 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Universal Protocol to Benchmark Camera Calibration for Sports
Apr 15, 2024
Camera calibration is a crucial component in the realm of sports analytics, as it serves as the foundation to extract 3D information out of the broadcast images. Despite the significance of camera calibration research in sports analytics, progress is impeded by outdated benchmarking criteria. Indeed, the annotation data and evaluation metrics provided by most currently available benchmarks strongly favor and incite the development of sports field registration methods, i.e. methods estimating homographies that map the sports field plane to the image plane. However, such homography-based methods are doomed to overlook the broader capabilities of camera calibration in bridging the 3D world to the image. In particular, real-world non-planar sports field elements (such as goals, corner flags, baskets, ...) and image distortion caused by broadcast camera lenses are out of the scope of sports field registration methods. To overcome these limitations, we designed a new benchmarking protocol, named ProCC, based on two principles: (1) the protocol should be agnostic to the camera model chosen for a camera calibration method, and (2) the protocol should fairly evaluate camera calibration methods using the reprojection of arbitrary yet accurately known 3D objects. Indirectly, we also provide insights into the metric used in SoccerNet-calibration, which solely relies on image annotation data of viewed 3D objects as ground truth, thus implementing our protocol. With experiments on the World Cup 2014, CARWC, and SoccerNet datasets, we show that our benchmarking protocol provides fairer evaluations of camera calibration methods. By defining our requirements for proper benchmarking, we hope to pave the way for a new stage in camera calibration for sports applications with high accuracy standards.
Developing An Attention-Based Ensemble Learning Framework for Financial Portfolio Optimisation
Apr 13, 2024In recent years, deep or reinforcement learning approaches have been applied to optimise investment portfolios through learning the spatial and temporal information under the dynamic financial market. Yet in most cases, the existing approaches may produce biased trading signals based on the conventional price data due to a lot of market noises, which possibly fails to balance the investment returns and risks. Accordingly, a multi-agent and self-adaptive portfolio optimisation framework integrated with attention mechanisms and time series, namely the MASAAT, is proposed in this work in which multiple trading agents are created to observe and analyse the price series and directional change data that recognises the significant changes of asset prices at different levels of granularity for enhancing the signal-to-noise ratio of price series. Afterwards, by reconstructing the tokens of financial data in a sequence, the attention-based cross-sectional analysis module and temporal analysis module of each agent can effectively capture the correlations between assets and the dependencies between time points. Besides, a portfolio generator is integrated into the proposed framework to fuse the spatial-temporal information and then summarise the portfolios suggested by all trading agents to produce a newly ensemble portfolio for reducing biased trading actions and balancing the overall returns and risks. The experimental results clearly demonstrate that the MASAAT framework achieves impressive enhancement when compared with many well-known portfolio optimsation approaches on three challenging data sets of DJIA, S&P 500 and CSI 300. More importantly, our proposal has potential strengths in many possible applications for future study.
RLEMMO: Evolutionary Multimodal Optimization Assisted By Deep Reinforcement Learning
Apr 12, 2024Solving multimodal optimization problems (MMOP) requires finding all optimal solutions, which is challenging in limited function evaluations. Although existing works strike the balance of exploration and exploitation through hand-crafted adaptive strategies, they require certain expert knowledge, hence inflexible to deal with MMOP with different properties. In this paper, we propose RLEMMO, a Meta-Black-Box Optimization framework, which maintains a population of solutions and incorporates a reinforcement learning agent for flexibly adjusting individual-level searching strategies to match the up-to-date optimization status, hence boosting the search performance on MMOP. Concretely, we encode landscape properties and evolution path information into each individual and then leverage attention networks to advance population information sharing. With a novel reward mechanism that encourages both quality and diversity, RLEMMO can be effectively trained using a policy gradient algorithm. The experimental results on the CEC2013 MMOP benchmark underscore the competitive optimization performance of RLEMMO against several strong baselines.
LUCF-Net: Lightweight U-shaped Cascade Fusion Network for Medical Image Segmentation
Apr 11, 2024In this study, the performance of existing U-shaped neural network architectures was enhanced for medical image segmentation by adding Transformer. Although Transformer architectures are powerful at extracting global information, its ability to capture local information is limited due to its high complexity. To address this challenge, we proposed a new lightweight U-shaped cascade fusion network (LUCF-Net) for medical image segmentation. It utilized an asymmetrical structural design and incorporated both local and global modules to enhance its capacity for local and global modeling. Additionally, a multi-layer cascade fusion decoding network was designed to further bolster the network's information fusion capabilities. Validation results achieved on multi-organ datasets in CT format, cardiac segmentation datasets in MRI format, and dermatology datasets in image format demonstrated that the proposed model outperformed other state-of-the-art methods in handling local-global information, achieving an improvement of 1.54% in Dice coefficient and 2.6 mm in Hausdorff distance on multi-organ segmentation. Furthermore, as a network that combines Convolutional Neural Network and Transformer architectures, it achieves competitive segmentation performance with only 6.93 million parameters and 6.6 gigabytes of floating point operations, without the need of pre-training. In summary, the proposed method demonstrated enhanced performance while retaining a simpler model design compared to other Transformer-based segmentation networks.
