 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generative Residual Attention Network for Disease Detection
Oct 25, 2021
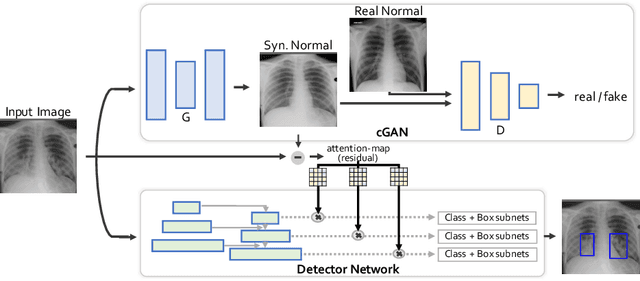
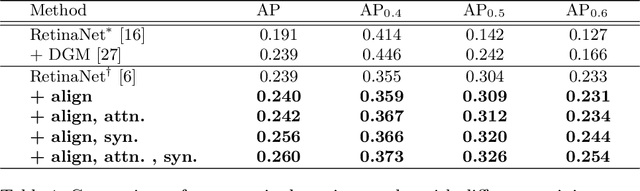
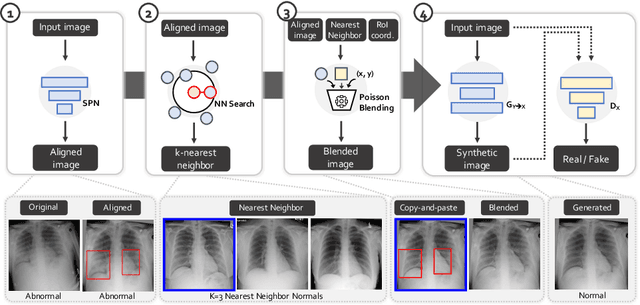
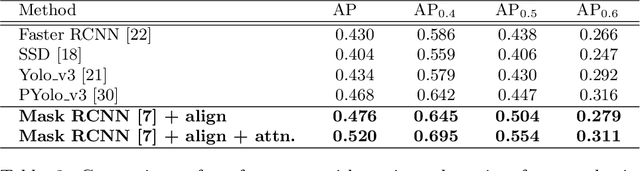
Accurate identification and localization of abnormalities from radiology images serve as a critical role in computer-aided diagnosis (CAD) systems. Building a highly generalizable system usually requires a large amount of data with high-quality annotations, including disease-specific global and localization information. However, in medical images, only a limited number of high-quality images and annotations are available due to annotation expenses. In this paper, we explore this problem by presenting a novel approach for disease generation in X-rays using a conditional generative adversarial learning. Specifically, given a chest X-ray image from a source domain, we generate a corresponding radiology image in a target domain while preserving the identity of the patient. We then use the generated X-ray image in the target domain to augment our training to improve the detection performance. We also present a unified framework that simultaneously performs disease generation and localization.We evaluate the proposed approach on the X-ray image dataset provided by the Radiological Society of North America (RSNA), surpassing the state-of-the-art baseline detection algorithms.
