 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
M2A: Motion Aware Attention for Accurate Video Action Recognition
Nov 18, 2021
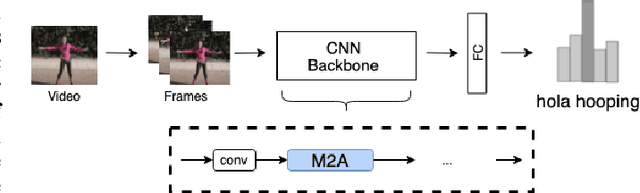
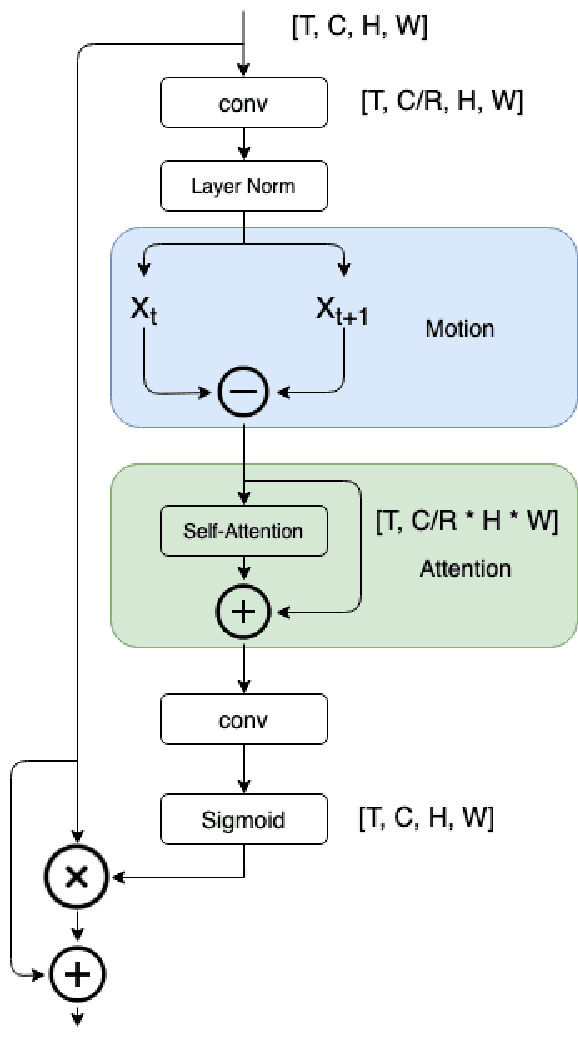


Advancements in attention mechanisms have led to significant performance improvements in a variety of areas in machine learning due to its ability to enable the dynamic modeling of temporal sequences. A particular area in computer vision that is likely to benefit greatly from the incorporation of attention mechanisms in video action recognition. However, much of the current research's focus on attention mechanisms have been on spatial and temporal attention, which are unable to take advantage of the inherent motion found in videos. Motivated by this, we develop a new attention mechanism called Motion Aware Attention (M2A) that explicitly incorporates motion characteristics. More specifically, M2A extracts motion information between consecutive frames and utilizes attention to focus on the motion patterns found across frames to accurately recognize actions in videos. The proposed M2A mechanism is simple to implement and can be easily incorporated into any neural network backbone architecture. We show that incorporating motion mechanisms with attention mechanisms using the proposed M2A mechanism can lead to a +15% to +26% improvement in top-1 accuracy across different backbone architectures, with only a small increase in computational complexity. We further compared the performance of M2A with other state-of-the-art motion and attention mechanisms on the Something-Something V1 video action recognition benchmark. Experimental results showed that M2A can lead to further improvements when combined with other temporal mechanisms and that it outperforms other motion-only or attention-only mechanisms by as much as +60% in top-1 accuracy for specific classes in the benchmark.
