 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Investigating Tradeoffs in Real-World Video Super-Resolution
Nov 24, 2021
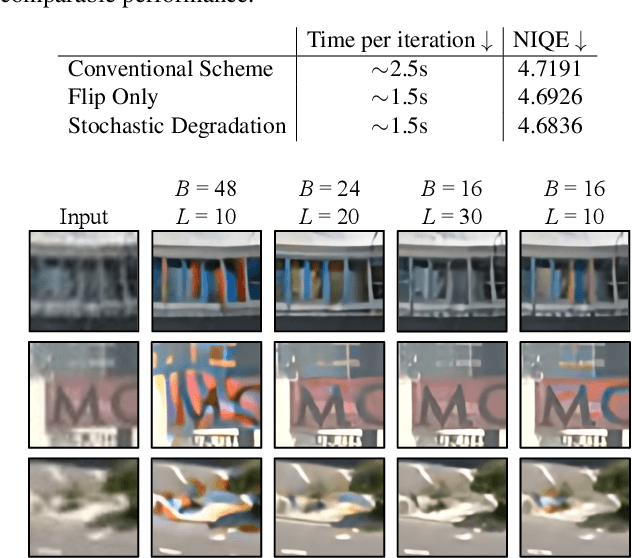


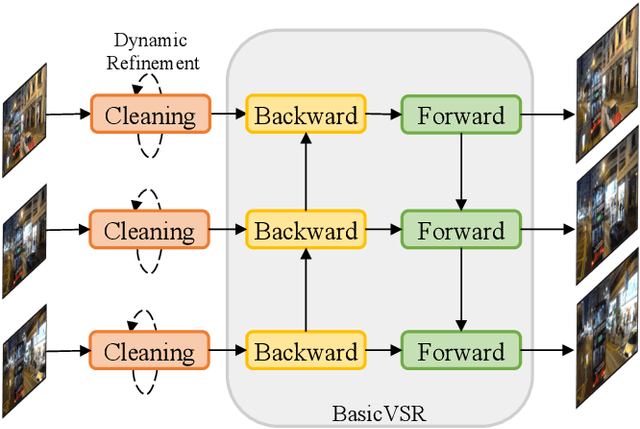
The diversity and complexity of degradations in real-world video super-resolution (VSR) pose non-trivial challenges in inference and training. First, while long-term propagation leads to improved performance in cases of mild degradations, severe in-the-wild degradations could be exaggerated through propagation, impairing output quality. To balance the tradeoff between detail synthesis and artifact suppression, we found an image pre-cleaning stage indispensable to reduce noises and artifacts prior to propagation. Equipped with a carefully designed cleaning module, our RealBasicVSR outperforms existing methods in both quality and efficiency. Second, real-world VSR models are often trained with diverse degradations to improve generalizability, requiring increased batch size to produce a stable gradient. Inevitably, the increased computational burden results in various problems, including 1) speed-performance tradeoff and 2) batch-length tradeoff. To alleviate the first tradeoff, we propose a stochastic degradation scheme that reduces up to 40\% of training time without sacrificing performance. We then analyze different training settings and suggest that employing longer sequences rather than larger batches during training allows more effective uses of temporal information, leading to more stable performance during inference. To facilitate fair comparisons, we propose the new VideoLQ dataset, which contains a large variety of real-world low-quality video sequences containing rich textures and patterns. Our dataset can serve as a common ground for benchmarking. Code, models, and the dataset will be made publicly available.