M2A: Motion Aware Attention for Accurate Video Action Recognition
Nov 18, 2021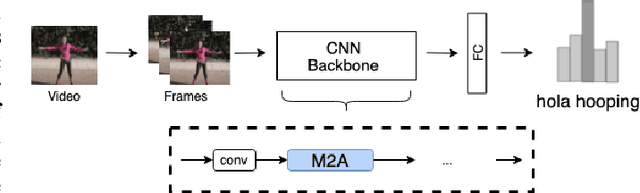
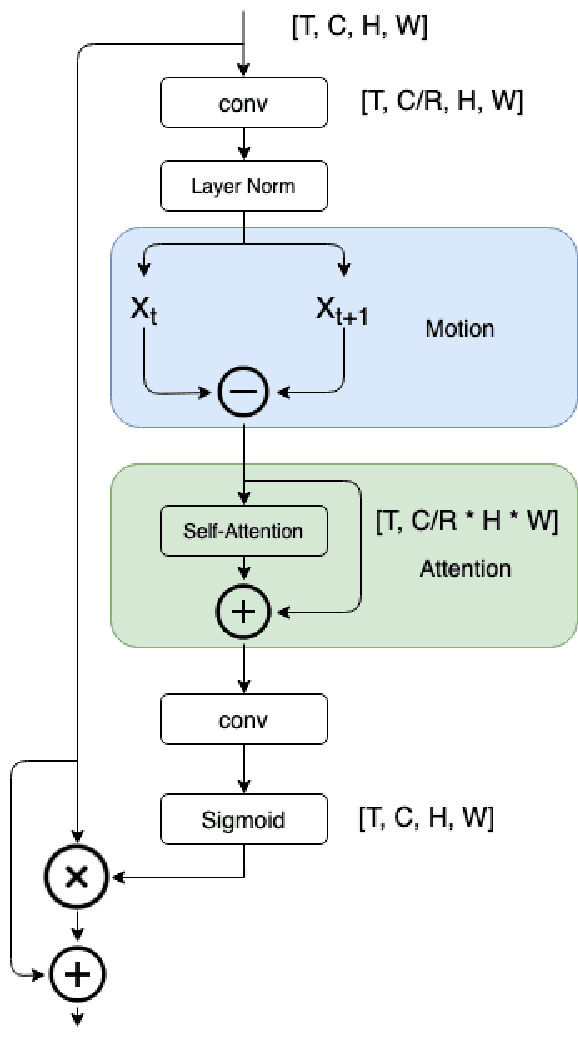


Advancements in attention mechanisms have led to significant performance improvements in a variety of areas in machine learning due to its ability to enable the dynamic modeling of temporal sequences. A particular area in computer vision that is likely to benefit greatly from the incorporation of attention mechanisms in video action recognition. However, much of the current research's focus on attention mechanisms have been on spatial and temporal attention, which are unable to take advantage of the inherent motion found in videos. Motivated by this, we develop a new attention mechanism called Motion Aware Attention (M2A) that explicitly incorporates motion characteristics. More specifically, M2A extracts motion information between consecutive frames and utilizes attention to focus on the motion patterns found across frames to accurately recognize actions in videos. The proposed M2A mechanism is simple to implement and can be easily incorporated into any neural network backbone architecture. We show that incorporating motion mechanisms with attention mechanisms using the proposed M2A mechanism can lead to a +15% to +26% improvement in top-1 accuracy across different backbone architectures, with only a small increase in computational complexity. We further compared the performance of M2A with other state-of-the-art motion and attention mechanisms on the Something-Something V1 video action recognition benchmark. Experimental results showed that M2A can lead to further improvements when combined with other temporal mechanisms and that it outperforms other motion-only or attention-only mechanisms by as much as +60% in top-1 accuracy for specific classes in the benchmark.
Making the Last Iterate of SGD Information Theoretically Optimal
May 29, 2019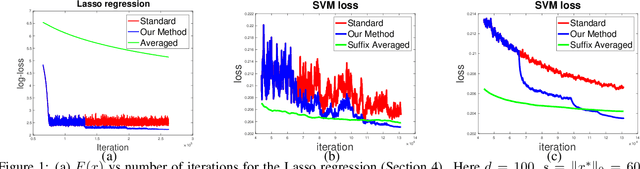
Stochastic gradient descent (SGD) is one of the most widely used algorithms for large scale optimization problems. While classical theoretical analysis of SGD for convex problems studies (suffix) \emph{averages} of iterates and obtains information theoretically optimal bounds on suboptimality, the \emph{last point} of SGD is, by far, the most preferred choice in practice. The best known results for last point of SGD \cite{shamir2013stochastic} however, are suboptimal compared to information theoretic lower bounds by a $\log T$ factor, where $T$ is the number of iterations. \cite{harvey2018tight} shows that in fact, this additional $\log T$ factor is tight for standard step size sequences of $\OTheta{\frac{1}{\sqrt{t}}}$ and $\OTheta{\frac{1}{t}}$ for non-strongly convex and strongly convex settings, respectively. Similarly, even for subgradient descent (GD) when applied to non-smooth, convex functions, the best known step-size sequences still lead to $O(\log T)$-suboptimal convergence rates (on the final iterate). The main contribution of this work is to design new step size sequences that enjoy information theoretically optimal bounds on the suboptimality of \emph{last point} of SGD as well as GD. We achieve this by designing a modification scheme, that converts one sequence of step sizes to another so that the last point of SGD/GD with modified sequence has the same suboptimality guarantees as the average of SGD/GD with original sequence. We also show that our result holds with high-probability. We validate our results through simulations which demonstrate that the new step size sequence indeed improves the final iterate significantly compared to the standard step size sequences.