Entropy optimized semi-supervised decomposed vector-quantized variational autoencoder model based on transfer learning for multiclass text classification and generation
Nov 10, 2021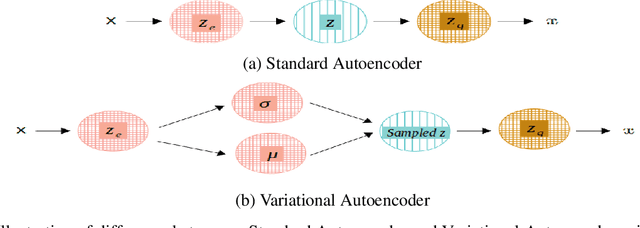
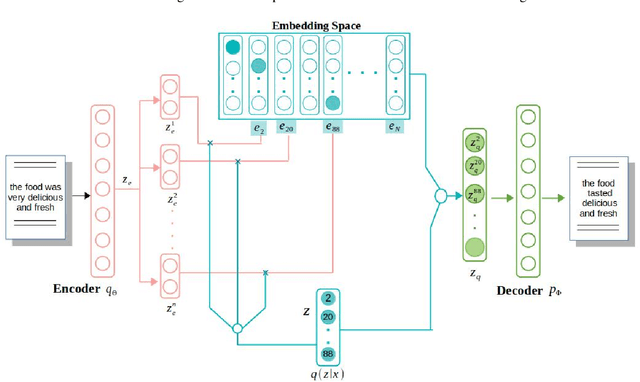
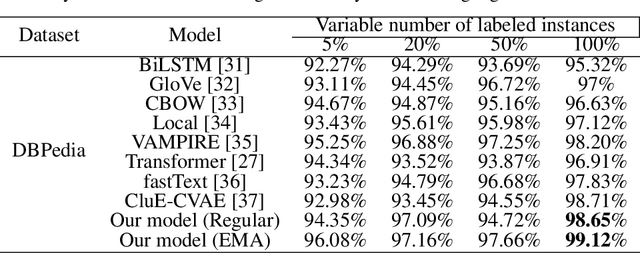
Semisupervised text classification has become a major focus of research over the past few years. Hitherto, most of the research has been based on supervised learning, but its main drawback is the unavailability of labeled data samples in practical applications. It is still a key challenge to train the deep generative models and learn comprehensive representations without supervision. Even though continuous latent variables are employed primarily in deep latent variable models, discrete latent variables, with their enhanced understandability and better compressed representations, are effectively used by researchers. In this paper, we propose a semisupervised discrete latent variable model for multi-class text classification and text generation. The proposed model employs the concept of transfer learning for training a quantized transformer model, which is able to learn competently using fewer labeled instances. The model applies decomposed vector quantization technique to overcome problems like posterior collapse and index collapse. Shannon entropy is used for the decomposed sub-encoders, on which a variable DropConnect is applied, to retain maximum information. Moreover, gradients of the Loss function are adaptively modified during backpropagation from decoder to encoder to enhance the performance of the model. Three conventional datasets of diversified range have been used for validating the proposed model on a variable number of labeled instances. Experimental results indicate that the proposed model has surpassed the state-of-the-art models remarkably.
Couple Learning: Mean Teacher method with pseudo-labels improves semi-supervised deep learning results
Oct 12, 2021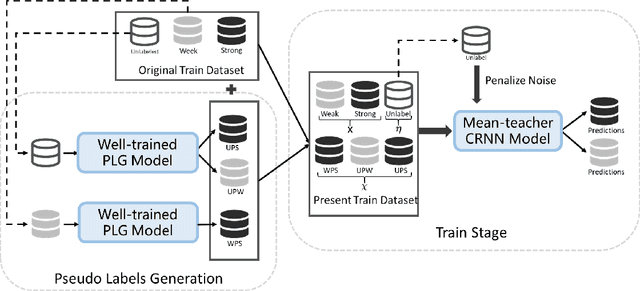
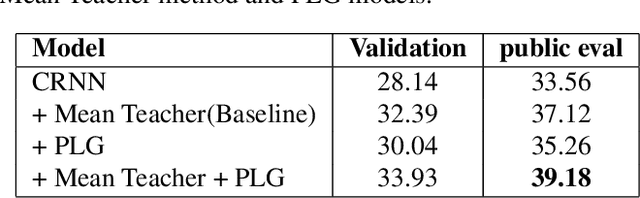
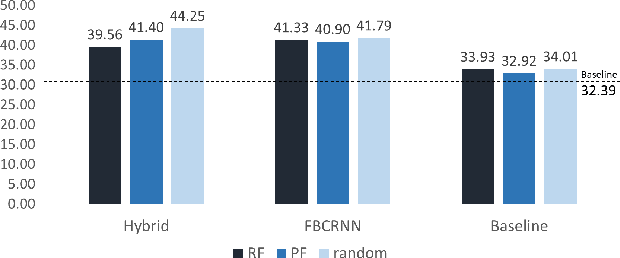
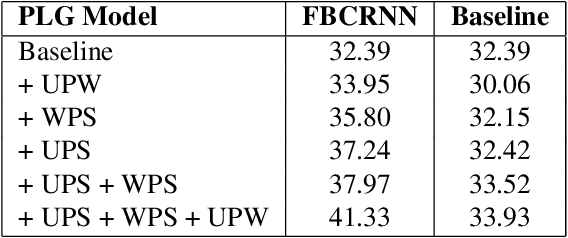
