 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Query-based Adversarial Attacks on Graph with Fake Nodes
Sep 27, 2021
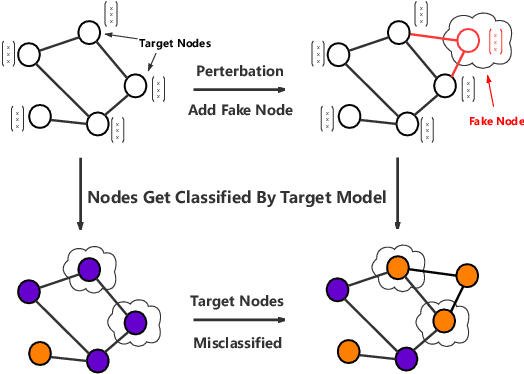
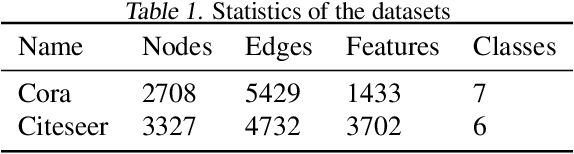
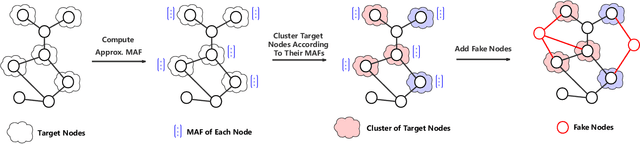
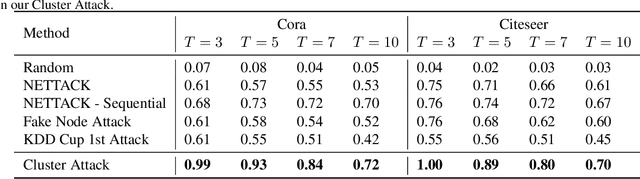
While deep neural networks have achieved great success on the graph analysis, recent works have shown that they are also vulnerable to adversarial attacks where fraudulent users can fool the model with a limited number of queries. Compared with adversarial attacks on image classification, performing adversarial attack on graphs is challenging because of the discrete and non-differential nature of a graph. To address these issues, we proposed Cluster Attack, a novel adversarial attack by introducing a set of fake nodes to the original graph which can mislead the classification on certain victim nodes. Specifically, we query the victim model for each victim node to acquire their most adversarial feature, which is related to how the fake node's feature will affect the victim nodes. We further cluster the victim nodes into several subgroups according to their most adversarial features such that we can reduce the searching space. Moreover, our attack is performed in a practical and unnoticeable manner: (1) We protect the predicted labels of nodes which we are not aimed for from being changed during attack. (2) We attack by introducing fake nodes into the original graph without changing existing links and features. (3) We attack with only partial information about the attacked graph, i.e., by leveraging the information of victim nodes along with their neighbors within $k$-hop instead of the whole graph. (4) We perform attack with a limited number of queries about the predicted scores of the model in a black-box manner, i.e., without model architecture and parameters. Extensive experiments demonstrate the effectiveness of our method in terms of the success rate of attack.