Normative Epistemology for Lethal Autonomous Weapons Systems
Oct 25, 2021The rise of human-information systems, cybernetic systems, and increasingly autonomous systems requires the application of epistemic frameworks to machines and human-machine teams. This chapter discusses higher-order design principles to guide the design, evaluation, deployment, and iteration of Lethal Autonomous Weapons Systems (LAWS) based on epistemic models. Epistemology is the study of knowledge. Epistemic models consider the role of accuracy, likelihoods, beliefs, competencies, capabilities, context, and luck in the justification of actions and the attribution of knowledge. The aim is not to provide ethical justification for or against LAWS, but to illustrate how epistemological frameworks can be used in conjunction with moral apparatus to guide the design and deployment of future systems. The models discussed in this chapter aim to make Article 36 reviews of LAWS systematic, expedient, and evaluable. A Bayesian virtue epistemology is proposed to enable justified actions under uncertainty that meet the requirements of the Laws of Armed Conflict and International Humanitarian Law. Epistemic concepts can provide some of the apparatus to meet explainability and transparency requirements in the development, evaluation, deployment, and review of ethical AI.
Joint Range and Doppler Adaptive Processing for CBM based DFRC systems
Jul 22, 2021
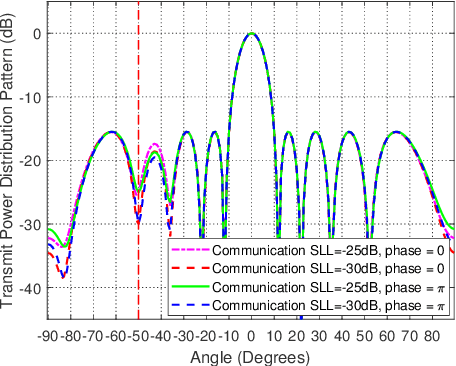

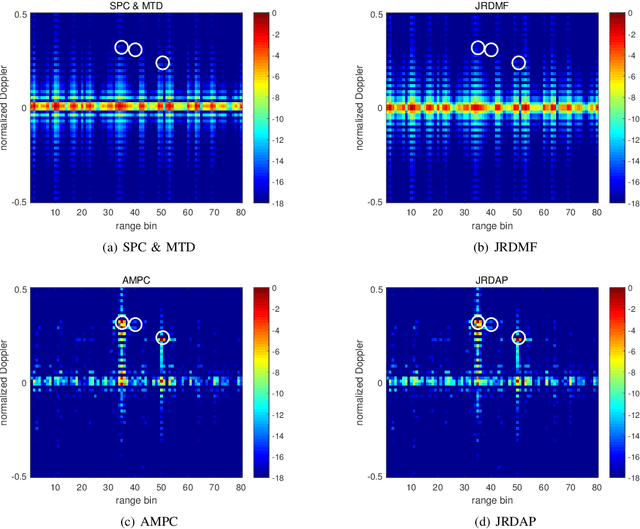
Recently, dual-function radar communication (DFRC) systems have been proposed to integrate radar and communication into one platform for spectrum sharing. Various signalling strategies have been proposed to embed communication information into the radar transmitted waveforms. Among these, complex beampattern modulation (CBM) embeds communication information into the complex transmit beampattens via changing the amplitude and phase of the beampatterns towards the communication receiver. The embedding of random communication information causes the clutter modulation and high range-Doppler sidelobe. What's more, transmitting different waveforms on a pulse to pulse basis degrades the radar target detection capacity when traditional sequential pulse compression (SPC) and moving-target detection (MTD) is utilized. In this paper, a minimum mean square error (MMSE) based filter, denoted as joint range and Doppler adaptive processing (JRDAP) is proposed. The proposed method estimates the targets' impulse response coefficients at each range-Doppler cell adaptively to suppress high range-Doppler sidelobe and clutter modulation. The performance of proposed method is very close to the full-dimension adaptive multiple pulses compression (AMPC) while reducing computational complexity greatly.
