 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Developing Products Update-Alert System for e-Commerce Websites Users Using HTML Data and Web Scraping Technique
Sep 02, 2021
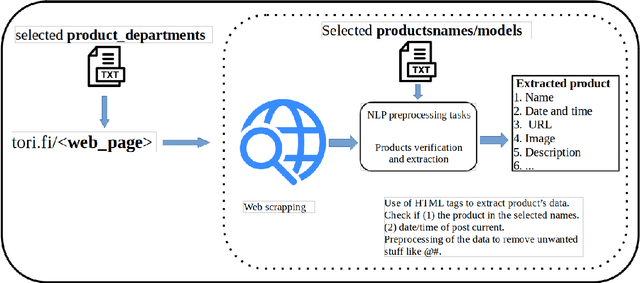

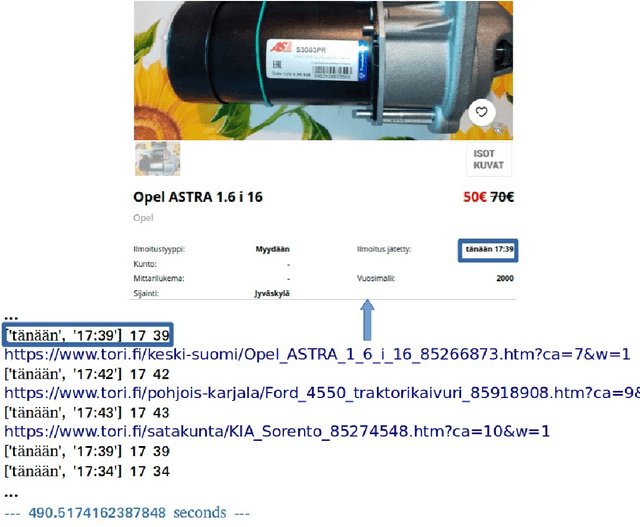
Websites are regarded as domains of limitless information which anyone and everyone can access. The new trend of technology put us to change the way we are doing our business. The Internet now is fastly becoming a new place for business and the advancement in this technology gave rise to the number of e-commerce websites. This made the lifestyle of marketers/vendors, retailers and consumers (collectively regarded as users in this paper) easy, because it provides easy platforms to sale/order items through the internet. This also requires that the users will have to spend a lot of time and effort to search for the best product deals, products updates and offers on e-commerce websites. They have to filter and compare search results by themselves which takes a lot of time and there are chances of ambiguous results. In this paper, we applied web crawling and scraping methods on an e-commerce website to get HTML data for identifying products updates based on the current time. The HTML data is preprocessed to extract details of the products such as name, price, post date and time, etc. to serve as useful information for users.
* 6 pages, 3 figures, 1 table, IJNLC Journal
A Neural Conversation Generation Model via Equivalent Shared Memory Investigation
Aug 20, 2021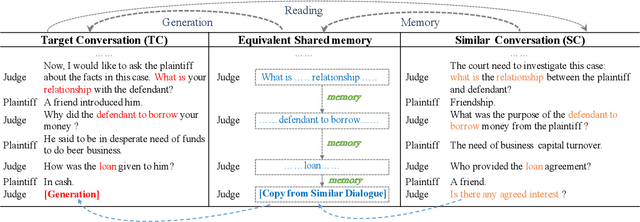
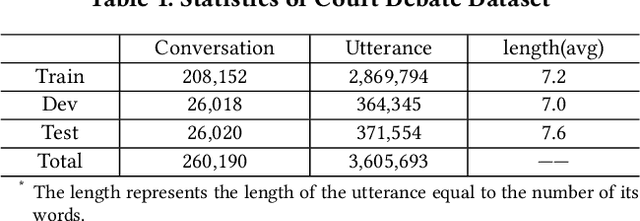
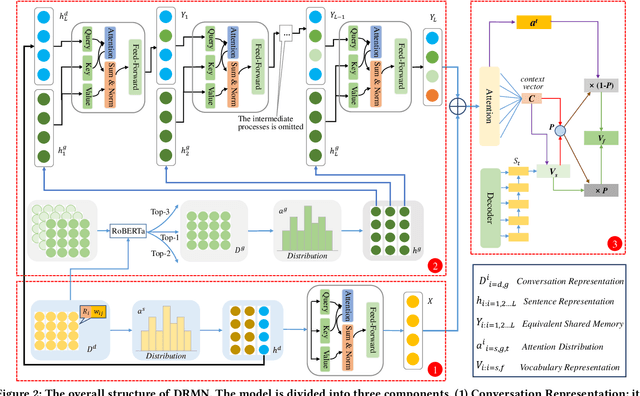
Conversation generation as a challenging task in Natural Language Generation (NLG) has been increasingly attracting attention over the last years. A number of recent works adopted sequence-to-sequence structures along with external knowledge, which successfully enhanced the quality of generated conversations. Nevertheless, few works utilized the knowledge extracted from similar conversations for utterance generation. Taking conversations in customer service and court debate domains as examples, it is evident that essential entities/phrases, as well as their associated logic and inter-relationships can be extracted and borrowed from similar conversation instances. Such information could provide useful signals for improving conversation generation. In this paper, we propose a novel reading and memory framework called Deep Reading Memory Network (DRMN) which is capable of remembering useful information of similar conversations for improving utterance generation. We apply our model to two large-scale conversation datasets of justice and e-commerce fields. Experiments prove that the proposed model outperforms the state-of-the-art approaches.
