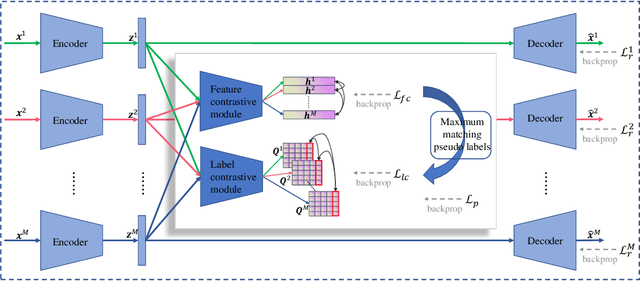
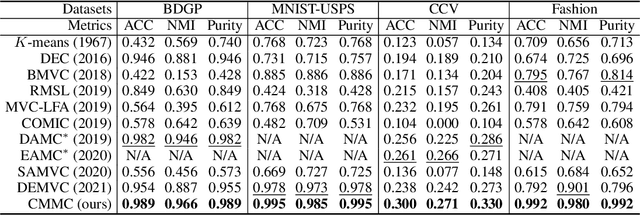
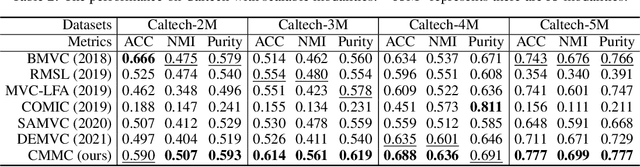
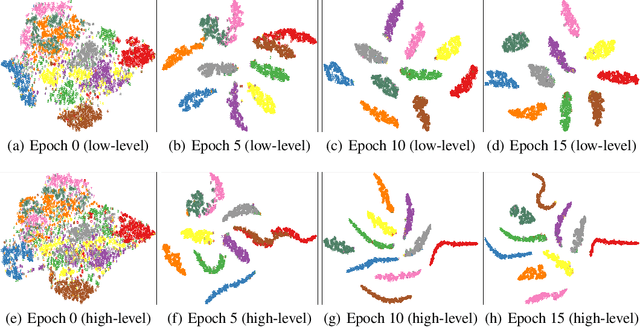
Multi-modal clustering, which explores complementary information from multiple modalities or views, has attracted people's increasing attentions. However, existing works rarely focus on extracting high-level semantic information of multiple modalities for clustering. In this paper, we propose Contrastive Multi-Modal Clustering (CMMC) which can mine high-level semantic information via contrastive learning. Concretely, our framework consists of three parts. (1) Multiple autoencoders are optimized to maintain each modality's diversity to learn complementary information. (2) A feature contrastive module is proposed to learn common high-level semantic features from different modalities. (3) A label contrastive module aims to learn consistent cluster assignments for all modalities. By the proposed multi-modal contrastive learning, the mutual information of high-level features is maximized, while the diversity of the low-level latent features is maintained. In addition, to utilize the learned high-level semantic features, we further generate pseudo labels by solving a maximum matching problem to fine-tune the cluster assignments. Extensive experiments demonstrate that CMMC has good scalability and outperforms state-of-the-art multi-modal clustering methods.