MambaAD: Exploring State Space Models for Multi-class Unsupervised Anomaly Detection
Apr 14, 2024Recent advancements in anomaly detection have seen the efficacy of CNN- and transformer-based approaches. However, CNNs struggle with long-range dependencies, while transformers are burdened by quadratic computational complexity. Mamba-based models, with their superior long-range modeling and linear efficiency, have garnered substantial attention. This study pioneers the application of Mamba to multi-class unsupervised anomaly detection, presenting MambaAD, which consists of a pre-trained encoder and a Mamba decoder featuring (Locality-Enhanced State Space) LSS modules at multi-scales. The proposed LSS module, integrating parallel cascaded (Hybrid State Space) HSS blocks and multi-kernel convolutions operations, effectively captures both long-range and local information. The HSS block, utilizing (Hybrid Scanning) HS encoders, encodes feature maps into five scanning methods and eight directions, thereby strengthening global connections through the (State Space Model) SSM. The use of Hilbert scanning and eight directions significantly improves feature sequence modeling. Comprehensive experiments on six diverse anomaly detection datasets and seven metrics demonstrate state-of-the-art performance, substantiating the method's effectiveness.
Towards Practical Tool Usage for Continually Learning LLMs
Apr 14, 2024Large language models (LLMs) show an innate skill for solving language based tasks. But insights have suggested an inability to adjust for information or task-solving skills becoming outdated, as their knowledge, stored directly within their parameters, remains static in time. Tool use helps by offloading work to systems that the LLM can access through an interface, but LLMs that use them still must adapt to nonstationary environments for prolonged use, as new tools can emerge and existing tools can change. Nevertheless, tools require less specialized knowledge, therefore we hypothesize they are better suited for continual learning (CL) as they rely less on parametric memory for solving tasks and instead focus on learning when to apply pre-defined tools. To verify this, we develop a synthetic benchmark and follow this by aggregating existing NLP tasks to form a more realistic testing scenario. While we demonstrate scaling model size is not a solution, regardless of tool usage, continual learning techniques can enable tool LLMs to both adapt faster while forgetting less, highlighting their potential as continual learners.
MetaIE: Distilling a Meta Model from LLM for All Kinds of Information Extraction Tasks
Mar 30, 2024Information extraction (IE) is a fundamental area in natural language processing where prompting large language models (LLMs), even with in-context examples, cannot defeat small LMs tuned on very small IE datasets. We observe that IE tasks, such as named entity recognition and relation extraction, all focus on extracting important information, which can be formalized as a label-to-span matching. In this paper, we propose a novel framework MetaIE to build a small LM as meta-model by learning to extract "important information", i.e., the meta-understanding of IE, so that this meta-model can be adapted to all kind of IE tasks effectively and efficiently. Specifically, MetaIE obtains the small LM via a symbolic distillation from an LLM following the label-to-span scheme. We construct the distillation dataset via sampling sentences from language model pre-training datasets (e.g., OpenWebText in our implementation) and prompting an LLM to identify the typed spans of "important information". We evaluate the meta-model under the few-shot adaptation setting. Extensive results on 13 datasets from 6 IE tasks confirm that MetaIE can offer a better starting point for few-shot tuning on IE datasets and outperform other meta-models from (1) vanilla language model pre-training, (2) multi-IE-task pre-training with human annotations, and (3) single-IE-task symbolic distillation from LLM. Moreover, we provide comprehensive analyses of MetaIE, such as the size of the distillation dataset, the meta-model architecture, and the size of the meta-model.