LayoutReader: Pre-training of Text and Layout for Reading Order Detection
Aug 27, 2021
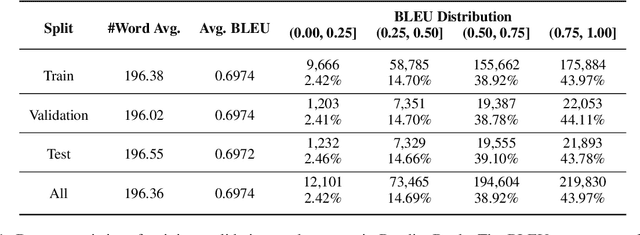
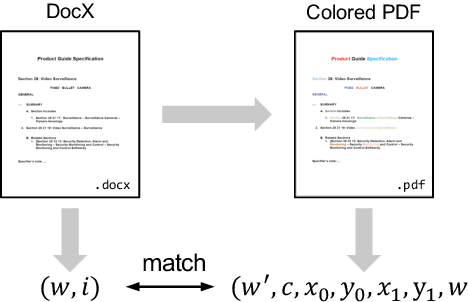

Reading order detection is the cornerstone to understanding visually-rich documents (e.g., receipts and forms). Unfortunately, no existing work took advantage of advanced deep learning models because it is too laborious to annotate a large enough dataset. We observe that the reading order of WORD documents is embedded in their XML metadata; meanwhile, it is easy to convert WORD documents to PDFs or images. Therefore, in an automated manner, we construct ReadingBank, a benchmark dataset that contains reading order, text, and layout information for 500,000 document images covering a wide spectrum of document types. This first-ever large-scale dataset unleashes the power of deep neural networks for reading order detection. Specifically, our proposed LayoutReader captures the text and layout information for reading order prediction using the seq2seq model. It performs almost perfectly in reading order detection and significantly improves both open-source and commercial OCR engines in ordering text lines in their results in our experiments. We will release the dataset and model at \url{https://aka.ms/layoutreader}.
Learning Sense-Specific Static Embeddings using Contextualised Word Embeddings as a Proxy
Oct 06, 2021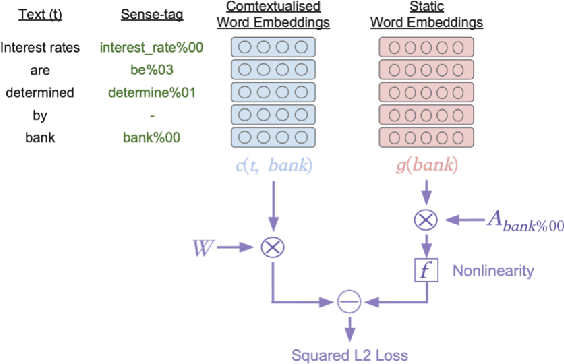
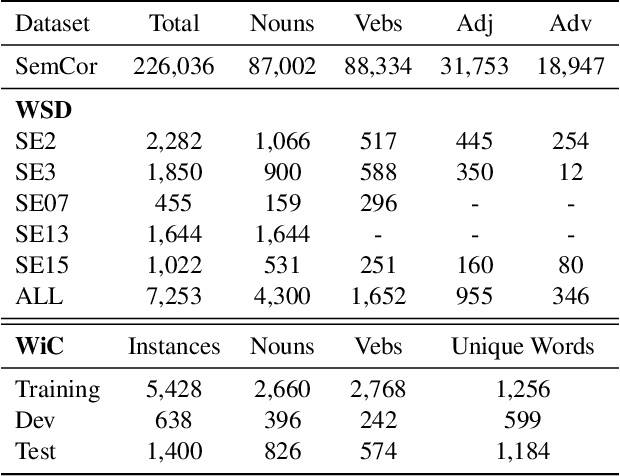
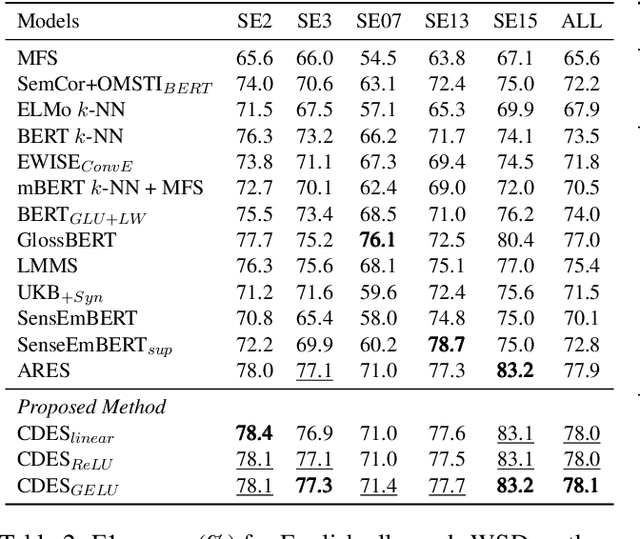
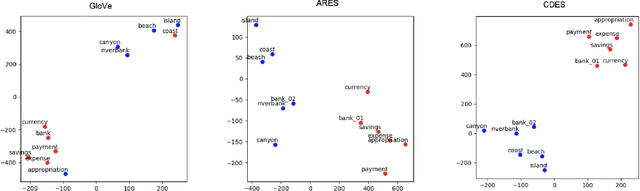
Contextualised word embeddings generated from Neural Language Models (NLMs), such as BERT, represent a word with a vector that considers the semantics of the target word as well its context. On the other hand, static word embeddings such as GloVe represent words by relatively low-dimensional, memory- and compute-efficient vectors but are not sensitive to the different senses of the word. We propose Context Derived Embeddings of Senses (CDES), a method that extracts sense related information from contextualised embeddings and injects it into static embeddings to create sense-specific static embeddings. Experimental results on multiple benchmarks for word sense disambiguation and sense discrimination tasks show that CDES can accurately learn sense-specific static embeddings reporting comparable performance to the current state-of-the-art sense embeddings.