LAnoBERT : System Log Anomaly Detection based on BERT Masked Language Model
Nov 20, 2021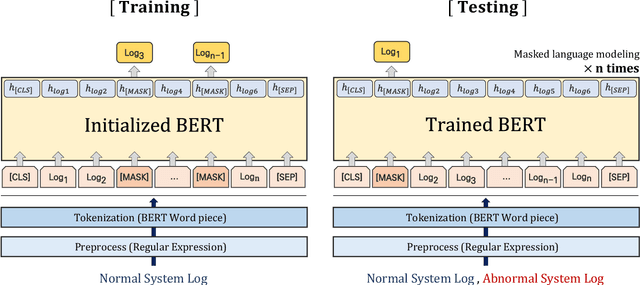
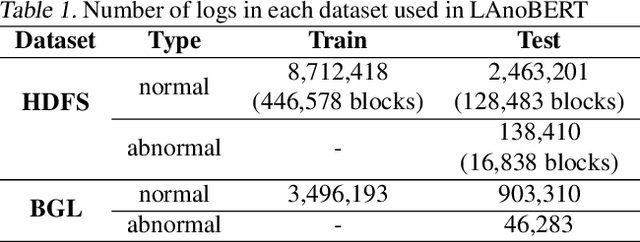


The system log generated in a computer system refers to large-scale data that are collected simultaneously and used as the basic data for determining simple errors and detecting external adversarial intrusion or the abnormal behaviors of insiders. The aim of system log anomaly detection is to promptly identify anomalies while minimizing human intervention, which is a critical problem in the industry. Previous studies performed anomaly detection through algorithms after converting various forms of log data into a standardized template using a parser. These methods involved generating a template for refining the log key. Particularly, a template corresponding to a specific event should be defined in advance for all the log data using which the information within the log key may get lost.In this study, we propose LAnoBERT, a parser free system log anomaly detection method that uses the BERT model, exhibiting excellent natural language processing performance. The proposed method, LAnoBERT, learns the model through masked language modeling, which is a BERT-based pre-training method, and proceeds with unsupervised learning-based anomaly detection using the masked language modeling loss function per log key word during the inference process. LAnoBERT achieved better performance compared to previous methodology in an experiment conducted using benchmark log datasets, HDFS, and BGL, and also compared to certain supervised learning-based models.
Radio Sensing with Large Intelligent Surface for 6G
Nov 04, 2021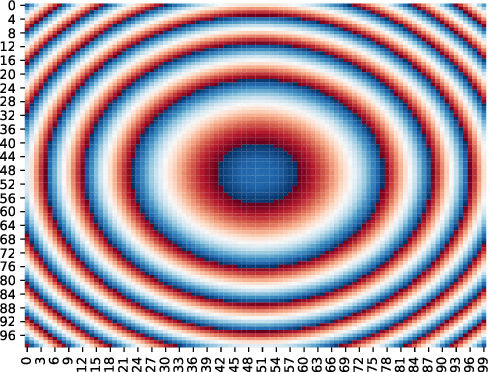
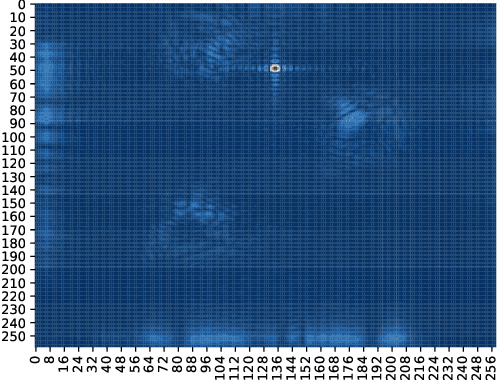


This paper leverages the potential of Large Intelligent Surface (LIS) for radio sensing in 6G wireless networks. Major research has been undergone about its communication capabilities but it can be exploited as a formidable tool for radio sensing. By taking advantage of arbitrary communication signals occurring in the scenario, we apply a Matched Filtering (MF) processing to the output signal from the LIS to obtain a radio map that describes the physical presence of passive devices (scatterers, humans) which act as virtual sources due to the communication signal reflections. We then assess the usage of machine learning (k-means clustering), image processing and computer vision (template matching and component labeling) to extract meaningful information from these radio maps. As an exemplary use case, we evaluate this method for both active and passive user detection in an indoor setting. The results show that the presented method has high application potential as we are able to detect around 98% of humans passively and 100% active users by just using communication signals of commodity devices even in quite unfavorable Signal-to-Noise Ratio (SNR) conditions.