AI-Based Detection, Classification and Prediction/Prognosis in Medical Imaging: Towards Radiophenomics
Nov 01, 2021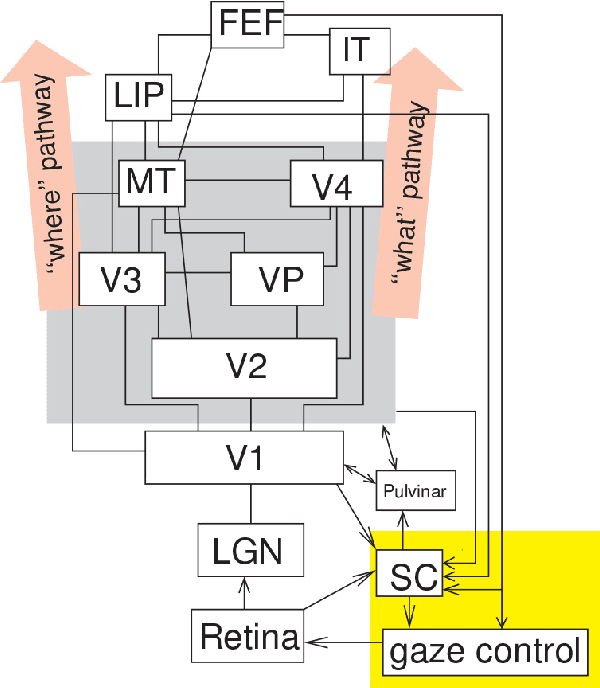
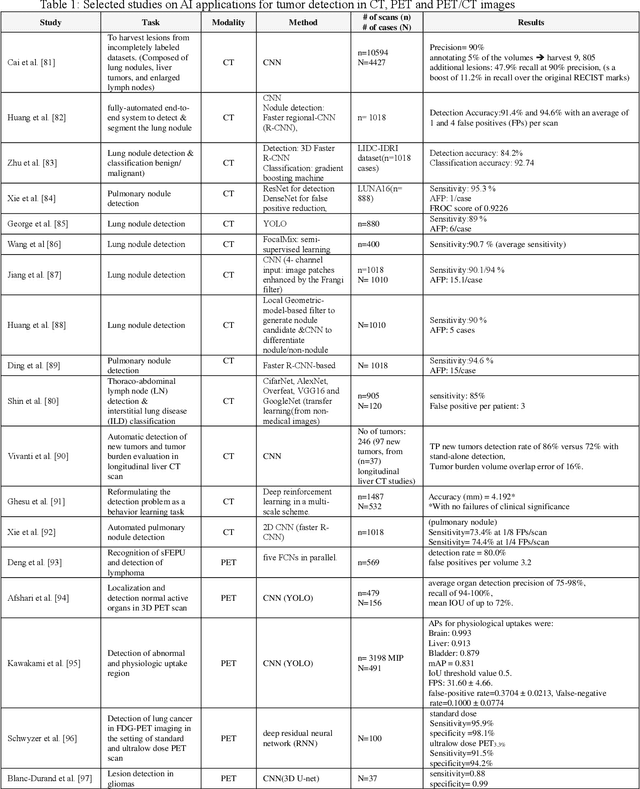

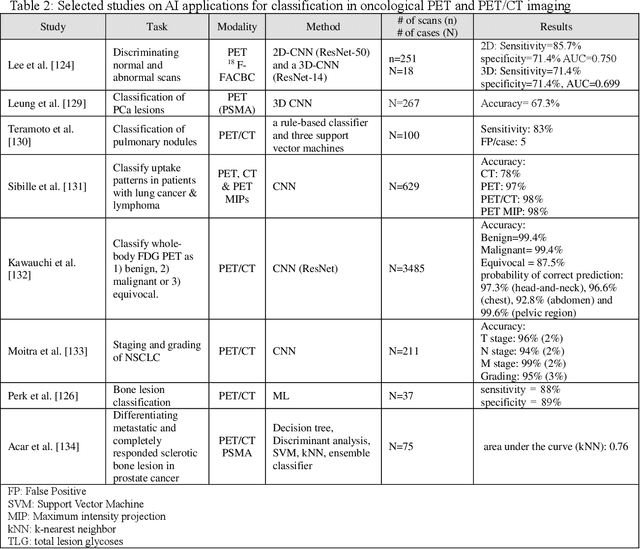
Artificial intelligence (AI) techniques have significant potential to enable effective, robust and automated image phenotyping including identification of subtle patterns. AI-based detection searches the image space to find the regions of interest based on patterns and features. There is a spectrum of tumor histologies from benign to malignant that can be identified by AI-based classification approaches using image features. The extraction of minable information from images gives way to the field of radiomics and can be explored via explicit (handcrafted/engineered) and deep radiomics frameworks. Radiomics analysis has the potential to be utilized as a noninvasive technique for the accurate characterization of tumors to improve diagnosis and treatment monitoring. This work reviews AI-based techniques, with a special focus on oncological PET and PET/CT imaging, for different detection, classification, and prediction/prognosis tasks. We also discuss needed efforts to enable the translation of AI techniques to routine clinical workflows, and potential improvements and complementary techniques such as the use of natural language processing on electronic health records and neuro-symbolic AI techniques.