SSA: Semantic Structure Aware Inference for Weakly Pixel-Wise Dense Predictions without Cost
Nov 05, 2021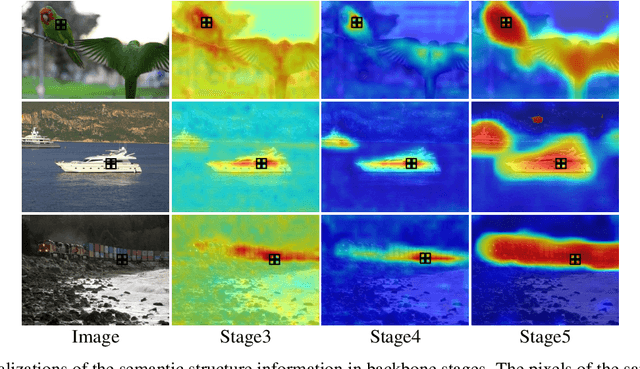
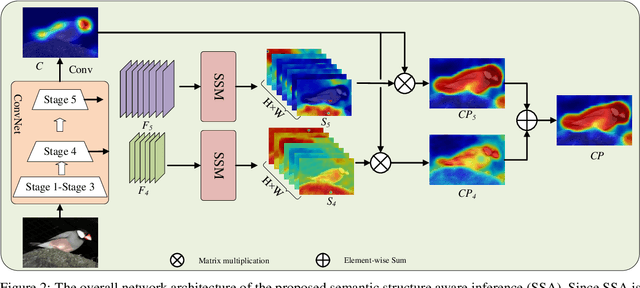
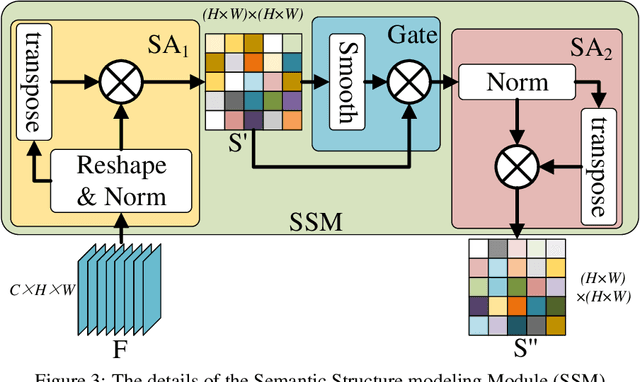
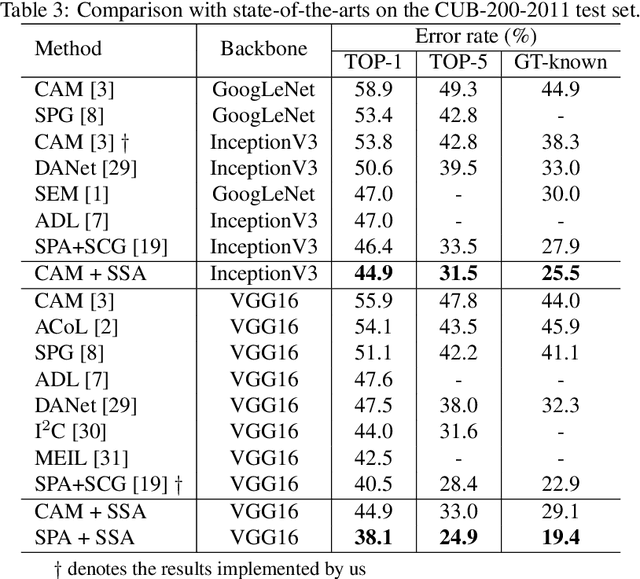
The pixel-wise dense prediction tasks based on weakly supervisions currently use Class Attention Maps (CAM) to generate pseudo masks as ground-truth. However, the existing methods typically depend on the painstaking training modules, which may bring in grinding computational overhead and complex training procedures. In this work, the semantic structure aware inference (SSA) is proposed to explore the semantic structure information hidden in different stages of the CNN-based network to generate high-quality CAM in the model inference. Specifically, the semantic structure modeling module (SSM) is first proposed to generate the class-agnostic semantic correlation representation, where each item denotes the affinity degree between one category of objects and all the others. Then the structured feature representation is explored to polish an immature CAM via the dot product operation. Finally, the polished CAMs from different backbone stages are fused as the output. The proposed method has the advantage of no parameters and does not need to be trained. Therefore, it can be applied to a wide range of weakly-supervised pixel-wise dense prediction tasks. Experimental results on both weakly-supervised object localization and weakly-supervised semantic segmentation tasks demonstrate the effectiveness of the proposed method, which achieves the new state-of-the-art results on these two tasks.