Joint Direction and Proximity Classification of Overlapping Sound Events from Binaural Audio
Jul 26, 2021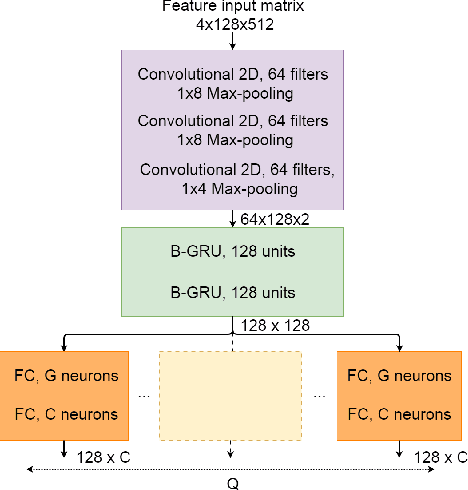
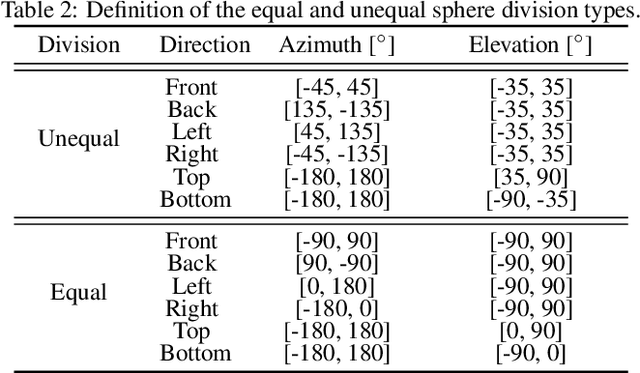
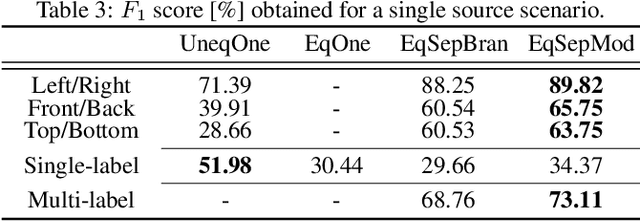
Sound source proximity and distance estimation are of great interest in many practical applications, since they provide significant information for acoustic scene analysis. As both tasks share complementary qualities, ensuring efficient interaction between these two is crucial for a complete picture of an aural environment. In this paper, we aim to investigate several ways of performing joint proximity and direction estimation from binaural recordings, both defined as coarse classification problems based on Deep Neural Networks (DNNs). Considering the limitations of binaural audio, we propose two methods of splitting the sphere into angular areas in order to obtain a set of directional classes. For each method we study different model types to acquire information about the direction-of-arrival (DoA). Finally, we propose various ways of combining the proximity and direction estimation problems into a joint task providing temporal information about the onsets and offsets of the appearing sources. Experiments are performed for a synthetic reverberant binaural dataset consisting of up to two overlapping sound events.
Layer-wise Analysis of a Self-supervised Speech Representation Model
Jul 10, 2021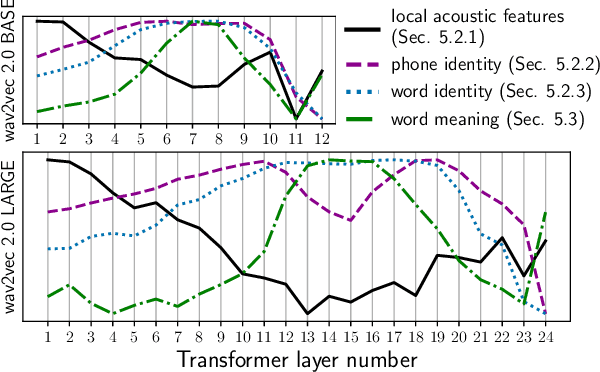
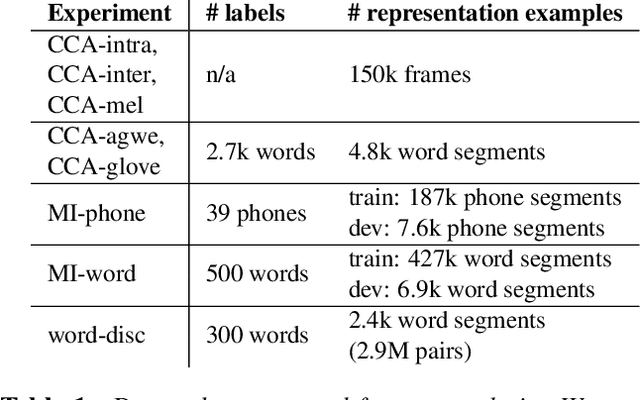
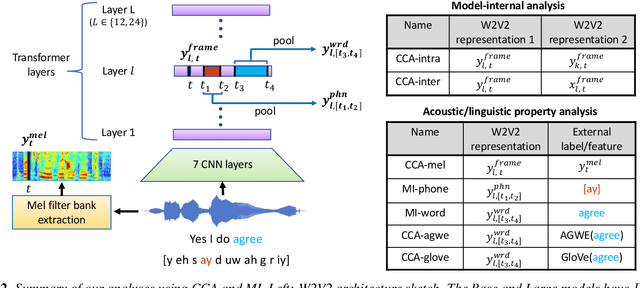

Recently proposed self-supervised learning approaches have been successful for pre-training speech representation models. The utility of these learned representations has been observed empirically, but not much has been studied about the type or extent of information encoded in the pre-trained representations themselves. Developing such insights can help understand the capabilities and limits of these models and enable the research community to more efficiently develop their usage for downstream applications. In this work, we begin to fill this gap by examining one recent and successful pre-trained model (wav2vec 