The recently proposed Mean Teacher has achieved state-of-the-art results in several semi-supervised learning benchmarks. The Mean Teacher method can exploit large-scale unlabeled data in a self-ensembling manner. In this paper, an effective Couple Learning method based on a well-trained model and a Mean Teacher model is proposed. The proposed pseudo-labels generated model (PLG) can increase strongly-labeled data and weakly-labeled data to improve performance of the Mean Teacher method. The Mean Teacher method can suppress noise in pseudo-labels data. The Couple Learning method can extract more information in the compound training data. These experimental results on Task 4 of the DCASE2020 challenge demonstrate the superiority of the proposed method, achieving about 39.18% F1-score on public eval set, outperforming 37.12% of the baseline system by a significant margin.
Parameterless Gene-pool Optimal Mixing Evolutionary Algorithms
Sep 11, 2021


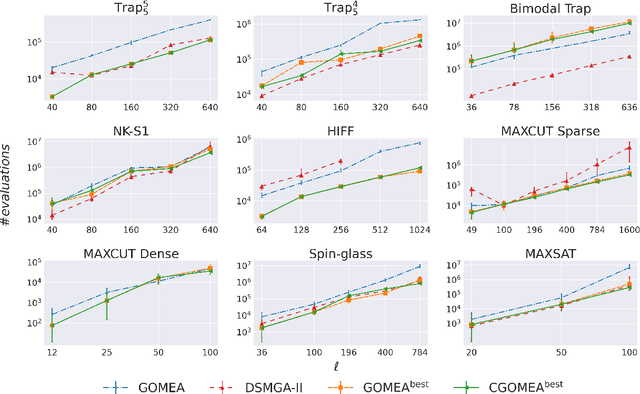
When it comes to solving optimization problems with evolutionary algorithms (EAs) in a reliable and scalable manner, detecting and exploiting linkage information, i.e., dependencies between variables, can be key. In this article, we present the latest version of, and propose substantial enhancements to, the Gene-pool Optimal Mixing Evoutionary Algorithm (GOMEA): an EA explicitly designed to estimate and exploit linkage information. We begin by performing a large-scale search over several GOMEA design choices, to understand what matters most and obtain a generally best-performing version of the algorithm. Next, we introduce a novel version of GOMEA, called CGOMEA, where linkage-based variation is further improved by filtering solution mating based on conditional dependencies. We compare our latest version of GOMEA, the newly introduced CGOMEA, and another contending linkage-aware EA DSMGA-II in an extensive experimental evaluation, involving a benchmark set of 9 black-box problems that can only be solved efficiently if their inherent dependency structure is unveiled and exploited. Finally, in an attempt to make EAs more usable and resilient to parameter choices, we investigate the performance of different automatic population management schemes for GOMEA and CGOMEA, de facto making the EAs parameterless. Our results show that GOMEA and CGOMEA significantly outperform the original GOMEA and DSMGA-II on most problems, setting a new state of the art for the field.