Pulmonary Disease Classification Using Globally Correlated Maximum Likelihood: an Auxiliary Attention mechanism for Convolutional Neural Networks
Sep 01, 2021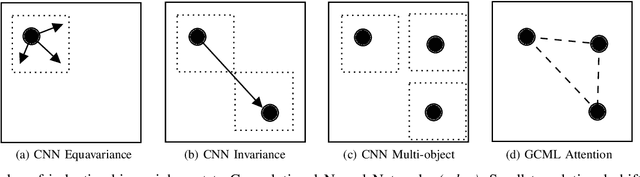



Convolutional neural networks (CNN) are now being widely used for classifying and detecting pulmonary abnormalities in chest radiographs. Two complementary generalization properties of CNNs, translation invariance and equivariance, are particularly useful in detecting manifested abnormalities associated with pulmonary disease, regardless of their spatial locations within the image. However, these properties also come with the loss of exact spatial information and global relative positions of abnormalities detected in local regions. Global relative positions of such abnormalities may help distinguish similar conditions, such as COVID-19 and viral pneumonia. In such instances, a global attention mechanism is needed, which CNNs do not support in their traditional architectures that aim for generalization afforded by translation invariance and equivariance. Vision Transformers provide a global attention mechanism, but lack translation invariance and equivariance, requiring significantly more training data samples to match generalization of CNNs. To address the loss of spatial information and global relations between features, while preserving the inductive biases of CNNs, we present a novel technique that serves as an auxiliary attention mechanism to existing CNN architectures, in order to extract global correlations between salient features.
A Multi-input Multi-output Transformer-based Hybrid Neural Network for Multi-class Privacy Disclosure Detection
Aug 19, 2021
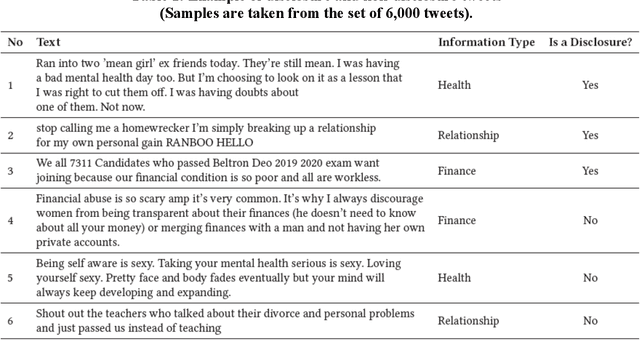
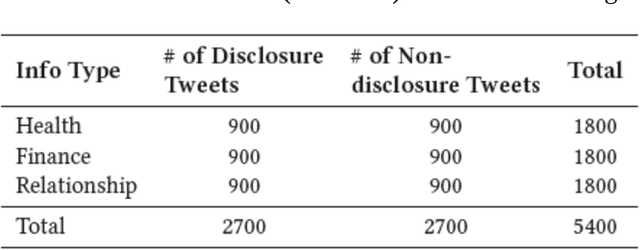

The concern regarding users' data privacy has risen to its highest level due to the massive increase in communication platforms, social networking sites, and greater users' participation in online public discourse. An increasing number of people exchange private information via emails, text messages, and social media without being aware of the risks and implications. Researchers in the field of Natural Language Processing (NLP) have concentrated on creating tools and strategies to identify, categorize, and sanitize private information in text data since a substantial amount of data is exchanged in textual form. However, most of the detection methods solely rely on the existence of pre-identified keywords in the text and disregard the inference of the underlying meaning of the utterance in a specific context. Hence, in some situations, these tools and algorithms fail to detect disclosure, or the produced results are miss-classified. In this paper, we propose a multi-input, multi-output hybrid neural network which utilizes transfer-learning, linguistics, and metadata to learn the hidden patterns. Our goal is to better classify disclosure/non-disclosure content in terms of the context of situation. We trained and evaluated our model on a human-annotated ground truth dataset, containing a total of 5,400 tweets. The results show that the proposed model was able to identify privacy disclosure through tweets with an accuracy of 77.4% while classifying the information type of those tweets with an impressive accuracy of 99%, by jointly learning for two separate tasks.