2.0), via its intermediate representation vectors, using a suite of analysis tools. We use the metrics of canonical correlation, mutual information, and performance on simple downstream tasks with non-parametric probes, in order to (i) query for acoustic and linguistic information content, (ii) characterize the evolution of information across model layers, and (iii) understand how fine-tuning the model for automatic speech recognition (ASR) affects these observations. Our findings motivate modifying the fine-tuning protocol for ASR, which produces improved word error rates in a low-resource setting.
Utterance-level neural confidence measure for end-to-end children speech recognition
Sep 16, 2021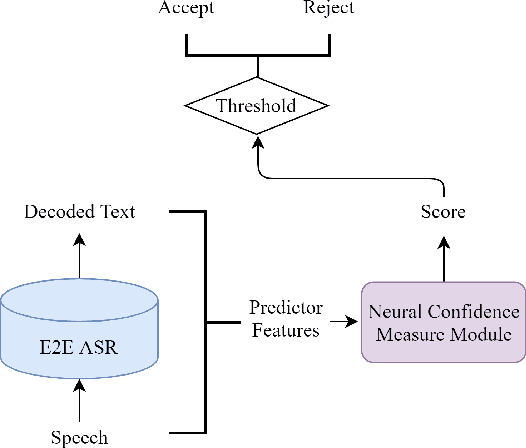
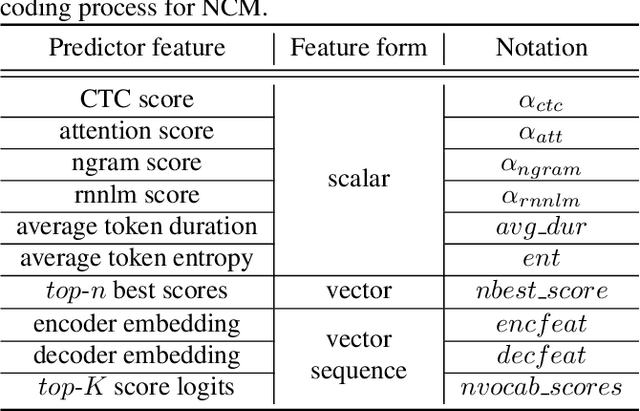
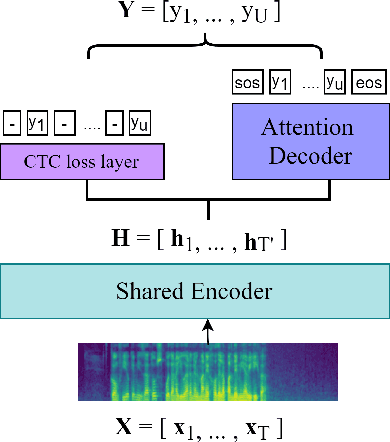
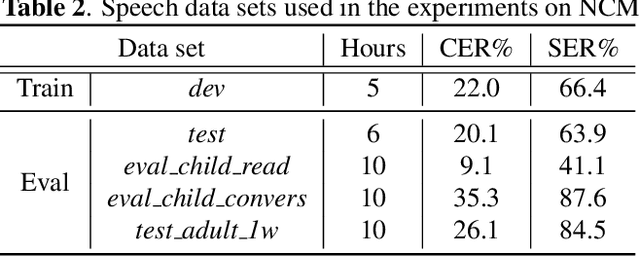
Confidence measure is a performance index of particular importance for automatic speech recognition (ASR) systems deployed in real-world scenarios. In the present study, utterance-level neural confidence measure (NCM) in end-to-end automatic speech recognition (E2E ASR) is investigated. The E2E system adopts the joint CTC-attention Transformer architecture. The prediction of NCM is formulated as a task of binary classification, i.e., accept/reject the input utterance, based on a set of predictor features acquired during the ASR decoding process. The investigation is focused on evaluating and comparing the efficacies of predictor features that are derived from different internal and external modules of the E2E system. Experiments are carried out on children speech, for which state-of-the-art ASR systems show less than satisfactory performance and robust confidence measure is particularly useful. It is noted that predictor features related to acoustic information of speech play a more important role in estimating confidence measure than those related to linguistic information. N-best score features show significantly better performance than single-best ones. It has also been shown that the metrics of EER and AUC are not appropriate to evaluate the NCM of a mismatched ASR with significant performance gap.