Self-Supervised Radio-Visual Representation Learning for 6G Sensing
Nov 01, 2021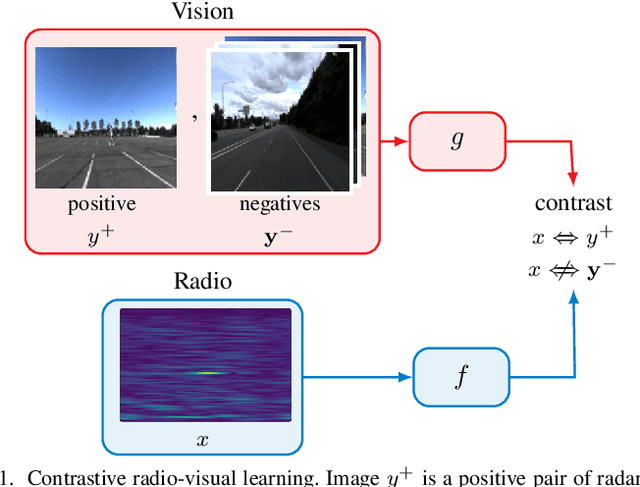
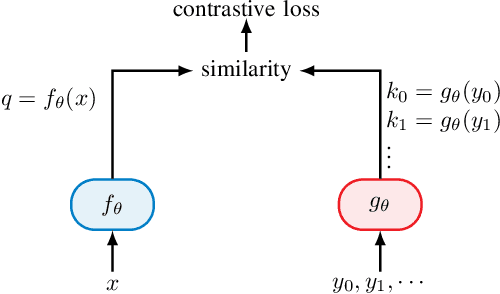
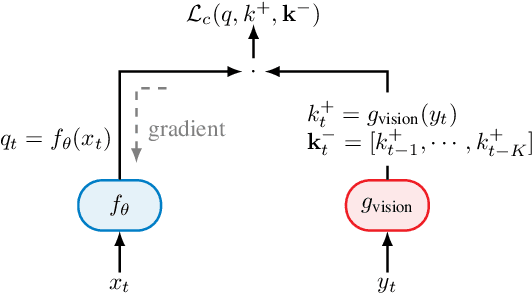
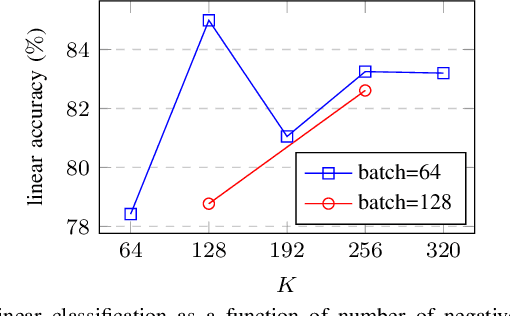
In future 6G cellular networks, a joint communication and sensing protocol will allow the network to perceive the environment, opening the door for many new applications atop a unified communication-perception infrastructure. However, interpreting the sparse radio representation of sensing scenes is challenging, which hinders the potential of these emergent systems. We propose to combine radio and vision to automatically learn a radio-only sensing model with minimal human intervention. We want to build a radio sensing model that can feed on millions of uncurated data points. To this end, we leverage recent advances in self-supervised learning and formulate a new label-free radio-visual co-learning scheme, whereby vision trains radio via cross-modal mutual information. We implement and evaluate our scheme according to the common linear classification benchmark, and report qualitative and quantitative performance metrics. In our evaluation, the representation learnt by radio-visual self-supervision works well for a downstream sensing demonstrator, and outperforms its fully-supervised counterpart when less labelled data is used. This indicates that self-supervised learning could be an important enabler for future scalable radio sensing systems.
