 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Synergy between 3DMM and 3D Landmarks for Accurate 3D Facial Geometry
Oct 20, 2021

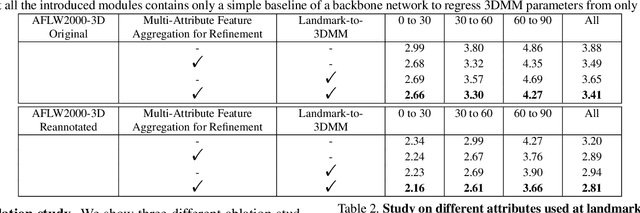
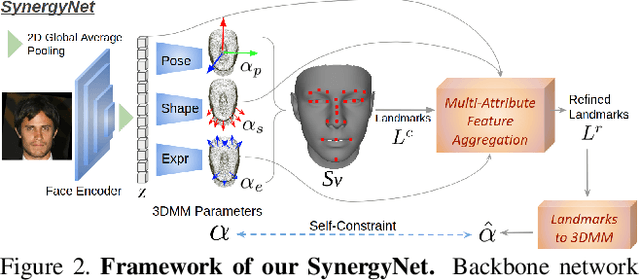
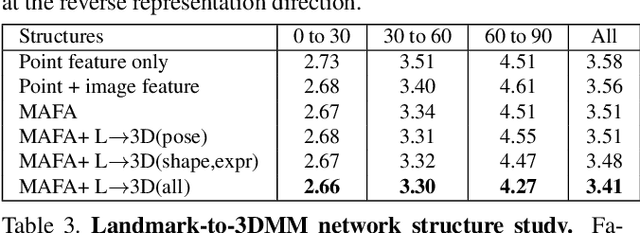
This work studies learning from a synergy process of 3D Morphable Models (3DMM) and 3D facial landmarks to predict complete 3D facial geometry, including 3D alignment, face orientation, and 3D face modeling. Our synergy process leverages a representation cycle for 3DMM parameters and 3D landmarks. 3D landmarks can be extracted and refined from face meshes built by 3DMM parameters. We next reverse the representation direction and show that predicting 3DMM parameters from sparse 3D landmarks improves the information flow. Together we create a synergy process that utilizes the relation between 3D landmarks and 3DMM parameters, and they collaboratively contribute to better performance. We extensively validate our contribution on full tasks of facial geometry prediction and show our superior and robust performance on these tasks for various scenarios. Particularly, we adopt only simple and widely-used network operations to attain fast and accurate facial geometry prediction. Codes and data: https://choyingw.github.io/works/SynergyNet/
One model to enhance them all: array geometry agnostic multi-channel personalized speech enhancement
Oct 20, 2021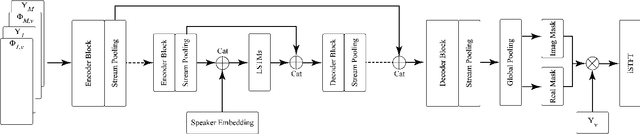
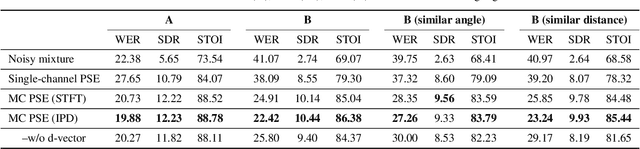
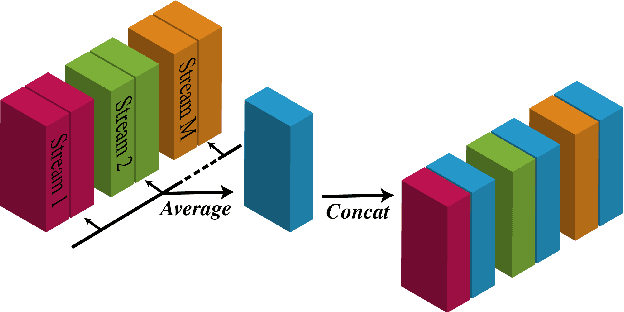
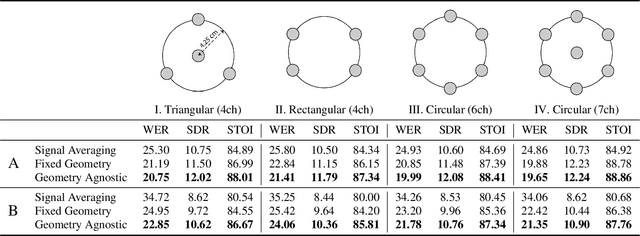
With the recent surge of video conferencing tools usage, providing high-quality speech signals and accurate captions have become essential to conduct day-to-day business or connect with friends and families. Single-channel personalized speech enhancement (PSE) methods show promising results compared with the unconditional speech enhancement (SE) methods in these scenarios due to their ability to remove interfering speech in addition to the environmental noise. In this work, we leverage spatial information afforded by microphone arrays to improve such systems' performance further. We investigate the relative importance of speaker embeddings and spatial features. Moreover, we propose a new causal array-geometry-agnostic multi-channel PSE model, which can generate a high-quality enhanced signal from arbitrary microphone geometry. Experimental results show that the proposed geometry agnostic model outperforms the model trained on a specific microphone array geometry in both speech quality and automatic speech recognition accuracy. We also demonstrate the effectiveness of the proposed approach for unseen array geometries.