Cross-layer Navigation Convolutional Neural Network for Fine-grained Visual Classification
Jun 21, 2021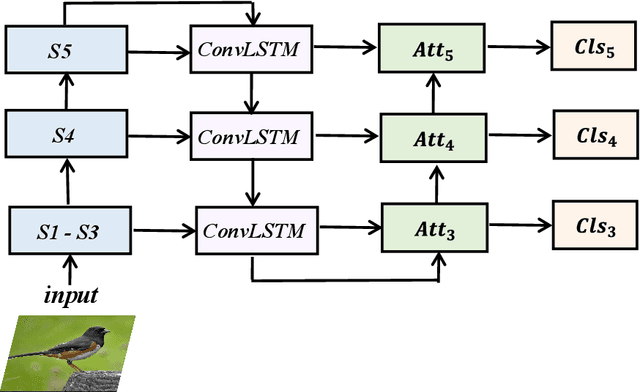
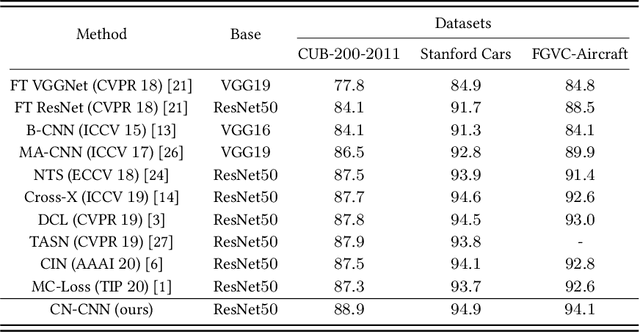
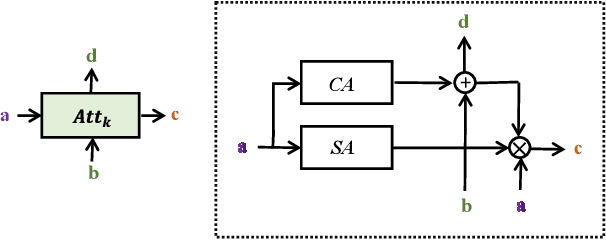

Fine-grained visual classification (FGVC) aims to classify sub-classes of objects in the same super-class (e.g., species of birds, models of cars). For the FGVC tasks, the essential solution is to find discriminative subtle information of the target from local regions. TraditionalFGVC models preferred to use the refined features,i.e., high-level semantic information for recognition and rarely use low-level in-formation. However, it turns out that low-level information which contains rich detail information also has effect on improving performance. Therefore, in this paper, we propose cross-layer navigation convolutional neural network for feature fusion. First, the feature maps extracted by the backbone network are fed into a convolutional long short-term memory model sequentially from high-level to low-level to perform feature aggregation. Then, attention mechanisms are used after feature fusion to extract spatial and channel information while linking the high-level semantic information and the low-level texture features, which can better locate the discriminative regions for the FGVC. In the experiments, three commonly used FGVC datasets, including CUB-200-2011, Stanford-Cars, andFGVC-Aircraft datasets, are used for evaluation and we demonstrate the superiority of the proposed method by comparing it with other referred FGVC methods to show that this method achieves superior results.