* 20 pages
On Mutual Information Maximization for Representation Learning
Jul 31, 2019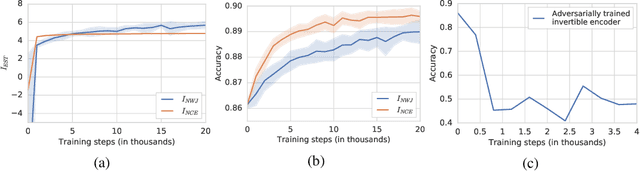
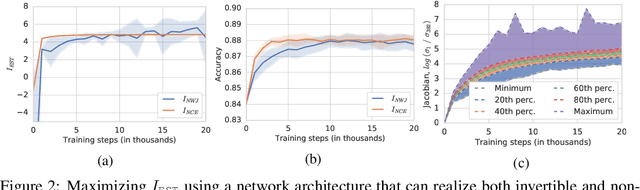
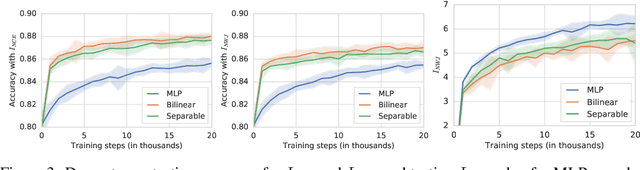
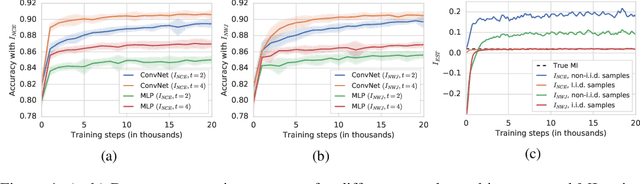
Many recent methods for unsupervised or self-supervised representation learning train feature extractors by maximizing an estimate of the mutual information (MI) between different views of the data. This comes with several immediate problems: For example, MI is notoriously hard to estimate, and using it as an objective for representation learning may lead to highly entangled representations due to its invariance under arbitrary invertible transformations. Nevertheless, these methods have been repeatedly shown to excel in practice. In this paper we argue, and provide empirical evidence, that the success of these methods might be only loosely attributed to the properties of MI, and that they strongly depend on the inductive bias in both the choice of feature extractor architectures and the parametrization of the employed MI estimators. Finally, we establish a connection to deep metric learning and argue that this interpretation may be a plausible explanation for the success of the recently introduced methods.