CS-Rep: Making Speaker Verification Networks Embracing Re-parameterization
Oct 26, 2021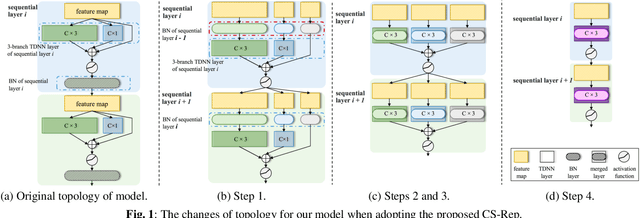
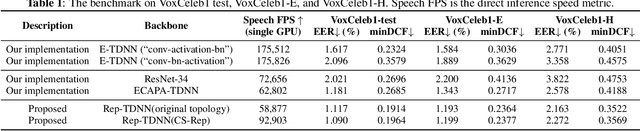
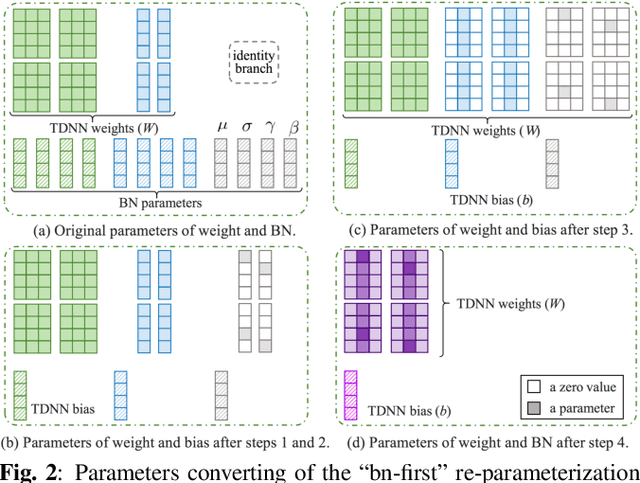
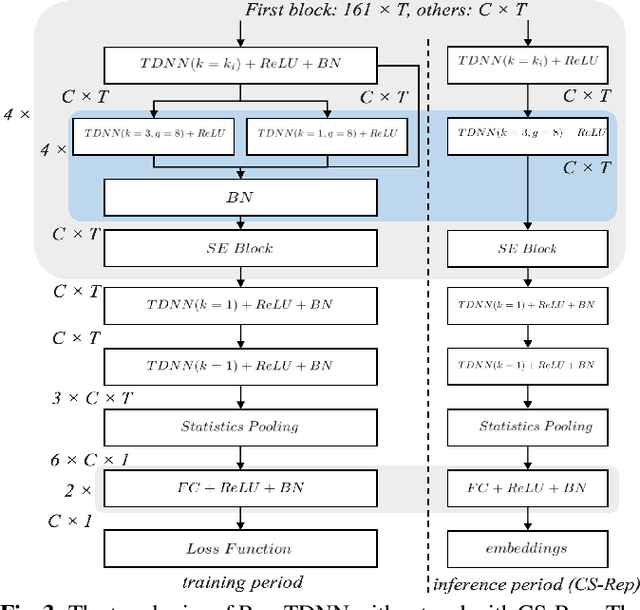
Automatic speaker verification (ASV) systems, which determine whether two speeches are from the same speaker, mainly focus on verification accuracy while ignoring inference speed. However, in real applications, both inference speed and verification accuracy are essential. This study proposes cross-sequential re-parameterization (CS-Rep), a novel topology re-parameterization strategy for multi-type networks, to increase the inference speed and verification accuracy of models. CS-Rep solves the problem that existing re-parameterization methods are unsuitable for typical ASV backbones. When a model applies CS-Rep, the training-period network utilizes a multi-branch topology to capture speaker information, whereas the inference-period model converts to a time-delay neural network (TDNN)-like plain backbone with stacked TDNN layers to achieve the fast inference speed. Based on CS-Rep, an improved TDNN with friendly test and deployment called Rep-TDNN is proposed. Compared with the state-of-the-art model ECAPA-TDNN, which is highly recognized in the industry, Rep-TDNN increases the actual inference speed by about 50% and reduces the EER by 10%. The code will be released.