Mutual Information Maximization on Disentangled Representations for Differential Morph Detection
Dec 02, 2020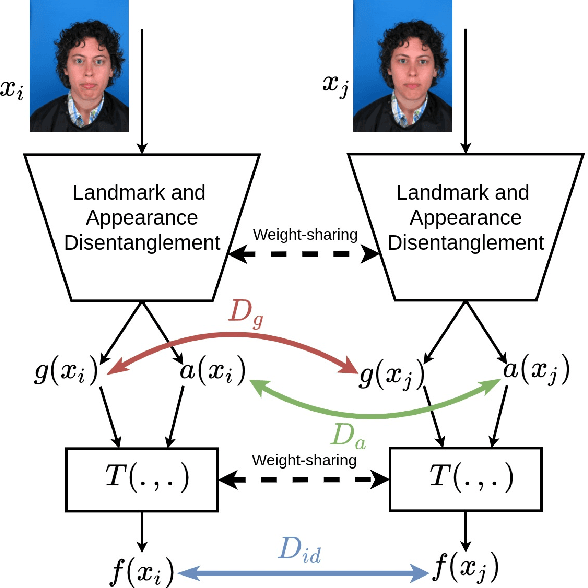
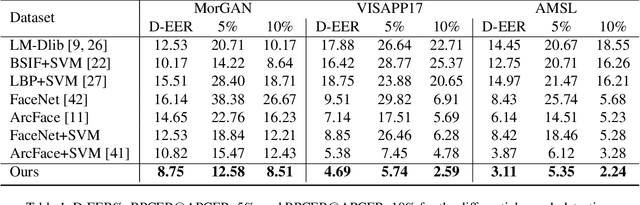
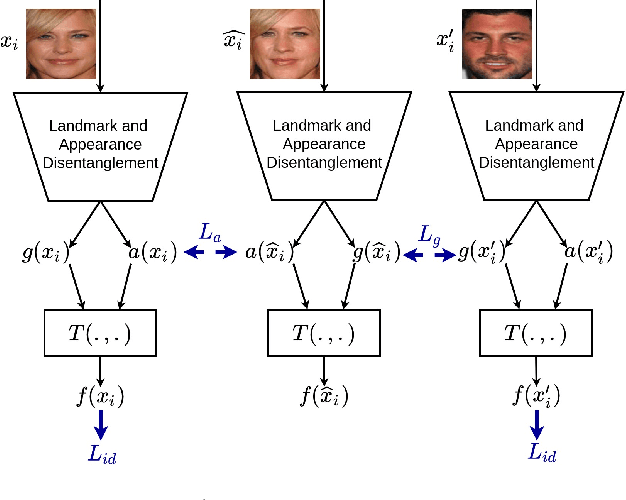
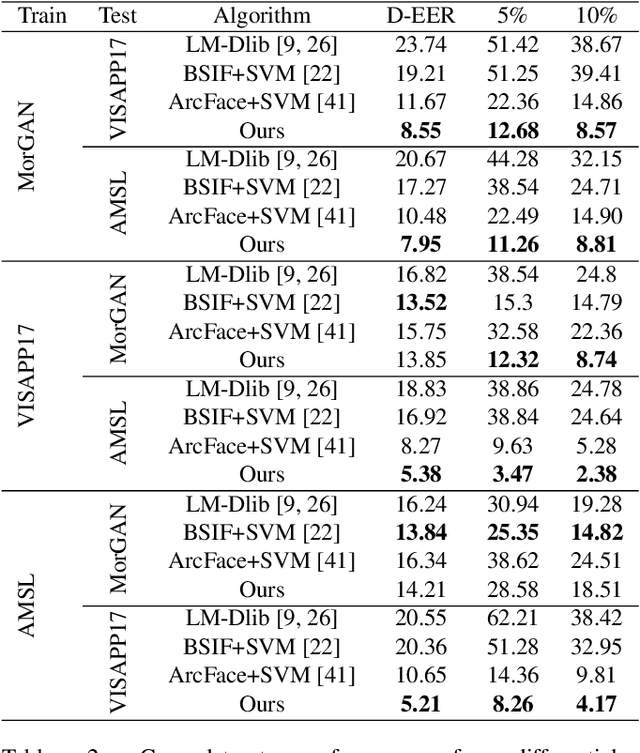
In this paper, we present a novel differential morph detection framework, utilizing landmark and appearance disentanglement. In our framework, the face image is represented in the embedding domain using two disentangled but complementary representations. The network is trained by triplets of face images, in which the intermediate image inherits the landmarks from one image and the appearance from the other image. This initially trained network is further trained for each dataset using contrastive representations. We demonstrate that, by employing appearance and landmark disentanglement, the proposed framework can provide state-of-the-art differential morph detection performance. This functionality is achieved by the using distances in landmark, appearance, and ID domains. The performance of the proposed framework is evaluated using three morph datasets generated with different methodologies.
Action Anticipation for Collaborative Environments: The Impact of Contextual Information and Uncertainty-Based Prediction
Oct 01, 2019
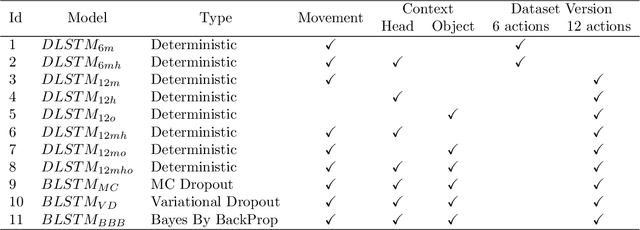

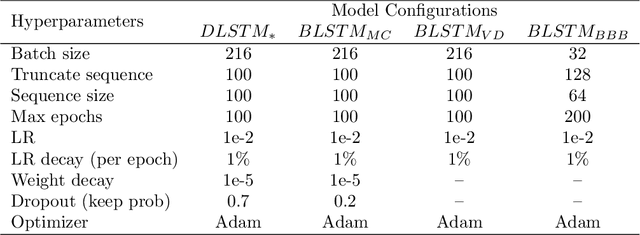
For effectively interacting with humans in collaborative environments, machines need to be able anticipate future events, in order to execute actions in a timely manner. However, the observation of the human limbs movements may not be sufficient to anticipate their actions in an unambiguous manner. In this work we consider two additional sources of information (i.e. context) over time, gaze movements and object information, and study how these additional contextual cues improve the action anticipation performance. We address action anticipation as a classification task, where the model takes the available information as the input, and predicts the most likely action. We propose to use the uncertainty about each prediction as an online decision-making criterion for action anticipation. Uncertainty is modeled as a stochastic process applied to a time-based neural network architecture, which improves the conventional class-likelihood (i.e. deterministic) criterion. The main contributions of this paper are three-fold: (i) we propose a deep architecture that outperforms previous results in the action anticipation task; (ii) we show that contextual information is important do disambiguate the interpretation of similar actions; (iii) we propose the minimization of uncertainty as a more effective criterion for action anticipation, when compared with the maximization of class probability. Our results on the Acticipate dataset showed the importance of contextual information and the uncertainty criterion for action anticipation. We achieve an average accuracy of 98.75% in the anticipation task using only an average of 25% of observations. In addition, considering that a good anticipation model should also perform well in the action recognition task, we achieve an average accuracy of 100% in action recognition on the Acticipate dataset, when the entire observation set is used.