Hippocampal Spatial Mapping As Fast Graph Learning
Jul 01, 2021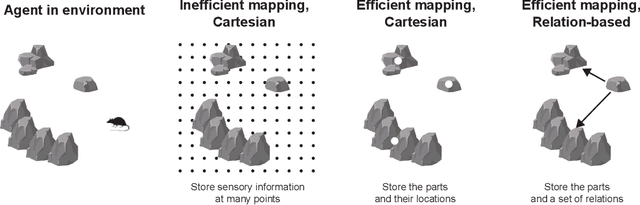
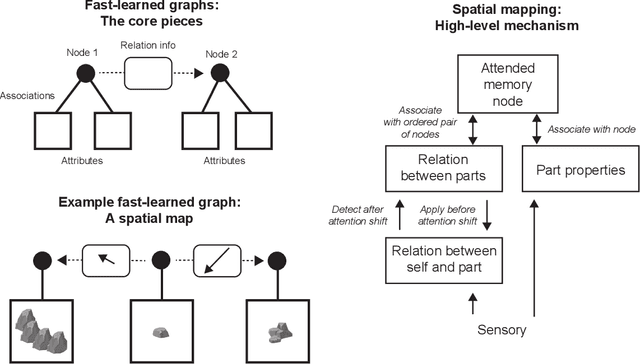
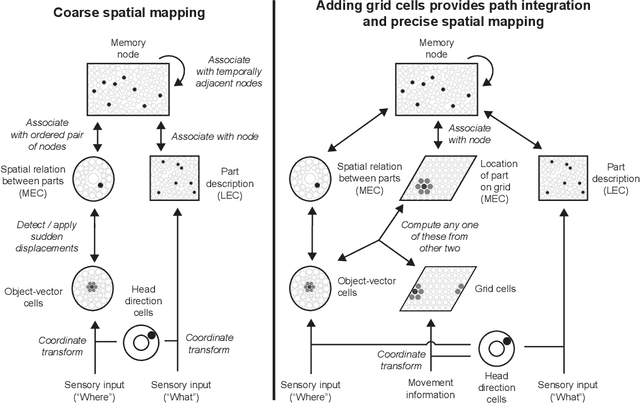
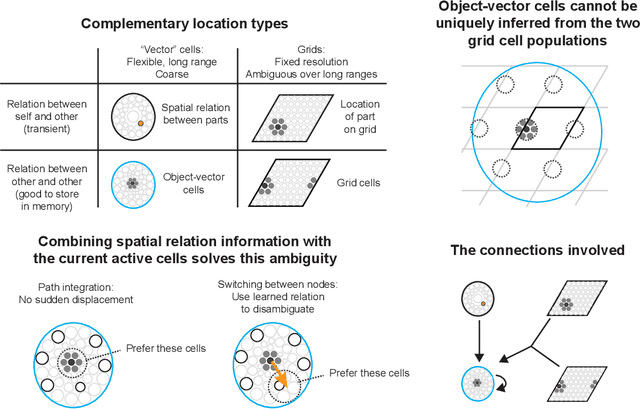
The hippocampal formation is thought to learn spatial maps of environments, and in many models this learning process consists of forming a sensory association for each location in the environment. This is inefficient, akin to learning a large lookup table for each environment. Spatial maps can be learned much more efficiently if the maps instead consist of arrangements of sparse environment parts. In this work, I approach spatial mapping as a problem of learning graphs of environment parts. Each node in the learned graph, represented by hippocampal engram cells, is associated with feature information in lateral entorhinal cortex (LEC) and location information in medial entorhinal cortex (MEC) using empirically observed neuron types. Each edge in the graph represents the relation between two parts, and it is associated with coarse displacement information. This core idea of associating arbitrary information with nodes and edges is not inherently spatial, so this proposed fast-relation-graph-learning algorithm can expand to incorporate many spatial and non-spatial tasks.
Gradient-enhanced physics-informed neural networks for forward and inverse PDE problems