TACTIC: Joint Rate-Distortion-Accuracy Optimisation for Low Bitrate Compression
Sep 22, 2021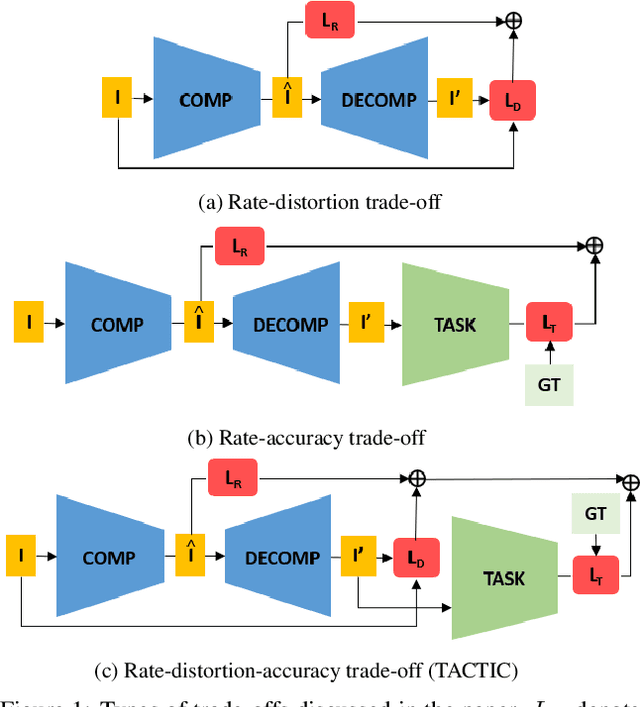

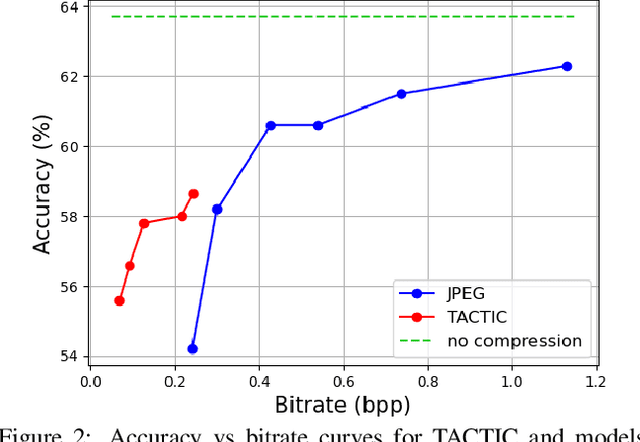
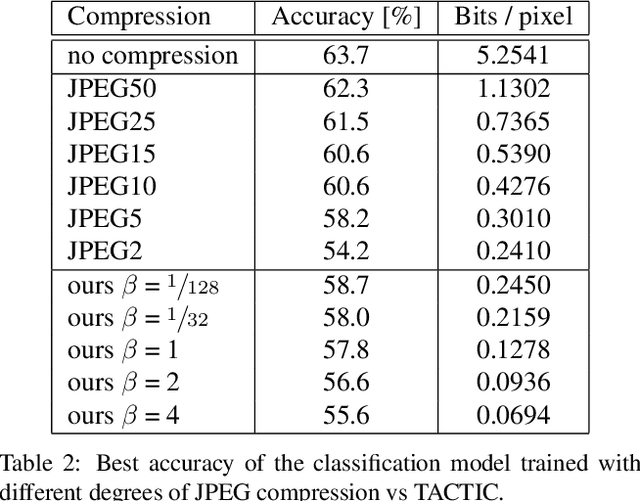
We present TACTIC: Task-Aware Compression Through Intelligent Coding. Our lossy compression model learns based on the rate-distortion-accuracy trade-off for a specific task. By considering what information is important for the follow-on problem, the system trades off visual fidelity for good task performance at a low bitrate. When compared against JPEG at the same bitrate, our approach is able to improve the accuracy of ImageNet subset classification by 4.5%. We also demonstrate the applicability of our approach to other problems, providing a 3.4% accuracy and 4.9% mean IoU improvements in performance over task-agnostic compression for semantic segmentation.