Enhanced Language Representation with Label Knowledge for Span Extraction
Nov 01, 2021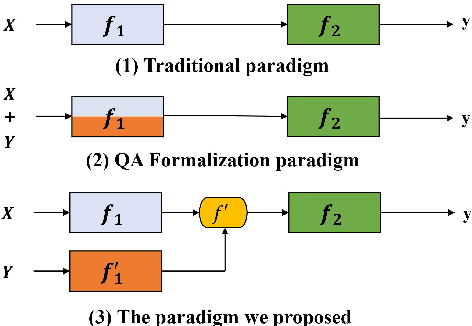


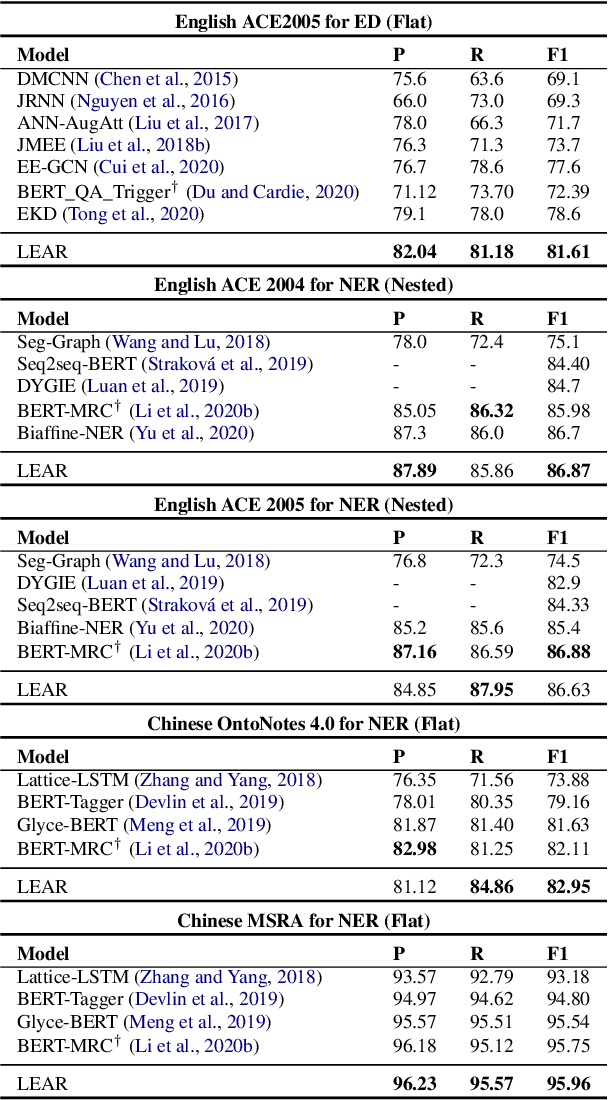
Span extraction, aiming to extract text spans (such as words or phrases) from plain texts, is a fundamental process in Information Extraction. Recent works introduce the label knowledge to enhance the text representation by formalizing the span extraction task into a question answering problem (QA Formalization), which achieves state-of-the-art performance. However, QA Formalization does not fully exploit the label knowledge and suffers from low efficiency in training/inference. To address those problems, we introduce a new paradigm to integrate label knowledge and further propose a novel model to explicitly and efficiently integrate label knowledge into text representations. Specifically, it encodes texts and label annotations independently and then integrates label knowledge into text representation with an elaborate-designed semantics fusion module. We conduct extensive experiments on three typical span extraction tasks: flat NER, nested NER, and event detection. The empirical results show that 1) our method achieves state-of-the-art performance on four benchmarks, and 2) reduces training time and inference time by 76% and 77% on average, respectively, compared with the QA Formalization paradigm. Our code and data are available at https://github.com/Akeepers/LEAR.