Unsupervised Part Discovery from Contrastive Reconstruction
Nov 11, 2021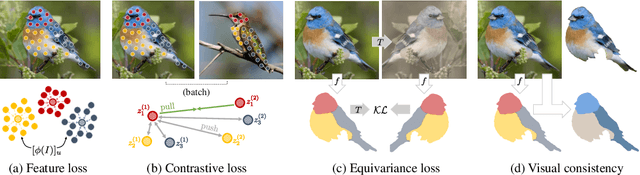
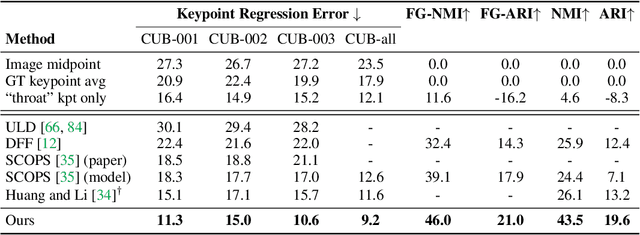

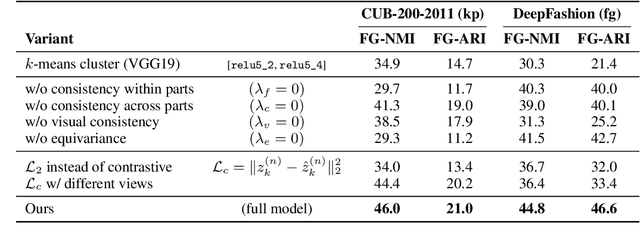
The goal of self-supervised visual representation learning is to learn strong, transferable image representations, with the majority of research focusing on object or scene level. On the other hand, representation learning at part level has received significantly less attention. In this paper, we propose an unsupervised approach to object part discovery and segmentation and make three contributions. First, we construct a proxy task through a set of objectives that encourages the model to learn a meaningful decomposition of the image into its parts. Secondly, prior work argues for reconstructing or clustering pre-computed features as a proxy to parts; we show empirically that this alone is unlikely to find meaningful parts; mainly because of their low resolution and the tendency of classification networks to spatially smear out information. We suggest that image reconstruction at the level of pixels can alleviate this problem, acting as a complementary cue. Lastly, we show that the standard evaluation based on keypoint regression does not correlate well with segmentation quality and thus introduce different metrics, NMI and ARI, that better characterize the decomposition of objects into parts. Our method yields semantic parts which are consistent across fine-grained but visually distinct categories, outperforming the state of the art on three benchmark datasets. Code is available at the project page: https://www.robots.ox.ac.uk/~vgg/research/unsup-parts/.
Improving Real-time Score Following in Opera by Combining Music with Lyrics Tracking
Oct 06, 2021
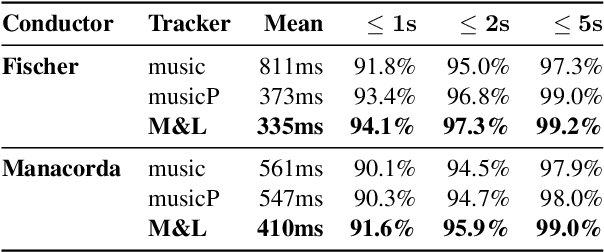
Fully automatic opera tracking is challenging because of the acoustic complexity of the genre, combining musical and linguistic information (singing, speech) in complex ways. In this paper, we propose a new pipeline for complete opera tracking. The pipeline is based on two trackers. A music tracker that has proven to be effective at tracking orchestral parts, will lead the tracking process. In addition, a lyrics tracker, that has recently been shown to reliably track the lyrics of opera songs, will correct the music tracker when tracking parts that have a text dominance over the music. We will demonstrate the efficiency of this method on the opera Don Giovanni, showing that this technique helps improving accuracy and robustness of a complete opera tracker.