Generating Diverse and Consistent QA pairs from Contexts with Information-Maximizing Hierarchical Conditional VAEs
May 28, 2020
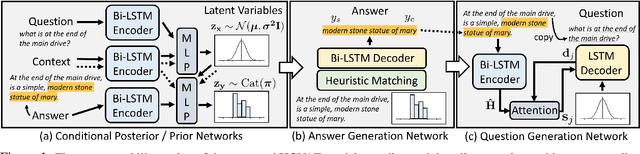
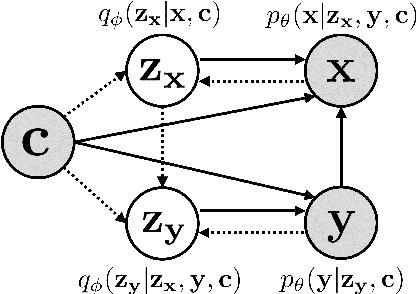
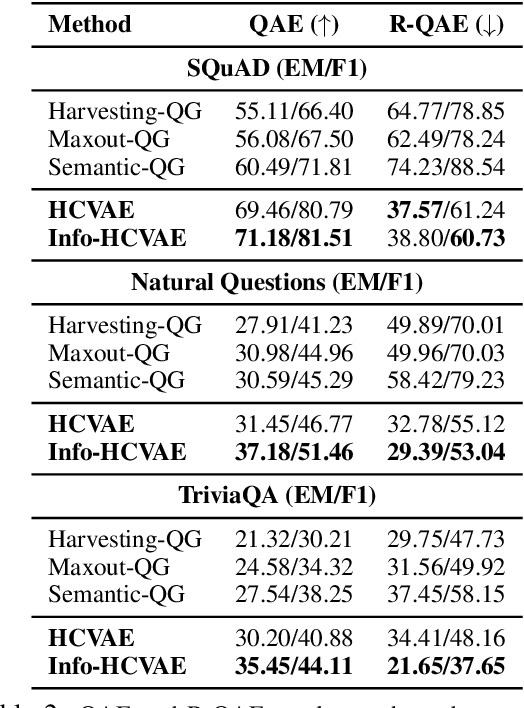
One of the most crucial challenges in questionanswering (QA) is the scarcity of labeled data,since it is costly to obtain question-answer(QA) pairs for a target text domain with human annotation. An alternative approach totackle the problem is to use automatically generated QA pairs from either the problem context or from large amount of unstructured texts(e.g. Wikipedia). In this work, we propose a hierarchical conditional variational autoencoder(HCVAE) for generating QA pairs given unstructured texts as contexts, while maximizingthe mutual information between generated QApairs to ensure their consistency. We validateourInformation MaximizingHierarchicalConditionalVariationalAutoEncoder (Info-HCVAE) on several benchmark datasets byevaluating the performance of the QA model(BERT-base) using only the generated QApairs (QA-based evaluation) or by using boththe generated and human-labeled pairs (semi-supervised learning) for training, against state-of-the-art baseline models. The results showthat our model obtains impressive performance gains over all baselines on both tasks,using only a fraction of data for training
Benign Adversarial Attack: Tricking Algorithm for Goodness
Jul 26, 2021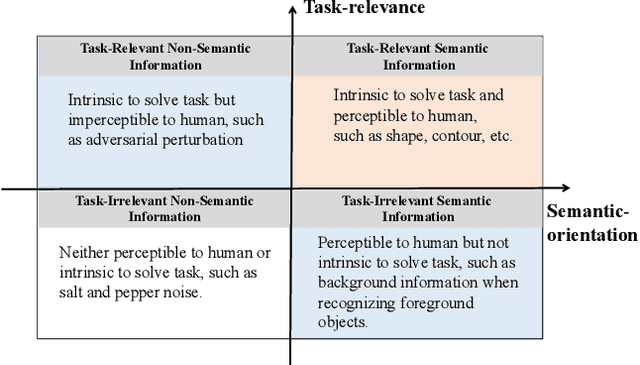
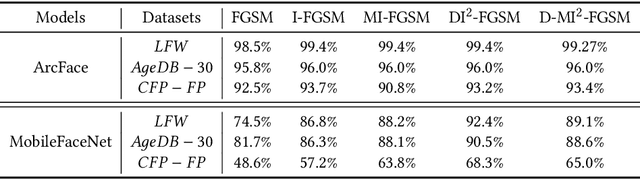


In spite of the successful application in many fields, machine learning algorithms today suffer from notorious problems like vulnerability to adversarial examples. Beyond falling into the cat-and-mouse game between adversarial attack and defense, this paper provides alternative perspective to consider adversarial example and explore whether we can exploit it in benign applications. We first propose a novel taxonomy of visual information along task-relevance and semantic-orientation. The emergence of adversarial example is attributed to algorithm's utilization of task-relevant non-semantic information. While largely ignored in classical machine learning mechanisms, task-relevant non-semantic information enjoys three interesting characteristics as (1) exclusive to algorithm, (2) reflecting common weakness, and (3) utilizable as features. Inspired by this, we present brave new idea called benign adversarial attack to exploit adversarial examples for goodness in three directions: (1) adversarial Turing test, (2) rejecting malicious algorithm, and (3) adversarial data augmentation. Each direction is positioned with motivation elaboration, justification analysis and prototype applications to showcase its potential.