ExIt-OOS: Towards Learning from Planning in Imperfect Information Games
Oct 25, 2018



The current state of the art in playing many important perfect information games, including Chess and Go, combines planning and deep reinforcement learning with self-play. We extend this approach to imperfect information games and present ExIt-OOS, a novel approach to playing imperfect information games within the Expert Iteration framework and inspired by AlphaZero. We use Online Outcome Sampling, an online search algorithm for imperfect information games in place of MCTS. While training online, our neural strategy is used to improve the accuracy of playouts in OOS, allowing a learning and planning feedback loop for imperfect information games.
Multi-task learning from fixed-wing UAV images for 2D/3D city modeling
Aug 25, 2021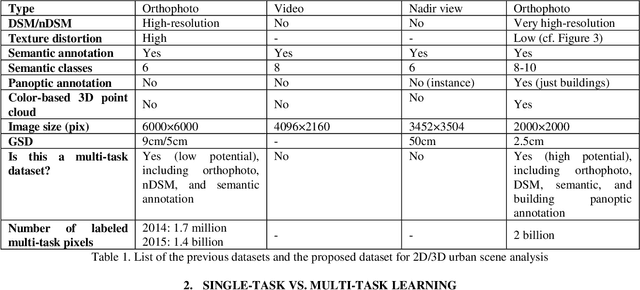
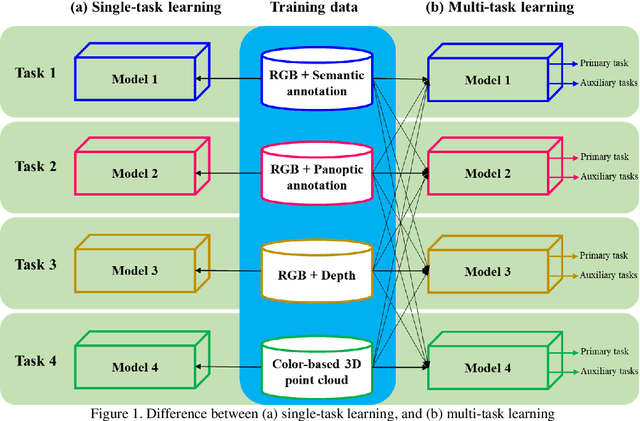
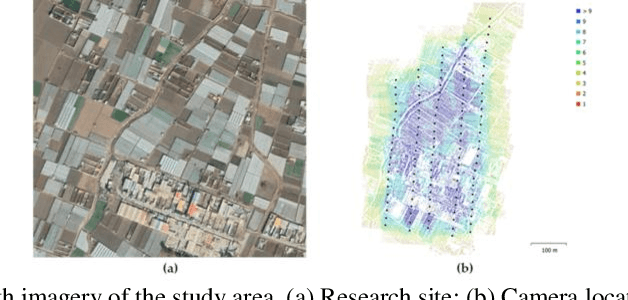

Single-task learning in artificial neural networks will be able to learn the model very well, and the benefits brought by transferring knowledge thus become limited. In this regard, when the number of tasks increases (e.g., semantic segmentation, panoptic segmentation, monocular depth estimation, and 3D point cloud), duplicate information may exist across tasks, and the improvement becomes less significant. Multi-task learning has emerged as a solution to knowledge-transfer issues and is an approach to scene understanding which involves multiple related tasks each with potentially limited training data. Multi-task learning improves generalization by leveraging the domain-specific information contained in the training data of related tasks. In urban management applications such as infrastructure development, traffic monitoring, smart 3D cities, and change detection, automated multi-task data analysis for scene understanding based on the semantic, instance, and panoptic annotation, as well as monocular depth estimation, is required to generate precise urban models. In this study, a common framework for the performance assessment of multi-task learning methods from fixed-wing UAV images for 2D/3D city modeling is presented.