Leveraging Low-Distortion Target Estimates for Improved Speech Enhancement
Oct 01, 2021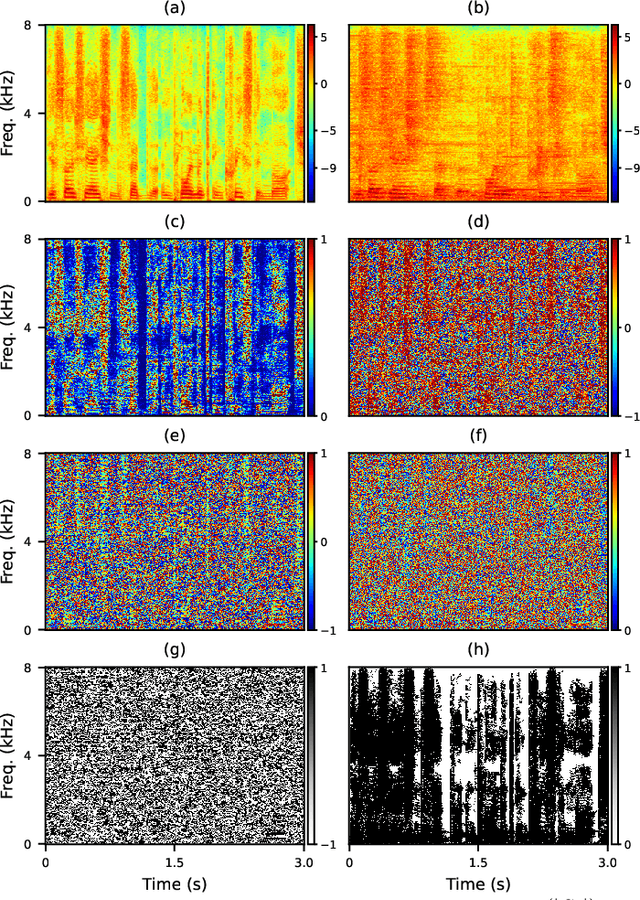
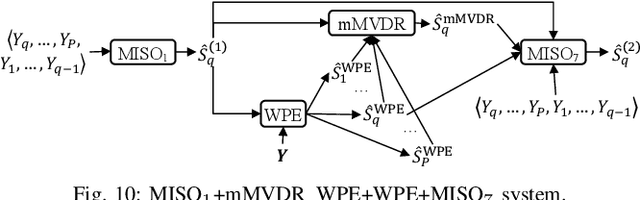
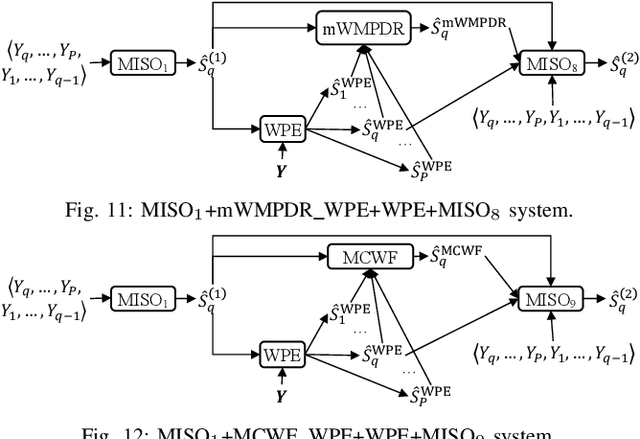
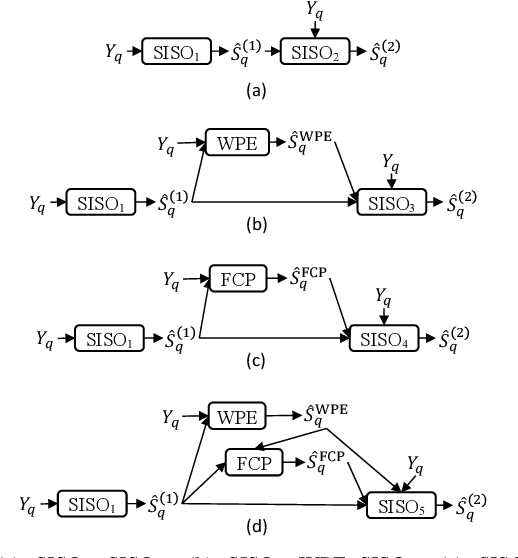
A promising approach for multi-microphone speech separation involves two deep neural networks (DNN), where the predicted target speech from the first DNN is used to compute signal statistics for time-invariant minimum variance distortionless response (MVDR) beamforming, and the MVDR result is then used as extra features for the second DNN to predict target speech. Previous studies suggested that the MVDR result can provide complementary information for the second DNN to better predict target speech. However, on fixed-geometry arrays, both DNNs can take in, for example, the real and imaginary (RI) components of the multi-channel mixture as features to leverage the spatial and spectral information for enhancement. It is not explained clearly why the linear MVDR result can be complementary and why it is still needed, considering that the DNNs and the beamformer use the same input, and the DNNs perform non-linear filtering and could render the linear filtering of MVDR unnecessary. Similarly, in monaural cases, one can replace the MVDR beamformer with a monaural weighted prediction error (WPE) filter. Although the linear WPE filter and the DNNs use the same mixture RI components as input, the WPE result is found to significantly improve the second DNN. This study provides a novel explanation from the perspective of the low-distortion nature of such algorithms, and finds that they can