Bursting Scientific Filter Bubbles: Boosting Innovation via Novel Author Discovery
Sep 10, 2021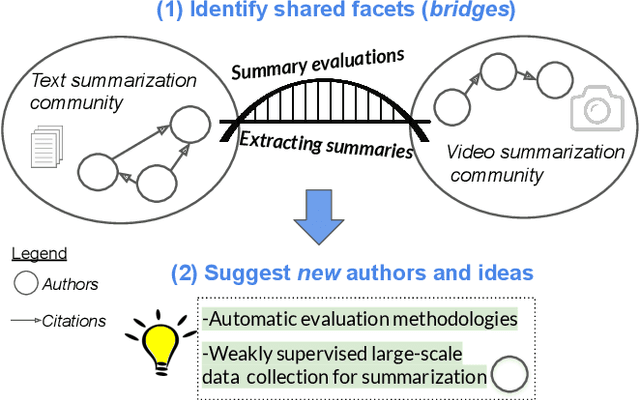
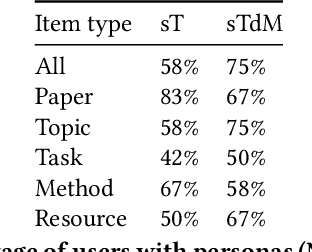
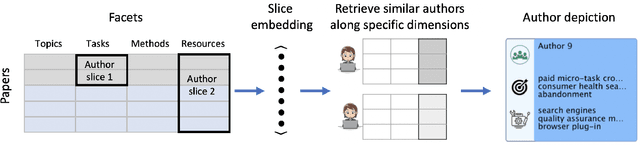
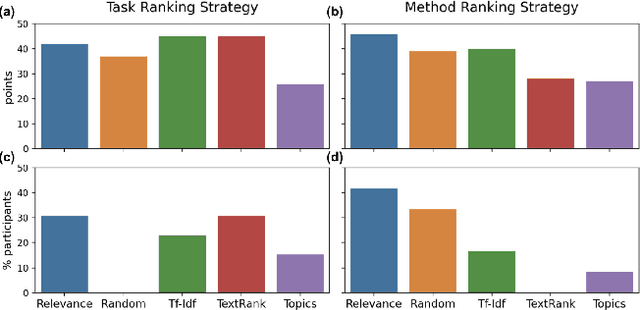
Isolated silos of scientific research and the growing challenge of information overload limit awareness across the literature and hinder innovation. Algorithmic curation and recommendation, which often prioritize relevance, can further reinforce these informational "filter bubbles." In response, we describe Bridger, a system for facilitating discovery of scholars and their work, to explore design tradeoffs between relevant and novel recommendations. We construct a faceted representation of authors with information gleaned from their papers and inferred author personas, and use it to develop an approach that locates commonalities ("bridges") and contrasts between scientists -- retrieving partially similar authors rather than aiming for strict similarity. In studies with computer science researchers, this approach helps users discover authors considered useful for generating novel research directions, outperforming a state-of-art neural model. In addition to recommending new content, we also demonstrate an approach for displaying it in a manner that boosts researchers' ability to understand the work of authors with whom they are unfamiliar. Finally, our analysis reveals that Bridger connects authors who have different citation profiles, publish in different venues, and are more distant in social co-authorship networks, raising the prospect of bridging diverse communities and facilitating discovery.