Tightening Mutual Information Based Bounds on Generalization Error
Jan 15, 2019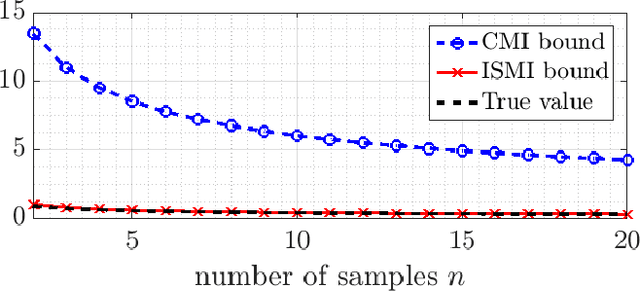
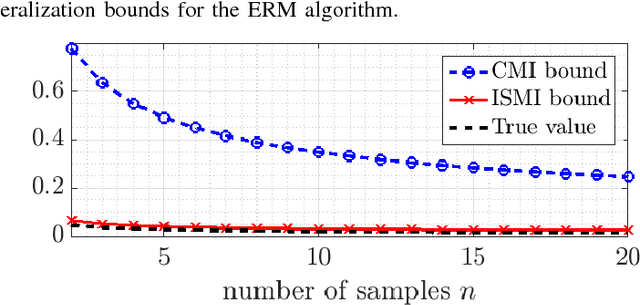
A mutual information based upper bound on the generalization error of a supervised learning algorithm is derived in this paper. The bound is constructed in terms of the mutual information between each individual training sample and the output of the learning algorithm, which requires weaker conditions on the loss function, but provides a tighter characterization of the generalization error than existing studies. Examples are further provided to demonstrate that the bound derived in this paper is tighter, and has a broader range of applicability. Application to noisy and iterative algorithms, e.g., stochastic gradient Langevin dynamics (SGLD), is also studied, where the constructed bound provides a tighter characterization of the generalization error than existing results.
Convergent Boosted Smoothing for Modeling Graph Data with Tabular Node Features
Oct 26, 2021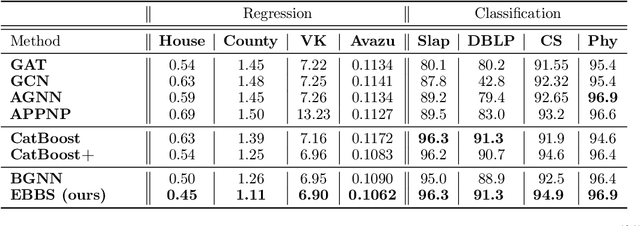
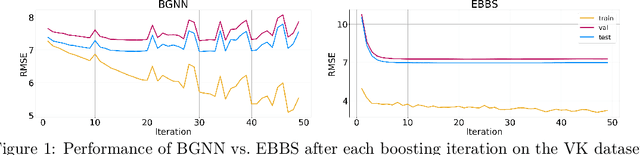

For supervised learning with tabular data, decision tree ensembles produced via boosting techniques generally dominate real-world applications involving iid training/test sets. However for graph data where the iid assumption is violated due to structured relations between samples, it remains unclear how to best incorporate this structure within existing boosting pipelines. To this end, we propose a generalized framework for iterating boosting with graph propagation steps that share node/sample information across edges connecting related samples. Unlike previous efforts to integrate graph-based models with boosting, our approach is anchored in a principled meta loss function such that provable convergence can be guaranteed under relatively mild assumptions. Across a variety of non-iid graph datasets with tabular node features, our method achieves comparable or superior performance than both tabular and graph neural network models, as well as existing hybrid strategies that combine the two. Beyond producing better predictive performance than recently proposed graph models, our proposed techniques are easy to implement, computationally more efficient, and enjoy stronger theoretical guarantees (which make our results more reproducible).
Artificial Neural Network and its Application Research Progress in Distillation
Oct 01, 2021Artificial neural networks learn various rules and algorithms to form different ways of processing information, and have been widely used in various chemical processes. Among them, with the development of rectification technology, its production scale continues to expand, and its calculation requirements are also more stringent, because the artificial neural network has the advantages of self-learning, associative storage and high-speed search for optimized solutions, it can make high-precision simulation predictions for rectification operations, so it is widely used in the chemical field of rectification. This article gives a basic overview of artificial neural networks, and introduces the application research of artificial neural networks in distillation at home and abroad.