An Information-Theoretic Framework for Out-of-Distribution Generalization
Mar 29, 2024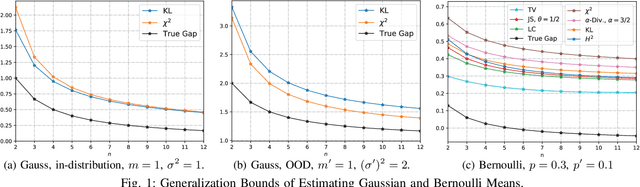
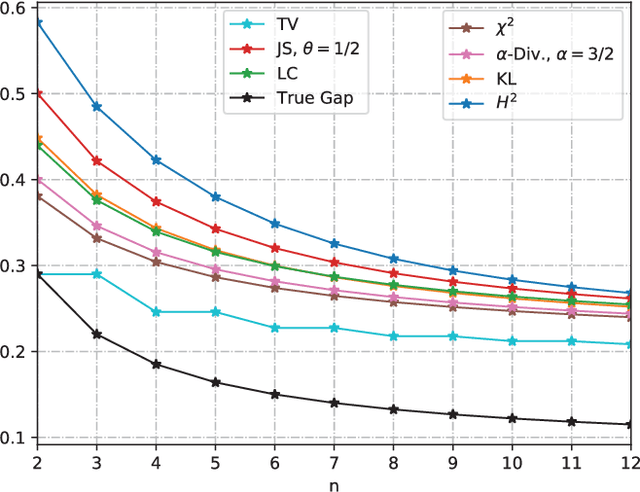
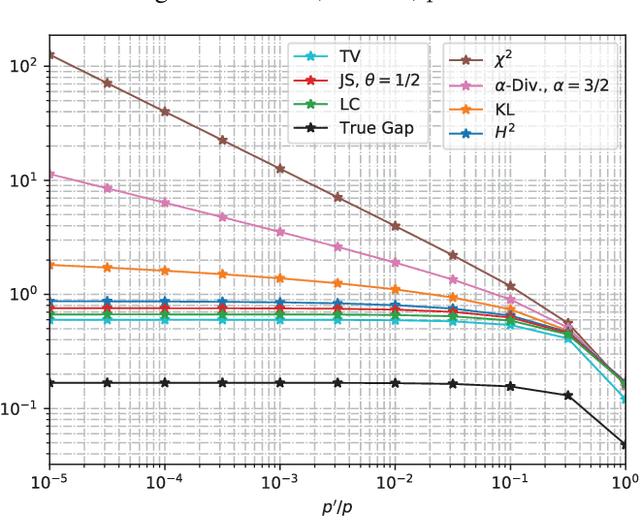

We study the Out-of-Distribution (OOD) generalization in machine learning and propose a general framework that provides information-theoretic generalization bounds. Our framework interpolates freely between Integral Probability Metric (IPM) and $f$-divergence, which naturally recovers some known results (including Wasserstein- and KL-bounds), as well as yields new generalization bounds. Moreover, we show that our framework admits an optimal transport interpretation. When evaluated in two concrete examples, the proposed bounds either strictly improve upon existing bounds in some cases or recover the best among existing OOD generalization bounds.
An Experimental Comparison Of Multi-view Self-supervised Methods For Music Tagging
Apr 14, 2024Self-supervised learning has emerged as a powerful way to pre-train generalizable machine learning models on large amounts of unlabeled data. It is particularly compelling in the music domain, where obtaining labeled data is time-consuming, error-prone, and ambiguous. During the self-supervised process, models are trained on pretext tasks, with the primary objective of acquiring robust and informative features that can later be fine-tuned for specific downstream tasks. The choice of the pretext task is critical as it guides the model to shape the feature space with meaningful constraints for information encoding. In the context of music, most works have relied on contrastive learning or masking techniques. In this study, we expand the scope of pretext tasks applied to music by investigating and comparing the performance of new self-supervised methods for music tagging. We open-source a simple ResNet model trained on a diverse catalog of millions of tracks. Our results demonstrate that, although most of these pre-training methods result in similar downstream results, contrastive learning consistently results in better downstream performance compared to other self-supervised pre-training methods. This holds true in a limited-data downstream context.
RF-Diffusion: Radio Signal Generation via Time-Frequency Diffusion
Apr 14, 2024Along with AIGC shines in CV and NLP, its potential in the wireless domain has also emerged in recent years. Yet, existing RF-oriented generative solutions are ill-suited for generating high-quality, time-series RF data due to limited representation capabilities. In this work, inspired by the stellar achievements of the diffusion model in CV and NLP, we adapt it to the RF domain and propose RF-Diffusion. To accommodate the unique characteristics of RF signals, we first introduce a novel Time-Frequency Diffusion theory to enhance the original diffusion model, enabling it to tap into the information within the time, frequency, and complex-valued domains of RF signals. On this basis, we propose a Hierarchical Diffusion Transformer to translate the theory into a practical generative DNN through elaborated design spanning network architecture, functional block, and complex-valued operator, making RF-Diffusion a versatile solution to generate diverse, high-quality, and time-series RF data. Performance comparison with three prevalent generative models demonstrates the RF-Diffusion's superior performance in synthesizing Wi-Fi and FMCW signals. We also showcase the versatility of RF-Diffusion in boosting Wi-Fi sensing systems and performing channel estimation in 5G networks.