Entropy optimized semi-supervised decomposed vector-quantized variational autoencoder model based on transfer learning for multiclass text classification and generation
Nov 10, 2021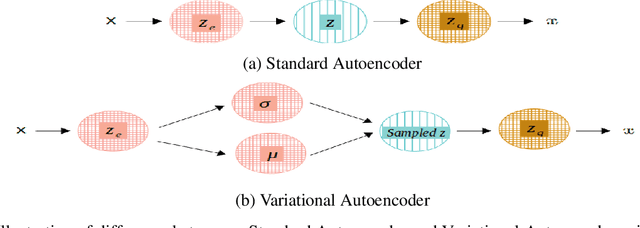
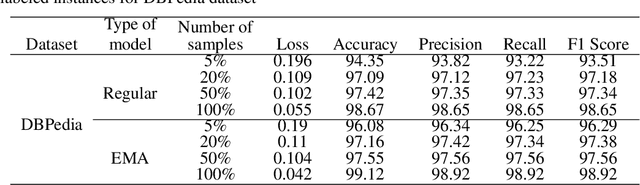
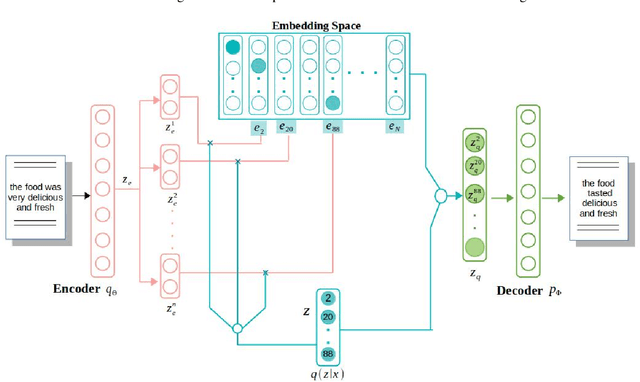
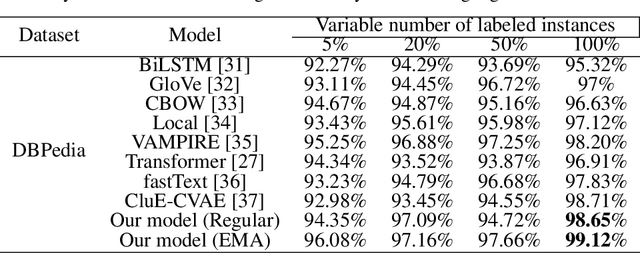
Semisupervised text classification has become a major focus of research over the past few years. Hitherto, most of the research has been based on supervised learning, but its main drawback is the unavailability of labeled data samples in practical applications. It is still a key challenge to train the deep generative models and learn comprehensive representations without supervision. Even though continuous latent variables are employed primarily in deep latent variable models, discrete latent variables, with their enhanced understandability and better compressed representations, are effectively used by researchers. In this paper, we propose a semisupervised discrete latent variable model for multi-class text classification and text generation. The proposed model employs the concept of transfer learning for training a quantized transformer model, which is able to learn competently using fewer labeled instances. The model applies decomposed vector quantization technique to overcome problems like posterior collapse and index collapse. Shannon entropy is used for the decomposed sub-encoders, on which a variable DropConnect is applied, to retain maximum information. Moreover, gradients of the Loss function are adaptively modified during backpropagation from decoder to encoder to enhance the performance of the model. Three conventional datasets of diversified range have been used for validating the proposed model on a variable number of labeled instances. Experimental results indicate that the proposed model has surpassed the state-of-the-art models remarkably.