Mac Users Do It Differently: the Role of Operating System and Individual Differences in File Management
Sep 30, 2021
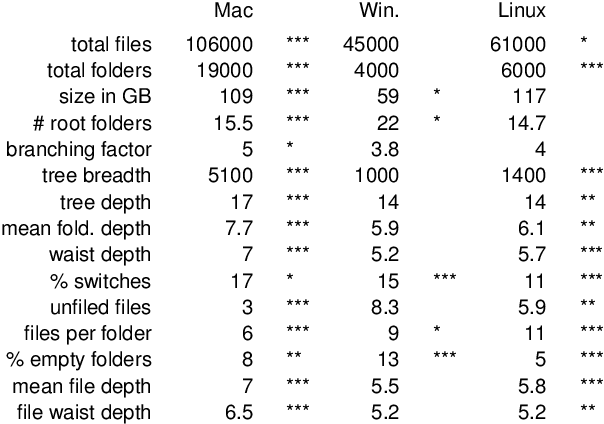
Despite much discussion in HCI research about how individual differences likely determine computer users' personal information management (PIM) practices, the extent of the influence of several important factors remains unclear, including users' personalities, spatial abilities, and the different software used to manage their collections. We therefore analyse data from prior CHI work to explore (1) associations of people's file collections with personality and spatial ability, and (2) differences between collections managed with different operating systems and file managers. We find no notable associations between users' attributes and their collections, and minimal predictive power, but do find considerable and surprising differences across operating systems. We discuss these findings and how they can inform future research.
* ACM CHI '20 conference paper ('late-breaking work' category), 8 pages
Highly Efficient Natural Image Matting
Oct 25, 2021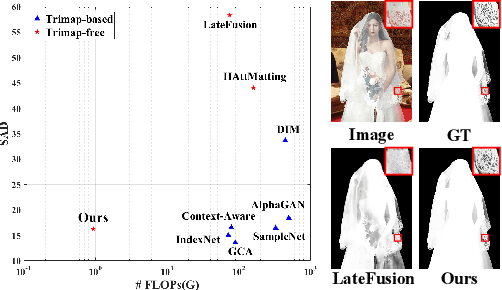
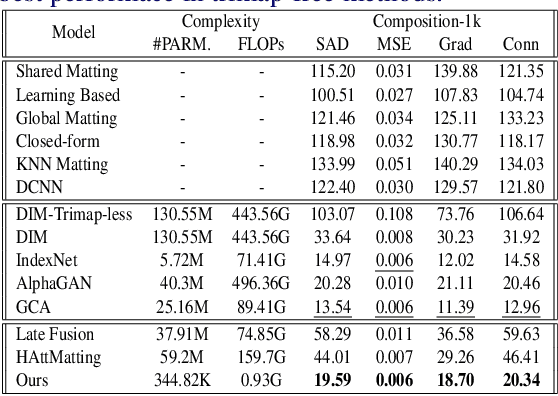
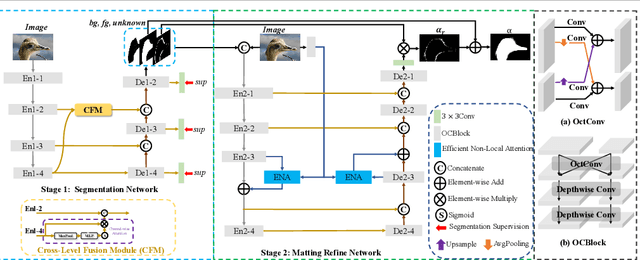
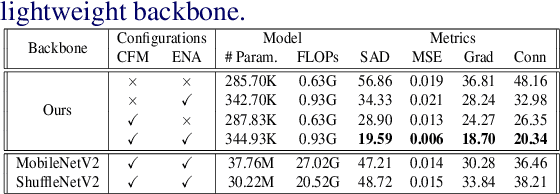
Over the last few years, deep learning based approaches have achieved outstanding improvements in natural image matting. However, there are still two drawbacks that impede the widespread application of image matting: the reliance on user-provided trimaps and the heavy model sizes. In this paper, we propose a trimap-free natural image matting method with a lightweight model. With a lightweight basic convolution block, we build a two-stages framework: Segmentation Network (SN) is designed to capture sufficient semantics and classify the pixels into unknown, foreground and background regions; Matting Refine Network (MRN) aims at capturing detailed texture information and regressing accurate alpha values. With the proposed cross-level fusion Module (CFM), SN can efficiently utilize multi-scale features with less computational cost. Efficient non-local attention module (ENA) in MRN can efficiently model the relevance between different pixels and help regress high-quality alpha values. Utilizing these techniques, we construct an extremely light-weighted model, which achieves comparable performance with ~1\% parameters (344k) of large models on popular natural image matting benchmarks.