Mutual Information Maximization on Disentangled Representations for Differential Morph Detection
Dec 02, 2020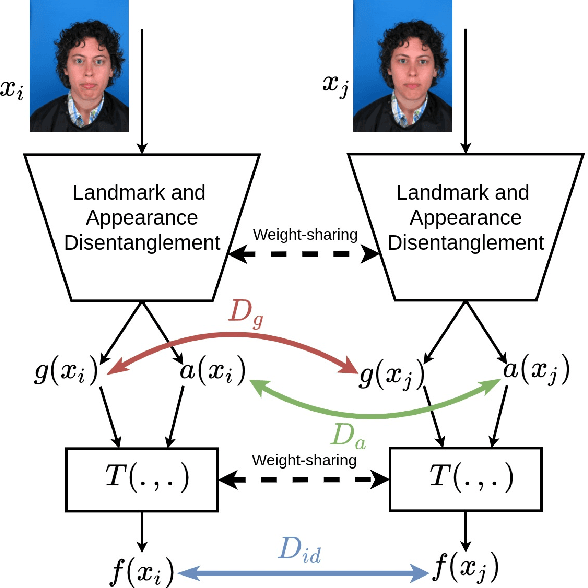
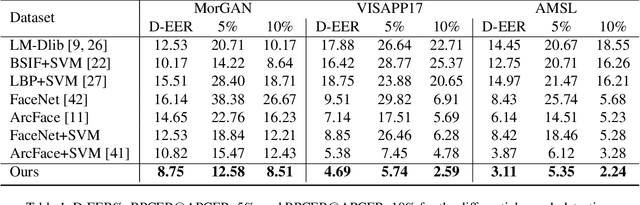
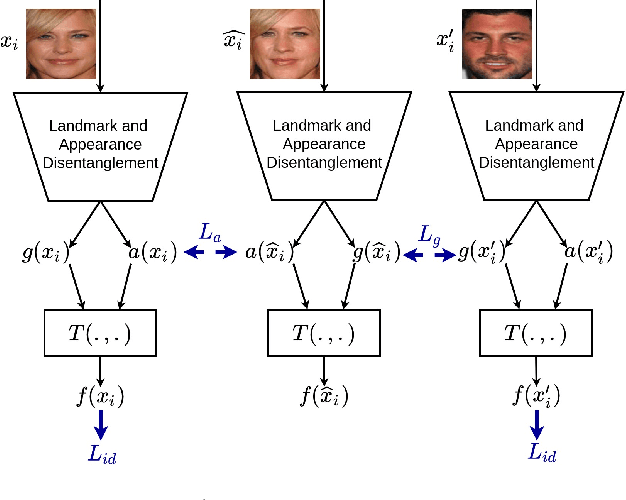
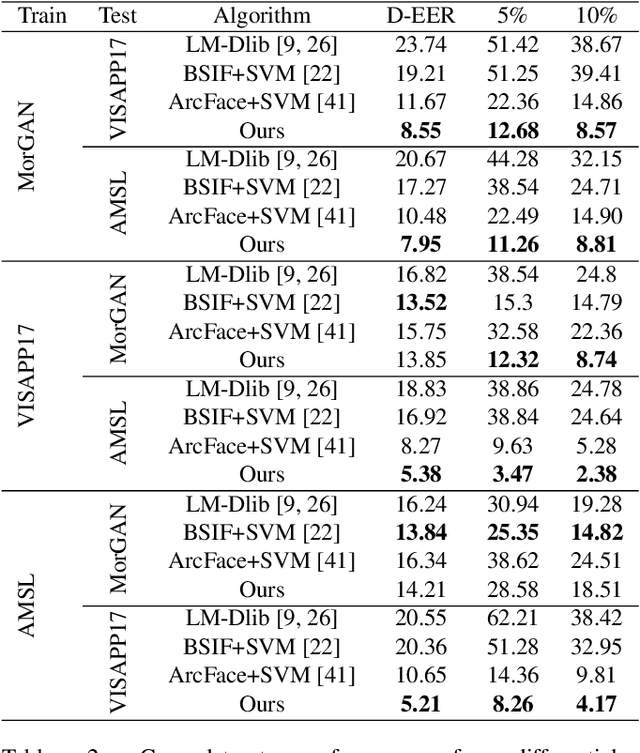
In this paper, we present a novel differential morph detection framework, utilizing landmark and appearance disentanglement. In our framework, the face image is represented in the embedding domain using two disentangled but complementary representations. The network is trained by triplets of face images, in which the intermediate image inherits the landmarks from one image and the appearance from the other image. This initially trained network is further trained for each dataset using contrastive representations. We demonstrate that, by employing appearance and landmark disentanglement, the proposed framework can provide state-of-the-art differential morph detection performance. This functionality is achieved by the using distances in landmark, appearance, and ID domains. The performance of the proposed framework is evaluated using three morph datasets generated with different methodologies.