consistently improve phase estimation. Equipped with this understanding, we investigate several low-distortion target estimation algorithms including several beamformers, WPE, forward convolutive prediction, and their combinations, and use their results as extra features to train the second network to achieve better enhancement. Evaluation results on single- and multi-microphone speech dereverberation and enhancement tasks indicate the effectiveness of the proposed approach, and the validity of the proposed view.
Environmental Information Improves Robotic Search Performance
Jun 22, 2018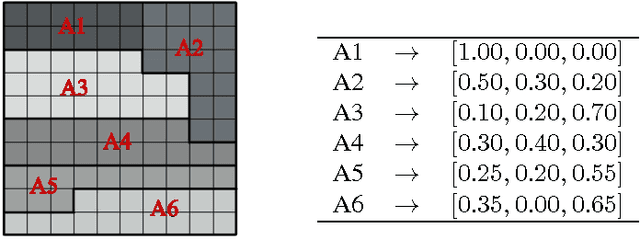
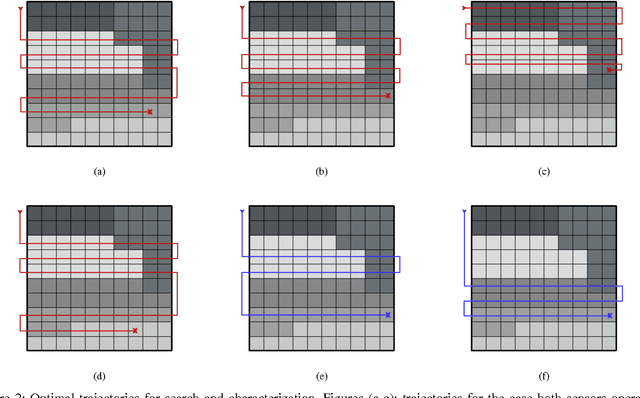
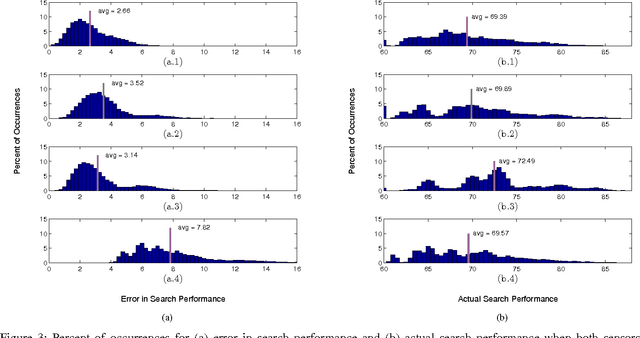
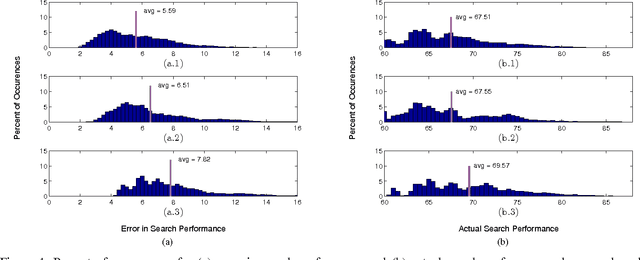
We address the problem where a mobile search agent seeks to find an unknown number of stationary objects distributed in a bounded search domain, and the search mission is subject to time/distance constraint. Our work accounts for false positives, false negatives and environmental uncertainty. We consider the case that the performance of a search sensor is dependent on the environment (e.g., clutter density), and therefore sensor performance is better in some locations than in others. We specifically consider applications where environmental information can be acquired either by a separate vehicle or by the same vehicle that performs the search task. Our main contribution in this study is to formally derive a decision-theoretic cost function to compute the locations where the environmental information should be acquired. For the cases where computing the optimal locations to sample the