Semi-supervised Network Embedding with Differentiable Deep Quantisation
Aug 20, 2021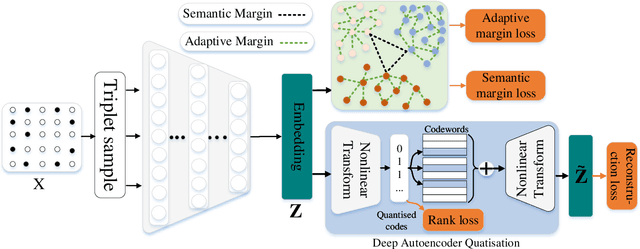
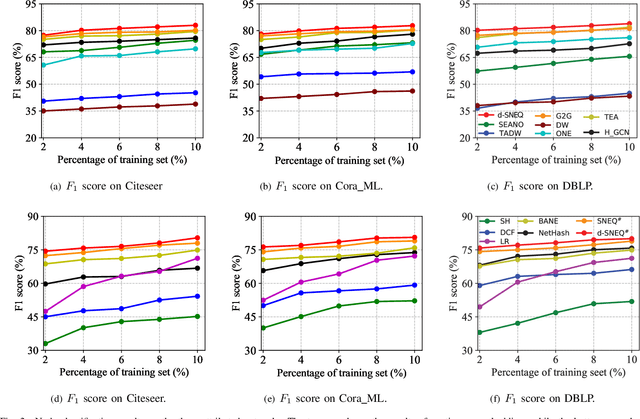
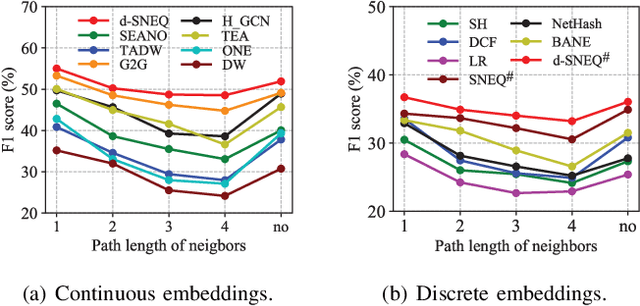
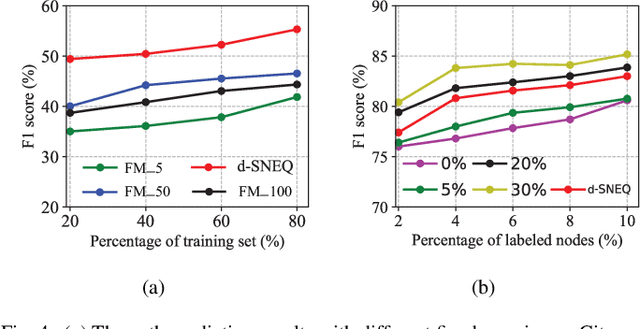
Learning accurate low-dimensional embeddings for a network is a crucial task as it facilitates many downstream network analytics tasks. For large networks, the trained embeddings often require a significant amount of space to store, making storage and processing a challenge. Building on our previous work on semi-supervised network embedding, we develop d-SNEQ, a differentiable DNN-based quantisation method for network embedding. d-SNEQ incorporates a rank loss to equip the learned quantisation codes with rich high-order information and is able to substantially compress the size of trained embeddings, thus reducing storage footprint and accelerating retrieval speed. We also propose a new evaluation metric, path prediction, to fairly and more directly evaluate model performance on the preservation of high-order information. Our evaluation on four real-world networks of diverse characteristics shows that d-SNEQ outperforms a number of state-of-the-art embedding methods in link prediction, path prediction, node classification, and node recommendation while being far more space- and time-efficient.