Nov 01, 2021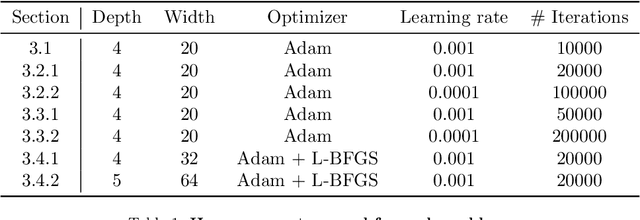
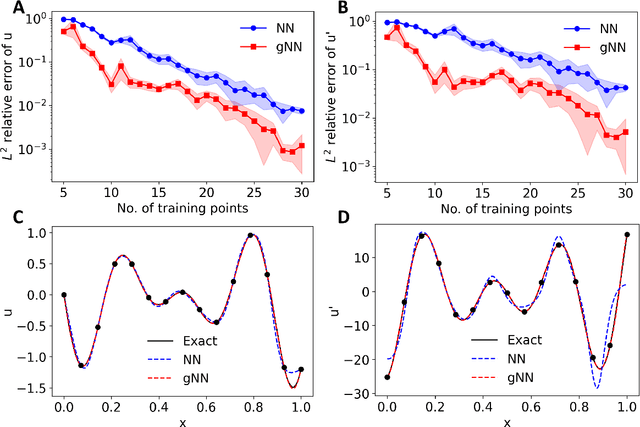
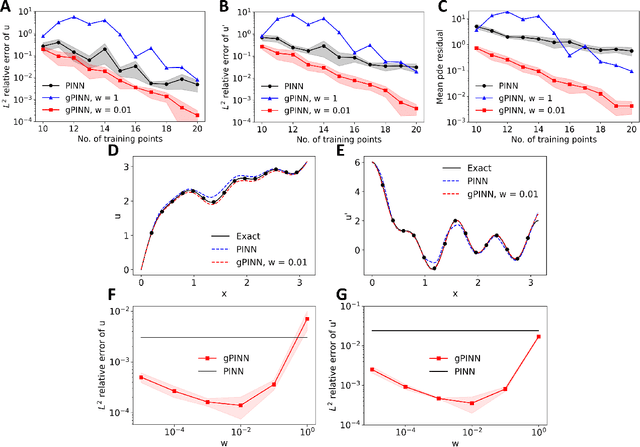
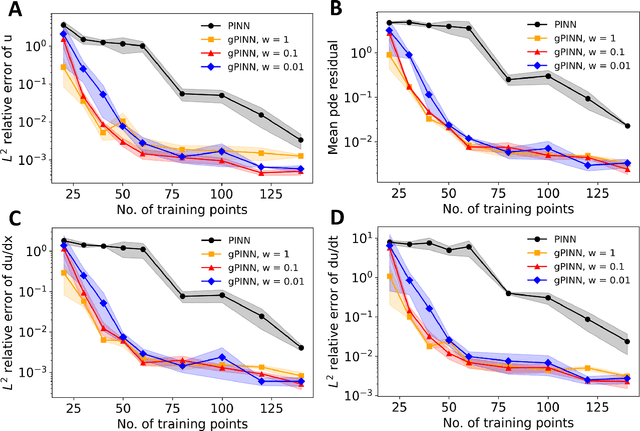
Deep learning has been shown to be an effective tool in solving partial differential equations (PDEs) through physics-informed neural networks (PINNs). PINNs embed the PDE residual into the loss function of the neural network, and have been successfully employed to solve diverse forward and inverse PDE problems. However, one disadvantage of the first generation of PINNs is that they usually have limited accuracy even with many training points. Here, we propose a new method, gradient-enhanced physics-informed neural networks (gPINNs), for improving the accuracy and training efficiency of PINNs. gPINNs leverage gradient information of the PDE residual and embed the gradient into the loss function. We tested gPINNs extensively and demonstrated the effectiveness of gPINNs in both forward and inverse PDE problems. Our numerical results show that gPINN performs better than PINN with fewer training points. Furthermore, we combined gPINN with the method of residual-based adaptive refinement (RAR), a method for improving the distribution of training points adaptively during training, to further improve the performance of gPINN, especially in PDEs with solutions that have steep gradients.