Edge-Native Intelligence for 6G Communications Driven by Federated Learning: A Survey of Trends and Challenges
Nov 14, 2021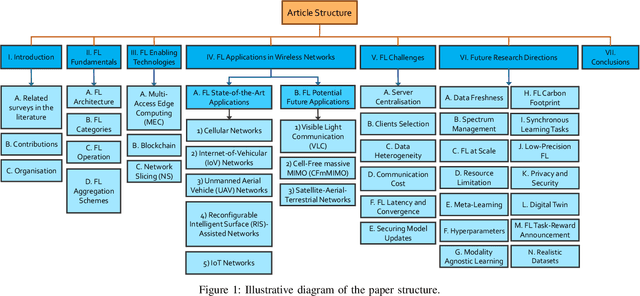
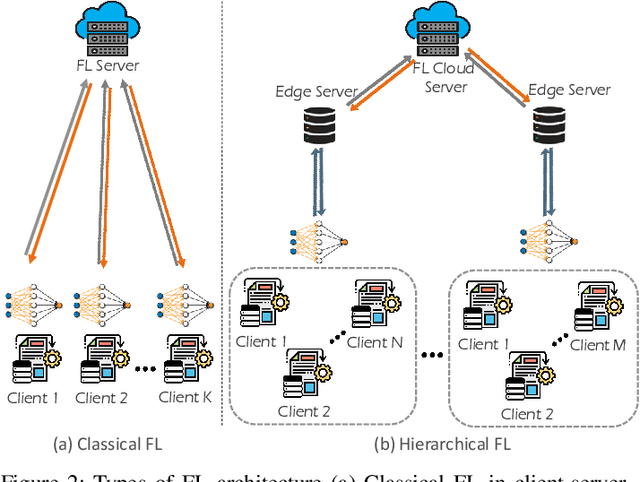
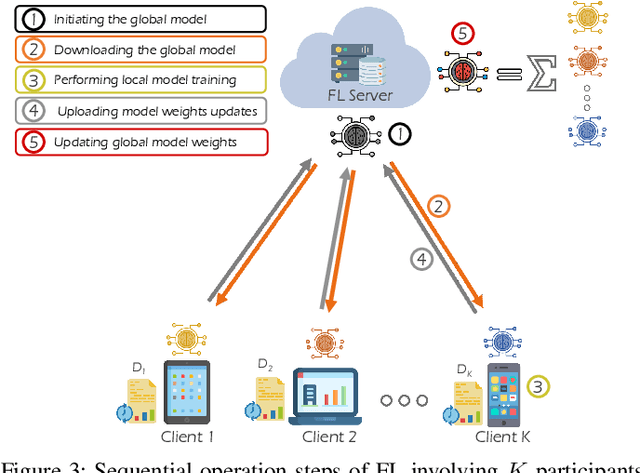
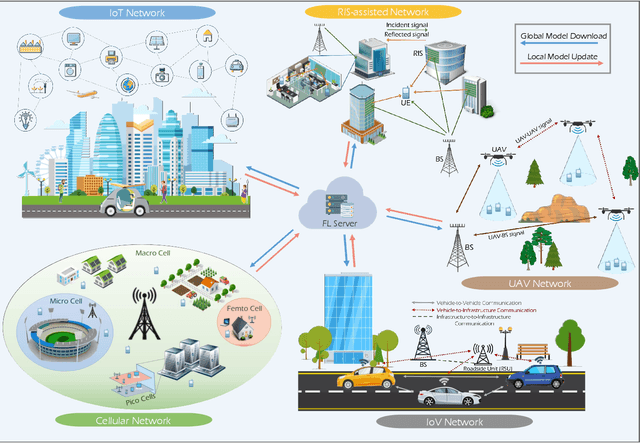
The unprecedented surge of data volume in wireless networks empowered with artificial intelligence (AI) opens up new horizons for providing ubiquitous data-driven intelligent services. Traditional cloud-centric machine learning (ML)-based services are implemented by collecting datasets and training models centrally. However, this conventional training technique encompasses two challenges: (i) high communication and energy cost due to increased data communication, (ii) threatened data privacy by allowing untrusted parties to utilise this information. Recently, in light of these limitations, a new emerging technique, coined as federated learning (FL), arose to bring ML to the edge of wireless networks. FL can extract the benefits of data silos by training a global model in a distributed manner, orchestrated by the FL server. FL exploits both decentralised datasets and computing resources of participating clients to develop a generalised ML model without compromising data privacy. In this article, we introduce a comprehensive survey of the fundamentals and enabling technologies of FL. Moreover, an extensive study is presented detailing various applications of FL in wireless networks and highlighting their challenges and limitations. The efficacy of FL is further explored with emerging prospective beyond fifth generation (B5G) and sixth generation (6G) communication systems. The purpose of this survey is to provide an overview of the state-of-the-art of FL applications in key wireless technologies that will serve as a foundation to establish a firm understanding of the topic. Lastly, we offer a road forward for future research directions.
Automated Human Mind Reading Using EEG Signals for Seizure Detection