Synergy between 3DMM and 3D Landmarks for Accurate 3D Facial Geometry
Oct 19, 2021
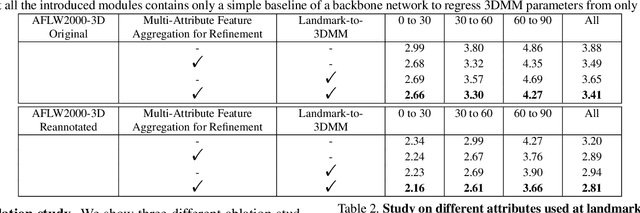
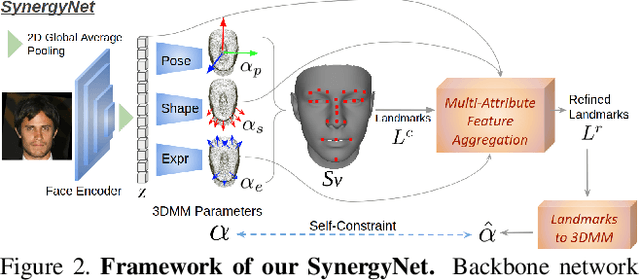
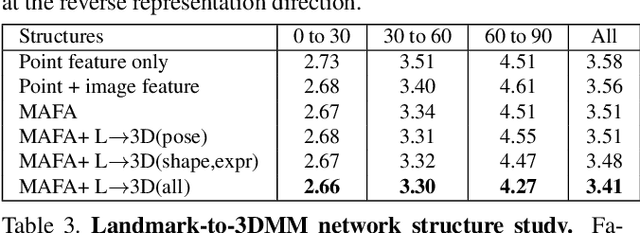
This work studies learning from a synergy process of 3D Morphable Models (3DMM) and 3D facial landmarks to predict complete 3D facial geometry, including 3D alignment, face orientation, and 3D face modeling. Our synergy process leverages a representation cycle for 3DMM parameters and 3D landmarks. 3D landmarks can be extracted and refined from face meshes built by 3DMM parameters. We next reverse the representation direction and show that predicting 3DMM parameters from sparse 3D landmarks improves the information flow. Together we create a synergy process that utilizes the relation between 3D landmarks and 3DMM parameters, and they collaboratively contribute to better performance. We extensively validate our contribution on full tasks of facial geometry prediction and show our superior and robust performance on these tasks for various scenarios. Particularly, we adopt only simple and widely-used network operations to attain fast and accurate facial geometry prediction. Codes and data: https://choyingw.github.io/works/SynergyNet/
Versatile Learned Video Compression
Nov 05, 2021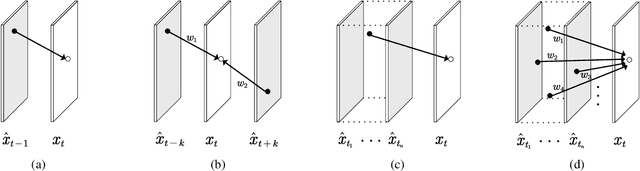


Learned video compression methods have demonstrated great promise in catching up with traditional video codecs in their rate-distortion (R-D) performance. However, existing learned video compression schemes are limited by the binding of the prediction mode and the fixed network framework. They are unable to support various inter prediction modes and thus inapplicable for various scenarios. In this paper, to break this limitation, we propose a versatile learned video compression (VLVC) framework that uses one model to support all possible prediction modes. Specifically, to realize versatile compression, we first build a motion compensation module that applies multiple 3D motion vector fields (i.e., voxel flows) for weighted trilinear warping in spatial-temporal space. The voxel flows convey the information of temporal reference position that helps to decouple inter prediction modes away from framework designing. Secondly, in case of multiple-reference-frame prediction, we apply a flow prediction module to predict accurate motion trajectories with a unified polynomial function. We show that the flow prediction module can largely reduce the transmission cost of voxel flows. Experimental results demonstrate that our proposed VLVC not only supports versatile compression in various settings but also achieves comparable R-D performance with the latest VVC standard in terms of MS-SSIM.