Cross-domain Single-channel Speech Enhancement Model with Bi-projection Fusion Module for Noise-robust ASR
Aug 26, 2021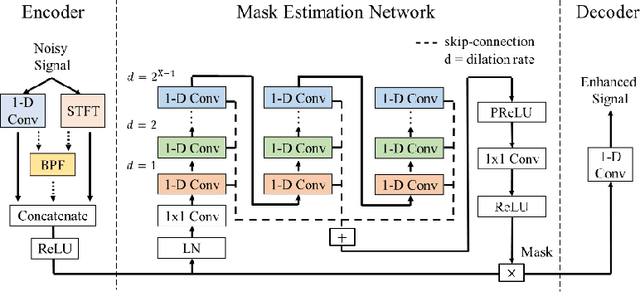
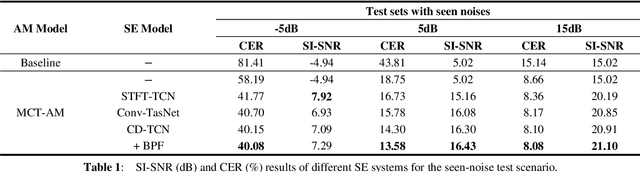
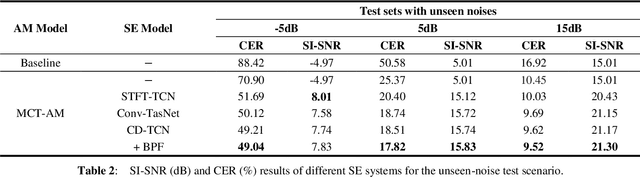
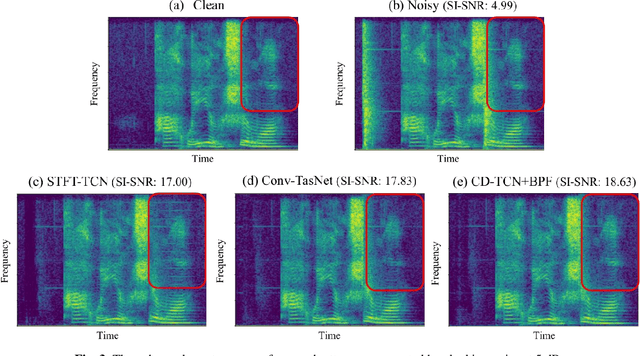
In recent decades, many studies have suggested that phase information is crucial for speech enhancement (SE), and time-domain single-channel speech enhancement techniques have shown promise in noise suppression and robust automatic speech recognition (ASR). This paper presents a continuation of the above lines of research and explores two effective SE methods that consider phase information in time domain and frequency domain of speech signals, respectively. Going one step further, we put forward a novel cross-domain speech enhancement model and a bi-projection fusion (BPF) mechanism for noise-robust ASR. To evaluate the effectiveness of our proposed method, we conduct an extensive set of experiments on the publicly-available Aishell-1 Mandarin benchmark speech corpus. The evaluation results confirm the superiority of our proposed method in relation to a few current top-of-the-line time-domain and frequency-domain SE methods in both enhancement and ASR evaluation metrics for the test set of scenarios contaminated with seen and unseen noise, respectively.
The Faulty GPS Problem: Shortest Time Paths in Networks with Unreliable Directions
Nov 17, 2021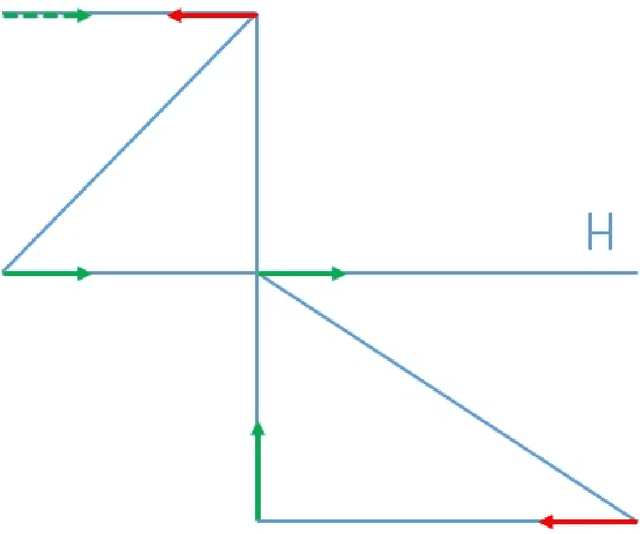
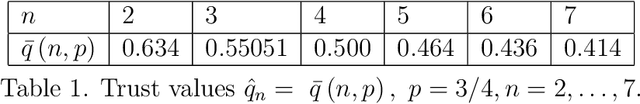
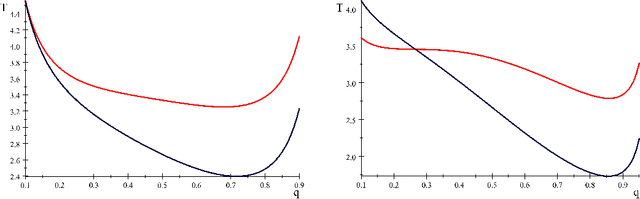
This paper optimizes motion planning when there is a known risk that the road choice suggested by a Satnav (GPS) is not on a shortest path. At every branch node of a network Q, a Satnav (GPS) points to the arc leading to the destination, or home node, H - but only with a high known probability p. Always trusting the Satnav's suggestion may lead to an infinite cycle. If one wishes to reach H in least expected time, with what probability q=q(Q,p) should one trust the pointer (if not, one chooses randomly among the other arcs)? We call this the Faulty Satnav (GPS) Problem. We also consider versions where the trust probability q can depend on the degree of the current node and a `treasure hunt' where two searchers try to reach H first. The agent searching for H need not be a car, that is just a familiar example -- it could equally be a UAV receiving unreliable GPS information. This problem has its origin not in driver frustration but in the work of Fonio et al (2017) on ant navigation, where the pointers correspond to pheromone markers pointing to the nest. Neither the driver or ant will know the exact process by which a choice (arc) is suggested, which puts the problem into the domain of how much to trust an option suggested by AI.