Nov 05, 2021Epilepsy is one of the most occurring neurological disease globally emerged back in 4000 BC. It is affecting around 50 million people of all ages these days. The trait of this disease is recurrent seizures. In the past few decades, the treatments available for seizure control have improved a lot with the advancements in the field of medical science and technology. Electroencephalogram (EEG) is a widely used technique for monitoring the brain activity and widely popular for seizure region detection. It is performed before surgery and also to predict seizure at the time operation which is useful in neuro stimulation device. But in most of cases visual examination is done by neurologist in order to detect and classify patterns of the disease but this requires a lot of pre-domain knowledge and experience. This all in turns put a pressure on neurosurgeons and leads to time wastage and also reduce their accuracy and efficiency. There is a need of some automated systems in arena of information technology like use of neural networks in deep learning which can assist neurologists. In the present paper, a model is proposed to give an accuracy of 98.33% which can be used for development of automated systems. The developed system will significantly help neurologists in their performance.
* 11 Pages, 12 Figures, 5 Tables
Robust marginalization of baryonic effects for cosmological inference at the field level
Sep 21, 2021
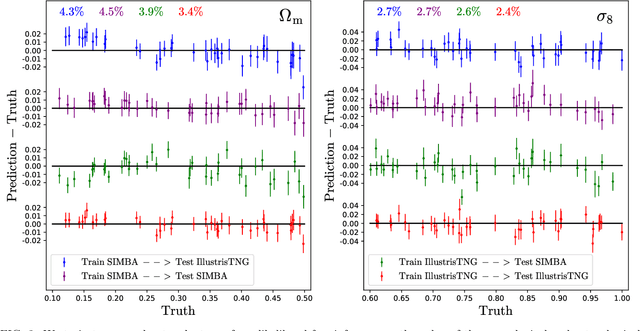
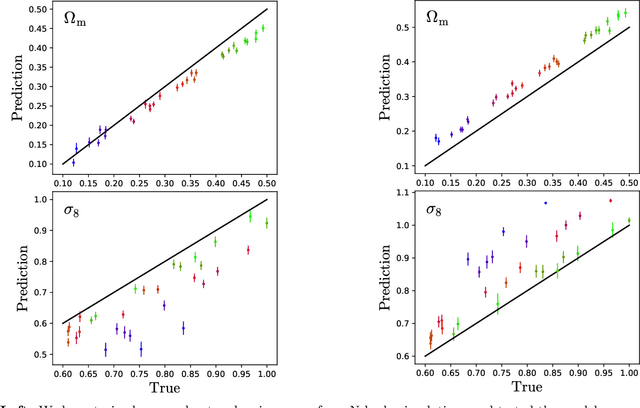
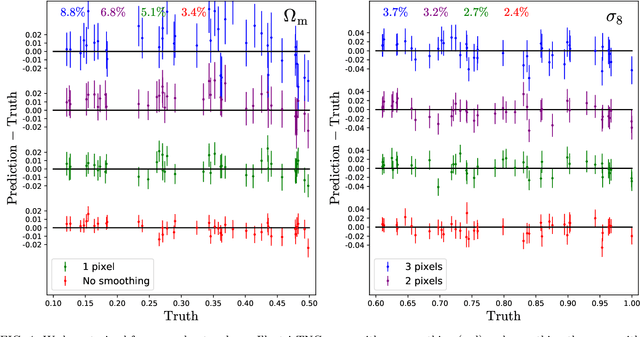
We train neural networks to perform likelihood-free inference from $(25\,h^{-1}{\rm Mpc})^2$ 2D maps containing the total mass surface density from thousands of hydrodynamic simulations of the CAMELS project. We show that the networks can extract information beyond one-point functions and power spectra from all resolved scales ($\gtrsim 100\,h^{-1}{\rm kpc}$) while performing a robust marginalization over baryonic physics at the field level: the model can infer the value of $\Omega_{\rm m} (\pm 4\%)$ and $\sigma_8 (\pm 2.5\%)$ from simulations completely different to the ones used to train it.