Exploiting Scene Graphs for Human-Object Interaction Detection
Aug 19, 2021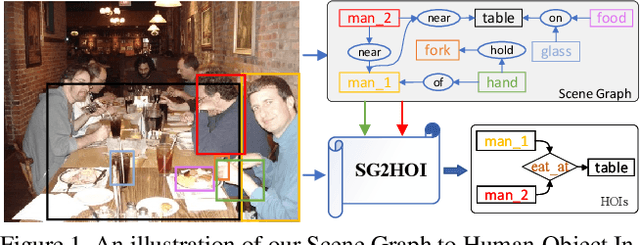
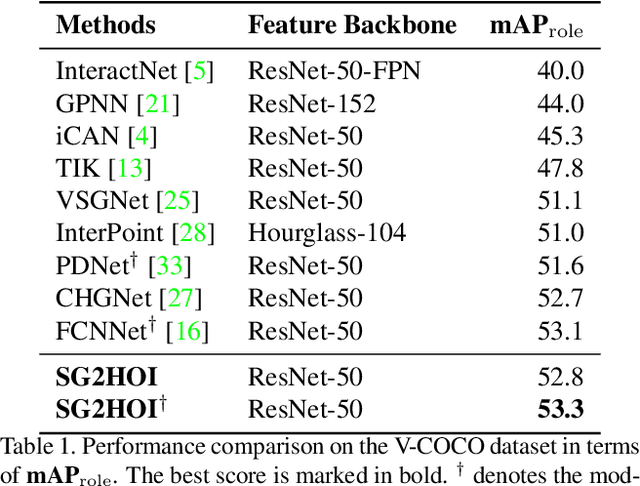
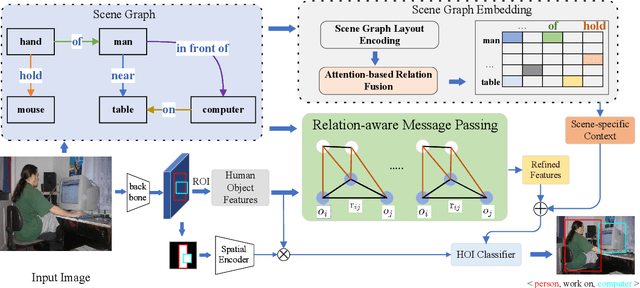
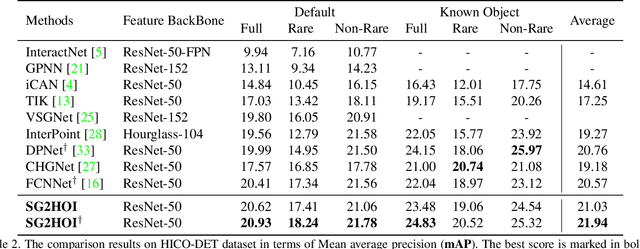
Human-Object Interaction (HOI) detection is a fundamental visual task aiming at localizing and recognizing interactions between humans and objects. Existing works focus on the visual and linguistic features of humans and objects. However, they do not capitalise on the high-level and semantic relationships present in the image, which provides crucial contextual and detailed relational knowledge for HOI inference. We propose a novel method to exploit this information, through the scene graph, for the Human-Object Interaction (SG2HOI) detection task. Our method, SG2HOI, incorporates the SG information in two ways: (1) we embed a scene graph into a global context clue, serving as the scene-specific environmental context; and (2) we build a relation-aware message-passing module to gather relationships from objects' neighborhood and transfer them into interactions. Empirical evaluation shows that our SG2HOI method outperforms the state-of-the-art methods on two benchmark HOI datasets: V-COCO and HICO-DET. Code will be available at https://github.com/ht014/SG2HOI.