CCVS: Context-aware Controllable Video Synthesis
Jul 16, 2021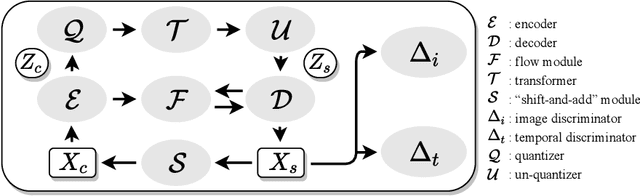
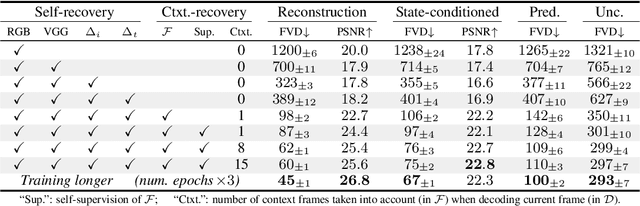
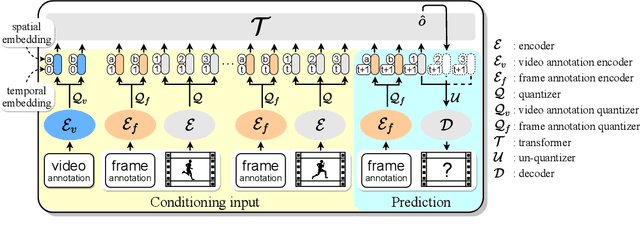
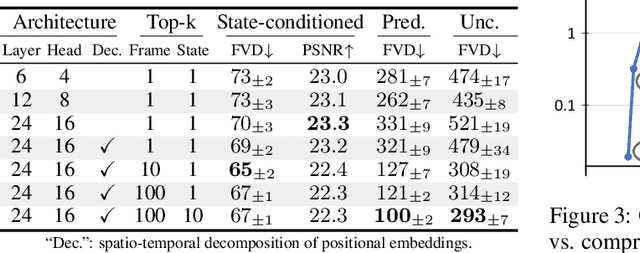
This presentation introduces a self-supervised learning approach to the synthesis of new video clips from old ones, with several new key elements for improved spatial resolution and realism: It conditions the synthesis process on contextual information for temporal continuity and ancillary information for fine control. The prediction model is doubly autoregressive, in the latent space of an autoencoder for forecasting, and in image space for updating contextual information, which is also used to enforce spatio-temporal consistency through a learnable optical flow module. Adversarial training of the autoencoder in the appearance and temporal domains is used to further improve the realism of its output. A quantizer inserted between the encoder and the transformer in charge of forecasting future frames in latent space (and its inverse inserted between the transformer and the decoder) adds even more flexibility by affording simple mechanisms for handling multimodal ancillary information for controlling the synthesis process (eg, a few sample frames, an audio track, a trajectory in image space) and taking into account the intrinsically uncertain nature of the future by allowing multiple predictions. Experiments with an implementation of the proposed approach give very good qualitative and quantitative results on multiple tasks and standard benchmarks.