Learning-Based Downlink Power Allocation in Cell-Free Massive MIMO Systems
Sep 07, 2021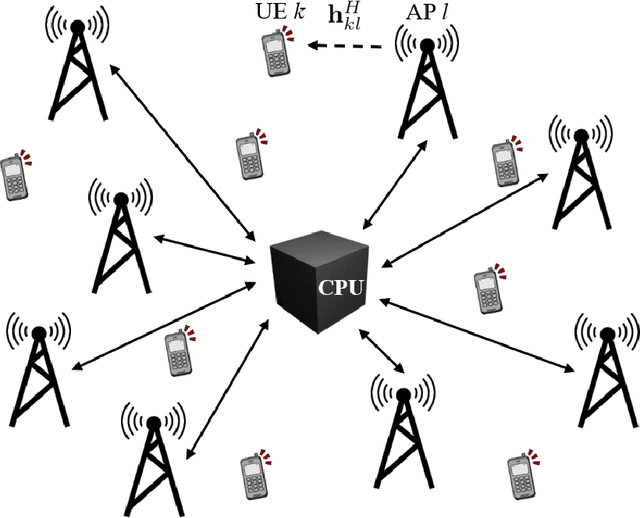
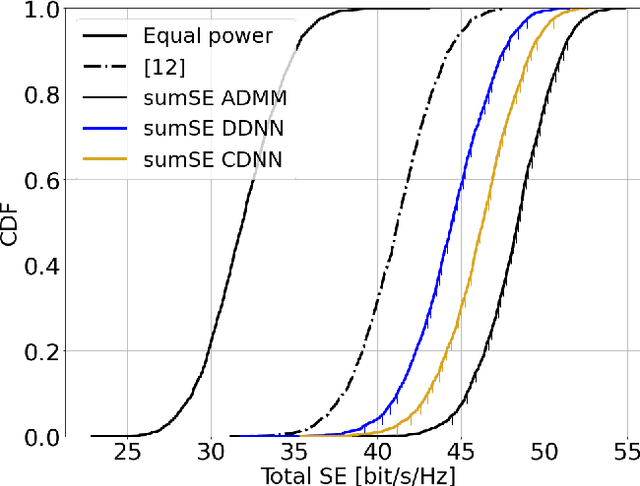
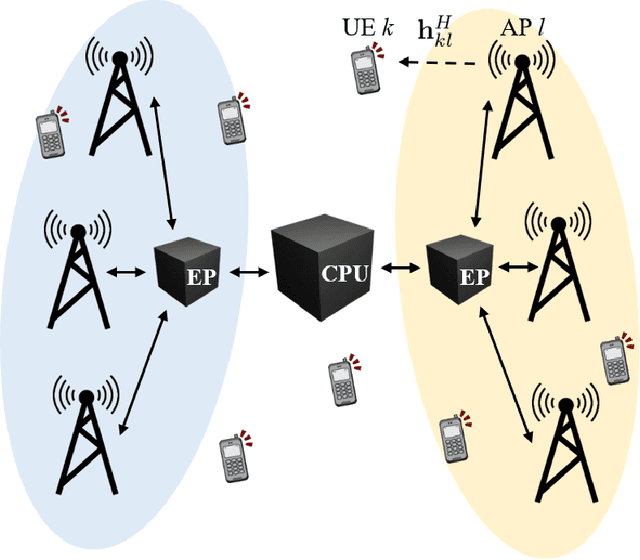
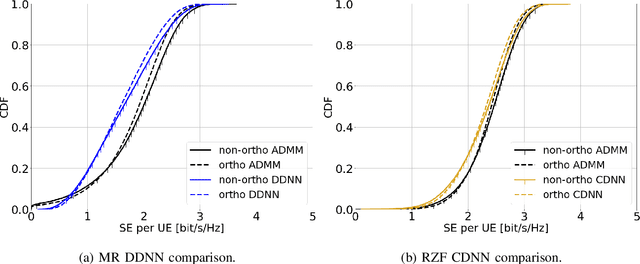
This paper considers a cell-free massive multiple-input multiple-output (MIMO) system that consists of a large number of geographically distributed access points (APs) serving multiple users via coherent joint transmission. The downlink performance of the system is evaluated, with maximum ratio and regularized zero-forcing precoding, under two optimization objectives for power allocation: sum spectral efficiency (SE) maximization and proportional fairness. We present iterative centralized algorithms for solving these problems. Aiming at a less computationally complex and also distributed scalable solution, we train a deep neural network (DNN) to approximate the same network-wide power allocation. Instead of training our DNN to mimic the actual optimization procedure, we use a heuristic power allocation, based on large-scale fading (LSF) parameters, as the pre-processed input to the DNN. We train the DNN to refine the heuristic scheme, thereby providing higher SE, using only local information at each AP. Another distributed DNN that exploits side information assumed to be available at the central processing unit is designed for improved performance. Further, we develop a clustered DNN model where the LSF parameters of a small number of APs, forming a cluster within a relatively large network, are used to jointly approximate the power coefficients of the cluster.