environment is computationally expensive, we offer an approximation approach that yields provable near-optimal paths. We show that our decision-theoretic cost function outperforms the information-maximization approach, which is often employed in similar applications.
Developing Products Update-Alert System for e-Commerce Websites Users Using HTML Data and Web Scraping Technique
Sep 02, 2021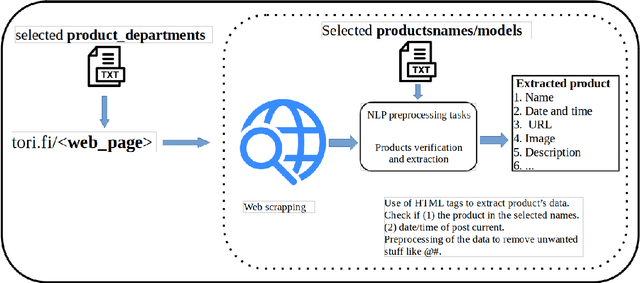

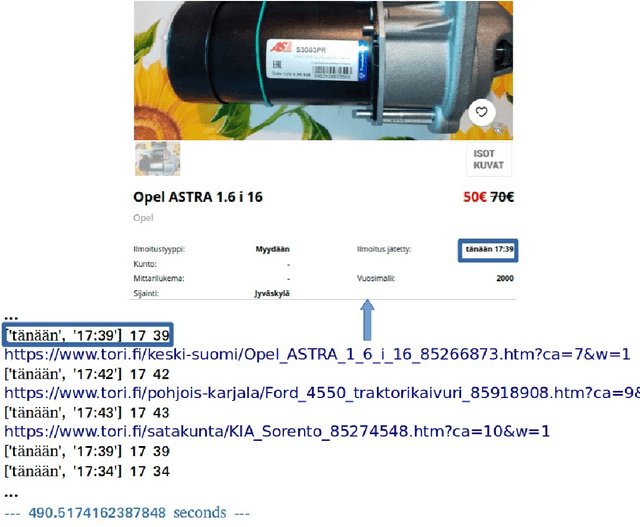
Websites are regarded as domains of limitless information which anyone and everyone can access. The new trend of technology put us to change the way we are doing our business. The Internet now is fastly becoming a new place for business and the advancement in this technology gave rise to the number of e-commerce websites. This made the lifestyle of marketers/vendors, retailers and consumers (collectively regarded as users in this paper) easy, because it provides easy platforms to sale/order items through the internet. This also requires that the users will have to spend a lot of time and effort to search for the best product deals, products updates and offers on e-commerce websites. They have to filter and compare search results by themselves which takes a lot of time and there are chances of ambiguous results. In this paper, we applied web crawling and scraping methods on an e-commerce website to get HTML data for identifying products updates based on the current time. The HTML data is preprocessed to extract details of the products such as name, price, post date and time, etc. to serve as useful information for users.
* 6 pages, 3 figures, 1 table, IJNLC Journal