Towards Lightweight Controllable Audio Synthesis with Conditional Implicit Neural Representations
Nov 14, 2021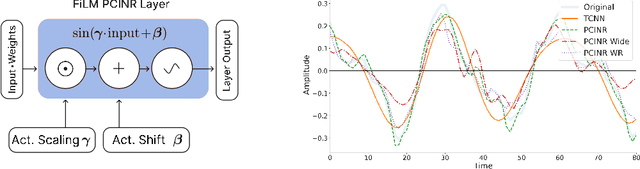
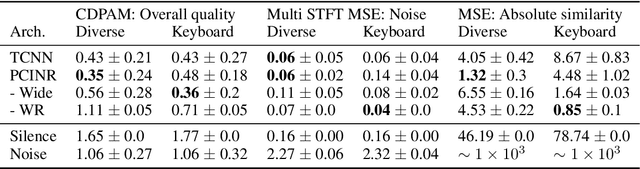
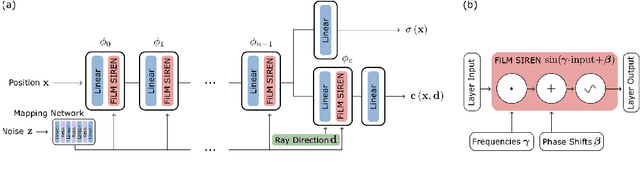
The high temporal resolution of audio and our perceptual sensitivity to small irregularities in waveforms make synthesizing at high sampling rates a complex and computationally intensive task, prohibiting real-time, controllable synthesis within many approaches. In this work we aim to shed light on the potential of Conditional Implicit Neural Representations (CINRs) as lightweight backbones in generative frameworks for audio synthesis. Implicit neural representations (INRs) are neural networks used to approximate low-dimensional functions, trained to represent a single geometric object by mapping input coordinates to structural information at input locations. In contrast with other neural methods for representing geometric objects, the memory required to parameterize the object is independent of resolution, and only scales with its complexity. A corollary of this is that INRs have infinite resolution, as they can be sampled at arbitrary resolutions. To apply the concept of INRs in the generative domain we frame generative modelling as learning a distribution of continuous functions. This can be achieved by introducing conditioning methods to INRs. Our experiments show that Periodic Conditional INRs (PCINRs) learn faster and generally produce quantitatively better audio reconstructions than Transposed Convolutional Neural Networks with equal parameter counts. However, their performance is very sensitive to activation scaling hyperparameters. When learning to represent more uniform sets, PCINRs tend to introduce artificial high-frequency components in reconstructions. We validate this noise can be minimized by applying standard weight regularization during training or decreasing the compositional depth of PCINRs, and suggest directions for future research.