Nonparanormal Information Estimation
Feb 24, 2017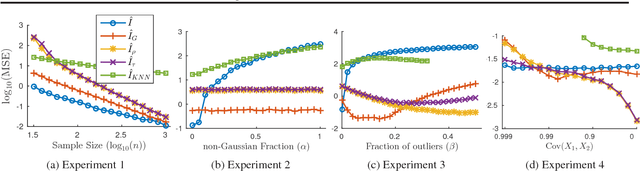
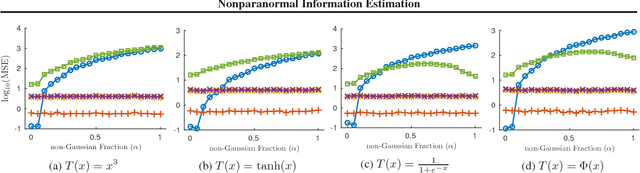
We study the problem of using i.i.d. samples from an unknown multivariate probability distribution $p$ to estimate the mutual information of $p$. This problem has recently received attention in two settings: (1) where $p$ is assumed to be Gaussian and (2) where $p$ is assumed only to lie in a large nonparametric smoothness class. Estimators proposed for the Gaussian case converge in high dimensions when the Gaussian assumption holds, but are brittle, failing dramatically when $p$ is not Gaussian. Estimators proposed for the nonparametric case fail to converge with realistic sample sizes except in very low dimensions. As a result, there is a lack of robust mutual information estimators for many realistic data. To address this, we propose estimators for mutual information when $p$ is assumed to be a nonparanormal (a.k.a., Gaussian copula) model, a semiparametric compromise between Gaussian and nonparametric extremes. Using theoretical bounds and experiments, we show these estimators strike a practical balance between robustness and scaling with dimensionality.
LSTA-Net: Long short-term Spatio-Temporal Aggregation Network for Skeleton-based Action Recognition
Nov 01, 2021
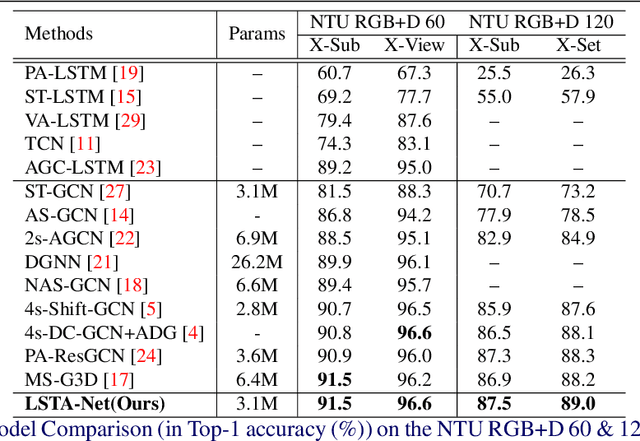


Modelling various spatio-temporal dependencies is the key to recognising human actions in skeleton sequences. Most existing methods excessively relied on the design of traversal rules or graph topologies to draw the dependencies of the dynamic joints, which is inadequate to reflect the relationships of the distant yet important joints. Furthermore, due to the locally adopted operations, the important long-range temporal information is therefore not well explored in existing works. To address this issue, in this work we propose LSTA-Net: a novel Long short-term Spatio-Temporal Aggregation Network, which can effectively capture the long/short-range dependencies in a spatio-temporal manner. We devise our model into a pure factorised architecture which can alternately perform spatial feature aggregation and temporal feature aggregation. To improve the feature aggregation effect, a channel-wise attention mechanism is also designed and employed. Extensive experiments were conducted on three public benchmark datasets, and the results suggest that our approach can capture both long-and-short range dependencies in the space and time domain, yielding higher results than other state-of-the-art methods. Code available at https://github.com/tailin1009/LSTA-Net.
Evaluation of Hyperparameter-Optimization Approaches in an Industrial Federated Learning System
Oct 20, 2021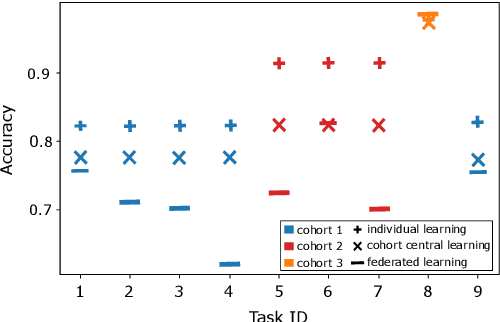
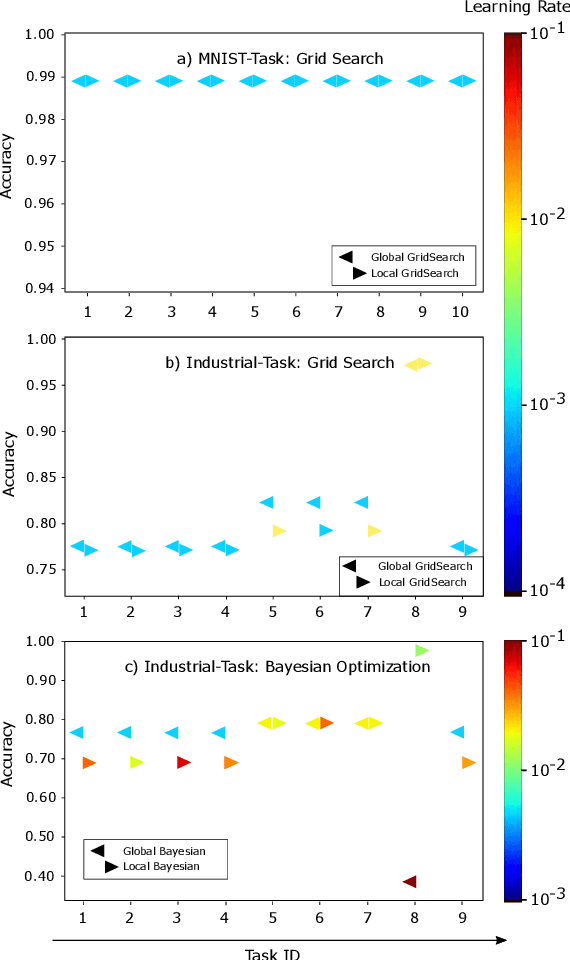
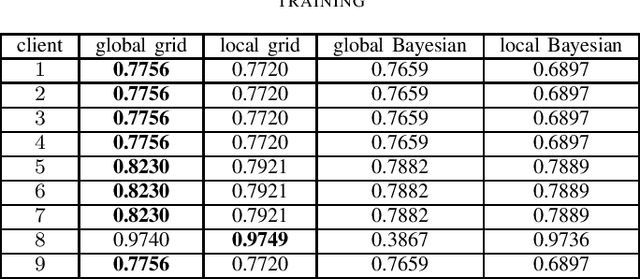
Federated Learning (FL) decouples model training from the need for direct access to the data and allows organizations to collaborate with industry partners to reach a satisfying level of performance without sharing vulnerable business information. The performance of a machine learning algorithm is highly sensitive to the choice of its hyperparameters. In an FL setting, hyperparameter optimization poses new challenges. In this work, we investigated the impact of different hyperparameter optimization approaches in an FL system. In an effort to reduce communication costs, a critical bottleneck in FL, we investigated a local hyperparameter optimization approach that -- in contrast to a global hyperparameter optimization approach -- allows every client to have its own hyperparameter configuration. We implemented these approaches based on grid search and Bayesian optimization and evaluated the algorithms on the MNIST data set using an i.i.d. partition and on an Internet of Things (IoT) sensor based industrial data set using a non-i.i.d. partition.
Learning protein sequence embeddings using information from structure
Feb 22, 2019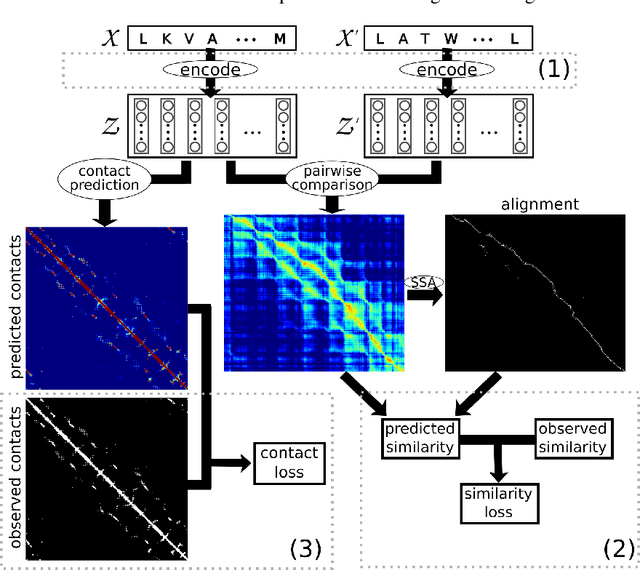
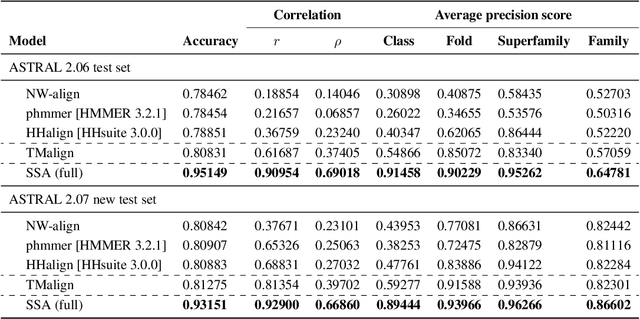
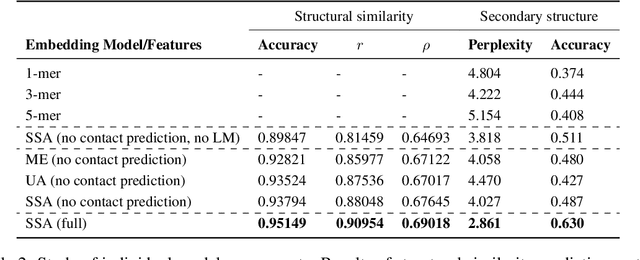
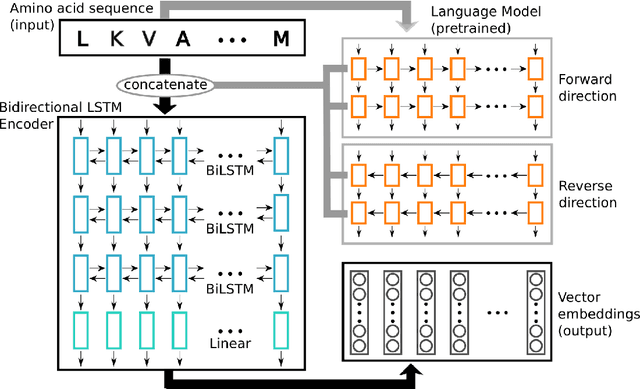
Inferring the structural properties of a protein from its amino acid sequence is a challenging yet important problem in biology. Structures are not known for the vast majority of protein sequences, but structure is critical for understanding function. Existing approaches for detecting structural similarity between proteins from sequence are unable to recognize and exploit structural patterns when sequences have diverged too far, limiting our ability to transfer knowledge between structurally related proteins. We newly approach this problem through the lens of representation learning. We introduce a framework that maps any protein sequence to a sequence of vector embeddings --- one per amino acid position --- that encode structural information. We train bidirectional long short-term memory (LSTM) models on protein sequences with a two-part feedback mechanism that incorporates information from (i) global structural similarity between proteins and (ii) pairwise residue contact maps for individual proteins. To enable learning from structural similarity information, we define a novel similarity measure between arbitrary-length sequences of vector embeddings based on a soft symmetric alignment (SSA) between them. Our method is able to learn useful position-specific embeddings despite lacking direct observations of position-level correspondence between sequences. We show empirically that our multi-task framework outperforms other sequence-based methods and even a top-performing structure-based alignment method when predicting structural similarity, our goal. Finally, we demonstrate that our learned embeddings can be transferred to other protein sequence problems, improving the state-of-the-art in transmembrane domain prediction.
* 17 pages, 3 figures, 8 tables, proceedings of ICLR 2019